
级联跨域特征融合的虚拟试衣
2022-05-07 07:08胡新荣张君宇刘军平何儒汉
计算机应用 2022年4期
胡新荣,张君宇,彭 涛*,刘军平,何儒汉,何 凯
(1.湖北省服装信息化工程技术研究中心(武汉纺织大学),武汉 430200;2.武汉纺织大学计算机与人工智能学院,武汉 430200)
0 引言
近年来,网购服装逐渐成为人们购买服装的主要途径之一,网购服装的一大难点是缺少试穿的条件,消费者难以想象服装穿着在自己身上的样子。对于消费者,虚拟试衣技术可以大幅提升购物体验;对于商家而言,该技术也能帮助他们节约成本。传统的虚拟试衣方法使用计算机图形学建立三维模型并渲染输出图像,由于图形学方法需要对几何变换和物理约束实现精确控制,这需要大量的人力工作和昂贵的设备来搜集必要的信息,以建立3D 模型和大规模计算。
近年一些基于图像的虚拟试衣方法,如VITON(VIrtual Try-On Network)、CP-VTON(Characteristic-Preserving VITON)等,不需要用到昂贵的3D 计算,而是将虚拟试衣问题定义为一种条件图像生成问题。给定目标人物的照片I
,以及一张目标服装的照片c
,网络的目标是合成一张新的图片,由I
中的目标人物,穿着c
中的目标服装。生成图像的质量面临以下挑战:1)目标人物的体型和姿势需保持不变;2)服装的印花图案,需要在新的体型和姿势下,保持自然的、逼真的图案;3)替换上的服装和目标人体的其他区域,在连接处需要保持平滑;4)生成图像的身体各部分不能产生不必要的遮挡。生成对抗网络(Generative Adversarial Network,GAN)在图像合成、图像编辑等任务中展现了良好的效果。条件对抗生成网络(Conditional Generative Adversarial Net,CGAN),通过对模型提供先验信息(如标签、文本等),使得生成结果具有想要的属性,在图到图的转换任务上表现良好。但是大多GAN 不具有明确地适应几何形变的能力,VITON、CP-VTON 等工作中提到:在处理图像间大规模形变时,添加对抗损失的提升很小;条件图像与目标图像并未很好地对齐时,GAN 倾向于生成模糊的图像。
文献[3-4]采用两阶段的策略:首先将目标服装进行扭曲,使其对齐目标人体;然后将扭曲后的服装与人体合成在一起。VITON 采用由粗到细的框架,使用薄板样条插值(Thin Plate Spline,TPS)扭曲服装。CP-VTON 引入直接学习TPS 参数的策略预测扭曲服装,并在试衣合成阶段采用U-Net生成器,预测服装区域以外的人物图像和合成蒙版,来合成最终的试衣图像。合成蒙版的策略是保留服装特征的关键,CP-VTON 因此获得了保留服装细节的能力;但由于合成蒙版难以拟合目标人体的服装区域,又带来了严重的遮挡问题。
为解决CP-VTON 这类采用合成蒙版策略的工作中容易产生严重遮挡的问题,本文提出一种新的关注服装形状的虚拟试衣模型。包括两个模块:1)服装扭曲模块,将目标服装对准给定人的姿势;2)试衣合成模块,将变形服装与目标人体合成。与CP-VTON 算法相比,本文引入了一种含注意力机制的解码器,能更好地预测合成蒙版,从而改善结果中的遮挡问题。
1 数据预处理
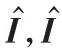
1.1 着装人体信息解析
为了尽可能保留人体的特征,并排除I
中原本服装的影响,VITON 中提出表示人体信息的方法。如图1 所示,解析出的人体信息P
包含三个部分,一共22 通道,分别为:
图1 着装人体信息解析P实现人体和服装解耦Fig.1 Person representation information P to decouple human body and clothing
1)脸和头发:3 通道RGB 图像,包含脸部和头发部分。采用最先进的人体解析方法计算人体分割图,并提取在试衣过程中不会改变,能体现身份信息的脸和头发部分。
2)体型:1 通道,采用人体解析获得覆盖人体I
的二值化掩码,人体区域用1 表示,其他部分用0 表示。为排除不同服装对掩码形状的影响,先将掩码进行下采样到较低的分辨率,再通过上采样恢复原先的分辨率。这样获得模糊的掩码能粗略地覆盖人体。由于减少不同服装的影响,能更好地表示基本的体型信息。3)姿势热图:18 通道的姿势图,每个通道以二值化表示,各包含有一个人体关键点信息,以关键点的坐标为中心,在11×11 的矩形范围内填1,其他部分填0。18 个人体关键点由最先进的姿态提取器获得。
1.2 服装扭曲模块
本文实验采用两阶段的策略,采用CP-VTON预测几何匹配参数的方法,设计服装扭曲模块。通过这个模块,在人体信息解析P
的指导下,生成扭曲服装c
。将c
输入本文改进的试衣模块,生成最终的虚拟试衣结果。本节将简要描述服装扭曲模块,服装扭曲模块如图2 所示。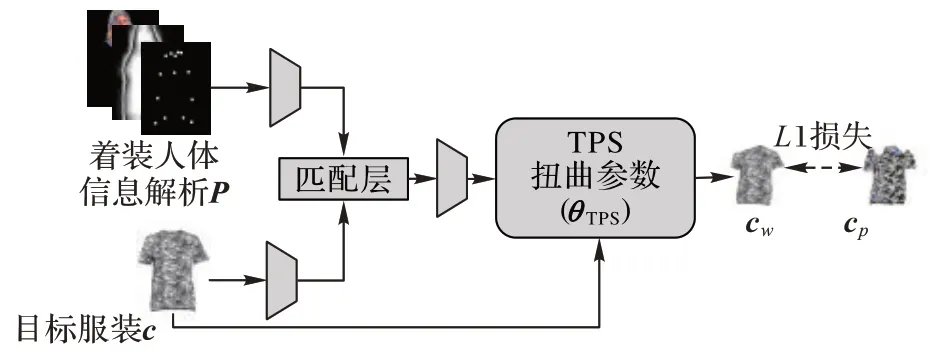
图2 服装扭曲模块Fig.2 Clothing warping module
分别将参考服装c
,目标人体的人体信息解析P
输入两个由步长为2 的卷积层组成的编码器来提取特征。再通过特征匹配将两组特征融合,送入回归网络,预测50 个TPS 转换参数θ
,并用θ
计算出扭曲后拟合人体的服装c
。c
的标签是从I
中通过人体解析获得的解析服装部分c
。在c
和c
之间计算L
1 损失:
c
。2 本文模型
服装掩码M′
是结合服装与人体的关键,其生成效果的质量将很大程度上影响最终试衣结果的视觉效果。传统的方法中,使用普通的U-Net 作为试衣合成模块,生成的M′
不能很好地拟合对应的服装区域,试衣结果在手臂、头发处产生遮挡,在不同服装区域的连接处产生了不自然的接缝。为了解决这类框架中容易产生的遮挡问题,受近年来带有注意力机制的U-Net启发,本文设计了一种改进的试衣合成模块。图3 为本文试衣合成模块的框架。给定一张着装人体图像I
,将I
中的人体信息与服装信息解耦,采用VITON 中构建人体信息解析的方法,构建出人体信息解析P
。P
中包含I
中人体的姿态、体型、脸和头发等信息,但不包含I
中的服装信息。通过服装扭曲模块,获得大致与目标人体对齐的扭曲服装c
。将c
与P
作为本文模型的输入,输入试衣合成模块,生成对应目标人体的服装掩码M′
和中间人物图像I
。使用M′
将I
和c
合成最终的试衣结果: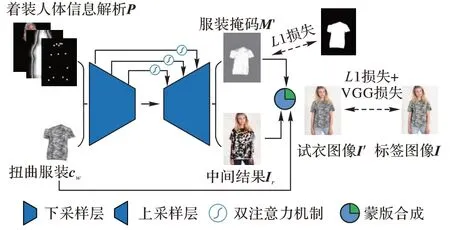
图3 改进试衣合成模块的框架Fig.3 Framework of improved try-on synthesis module
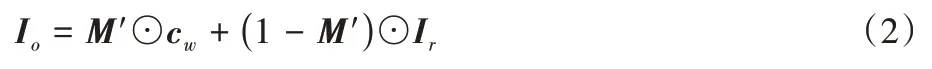
其中:运算⊙表示哈达玛积。
2.1 改进的试衣合成模块
试衣合成模块主要结构是一个U 型网络,如图4 所示。编码器主要由卷积核大小为3×3 的标准卷积函数,以及2×2最大池化的下采样层组成。编码阶段共经历四次下采样,将编码器的中间特征图分为5 个尺度,每个尺度下最后一个卷积层的卷积核个数分别为64、128、256、512、1 024。解码器主要由卷积核大小为3×3 的标准卷积函数,以及最近邻插值法的上采样层组成。通过四次上采样,将解码器输出的特征图分为4 个尺度,每个尺度下最后一个卷积层的卷积核个数分别为512、256、128、64。在编码器的最后部分,通过一个包含四个卷积核,每个卷积核大小为1×1 的卷积层输出最终结果。
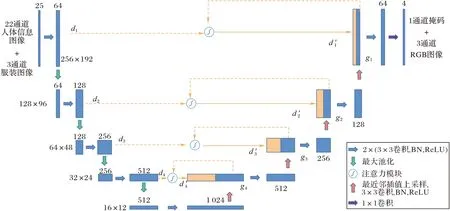
图4 改进的试衣合成模块主要结构Fig.4 Main structure of improved try-on synthesis module
每个尺度下编码器输出的特征图,通过跳跃连接和低分辨率的解码器块融合,捕捉更多的语义和空间信息。在融合时,本文提出级联的双注意力解码器,将在2.2 节描述。
2.2 解码器的级联注意力机制
如图5 所示,通过跳跃连接传来的特征图d
,首先通过一个通道注意力路径,再通过一个空间注意力路径,且计算注意力时,都要结合解码器上采样得到的特征图g
的信息。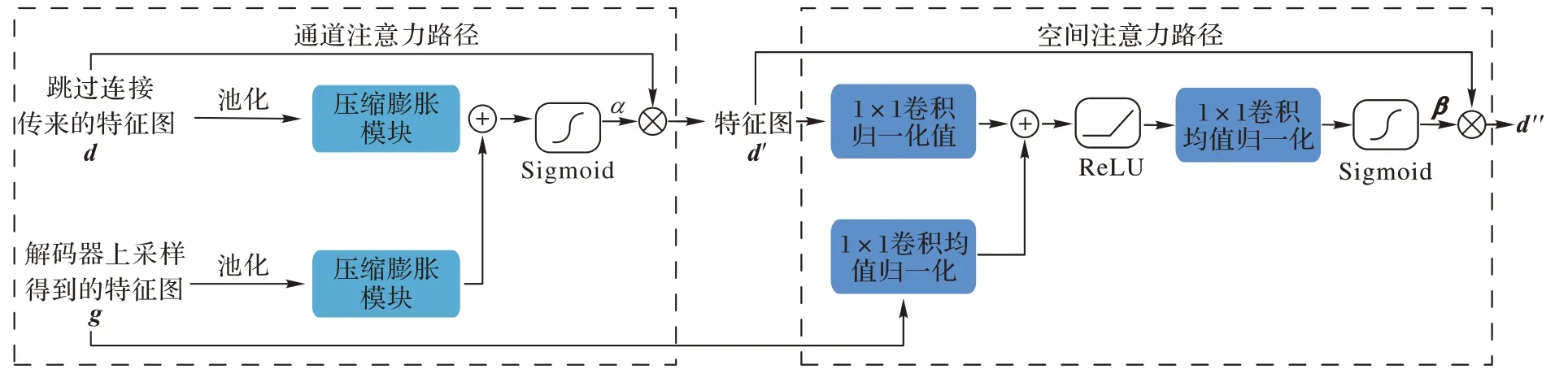
图5 级联的双注意力机制Fig.5 Cascaded dual attention mechanism
g
,与通道注意力路径的输出结果d′
,分别通过1×1 卷积输出单通道的特征图,两个特征图相加之后送入ReLU 函数,再通过1×1 卷积和Sigmoid 函数,获得通道为1、分辨率和d′
相同的参数矩阵β
,与d′
相乘,作为注意力模块的输出结果d″
。每一层解码器的最终输出结果F
为: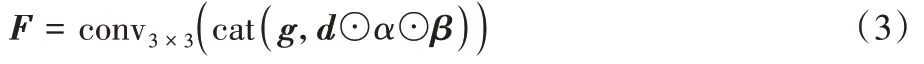
x
)为卷积核大小为3×3 的卷积函数;cat(x
)为通道连接操作。2.3 试衣合成模块的损失函数
通过人体解析,从参考图像I
中得到的服装区域的掩码M
,作为服装掩码M′
的ground truth,训练时通过最小化L
1损失,减小M′
和M
的差异:
I
与I
之间的差异,计算Perceptual损失和L
1 损失。Perceptual 损失定义如下: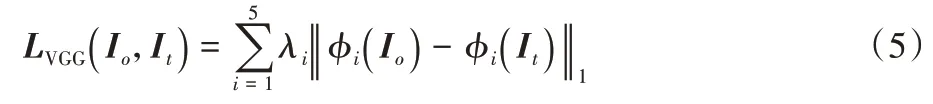
φ
(I
)表示图像I
在视觉感知网络φ
的第i
层的特征图;φ
是在ImageNet上预训练的VGG19网络;i
≥1 表 示conv1_2、conv2_2、conv3_2、conv4_2、conv5_2。试衣合成模块的总体损失函数为: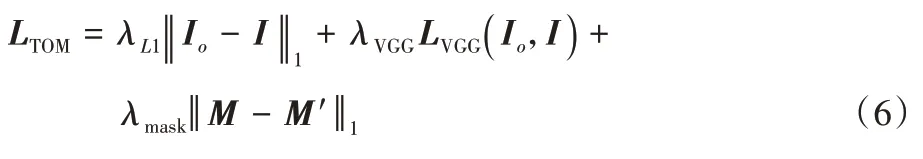
3 实验与结果分析
3.1 数据集
在Wang 等使用的数据集上进行实验。包含16 253 张正视图女人图像和正面服装图像对,图像大小为256×192。分为14 221 组训练集对和2 032 组测试集对。将测试集打乱排列为未配对的图像对用于进一步评估。
3.2 定量评价方案
在相同实验设置的条件下,比较本文方法与CPVTON、ACGPN的试衣结果。其中,CP-VTON 需重新训练,ACGPN(Adaptive Content Generating and Preserving Network)则采用在Github 网站上提供的训练好的模型(https://github.com/switchablenorms/DeepFashion_Try_On)。
在打乱排列的测试集上,对试衣结果计算FID(Fréchet Inception Distance)评分。由于打乱排列的测试集上获得的试衣结果没有对应的ground truth,对一一配对的测试集的试衣结果计算结构相似性(Structure SIMilarly,SSIM)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)评分和VGG 误差(VGG Error)评分。通过记录网络的参数量,来衡量网络的空间复杂度。
2)SSIM:从亮度,结构和对比度三个方面,计算合成图像和ground truth 之间的相似性,值域从0 到1。SSIM 值越高越好。
3)PSNR:越大越好。
4)VGG Error:衡量两者之间的感知损失,越小越好。
3.3 实施细节
在所有实验中,训练阶段设置λ
=λ
=λ
=1。训练服装扭曲模块和试衣合成模块各200 000 步,batch size 设置为4,使用Adam 优化器,β
=0.5,β
=0.999。学习率在前100 000 次迭代中设置为0.000 1,在剩下的100 000 次迭代中线性衰减到0。输入和输出图像的分辨率都是256×192。服装扭曲模块中,人体信息图像和服装图像采用相同结构的特征提取网络,包含4 个2 步长卷积层,2 个1 步长的卷积层,卷积核的数量分别为64、128、256、512、512。回归网络包含2 个2 步长的卷积层,2 个步长为1 的卷积层和一个全连接输出层。卷积核的数量分别为512、256、128、64。全连接层阶层预测50 个TPS 参数。
3.4 定量结果
表1 是本文模型与CP-VTON、ACGPN的比较结果。其中:↑表示越高越好,↓表示越低越好。
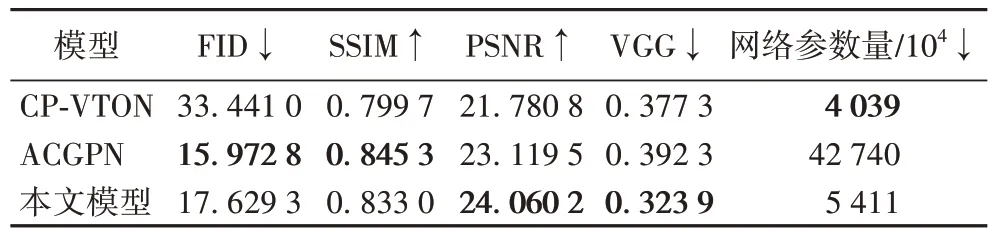
表1 三种模型的定量结果对比Tab 1 Comparison of quantitative results among three models
与CP-VTON 相比,本文模型的PSNR 提高了10.47%,FID 减小了47.28%,SSIM 提高了4.16%。与ACGPN 相比,本文模型在FID 评分上较差,一定程度上是由于ACGPN 能更好地保留裤子、手部等非换装区域特征;但本文模型的网络参数量相较于ACGPN,减少约87.34%,同时在PSNR 和VGG Error 上取得最好的结果,也能说明本文模型的先进性。
3.5 定性结果
图6 展示了本文模型与CP-VTON 服装掩码M′
生成效果的对比结果。当M′
能对应目标服装在目标人体的服装区域时,认为M′
达到了较好的生成效果。中间结果I
的主要作用在于生成脸部、裤子、手臂等非换装区域。由图6 可以看出,本文模型取得了更好的效果,并且在最终的试衣结果中,改善了遮挡现象。
图6 本文模型与CP-VTON的服装掩码M′生成效果对比Fig.6 Comparison of generation effect of clothing mask M′between proposed model with CP-VTON
图7 展示了本文模型与CP-VTON、ACGPN 之间的视觉效果对比结果。与CP-VTON 模型相比,本文模型都取得了更清晰的结果;与ACGPN 相比,本文模型和ACGPN 都能生成清晰的图像结果:ACGPN 的结果优势在于能更好地保留裤子的特征(图7 第2、3 行),并在手部的细节保留上有优势(图7 第1、2 行),本文模型的优势在于能更好地保留服装的细节(图7 第1 行领口部位),不会在手臂出现缺少像素的情况(图7 第2、3 行左臂)。

图7 本文模型与CP-VTON、ACGPN的视觉效果对比结果Fig.7 Visual effects of proposed model compared with CP-VTON and ACGPN
CP-VTON 的缺陷在于,试衣合成模块获得的组成掩码M′
不能很好地对齐身体的上衣部分。而M′
生成的质量不佳,将导致服装与手臂和头发等部位产生大量的遮挡。生成M′
的同时,试衣合成模块同时生成中间人物图像I
,I
会承担一定的全局优化作用,由于遮挡问题的存在,I
不得不承担更多的调节遮挡功能,与此同时,I
的主要功能、恢复图像清晰度以及调节服装花纹的能力将遭到减弱。实验结果表明,相较于CP-VTON,本文方法能获得更少遮挡的结果,生成更清晰的图像,更好地保留服装细节。
4 结语
本文方法在U-Net 解码器上添加级联的注意力机制,能够使模型更好地注意到目标人体的服装区域,生成了更符合人体特征的服装组成掩码,并且进一步提高了图像的生成质量。但本文所提试衣方法,在面对复杂的服装印花时,依然有较严重的失真现象。在很大程度上,是由于服装扭曲阶段获得的结果不能很好地拟合人体。在未来的工作中,将在服装扭曲阶段进行改进,获得更好的扭曲服装结果后,能够更好地发挥本文中提出的试衣合成模块的性能。
