
基于标签分层延深建模的企业画像构建方法
2022-05-07 07:07丁行硕
计算机应用 2022年4期
丁行硕,李 翔*,谢 乾
(1.淮阴工学院计算机与软件工程学院,江苏淮安 223003;2.江苏卓易信息科技股份有限公司,江苏宜兴 214200;3.南京百敖软件有限公司,南京 210032)
0 引言
近年来,随着知识图谱与大数据的快速发展,画像技术受到工业界和学术界广泛的关注。目前比较流行的企业画像在电子商务、风险评估、市场监管等方面有着广泛的应用,其网站不仅具备传统门户网站的信息服务功能,还能提供许多与标签相关的服务如热点分析和企业推荐等。作为一种新型的画像技术应用,企业画像中不仅包含大量企业、位置等多模实体,还拥有大量的异质关系和文本特征,比如企业位置关系、企业竞争合作关系以及企业研究者发表的论文专利关系。企业画像的实质是基于企业结构化和半结构数据,抽取出标签化的企业模型,这些大量数据混合在一起形成了非常复杂的结构特征。
企业文本是企业向社会展示企业基本信息和综合实力的载体。通过画像技术对不同维度信息筛选整合,以不同的形式向企业、政府提供服务。在企业画像中,标签体系建设是画像研究的重要部分,是通过企业基础的统计类标签,以及行为产生的规则类标签,最后是数据挖掘产生的挖掘类标签共同构建而成。然而,由于大量不同维度企业信息过于杂乱,导致信息处理、标签提取等任务难度较大,因此标签建模的合理性以及标签抽取的精确程度直接影响到画像的表达能力及画像应用效果。目前,在传统的标签建模领域已有许多成果,总体上看,现阶段主流的标签建模方法大致有3 种:基于传统模式的方法、基于机器学习的方法和基于神经网络的方法等。一方面,这些方法虽然能准确地发现文本标签,但都存在的问题是仅适用于同一实体或单一关系,特别是对于企业文本这种既有多模实体,又有因多维度实体形成的异质关系,比如企业在行为空间活跃形成发展趋势主题,还在结构空间由多源信息形成趋势点,上述标签建模方法显然无法有效地融合多维实体和异质关系;另一方面,信息的多样性给数据处理、分析带来挑战,在传统标签建模过程中易出现模糊标签集合,但较少有学者关注于企业模糊标签特点,例如批发业、零售业等无法完整概括企业特点的标签。自然语言处理(Natural Language Processing,NLP)和数据挖掘能够从非结构化数据中得到具有高度概括能力的标签,并呈现语义化和短文本两个主要特征,为标签建模提供新的思路,但这些方法仍未能准确、真实反映企业特点和关联性。因此,为了更好地对复杂信息标签建模,多源信息融合与NLP 相结合成为新的标签建模方式。
本文针对以上问题提出了一种基于标签分层延深建模的企业画像构建方法EPLLD(Enterprise Portrait of Label Layering and Deepening)。首先,基于企业画像指标体系建立模糊标签指标体系;然后,阐述模糊标签处理和EPLLD 建模的过程;最后,以企业信息文本作为实验数据,根据实验结果分析EPLLD 的优势以及未来工作。概括来看,本文的主要工作如下:
1)提出了一种基于标签分层延深建模的企业画像构建方法,该方法对模糊标签进行模糊标签延深,然后使用关键词提取实现标签分层延深建模,可以形象展示企业特点。
2)以企业标签指标体系为基线,建立企业模糊标签指标体系,由此展示模糊标签在画像维度上的分布与规律。
3)本文使用特征融合的方法对多源文本进行向量拼接,并充分利用BERT(Bidirectional Encoder Representation from Transformers)语言模型和深度学习抽取企业文本的多特征信息,最后通过TF-IDF(Term Frequency-Inverse Document Frequency)、TextRank、隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型进行标签抽取。在真实企业数据集上的实验结果表明本文所提的EPLLD 方法在标签延深和标签体系结构上都具有最好的表示效果。
1 相关工作
现有画像技术研究工作主要有三大类:面向应用画像的研究发现、面向标签体系建设的研究发现以及面向NLP 的标签建模。
在面向应用画像的研究发现中,大多数的画像研究都是基于用户画像而产生,Alan 在1999 年提出Persona 的概念,它是一种建立在真实数据之上的目标用户模型,被作为一种交互设计工具;2006 年Chun 等提出了Corporate Character Scale的相关概念,讨论了Agreeableness、Competence、Enterprise、Ruthlessness、Chic 五个主要维度和Informality、Machismo 两个次要维度,用于评估企业声誉对员工和客户的影响;2015 年Maťová 等在Corporate Character Scale 的概念上进行扩展,仍使用七个维度标签对两个著名零售企业进行调查,分析和揭示它们的企业形象;2019 年杨沛安等将画像技术应用于网络安全,通过分析威胁情报从而提高网络攻击识别的效率与准确性;2021 年李晓敏等通过了解用户认知需求以及用户画像在图书馆的应用实践,提出了一种面向用户认知需求的图书馆用户画像推荐模型,促进了用户画像的构建与完善。
在面向标签体系建设的研究发现中,其关键问题是如何有效地融合多模实体和多维关系。刘海鸥等对用户画像研究成果进行细致的梳理,揭示了用户画像建模的不同方法,总结出了各类建模方法的特点与发展趋势;Che 等对多标签任务中的标签相关性进行了深入研究,并提出了一种新 的FL-MLC(Feature distribution-based Label correlation in Multi-Label Classification)方法,描述特征变量和标签变量之间的关系;Lin 等提出了一种消费者需求标签提取方法,将电子口碑与信息技术结合在一起,提高企业市场竞争力。从已有的研究成果来看,标签体系建设又可分为两种维度:一种是使用标签分类建设标签体系,例如Pan 等提出了一种社交标签扩展模型,利用标签之间的关系扩展标签,缓解标签稀疏问题;黄晓斌等融合多源数据进行企业竞争对手画像构建,通过整合数据类型和增加权重,使用多种聚类算法对企业进行竞争者推荐;另一种是标签分层建设标签体系,标签分层因具有高效、具体化优势,逐渐受到研究者们的广泛关注。例如An 等使用交互式设计技术,基于对社交媒体数据的自动分析,实现了对画像内容的层次性更新;Zhang 等利用数据驱动构建画像,提出了一种从下至上的定量数据驱动方法,并结合混合模型更新画像内容。此外,还可以通过融合结构信息进行特征扩展,提高标签准确率。
在面向NLP 的标签建模中,研究者通常会采用NLP 来发现企业文本的隐藏特征,而传统的文本处理方法会导致文本特征稀疏和语义敏感等问题。为更精准地建立全方面、多维度的企业画像,多源信息融合为企业画像构建提供了新的思路,神经网络依据出色的自适应和实时学习特点成为画像构建的常用方法,关键词提取因其适应性强广泛应用于画像标签构建。Mikolov 等提出Word2Vec 证明了在向量空间中单词表示的有效性;Pennington 等和Peters 等提出的全局向量(Global Vectors,GloVe)和 ELMo(Embeddings from Language Models)取得了很大成功,解决了Word2Vec 只考虑词的局部特征问题;Du 等提出了一种多级用户画像模型,通过集成标签和评分来实现个性化推荐,反映用户的喜好特点。在关键词提取中,能把非结构化文本中包含的信息进行结构化处理,并将提取的信息以统一形式集成在一起。有监督的关键词提取精度高,需大量标注数据,人工成本过高,无监督提取应用广泛,有基于统计特征的TF-IDF 算法、基于词图模型的TextRank 算法和基于主题的LDA 主题模型算法等。不同类型文本中,同一算法应用效果存在差异,因此组合算法的应用弥补了单算法不足。
综上可知,目前学者研究中,基于机器学习模型和深度学习模型的标签抽取、标签分类任务已经取得了很高的成就,但较少有学者关注企业模糊标签特点,建立自上而下的标签分层延深建模体系。虽然已有一些研究尝试采用集成方法来融合多维信息,但这些方法都存在局限性,有些方法忽略了多源文本的交互关系或关联性,而另一些方法则无法充分发现企业文本特征,容易丢失重要信息。针对标签体系建设特别是标签建模中存在的标签概括能力差、模糊标签处理难、标签提取不合理等问题,本文结合数据特点和企业特性来规约数据实体,依据企业领域专业术语进行企业词库特征拓展,提出了一种EPLLD 方法。首先,利用分布式爬虫爬取企业信息并进行数据清洗,标注和构建企业标签、词库,对企业模糊标签进行统计和筛选,筛选出如批发业、零售业等不能完整概括企业特点的标签信息;接着,通过对各企业类别、标签等要素分析进行多源信息融合,并将整合后的特征信息使用BERT 语言模型进行字嵌入表示,利用注意力(Attention)机制发现文本信息长距离依赖关系;然后,将处理后的向量序列传入双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络,依据企业特征信息和企业标签进行模糊标签延深;最后,使用综合抽取算法从多特征信息中提取关键词,将处理后的关键词作为更深层的企业延深标签。EPLLD 方法能够挖掘深层次的标签信息,并进行由浅入深的标签体系构建,从而解决企业标签建模难度大和标签分层效果差等问题。
2 标签分层延深建模的企业画像构建模式
2.1 相关概念及形式化描述
标签体系建设是企业画像建设中的基本任务,本文以企业数据指标体系为基线,建立企业模糊标签指标体系,通过EPLLD 实现模糊标签的自动延深。即结构化标签无法概括企业特点,从企业网络文本提取具有实际意义的标签来表示企业形象。
相较于基线体系,企业模糊标签指标体系在标签的类型划分和模糊标签的处理上有很大改变。本文依据标签抽取方法的不同来划分标签类型,该指标体系能够对处理方法相同的企业数据进行数据分群,从而有效筛选和处理模糊标签,企业模糊标签指标体系如表1 所示,共包含三种标签类型:1)统计类标签,包括基本信息、科研信息以及其他信息;2)规则类标签,包含企业规模、企业价值以及风险等级;3)挖掘类标签,包含企业需求、企业特点等,其中x
、y
为二级标签。第二类中的规则类标签抽取主要为统计学方法,能够避免模糊标签出现,而统计类和挖掘类标签中的结构化数据易出现标签表达不明确的现象,本方法对其进行了模糊标记。同时,本文针对二级指标的直观表达展开研究,依据数据的差异对一级指标和二级指标进行微调。
表1 模糊标签指标体系Tab 1 Fuzzy label index system
基于模糊标签指标体系存在的相关问题,本文建立的企业标签分层延深模型如图1所示。分为以下三部分:1)基于多源异构分布式爬虫获取企业网络文本,并对内部数据和网络文本进行数据清洗,包括去重、去空以及缺失值填补等;2)使用特征融合的方法进行向量拼接,将多源企业信息融合为多特征语料,基于融合的多特征语料进行特征抽取,将抽取的隐藏特征传入BiLSTM获取模糊标签延深结果;3)结合模糊标签延深信息实现进一步的标签抽取延深,完成EPLLD建模。
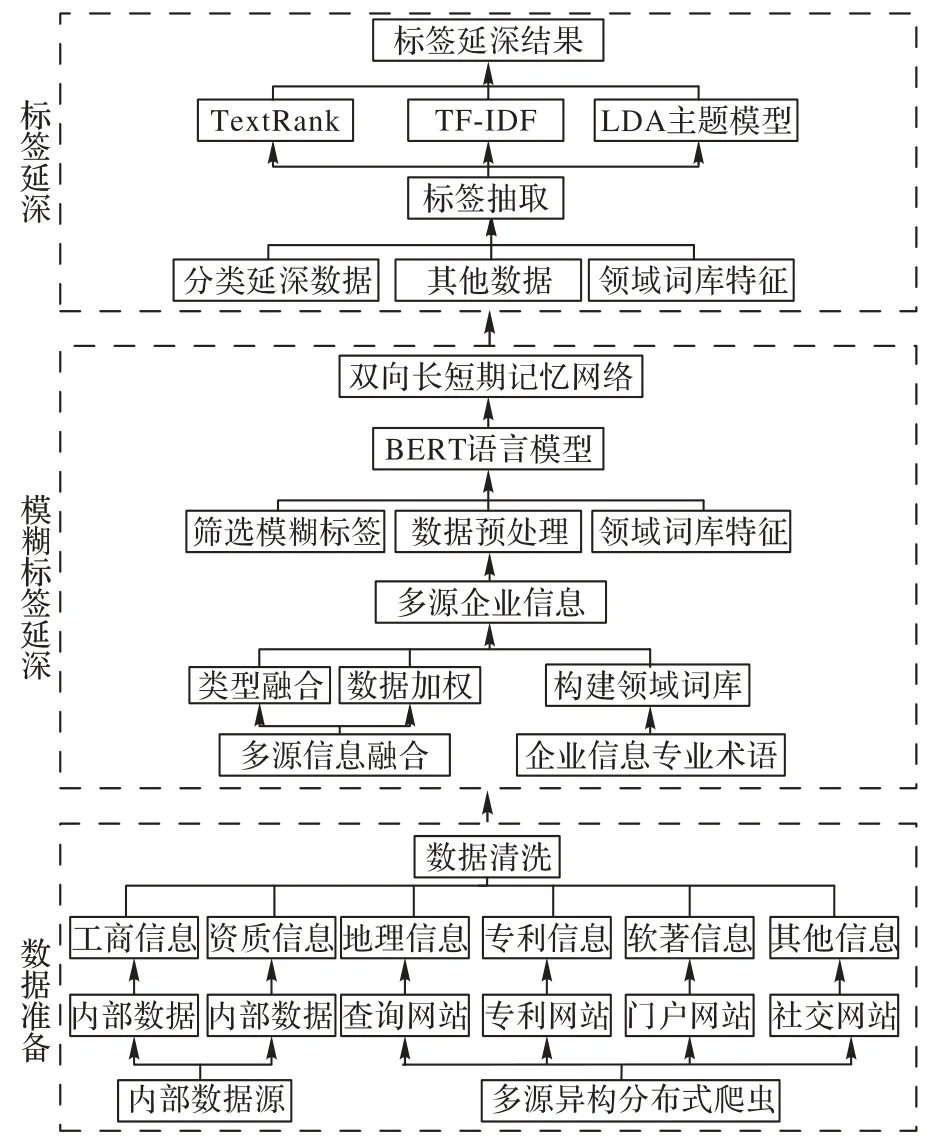
图1 EPLLD建模过程Fig.1 EPLLD modeling process
2.2 数据准备
在明确企业画像指标体系后,进一步获取各指标数据。获取指标数据的方式主要分为两种:一种是通过企业内部数据源得到企业基本信息、企业资质信息和企业交易数据等;另一种是通过分布式爬虫爬取各信息网站中的网络文本,间接获得如专利信息、招聘信息和企业评价信息等。本文结合两种方法获得指标数据,首先从企业内部得到企业核心数据;其次使用Scrapy 爬虫框架建立分布式爬虫,从社交平台、招聘网站和门户网站等进一步得到指标数据。
获取各维度的指标数据后,对其进行数据清洗,本文数据清洗包含:重复数据的检测及消除、缺失数据的统计及填补以及异常值的筛选和清理。
2.3 模糊标签延深中的特征抽取
特征抽取是NLP 中的基本任务,特征抽取直接影响到EPLLD 建模的质量,也是EPLLD 建模的核心内容。由于中文语言无法用空格直接分词,因此数据预处理的方式会对模型结果产生关键影响。为寻找更多特征信息,本文基于多源信息融合,使用企业名称、经营范围等信息,通过特征融合方法对不同的数据类型进行向量拼接,对其赋予权重后提炼多特征企业信息,并构建领域专业词库处理词嵌入和保证分词效果。例如,某商贸企业的名称中通常含有企业偏好和特点的词语,使用本方法将其向量化后乘以权重并与经营范围的特征向量进行拼接,让后续的网络层对参数之间的联系进行自适应调整。然后引入BERT 模型依据待处理文本内容,抽取出潜在特征,得到向量序列S
=T
,T
,…,T
,其中n
为字向量序列长度,将此向量表示作为深度神经网络的输入。BERT 模型是基于双向Transformer 编码器构建的语言模型,能够发现词语间的相互关系,此过程如图2 所示。Transformer 是由编码器和解码器堆叠而成,在经过6 个编码器处理后在传入6 个解码器进行解码。而编码器和解码器的核心是注意力机制,它能聚焦句子中的关键点,并整合到Value 上,从而计算其价值。通过不断进行这样的注意力机制层和非线性层交叠来得到最终的文本表达,更容易地捕获长距离依赖信息。
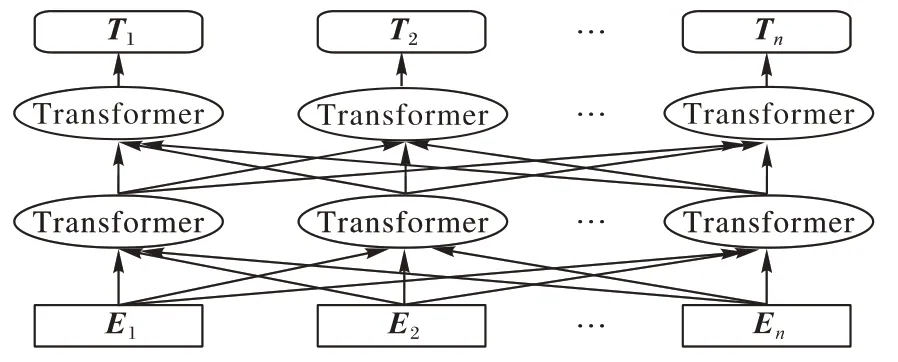
图2 BERT语言模型Fig.2 BERT language model
注意力机制的定义如式(1)所示,其计算流程如图3所示:
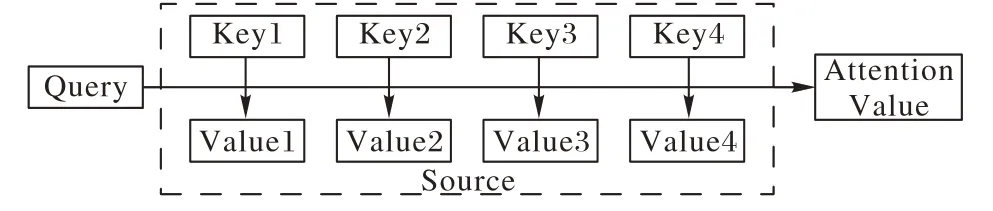
图3 Attention计算流程Fig.3 Attention calculation flow
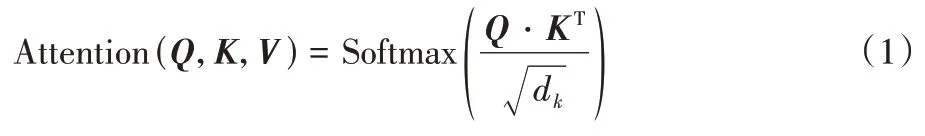
d
为向量的维度,Q
、K
、V
为输入的字向量矩阵。此语言模型将两个单词直接计算并将其相互联系,通过将所有单词表示加权求和,缩短特征间距离,提高特征的有效利用率。2.4 模糊标签延深中的BiLSTM
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相较于一般的神经网络模型,能够有效处理序列变化的数据。LSTM 是一种特殊的RNN,LSTM 的提出解决了普通RNN 在训练过程中出现的梯度消失和梯度爆炸问题。LSTM 通过简单的网络结构,使用门控机制保留序列中的长期信息,引入遗忘门、输入门、输出门3 个门控单元,来实现模型的有效训练。
本文采用LSTM 处理文本多特征向量信息,其内部结构如图4 所示。图4中,σ
是为Sigmoid 激励函数;C
表示细胞状态;h
表示隐藏层状态;x
表示t
时刻网络输入。在LSTM 网络中,f
、i
、o
分别表示遗忘门、输入门和输出门,W
和b
分别表示权重矩阵和偏置项,LSTM 网络首先需要计算它的遗忘程度,即将t
时刻的记忆状态乘以一个记忆衰减系数f
,衰减系数f
是根据t
时刻网络输入x
和t
-1 时刻的网络输入f
所决定,定义如式(2)所示: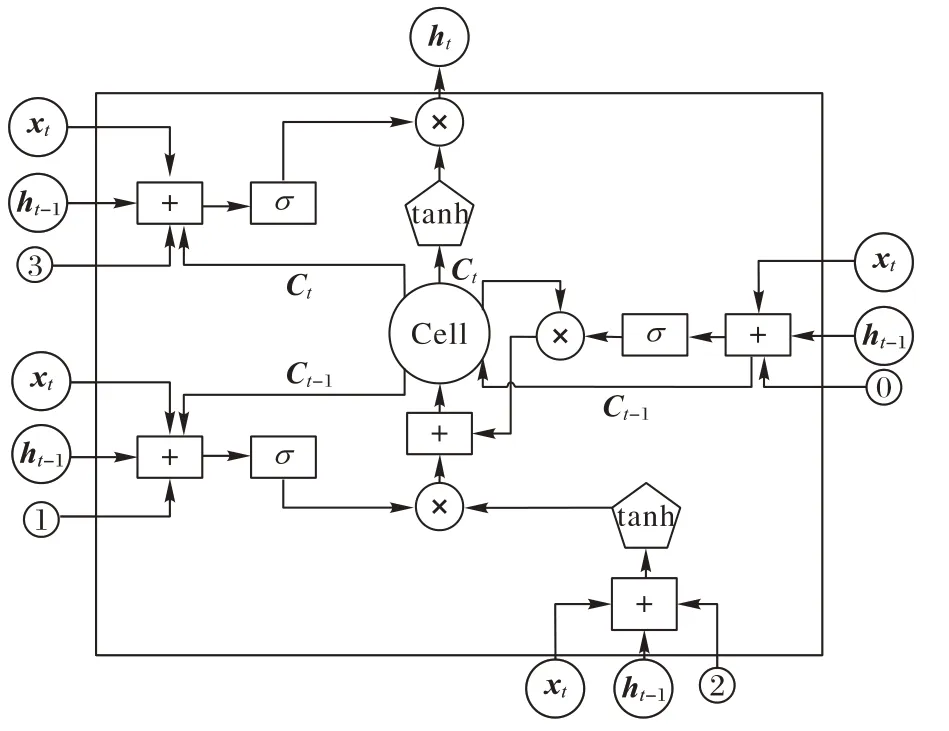
图4 LSTM结构Fig.4 LSTM structure

i
,它是由t
-1 时刻的h
和t
时刻的x
所决定,定义如式(3)所示:
t
时刻记忆C
ˉ是经过线性变换所得到,它也是由t
-1 时刻的h
和t
时刻的x
所决定,定义如式(4)所示: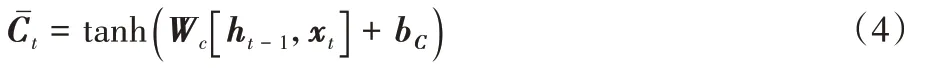
t
时刻的新记忆乘以衰减系数i
得到此时刻的学习记忆,然后计算保留的t
-1 时刻记忆f
*C
,将两者相加作为t
时刻的记忆状态,定义如式(5)所示:
t
-1 时刻的h
和t
时刻网络输入中的x
计算输出门o
,定义如式(6)所示:
最终网络经过tanh 转化并输出结果,由式(7)所计算:

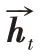

ω
、υ
、b
分别为正向输出权重矩阵、反向输出权重矩阵和偏置。2.5 模糊标签延深
在标签体系构建中,经常会得到不能完整表示企业形象的模糊标签,而较少有学者关注模糊标签的规范表示。本文设计了一种模糊标签延深算法(Fuzzy Label Deepening Algorithm),在基于多源信息融合和专业领域词库的多特征选择上,使用BiLSTM 网络并添加注意力机制,得到企业的延深标签信息。模糊标签延深结构如图5 所示。
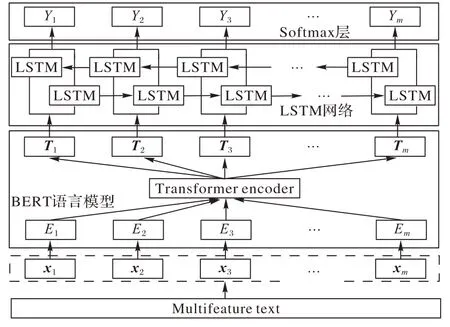
图5 模糊标签延深结构Fig.5 Fuzzy label deepening structure
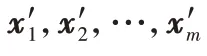
算法1 模糊标签延深算法。
输入 字向量特征表示x
,x
,…,x
,BiLSTM 网络参数。输出 模糊标签延深序列Y
,Y
,…,Y
。待处理文本固定为统一长度L
令i
=1,依据统一长度进行向量标准化通过符号分割得到融合全文语义信息的向量表示T
,T
,…,T
通过式(1)对向量进行编码和解码
REPEAT
通过式(2)传入h
和x
计算遗忘门f
值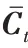
C
通过式(6)~(7)计算输出门o
和正向输出结果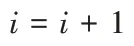
通过式(9)进行反向编码
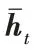
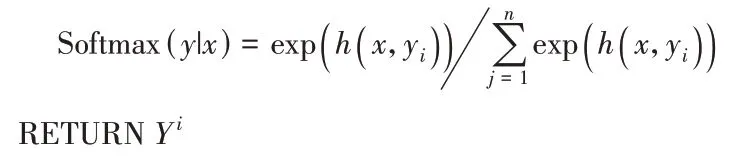
2.6 标签延深
标签延深是基于已获得的模糊标签以及构建的领域词库,使用综合提取算法对多特征信息提取关键词汇。在关键词提取任务中,不同算法的提取结果存在明显差异,因此综合提取算法能够弥补单一算法的不足。本文使用基于统计特征的TF-IDF 算法、基于词图模型的TextRank 算法和基于主题的LDA 主题模型算法建立标签延深模型;然后,依据需求定义单个标签提取数量N
,让待延深文本依次传入三种算法抽取标签,从不同维度获取企业核心词汇;最后,对抽取到的标签进行划分,相同标签作为标签延深的重要标签,其余标签作为重要的补充标签,实现EPPLD 建模,其中label_number
≤3N
,label_number
为标签延深后的标签数量。通过多算法综合提取,能够发现文本的特征与联系,使得整个模型获得更好的效果。同时综合提取算法主要面向企业经营范围和专利等信息进行提取,这些信息一般具有较强的企业特点和兴趣偏好,因此延深后的标签可以避免模糊标签情况出现。3 实验与结果分析
3.1 实验数据
实验数据本文使用行业网站收集的企业文本作为实验数据,由于没有现有的公共数据集,本文构建了企业网络文本数据集,数据集公开地址:https://github.com/Dingxingshuo/Corporate-portrait,其中包含244 890 篇企业文档,共1 682 万个汉字。使用2 880 条中英文企业领域关键词进行特征扩展。将244 890 篇企业文档以6∶2∶2 的比例分为训练集、验证集和测试集,数据描述如表2 所示。
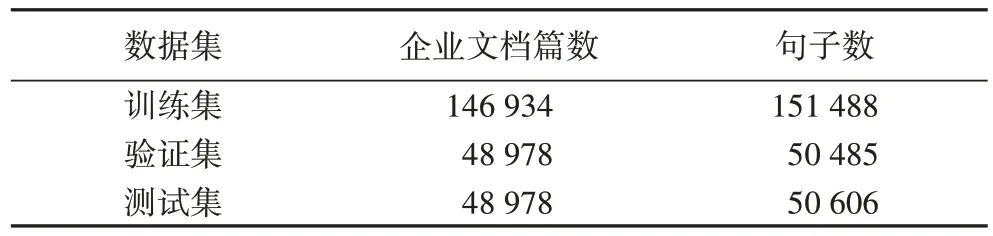
表2 实验数据集详细信息Tab 2 Detail information of experimental datasets
3.2 评价指标
为了验证本模型实用性,本文使用准确率(Acc
)、精确率(P
)、召回率(R
)和F
1_
score 来评价模型效果。准确率是文本问题中最基本的评价指标;精确率是预测正确的数据量与被预测为正确的数据量之比,衡量的是查准率;召回率是预测为正确的数据量与实际类别为正确的数据量之比,衡量的是查全率;F
1_
score 是精确率和召回率的调和平均数。各个评价指标的计算公式如式(11)~(14)所示: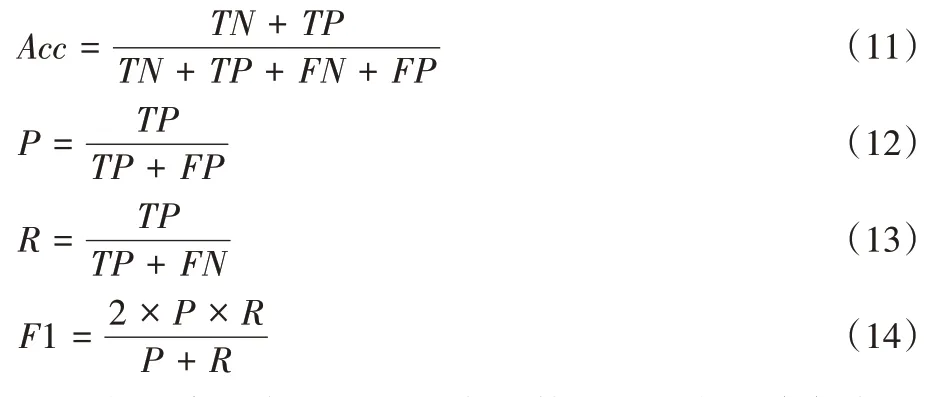
TP
表示将正类预测为正类的数量;TN
表示将负类预测为负类的数量;FP
表示将负类预测为正类的数量;FN
表示将正类预测为负类的数量。3.3 实验与结果分析
实验使用百分比表示本文模型的延深结果,通过对2 880 条中英文企业领域关键词进行特征扩展,以BiLSTM 为基线加入特征提取算法进行测试,模型通过多特征提取随机生成向量作为神经网络模型的输入,所有模型若超过1 000 batch 效果没有提升,则提前结束模型训练。
为了验证模型的优越性,将本文所提EPLLD 与传统标签构建算法K 近邻(K-NearestNeighbor,KNN)、朴素贝叶斯分类器(Naive Bayesian Classifier,NBC)、卷积神经网络(Convolutional Neural Network,CNN)、Deep CNN、BiGRU(Bidirectional Gated Recurrent Unit)、RNN+CNN、BiLSTM+Attention 和BERT+Deep CNN 在企业数据集上分别进行实验,实验结果如表3 所示。相较于其他标签处理的机器学习和神经网络模型,EPLLD 的结果最好。EPLLD 的F1_score 值达到91.08%,高于其他机器学习和深度学习模型。
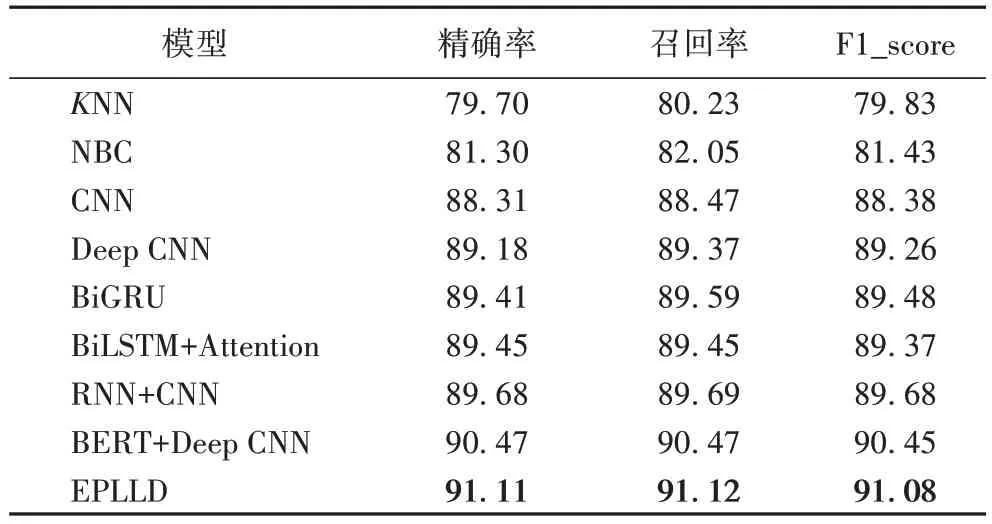
表3 对比实验结果 单位:%Tab 3 Comparative experimental results unit:%
为直观表示各模型优劣,挑选传统深度学习模型使用验证集进行迭代测试,结果如图6 所示。由图6 可以看出,随着迭代次数的增加,所有模型损失值都在减小,损失值的大小表明模型训练中的收敛情况。EPLLD 模型使用双向Transformer 生成特征向量传入神经网络不仅能够获得字嵌入特征,还能够发现文本的层级特征和上下文特征,因此可以在较少的迭代中实现较好的收敛效果,而其他模型在EPLLD模型收敛后损失值依旧波动较大,易出现过拟合的情况。
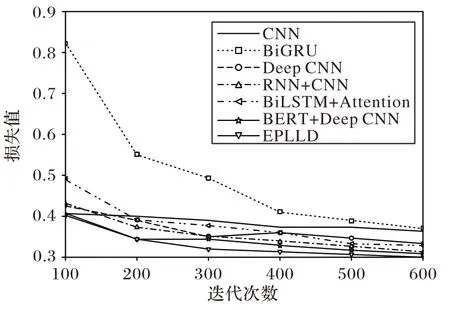
图6 验证集损失值变化曲线Fig.6 Validation set loss value change curve
同时,挑选不同维度的4 种模型:能够发现局部特征的Deep CNN 模型,发现上下文特征并聚焦关键点的BiLSTM+Attention 模型,发现上下文特征后在池化层进行最大池化的RNN+CNN 模型,以及多特征融合的EPLLD 模型,记录4 种模型验证集在每轮epoch 后的准确率变化,结果如图7 所示。由图7 可以看出,EPLLD 从第一轮迭代开始,准确率明显高于其他模型,且在第二轮后准确率一直稳定在90%以上。由此可见,双向transformer 具备更强的学习能力,能够发现长距离依赖关系和企业文本中的隐藏特征,说明EPLLD 方法对企业模糊标签延深的有效性。
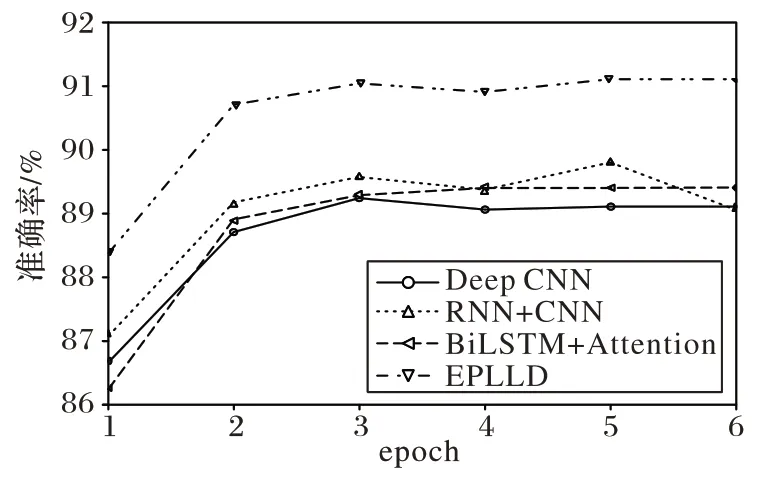
图7 验证集准确率变化曲线Fig.7 Validation set accuracy change curve
实验最终使所有模型趋于平稳,学习能力达到饱和。为进一步说明这种快速收敛是由于模型的优劣,本实验给出了训练集的损失值变化曲线,如图8 所示。由图8 可以看出,训练集损失值一直在合理范围上下波动,因此验证集的快速收敛不是过早陷入局部最优引起的。
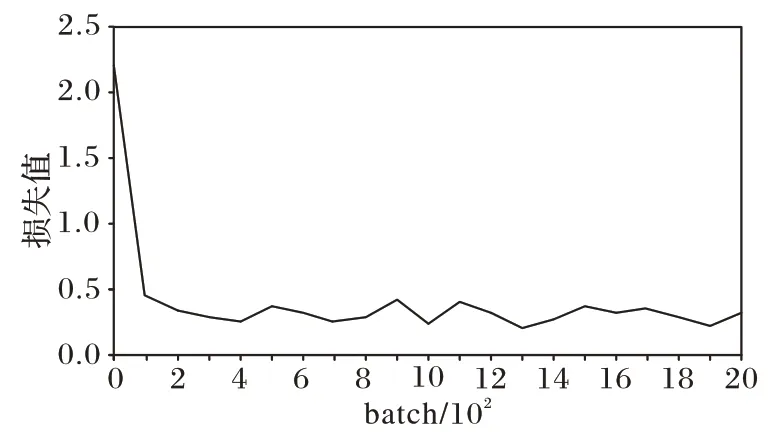
图8 训练集损失值变化曲线Fig.8 Training set loss value change curve
将EPLLD 与传统数据分析处理方法进行对比,在画像的体系建设中存在明显差异。以连云港市H 有限公司为例,建立标签词云图,结果如图9 所示。由图9(a)可知,在传统的数据分析处理标签主题中仅有工程和化工标签较为突出,此标签无法直观表示企业形象,且没有表达出最重要的批发和商贸公司的特点。由图9(b)可知,在EPLLD 标签主题中,企业所属的批发业标签最为突出,在经过多特征模糊标签延深后获得商贸标签,然后使用综合提取算法得到化工、钢材以及工程等标签,最后是普通标签。因此,相较于传统数据分析处理方法,EPLLD具有标签层次好和概括能力强的优点。

图9 传统数据分析处理方法与EPLLD的标签主题Fig.9 Label themes of traditional data analysis and processing and EPLLD
EPLLD 标签分层延深建模和传统分析处理方法的对比结果如表4 所示。由表4 可知,EPLLD 能够对企业模糊标签进行延深,形成分级表示的多特征标签,具有标签层次好、概括能力强的特点,同时表明EPLLD 在标签处理和关键词提取方面具有很好的效果。
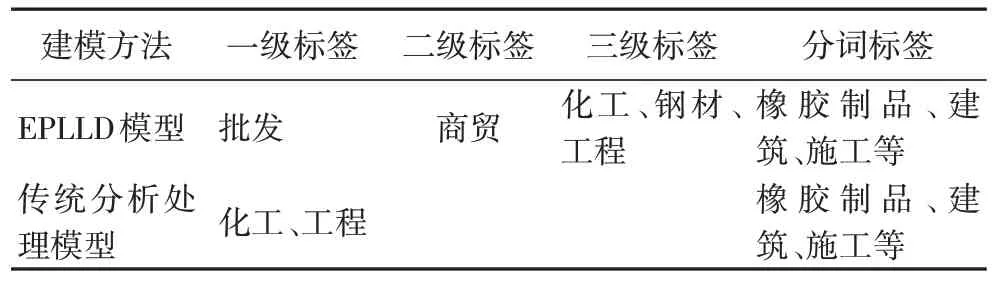
表4 标签建模对比结果Tab 4 Label modeling comparison results
4 结语
本文所提出的基于标签分层延深建模的企业画像构建方法EPLLD,在分析处理标签的同时,能够对模糊信息建立由浅入深的标签延深。该方法通过分析处理多维度信息来融合企业特征,采用BiLSTM 网络完成模糊标签延深;接着基于多源信息融合后的企业数据,通过TF-IDF、TextRank、LDA主题模型提取算法,完成标签分层延深建模。使用企业数据集实验,结果表明EPLLD 能有效提高企业画像标签建模准确率;并以连云港市H 有限公司为例,构建标签主题来展示由浅入深的标签建模体系。
在多特征抽取中不同的特征融合方法对后续特征选择存在影响,因此,在标签分层延深建模之后,如何利用特征间的关系进行特征分析,使得标签建模具有关联性是日后的研究重点。
