
结合长尾数据解决方法的野生动物目标检测
2022-05-07 07:08蔡前舟郑伯川曾祥银
计算机应用 2022年4期
蔡前舟,郑伯川,曾祥银,侯 金
(1.西华师范大学数学与信息学院,四川南充 637009;2.西华师范大学计算机学院,四川南充 637009;3.西华师范大学生命科学学院,四川南充 637009)
0 引言
红外线照相设备由于具有安装方便、对野生动物没有伤害等优点,目前已经成为野生动物调查研究的主要工具。当野生动物出现在红外线照相设备前面时,红外线照相设备可以自动拍摄到野生动物图像和视频。研究人员通过对图像和视频分析可以获得野生动物的生活习惯、种类和数量等有价值的信息,获得这些信息有利于对野生动物进行更好的保护。红外相机可以长期在野外环境自动采集图像和视频,因此随着时间推移,将会产生大量的野生动物图像和视频数据。如果通过人工观看方式分析识别图像和视频中的动物种类和数量将消耗大量的人力物力。随着计算机技术的发展,采用计算机视觉技术自动识别图像中野生动物种类和数量已经成为研究的热点问题,特别是采用神经网络进行野生动物种类的识别已经成为了首要方法。
基于神经网络的野生动物种类和数量自动识别方法需要标注大量的样本数据,但是由于野生动物种类数量不同,造成采集到图像数据集中每个野生动物种类的样本数量不同,一些野生动物种类的样本数量占比大,而一些占比较小。如图1 所示,不同种类的野生动物样本数量分布呈现出一条长长的尾巴,通常将有这样分布的数据集叫作长尾数据,将占比大的类称为头部类,占比小的类称为尾部类。
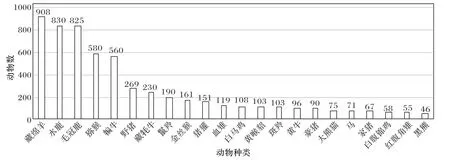
图1 野生动物数据集的种类数量分布Fig.1 Distribution of the numbers of species in wildlife dataset
从图1 可以看出,尾部类的野生动物种类样本数量很少,不同种类动物的样本数量分布极不均匀。与COCO(Microsoft Common Objects in COntext)、ImageNet、Cifar等均衡数据集不同,用长尾数据集训练深度神经网络时,由于头部类样本数量远多于尾部类样本数量,所得模型预测结果会偏向头部类,使得尾部类的识别错误率上升,导致整体预测正确率下降。最近的一些研究旨在减小这种长尾问题的错误率,提出了一些解决方法,这些方法大致可分成三种策略:重采样、重加权和迁移学习。在重采样中,可以对尾部类样本进行过采样(添加重复数据)或者是对头部类样本进行欠采样(删除部分样本)来调整样本数量,使得数据集中各个类别的数量变得均匀,从而提升整体准确率。例如王俊红等提出了一种基于欠采样和代价敏感的不平衡数据分类算法,在不平衡数据上表现出了更好的分类性能。在重加权中,通过给尾部类样本分配更高的权重来影响损失函数。此类方法变种很多,例如最简单的使用逆序加权、按照有效样本数加权、根据样本数优化类间距的损失加权、根据正负样本之间的成对损失进行加权等。迁移学习是对头部样本和尾部样本分别建立模型,将学到的头部样本的知识迁移给尾部样本使用,例如:Xiang 等发现一个更均衡子集的训练结果反而比利用完整的数据集效果更好,因此采用多个子集来训练出更均衡的专家模型去指导一个学生模型。Zhang 等针对两个阶段训练的数据集有偏差的问题,提出了标签感知平滑和规范化批处理方法。
本文在自采集并标注的野生动物数据集上开展研究,由于YOLO(You Only Look Once)系列方法中YOLOv4-Tiny目标检测网络具有参数小、识别速度快的优点,因此更容易加载到便携式设备上,实现在边缘设备上目标自动检测。基于此,本文利用YOLOv4-Tiny 目标检测网络检测野生动物目标,从而识别野生动物种类。重点针对数据集的长尾情况,提出了一种基于两阶段学习和重加权相结合的方法,其中重加权方法是对文献[13]中的加权方法进行改进而来。
本文主要工作包括:
1)建立了一个新的野生动物数据集,该数据集包含22种野生动物种类,共有4 123 张图像,每张图像中都标注了野生动物的位置和类别。
2)采用两阶段训练方法训练神经网络:第一阶段在分类损失函数中采用无加权方式进行训练,使得网络对头部数据进行了充分训练;第二阶段则采用第一阶段学习到的模型作为预训练模型进行重加权训练,使得尾部数据能够得到更高的权重。
3)对文献[13]中的有效样本加权方法进行了改进,用真实采集数据量代替特征空间中所有可能数据量,直接依据每类野生动物样本数量确定每个类别的特定权重参数,不需要反复实验测试获得全局统一权重参数。
1 相关工作
1.1 野生动物识别
利用红外线照相设备可以在不干扰野生动物的情况下采集野生动物图像和视频,当前一些研究通过神经网络对采集到的野生动物图像进行分类识别。Zhu 等针对采集图像清晰度低的问题提出了一种双通道感知残差金字塔网络,通过该网络可生成高分辨率和高质量的图像,并且利用网络中的残差块可以学习整合所有信息,获得全尺度检测分类结果。Chen 等使用深度卷积神经网络对20 种动物进行分类识别,他们使用自动分割方法从图像中裁剪出动物图像,然后用这些动物图像训练和测试网络模型。Gomez 等在文献[2]的基础上使用不均衡和分段式的数据集进行训练,并且使用了更深层数的神经网络进行分类识别。
1.2 长尾数据问题
现有解决长尾数据问题的方法可分为三类:数据重采样、数据重加权和迁移学习。
1.2.1 数据重采样
数据重采样技术指在数据预处理阶段通过各种重采样方法来平衡类别之间的数量。文献[9,22]通过从少数类样本中复制可用样本来增加样本数量,但是会产生过拟合问题。Chawla 等提出合成少数过采样技术(Synthetic Minority Oversampling Technique,SMOTE),通过在原始数据点之间插值创建合成数据,增加少数类数据的样本数量。同时也有一些SMOTE 的改进版本,如:Borderline SMOTE和Safe level SMOTE,但是这些过采样技术不能确保生成的新样本满足少数类样本的实际分布。除了增加少数类样本数量外,文献[10,26]则通过减少多数类样本数量来平衡类别之间的数量,这些研究方法虽然减少了多数类的样本数量,但一些重要的样本数据可能被删除,从而增加产生过拟合的风险。
1.2.2 数据重加权
数据重加权是通过在损失函数中给尾部类样本分配更高的权重比例来达到平衡的方法。最简单有效的加权方式是采用每类样本数量的倒数作为每类样本的权重,样本出现频率越高权重越低,反之亦然。文献[27]在此基础上进行了改进,采用逆类频率的平方根来计算样本权重。Cui等则计算每类样本的有效样本数,并根据有效样本数分配权重。上述方法都假设尾部类样本是最具代表性的样本,因此给它们分配更高的权重。但这种假设可能不正确,如果给予高权重的样本不具有代表性会导致整体性能下降。因此,Lin 等提出了一种称作“焦点损失”的加权技术,每个样本的难度根据该样本在网络中的损失来衡量,损失越大则样本难度越高。尾部类作为困难样本,通过焦点损失加权时会比头部类获得更高的权重。
1.2.3 迁移学习
迁移学习是指两个不同领域的知识迁移过程,利用源领域中学到的知识来帮助目标领域上的学习任务。处理长尾问题时,对尾部类采取重采样或者重加权的方式可能会使头部类的识别精度下降,影响整体性能。处理长尾问题采用迁移学习则是先学习原始数据的整体分布,然后再通过重采样或者重加权的方式去学习尾部类。Liu 等提出通过一种方法学习一组动态的元向量将头部的视觉信息知识迁移给尾部类别使用。这组动态元向量之所以可以迁移视觉知识,是因为它不仅结合直接的视觉特征,同时也利用一组关联的记忆特征,这组记忆特征允许尾部类别通过相似度来利用相关的头部信息。Kang 等提出将长尾分类模型的学习分成两步:首先在不做处理的情况下使用原始数据来获得一个学习模型,然后将学习模型中的权重参数固定,再单独接上一个分类器,对分类器进行重采样学习。Zhou 等提出的方法和文献[30]方法的想法类似,但是将模型两步的学习步骤合并成一个双分支模型,该模型的双分支共享参数,一个分支利用原始数据学习,另一个分支使用重采样学习,然后对这两个分支进行动态加权。
2 本文方法
本文提出了一种基于两阶段学习的重加权方法。第一阶段利用进行无加权学习,第二阶段利用第一阶段学习到的模型进行重加权训练,加权方法基于文献[13]改进而来。本章先介绍YOLOv4-Tiny 网络结构以及改进后的损失函数,再介绍具体的加权改进方法。
2.1 两阶段学习
由于两阶段学习可以在第一阶段学习整体数据,然后在第二阶段中通过重加权的方式使得模型重点关注尾部类样本。这种学习方法优点在于利用充分学习了头部类知识的网络去指导重加权下尾部类的网络,使得在不降低整体精度的情况下提升尾部类样本的分类精度。图2 中给出了两阶段学习的训练过程,主要思想是通过迁移学习将第一阶段训练所得的最优权重作为第二阶段的预训练权重进行训练,最后利用第二阶段的最优权重进行分类预测。
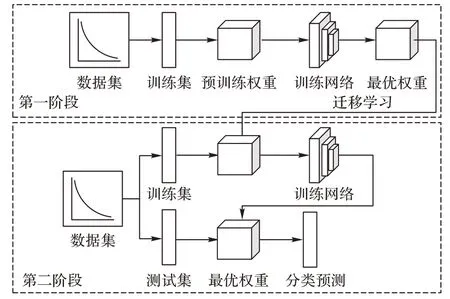
图2 两阶段训练过程Fig.2 Process of two-stage training
2.1.1 网络结构
YOLOv4-Tiny 网络结构如图3 所示,采用CSPDarknet53(Cross Stage Partial Network Darknet 53)作为主干特征提取网络,激活函数为LeakyReLU(Leaky Rectified Linear Unit)。CSPDarknet53 具有两个特点:1)使用CSPNet(CSP Network)结构,将原来的残差块的堆叠进行了拆分,拆成左右两部分,主干部分继续进行原残差块的堆叠,另一部分则像一条残差边,经过少量处理后直接连接,如图3 中的Res(N
)Unit 结构;2)进行通道的分割。CSPDarknet53 中会对一次3×3 卷积后的特征层进行通道划分,分成两部分,各自经过不同卷积核卷积后连接起来,如图3 中的CSP-N 结构。CSPDarknet53 后面连接特征金字塔网络(Feature Pyramid Network,FPN)用于融合两个不同大小的特征层。FPN 输出两个不同大小特征层,该两个特征层输入检测网络分别用于检测不同大小的目标。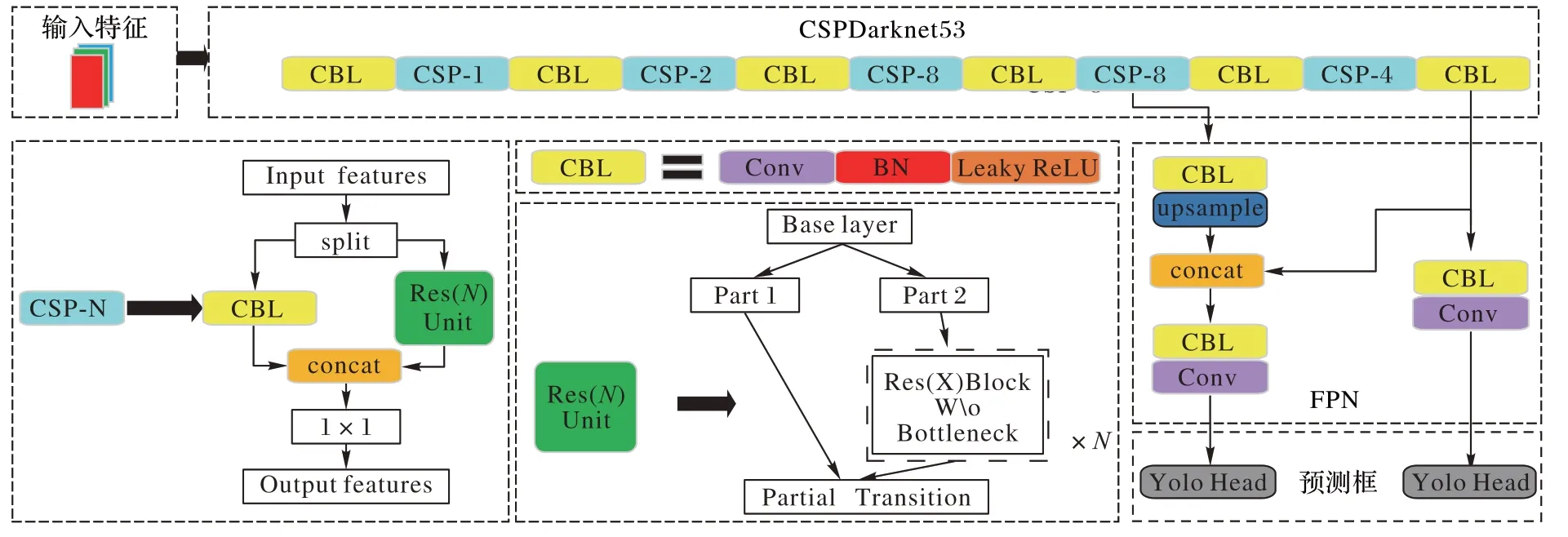
图3 YOLOv4-Tiny网络结构Fig.3 Network structure of YOLOv4-Tiny
2.1.2 损失函数
YOLOv4-Tiny 的损失函数主要由三部分构成,分别是预测边界框的坐标损失、含有物体的置信度损失以及物体类别预测值和真实值之间的分类损失,则总共损失Loss
可以写成: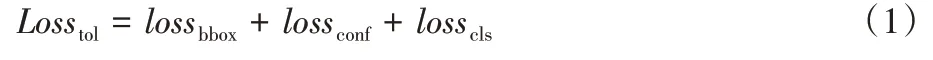
loss
是预测候选框与真实框边界之间产生的损失;loss
是该预测框是否含有物体的置信度损失;loss
是预测分类标签与真实分类标签的分类损失。由于完全交并比(Complete Intersection over Union,CIoU)损失对目标与锚框之间的距离、重叠率、尺度以及惩罚项都有考虑,使得目标框回归更稳定,不会出现类似IoU和广义IoU(Generalized IoU,GIoU)中的发散问题,因此将CIoU 作为预测边界框的损失。其计算公式如下:
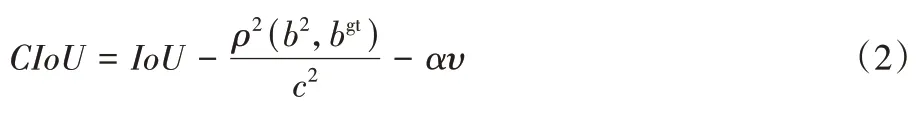
ρ
(b
,b
)表示预测框与真实框的中心点的欧氏距离;c
是能够同时包含预测框和真实框的最小闭包区域的对角线距离。α
和υ
的公式如下: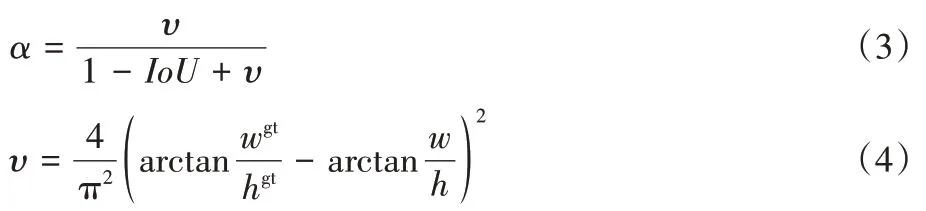
w
与w
分别为真实框和预测框的高;h
与h
分别为真实框和预测框的宽。loss
的计算公式为: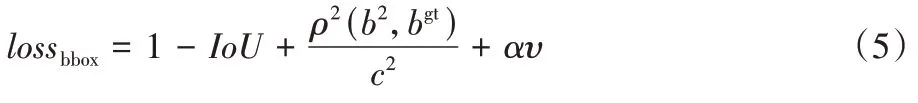
本文对分类损失的权重计算公式进行改进,同时在实验中测试了交叉熵损失和焦点损失两种分类损失计算方法。改进后的分类损失函数计算公式见2.2 节。
2.2 有效样本加权改进
在模型刚开始训练时,模型通过新数据可以很快学习特征;但是随着数据量的增加,新加入的数据和之前的数据存在一定的特征重叠,导致新学到的特征越来越少。假设把某一类别特征空间中所有可能数据的集合V
构成的样本体积设为N
,该类特征空间中每个样本都看作是特征空间V
的一个子集。由于特征重叠,所有子集的并集所构成的样本体积小于N
,把所有子集的并集构成的样本体积称为期望体积,也被称为有效样本量。文献[13]中有效样本量的定义如下:设n
为某类采集到样本的数量,N
为该类特征空间中所有可能样本数量,定义该类样本的有效样本量E
为:
S
=N
+N
+… +N
(i
∈C
,C
为样本类别数),即S
为所有类别特征空间中所有可能的样本数量N
的总和。由于无法知道每个类特征空间中所有可能的样本数量N
,因此在文献[13]中所有类的样本量都统一设置为超参数N
。文献[13]中在β
=0.9,0.99,0.999,0.999 9 时计算损失函数,然后找出β
的最优取值。2.2.1 公式计算改进方法1
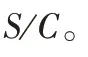
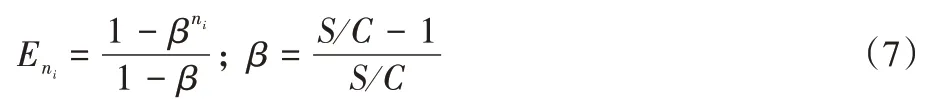
2.2.2 公式计算改进方法2
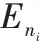

2.2.3 改进后的分类损失函数
设样本标签为y
∈{1,2,…,C
},模型预测类概率为p
=[p
,p
…,p
],其中p
∈[0,1],分类损失函数用L
(p
,y
)表示,则对L
(p
,y
)进行加权后的分类损失函数loss
表示为:
3 实验与结果分析
3.1 数据集
野生动物图像数据集是通过红外相机采集自四川卧龙自然保护区,然后通过人工整理筛选后得到的。数据集包括大熊猫、金丝猴、藏绵羊、藏牦牛等19 种野生动物,以及当地牧民在野外放养的黄牛、家猪和马3 种动物,共4 123 张图像。野生动物种类数量的分布见图1,其中藏绵羊最多(908 张),黑熊最少(46 张)。从图1 可以看出,采集得到的野生动物图像数据集是典型的长尾数据。野生动物图像数据集中的每张图像中还标注了野生动物的位置和类别信息。
在训练模型前将数据集按照9∶1 的比例随机划分成训练集和测试集,在训练集中随机取出10%作为验证集,则训练集、验证集和测试集的数量分别为3 339 张、371 张、412 张。在训练模型之前,对训练集进行mosaic 数据增强,mosaic 数据增强利用4 张图像进行拼接,这样可以丰富检测物体的背景,并且可以一次性处理4 张图像的数据。具体操作是每次读取4 张图像,分别对4 张图像进行翻转、缩放、色域变换等操作,并且按照4 个方向位置摆放,然后进行图像裁剪拼接组合。
3.2 实验环境和训练参数
实验软件环境:Ubuntu18.04.4 系统,Python3.6 编程语言,Pytorch1.0 框架;硬件环境:Intel Xeon Silver 4114 CPU @2.20 GHz×40,内存大小32 GB,GPU 为P5 000 和P2 000 两张卡,显存大小分别为8 GB 和4 GB。训练1 000 个Epoch,初始学习率设置为0.01,当进行到500 个Epoch 时,学习率变成0.001。最小批次量设置为32,衰减速率设置为5E-4。
3.3 模型训练
模型分两阶段进行训练,第一阶段训练时,损失函数采用无加权方式,第二阶段利用第一阶段训练得到的权重作为预训练权重,然后分别采用无加权和本文改进的2 种加权方式进行训练。对于分类损失函数分别用交叉熵损失(Cross-Entropy loss,CE loss)函数和焦点损失(Focal loss)函数进行训练。图4 是交叉熵损失函数的变化情况,可以看出,在第二阶段训练时,本文提出的方法一和方法二的损失函数比无加权方式都下降得更低。图5 是焦点损失函数的变化情况,其情况与图4 类似,其中方法二的焦点损失函数相对较小。
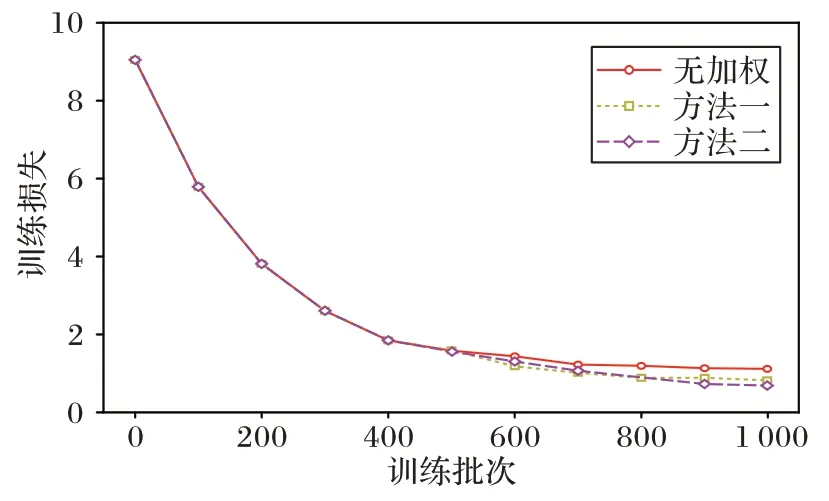
图4 交叉熵损失函数的变化图Fig.4 Change graph of cross-entropy loss function
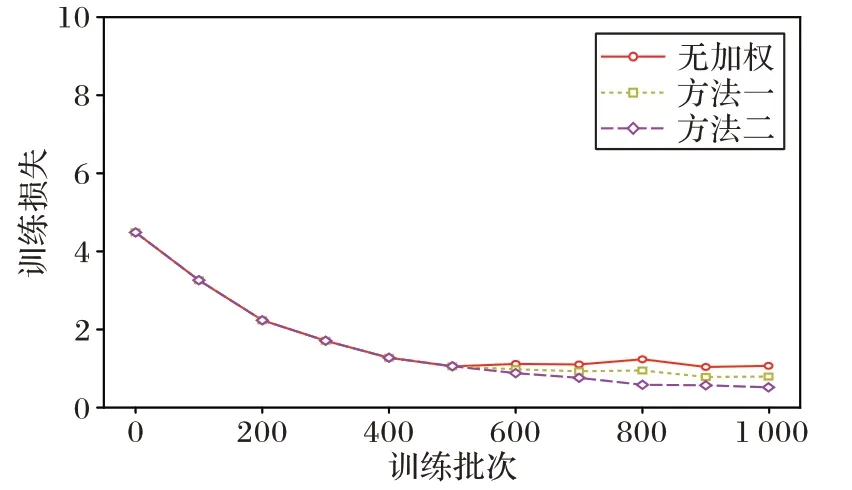
图5 焦点损失函数的变化图Fig.5 Change graph of focal loss function
3.4 结果及分析
针对测试集,对比了一阶段和二阶段学习下本文加权方法与无加权方法的平均精确率均值(mean Average Precision,mAP),实验结果如表1 所示。从表1 可以看出:1)在一阶段和二阶段学习,与无加权方式相比,无论采用交叉熵损失函数还是焦点损失函数,本文提出的两种加权方法的mAP 都更高,分别提高了3.30 个百分点和5.16 个百分点,说明两种加权方式能改善本文数据的长尾问题。2)两种加权方法无论采用交叉熵损失函数还是焦点损失函数,通过二阶段学习获得的mAP 都比一阶段学习更高,说明两阶段学习能提高mAP。3)在相同的损失函数和训练方法的情况下,加权方法二的mAP 都要高于加权方法一;并且,加权方法二在采用γ
=0.5 的焦点损失函数,进行两阶段学习时可以获得最好的mAP。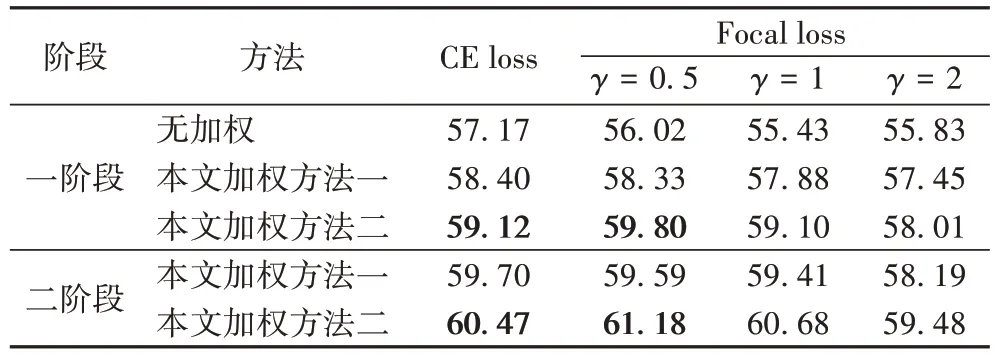
表1 本文方法与无加权方法的mAP对比 单位:%Tab 1 mAP comparison of proposed methods and no-weighting method unit:%
当采用γ
=0.5 的焦点损失函数时,计算无加权、加权方法一和加权方法二对各样本类别的平均精度(Average Precision,AP),结果如图6 所示。由图6 可以发现:1)相较于无加权方法,两种加权方法在整体上能保持头部类的AP,同时也提高了整体尾部类的AP;2)整体上,加权方法二比加权方法一更有效,特别对尾部类更有效,例如对红腹角雉、白腹锦鸡、家猪、马、大熊猫、斑羚等尾部类动物的AP 相对更高。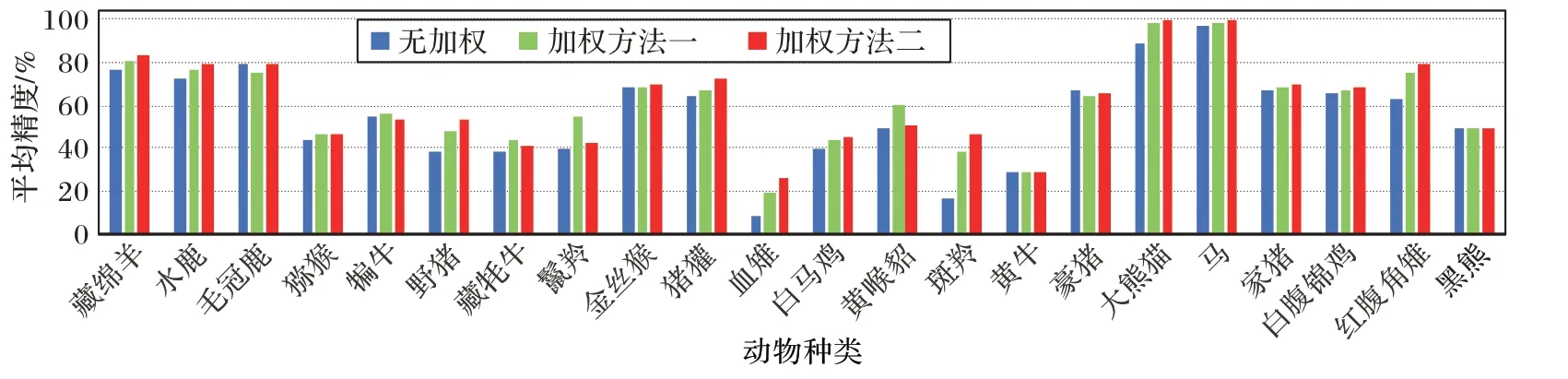
图6 不同动物种类的AP对比Fig.6 AP comparison of different species
为了进一步验证本文加权方法的性能,将本文加权方法二与无加权、逆序加权、逆序平方根加权、有效样本加权和LDAMLoss(Label-Distribution-Aware Margin Loss)方法在YOLOv4-Tiny 网络下进行对比实验,实验结果如表2所示。可以看出本文的加权方法二获得的mAP 为61.18%,优于其他4 种加权方法,与有效样本加权方法相比,提高了2.14 个百分点。实验中对于有效样本加权采用参数β
=0.99,以及焦点损失函数。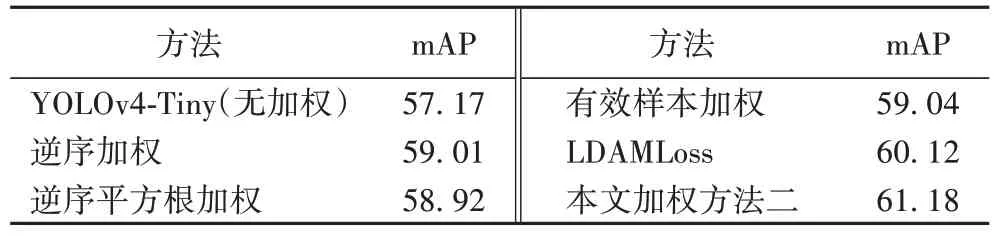
表2 无加权方法与不同加权方法的mAP对比 单位:%Tab 2 mAP comparison of no-weighting method and different weighting methods unit:%
图7 是不同加权方法获得的部分尾部类野生动物检测结果。图7 中每行是不同加权方法对同一张野生动物图像进行目标检测的结果图片。可以发现:

图7 不同加权方法的部分野生动物检测结果Fig.7 Some wildlife detection results of different weighting methods
1)本文提出的加权方法二能更准和更全地检测出野生动物目标。对于样例1 和样例3,逆序加权和逆序平方根加权都不能检测出图像中的野生动物;对于样例1,只有本文加权方法二和LADMLoss 正确检测出了野生动物;对样例2和样例4 只有本文加权方法二正确检测出了所有野生动物;对于样例3,只有有效样本加权、LADMLoss 和本文加权方法二正确检测出了野生动物;
2)本文加权方法二检测出的动物目标的置信度更高。对于样例5 和样例6,虽然所有加权方法都能检测出野生动物,但是本文提出的两种加权方法的置信度是最高的,其中加权方法二对样例5 和样例6 的置信度更是达到了1。
4 结语
为了解决长尾问题中数据不平衡问题,提出了一种两阶段学习与改进重加权结合的方法,并将该方法融入YOLOv4-Tiny 中用于检测野生动物目标。所提重加权方法基于有效样本加权进行改进,针对其需要多次寻找最优超参数的不足,提出自动计算超参数的公式。实验结果表明,提出的解决长尾问题的方法能有效解决野生动物数据集的长尾问题,提升目标检测的整体性能,特别时提升对样本量少的野生动物种类的目标检测精度。下一步的工作将进一步增加野生动物图像数据采集,研究进一步提升野生动物类别识别的技术。
