
基于自适应双阈值的地下目标自动检测算法
2022-05-07 07:08李海丰赵碧帆侯谨毅王怀超桂仲成
计算机应用 2022年4期
李海丰,赵碧帆,侯谨毅,王怀超,桂仲成
(中国民航大学计算机科学与技术学院,天津 300300)
0 引言
地下目标是指存在于地下的空洞、疏松体、富水体等病害,以及钢筋、管线等物体。这些地下目标的存在会导致路面塌陷、施工失败等事故,从而造成人力物力损失,甚至危及人们的生命安全。提前检测地下目标的存在以及识别目标的类别,可以有效减少以上事故的发生。
目前被广泛应用于检测地下目标的工具为探地雷达(Ground Penetrating Radar,GPR),它具有快速无损且高效的特点。但是由于地下目标的复杂性、多样性和空间分布的未知性,在实际业务应用中多采用人工交互异地分析GPR图像数据的方式进行地下目标检测,而这种方式无法满足工程应用中实时高效地探测和反馈多种地下目标的需求。
随着信息处理技术的发展,科研人员开发了一些利用GPR 图像数据自动探测地下目标的方法。这些方法可以分为两类:传统方法与深度学习方法。
传统方法的特点是需要经过大量的人工设计和数学运算。人们通常通过信号处理或图像处理的方式提取出地下目标的特征,如梯度特征、点特征、曲率特征、频域特征、双曲线拟合参数等,通过模板匹配或参数估计的方法,达到目标检测的目的。一些机器学习的算法,如支持向量机(Support Vector Machine,SVM)等,也被用于特征的分类。传统方法具有准确率低、计算复杂、只能针对性地检测某一类目标等缺点。
近年来,基于卷积神经网络的深度学习方法在目标检测领域取得了巨大的成就。一些成熟的目标检测模型,如Faster-RCNN(Faster-Region-based Convolutional Neural Networks)、YOLO(You Only Look Once)、Mask-RCNN(Mask-Region-based Convolutional Neural Networks)等,也被应用于GPR 图像中的目标检测。这些深度学习方法的检测效果比传统方法的准确率更高,但是具有样本需求量较大、处理时间长、检测结果难以解释等缺点。
另外还存在一些传统方法与深度学习相结合的地下目标检测算法。比如:Al-Nuaimy 等首先使用神经网络提取出目标特征区域,然后提取边缘信息,再通过霍夫变换检测地下目标的双曲线结构特征;Dou 等和Zhou 等分别在此基础上添加了列连接聚类和OSCA(Open-Scan Clustering Algorithm)来提高检测的准确效率;Shaw 等先使用边缘检测简化数据集,再使用MLP(Multi-Layer Perceptron)网络识别简化后的双曲线形状,由于这种方法的神经网络输入为整个图像中的所有曲线,且不考虑目标邻近区域信息,使得该方法受环境噪声影响较大,识别率较低。
本文提出了一种结合了传统方法和深度学习方法的地下目标自动检测算法。针对现有算法实时性较差、样本要求高、检测结果解释性差等特点,提出了一种基于图像直方图分析的自适应双阈值目标分割算法,同时使用SVM 分类器与LeNet 神经网络对分割结果进行分类筛选,最后得到当前图像区域内的所有地下目标的位置及类别。与以往算法相比,本文算法具有实时性强、样本需求量小、多类别目标并行检测等特点。
1 本文算法
1.1 算法设计
地下目标检测包括两个方面:1)雷达图像中的地下目标区域分割;2)地下目标区域分割结果的分类识别。从分类的角度看,前者是一个二分类问题,而后者为一个多分类问题。基于以上思路,本文提出的地下目标自动检测算法包含两个部分:目标分割和目标分类。
图1 展示了本文算法的整体流程。算法输入为经过预处理的探地雷达图片。算法首先通过目标分割算法找出图片中的显著和非显著目标区域,然后通过一个综合分类器识别目标类别,作为算法输出。
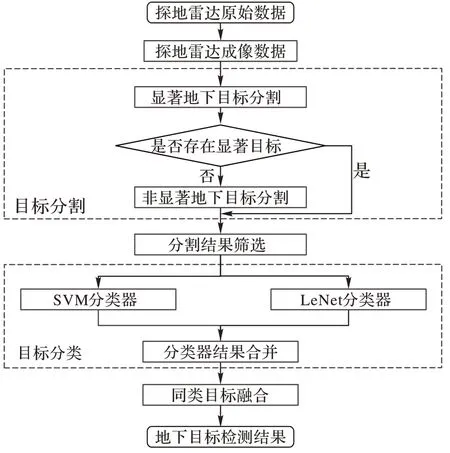
图1 本文算法处理流程Fig.1 Proposed algorithm processing flow
为了能够同时检测雷达图片中的显著和非显著目标,在算法的目标分割部分设计了两步分割算法:第一步分割图像中的显著目标,通过对分割结果进行分析,判断图片中是否存在显著目标;第二步当不存在显著目标时,分割图片中的非显著目标。两步分割算法都采用了自适应双阈值分割算法。区别在于第二步分割算法加入了直方图压缩操作。
为了能够同时获得不同类别目标的分类识别结果,在算法的目标分类部分结合了两种分类器:LeNet 分类器和SVM分类器,前者用于识别地下目标的纹理特征,而后者用于识别地下目标的几何结构特征。两种分类器的目标识别结果通过设计数学形态学方法进行连接合并,最终得到地下目标的整体识别结果作为输出。
1.2 输入雷达图片特征
探地雷达通过发射和接收电磁波以探测地面目标,当地下存在异物时,由于介电常数的改变,探地雷达接收到的雷达回波就会产生较大的波动。通过分析回波信号中的波动情况,可以识别各类地下目标。常见的地下目标包括各类地下异物,如塌陷、空洞、积水等病害,以及钢筋、管线、地灯等物体。在探地雷达在探测地下目标时,会受到测量噪声、地下小目标、未知异物等造成的干扰,形成噪声域。
对于探地雷达获得的雷达回波数据,通常需要经过数据预处理操作,然后再经过插值、线性拉伸等操作转换为能够可视化的雷达图像数据。通用的数据预处理操作包括:地平线调节、滤波器去噪、细节增益放大等。探地雷达的数据预处理操作可以自动筛选有用的数据,并且通过不同程度地增强数据的波动幅值,使得地下目标在视觉上更加清晰和突出。
本文算法以探地雷达预处理之后的雷达图片数据作为输入。图2 给出了一个探地雷达图片数据的示例。在探地雷达图片数据上,地下目标表现为一片突出的紧密相邻的黑白像素区域,并且呈现出一定的几何及纹理特征,而背景区域则为一片灰色区域。如图2(b)中上部的连续双曲线状凸起结构对应于一组平行的地下钢筋目标。
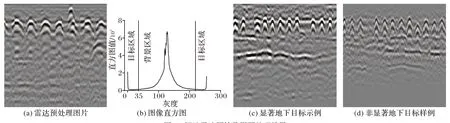
图2 探地雷达原始数据预处理效果Fig.2 Preprocessing effect of ground penetrating radar raw data
图2 中同时给出了探地雷达图片的直方图分布(见图2(b)),其中包含三个明显的峰值分布。直方图两侧的峰值分别对应于地下目标的黑白像素连通区域,而直方图中部的峰值对应目标背景区域。另外,探地雷达图片的直方图整体呈现出近似对称的结构。直方图的对称中心点在灰度级128 左右浮动,象征“正波”的白色区域和象征“负波”的黑色区域同样表现出近似对称。
本文算法的目标是能够同时检测出显著和非显著的地下目标。图2(c)和图2(d)给出了显著和非显著目标的示例。两者的区别在于,显著性目标与背景区域具有较大的对比度,而非显著目标由于介电常数不同、增益调节不明显、病害严重程度较低等原因,与背景区域的对比度较小。图2(d)所示为增益调节相对不足条件下的Bscan 图像。
1.3 双阈值地下目标分割算法
根据地下目标雷达图片直方图的特性,可以通过设置双阈值自动分割地下目标,其中低阈值用于分割目标的暗区部分,而高阈值用于分割目标的亮区部分,综合两部分分割结果,可以得到地下目标的整体分割结果。
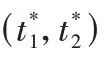
1.3.1 显著性目标分割
显著性地下目标的双阈值分割算法步骤如下:
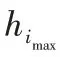
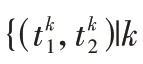

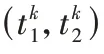
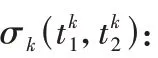
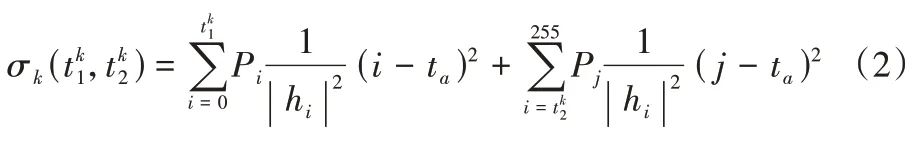
P
代表像素点强度为h
的概率,t
代表背景区域的平均亮度。P
和t
的计算公式如下:
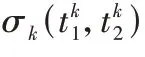
图3 给出了一个案例说明以上算法对显著和非显著性目标的检测效果。
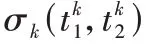
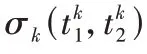
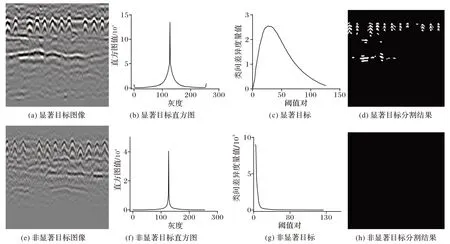
图3 不同显著程度下的Bscan图像和其直方图统计后分割结果Fig.3 Bscan images with different saliency and segmentation results after histogram statistics
1.3.2 非显著性目标分割
当判断雷达图片上不含显著性目标时,针对非显著性目标应用单独的检测算法。图4 展示了一个包含非显著性目标的雷达图片的直方图及其局部放大图。可见,非显著性目标的直方图两侧同样存在一些目标分布造成的局部极值,但是这些局部极值的强度非常低。
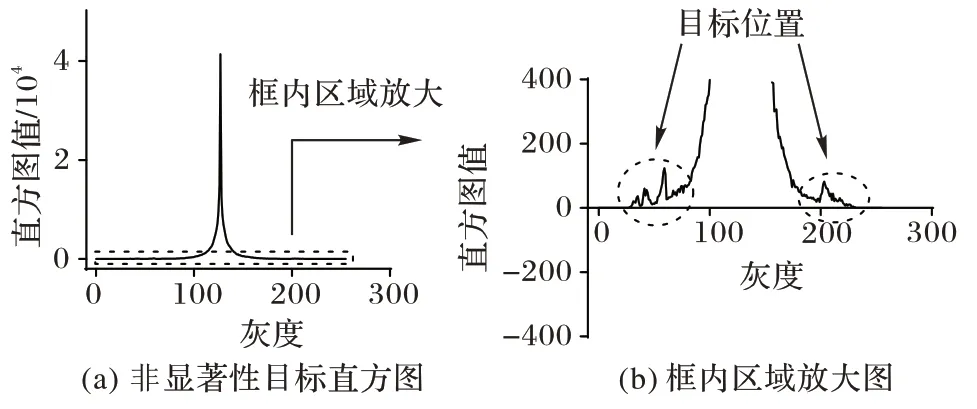
图4 非显著性目标直方图及其局部放大图Fig.4 Histogram of nonsignificant objects and its local enlargement
对于此类非显著目标,本文同样采用以上的双阈值分割算法进行分割,但是在计算阈值之前,需要对直方图进行压缩,针对非显著性目标检测的具体步骤为:
1)引入一个直方图压缩参数K
。根据参数K
确定直方图的一对压缩空间:[0,n
) 和(m
,255],其中n
=K
× 128,m
=255 -n
。在算法中,压缩参数K
的取值设为0.6,确定K
的步骤详见实验部分。2)在直方图[n
,m
]中寻找直方图的对称中心轴i
=i
。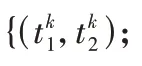
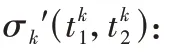

非显著性目标分割算法与显著性目标分割算法的步骤几乎相同,主要区别在于加入了直方图的压缩步骤,并且缩小了阈值的搜索区间。
图5 展示了加入直方图压缩之后的非显著性目标检测效果。经过压缩后的直方图在两侧出现了两个明显的峰值,根据压缩直方图获得的双阈值能够较好地分割非显著性目标区域,见图5(c)。
1.3.3 分割结果筛选。
由于信号干扰会在图像中显示出一定的噪声区域,这些区域的特点是面积小、存在孤立;尤其在显著性较差的图片中,噪声区域对实验的干扰更加突出。因此,可以通过区域面积的大小和独立性对分割结果进行筛选。区域面积小于30 或者周围3×3 个像素区域内没有其他目标存在时,认为是噪声,从分割结果中剔除。图5(d)中展示了针对图5(c)分割结果的筛选效果。
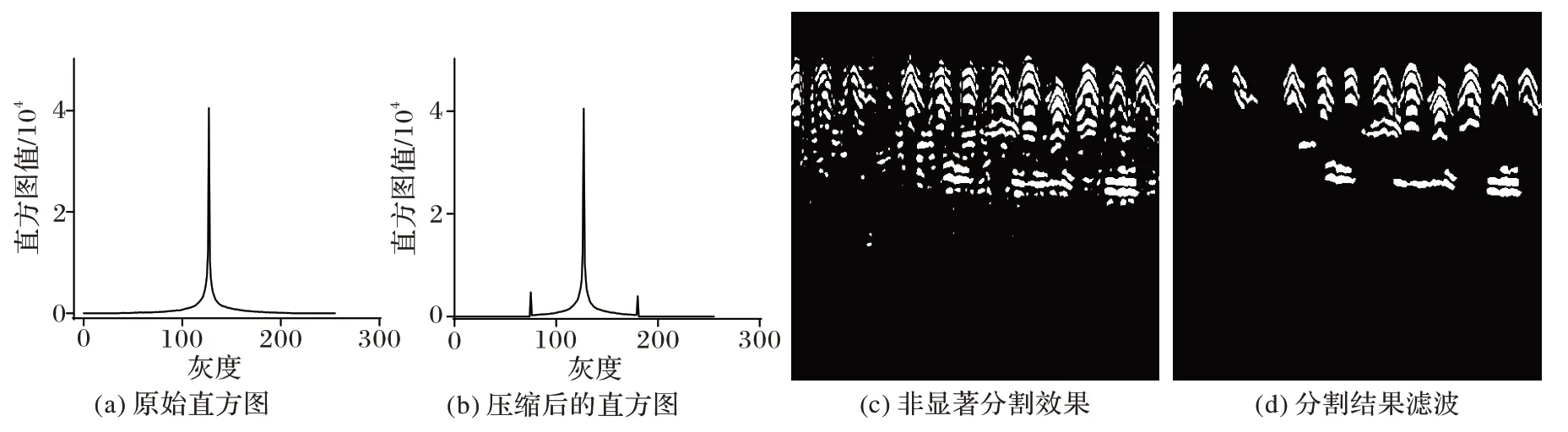
图5 非显著目标检测效果示例Fig.5 Example of non-salient target detection effect
1.4 目标分类
对于1.3 节的分割结果,进一步设计分类器对其进行分类识别。由于每一个地下目标在图像信息中表示为多次明暗交替的区域,1.3 节的目标分割结果往往不能对应地下目标的整体区域,因此在进行分类识别之前,需要对目标分割结果先进行形态外扩,引入部分周围环境信息。具体的外扩方式采用向上下两个方向共扩增两个信号变换周期的范围,之后以外扩的区域作为判别区域,对分割结果进行目标分类识别。
本文主要设计分类器识别三类常见的目标,分别是脱空、钢筋、平行钢筋。图6 给出了以上三类目标的典型结构示意图。

图6 地下目标的外观特征Fig.6 Appearance characteristics of underground targets
从图6 可见,不同类型的目标具有自己独特的特征:
1)脱空:脱空在探地雷达图片上表现为一个具有多个不规则起伏的长条状目标。由于脱空常分布于较深的地层中,所以脱空通常位于图片下方。
2)钢筋:钢筋表现为一排具有明显双曲线结构的区域。通常多个钢筋在同一高度集体出现,且位于较浅的地层中,钢筋常位于图片中上方。
3)平行钢筋:平行钢筋是指探地雷达采集到的钢筋侧剖面图。在雷达图片上,平行钢筋表现为一个块状区域,且具有无明显起伏的规则外形。
针对以上目标的典型特征,可以利用目标的形状描述特征和纹理特征对目标进行分类识别。本文使用了两种分类器(SVM和LeNet神经网络)用于识别以上三类典型的地下目标。
在分类器的训练过程中,需要采集噪声数据作为负样本。噪声在图像中随机分布,面积较小,纹理混乱,呈现为显著性不强的不规则区域。另外,在分类器的训练过程中,还将其他类别的地下目标样本也作为负样本。
算法使用SVM 模型识别具有典型形状特征的目标。SVM 是一种非常经典的监督学习方法,其旨在找到一个最优超平面,可以把所有训练样本分离为最优的两类。本文算法中,SVM 使用高斯径向基函数核进行数据映射,输入特征为目标的几何中心点坐标(c
,c
)与长宽信息(w
,h
)的组合,通过将多个SVM 分类器组合,实现地下目标的多分类识别。算法采用LeNet 模型识别具有典型纹理特征的目标。LeNet 分类器是一种经典的卷积神经网络,它的提出是为了解决手写体的文字识别问题,手写文字与地下目标的图像特征有极高的相似度,且具有参数少、层数小、训练简便等特征,在小样本数据集中仍旧可用,所以本文选择LeNet 分类器对地下目标的纹理信息进行分类。
算法最后将SVM 和LeNet 分类器相结合,得到最终的识别结果。SVM 分类器和LeNet 分类器分别从不同的角度对每个分割区域进行分类,输出每个分割结果的类别概率,通过把两个分类器分别得到的概率值相加,即可得到两个分类器融合后的总体概率。
图7 中给出了一个算法分类器识别的输出结果实例。从图7(b)可以看出,由于地下目标的明暗区域之间存在一些高频信号区域,导致最终的目标分类识别结果在纵向断裂,为了能够获得完整的目标识别结果,需要对对类型的目标进行整合。

图7 同类别融合处理步骤Fig.7 Processing steps of same class fusion
算法中采用数字形态学膨胀算法对同类型目标识别结果进行融合。膨胀核H
选取9×9的自定义核矩阵,其具体形式如下: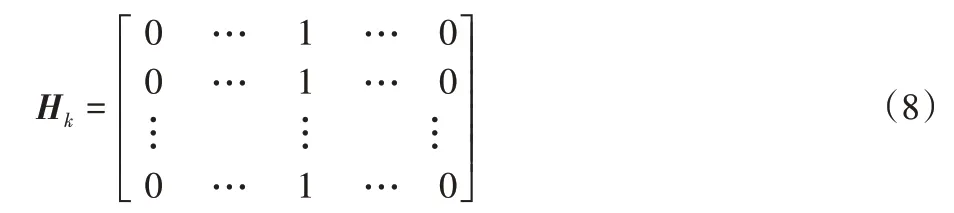
该膨胀核只对目标区域进行纵向膨胀。
经过数学形态学融合之后,同类型的目标识别结果合并为一个完整目标,同时输出每个识别结果的外包矩形框,见图7(c)和图7(d)。图7(c)为分类结果为脱空的目标区域的融合,图7(d)为分类结果为平行钢筋的目标区域的融合。图中使用白色虚线表示了识别后的外包矩形框,白色实线表示了人工标记的目标区域外接框。由图7 可见,检测结果与人工标记的正确结果非常接近。
2 实验与结果分析
首先测试了算法参数对本文算法检测效果的影响,然后从定性分析和定量分析两个方面在算法的不同阶段对本文提出的算法与传统的算法进行了对比评估。在目标分割阶段,与传统的一些自适应阈值如大津法、双峰法、迭代法等进行了对比;在目标识别阶段,与一些基于深度神经网络的自动分割网络模型算法进行了对比。实验程序的运行环境是1.60 GHz 的i5-10210U CPU 处理器,16 GB 内存,操作系统为64 位Windows10,实验过程采用Python 编程语言实现。
2.1 测试数据
为了检测算法的通用性和普适性,实验中所用的数据集来自苏南硕放国际机场、宝鸡太白山机场和厦门高崎机场等机场采集到的探地雷达数据。这些数据经过统一的预处理后,被分割成448×448 像素的雷达图片,雷达图片被打乱后,随机选取三个不同大小的数据集,分别为50、100 和200 张图片,标记为训练集A、B、C,另随机抽取36 张图片作为测试集。数据集中包含的地下目标包括脱空、钢筋、平行钢筋、地灯、沉降、断裂、钢筋网等。实验针对数量较多的脱空、钢筋、平行钢筋三类目标进行了标注,以上的三类目标均采用外接矩形框进行标注,作为训练数据集中的正样本,其余数量较少的目标与随机提取的噪声合并为训练数据集中的负样本。数据集的具体信息见表1。
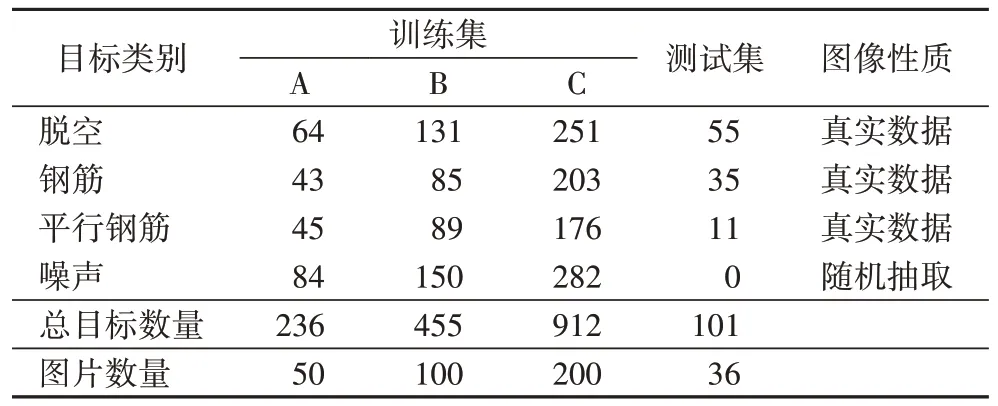
表1 实验数据集Tab 1 Experimental dataset
2.2 参数敏感性测试
算法中对算法效果影响最为明显的参数为直方图压缩率K
,当K
取值过小时,表示对原始的雷达图片几乎没有压缩,会将雷达图片中的非显著目标与背景图片混成一片,造成地面目标的漏检;当K
取值过大时,表示直方图的压缩率过高,会造成目标分割结果中存在大量噪声。为了确定合适的参数K
的取值,实验测试了不同的参数K
取值对目标检测结果的影响,具体如图8 所示。图8(a)所示的探地雷达图片中包含了不同显著性的地下钢筋目标;在实验中将参数K
的取值分别设为0、0.6 和0.8 时,对应的地下目标检测结果见图8(b)~(d)。从图8 可见,在不进行直方图压缩的环境下(K
=0),算法只能分割出少量显著的钢筋目标,当加入直方图压缩后(K
>0),本文算法不仅能够将图片内显著的钢筋目标分割出来,同时也能够成功分割出图片下部非显著性的脱空目标。但是当K
的取值过大时,同时算法会同时分割出较多的噪声,见图8(d)。最终通过实验发现,当参数K
取值为0.6 的时候,既能够有效分割出显著目标和非显著性目标,同时还能够避免在分割结果中产生过多的噪声点。因此,在后期的实验中,K
值设定为0.6。
图8 K取值对地下目标分割效果的影响Fig.8 Effect of K on underground target segmentation
2.3 不同算法检测效果对比
本文针对GPR 图片中的地下目标检测问题设计了一种自适应双阈值分割算法。在实验中,本文算法与其他的自适应阈值分割算法进行了对比评估。对比算法包括:Ostu 双阈值算法、自适应阈值分割算法、最大熵值分割算法、迭代阈值分割算法、Ostu 阈值分割算法、双峰分割法。以上各类分割算法的具体描述见文献[21]。
由于GPR 图片中目标同时包含明区和暗区,中间的灰度区间为背景区域,所以传统的单阈值算法无法实现三个区域的分割。因此,在使用单阈值算法分割地下目标之前,需要对雷达图片进行变换,将亮区的像素值转换为关于中间值128 对称的暗区值,再把图片从[0,128]的值域线性拉伸到[0,255],以用于对比算法中的单阈值分割,转换公式如下:

s
为图片中每一个像素点的像素值,s
′为该像素点经过转换之后的像素值。各种不同分割算法的分割效果对比如图9 所示。图9(a)为一张包含一个显著目标的448 像素×448 像素的Bscan 图像。图9(b)~(h)分别为以上各种不同分割算法的检测效果。
从图9 可见,本文算法获得了针对地下目标的最佳的分割效果,分割结果中包含地下目标的完整结构,同时几乎没有受到任何噪声的影响,非常有利于后续的目标分类。相比之下,Ostu 双阈值算法和自适应阈值算法几乎完全不能用来分割地下目标(图9(b)和图9(c)),Ostu 双阈值算法的核心在于分割结果的类间方差最大,而自适应阈值分割算法的核心在于邻域内相似点扩充;两者的算法思想均完全不适用于探地雷达图像的目标分割,所以分割效果杂乱,分割结果中包含了大量噪声。
最大熵阈值分割和迭代阈值分割得到了地下目标的过分割结果(图9(d)和图9(e))。最大熵阈值分割算法的目的是计算最佳阈值从而使背景与前景的熵之和最大;迭代阈值分割算法的目的是使分割出的前景和背景的平均值相等。这类算法的灰度区域都会大量被两端平均,所以算法不仅分割出了目标区域,而且还分割出了过多的噪声,模糊了明暗区域的界限,丢失了完整的空间信息和纹理信息。
Ostu 阈值分割算法(图9(f))可以分割出目标位置,同时保留了空间信息和纹理信息,但是该算法同时得到了大量噪声区域,分割结果较差。其原因与最大熵分割法相似,雷达图像中两个峰的大小不一,会促使阈值向大峰偏移。
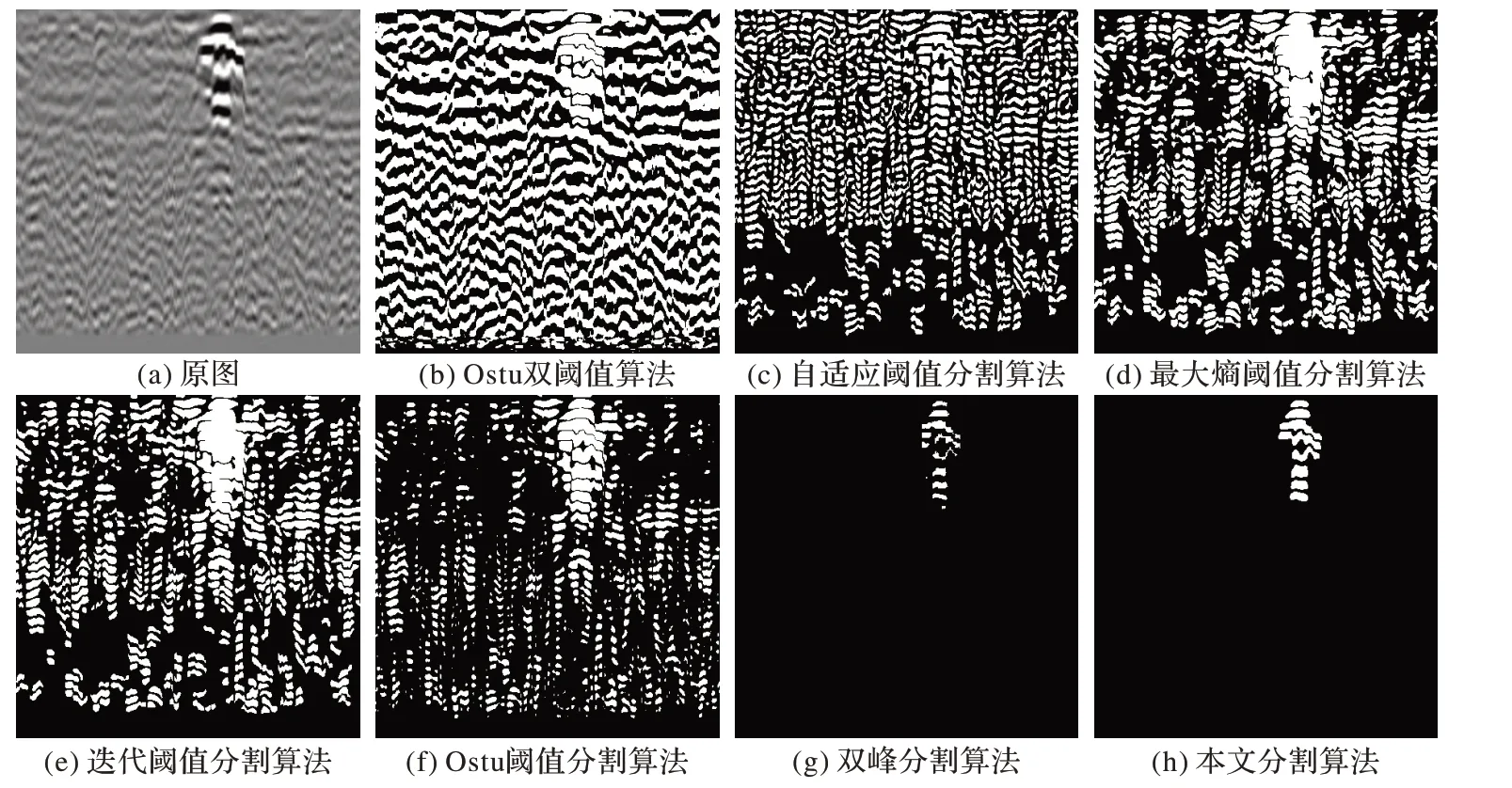
图9 不同分割算法的效果对比Fig.9 Effect comparison of different segmentation algorithms
双峰分割算法(图9(g))被设计用于分割直方图表现为两个峰值的图像。由于本样例中直方图也表现为双峰结构,所以双峰分割算法表现良好。但由于该算法只是简单取直方图最小值位置,算法会过早停止迭代,导致分割结果结构不完整。
本文算法获得了比Ostu 阈值分割算法更佳的表现,其原因在于,本文算法是针对探地雷达图像而专门设计的阈值分割算法,其差异度函数考虑到了前景区域和背景区域的强度分布,弱化了背景区域的存在系数,将算法的分割权重集中在明暗两区与背景区域的综合差异上,而不是计算类间或类内的所有差异,从而既避免了噪声的干扰,又保证了分割结果的完整性。
2.4 地下目标分类识别结果对比
地下目标的分类识别结果采用表1 中给出的样本数据进行对比测试。实验中测试了三种分类方案的多目标分类结果:1)基于纹理特征的LeNet 神经网络;2)基于形态特征的SVM 分类器;3)LeNet 和SVM 相结合。
在实验过程中采用准确率(Precision)、召回率(Recall)和F1 分值(F1-Score)三个指标对以上三类识别方案进行定量评估。当算法目标预测区域的外接框(即检测框)与标注区域的圈注框(标记框)之间的交集与并集的比例(Intersection over Union,IoU)大于0.5 时,代表算法正确检测出了一个目标;Precision 表示被检测框中被正确检测出的数量占总检测框的比例。Recall 表示在标记中被检测出的数量占总标记框的比例。
F1-Score 为Precision 和Recall 的综合评价指标,其计算公式为:
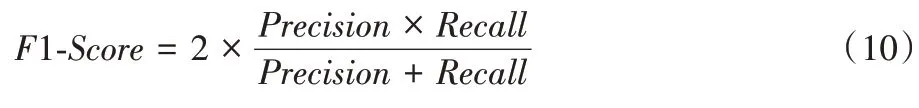
较高的F1-Score 表示在Precision 和Recall 上的评价结果都很高,即算法不仅检测出了标记目标,且没有误检。在本文实验中以F1-Score 为目标分类算法的检测指标。
表2 给出了在训练集A 上的三种检测方案量化对比评估结果。从表2 中可以看出:
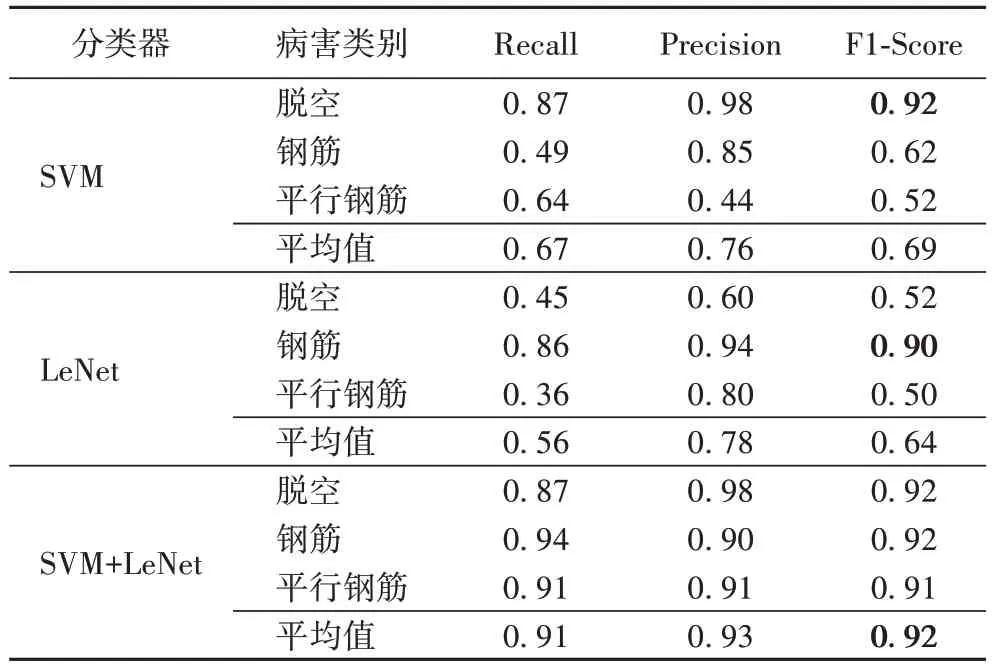
表2 每类目标最终检测结果评分值Tab 2 Final test result score of each type of targets
1)SVM 和LeNet 的结合识别方案获得了最好的识别效果,在所有类别上的平均F1-Score 最高。
2)结合表2 和1.4 节,当仅使用SVM 分类器时,由于不考虑纹理特征,钢筋与平行钢筋的位置和大小相似,所以较难识别,钢筋和平行钢筋的准确率较低;当仅使用LeNet 分类器时,由于不考虑位置和大小特征,某些较小脱空与平行钢筋的纹理相似,所以较难识别,导致脱空和平行钢筋的准确率较低。
3)两者结合的方案能够在所有类别上获得更为均衡的识别效果。这是由于不同的目标需要通过不同的特征进行检测,而结合两个分类器,可以综合两个分类器的优点,使得在各个类别上都达到较好的识别效果。
本文进一步分别使用A、B、C 三个不同大小的数据集对分类器进行训练,用于检测训练样本规模对算法的影响,训练结果如表3 所示。由表3 可知:
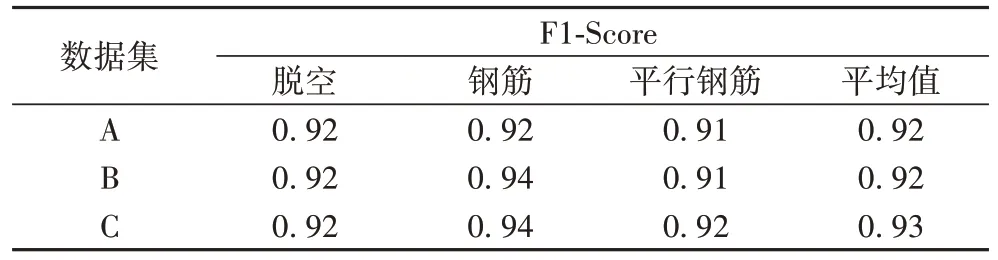
表3 不同训练集检测结果F1-Score值Tab 3 F1-Score values of different training set test results
1)三个训练集最终在测试集上得到的平均F1-Score 的值均在90%以上,本文算法对地下目标的检测效果突出。
2)增加训练样本数量后,某些类别目标的准确率有略微的增加,这是因为扩大样本数量可以使模型学习到更多的特征信息。
3)增加训练样本数量后,总体的准确率不会有大幅度的提升,主要因为双阈值分割后目标的特征明显,所以使用简单的分类器相结合,在较小的数据集上就能发挥良好的作用。
通过对误检样本进行综合分析,可以对算法的稳定性、局限性和可适用性进行评估。图10 为本文算法测试实验出现的典型错分样例。

图10 典型的漏检与误检样例Fig.10 Examples of missed detection and false detection
由图10 可知:
1)当目标的显著性过低时,如图10(a),会被算法漏分割或被检验为噪声。当目标与噪声特征相似时,如图10(b),会被算法检验为噪声。以上两种情况都会造成算法漏检,降低算法的Recall 值。
2)与目标存在相似结构特征的噪声会导致算法的误检。如图10(c)所示,噪声区域的部分纹理特征与钢筋相类似,导致该区域被误检为钢筋;在图10(d)中,一个较小的脱空由于和平行钢筋类似,被误检为平行钢筋。以上这些情况会被算法误检,降低算法的Precision。
通过以上分析可知,Bscan 图像中的噪声结构存在很大的不确定性,这些不确定性造成的算法局限性是不可避免的。为了减少噪声给检测算法带来的影响,需要进一步研究噪声的结构规律,设计针对性算法。对于无法仅依靠大小、位置、纹理特征进行检测的目标,需要设计利用更高维度特征(如目标上下文特征、环境特征等)的算法进行检测。
在定量评估实验中,本文提出的地下目标自动分类识别算法还与目前主流的基于深度学习的目标识别算法进行了对比,包括Faster-RCNN、RetinaNet、SSD(Single Shot multibox Detector)等目标检测模型,由于深度学习的模型算法不适用于小样本,所以以上模型的准确率极低,甚至根本无法实现检测。
3 结语
针对当前探地雷达地下目标自动检测算法数据量需求大、硬件环境要求高、实时性低、准确率低等缺点,本文提出了一种基于直方图的自适应双阈值分割算法,并且对目标分割结果从纹理和形状特征两个方面,利用组合分类器进行分类识别。实验结果表明:1)本文算法可以快速识别探地雷达图片中的显著和非显著目标;2)本文算法能够获得比传统阈值分割算法更好的分割效果;3)本文算法在不同量级的数据集上对各类目标均能够获得高识别率,平均达90%以上。本文算法在小样本数据集中获得了较好的识别效果,为探地雷达目标检测问题提供了全新的解决方案。但是对于更大的数据集或者较为复杂环境下的目标检测任务,本文算法的最终准确率距离传统深度学习检测算法还有一定的差距,需要进一步研究。
