
基于改进卷积神经网络与支持向量机结合的面部表情识别算法
2022-05-07 07:08乔桂芳侯守明刘彦彦
计算机应用 2022年4期
乔桂芳,侯守明*,刘彦彦
(1.河南理工大学计算机科学与技术学院,河南焦作 454003;2.杭州师范大学阿里巴巴商学院,杭州 311121)
0 引言
面部表情作为人脸识别和情感信息传递的重要门户,在人机交互领域正经历着空前未有的发展。面部表情识别主要利用计算机提取给定的静态人脸图像或动态人脸序列的表情特征,使其以人的思维对检测到的表情进行理解和分类,满足人们在不同应用场景下的需求,进而建立良好的人机智能交互环境。面部表情识别技术在疲劳驾驶、互联网教学、刑事案件侦测、医学诊断、安防监控、心理咨询等领域有着非常广泛的应用。
面部表情识别的五个过程包括表情图像获取、输入数据预处理、提取层次特征、表情分类和所属类别,其核心是提取层次特征,高效快速地抽取表情图像中的有利信息是提升表情识别准确率的重要前提。传统的表情识别方法主要通过人工提取特征,如Gabor 小波变换、方向梯度直方图(Histograms of Oriented Gradients,HOG)、主成分分析(Principal Components Analysis,PCA)等,再结合支持向量机(Support Vector Machine,SVM)进行分类。传统方法设计特征需要借助一定的专家知识,人为干扰因素较大,且易丢失原有样本的特征信息,进而影响表情识别准确率。然而卷积神经网络(Convolutional Neural Network,CNN)可将原始数据直接传送至模型,依据端到端的图形拓扑结构自动提取输入数据的抽象特征,有效缩短人工预处理的过程。1989年,LeCun 等发明CNN,并于1998 年采用LeNet-5 模型成功提高手写字符识别率。Krizhevsky 等在2012 年创造了深层CNN AlexNet,首次实现Top 5 最低误差率,是CNN 崛起的转折点。Simonyan 等于2014 年提出VGGNet,通过叠加小尺寸卷积核不断加深网络层次,取得不错的分类精度。为了更有效地改善表情识别的准确性,众多研究者开始改进CNN与其他特征方法结合使用,Li 等提出改进CNN 与注意力机制相融合的方法,将全局图像特征与多个无遮挡的面部感兴趣区域特征集合起来,从而提高无遮挡区域特征的表现能力;Xie 等采用空间注意力+多路连接的方法对CNN 进行针对性的改进,先微调预训练的模型得到特征图,加入空间注意力机制,突显表情区域,再对具有明显区分性的特征向量进行全连接和分类;Xia 等设计多个损失函数加权组合,通过网格搜索方法提升含遮挡人脸表情的识别效果;王忠民等借助改进的CNN 模型作为特征提取器,抽取更深层次的复杂特征,融合SVM 进行表情识别,最终识别精度高于传统方法。上述研究表明,CNN 的确能够进一步提升表情识别准确率,但随着各种网络模型及其变体的提出,导致网络结构越来越复杂,参数量增多且识别效果不够理想。
为此,本文提出一种基于改进卷积神经网络与非线性支持向量机相结合的面部表情识别算法。首先,在感受野大小不变的前提下,多个结构简单的小尺寸卷积核以串并联融合的方式代替大尺寸卷积核,在增强模型特征学习能力的同时拥有更少的网络参数,且获得的特征分类性更强;其次,采用全局平均池化(Global Average Pooling,GAP)层取代全连接层,简化卷积结构,同时省略大量训练调优的参数;最后,送入SVM 分类器进行表情分类,以提升模型的泛化能力。
1 相关技术
1.1 CNN原理
典型的CNN由卷积层、池化层、全连接层和Softmax 分类函数组成,图1 为其基本结构。CNN 具有强大的表征学习能力,其隐含层内引入的参数共享和层间连接稀疏性机制,能极大地减少模型参数量,具备辨识面部表情微小变化的潜力。
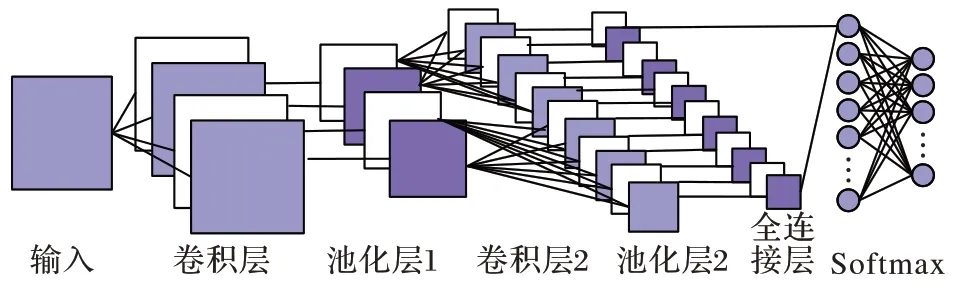
图1 CNN基本结构Fig.1 Basic structure of CNN
图1 中的卷积层用于提取图像细节和抽象信息,实现参数共享;池化层能缩减特征图尺寸,起到降维效果;全连接层执行最终分类任务。经大量研究发现,传统CNN 算法用于表情识别需关注以下三个问题:
1)面部表情识别的关键在于快速觉察人脸五官微妙变化的特征,传统CNN 直接应用于面部表情识别领域,识别效果不佳;
2)传统CNN 模型中2~3 层的全连接层产生的参数量过大,占据CNN 总参数的80%以上,参数过多导致计算量增加,还易引起过拟合,不利于面部表情的快速分类;
3)传统CNN 模型中的Softmax 分类函数只是使输出结果符合概率分布,并未对识别性能产生帮助,在小样本和多分类任务中,性能不优越,难以进一步提升最终识别精度。
1.2 全局平均池化
为实现面部表情的快速分类,Lin 等提出设计一个维度自适应全局平均池化(GAP)层取代传统CNN 中的全连接层来融合学习到的深度特征。假设最后一个卷积层的输出为三维特征图w
×h
×d
,将平均池化的窗口大小动态设置成特征图大小w
×h
,经GAP 变换后,每一层w
×h
会被平均化成一个值进行展平和全连接操作,即输出值为1×1×d
,特征图结构可表示为N
×1×1×d
,N
表示特征图的数量,最后将得到的二维数据N
×d
送入SVM 分类器。1.3 支持向量机
支持向量机(SVM)是由Vapnik 等最早提出的经典二分类学习方法,它在小样本和多分类任务中,比传统的Softmax 分类函数性能优越。为进一步提升表情分类效果,在算法设计中使用非线性SVM 代替Softmax 分类器工作,SVM 采用“一对多”策略来处理表情分类任务,假设样本共有m
类,先构造m
-1 个SVM 子分类器,转换为处理二分类问题,第i
个分类器将类别为T
的样本标记为+1,剩余类别全标记为-1,SVM 多分类算法过程如图2 所示。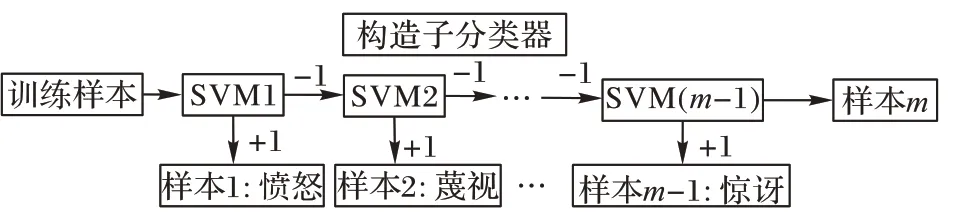
图2 SVM多分类算法过程Fig.2 SVM multi-classification algorithm process
2 改进CNN+SVM识别算法
图3 为所提优化算法的基本识别流程。
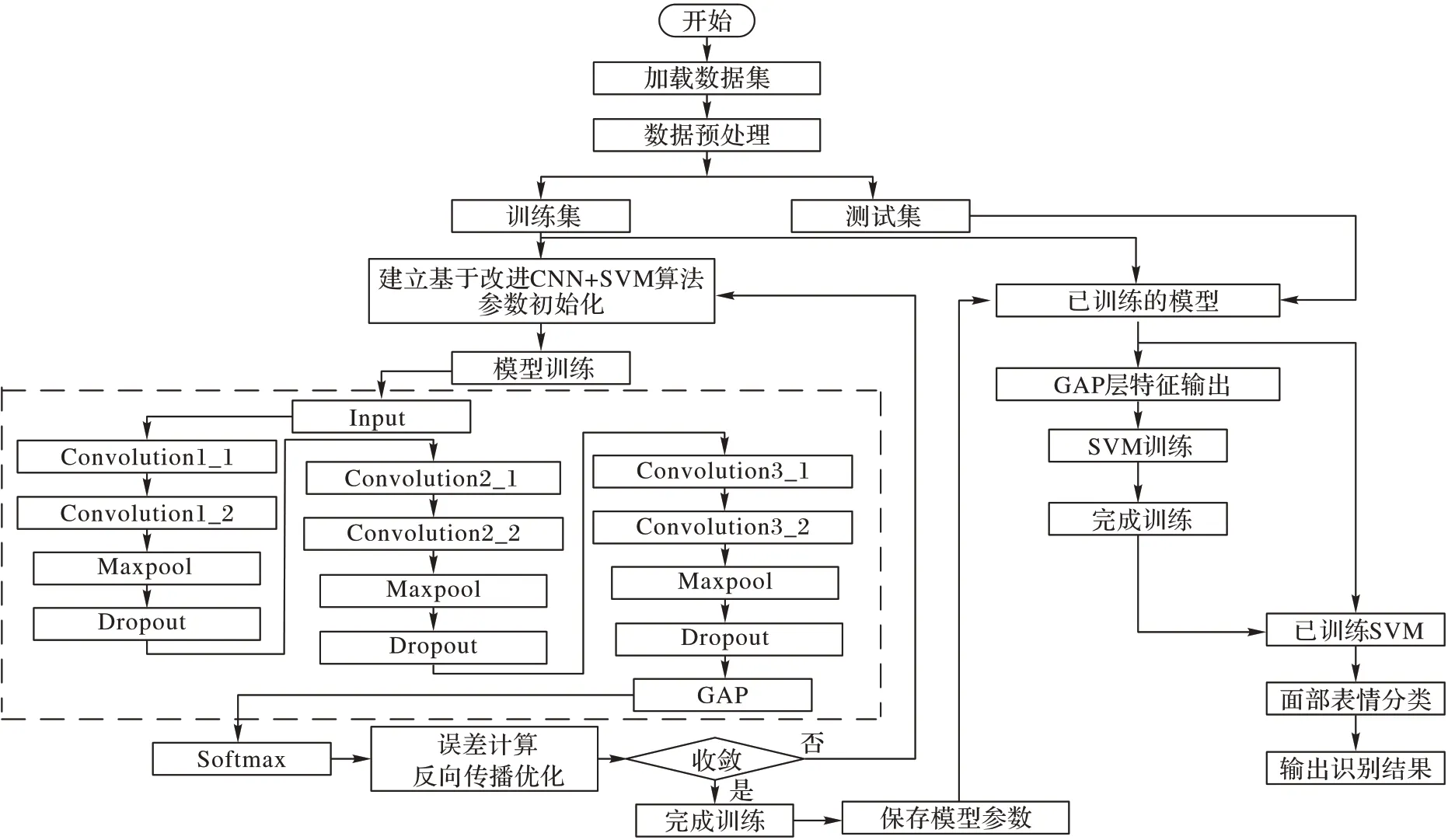
图3 基于改进CNN+SVM的面部表情识别算法流程Fig.3 Flow of facial expression recognition algorithm based on improved CNN+SVM
本文算法的步骤如下:
1)输入层对原始表情数据进行预处理;
2)特征提取层对预处理后的表情灰度图进行深度提取:
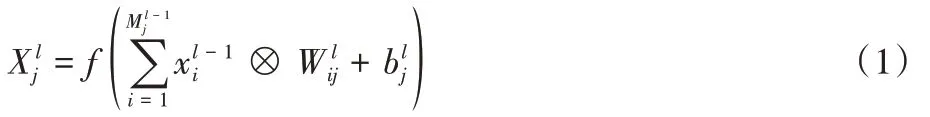
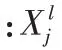
3)计算修正线性单元(Rectified Linear Unit,ReLU)激活函数值:
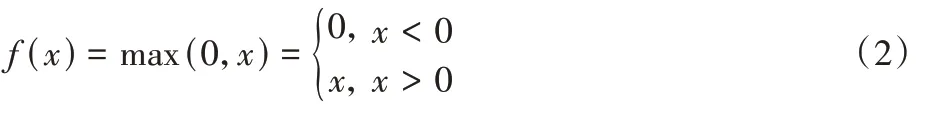
4)用最大值池化方式进行降维减参:

MP
表示最大池化后的输出特征图;X
(K
)表示输出特征图的第K
个像素值。5)对最后卷积层输出的特征图进行GAP 变换:

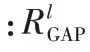
W
和偏置b
:
η
表示学习率;E
表示误差函数。7)将GAP 层的稀疏特征数据送入SVM 分类器,计算高维特征空间最大分离超平面:
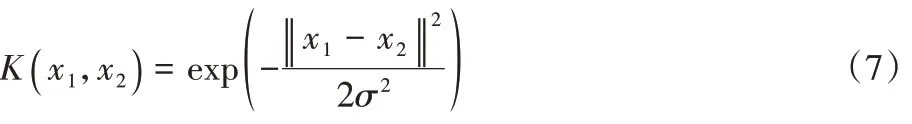
x
表示任意一个样本点;x
表示中心坐标值;σ
表示函数的宽度参数,σ
<0。图4 为算法总体改进策略。根据深度模型VGG16连续卷积的思想设计网络模型,本文构建的基于改进CNN+SVM 算法的面部表情识别模型如图5 所示。图5 中标注了每层的命名、卷积核大小和通道数,“@”符号后面的数字为卷积层通道数。此模型由一个输入层、三个卷积模块层、一个GAP 层和一个SVM 分类器构成。三个卷积模块层结构相同,由含两个3×3 卷积核的卷积层串联,随后紧跟池化层及随机丢弃层(Dropout)组成,另外,模型中加入ReLU 激活函数防止梯度弥散。改进模型先通过卷积模块中的卷积层提取表情图像特征,之后将提取到的深层次特征通过下采样层进行降维处理,并融入Dropout 机制预防过拟合,GAP 层将最后得到的特征图送入SVM 分类器,执行分类任务。
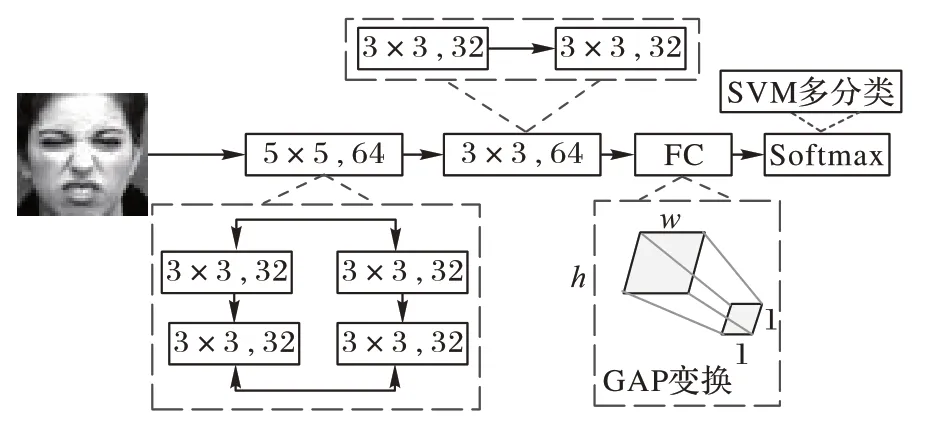
图4 本文算法总体改进策略Fig.4 Overall improvement strategy of proposed algorithm
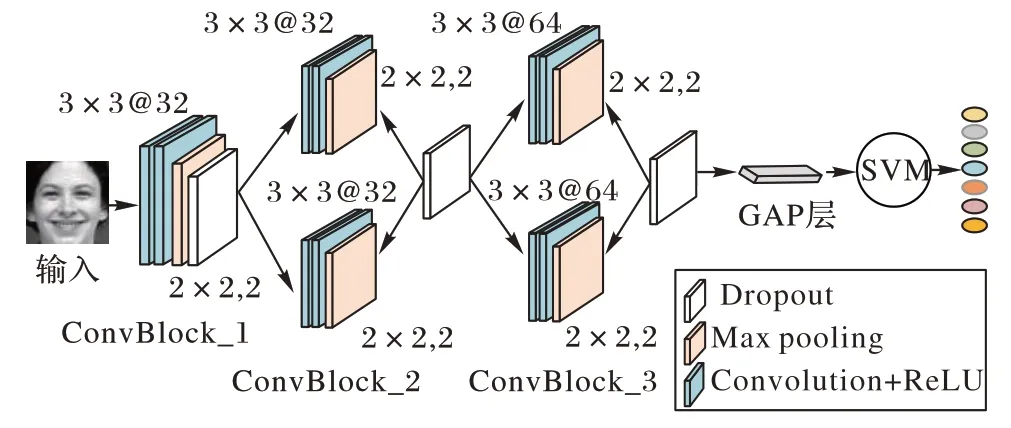
图5 基于改进CNN+SVM算法的面部表情识别模型结构Fig.5 Structure of facial expression recognition model based on improved CNN+SVM algorithm
图5 中的卷积模块1(ConvBlock_1)、卷积模块2(ConvBlock_2)、卷积模块3(ConvBlock_3)是改进CNN+SVM模型中的卷积提取层。其中:ConvBlock_1 用两个通道数为32 的3×3 卷积核提取面部表情特征,选用小尺寸卷积核代替较大卷积核,能有效减少网络模型参数量,同时提升网络性能;ConvBlock_2 中用两个通道数为32 的3×3 卷积核并联取代一个通道数为64 的3×3 卷积核,通过拓展网络宽度保持表情图像的性质,确保参数量一致的前提下,前者能提取的特征分类性更强、非线性激活更多;同样原理,将ConvBlock_3中通道数为128 的较大卷积核进行串并联融合操作。
输入48×48 像素的表情灰度图,经过ConvBlock_1 操作和Same 填充后,进行了平卷积,输出与输入大小一致,经最大值下采样,得到的特征图大小减半,为24×24 像素。通过ConvBlock_2 和ConvBlock_3 中“卷积+最大池化”计算后,得到6×6×128 的特征图,经GAP 变换,得到一个1×1×128 的张量,送入SVM 进行分类。模型中各网络层的参数量计算方法如式(8):
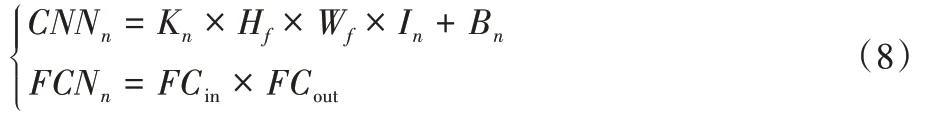
CNN
表示卷积层的参数量;FCN
表示全连接层的参数量;K
表示卷积核个数;H
和W
分别表示卷积核的高和宽;I
表示卷积层输入数据的通道数;B
表示偏置量;FC
表示全连接层输入数据的维度;FC
表示输出神经元的节点数。基于改进CNN+SVM 算法的面部表情识别模型的各网络层参数情况如表1 所示,该模型的总参数量远小于传统CNN 模型。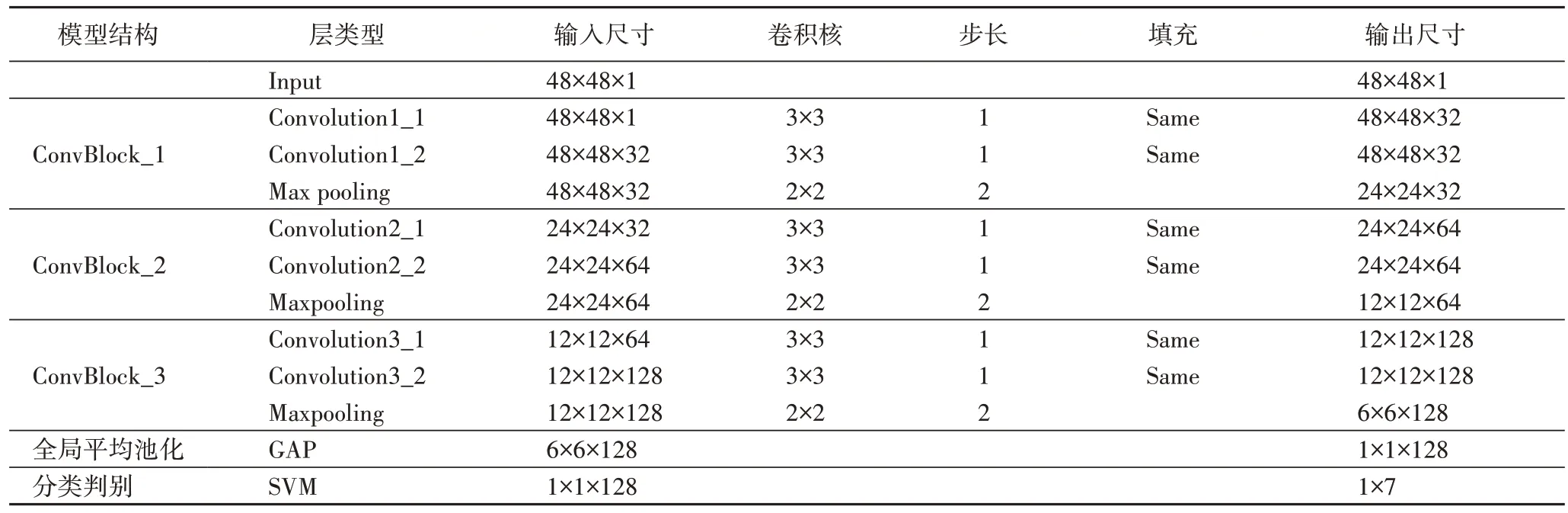
表1 基于改进CNN+SVM算法的面部表情识别模型的各层参数描述Tab 1 Parameter description of each layer of facial expression recognition model based on improved CNN+SVM algorithm
3 实验与结果分析
3.1 数据集
本文模型训练采用Fer2013和CK+两个数据集,按8∶2 的比例随机划分为训练集和测试集。表2~3 给出了各数据集的标签对照及训练集和测试集中各表情类别数量分布情况。实验中先将全部图像预处理并归一化成48×48 大小的灰度图,如图6 所示。
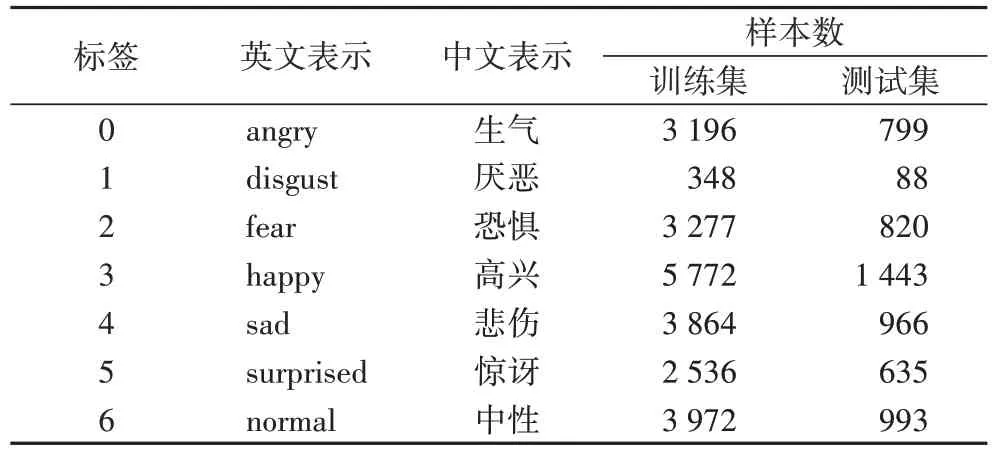
表2 Fer2013数据集中英标签对照及各类别数Tab 2 Chinese and English labels and numbers of different categories in Fer2013 dataset
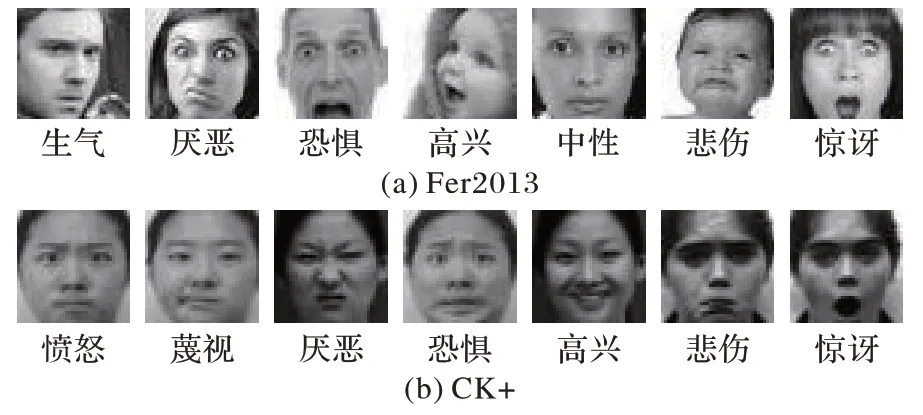
图6 Fer2013、CK+数据集中7类表情样例图Fig.6 Sample diagrams of 7 categories of facial expression in Fer2013 and CK+datasets
由于CK+数据集样本总数偏少,送入神经网络训练容易造成泛化能力弱及过拟合问题,实验过程中对CK+训练集图像做随机旋转、随机缩放、水平/垂直平移、随机水平翻转、亮度及对比度变化等几何变换以扩增数据集,如图7 所示。

图7 CK+数据集中人脸图像数据增强前后对比Fig.7 Comparison before and after facial image data augmentation in CK+dataset
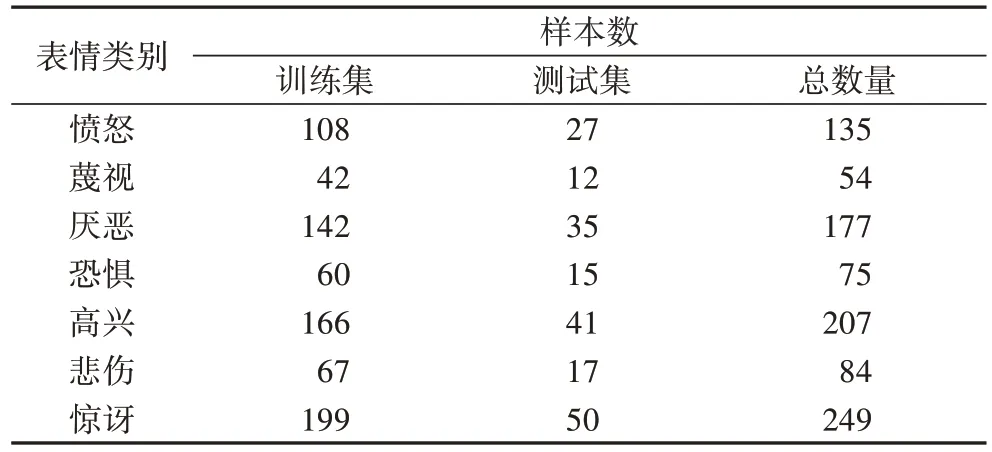
表3 CK+数据集中各表情类别数Tab 3 Number of each expression category in CK+dataset
3.2 实验环境及参数指标
采用深度学习框架Tensorflow 来验证本文改进模型的可行性,实验环境及硬件配置如下:CPU 为Intel Core i5-7200U,内存8 GB,GPU4 GB,TITANX(Pascal),软件环境为Python 3.6.12,Tensorflow 2.0.0,Windows10 专业版64 位。
本实验主要通过识别准确率、损失函数变化曲线、模型参数量三个指标来评估算法性能。基于本文算法的改进模型确保训练时间相差不大,损失函数有所下降,准确率有所提高,模型参数量比改进前有所减少。网络训练时的批次大小设置恰当的范围能使梯度下降方向准确且振荡小,过大会出现局部最优,过小会难以收敛,通过多次实验,最终将批次大小设置为24,并加入随机梯度下降策略优化网络模型。实验参数设置如表4 所示。

表4 模型训练参数描述Tab 4 Model training parameter description
3.3 实验结果与分析
利用基于改进CNN+SVM 算法的模型在Fer2013、CK+数据集上训练,得到的识别精度曲线和损失值变化曲线如图8所示。由图8 可看出:在CK+数据集上,当迭代次数达到150时,模型趋于稳定,识别准确率为98.06%;在Fer2013 数据集上,识别准确率达到73.4%,性能明显提升。图8(b)中,损失误差值在特定的迭代次数内逐渐降低,结合了GAP 和SVM 分类器的优点,其收敛速度更快。因此,基于改进CNN+SVM 算法设计的网络模型能够很好地学习表情特征,具有更好的分类效果。
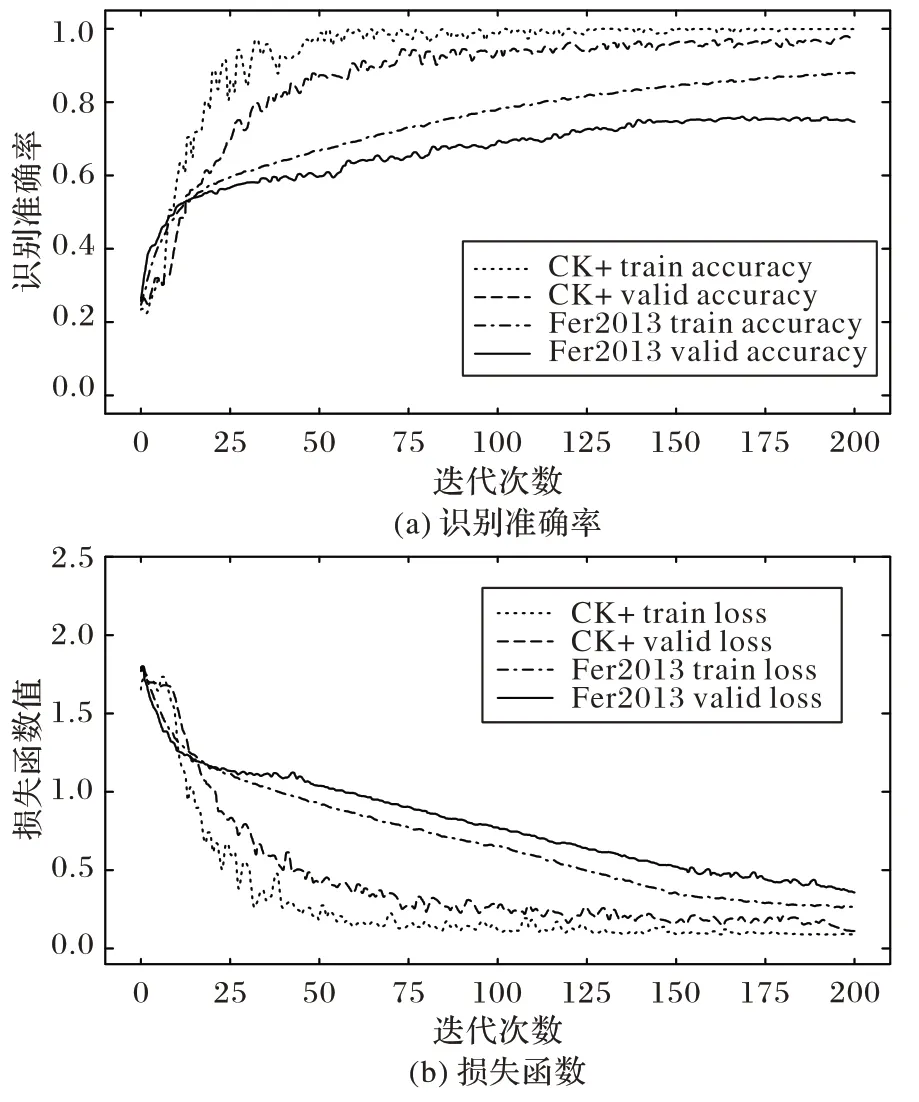
图8 Fer2013及CK+数据集上的训练过程曲线Fig.8 Training process curves on Fer2013 and CK+datasets
基于改进CNN+SVM 算法的网络模型在Fer2013、CK+数据集上对各类表情的识别结果如图9 所示。图9 中共7 种表情类别,混淆矩阵图主对角线上数字为该优化算法对各类表情的识别准确率。由图9 可以得出,本文算法对一些表情变化不明显和不容易区分的类别误判率较高。图9(a)中,类间准确率较低的是恐惧(0.62)和悲伤(0.62),因悲伤和恐惧表情有着相似的嘴角和眉毛变化,导致二者的核心特征难以被充分学习。图9(b)中,蔑视的准确率最低(0.955),因蔑视表情表现为微抬嘴唇,嘴角微微上扬,面部肌肉运动幅度小,导致在SVM 分类中不易被判断和识别。
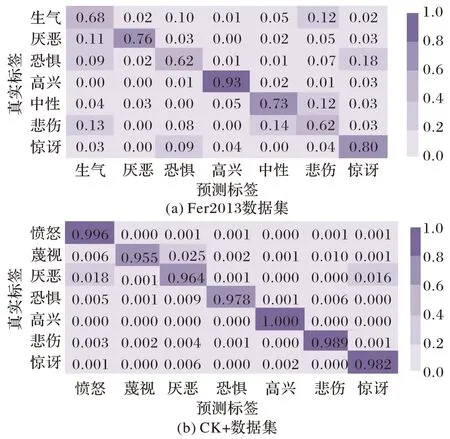
图9 各数据集生成的表情类别混淆矩阵图Fig.9 Confusion matrix of expression category generated by each dataset
图10 描述了传统LeNet-5 算法与本文算法在Fer2013 数据集和CK+数据集上的识别准确率对比曲线。由图10 可见,传统LeNet-5 算法在Fer2013 数据集上的识别率为61.2%,而改进模型识别率达到73.4%,提升了2.2 个百分点;且改进模型在CK+数据集上识别率维持在98.06%。本文算法在两个表情数据库上效果比传统LeNet-5 算法更好的原因:1)改进的CNN 结合了GAP 的优点,GAP 层在特征图与最终分类间转换更简单且省略大量训练参数的特点;2)Softmax 函数分配一个高值给某个节点,其余节点分配低值,结果两极分化。SVM 是计算每一类样本的估计概率值,分类性能更可靠。
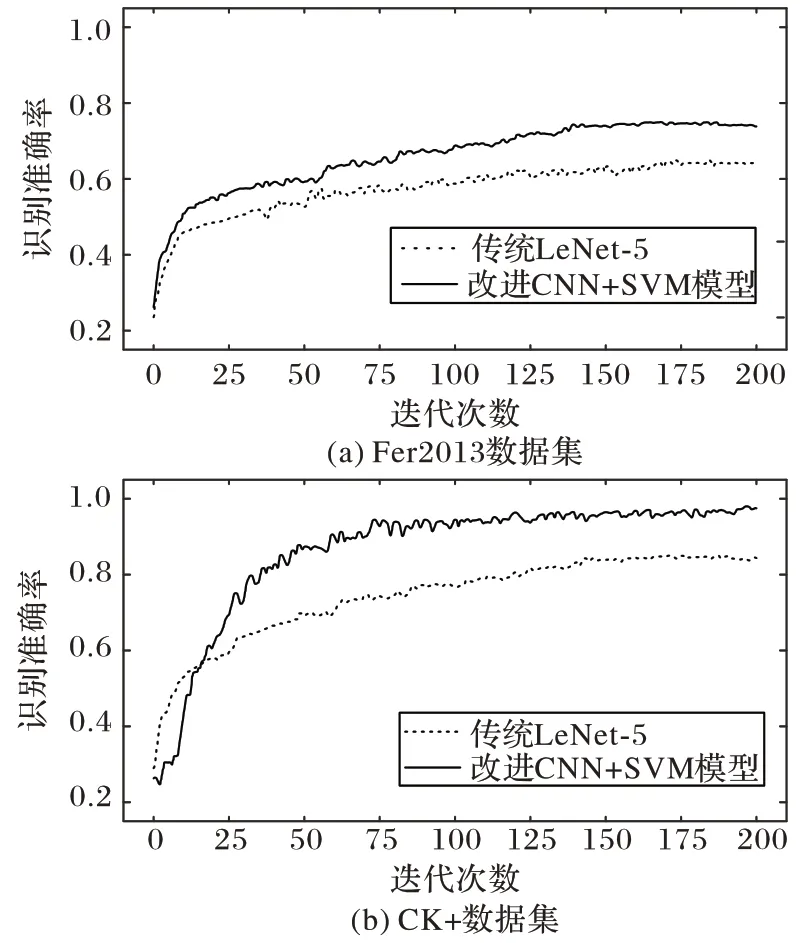
图10 传统模型和改进模型在Fer2013、CK+数据集上的识别准确率比较Fig.10 Comparison of recognition accuracy between traditional model and the improved model on Fer2013 and CK+datasets
为进一步验证本文提出的改进CNN+SVM 算法的优越性,将本文算法与其他算法进行综合对比分析。轻量级卷积+注意力机制(Lightweight Convolution Model based on Attention,LCMA)算法,通过分解多路通道卷积减少模型参数,得到69.6% 的识别率。改进CNN+自编码器(AutoEncoder,AE)引入含注意力机制的CNN 通道和卷积自编码器预训练通道相结合的双通道模型,利用残差思想提取表情特征,取得72.7%的识别率。结合单发多盒检测器(MobileNet Single Shot multibox Detector,MSSD)及核滤波(Kernel Correlation Filter,KCF)模型MSSD+KCF对轻量级CNN 改进,跟踪检测人脸坐标信息,以多尺度特征融合的方式快速精确地识别表情特征。CNN+改进Softmax先在中心损失函数的基础上增加注意力机制,再融合Softmax 损失函数共同监督表情训练,得到良好的识别性能。浅层CNN是在LeNet-5 基础之上调整并移除两个全连接层,利用简单网格搜索方法对图像随机旋转的角度进行最优搜索,取得不错的分类效果。
由图11(a)可见,本文算法识别准确率较优,这是因为CNN 在逐层提取表情特征时,小尺寸卷积核提取的特征属性不同,能充分提取图像更细节和局部的信息,改善了识别效果;GAP 层改进传统CNN 中的全连接层,将卷积层输出特征图的展平向量过程和分类操作合二为一,直接在特征图通道上做变换,进行降维减参处理,提高了识别准确率。
在CK+数据集的对比实验中,浅层神经网络利用数据增强及人脸裁剪的手段得到97.38%的识别率;CNN+SVM通过在LeNet-5 算法的基础上增加一层卷积层和池化层,再融合SVM 分类器的方法提升表情识别效果;改进AlexNet通过减少AlexNet 网络上卷积层的方法,得到97.46%的识别结果;多尺度卷积方法在AlexNet 中引入多尺度卷积,提取不同尺度的特征信息,并把低层次特征信息在向下传递的同时与高层次特征信息进行跨连接特征融合,取得较高的识别准确率;CNN+LBP利用LBP 提取表情特征,然后用均值聚类方法得到样本模板,结合CNN 进行表情的识别,方法有效。由图11(b)可知,所提出的改进CNN+SVM 算法识别准确率相较于传统机器学习方法和改进CNN 都有进一步的提升,这是因为通过小尺寸卷积核串并联融合的技术避免了表情图像有利信息的遗漏,减少了计算量,再融合SVM 分类器在小样本数据集上的分类优势,使得分类效果更优。
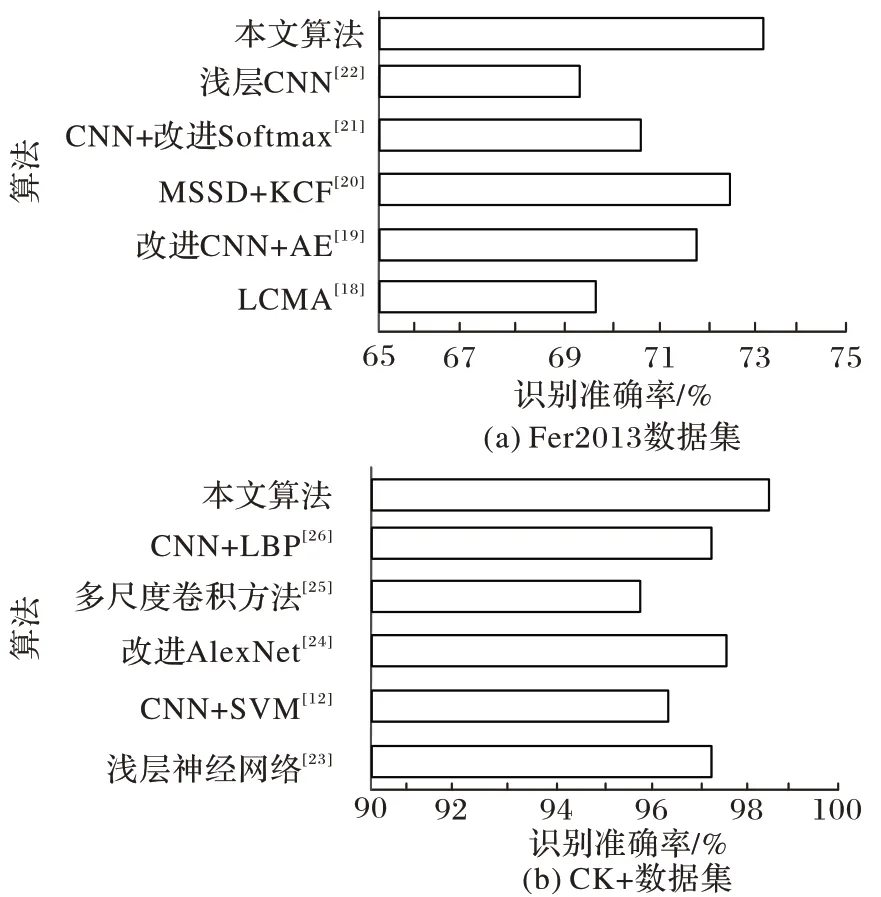
图11 Fer2013、CK+数据集上不同方法的识别效果比较Fig.11 Comparison of recognition effects of different methods on Fer2013 and CK+datasets
4 结语
由于人们在情感交流时表现出多种混合表情,导致面部表情的识别特殊且复杂。为解决各种网络模型及其变体识别面部表情时存在的结构复杂、识别不够理想等问题,本文提出了改进CNN 与SVM 相结合的算法,用于准确且快速地对表情状态分类。通过网络串并联融合的方式提取到更为全局且代表性更强的表情特征,并设计维度自适应GAP 层融合SVM 分类器,有效减少CNN 模型总参数量。由对比实验得出,该改进算法在Fer2013 数据集上的识别准确率相较于传统LeNet-5 算法提升了2.2 个百分点,具有一定的识别效果和稳健性。但本文未考虑面部表情信息缺失及非正面人脸图像在复杂环境下的识别率情况,如何将本文算法应用于复杂环境下的表情识别系统中将是下一步的研究工作。
