
基于场景变化的传输控制协议拥塞控制切换方案
2022-05-07 07:08赖涵光
计算机应用 2022年4期
赖涵光,李 清,江 勇*
(1.清华大学深圳国际研究生院,广东深圳 518055;2.南方科技大学未来网络研究院,广东深圳 518055)
0 引言
传输控制协议(Transmission Control Protocol,TCP)拥塞控制是网络传输的传统问题,也是核心问题,传统的TCP 通过调整拥塞窗口的方式来进行拥塞控制。而拥塞窗口的调整主要通过慢启动、拥塞避免、快速重传和快速恢复四个机制来实现,从而在避免拥塞的情况下实现吞吐量的最大化。
当前,在学术界和工业界,人工智能(Artificial Intelligence,AI)的研究与应用发展迅猛,包含机器学习、深度学习和深度强化学习等人工智能方法正越来越多地被应用于解决各种实际问题,并在人脸识别、推荐系统、语音识别、工业机器人等一系列领域取得了相当显著的成果。
近年来,许多学者开始将人工智能方法用于TCP 拥塞控制的领域,并取得了一定的成果,但尚无法达到替代传统方法的程度。主要原因在于,基于AI 的拥塞控制方法在不同场景下仍然存在着一定的不足。例如,在基于强化学习的拥塞控制算法中,Aurora虽然取得了较好的吞吐量但牺牲了收敛性和公平性,而Orca为了解决收敛性和强化学习的可解释性问题,不得不在吞吐量和时延性能上作出让步。而对于目前主流的研究方案,即测量瓶颈链路带宽和时延的拥塞控制(congestion control based on measuring Bottleneck Bandwidth and Round-trip propagation time,BBR)、面向性能的拥塞控制(Performance-oriented Congestion Control,PCC)、Copa等相对轻量级基于人工智能的拥塞控制方法而言,虽然它们具备一定的可解释性,且在一定场景下能够实现较高的网络性能,但普遍存在TCP 友好性的问题,同时在某些特定场景下性能表现会出现断崖式下跌。
本文综合已有研究方案,针对轻量级基于学习的拥塞控制算法在某些场景下性能会出现断崖式下跌的问题,提出一个基于场景变化的传输控制协议拥塞控制切换方案。首先,在全场景下分析基于学习的拥塞控制算法的优缺点,着重考察它们在不同场景、维度下的性能指标;然后,提出基于场景变化的传输控制协议拥塞控制切换方案;最后,在网络仿真器3(Network Simulator 3,NS3)平台上进行仿真实验以验证其性能,并将实验结果与已有方法进行对比。
1 相关工作
1.1 轻量级基于学习的拥塞控制
随着传统拥塞控制在吞吐量、时延、丢包率等指标上的表现越来越不符合用户的需求,以及近年来计算机算力的提升与人工智能的重新兴起,许多研究人员开始将机器学习、深度学习和强化学习等基于人工智能的方法应用到拥塞控制研究当中,亦取得了一定的成果。而这其中的主流是轻量级基于学习的拥塞控制,所谓“轻量级”,就是指这其中使用启发式算法、效用函数、梯度下降等未涉及深度学习(包括深度强化学习)的一类拥塞控制算法,这类算法训练时间短、成本低,因而称其“轻”。以下简要叙述使用该类方法的几项研究工作。
1.1.1 PCC和PCC-Vivace
PCC 是一个直接由发送端观测到的性能表现来决定下一时刻动作的算法。每个发送端只观察其动作与性能表现的联系,采用能带来最佳性能的动作。
TCP 硬连接映射需要对网络条件作出假设,但现实网络状况往往比假设复杂得多,且一旦不满足假设,后续的动作对性能非常有害(例如窗口减半)。而PCC 使用实时数据,无任何假设,使用效用函数来描述“高吞吐量和低丢失率”。其收敛速度与TCP 相近,且速率方差更小。
下一时刻的发送速率由效用函数u
决定,u
是关于吞吐量T
和丢包率L
的函数,如式(1)所示: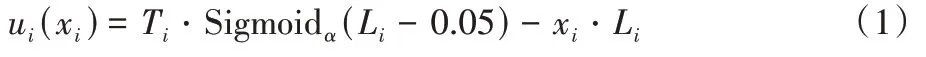
PCC 的控制算法分为以下几种状态:

+ε
)r
,另一个MI 尝试(1-ε
)r
,r
为原始速率。之后速率调整回r
并等待结果。根据u
函数算出的结果,如果两组的(1+ε
)r
都获得较好的u
,则选择之;(1+ε
)r
同理。如果两组结果不同,则速率回到r
并重新进入决策状态并尝试更大的ε
,ε
最小值为0.01,最大值为0.05。3)速率调整状态。决策状态之后得到的速率r
,PCC 会以越来越大的幅度来调整之。若效用函数增大,则采用下一时刻的速率,如式(2)所示: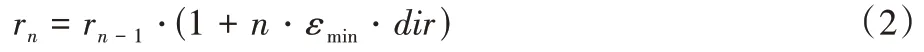
dir
表示±号。一旦效用函数变小,则采用r
并重新进入决策状态。PCC 相较于TCP 的优点:同一个PCC 学习算法可以适应不同的情况,但TCP 不行。从基于延迟变换到基于丢包率,TCP 需要例如active queue management等复杂机制,而PCC只需要修改一行代码而已;PCC 部署时不需要路由器支持、无新协议、不需要接收端的调整,只修改发送端,其余与TCP一致。
PCC 存在的问题主要在于效用函数的选择:是否存在效用函数收敛到纳什均衡同时TCP 友好(TCP 友好性表示该算法能够与传统TCP 流友好共处、公平竞争)。本文中介绍的效用函数都不包含时延,那么包含时延的效用函数是否可被证明收敛并且与默认效用函数表现一样好?这些问题都有待解决。
针对PCC 存在的问题,该研究小组之后又发表了PCC的升级版PCC-Vivace,在新的效用函数中引入了时延:
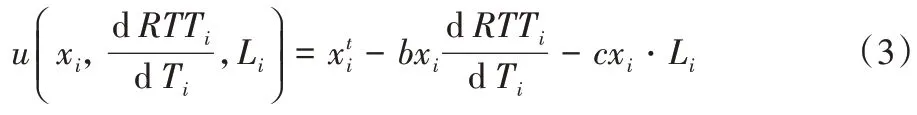
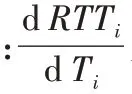
PCC-Vivace 使用了修改后的同样是基于梯度上升的速率调节算法,并证明了其收敛性,也在实验中验证了其TCP友好性。
1.1.2 BBR和Copa
与传统拥塞控制算法显著不同的是,BBR 算法不以数据包丢失或传输时延增加作为识别网络拥塞的标准,而是使用带宽时延乘积(Bandwidth-Delay Product,BDP)作为识别指标,当网络中的数据包总量大于BDP 时,BBR 才认为网络出现了拥塞。因此,BBR 也被恰如其分地称为基于拥塞的拥塞控制算法。
在网络中可以观察到这样的现象:当带宽非常大时,网络将被填满而导致排队,此时网络延迟必定非常大;反之,当网络延迟非常小时,网络中的数据包需要避免排队直接转发,此时带宽必定会非常小。因此可以得出结论:网络中的流不可能同时获得非常大的链路带宽和非常小的网络延迟。根据这一结论,BBR 算法对网络容量进行周期性的探测,对一段时间内链路带宽的极大值和网络延迟的极小值进行交替性的测量,再将它们的乘积作为拥塞窗口大小,从而就能用拥塞窗口来表征网络容量,使拥塞的识别更加准确。
由于BBR 算法特有的测量拥塞窗口的机制,它不会像传统拥塞控制算法那样无限地增加拥塞窗口,也就不会用尽交换机节点的缓存,从而避免了Bufferbloat(缓冲区溢出)现象的出现,进一步就可以让传输时延显著降低。
另一方面,BBR 算法使用通过主动探测网络容量来调节拥塞窗口的机制,此种自主调节的机制使BBR 算法可以自行控制流的发送速率。与之相反的是,传统拥塞控制算法只完成了将拥塞窗口计算出来的工作,而将流的发送速率完全交由TCP 决定,造成的后果便是在当速率接近瓶颈链路带宽时,容易因发送速率的陡增而使得数据包排队或数据包丢失的现象产生。
BBR 算法的缺陷在于:当交换机节点的缓存较大时,BBR 的吞吐量表现可能会逊色于Cubic等相对激进的拥塞控制算法。原因是BBR 算法不会主动去占据节点的缓存,而一旦Cubic 流基于其激进的速率增加策略,长时间占据队列缓存,则很容易导致BBR 算法在邻近的多个周期内所测得的网络延迟的极小值增大,进而导致BBR 流的吞吐量减小。
Copa 算法的整体思路与BBR 类似,都是以端系统采集得到的RTT 信息推测网络状态从而进行速率调整。相较于BBR 其优势在于对链路中队列长度的主动且细粒度的控制,而非基于BDP 的主动排空。
Copa 的核心思想在于,当一个流在链路中产生排队延迟时,给定一个当前拥塞状态下的目标速率λ
,并控制当前速率在该目标上下的一定范围内进行波动。而为了使流在竞争时能同时满足高吞吐量和低延迟,文献[7]对第i
条流给出了目标函数如式(4)所示:
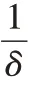

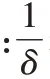
1.1.3 Remy
Winstein 等所探究的问题是:TCP 拥塞控制本身是一个动态的过程,每一步的选择都可能造成后面所有反馈的不同,如何能判定一个拥塞控制是“表现得最好”的?给出的解决办法是:既然人看不出好不好,那就用机器预先算出给定网络里每个决策可能造成的所有后果,选最终评分最高的,将其一路过来的所有决策用来生成一个拥塞控制算法,那肯定就是“表现得最好的”。
因此,Winstein 等设计了Remy 算法来算出不同参数的拥塞控制策略产生的结果,细化较优结果的参数并进行优化,经过几轮迭代后,用生成最优结果的所有决策生成最优拥塞控制(Congestion Control,CC),就是RemyCC。
Remy 的输入包括:网络的参数,即瓶颈链路的速度、网络路径传输时延和多路复用的程度;发送端的流量发送模型,Remy 建模时把流量变化过程看作很多对独立的发送-接收端链路随机开/关的过程,每条链路开的持续时间遵循特定的分布;目标函数,算法的总得分可以通过计算每条流的分数之和得到,链路中不同的数据流获得的分数为:

x
是该流的吞吐量,α
表示公平性的重要程度。在Remy 算法中,公平性被定义为:
y
表示平均RTT;U
(y
)是RTT 的效用函数;系数δ
是平衡系数,作用是改变Remy 算法在吞吐量和时延上的侧重点。文献[7]把发送端观测到的指标用三个参数来表示,统称memory:ack_ewma 表示确认字符(ACKnowledge character,ACK)的到达间隔的指数加权移动平均值;send_ewma 表示ACK 的发送间隔的指数加权移动平均值;rtt_ratio 表示最新RTT 除以最小RTT。
把发送端的action(控制拥塞窗口大小)也用三个参数来表示:m
≥0 表示拥塞窗口的倍数;b
表示拥塞窗口的增量;r
>0 表示连续发送的最小间隔时间。把一条memory 映射到一条action 的过程称为一条rule。一个完整的拥塞控制策略由很多条rule 构成,即一张rule table。Remy 的自动搜索过程就是用贪心算法建立和优化这张rule table 的过程。
以下简要描述Remy 算法的主要过程:首先,通过迭代修正action,找到最合适的将memory 映射到action 的方法,即最合适的rule;其次,将常用的rule 和不常用的rule 进行区分;在合理的统计与分类之后,可以生成一个完整的rule table,即一张统计了所有映射方式的表格,表格中每个rule 的action 都是基于当前网络状态,对拥塞窗口大小进行最优方向上的调整。同时,在最常用的rule 附近,划分粒度非常细,而较不常用的rule 其划分粒度则较粗糙。
Remy 算法存在的问题:用Remy 搜索找到的最佳RemyCC,当把它用于和生成RemyCC 时使用的网络相似的网络上时,效果非常不错;一旦用于不同类型网络时,效果就不太理想了。这是因为RemyCC 只能预测它所见过的网络的最优决策,一旦遇到没见过的网络,RemyCC 仍使用本身的预见方法来应对,就会显得不够灵活。
1.2 基于强化学习的拥塞控制
随着强化学习(Reinforcement Learning)在游戏博弈(围棋、星际争霸)、机器人控制等领域取得卓越成就,有学者开始将强化学习用于网络拥塞控制的研究。近年来,深度强化学 习(Deep Reinforcement Learning),包 含DQN(Deep Q Network)、DDPG(Deep Deterministic Policy Gradient)等算法的出现也为强化学习用于拥塞控制提供了强有力的理论武器。
强化学习用于拥塞控制方面有其先天优势,首先深度强化学习不必依赖于模型,这就增强了其在不可预测行为的复杂网络中的适用性;其次它可以处理复杂的状态空间,这与实际网络的情况十分吻合。
但是,使用强化学习算法也有其缺点,普遍的共性就是训练时间太长,这会导致拥塞控制的开销过大,以至于无法被广泛应用于网络中。此外,在使用深度强化学习这类复杂算法进行拥塞控制时,其收敛性较难保证。
以下简要介绍几项基于强化学习进行网络拥塞控制的工作。
1.2.1 Aurora
Aurora是最早使用强化学习方法进行网络拥塞控制的研究之一,尽管存在着一些不足,其理念仍是具有开创性的。
文献[3]根据拥塞控制的特点设计了强化学习智能体的动作与状态。由于发送端是通过调整发送速率来适应网络拥塞状况,因此智能体的动作也就是发送端的发送速率。状态空间则由三维向量组成,每个向量v
包含延迟梯度、延迟比率、发送比率三个维度。其中,延迟梯度指的是网络延迟关于时间的导数,延迟比率表示当前MI 的平均延迟与此前MI 中观测到的最小平均延迟之比,发送比率表示发送端发送的数据包数量与接收端接收到的数据包数量之比。同时,智能体在决定下一时刻的动作时需要根据过去一段时间的向量来观测网络变化的趋势,因此t
时刻的状态空间s
为: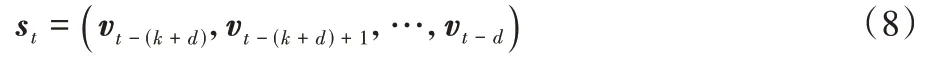
k
是常数,代表过去这段时间的长度;d
表示选择从发送速率到收集到结果的这一小段延时。在k
值的选择上,文献[3]以MI 为单位进行实验,结果表明,除了在只有1 个MI 时算法无法得出理想的奖赏值,其余情况即当采用2 个及以上MI 的训练时长时,算法都能达到相似的理想奖赏值。Aurora 的奖赏函数设计如下:
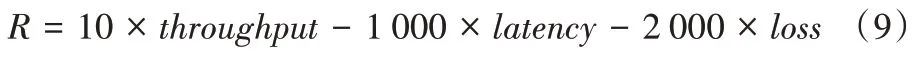
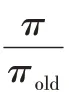
π
得出当前时刻的动作a
(发送速率的增加或减少),从而计算出当前时刻的发送速率x
: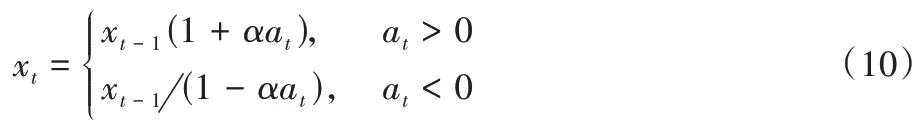
α
是常数,用于减小速率的波动。Aurora 存在的问题主要有:1)公平性差,在与TCP 流进行竞争时,会急剧限制TCP 流的吞吐量,导致算法的TCP 友好性不佳,主要原因在于Aurora 在训练时会主动学习出偶尔丢包的能力,以让TCP 吞吐量下降从而释放链路带宽;2)算法的收敛性较差,即收敛时间过长。
1.2.2 Orca
基于学习的拥塞控制算法适应复杂网络环境的能力更强,因为不需要将环境与动作进行硬编码。但文献[4]认为,单纯的基于学习的拥塞控制也有以下问题:1)在未知的网络条件下有过度(Aurora、PCC-Vivace)或过少(Indigo、Remy)利用带宽的问题;2)收敛到错误的值(Indigo、Remy)或根本不收敛(Aurora);3)开销即中央处理器(Central Processing Unit,CPU)占用率非常高。
因此,文献[4]设计了一个实用的拥塞控制算法框架Orca,将传统拥塞控制的设计与深度强化学习技术结合起来。使用强化学习的原因:网络拥塞控制作为一个顺序的决策制定过程,与强化学习的特性非常吻合。
具体地,Orca 在底层使用传统TCP 调节拥塞窗口的逻辑(文献[4]中选用Cubic),上层的强化学习智能体通过监控获取网络状态和底层传来的拥塞窗口变化,计算出新的拥塞窗口。这样做的好处有:1)能够持续探测带宽并收敛到正确的值;2)因为底层使用传统TCP,其动作调节更具可预测性(相对于深度学习的不可解释性而言);3)能够以更小的开销,即更低的CPU 占用率来达到既定目标;4)相较于其他单纯基于强化学习的拥塞控制算法,其训练速度更快。
Orca 的奖赏函数设计来源于Giessler 等提出的Power指标,Gail 等证明,当Power=Throughput/Delay
取得最大值时,网络拥塞状况达到最优,因而Power
也被广泛应用于衡量网络拥塞的指标,Orca 根据这一指标得出式(11)~(13)所示的奖赏:
ζ
是吞吐量和丢包率的平衡系数,代表二者对总奖赏的影响程度。同时,由于TCP 调节拥塞窗口具有连续的动作空间,Orca 为了减少强化学习中智能体的动作空间,设计新的cwnd
来代替底层TCP 的拥塞窗口cwnd
,并通过式(12)~(14),使得算法可以通过调节α
来调节cwnd
:
π
在当前状态s
下给出动作a
,观测到奖赏r
和新状态s′
,并将这一经验(s
,a
,r
,s′
)存储到Replay Memory 中;Learner 负责更新神经网络模型,每一个迭代中它从Replay Memory 中随机抽取一组经验样本,计算其梯度并更新TD3 算法中的参数。Actor 和Learner 的工作在这里是异步进行的,如此则Learner 对模型的更新不会受阻于Actor(相对于之前的Actor-Critic 架构而言)。实际训练中,将多个Actor 放置于不同的物理服务器中以观测不同的环境,同时将它们连接到一个中心化的Learner,并将Replay Memory 与Learner 放置于同一台物理机上。2 全场景性能分析
本章主要对现有较流行的几种轻量级基于学习的拥塞控制方案在各种场景下的性能进行了测试与结果对比。对照传统拥塞控制方法,分析出各场景下性能较优的拥塞控制方案。
2.1 实验设置与参数
2.1.1 实验设置
本文实验在开源仿真模拟器NS3 平台上进行,在多种带宽、延迟、随机丢包率的场景下,比较吞吐量、时延、公平性、TCP 友好性等性能指标。实验在DELL ECM PowerEdge R840服务器上运行,其CPU 为Intel Xeon Platinum 8168。
实验拓扑为端到端拓扑,在指定的链路带宽和网络延迟下,由发送端向接收端发送一到多条流。默认的数据包大小为100 b。实验运行时长为300 s。
2.1.2 实验参数
实验中使用四种已知的拥塞控制方法,包括三种轻量级基于学习的拥塞控制(BBR、Copa、PCC-Vivace)和作为对比的传统拥塞控制方法Cubic。
实验中使用的网络带宽有1 Mb/s、5 Mb/s、20 Mb/s、100 Mb/s、500 Mb/s;网络延迟的设定有1 ms、10 ms、100 ms、500 ms;实验中使用四种不同的随机丢包率设定:0%、0.1%、0.5%、1%。
2.2 性能分析示例
以下各以一种场景为例,展示考察指标分别为吞吐量、时延、公平性、TCP 友好性时的性能测试结果,并进行分析。
2.2.1 平均吞吐量与时延
表1 展示了链路带宽仍为5 Mb/s,网络延迟100 ms 时各拥塞控制算法的平均吞吐量与平均时延。在该场景下,BBR的平均吞吐量最高,达到了4.87 Mb/s,但相较于另外三者并无明显优势,四者的平均吞吐值非常接近。而在时延方面,时延最高者是Cubic,其时延显著高出其他三者,比时延最低的Copa 算法高出了接近30%,BBR 的时延仅次于Cubic,PCC-Vivace 的时延达到了113 ms;Copa 的平均时延仍最低,约为106 ms。

表1 网络带宽为5 Mb/s 和网络延迟为100 ms时的平均吞吐量与平均时延Tab 1 Average throughput and average delay with network bandwidth of 5 Mb/s and network delay of 100 ms
从实验结果来看,BBR 在绝大多数场景下的平均吞吐量都是领先的,原因在于BBR 的带宽探测机制,可以充分利用链路中的富余带宽;随着随机丢包率的增加,PCC-Vivace 的吞吐量不断下降,原因是PCC-Vivace 在PCC 原始版本的基础上引入了RTT 梯度来表征时延,但对丢包率的系数设置未作改动,因此在随机丢包增加的情况下,为了达到低时延,势必要牺牲吞吐量;Copa 的平均吞吐量在随机丢包0%、0.1%、0.5%时几乎都是最低的;Cubic 的吞吐量较高,总体而言仅次于BBR,但在随机丢包率增加之后,Cubic 的吞吐量急剧下降,原因是Cubic 是基于丢包的拥塞控制,随机丢包会显著影响其对网络状况的判断从而导致性能的下降。
时延方面,BBR 在几乎所有场景下时延都是最高的;PCC-Vivace 在绝大多数时候都是时延最低的,可见效用函数中RTT 梯度的引入是卓有成效的;Cubic 的时延在大多数情况下都较高,反而是在随机丢包率达到1%时,时延明显下降,可能的原因是Cubic 是基于丢包的拥塞控制方法,丢包率对其时延的影响远大于对其他方案的影响;Copa 的时延相对较低,但在均值附近震荡的幅度大。
2.2.2 单一方法多条流的公平性
为了测试同一方案在多条流共存时分享链路带宽的公平性,实验中在0 s、40 s、80 s 时分别发送一条流,考察这三条流最终是否能够均分链路带宽,以及均分带宽并达到收敛的时间长短。
以下以链路带宽为3 Mb/s,网络延迟为100 ms,随机丢包率0.1%为例,简要展示各方案公平性的测试结果。
图1 展示了四种拥塞控制算法的公平性。从图1 中可以看到:BBR(图1(a))的三条流带宽差距较大,无法实现公平性;Copa(图1(c))则实现了公平性;PCC-Vivace(图1(b))在大部分时刻仍能保持公平,个别时段带宽的极差能达到0.8 Mb/s;Cubic(图1(d))三条流的带宽能够收敛到均值,但带宽的波动幅度比Copa 还要高,在均值上下0.25 Mb/s波动。
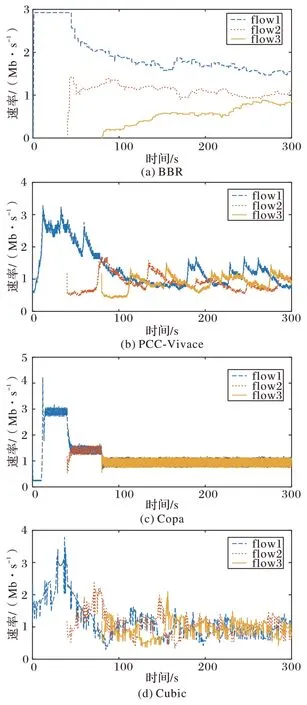
图1 随机丢包率0.1%时各方案的公平性Fig.1 Fairness of each scheme with random packet loss rate of 0.1%
2.2.3 TCP友好性
TCP 友好性,即新的拥塞控制方法在与现有的TCP 拥塞控制方案共存时的性能表现,着重关注其是否挤占TCP 流的带宽,能否与TCP 友好共存。因此,本文通过测试不同拥塞控制方法在与Cubic 竞争时的吞吐量表现来表征其TCP 友好性。
以下以网络延迟1 ms,随机丢包率0%为例,拥塞控制算法以BBR 为例,简要展示其TCP 友好性随带宽变化的结果。
如图2 所示,在随机丢包为0%时,在网络延迟为1 ms 的状况下,在带宽为1 Mb/s 时,BBR 抢占Cubic 带宽的情况非常严重,二者的平均带宽之比约为3∶1,此时BBR 的TCP 友好性较差。而在带宽为5 Mb/s、20 Mb/s、100 Mb/s 时,BBR 与Cubic 能够在链路中友好共存,二者的平均吞吐量之比小于等于1∶1,也就表明BBR 的TCP 友好性较优。
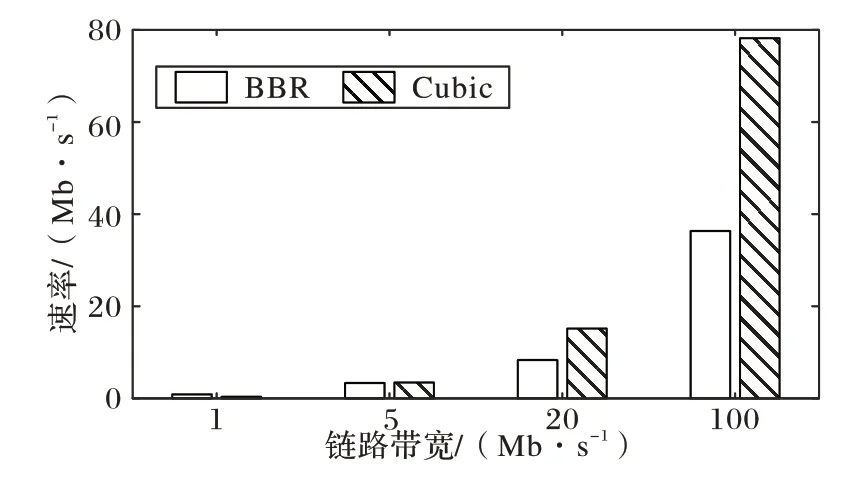
图2 随机丢包率0%时BBR的TCP友好性Fig.2 TCP friendliness of BBR with random packet loss rate of 0%
2.3 性能分析总结
表2~5 简要总结了各类场景下,根据所考察的性能指标的不同,以三种轻量级基于学习的拥塞控制算法(BBR、PCCVivace、Copa)及作为对比的Cubic 为备选项,应选取何种拥塞控制算法,方能在指定场景下达到网络性能的相对最优。
表2 展示了当考察的性能指标为吞吐量时,各场景下所应采用的最优拥塞控制算法。
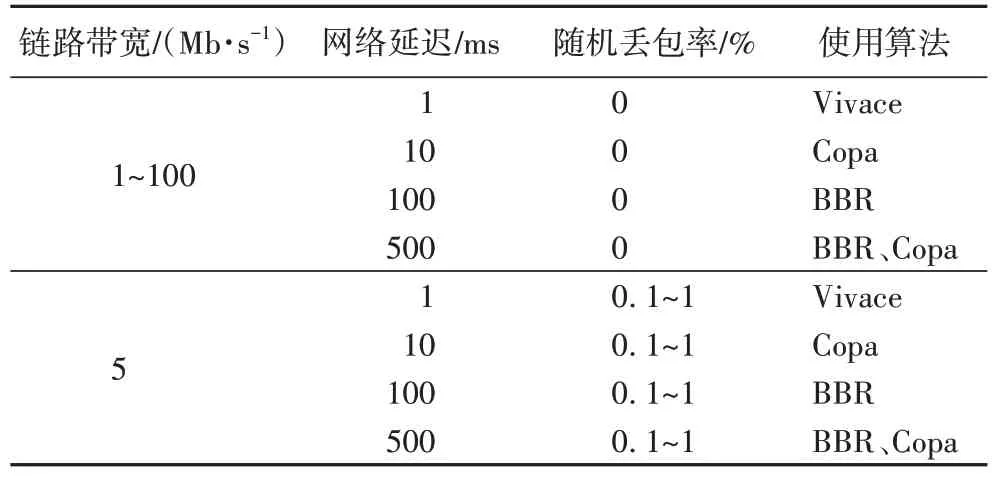
表2 考察吞吐量时的最优拥塞控制算法Tab 2 Optimal congestion control algorithm when focusing on throughput
表3 展示了各场景下所应采用的能使时延最低的拥塞控制算法。其中随机丢包率为0%时列举了所有可能的链路带宽和网络延迟的参数,而随机丢包率为0.1%、0.5%、1%时则以网络延迟10 ms 为代表,列举了所有可能的链路带宽参数。
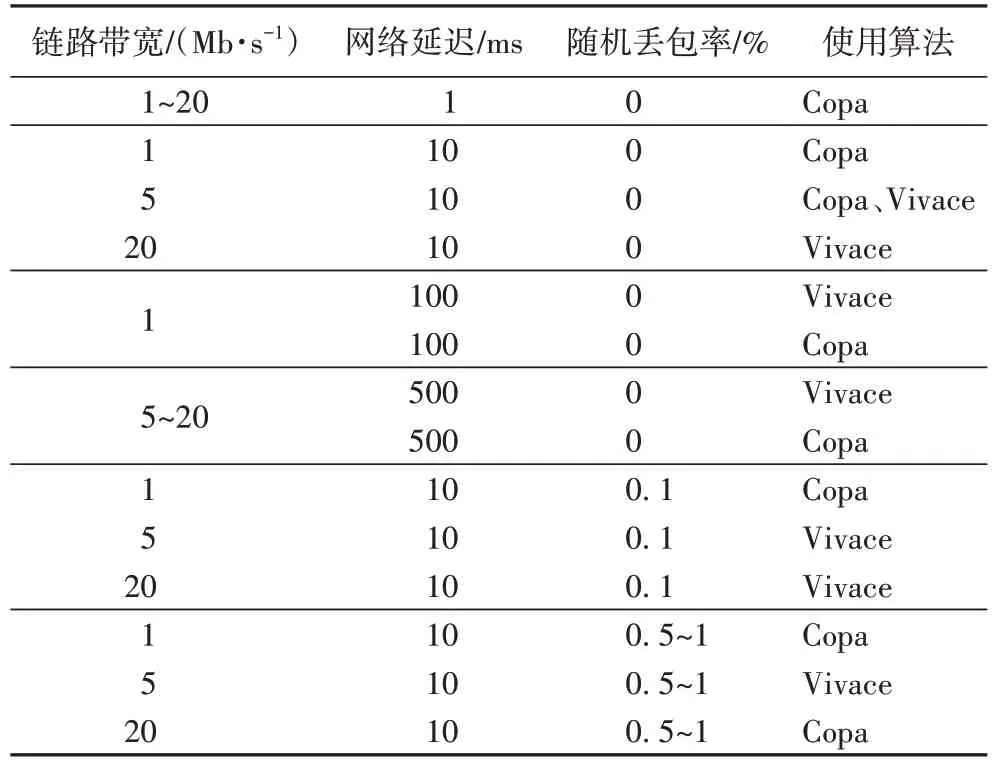
表3 考察时延时的最优拥塞控制算法Tab 3 Optimal congestion control algorithm when focusing on delay
表4 展示了当考察的性能为公平性,各场景下所应采用的拥塞控制算法。其中,网络延迟以100 ms 为代表,列举了所有的链路带宽和随机丢包率的可能参数,其他网络延迟的情况下,最优拥塞控制算法的选择与100 ms 几乎相同。

表4 考察公平性时的最优拥塞控制算法Tab 4 Optimal congestion control algorithm when focusing on fairness
表5 展示了各场景下所应采用的能使TCP 友好性最优的拥塞控制算法。其中网络延迟以1 ms 为代表,列举了所有链路带宽和随机丢包率的可能参数。
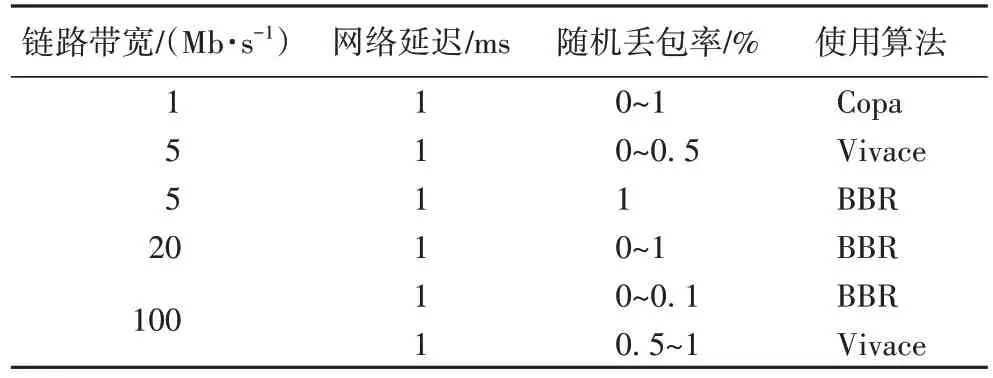
表5 考察TCP友好性时的最优拥塞控制算法Tab 5 Optimal congestion control algorithm when focusing on TCP friendliness
3 本文方案
3.1 设计动机与总览
实际网络环境中,不同应用场景的环境参数差异非常大。例如,在广域网中,网络带宽在100 Mb/s 量级,延迟在40 ms 左右;卫星网络的带宽则只有10 Mb/s 以内,延迟则达到了500 ms;而数据中心的带宽通常达到了100 Gb/s 以上,而延迟则只有1 ms 级别。同时,即使在同一应用下,网络环境参数也可能发生显著的变化。那么,在网络环境不断变化时,如果仍只使用单一的拥塞控制方法,势必网络的性能,例如吞吐量、时延等,会受到极大的影响,因此,必须设计一个能够对网络环境变化进行适应的拥塞控制方案,针对特定的性能指标,能够比原来使用单一拥塞控制方法时有明显的优势。
基于此前章节的分析,各种拥塞控制算法在不同场景下各有优劣,尤其在极端条件下这样的优缺点体现得更为显著,因此本文设计一个根据场景来切换拥塞控制方法的方案。具体地,本文通过对场景指标(带宽、网络延迟、随机丢包率)的识别,选择当前场景下表现较好的拥塞控制方法,而在网络环境发生显著变化时,切换到其他备选的拥塞控制方法,以期实现总体性能的优化;并且,方案还应考虑与链路中的其他流尤其是传统TCP 流友好的共存,根据这一指标对方案进行相应的调整,在兼顾TCP 友好性的情况下实现吞吐量最大化、时延最小化。
3.2 根据环境指标变化量触发场景变换
3.2.1 方案框架
在实际网络环境中,各项环境指标是不断变化的,并且各项指标的变化范围是连续值而非离散值。然而,不能将无数个连续的参数值视为无数个场景,因此,必须要对连续的参数值进行一定的离散化,当环境参数在某个固定的范围内波动时,将其视为同一个场景,而一旦波动超出这个指定的范围,则将其识别为另一个场景,并由此触发拥塞控制方案的切换。
实践中,本文在此前的100 多种实验场景的基础上,为每一个场景的链路带宽和网络延迟设定一个连续的波动范围,当实际网络的带宽与延迟落在范围内时,将其识别为特定的场景,而当系统监测到实时的带宽或延迟超出了指定范围时,根据其所属的新的范围,识别得到下一个场景,并触发拥塞控制方法的切换。
对于实时的带宽和延迟值所应落在的范围,以带宽为例,基于前述实验中各带宽值正好分别间隔约5 倍,考虑将带宽值取以5 为底的对数,当实时带宽落在某两个前述实验带宽值的范围内时,若其超出前一带宽值在一定范围内,则判定为前一带宽值所对应的场景,否则判定为后一带宽值所对应的场景。数学表达式如下:将实时带宽设为B
,前述实验的离散带宽值为B
,B
,…,B
,而B
实际落在了B
与B
之间,即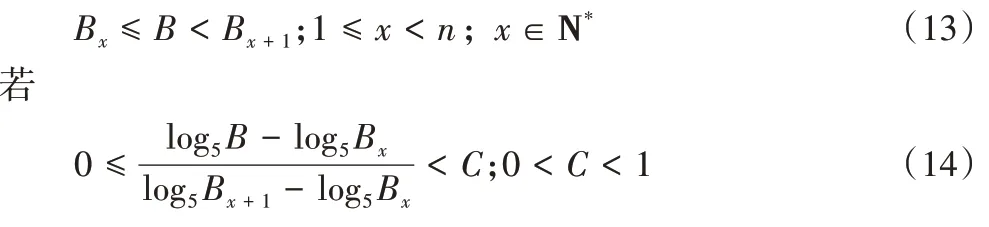
则令

否则有

C
是常数,表示变化的幅度。网络延迟的处理方法与带宽相同,但需要将式(14)中以5 为底的对数改为以10 为底的对数。拥塞控制决策方式如算法1 所示。算法1 拥塞控制算法决策流程。
输入 实时链路带宽B
,实时网络延迟D
,实时随机丢包率L
,阈值C
,带宽档位数n
。输出 决策后的拥塞控制算法。

C
和决策档位数n
输入拥塞控制决策模块。拥塞控制决策模块根据算法1 求出下一时刻的拥塞控制算法,传给流产生模块。流产生模块根据新的拥塞控制算法产生流,并将吞吐量和时延实时回报给系统。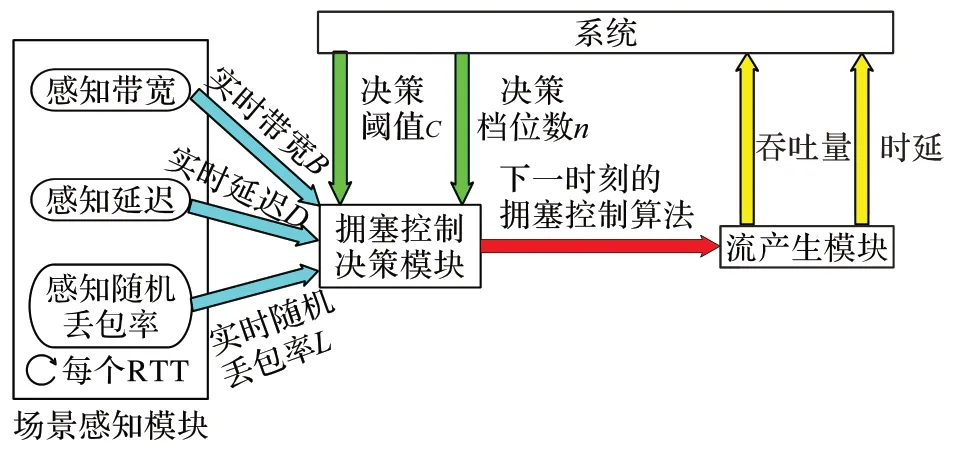
图3 方案架构Fig.3 Scheme architecture
3.2.2 实验设置与结果分析
实验总时长为500 s。设置初始的链路带宽和网络延迟,并设置带宽的变化范围在1 Mb/s~100 Mb/s,延迟的变化范围为1 ms~500 ms,随机丢包率的变化范围为0%~1%。实验中设置对照组与实验组,对照组一直使用初始链路带宽和网络延迟下的最优拥塞控制方法(以下称为原方案),实验组则根据系统实时监测到的当前的链路带宽与网络延迟,确定其所落在的范围来决定所应切换的拥塞控制算法。
具体地,本文进行3 组实验,实验时长均为500 s,每组实验除开始和结束的时刻外,随机生成4 个时刻,当实验进行到这些时刻时,网络环境参数即带宽、延迟和丢包率发生随机的改变,模拟实际网络环境的变化。3 组实验起始的链路带宽都为5 Mb/s,网络延迟都为10 ms,随机丢包率都为0%。在以吞吐量为考察指标时,对照组全程使用Copa 作为拥塞控制算法,而实验组初始状态使用Copa,其后根据网络环境的变化自行切换拥塞控制算法。若以时延为考察指标,则对照组应全程使用PCC-Vivace,实验组同理,初始状态使用PCC-Vivace,之后根据环境进行切换。实验中取式(14)中的常数C
为0.5。实际实验过程中,本文对于3 组实验分别都在0 s~500 s随机生成4 个时刻t
、t
、t
、t
,在这些时刻,网络环境即链路带宽和网络延迟发生随机变化,变化的情况见表6。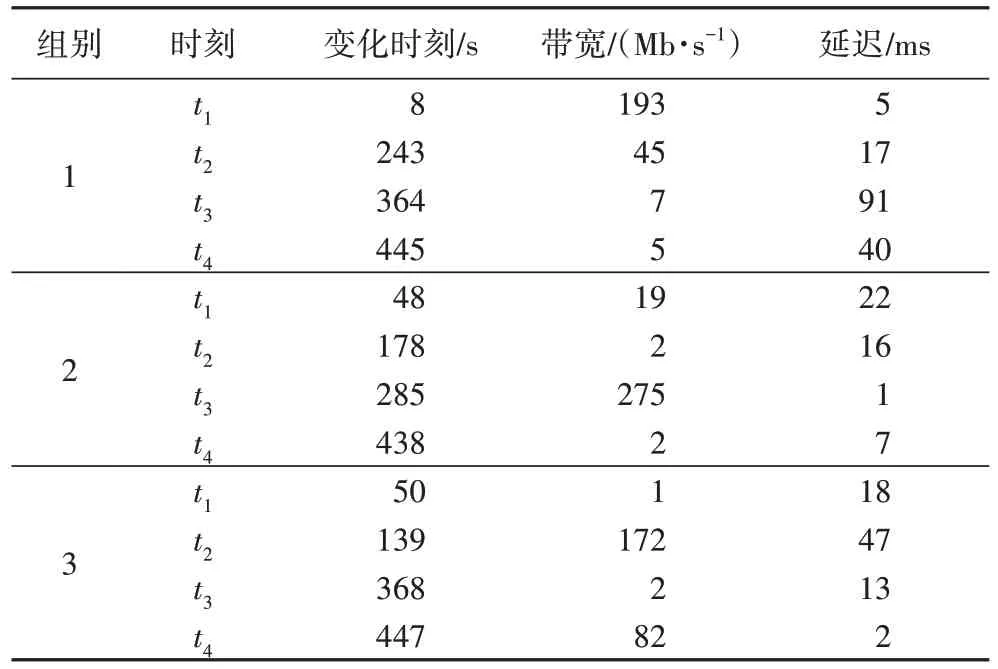
表6 三组实验随机产生的参数Tab 6 Randomly generated parameters in 3 sets of experiments
由表6 和算法1,当考察指标分别为吞吐量和时延时,得到在4 个随机时刻切换到的拥塞控制算法,如表7。
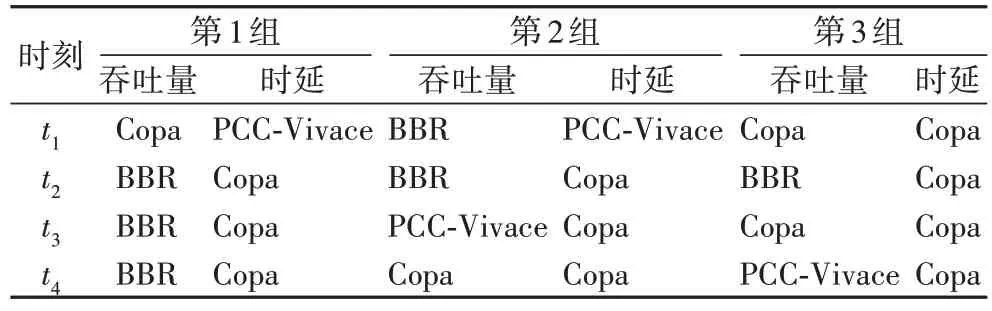
表7 四个随机时刻下3组实验根据环境参数求得的拥塞控制算法Tab 7 Obtained congestion control algorithm based on environmental parameters at 4 random moments in 3 sets of experiments
根据以上随机生成的环境参数和求得应切换的拥塞控制算法,运行实验后得到的结果如下。
图4(a)是第1 组实验以吞吐量为性能指标的实验结果。在8 s、243 s、364 s、445 s 时网络发生变化。从实验结果可以得到,8 s~243 s 这一过程中由于拥塞控制算法没有改变,因此吞吐量没有增加。而在243 s~364 s 时,拥塞控制算法切换为BBR,此过程中本文方案的平均吞吐为44.06 Mb/s,比原方案的43.75 Mb/s 高出了0.7%。此后,在364 s~445 s 这个过程中,本文方案的平均吞吐量达到了6.793 Mb/s,高出原方案的6.681 Mb/s 达16.8%。而在445 s 到实验结束时,本文方案同样取得了更高的平均吞吐量,为4.88 Mb/s,而原方案为4.762 Mb/s。
时延如图4(b)所示,从243 s~364 s 这个过程中,本文方案的平均时延为17.76 ms,比原方案20.73 ms 显著降低了14.3%。此外,在445 s~500 s 这个过程中,本文方案的平均时延也比原方案低了2.01 ms,降幅达4.2%。
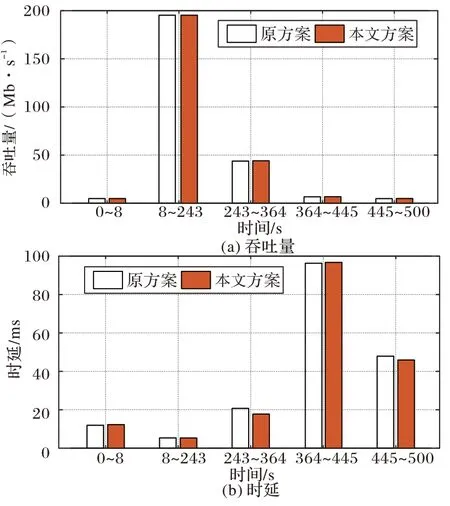
图4 第1组实验中,原方案与本文方案的平均吞吐量和平均时延比较Fig.4 Comparison of average throughput and average delay between original and proposed schemes in experiment 1
图5(a)是第2 组实验以吞吐量为性能指标的实验结果。从实验结果中可以看到,基于场景切换的拥塞控制方案在0 s~178 s 没有显著的优势,但从第178 秒开始取得比原方案更高的吞吐量,尤其是从285 s~438 s 时,本文方案328.9 Mb/s的平均吞吐量比原方案的247.8 Mb/s 高出了32.7%。
图5(b)是第2 组实验以时延为性能指标的实验结果。可以观察到,在178 s~285 s 时,本文方案比原方案的平均时延略增加了10%。但在438 s~500 s 时,基于场景切换的拥塞控制方案的时延有显著降低,从原来的78.3 ms 降为21.18 ms,降幅多达73%。
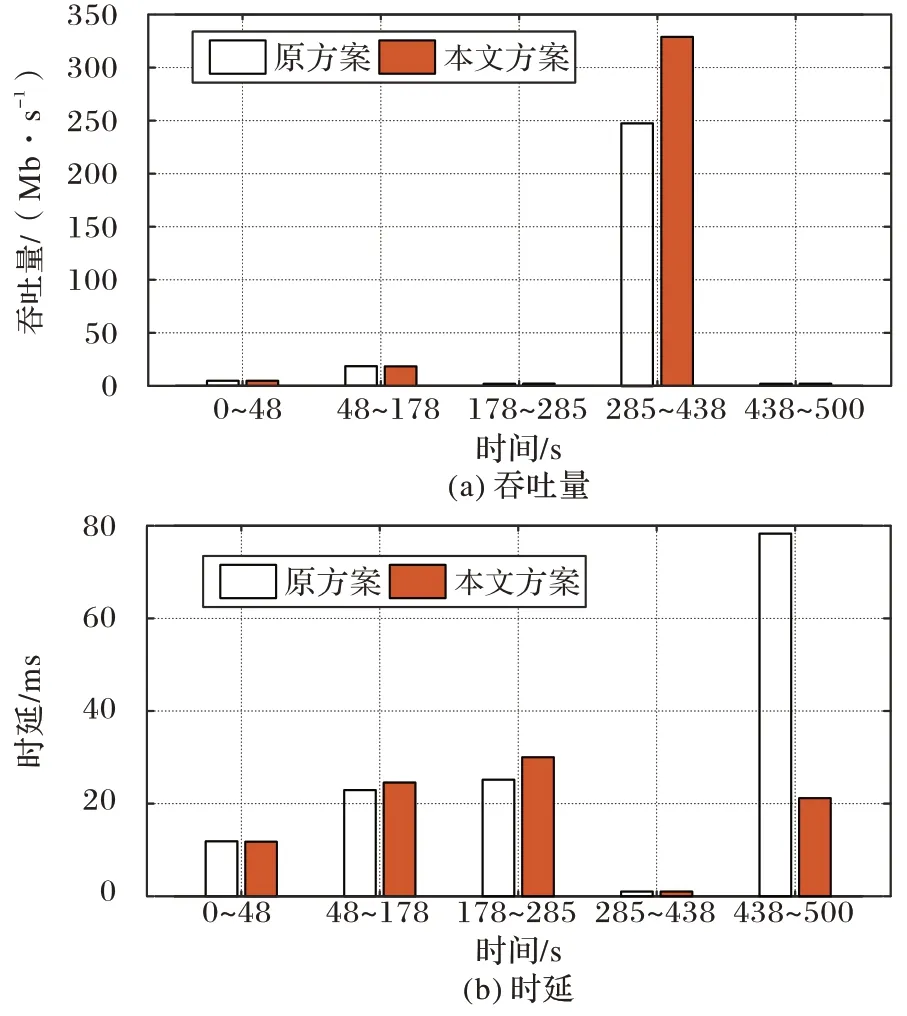
图5 第2组实验中,原方案与本文方案的平均吞吐量和平均时延比较Fig.5 Comparison of average throughput and average delay between original and proposed schemes in experiment 2
如图6(a)所示,在139 s~368 s 这个过程中,本文方案切换到的BBR 取得了167.3 Mb/s 的平均吞吐量,比原方案的161.7 Mb/s 高出了3.5%。但从第447 秒到实验结束的过程中,本文方案使用的PCC-Vivace 的平均吞吐量比原方案略低了8 Mb/s。
如图6(b)所示,基于场景变化的本文方案50 s~447 s 的时延都有显著降低,其中50 s~139 s 这一过程降低的幅度最大,从61.48 ms 降为44.55 ms,降幅达到了27.5%。在139 s~368 s 以及368 s~447 s 的时延降低量分别有10.79 ms 和3.62 ms,降幅分别为18.7%和11.3%。
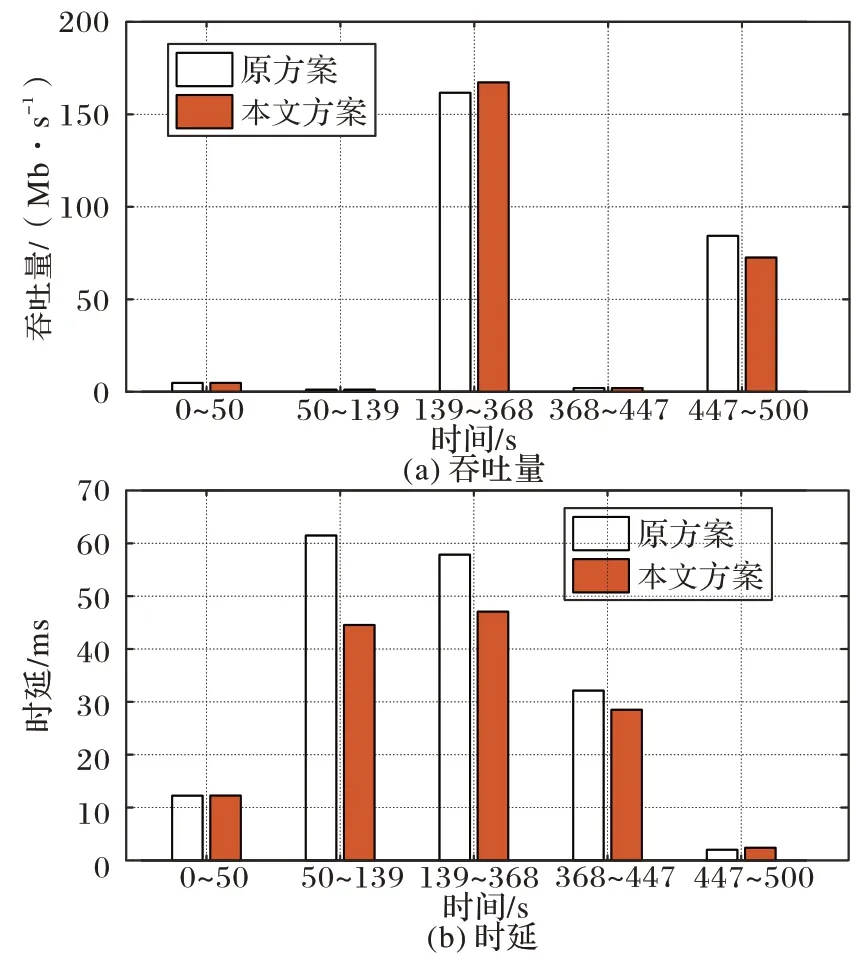
图6 第3组实验中,原方案与本文方案的平均吞吐量和平均时延比较Fig.6 Comparison of average throughput and average delay between original and proposed schemes in experiment 3
从以上实验中可以得出清晰的结论:在网络环境随机变化的情况下,相较于使用单一拥塞控制方案,基于场景变化的拥塞控制切换方案在吞吐量和时延上都能取得明显的性能优势,总吞吐量增幅达到5%以上,总时延降幅达到10%以上。
4 结语
本文的工作主要分为两部分:第一部分,对网络环境参数如链路带宽、网络延迟和随机丢包率等通过枚举组合出多种网络场景,在这些场景下进行大量的仿真实验,得到已有的轻量级基于学习的拥塞控制方案在各场景下的性能表现,性能指标包括方案的吞吐量与时延,同时也考虑方案的公平性与TCP 友好性,并对以上性能表现进行比较与总结;第二部分在第一部分的基础上,提出了一个基于场景变化的拥塞控制切换方案,从固定切换周期单项环境参数的变化、多项环境参数的变化,到根据网络环境参数变化的幅度触发场景的变化,由浅入深地阐述方案的设计思路与实现逻辑,目的是为了逐步模拟实际网络环境的变化情况。系统在识别到场景的变化之后切换至更优的拥塞控制算法,从而取得更佳的性能表现。利用仿真实验对方案的思路进行验证。实验结果表明,基于场景变化的拥塞控制切换方案在网络环境不断变化的情况下,能够比原来使用单一的拥塞控制算法在吞吐量和时延上都取得显著的优势,同时兼顾TCP 友好性。
未来的研究势必要提高对场景识别的精细程度,当前的场景识别相对粗糙,虽然实验中针对每种拥塞控制方案列举的场景超过了100 种,但仍然是许多离散值,需要对实际网络的场景进行近似之后方能采用本文提出的拥塞控制切换方案。而实际网络环境的场景指标都是连续值,其多样化程度必然超出了实验所列举的范围,因而必须要提高场景识别的精细程度,使其能够更真实地反映实际网络状况。特别地,场景与拥塞控制方案之间的映射关系也是值得重新思考的。同时,随着强化学习技术的不断发展,当其训练的时间成本与应用上的开销下降到可接受范围内时,必然要将强化学习的拥塞控制方案加入到备选方案中,届时切换方案的成本和难度也会相应增加,而这也是需要努力的方向之一。
