
基于改进YOLOv5的安全帽佩戴检测算法
2022-05-07 07:08屈佩琪
计算机应用 2022年4期
张 锦,屈佩琪*,孙 程,罗 蒙
(1.湖南师范大学信息科学与工程学院,长沙 410081;2.湖南师范大学数学与统计学院,长沙 410081)
0 引言
建筑业是一个高风险行业,建筑工人在工作过程中极易受伤,如若头部一旦受伤,结果往往是致命的。根据国家安全生产监督管理局2015-2018 年发布的一系列事故数据统计,在记录的78 起建筑事故中,其中有53 起事件是由于工人没有佩戴安全帽而引发的,占事故总数的67.95%。在施工现场的安全管理中,监督施工人员佩戴安全防护器具是必不可少的。安全帽可以承受和分散坠落物体的撞击,更能防止工人被高处坠落物体砸伤,未佩戴安全帽的施工工人更容易受伤。但由于建筑工人的自我安全防范意识欠缺,往往轻视佩戴安全帽的重要性。在建筑工地上,通常采用人工监督的方法判断工人是否佩戴安全帽,由于施工人员作业范围广,易造成在施工现场不能及时追踪和管理所有工人等问题。采用自动监控方法有利于监管施工人员以及确认在施工现场中施工人员的安全帽佩戴情况,特别是考虑到传统人工监督方法往往成本高、耗时长、容易出错,不足以满足现代施工安全管理的要求,自动监督的视觉方法有利于现场实时监控。
传统的目标检测通常采用人工选择特征,并根据特定的检测对象设计和训练分类器,该方法主观性强,设计过程复杂,泛化能力差,在工程应用上有较大局限性。近年来,因卷积神经网络(Convolutional Neural Network,CNN)不采用人工选择特征这一特点,逐渐受深度学习领域的学者们追捧。2014 年,Girshick 等陆续提出了R-CNN(Region-CNN)、Fast R-CNN 和Faster R-CNN,并分别在PASCAL VOC(the PASCAL Visual Object Classes)2007 数据集上进行验证,检测效果逐步得到提升。这些模型提取特征框的方式从选择性搜索(Selective Search)逐步变化到区域建议网络(Region Proposal Network,RPN),从而摆脱了传统的手工提取特征方法。2015 年,Redmon 等提出了一阶段检测算法YOLO(You Only Look Once),该算法首次将检测任务抽象为回归问题,避免了R-CNN 系列中将检测任务分两步完成的繁琐操 作。2016 年,Liu 等提 出SSD(Single Shot multibox Detector)算法,引入了多尺度检测方法,可有效检测成群小目标。2017 年,Redmon 等提出了YOLOv2,该算法采用了新的基础算法Darknet-19,并实现了端到端的训练。2018年,Redmon 等在YOLO、YOLOv2 基础上,进一步提出了YOLOv3,该算法采用特征金字塔网络(Feature Pyramid Network,FPN)方法融合三个不同尺寸的特征图层(Feature Map)进行检测任务,显著提高了小尺寸目标的检测效果。2020 年4 月,Bochkovskiy 等提出了YOLOv4,该算法选用CSP(Cross Stage Partial)Darknet-53为骨干网络,并采用PANet(Path Aggregation Network)路径聚合方法替换YOLOv3网络中的FPN 算法,大幅度提高了算法的检测精度。2020年6 月,Ultralytics提出了YOLOv5,该算法在骨干网络中新增了Focus 结构,实现了速度和准确率的最佳平衡新基准。
因深度学习在目标检测领域高速发展,许多研究学者致力于将深度学习领域与实际应用场景相结合,例如,Zhang等利用Faster R-CNN 中RPN 处理小目标以及负样本,并采用随机森林对候选区域进行分类,使行人检测中检测效果不佳状况得到大幅度改善。宋欢欢等将改进的RetinaNet 应用于车辆识别领域,实现了快速检测车辆。陈磊等将YOLOv3 网络最后一层的特征输出和上一层网络的输出进行融合,形成双向金字塔特征层,改善了对遥感图像中小目标的识别效果。邓壮来等通过压缩模型的SSD 对粮仓害虫进行检测识别,减少了粮食损失。张海川等将UNet++结合条件生成对抗网络(Conditional Generative Adversarial Net,CGAN)实现了道路裂缝检测。由此可见,深度学习已成为热门研究领域,将其与实际应用场景相结合已成为一种主流方向。
安全帽检测便是目标检测应用领域中的一种。截至目前,国内外已有大量学者对安全帽检测进行了一系列相关研究。2013 年,Kelm 等设计了一个移动射频识别(Radio Frequency IDentification,RFID)门户,用于检查人员的个人防护装备(Personal Protective Equipment,PPE)的合规性。然而,射频识别阅读器的工作范围是有限的,只能建议安全帽靠近工人,但不能确认安全帽是否被佩戴。2014 年,刘晓慧等使用支持向量机(Support Vector Machine,SVM)和肤色检测相结合的方式来实现安全帽检测。2015 年,Shrestha等使用类似Haar 的特征来检测人脸,并使用边缘检测算法查找安全帽轮廓特征。2016 年,Rubaiya 等将图像中的频域信息和梯度直方图(Histogram of Orientation Gradient,HOG)算法结合用于检测人体,再采用圆环霍夫变换(Circle Hough Transform,CHT)检测安全帽。2017 年,李琪瑞用Vibe(Visual background extractor)算法来定位人体,再采取凸字算法检测头部,最后将HOG 算法和SVM 结合实现安全帽佩戴检测。2018 年,Wu 等提出一种由局部二值模式(Local Binary Patterns,LBP)、颜色直方图(Color Histograms,CH)和Hu 矩阵不变量(Hu Moment Invariants,HMI)组成的混合描述子来提取安全帽特征,再构建分层支持向量机(Hierarchical SVM,H-SVM)对安全帽进行分类。因环境复杂造成现阶段安全帽佩戴检测检测准确率较低,不符合实际生产环境的监测需求。
本文以佩戴安全帽的施工作业人员和未佩戴安全帽的施工作业人员两类目标为检测任务,并从网上采集7 000 余张图片进行预处理,构建安全帽检测数据集。选取YOLOv5算法为主体,首先采用K
-Means++聚类算法对目标框大小进行聚类,获取适合目标的边界框,使算法能够更快收敛;其次在骨干网络特征融合处引入多光谱通道注意力(Multispectral Channel Attention,MCA)模块,加强对检测目标的关注从而提高抗背景干扰能力,并采用多尺度训练策略进行训练,提高网络的泛化能力。实验结果表明,改进后的YOLOv5 算法的均值平均精度(mean Average Precision,mAP)明显提升,能够满足施工场景下的检测要求。1 相关工作
1.1 YOLOv5目标检测算法原理
YOLOv5 是YOLO 系列新一代的目标检测网络,在YOLOv3 以及YOLOv4 基础上不断集成创新的产物。其次,YOLOv5 在PASCAL VOC 与COCO(Common Objects in COntext)目标检测任务上获得了较好的效果,因而本文采用YOLOv5 检测网络来进行安全帽佩戴检测。
YOLOv5 目标检测网络官方给出了YOLOv5s、YOLOv5m、YOLOv51 以 及YOLOv5x四个算法。其中YOLOv5s 算法是YOLOv5 这一系列中深度最小,特征图宽度最小的网络,而YOLOv5m、YOLOv51 以及YOLOv5x 这三个算法都是在YOLOv5s 的基础上不断加深以及加宽的产物。
YOLOv5 网络结构分为输入端、骨干网络(Backbone)、颈部(Neck)及预测部分(Prediction)。YOLOv5 在数据输入部分新加马赛克(Mosaic)数据增强;Backbone 中主要采用Focus 结构和CSP(Cross Stage Partial network)结构;Neck 中加入FPN+PAN(Path Aggregation Network)结构;Prediction 中将边界锚框的损失函数由完全交并比(Complete Intersection over Union,CIoU)损失改进为广义交并比(Generalized Intersection over Union,GIoU)损失;在目标检测后处理过程中,YOLOv5 采用加权NMS(Non-Maximum Suppression)运算对多个目标锚框进行筛选。
相较于YOLOv4,YOLOv5 的骨干网络中新增了Focus 结构,主要用来进行切片操作。在YOLOv5s 算法中,将尺寸为3×608×608 的普通图像输入网络,经一次Focus 切片运算,转换大小为12×304×304 的特征图,再将其通过32 个卷积核的普通卷积运算转换为大小为32×304×304 的特征图。不同于YOLOv4 算法在骨干网络中只使用CSP 结构,YOLOv5 算法设计了两种新的CSP 结构,以YOLOv5s 算法为例,骨干网络采用CSP1_1 结构和CSP1_3 结构,颈部采用CSP2_1 结构,加强网络之间的特征融合。YOLOv5s 的网络结构如图1 所示。
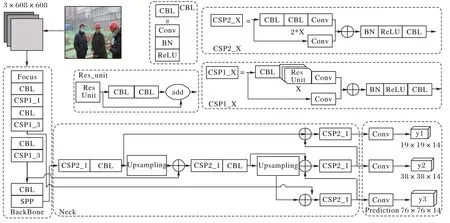
图1 YOLOv5s的网络结构Fig.1 YOLOv5s network structure
1.2 多光谱通道注意力
传统的通道注意力模块致力于构造各种通道重要性权重函数,例如,挤压激励网络(Squeeze and Excitation Network,SENet)提出了通道注意力机制,它对通道执行全局平均池(Global Average Pooling,GAP),然后使用全连接层来自适应地计算每个通道的权重。高效通道注意力网络(Efficient Channel Attention Network,ECA-Net)在局部使用一维卷积层以减少全连接层的冗余,并获得了显著的性能改进。集成双路注意力(Dual Attention Network,DANet)机制通过模拟通道和空间维度中的语义相互依赖性来提高语义分割的准确率。卷积注意力模块(Convolutional Block Attention Module,CBAM)表明由于信息的丢失,GAP 只能获得次优特征,为解决该问题,它采用GAP 和全局最大池来增强特征多样性。由于计算开销受限,权重函数要求每个通道都有一个标量进行计算,而GAP 由于其简单高效成为深度学习领域的一个标准选择。虽然这种选择简单高效,但GAP 不能很好地捕获丰富的输入模式信息,因此在处理不同的输入时缺乏特征多样性。
为解决该问题,本文采用多光谱通道注意力(MCA)模块。文献[24]表明,GAP 是离散余弦变量(Discrete Cosine Transform,DCT)的最低频率,仅使用GAP 等价于在特征通道中丢弃了包含大量信息的其他频率分量。多光谱通道注意力模块尽管和其他注意力模块有相同的出发点,但多光谱通道注意力模块不仅保留了全局平均池,还使用了除全局平均池之外的频率分量,可以解决因只关注单个频率而造成的信息缺失问题,使算法更关注重要特征,滤除冗余特征。多光谱通道注意力模块是基于SE(Squeeze and Excitation)模块改进的,具体结构对比示意图如图2 所示。
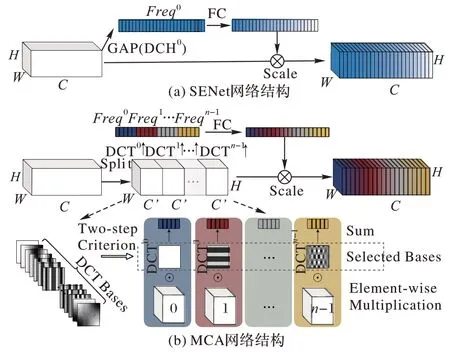
图2 SENet和MCA的结构对比Fig.2 Structure comparison between SENet and MCA
为了引入更多的信息,多光谱通道注意力模块采用二维DCT来融合多个频率分量,包括最低的频率分量,即GAP。具体操作流程如下:首先,根据通道维度将输入X
划分为n
个部分,其中n
必须能被通道数整除。对于其中每一部分,分配相应的二维DCT 频率分量,其结果可作为通道注意力的预处理结果(类似于GAP),如式(1)所示: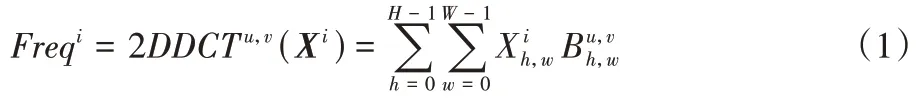
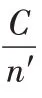
Frep
∈R即为多光谱向量,如式(2)所示: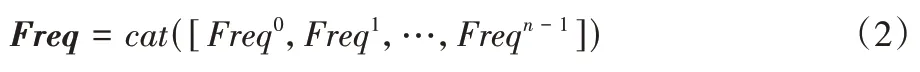
因此,整个MCA 框架可以表示为式(3):

fc
表示映射函数,如全连接层或一维卷积。2 改进YOLOv5算法
2.1 K-Means++进行目标锚框优化
对通用目标检测数据集COCO 进行K
均值(K
-Means)维度聚类,得到YOLOv5 初始先验锚框参数,但因COCO 数据集的目标种类有80 个类别,而本文中的安全帽检测种类只有两个类别,不能满足安全帽佩戴检测的实际需要,所以需要重新设计先验锚框大小。相较于只依赖人的先验知识而设计的锚框尺寸大小,本文采用K
-Means++聚类算法多次对安全帽佩戴数据集中已标注的目标边界锚框聚类,产生不同数量、不同大小的先验框,尽可能增加先验框与实际目标框之间的匹配度,从而进一步提高检测准确率。在聚类过程中,不同簇的中心个数对应的平均交并比(Mean Intersection over Union,MIoU)如图3 所示。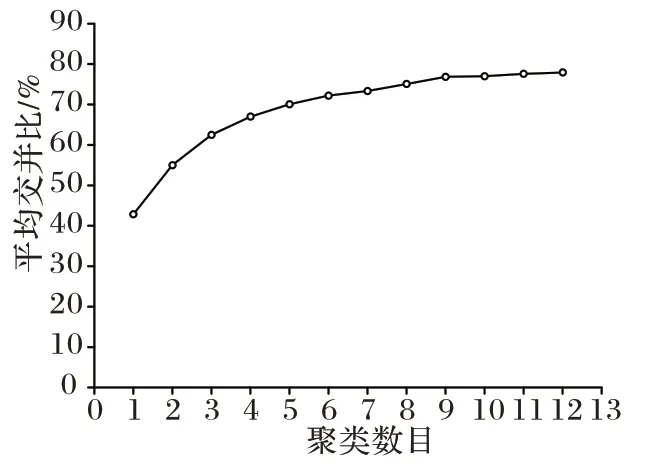
图3 不同簇的中心个数与对应的MIoUFig.3 Number of centers of different clusters and corresponding MIoU
由图3 可看出,先验锚框聚类数目在0 到9 个时,MIoU 呈快速上涨趋势;但先验锚框数目在9 到12 个时,MIoU 增长速率逐渐平缓。为了平衡计算效率与准确率,最终选用9 个先验锚框尺寸,并等分到3 个大小不同的预测分支上,确定的先验锚框尺寸经归一化后如表1 所示。
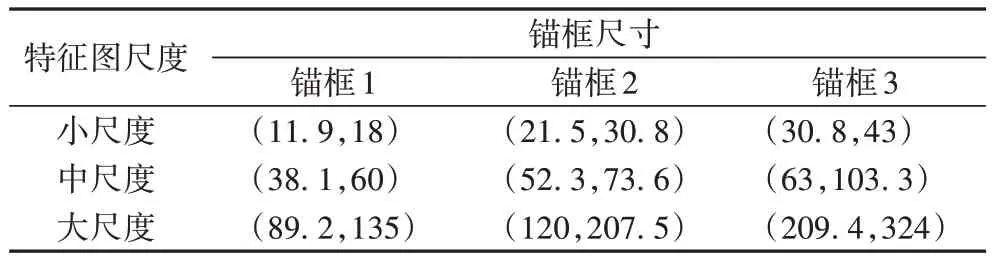
表1 先验锚框尺寸Tab 1 Anchor box size
表2 为算法性能比较,其中,将先验锚框的聚类算法由K
-Means 算法改为K
-Means++算法后,mAP 得到了一定程度的提高,由于网络结构发生改变,改进后的YOLOv5 的检测精度也有了较大提升。同时选取K
-Means++算法和MCA 模块的改进YOLOv5 算法与原始YOLOv5 算法相比,在自制的安全帽佩戴检测数据集上的mAP 提升了3.4 个百分点,能够准确地检测出施工作业人员是否佩戴安全帽。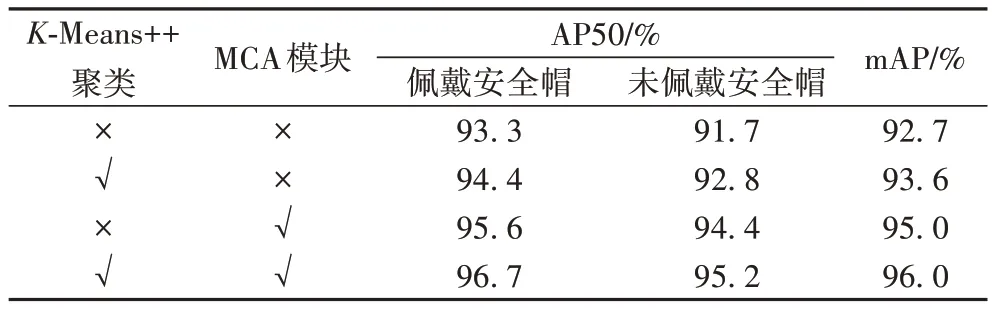
表2 YOLOv5在不同改进下的性能对比Tab 2 Performance comparison of different improvements of YOLOv5
2.2 MCA模块融合设计
文献[24]的实验结果表明:在ResNet(Residual Network)中添加MCA 模块可在图像分类领域取得较好的效果,但在目标检测领域,在网络哪个位置中融合MCA 模块能有效提升准确率仍是一个待研究的问题。
在小目标检测任务中,随着网络层数逐步地增加,可采集的小目标特征信息也逐步减弱,所以容易引起算法对小目标的误检和漏检。而MCA 模块本身采用全局平均池和其余频率分量对特征图中特征进行增强,使网络在训练过程中加强对目标特征的易忽视点学习。但是现阶段仍未有研究表明MCA 机制模块应融合网络哪一位置可有效提高检测效率。
受文献[29-31]启发,本文将MCA 模块融合至网络模型的不同位置,并对检测结果展开研究。根据YOLOv5s 算法的结构,本文在YOLOv5s 的骨干网络、颈部以及预测模块三个区域分别融合MCA 模块。由于MCA 模块是在重要通道以及空间位置进行特征增强,所以本文将MCA 模块分别融合至上述三部分中的每一特征融合区域,从而产生三种基于YOLOv5s的改进算法:MCA-YOLOv5s-BackBone、MCAYOLOv5s-Neck、MCA-YOLOv5s-Prediction,图4展示了MCA模块融合网络的具体位置。
由图4(a)可以看出,在YOLOv5s 的骨干网络中,将MCA模块融合到CSP1_3 处(即特征融合处);由图4(b)可以看出,将MCA 模块融合到YOLOv5s 的颈部Concat 层后;由图4(c)可以看出,在YOLOv5s 每一个预测模块的卷积之前分别融合一个MCA 模块。
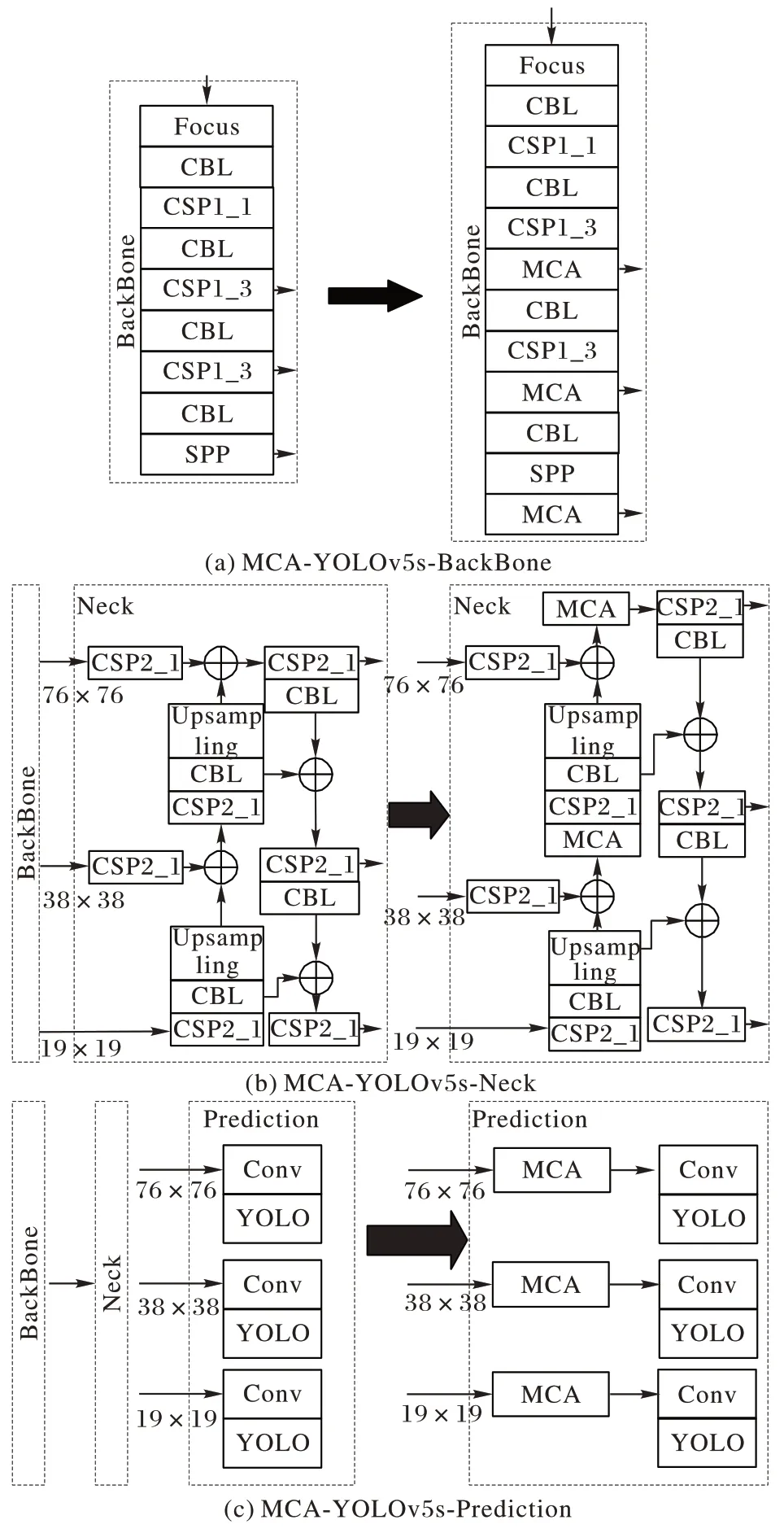
图4 三种融合MCA模块的YOLOv5s算法Fig.4 Three YOLOv5s algorithms fusing MCA module
在三个不同位置融合MCA 模块以及未融合MCA 模块的实验对比结果如表3 所示。其中,大中小目标以及mAP 评价指标均采用0.5 的IoU 阈值。
为了更加清晰观察到融合MCA 模块的网络在不同大小的目标上的检测能力,本文根据目标大小将实例划分为三个比例类别:小目标(像素面积≤32)、中等目标(32<像素面积≤96)和大目标(像素面积>96)。从表3 中观察可得:在YOLOv5s 的骨干网络部分融合MCA 模块后,小目标的检测准确率明显提升,能有效提高网络对小目标物体的检测效果,mAP 提高了3.4 个百分点;而在YOLOv5s 的颈部和预测模块中融合MCA 模块后,算法的性能不仅没有得到提升,反之mAP 下降了1.1 个百分点和0.3 个百分点。本文认为MCA 模块融合至算法中不同位置之所以产生不同实验效果,是由于骨干网络中虽语义信息不丰富,但仍隐含着目标在中低层中易忽视的纹理信息以及轮廓信息,在骨干网络中融合MCA 模块能够更好地将特征图中小目标的空间特征和通道特征进行融合,从而增强特征信息;而在网络更深层的颈部以及预测模块,因其特征图有更丰富的语义特征、更小尺寸的特征图以及庞大的感受野,MCA 模块难以区分重要的空间特征和通道特征。
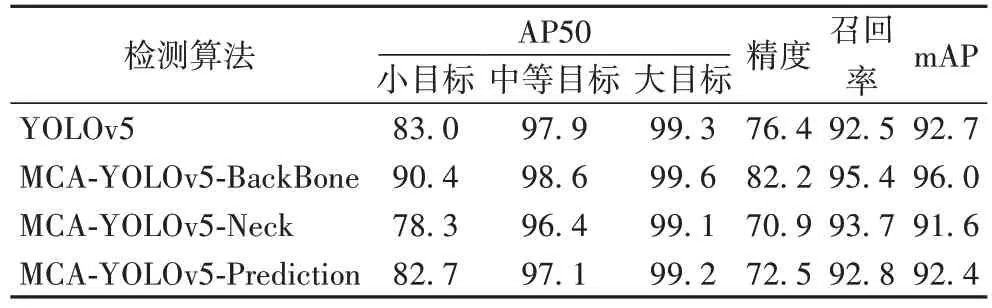
表3 MCA模块融合结果对比 单位:%Tab 3 Comparison of MCA module fusion results unit:%
2.3 多尺度训练
改进后的网络使用卷积网络提取特征,而不是使用全连接层。因此,在模型训练过程中,不需要固定输入图像的大小。
由于改进后的算法中包含5 个残差结构,所以在训练过程中输入图像的尺寸应该是32 的倍数以及图像的最小尺寸应该是输入图像的1/32。将自制安全帽数据集中图片分为多种尺寸,比如320、352、384 和608 等。在算法迭代训练过程中,每隔10 次随机更换一种图像输入尺寸,使算法能够适应不同大小图像的变化。多尺度训练过程示意图如图5所示。
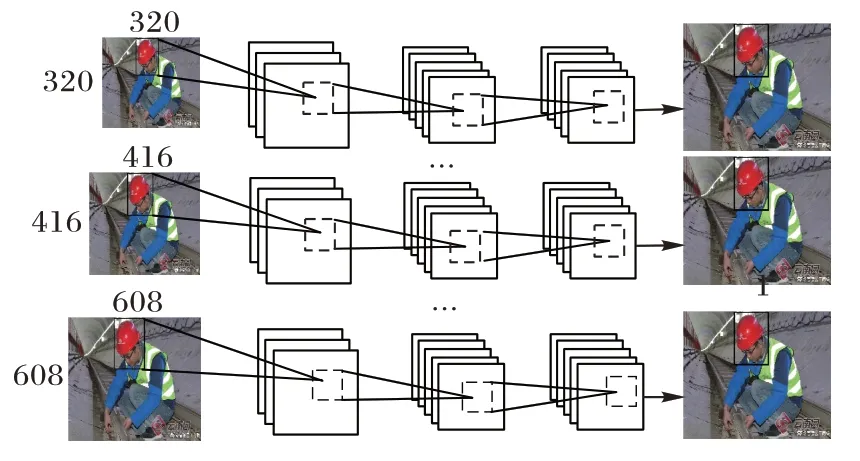
图5 多尺度检测过程示意图Fig.5 Schematic diagram of multi-scale detection process
采用多尺度策略训练的算法可以接受任意尺寸大小的图像作为输入,有助于增强算法泛化能力。
3 实验与结果分析
3.1 数据集构建
在深度学习检测领域,实验所需的数据集一直都是必不可缺的基础条件。已开源的安全帽数据集只有SHWD(Safety Helmet Wearing-Dataset),该数据集中未佩戴安全帽这一类别标签数据主要来源于SCUT-HEAD 数据集,其中SCUT-HEAD 数据集是在教室场景下学生上课的监控图像或者拍摄的照片,所以该数据集不是一个标准的工地场景数据集,不符合实际生产环境中实时监测需求。为了解决这一问题,本文自制了一个施工场景下安全帽佩戴检测数据集,构建该数据集的主要过程有:数据收集、数据筛选和数据处理。
3.1.1 数据收集
本文数据集所需的图像主要来源于公开数据集清洗、施工现场监控视频分帧、施工现场自行采集以及互联网爬取等。所搜集到的数据包括不同环境、不同分辨率、不同施工场地的工人佩戴安全帽和未佩戴安全帽两种类型的图片,并在该数据集中添加多组干扰图片,例如佩戴棒球帽的施工人员、将安全帽放置在桌上或手持的施工人员、佩戴竹编帽的施工人员等,增加数据集的多样性,以此来增强算法的泛化能力。本次采集到的数据集样本如图6 所示。

图6 安全帽样本图像示例Fig.6 Sample images of safety helmet
3.1.2 数据筛选与处理
从施工现场监控视频中分帧或互联网上爬取所采集的图片中,很多图片没有施工人员这一研究对象,可以视为背景图片,这对本文研究无实际意义,因此需要删除这些已确认的背景图片数据。本文对采集的图片数据进行初步筛选,从中选出符合要求的图片作为标注数据集。
对数据进行预处理,将符合要求的图片转化为.jpg 格式,并使用标注工具labelImg 对每张图片进行手动标注,将图像中施工人员按照佩戴安全帽(hat)以及未佩戴安全帽(person)这两个类别进行标注,如图7,经过处理,形成相应的xml 标签文件,该文件包含目标在框架内的四个坐标以及给定的类别(PASCAL VOC 格式)。
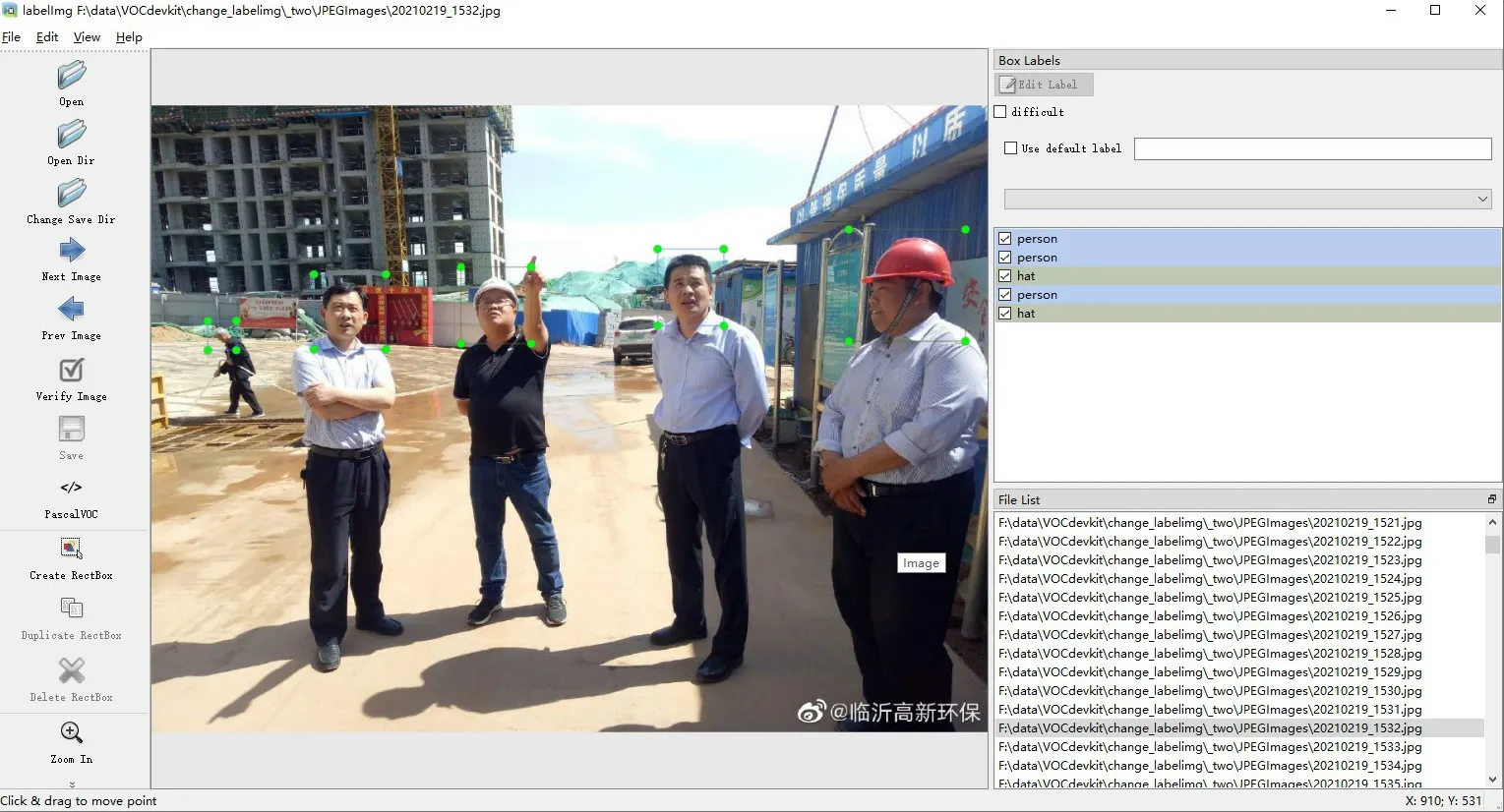
图7 安全帽佩戴情况标注Fig.7 Marking of safety helmet wearing
本文最终得到的数据集共有7 076 张图片,其中该数据集中佩戴安全帽与不佩戴安全帽的目标具体信息如表4 所示。该数据集中包含多种施工场景,能够较为完备地反映真实施工场景的情况。将所得到的数据集按照9∶1 划分为训练集和测试集,最后7 076 张图片数据集中训练集图片数量为6 370 张,测试集图片数量为706 张。

表4 数据集类别分配Tab 4 Dataset category distribution
3.2 实验环境与网络训练
3.2.1 实验环境
本文实验需要较好的硬件配置以及GPU(Graphics Processing Unit)加速运算。其中模型的搭建、训练和结果的测试均在Pytorch 框架下完成,使用CUDA(Compute Unified Device Architecture)并行计算架构,同时将CU-DNN(CUda Deep Neural Network library)加速库集成到Pytorch 框架下提高计算机计算能力,实验所需运行环境具体见表5。
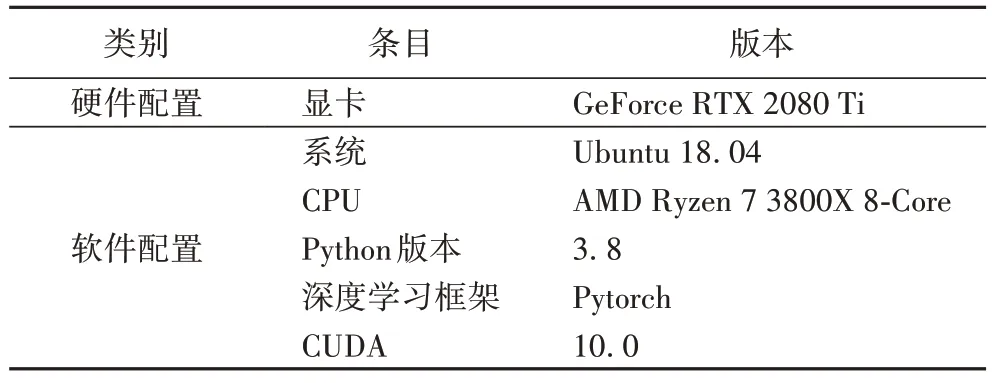
表5 实验运行环境Tab 5 Experimental operating environment
3.2.2 网络训练
在YOLOv5 模型训练中,模型结构的损失函数Loss 值越小越好,期望值为0。为了实现模型的最佳性能,在训练过程中,将迭代次数设置为1 700,权重衰减系数设置为0.000 1,学习率动量设置为0.937,以防止模型过拟合。最大训练批次设置为32,在0 到1 000 次时损失函数值急剧下降;在1 000 到1 200 次时损失数缓慢下降;在经过1 200 次迭代后,损失值在0.02 附近趋于稳定,模型达到最优状态。训练Loss 变化如图8 所示。
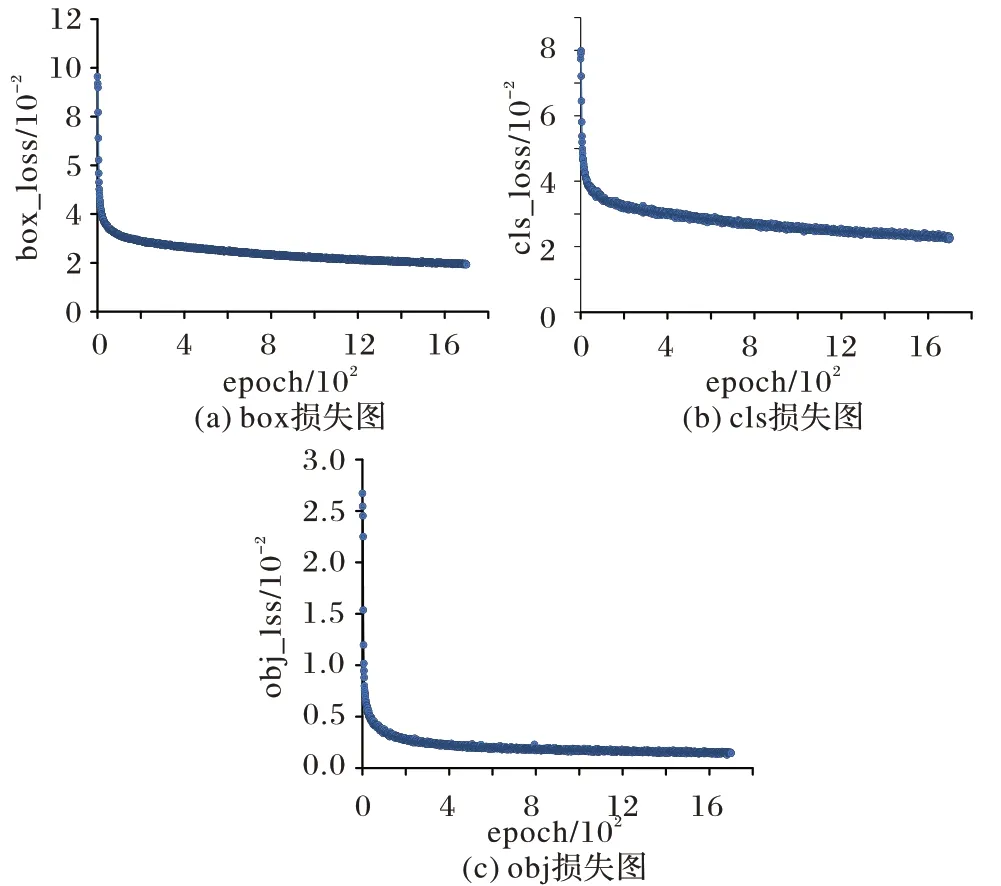
图8 改进YOLOv5的收敛情况Fig.8 Convergence of improved YOLOv5
3.3 评价指标
在目标检测领域,精度(Precision,P)、召回率(Recall,R)和均值平均精度(mAP)是评估训练算法性能和可靠性的常用指标,本文同样使用上述评价指标对安全帽佩戴检测算法性能进行评估。
将上述评价指标应用于安全帽检测算法的性能测试,可得到两类结果图像,包括佩戴安全帽的施工作业人员和未佩戴安全帽的施工作业人员。其中,真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)和假反例(False Negative,FN)是用来描述精度的关键指标。具体来说,TP
是指在施工现场监控范围内未佩戴安全帽的人数,同时检测结果正确;FP
表示实际上佩戴安全帽但被检测为未佩戴安全帽的人数;TN
表示算法检测正确;FN
表示未佩戴安全帽但被错误检测到的人数。计算公式如下: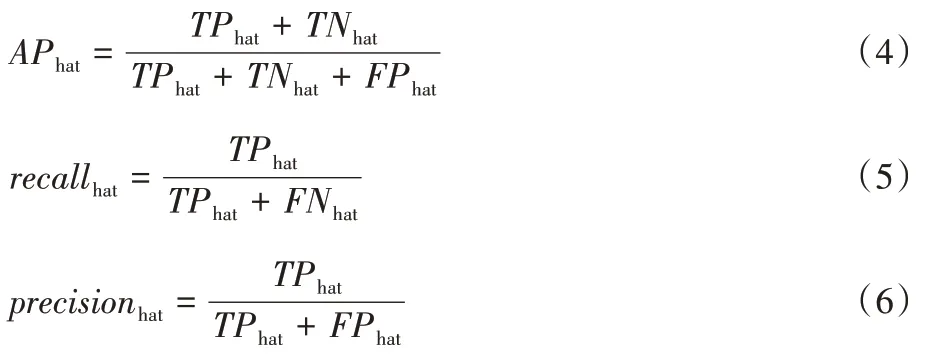
recall
表示真正例(TP
)与真正例和假反例之和(TP
+FN
)的比值,真正例和假反例之和为实际安全帽数量;precision
表示真正例(TP
)与真正例和假真例之和(TP
+FP
)的比值,真正例和假真例之和为安全帽检出的数量。平均精度(Average Precision,AP)是指在所有召回率的可能取值情况下得到的所有精度的平均值。其中,AP50 为IoU 阈值取0.5 时对应的AP 值。均值平均精度(mAP)为AP值在所有类别下取平均,计算公式如下:

3.4 结果分析
为了验证本文所提算法(MCA-YOLOv5)具有更好的效果,在相同的配置条件下使用相同数量的测试集,并使用目前比较流行的几种目标检测网络进行对比实验:Faster R-CNN、SSD 以及YOLOv3 等。其中,SSD 和YOLOv3 为一阶段检测算法,Faster R-CNN 为两阶段检测算法。实验结果以AP50 和mAP 这两项评价指标来分别进行评价,具体实验结果见表6。

表6 多种检测算法结果对比Tab 6 Comparison of results of multiple detection algorithms
由表6 可知,本文算法能够有效提高对安全帽以及未佩戴安全帽的施工人员的检测精度。本文算法对佩戴安全帽的施工人员检测平均精度为96.70%;对未佩戴安全帽的施工人员检测平均精度为95.20%;mAP 达到96.00%,远高于Faster R-CNN 和SSD 的。本文算法与YOLOv3、增加SPP 结构的YOLOv3 以及原始YOLOv5 相比,在AP50 和mAP 上都有一定提升。由此说明,本文算法在安全帽佩戴检测检测准确性方面表现优秀,能够满足现在复杂作业环境下安全帽检测的准确率要求。
此外,为了更加直观地看出不同算法之间的检测差距,本文另外采集了187 张施工作业现场图片作为验证集。在这个测试集上分别用YOLOv5 和本文改进后的YOLOv5 算法进行检测,部分测试结果如图9 所示,其中图中佩戴安全帽的施工作业人员上方出现“hat”字样,未佩戴安全帽的施工作业人员上方出现“person”字样。图9(a)为强光照施工场景下的检测,可以看出YOLOv5 原算法将石膏圆饼错认为一个佩戴安全帽的施工人员,而改进算法完全检测正确;图9(b)为钢筋遮挡施工场景下的小目标检测,经观察,原算法漏检了一个挡在钢筋后面的佩戴安全帽的施工人员;图9(c)为不同尺寸目标的检测,近景的目标尺寸较大,远景的目标尺寸较小,改进算法全部检测出来了,而原算法漏检了远景下的小目标;图9(d)为远距离施工场景下的小目标检测,对比可知,YOLOv5 原算法对远距离佩戴安全帽的施工作业人员以及未佩戴安全帽的施工作业人员都有出现漏检和错检情况,而改进算法检测效果较好;图9(e)为弱光照施工场景下的小目标检测,在光照不充足的情况下,因图像容易因像素模糊、图像中的目标较小等多种情况,YOLOv5原算法对这种情况漏检较多,但改进算法表现较好。由上述多种施工场景下的检测比较可知,改进后的YOLOv5 算法在复杂作业环境下对安全帽检测效果较好。

图9 不同施工场景下检测结果对比Fig.9 Comparison of detection results in different construction scenarios
4 结语
本文提出了一种基于改进YOLOv5 的安全帽佩戴检测算法。首先,选取K
-Means++算法对自制施工场景数据集中目标进行锚框聚类;其次,在特征提取网络中融合多光谱通道注意力模块,可以获取更多细节信息并采用多尺度训练策略减少图像尺寸变化带来的影响。实验结果表明,本文算法能够获得较好的检测精度,基本满足现在复杂施工场景下安全帽佩戴检测的均值精度需求。未来将继续探索如何减少算法参数量以及提升算法检测速率。