
基于联邦增量学习的工业物联网数据共享方法
2022-05-07 07:08董志红张喆语孙志刚季海鹏
计算机应用 2022年4期
刘 晶,董志红,张喆语,孙志刚,季海鹏
(1.河北工业大学人工智能与数据科学学院,天津 300401;2.河北省数据驱动工业智能工程研究中心(河北工业大学),天津 300401;3.天津开发区精诺瀚海数据科技有限公司,天津 300401;4.长城汽车股份有限公司天津哈弗分公司,天津 300462;5.河北工业大学材料科学与工程学院,天津 300401)
0 引言
随着“德国工业4.0”“美国工业互联网”以及“中国制造2025”战略目标相继提出,工业物联网(Industrial Internet Of Things,IIOT)以极高的速度向产业链传输海量工业数据,使得基于数据驱动的机器学习方法广泛应用于工业制造中。众所周知,随着训练数据量的增大和多样化,机器学习所训练的模型会更好。然而,在工业领域,企业间出于竞争或用户隐私原因而无法将数据资源共享,因此如何在保护企业数据隐私的前提下进行多源数据融合分析,以加快行业的发展变得十分重要。
联邦学习(Federated Learning,FL)是一种新兴的人工智能基础技术,其设计目标是在保障边缘数据和个人数据安全的前提下,在多参与方或多计算节点之间开展高效率的机器学习。目前,已有学者将FL 应用于多个领域,如Hu 等通过对空气质量数据进行区域划分,在FL 中建立有权值的区域模型,解决了空气质量数据分布不平衡和计算资源浪费的问题。Yang 等提出了一种基于FL 的带隐私保护的信用卡欺诈检测方法,采用过采样技术来平衡极度倾斜的信用卡交易记录,同时使用FL 构建全局共享欺诈检测方法,以解决因数据隐私保护而导致无法大规模协作训练的难题。Hu 等将数据特征和模型参数同时上传至FL 中央服务器,同时给出面向各客户端的特征融合策略,并利用回声状态网络实现精准趋势跟踪,最后将所提算法应用于矿井多传感器采集的时序数据趋势跟踪中,验证了算法的有效性。王蓉等通过数据填充进行数据维度重构,然后在FL 的机制下利用深度卷积神经网络(Deep Convolutional Neural Network,DCNN)进行特征提取学习,最后结合Softmax 分类器训练入侵检测模型,保证了数据安全隐私的同时还减少了模型的训练时间。上述方法都在一定程度上实现了保护数据安全隐私情况下的联合学习,但在工业领域,由于IIOT 中实时产生的新增数据是海量的,如何有效地增量学习使新增状态数据与已有行业联合模型快速融合,同时保证各工厂子端同等参与成为新的问题焦点。不考虑增量数据权重的传统联邦增量算法在很大程度上取决于工厂子端的重复学习,从而增加了时间成本,并且还会导致行业联合模型精准度严重下降及联合训练过程中行业联合模型的倾斜等问题。
为解决IIOT 新增数据量大及工厂子端数据量不均衡的问题,本文提出一种基于联邦增量学习的IIOT 数据共享方法(data sharing method of Industrial Internet Of Things based on Federal Incremental Learning,FIL-IIOT)。
本文主要工作为:1)针对工厂子端数据量不均衡问题,提出了一种联邦优选子端算法,目的是根据工厂子端等级值动态调整参与子集,保证联合训练的动态平衡;2)针对工厂子端大量新增数据与原行业联合模型融合问题,提出了一种联邦增量学习算法,目的是通过计算工厂子端的增量加权,将新增状态数据与原行业联合模型快速融合,实现对新增状态数据的有效增量学习。
1 相关工作
1.1 联邦学习
FL 由谷歌在2017 年提出,遵循知情收集或者数据量最小化原则。如图1 所示,FL 包含两个重要组成部分:局部模型训练和中心聚合,其中,局部模型训练使用存储在本地客户端上的数据,仅将局部模型参数发送至中心服务器,以聚合获取中心全局模型的参数。典型FL 的整个流程由很多通信轮次构成,在这些通信轮次中,利用本地数据,客户端同步地训练局部模型。以第k
个客户端为例,其训练样本数据记作D
,对应的局部模型参数记作ω
,其中k
∈S
,S
为包含m
个客户端的参与子集。每个通信轮次中,只有属于此子集的客户端的模型下载中心全局模型的参数,作为局部模型的初始参数;在局部训练后,这些客户端会把更新后的模型参数发送给中心服务器,服务器通过执行聚合操作,更新中心模型参数,即ω
=Agg
(ω
)。在客户端本地执行的局部训练,仅仅利用本地存储的相应数据。由于不需要各客户端上传任何用户隐私数据至中心服务器,此技术提供了一个保障客户端数据隐私的安全学习模式。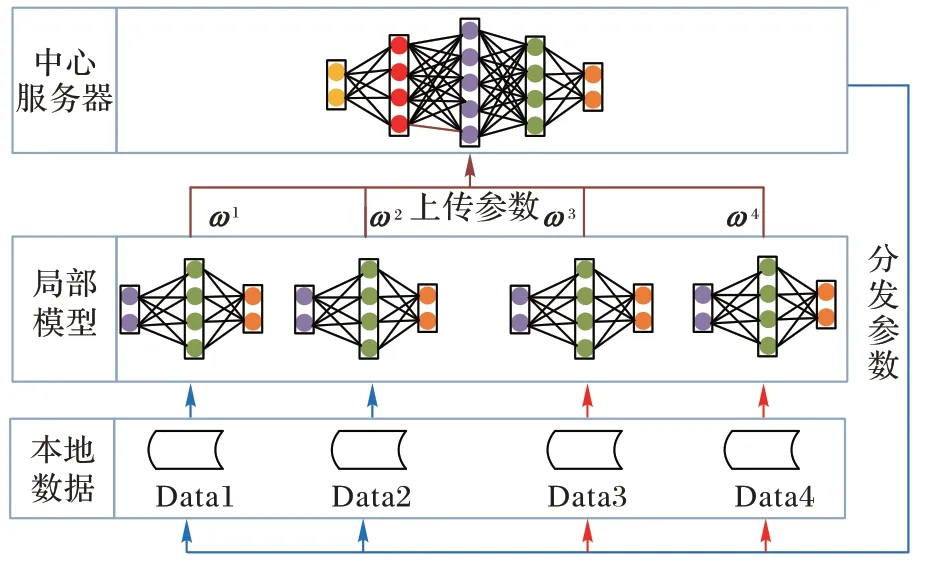
图1 联邦学习框架Fig.1 Federated learning framework
在诸多领域,FL 都具有广阔的研究价值和应用前景,与金融、医疗、智慧城市、物联网和区块链等结合的研究都取得了一定的进展与成就。
1.2 联邦均值算法

t
=1,2,…过程中,将随机从所有参与联合训练的客户端中选择一定百分比的客户端与中心服务器直接通信。然后,各个参与进FL 的客户端从中心服务器下载当前的全局模型参数。每个客户端固定的学习率为η
,在当前本地模型参数ω
下计算私有数据集上的平均损失的梯度f
,f
=∇L
(x
,y
;ω
)。这些客户端同步更新其本地模型,同时将本地模型参数的更新上传至中心服务器。中心服务器将对上传的模型参数进行聚合操作来进一步优化全局共享模型: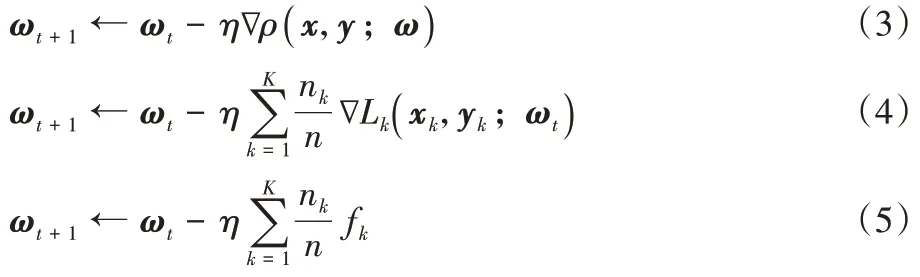

2 本文方法
2.1 方法框架
本文方法FIL-IIOT 框架分为行业联合端层和工厂子端层,其中联邦优选子端模块处于行业联合端层,联邦增量学习模块横跨2 层,如图2 所示。
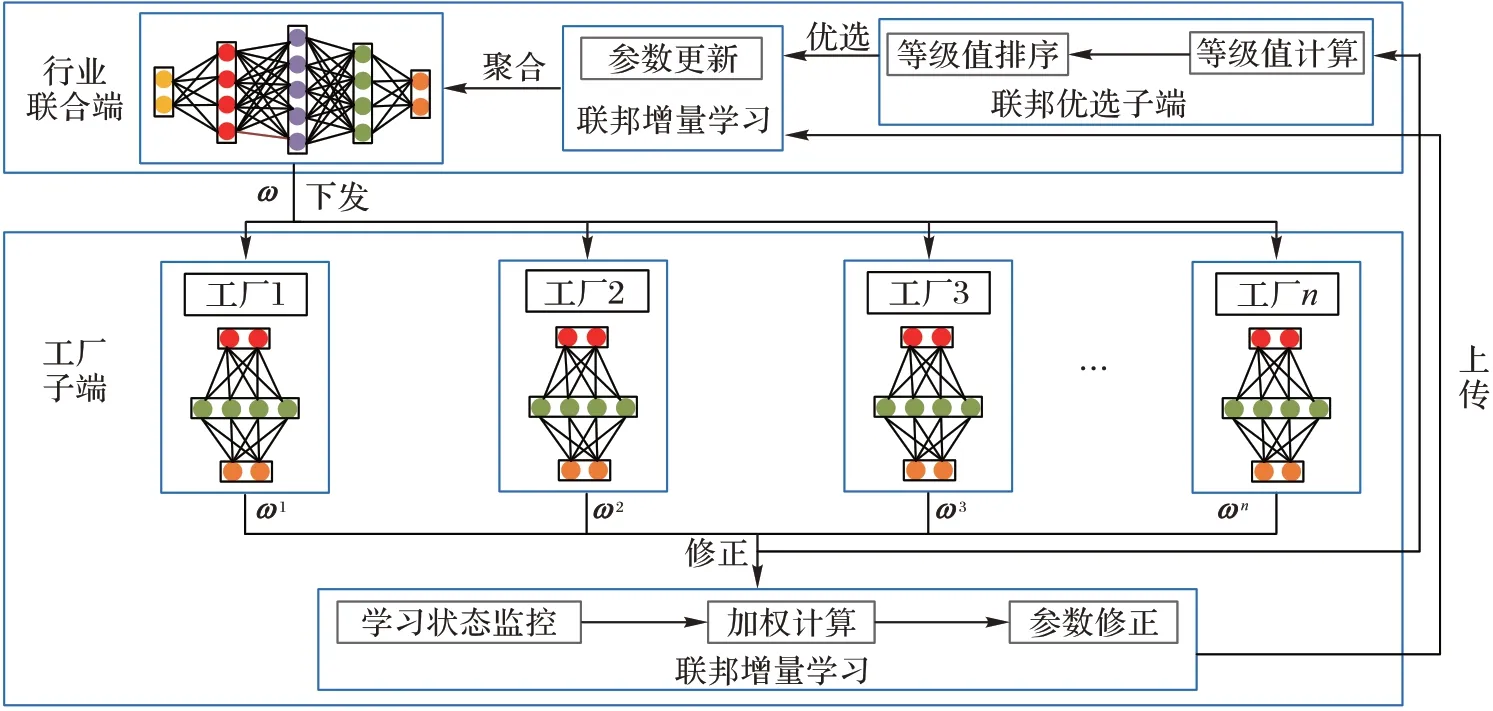
图2 FLT-IIOT的框架Fig.2 Framework of FLT-IIOT
联邦优选子端模块分为等级值计算和等级值排序2 个子模块,分别负责根据工厂子端性能指标计算最新等级值和对等级值进行排序便于对工厂子端进行优选。
由于工厂子端具有高度自由性,因此将具有不同新增数据量的工厂子端对行业联合端中的模型参数进行等量的更新显然是不合理的。联邦增量学习模块则分为4 个子模块:参数更新、参数修正、加权计算和学习状态监控。学习状态监控子模块负责监控工厂子端学习状态如参数深度值与增量样本数量等;加权计算子模块根据工厂子端学习信息计算对应样本的增量加权;参数修正子模块将工厂子端上传模型参数根据增量加权进行修正;而只有经联邦优选子端模块优选的模型参数才被用于参数更新子模块进行行业联合模型参数更新。
联邦优选子端模块与联邦增量学习模块不是相互独立的,联邦优选子端等级值计算需要获取聚合后的参数,并训练本地模型求出性能指标等级值。而优选后的工厂子端影响了行业联合模型学习方向,进而影响联邦增量的融合。
2.2 联邦优选子端算法
2.2.1 联邦优选子端说明
联邦优选子端是指行业联合端在每次更新模型参数前对参与本次通信子端进行选择,即选择参加联合训练的工厂子端。在传统的FL 中,大多采用设置参与通信的比例,或者根据设定的固定阈值作为能否参加联合训练的判别条件,这些方法在工业应用中存在如下不足:1)工厂子端本地数据及新增数据不均衡导致学习过程中参数变化程度是不同的,简单地根据通信比例随机选取参与子集很容易忽略有用参数信息,造成行业联合模型训练过程发生倾斜,进而影响工厂子端模型精准度;2)依据设定的固定阈值有时会耗费大量的时间,且在训练的后期造成行业联合模型波动不易收敛的结果。
在FIL-IIOT 中,行业联合端在选择参与本次通信的工厂子端时,首先计算工厂子端等级值并对其进行排序,然后根据设定的比例系数F
挑选出参与子集。只有被选中的子端才能获取对应轮次行业联合端聚合本地参数的资格,否则在本地累计参数信息,进行下一轮学习迭代,最终参数将累计足够的信息量上传到行业联合端。无论工厂子端是否获得该轮次的聚合参数资格,在下一轮学习结束后都要进行等级值计算,即等级值计算是贯穿整个学习过程。2.2.2 等级值计算
马氏距离是一种用来表示数据的协方差距离的方法,可以有效地计算两个未知样本的相似度,应用于工厂子端的性能指标上,可以使性能指标的马氏距离更加准确地反映工厂子端当前参与程度。为了得到更加全面的一维性能指标来准确描述工厂子端的参与程度,使用马氏距离对工厂子端的准确率(Acc)、损失值(loss)和kappa 值特征向量进行计算,统计出该工厂子端与其他所有子端性能指标的马氏距离之和作为该工厂子端等级值SD
。等级值越大,性能指标相似性越小;反之亦然。假设两个工厂子端分别为u
=(u
,u
,u
),v
=(v
,v
,v
),则u
与v
协方差P
的计算式为: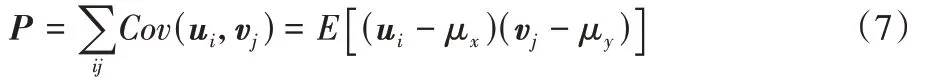
μ
=E
(u
),μ
=E
(v
)。两个来自非独立同分布的工厂子端u
和v
的马氏距离MD
(u
,v
)的计算式为: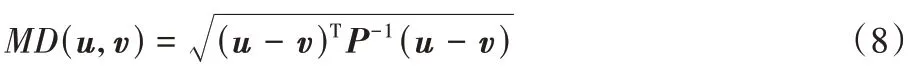
SD
:
K
表示所有工厂子端的数量。2.3 联邦增量学习算法
FIL-IIOT 面向的对象是高度自由的工厂子端,对于指数型增长的新增数据如何挖掘新产生状态数据,合并到已有FL 算法的挖掘模式中成为新的问题焦点。传统联邦增量算法训练的模型重复从本地数据中提取数据特征进行训练学习,但无法随IIOT 实时新增数据自适应增量修正行业联合模型,导致时间成本增加,模型诊断精度下降。本文使用增量加权来解决联邦增量学习问题。
联邦增量学习中工厂子端存在学习样本不均、数据动态增加等问题。如图3 所示,所有工厂子端所处的通信轮次是相同的,通信轮次线下面表示已经完成训练的数据,通信轮次线上面部分表示新增加的数据,还未进行训练。图3 中工厂子端新增的数据量是不同的,如子端1 在原有数据的基础上增加了一倍,若原数据量为200,则子端1 现有数据量为400。

图3 子端增量数据不均衡示意图Fig.3 Schematic diagram of sub-end incremental data imbalance
样本数在一定程度上反映了样本的多样性,基于高复杂度数据训练的模型具有更好的扩展性。而模型训练的过程可以理解为模型的“学习”的过程,一般地,随着时间的推移,模型越接近问题的最优解,但更多的新增数据会使工厂子端与学习问题最优解的距离加大,因此这些新增数据不均的工厂子端对行业联合端中的模型参数进行等量的更新显然是不合理的。本文引入增量加权聚合策略来解决联邦增量学习中工厂子端最优解不均衡的问题。
在1.2 节中给出了联邦均值(Federated Averaging,FedAvg)算法,其聚合策略参见式(6),此策略仅考虑工厂子端训练集数据量对聚合的影响,即更大的n
会对生成的行业联合模型影响更大,而对于新增状态数据并未做特殊处理。本文引入增量权值,通过对工厂子端参数深度值的计算进而影响聚合策略。增量权值表示工厂子端新增样本数在原样本总数中占比大小。工厂子端k
的增量权值可由新增样本数与总样本数求得:
I
|为工厂子端新增的样本数,|D
|为工厂子端原样本总数。图4 中方块和圆形颜色的深浅表示增量效应,即工厂子端对生成模型影响的重要程度。
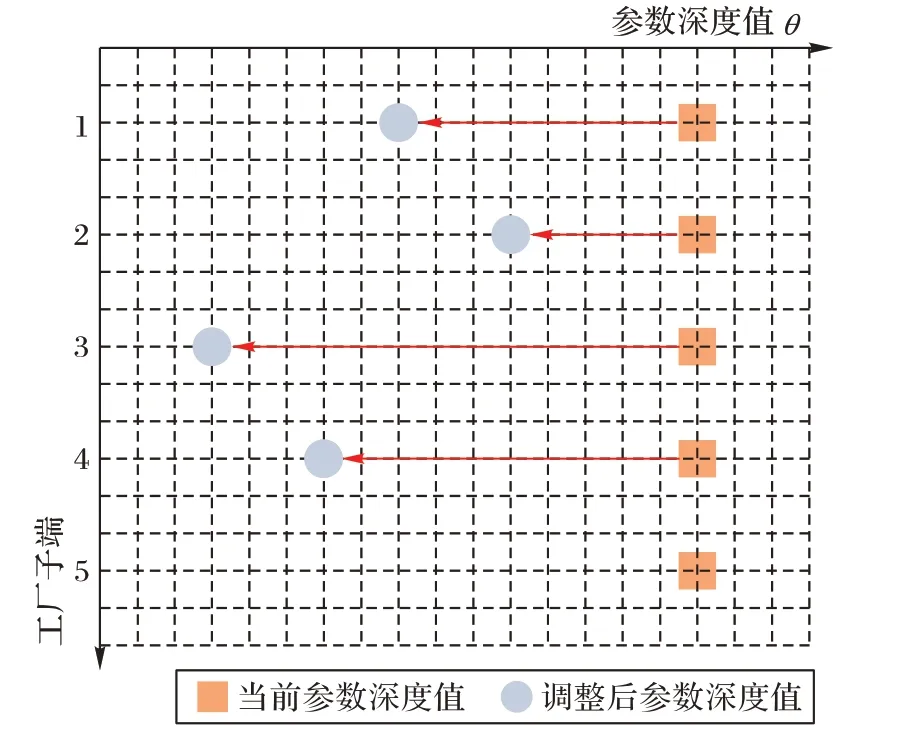
图4 联邦增量学习与参数深度值Fig.4 Federal incremental learning and parameter depth value
参数优化过程中具有一定的深度值,令参数深度值为:

工厂子端下载和上传参数的时间间隔内都会有新的训练数据的产生,参数深度值也会进行一定的更新。参数深度值表示工厂子端在完成一次迭代学习中本地数据集新增加的数据对模型性能的影响程度,反映了工厂子端的更新度。为了使参数深度值越大的工厂子端其参数加权越小,且衰减的过程相对平缓,本文选择反正切函数作为增量加权的衰减函数:

FL 框架下,每一轮仅更新参与子集中的工厂子端,根据工厂子端模型的参数深度值确定模型对聚合操作的贡献可有效利用历史信息,并区分本地模型利用价值,可望提高聚合操作的有效性,因而进一步关注本地模型的参数加权,提出的改进聚合策略如下:

在联邦增量学习过程中,工厂子端提交的模型参数要经过增量加权的修正才能参与行业联合模型优化。修正后的参数在行业联合端上根据具体的优化算法更新模型参数,优化结束后,工厂子端重新获得最新的行业联合模型参数并将其覆盖本地参数,进行下一轮迭代学习。
2.4 基于联邦增量学习的工业物联网数据共享方法实现
本节给出FIL-IIOT 方法的伪代码,包括行业联合端执行部分(UnionExecutes,参见算法1)以及工厂子端更新部分(FactoryUpdate,参见算法2)。
算法1 FIL-IIOT 行业联合端执行部分。

ω
、t
和θ
为输入,其中:ω
表示行业联合端的模型参数,t
代表通信轮次的标号,θ
表示t
轮次工厂子端的参数深度值。设B
代表工厂子端数据分批次大小,E
代表工厂子端训练迭代次数,η
代表学习率。具体而言,第2)~7)行表示获取工厂子端最新参数深度值,如果有新增数据使用2.3 节方法得到参数深度值,否则将轮次标号作为最新值;第8)行表示根据参数深度值求出增量加权β
;第9)行表示获取最新的数据集;第10)~15)行表示采用局部梯度训练法训练工厂子端模型参数;第16)行表示将工厂子端模型参数ω
和参数增量加权β
返回至行业联合端。算法2 FIL-IIOT 工厂子端更新部分。
输入ω
、t
、θ
。输出ω、β
。

3 实验与结果分析
为验证FIL-IIOT 方法的有效性,本章选择在IIOT 中最常见的轴承故障分类为例。轴承作为工厂设备的关键支撑部件,是机械设备中最易受损的零件之一。由于各工厂之间轴承具有高度相似性,其数据共享对模型的训练有非常大的价值。但是,由于设备状态数据属于工厂隐私数据,出于数据安全的原因而无法共享,造成单体工厂的轴承数据存在样本量少、相似度高、多样性不足等问题。FL 可在不上传工厂轴承数据的情况下协同多工厂子端训练行业联合模型,既满足了模型精确度的要求又兼顾了工厂数据的安全。由于设备运行的连续性,其状态数据随着时间的临近价值也在增加,其对故障诊断的重要性也在增加,但是传统的FL 难以处理工厂子端大量新增数据的模型融合问题,从而很难持续优化。本文以美国凯斯西储大学(Case Western Reserve University,CWRU)电气工程实验室的轴承故障数据为实验数据,验证FIL-IIOT 方法能够较好地解决上述问题。
3.1 数据描述
美国凯斯西储大学电气工程实验室的轴承故障数据,共计1 341 856 个数据点,轴承型号为6205-2RS JEM SKF 深沟球轴承。利用电火花加工方式分别在轴承上对内圈(Inner RaceWay,IRW)、外圈(Outer RaceWay,ORW)和滚动体(BAll,BA)设置了3 个等级的单点故障,故障直径分别为0.007 inch(轻度)、0.014 inch(中度)、0.021 inch(重度),故障深度分别为0.011 inch、0.050 inch、0.150 inch(1 inch=25.4 mm)。单点故障分别设置在了电机驱动端(Driver End)和风扇端(Fan End)。本节实验采用在Driver End 和Fan End的振动传感器(采集频率12 kHz)采集的包含12 种故障类型和正常数据的样本,样例长度为1 024,各类别样例数量为400,样本信息如表1 所示。
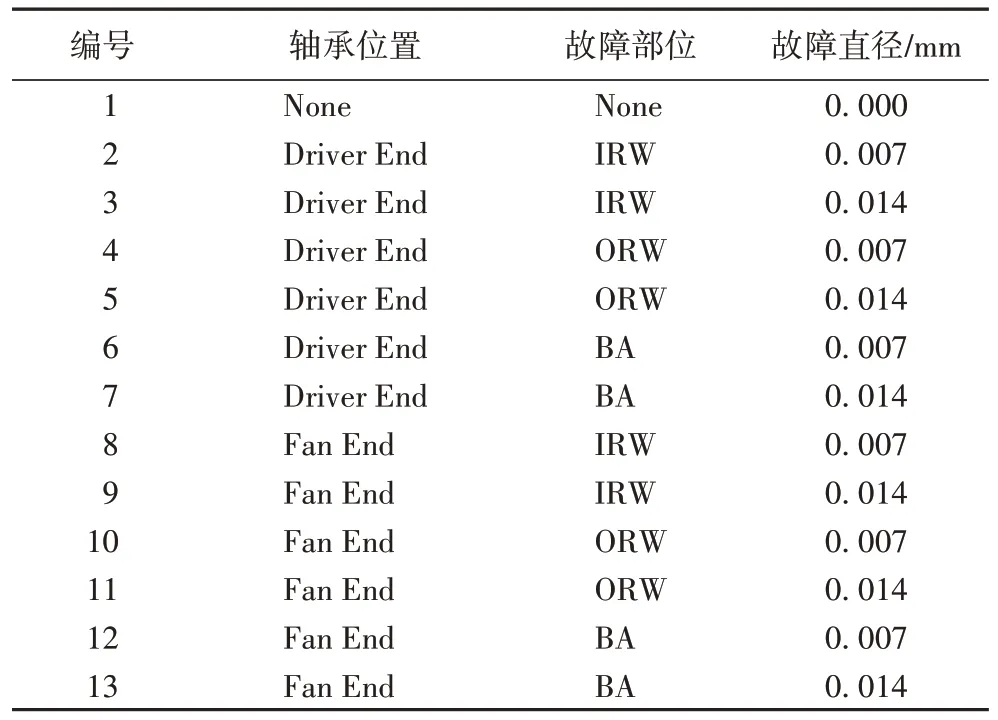
表1 轴承故障实验数据描述Tab 1 Experimental data description of bearing failure
3.2 模型及工具
本节实验中使用的长短期记忆(Long Short-Term Memory,LSTM)网络的架构为:输入层,一层LSTM 层(cell size=30,time steps=1 024),后接一64 节点及线性整流(Rectified Linear Unit,ReLU)激活函数的全连接层,以及一个Softmax 输出层。具体参数见表2。
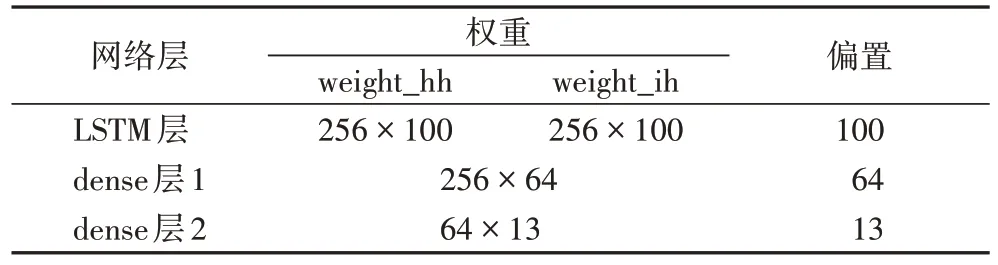
表2 LSTM参数Tab 2 LSTM parameters
运行实验计算机的具体配置为:Intel 酷睿i7-8700K CPU,DDR4 2 400 MHz 16 GB 内 存,NVIDIA Geforce GTX1080Ti GPU,CUDA10.0 和CuDNN7.5 驱动,Windows10专业版64 位操作系统。实验的软件开发使用Python3.7、TensorFlow1.14.0 以及Keras2.3。
3.3 联邦优选实验
在本节中,使用3.1 节确定的数据集验证FIL-IIOT 方法在工厂子端选择上的优化效果,将上述数据集随机打乱后划分出30% 用于测试,其余随机划分成10 份(Factory_0,Factory_1,…,Factory_9),表示10 个工厂子端本地数据集用来训练本地模型。随机划分数据集可以满足数据源特征相同、本不同的需求,以及可以满足交叉验证模型的合理性。第一部分实验对FIL-IIOT 方法在故障诊断模型中参与联合训练的工厂子端比例系数F
做测试和验证,确定好方法基本的参数,能更好地协调方法的性能和效率。实验使用的性能指标:1)训练准确率,50 通信轮全局模型所能达到准确率,以说明在指定通信代价下,聚合操作的有效性;2)通信轮次,全局模型达到特定准确率(0.95)所需轮数,以比较在相同准确率下算法所需通信代价;3)每轮时间。所有实验重复10次,对比分析相应参数分类性能的平均值,实验结果如表3所示。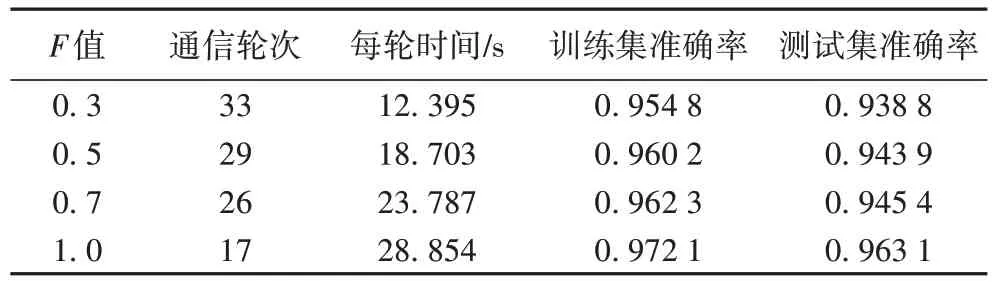
表3 比例系数对模型性能影响Tab 3 Influence of scale factor on model performance
表3 展示了不同的比例系数F
值(即每轮次参与联合训练的工厂子端数量)对故障诊断模型各方面的性能影响。根据表3 可知,随着参与联合训练的工厂子端数量的增加,达到目标准确率所需要的迭代轮数呈现递减的趋势,同时整个故障诊断模型的性能也有一定的提升。图5 表示随着参与联合训练的工厂子端数量的增加,每轮迭代训练的时间也随之增加,虽然达到目标准确率的训练轮数减少,但系统总消耗的时间仍然是呈上升趋势。从最佳训练准确率和最佳测试准确率的角度来看,随着工厂子端数量的增加,整个故障诊断模型性能得到提升。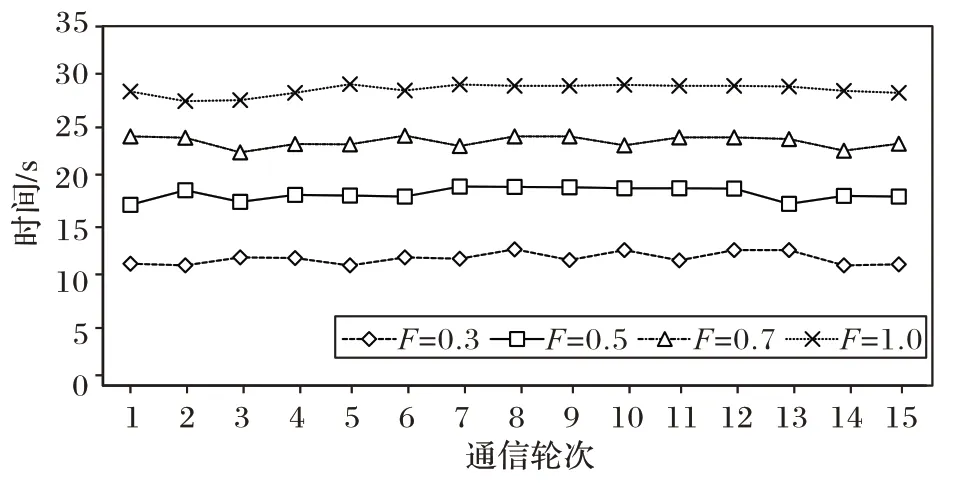
图5 不同比例系数每轮迭代时间Fig.5 Iteration time of each round with different scale factors
在确定好故障诊断模型的F
值后,本文还测试了本地模型批处理大小(Batchsize,B
)和迭代次数(Epoch,E
)对算法分类性能的影响。实验中固定F
=0.3,对于B
的实验给定E
=5,而E
的实验B
=100。从图6 可知,模型分类性能随B
的增大表现出下降的现象;而图7 中,模型分类性能随E
的增大,先增大后减小。这要求在实验中控制B
和E
的大小。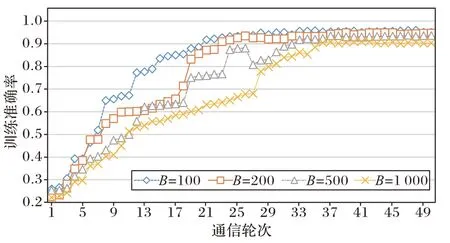
图6 本地批处理大小对模型性能影响Fig.6 Influence of local batch size on model performance
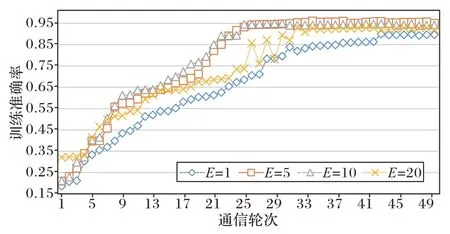
图7 本地迭代次数对模型性能影响Fig.7 Influence of local iteration times on model performance
基于上述参数实验结果,这里同样固定B
=100 以及E
=5,记录在不同的F
值下训练过程中工厂子端部分轮次等级值变化情况,如表4 所示。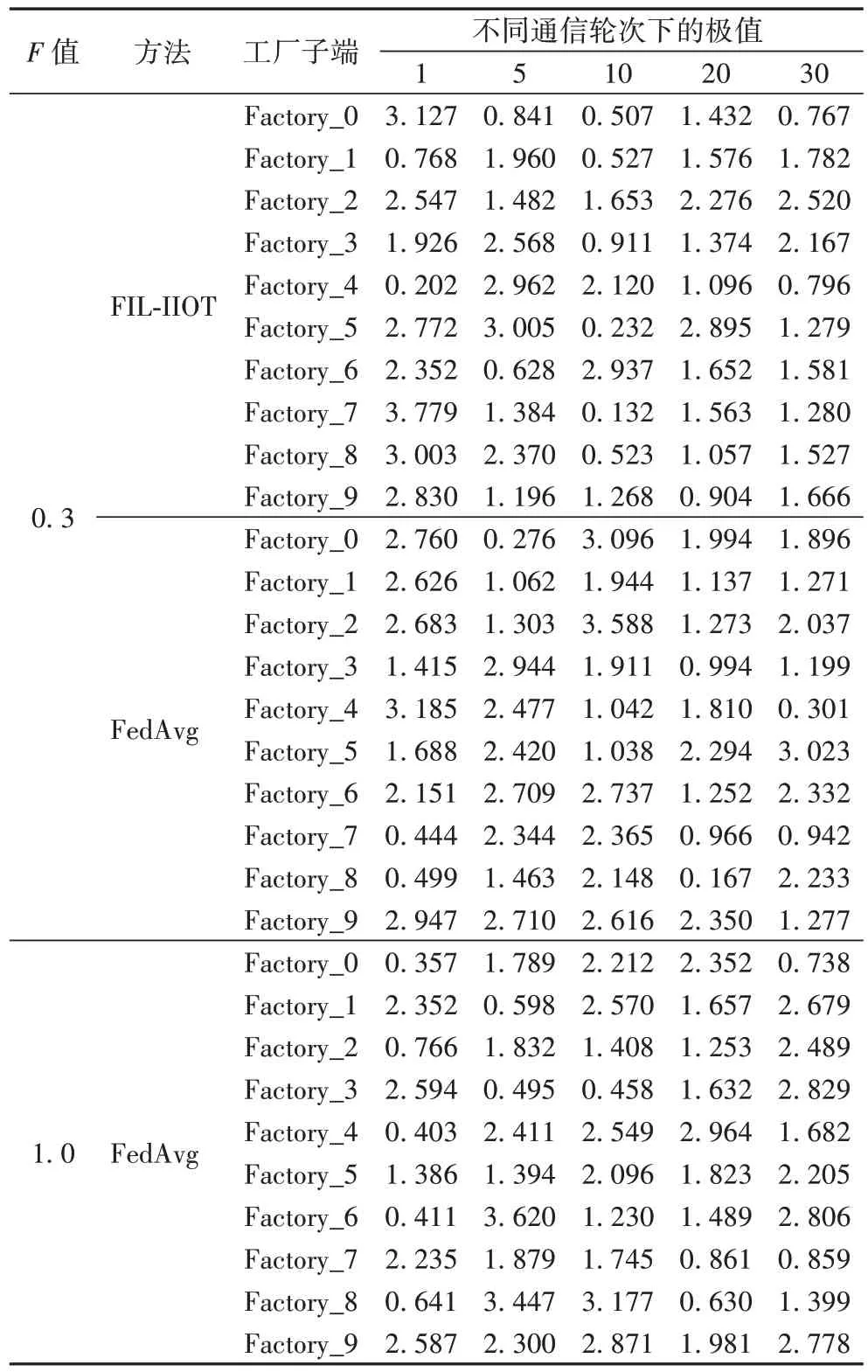
表4 工厂子端等级值变化情况Tab 4 Change of factory sub-end level value
通过表4 可以得出,FIL-IIOT 方法保证了工厂子端的公平参与训练,第一轮后工厂子端等级值分布较分散,进行到第五轮后,FIL-IIOT 方法下的工厂子端等级值分散度缩小。从图8 的方差对比图亦可得知,而FedAvg 方法在F
=0.3 下的工厂子端倾斜最严重,一方面向随机选择次数多的工厂子端数据倾斜,另一方面向工厂子端本地数据量大的方向倾斜;FedAvg 方法在F
=1 下的工厂子端倾斜虽然没有在F
=0.3 下倾斜严重,但还是可以看出等级值分布偏向了数据量大的工厂子端。图8 表示的是工厂子端在部分轮次后工厂子端等级值方差变化,可以看出:FIL-IIOT 方法随着训练的深入方差在减小;而FedAvg 方法方差表现不稳定、波动量很大,表明训练过程工厂子端出现倾斜情况。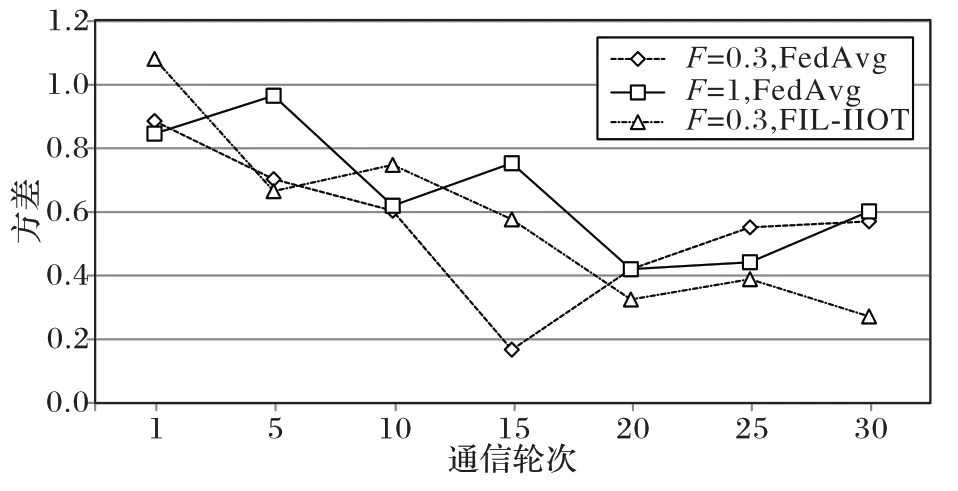
图8 工厂子端等级值方差对比Fig.8 Variance comparison of factory sub-end level value
选择在FL 任务中性能优异的FedAvg 算法作为对比方法进行在不同F
值、不同方法下的性能对比实验。其中,训练集准确率为在50 通信轮内全局模型所能达到的最优精度,训练时间为在50 通信轮内全局模型达到最优精度所需时间。性能对比实验结果如表5 所示。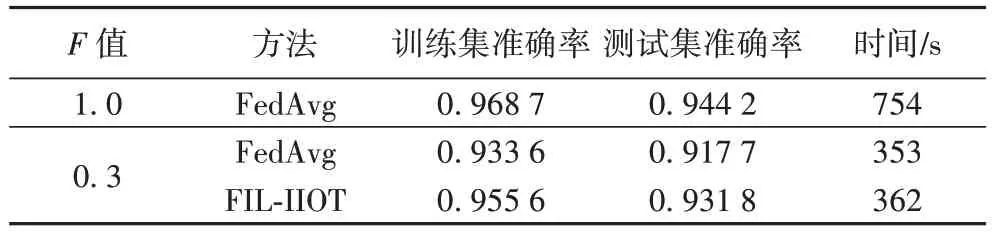
表5 联邦优选算法性能对比Tab 5 Performance comparison of federal optimization algorithm
通过表5 可以看出,在F
=0.3 的情况下,FIL-IIOT 方法无论是在训练集还是测试集上都比FedAvg 表现更好;与F
=1的FedAvg 相比,FIL-IIOT 方法在训练集和测试集上准确率相差无几,但模型的训练时间更短,且FedAvg 的性能倾向于大数据集,所以整体上平衡性能表现不如FIL-IIOT 方法。3.4 联邦增量实验
为了使增量学习的实验效果更加显著,增量学习这部分的实验数据还是采用3.1 节确定的数据集,但是在工厂子端将数据平均分配成四组,其中一组用于训练FL 模型,剩余三组分三次添加至本地数据集进行增量学习。在F
=0.3,B
=100 以及E
=5 的情况下,使用本文提出的FIL-IIOT 方法分别同无增量公式的FIL-IIOT(FIL-IIOT of Non Increment,FILIIOT-NI)方法和FedAvg 方法进行增量学习对比,并使用测试样本测试模型分类效果。其中:训练准确率为在50 通信轮内全局模型所能达到的最优精度,训练时间为在50 通信轮内全局模型达到最优精度所需时间;对每组增量数据记录10 次实验的准确率和运行时间并求平均值。计算四组增量数据的训练平均值和测试值对比结果如表6 所示。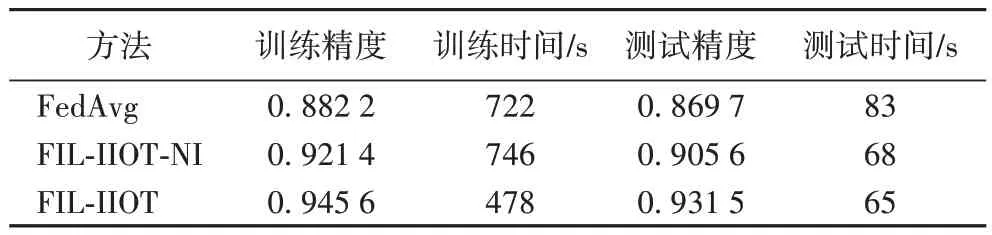
表6 增量故障分类结果对比Tab 6 Comparison of incremental failure classification results
通过观察表6 实验结果可知,FIL-IIOT 方法在模型准确率和运行时间方面均优于其他两种方法,从模型分类准确率方面来看,在训练阶段达到94.56%;在测试阶段达到93.15%,相较于FedAvg 方法提高了6.18 个百分点,相较于FIL-IIOT-NI 方法提高了2.59 个百分点。可见FIL-IIOT 方法由于对增量数据进行了增量加权,考虑了本地数据随时间变化的重要性改变程度,因此使得模型故障分类精度有了一定程度的提高。从模型运行时间方面来看,FIL-IIOT 方法在训练时间和测试时间上均少于其他方法,这是由于其他两种方法在面临增量数据时需要重新训练已有模型增加了运行时间,因此表明增量加权聚合的FL 算法对于减轻模型计算量、节约时间成本起到了一定作用。图9 所示为FIL-IIOT 方法同FIL-IIOT-NI 方法的训练精度和训练时间的对比图,验证了所提FIL-IIOT 方法的高效性。
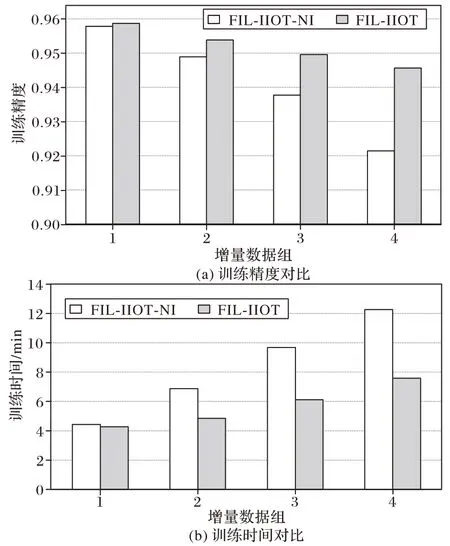
图9 联邦增量数据模型性能对比Fig.9 Performance comparison of federal incremental data models
由此可见,FIL-IIOT 方法与FIL-IIOT-NI 方法相比在模型精度和运行效率方面均具有优势。FIL-IIOT 方法通过增量加权学习对新增特征模式进行增量合并和动态加权,既能利用已有知识模式有效减少故障特征学习时间,又能利用新增特征显著提高故障诊断精度,兼顾新增模式与失效模式,满足轴承故障分类诊断海量新增数据的需求。
4 结语
在工业领域,企业间出于竞争或隐私保护原因难以将数据资源共享,阻碍了行业进步和提升,因此如何在保护企业数据隐私的前提下进行多源数据融合分析变得十分重要。联邦学习可以在保护数据隐私的情况下进行数据共享,以优化行业联合模型。但是由于IIOT 存在工厂子端数据量不均衡等问题,传统的联邦学习很难利用经典增量学习算法对其模型进行持续优化。针对上述问题,提出了一种基于联邦增量学习的IIOT 数据共享方法,该方法首先针对工厂子端数据量不均衡问题提出联邦优选子端算法,根据工厂子端等级值动态调整参与子集,保证联合训练的动态平衡。其次,针对工厂子端海量新增数据与原行业联合模型融合问题提出联邦增量学习算法,通过计算工厂子端的增量加权,使新增状态数据与原行业联合模型快速融合,实现对新增状态数据的有效增量学习。最后,利用设备故障诊断数据证明该方法在考虑子端数据分布不均衡问题的同时,进一步兼顾了对新增状态数据的融合,可有效完成IIOT 中数据共享需求,并进一步利用增量数据优化行业模型。
但本文方法仍有需要进一步完善的地方,如在联邦优选子端算法中,执行等级值计算及排序是牺牲时间来保证训练平衡,在实际应用中,对百万甚至千万级别的子端进行计算和排序带来的时间成本无疑是不可忽视的。为了缓解行业联合端计算量,可以在行业联合端增加“预估”模块。在未来的研究中,将进一步对“预估”模块进行研究。
