
结合BERT和特征投影网络的新闻主题文本分类方法
2022-05-07 07:07张海丰郝儒松温超东
计算机应用 2022年4期
张海丰,曾 诚,2,3*,潘 列,郝儒松,温超东,何 鹏,2,3
(1.湖北大学计算机与信息工程学院,武汉 430062;2.湖北省软件工程工程技术研究中心,武汉 430062;3.智慧政务与人工智能应用湖北省工程研究中心,武汉 430062)
0 引言
新闻文本分类包括主题分类和内容分类,而新闻主题文本分类任务中,新闻主题文本通常是由一些高度概括新闻内容的词汇组成,由于用词缺乏规范、语义模糊,使得现有的文本分类方法表现不佳。新闻主题文本长度短,在有限长度的新闻主题文本中提取其完整语义特征进行分类挑战极大。
新闻主题分类属于自然语言处理(Natural Language Processing,NLP)短文本分类任务,文本分类任务首先需要对相关文本进行文本处理,并进行文本向量化表示。随着深度学习方法的兴起,目前普遍使用的词嵌入方式有两种,一种是静态的语言模型Word2Vec、GloVe;另一种是预训练模型BERT(Bidirectional Encoder Representations from Transformers)、XLNet 等动态语言模型。Word2Vec 方法可以较好地体现上下文信息,被大量应用于自然语言任务中。而预训练模型BERT 的出现,解决了静态词向量无法解决的一词多义问题,在多个NLP 任务中表现优异。
本文结合BERT 和特征投影网络(Feature Projection network,FPnet),提出了新闻主题分类方法BERT-FPnet,通过梯度反转网络提取共性特征,以特征投影方式,将BERT 模型提取特征进行特征投影提纯,提取强分类特征,提升新闻主题文本分类效果。
1 相关工作
新闻主题分类是指将新闻主题通过NLP 技术对新闻文本进行特征处理、模型训练、输出分类。新闻主题分类是当前NLP 文本分类的重要研究方向之一,互联网发展至今,每天产生海量新闻,各种新闻类别混杂其中,如何更好地对其分类有着重要研究意义。
1.1 文本向量化
文本向量化表示就是用数值向量来表示文本的语义,对文本进行向量化,构建合适的文本表示模型,让机器理解文本,是文本分类的核心问题之一。传统的机器学习中朴素贝叶斯模型不需要将文本向量化表示,它记录词语的条件概率值,对输入各词语的条件概率值进行计算即可得到预测数值。但是目前绝大多数线性分类模型还是需要对文本进行向量化表示,必须输入一个数值向量才能计算得到预测数值。传统的特征表示中,使用词袋表示文本,这种方式容易导致特征出现高维、稀疏问题,不仅影响文本分析的效率和性能,可解释性也比较差。随着深度学习的发展,一些优秀的神经网络语言模型被提出,极大地推动了NLP 领域的发展。Mikolov 等提出一种神经网络概率语言模型Word2Vec,它包括连续词袋(Continuous Bag-Of-Words,CBOW)和Skip-Gram 两种模型训练方法,让词向量很好地表达上下文信息,并提出了负采样的方式来减少Softmax 的计算时间,但它只考虑了文本的局部信息,未有效利用整体信息。针对此问题,Pennington 等提出全局词向量(Global Vectors,GloVe)模型,同时考虑了文本的局部信息与整体信息。
Word2Vec、GloVe 模型等训练词向量的方法,得到的词向量文本特征表示为下游文本分类任务性能带来了有效提升,但是它们的本质是一种静态的预训练技术,在不同的上下文中,同一词语具有相同的词向量,这显然是不合常理的,它无法解决自然语言中经常出现的一词多义问题,也导致下游分类任务的性能受到限制。随着预训练技术的发展,GPT(Generative Pre-Training)、BERT、XLNet 等一些优秀的预训练模型相继被提出,其中最具代表的BERT预训练模型,它的动态字向量可以更好地表示文本特征,有效地解决一词多义问题,并在多个NLP 任务上效果显著,尤其适合新闻主题短文本分类任务。因此本文利用BERT 模型在短文本处理上的优势,在其基础上结合FPnet 进行改进。
1.2 文本分类方法
现有的深度学习文本分类方法主要包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、注意力机制以及根据这些模型的优缺点互相融合的组合模型。Kim提出一种文本卷积神经网络TextCNN,利用多窗口一维CNN 在Word2Vec 词向量上进行特征提取分类,效果卓越;Zhang 等提出了一种字符级的卷积神经网络(character-level CNN,char-CNN)分类模型,采用字符级向量输入的6 层卷积网络,并将多卷积层网络连接到一个双向循环层在短文本分类上进行文本分类。在RNN 的应用上,Mikolov 等利用RNN进行文本分类,取得了不错的效果。但CNN 不能直接获得数据中的长期依赖关系,RNN 在处理文本时可能会出现梯度爆炸和消失问题。针对这些问题,一些组合模型相继被提出,Lai等针对可能导致上下文语义缺失的问题,使用RNN 提取上下文语义信息,并融合原有的特征,通过结合单层池化网络提出了一个循环卷积神经网络模型TextRCNN;Xiao 等提出了一个char-CRNN(character-level Convolutional RNN)模型,用另一种方式将CNN 与双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)结合,先进行卷积操作,然后再进行RNN 特征提取。
注意力机制的提出,让神经网络模型对训练文本中的不同语句有不同的关注度,实现了更加合理的自然语言建模,越来越多的神经网络中开始加入注意力机制。Zhou等提出的TextRNN-Attention 模型结合双向RNN 与注意力机制,在特定任务上取得了不错的效果。而BERT 模型所基于的Transformer 架构更是一种完全基于注意力机制的模型。
在新闻主题分类任务上过去一般使用TextCNN 在Word2Vec 训练的字向量上进行特征提取,分类效果比词粒度效果更好,但词向量也有其价值。杨春霞等提出了一种字粒度和词粒度融合的新闻主题分类方法,将字粒度的Word2Vec 向量和词粒度的Word2Vec 向量进行融合。付静等将词向量和位置向量作为BERT 的输入,通过多头自注意力机制获取长距离依赖关系,提取全局语义特征;然后利用Word2Vec 模型融合LDA(Linear Discriminant Analysis)主题模型扩展短文本的特征表示方法,解决短文本数据稀疏和主题信息匮乏的问题。
BERT 模型性能强大,许多优秀的模型都是在BERT 模型基础上进行改进。Lan 等提出一种基于BERT 的轻量级预训练语言模型ALBERT(A Lite BERT),通过嵌入层参数因式分解减少BERT 参数量,扩展了BERT 模型的可用性。温超东等结合ALBERT 与门控循环单元(Gated Recurrent Unit,GRU)模型在专利文本分类任务上取得了不错的效果,但模型分类精度相较于BERT 会有一定程度的下降。Chen等提出了一种半监督文本分类方法MixText,使用一种全新文本增强方式TMix,在BERT 编码层进行隐空间插值,生成全新样本,相较于直接在输入层进行Mixup,TMix 的数据增强的空间范围更加广阔。Meng 等提出一种不需要任何标注数据,只利用标签进行文本分类的方法LOTClass,使用BERT 模型训练标签的类别词汇,利用BERT 的MLM(Mask Language Model)进行标签名称替换、类别预测,然后通过自训练加强分类效果,达到了接近有监督学习的分类效果。
本文主要研究有监督方法对BERT 模型进行改进提升。Qin 等在2020 年首次提出一种提升文本分类的特征投影网络(FPnet),在多个文本分类模型上加入FPnet,有效提升了分类模型的文本分类效果。本文在其基础上以双BERT模型融合FPnet,提取域共性特征和特性特征,结合特征投影方法,以端到端的方式采用两种融合方式进行融合。
2 相关技术
2.1 预训练语言模型BERT
BERT 模型采用双向Transformer 编码器获取文本的特征表示,模型结构如图1 所示,将训练文本以字符级别输入到多层双向Transformer 编码器中进行训练,输出文本字符级特征。
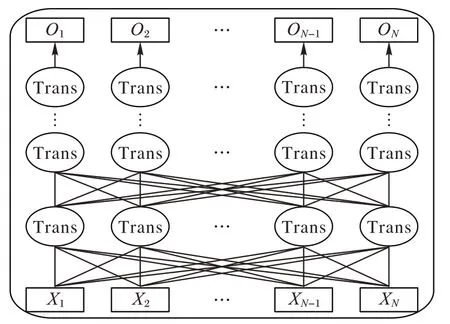
图1 BERT模型结构Fig.1 BERT model structure
在预训练阶段,BERT 模型通过MLM 任务结合Transformer 架构注意力机制本身全局可视性,增加了BERT模型的信息获取,且随机掩码使得BERT 模型不能获得全量信息,避免过拟合。通过NSP(Next Sentence Prediction)任务让模型更好地理解句子之间的联系,从而使预训练模型更好地适应下游任务。因此,BERT 模型具有强大的文本语义理解能力,在文本分类任务上效果显著。
2.2 FPnet
FPnet 是一种强化文本分类效果的神经网络结构。主要利用梯度反转网络来实现,使用梯度反向层(Gradient Reversal Layer,GRL)提取多个类的共性特征。Ganin等详细介绍了GRL 的实现原理,并将其用于领域自适应(Domain Adaptation)中提取共性特征。它将领域自适应嵌入到学习表示的过程中,以便最终分类决策对于域的改变仍能提取到不变特征。FPnet 利用GRL 的这一特点来提取共性特征,并采用类似对抗学习方法通过特征投影改进表示学习。
如图2 所示,FPnet 由两个子网络组成:右边为共性特征学习网络(Common feature learning network,C-net);左边为投影网络(Projection network,P-net)。
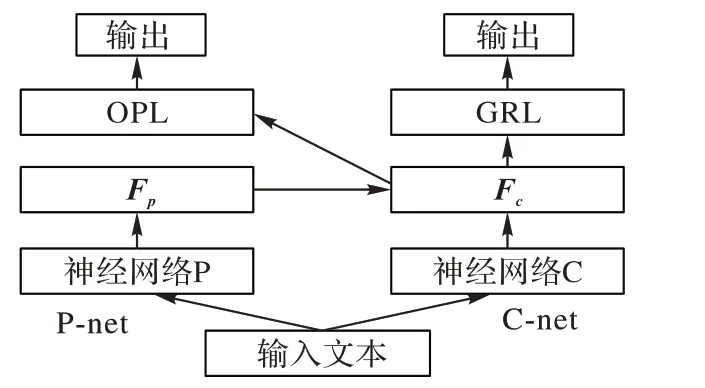
图2 特征投影网络的结构Fig.2 Structure of FPnet
FPnet 的主要重点在于使用双网络进行不同的任务,两个神经网络所提取的特征不同,通过特征投影的方式,强化主网络的分类特征,从而提升文本分类效果。FPnet 可以与现有的LSTM、CNN、Transformer、BERT 神经网络进行融合,在与不同的神经网络相结合时候,只需要将FPnet 结构中的神经网络P 和神经网络C 特征提取器换成LSTM、CNN、Transformer、BERT 即可。FPnet 作为一种神经网络结构并没有固定的形式,其主要思想在于强化提纯特征,从而达到强化神经网络的分类效果。在TextCNN-FPnet中使用了2 个TextCNN 网络作为FPnet 的C-net 和P-net 特征提取器来提取共性特征和特性特征。OPL(Original Projection Layer)处于卷积池化层之后,在神经网络最后一层进行特征投影,从而提升了TextCNN 模型的分类性能。
C-net 模块在正常的文本分类神经网络结构中加入GRL会使得神经网络C 所提取的特征F
为共性特征。由于C-net输出通过损失函数计算,在反向传播过程中受到GRL 反转作用,使得整个网络损失函数loss 值逐渐增大,无法正确分类,神经网络C 所提取的特征F
在神经网络参数更新过程中逐渐丢弃类别信息,只带有共性信息,在向量空间中表现为没有正确的类别指向。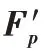
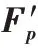
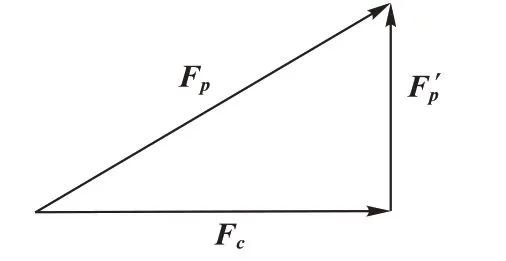
图3 特征投影Fig.3 Feature projection
FPnet 使用双网络合作进行文本分类任务,神经网络Pnet 和神经网络C-net 结构相同但参数并不共享,C-net 中加入梯度反转层GRL,P-net 中加入特征投影层OPL,双网络使用相同的交叉熵损失函数,C-net 中的梯度反转使得网络提取的特征并不能正确分类,即提取到了共性特征。
在新闻主题文本分类任务难点主要包括两个方面:1)主题文本长度过短,语义信息少,普通文本分类模型不易提取其有效分类语义信息,一些主题词可能属于多个类别,而另一些主题词并不能指向任何类别,更适合使用BERT 模型作为特征提取器;2)部分新闻包含多个类别信息,例如财经类新闻与房产类新闻通常不易区分,科技新闻又容易和汽车类新闻混淆。使用FPnet 后,通过计算净化提纯后的向量特征,可以将学习到的输入新闻主题文本的信息向量投影到更具区分性的语义空间中来消除共同特征的影响。
BERT 模型与一般的文本分类模型不同,不仅可以使用分类器最终提取的特征进行特征投影融合,也可以在BERT网络的隐藏层中融合FPnet 进行改进。
3 BERT-FPnet框架及其实现
本文BERT-FPnet 新闻主题文本分类方法主要包括两种实现方式:
1)BERT-FPnet-1。使用BERT-FPnet 的MLP 层输出进行特征投影结合,使用预训练模型BERT 构建文本分类模型时需要在BERT 的输出后加入MLP(MultiLayer Perceptron)层进行进一步特征提取,MLP 层使用多个全连接网络。
2)BERT-FPnet-2。使用BERT-FPnet 模型中BERT 的隐藏层进行特征投影结合。
BERT-FPnet-1 的整体模型结构如图4 所示,模型网络主要分为两部分,左边为BERT 投影网络P-net,右边为BERT 共性特征学习网络C-net。
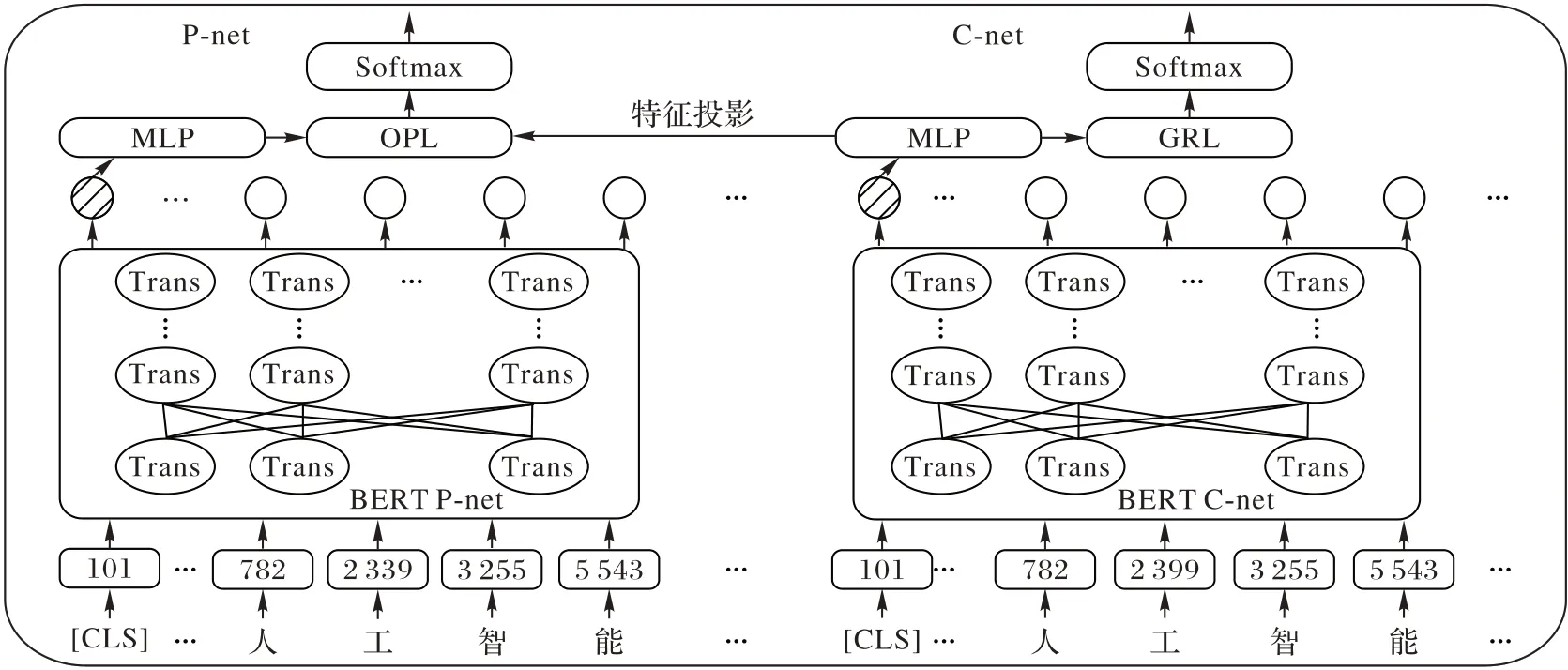
图4 BERT-FPnet模型框架Fig.4 BERT-FPnet model framework
BERT-FPnet-1 模型工作流程如下:在新闻文本输入到BERT 层之前需要进行特征处理,将输入新闻文本的开头加上[CLS]字符,然后根据BERT 字典将所有的字符转化为字典中对应id,输入到BERT 模型中。如式(1)~(2)所示:

E
取出,放入MLP 层中进行进一步特征提取,得到文本特征E
和E
。如式(3)~(5)所示:
在MLP 层中包含2 个全连接层和激活函数tanh,第一个全连接层维度参数设置为[768,768],输出特征通过激活函数tanh 后进入第二个全连接层,其维度参数设置为[768,class_dim],class_dim 根据新闻文本标签类别数来设置,如式(6)~(7)所示:

分别通过P-net 模块和C-net 模块的MLP 层提取原始特征和共性特征,如式(8)~(9)所示:

如前文所述,C-net 模块主要提取共性特征,共性特征是指对分类任务不做区分的特征,它是所有类的共性特征,C-net 通过MLP 层后特征提取完毕,将特征放入GRL 中进行梯度反转。如式(10)~(11)所示:

λ
值为GRL 梯度反转超参数。梯度反转层在正向传播时对特征f
不做修改,在反向传播时传递了-λ
使得整个C-net 网络的损失函数LOSS 求反。特征投影方法是将特征向量投影到共性特征向量上,投影公式如式(12)所示:

f
向量中只包含公共语义信息。而第二次投影得到提纯后的特征向量,只包含分类语义信息,如式(13)~(14)所示:
两个网络在结构上相同,参数上并不共享。C-net 中加入GRL 梯度反转层后,和P-net 的输出一样,P-net 和C-net 的输出都使用Softmax 归一化激活函数,如式(15)~(16)所示:

双网络使用交叉熵损失函数进行计算。C-net 通过GRL使网络损失增大,所提取的特征不能正确分类,即提取到了共性特征。如式(17)~(18)所示:
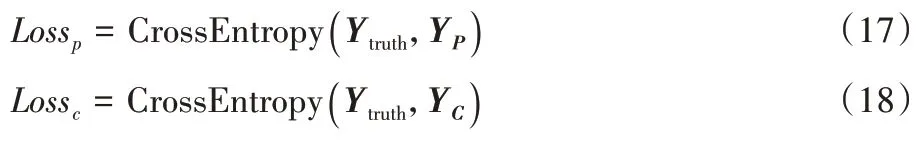
Loss
反向传播只更新右侧C-net 网络参数,Loss
反向传播只更新左侧P-net 网络参数。C-net 中虽然同样使用Softmax 和交叉熵损失函数,但是由于在反向传播时候C-net模块中GRL 层进行梯度反转,因此Loss
的值会逐渐变大。进行Loss
计算和反向传播只是为让神经网络得到共性特征。P-net 模块中Loss
为最终整个模型预测分类损失函数值,Y
值为整个特征投影网络的最终预测输出。BERT-FPnet-2 主要区别在于OPL 特征投影层处于BERT内部的隐藏层之间。BERT-BASE 中文预训练模型为12 层Transformer 结构,由于BERT 模型各个隐藏层中所提取的语义信息各不相同,从低层到高层分别提取的是短语级别、句法级别以及深度语义级别的特征语义信息,而文本特征的长期依赖需要对模型多层输出进行建模。因此本文分别对BERT 的低、中、高隐藏层进行特征投影结合,通过实验对比提出了BERT-FPnet模型第二种特征投影方式BERT-FPnet-2。
BERT 隐藏层特征投影是将当前隐藏层输出进行特征投影后,输入到下一层隐藏层中,BERT-BASE 中文预训练模型隐藏层为12 层,如图5 所示,以BERT 模型第6 层特征投影为例,在BERT-FPnet-2 的第6 层加入OPL 层进行特征投影提纯,BERT-Cnet 网络结构不变。
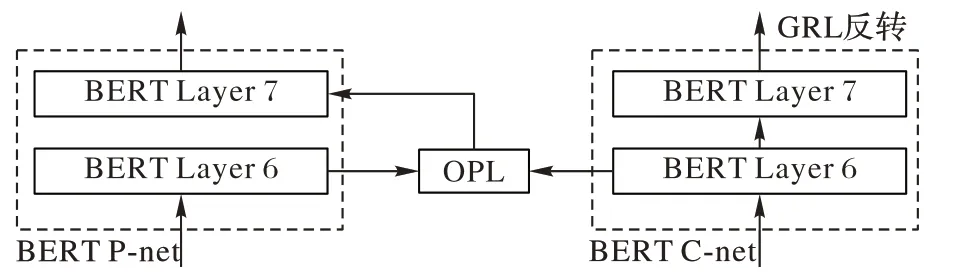
图5 BERT-FPnet-2隐藏层特征投影Fig.5 BERT-FPnet-2 hidden layer feature projection
由于BERT模型有多个隐藏层,本文通过多种实验选取不同的隐藏层进行特征投影实验对比,从而得到最优实验效果。
4 实验与结果分析
4.1 实验环境与数据
本文实验环境如表1 所示。为了评估本模型方法在新闻主题文本分类任务上的有效性,本文使用四个新闻主题数据集进行模型实验,如表2 所示。
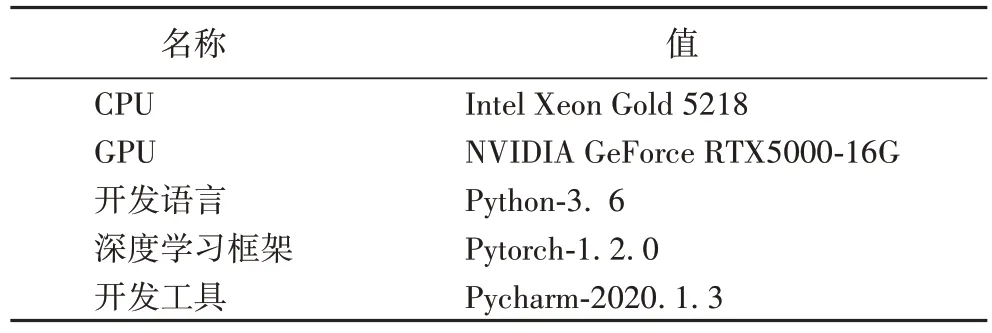
表1 实验环境Tab 1 Experimental environment
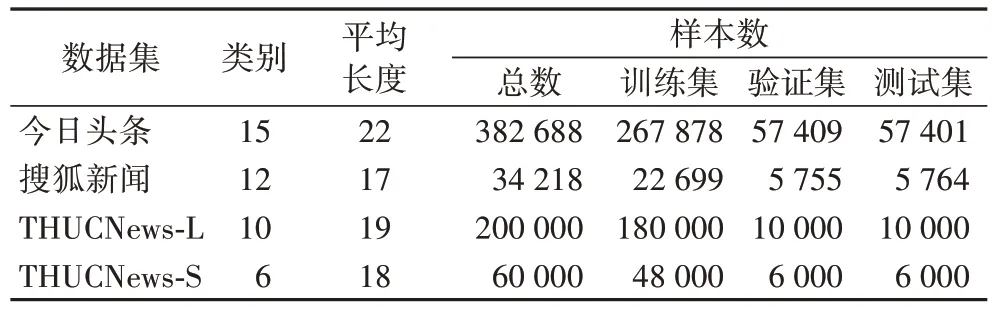
表2 数据集详情Tab 2 Dataset details
1)今日头条数据集:根据今日头条客户端收集而来,分别包括民生、文化、娱乐、体育、财经、房产、汽车、教育、科技、军事、旅游、国际、证券、农业、电竞共15 个类别。
2)搜狐新闻数据集:通过网络开源搜狐新闻数据集进行数据清洗,去除数据中部分缺少标签数据,去除新闻内容,只保留新闻主题。数据集共包含娱乐、财经、房地产、旅游、科技、体育、健康、教育、汽车、新闻、文化、女人共12 个类别。
3)THUCNews-L 数据集:THUCNews 是根据新浪新闻RSS订阅频道2005—2011 年的历史数据筛选过滤生成,包含约74 万篇新闻文档。本文在原始数据集上进行数据清洗,重新整合划分出财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐,共计10 个类别,每个类别数据约2 万条。
4)THUCNews-S 数据集:在THUCNews 基础上进行数据清洗的小型数据集,共包含财经、股票、科技、社会、时政、娱乐6 个类别,每个类别数据1 万条。
4.2 对比实验设置
为验证本文所提出的结合BERT 和特征投影网络的新闻主题分类方法的有效性,选择了8 个在新闻文本分类上效果较好的分类模型作为对比。其中:TextCNN、FastText、Transformer 和DPCNN,结合Word2Vec 字粒度词向量进行文本分类实 验;ALBERT-FC、BERT-FC、BERT-CNN 和BERTBIGRU 结合预训练模型进行文本分类实验。具体如下:
1)TextCNN:多窗口超参数设置为[2,3,4],4 窗口可以很好地提取中文新闻数据的四字成语语义,卷积核数量设置为256。
2)FastText:将输入文本的序列投射到词嵌入空间,然后通过池化层得到文本特征向量分类,FastText 没有卷积操作,模型结构简单、速度快。
3)Transformer:使用encoder 作为特征提取器,本次实验使用了单组注意力机制和3 个encoder 块作为模型组成。
4)深层金字塔模型(Deep Pyramid Convolutional Neural Network,DPCNN):该模型参考深度残差网络(Residual Network,ResNet),解决深层模型的梯度消失问题。通过固定特征图(feature map)的数量,采用步长为2 的最大池化操作,使每个卷积层的数据大小减半,同时相应的计算时间减半,从而形成一个金字塔(Pyramid)。
5)ALBERT:使用ALBERT-BASE 中文预训练模型,在模型最后一层pooling 层输出连接全连接层(Fully Connected layer,FC)进行Softmax 分类。
6)BERT-FC:使用BERT 模型最后的[CLS]向量连接FC进行分类。
7)BERT-CNN:使用BERT 模型的最后一层的encoder输出的每个字向量特征,通过卷积池化进一步提取特征进行分类任务,其中CNN 也使用[2,3,4]窗口卷积池化,卷积核数量256。
8)BERT-BIGRU(BERT-Bidirectional Gated Recurrent Unit):使用BERT 模型的最后一层的encoder 输出,提取每个字向量特征,输入双向门控单元(Bidirectional Gated Recurrent Unit,BiGRU)提取上下文语义特征从而进行文本分类。
在实验之前对四个新闻数据集进行预处理,过滤掉非ASCII 字符,清洗换行符等标点符号,对英文字符进行大小写转换,并对中文文字进行简繁字体转换。
对比实验中TextCNN、FastText、Transformer 和DPCNN 模型结合Word2Vec 字粒度词向量进行文本分类实验,并分别在训练集上训练Word2Vec 字向量,本次对比实验中Word2Vec 字典大小设置为5 000,字符映射为300 维字向量。
对比实验中ALBERT-FC、BERT-FC、BERT-CNN 和BERT-BIGRU 结合预训练模型进行文本分类实验。ALBERT-FC 使用ALBERT-BASE-CHINESE 中文预训练模型,BERT-FC、BERT-CNN 和BERT-BIGRU 使 用BERT-BASECHINESE 中文预训练模型。对比模型超参数均在新闻主题文本分类数据集上进行调优。
4.3 评价指标
本文采用准确率Acc(Accuracy)、精确率P
(Precision)与召回率R
(Recall)的F
1 值对模型效果进行评价,其计算公式如下: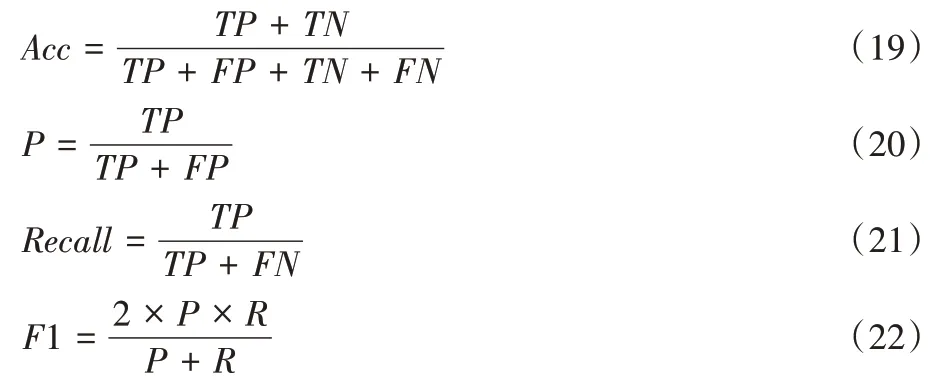
TP
表示实际正样本预测为正,TN
表示负样本预测为负,FP
表示负样本预测为正,FN
表示正样本预测为负。由于本次实验任务为多类别新闻主题文本分类任务,因此使用精确率P
、召回率R
和F
1 值的宏平均(Macroaveraging)值M_F1 作为评价指标。宏平均计算方式将每个类别的精确率、召回率和F
1 值分别计算出来,然后对所有类求算术平均值,如式(23)~(25)所示。宏平均值更适合作为多类别分类任务评价指标。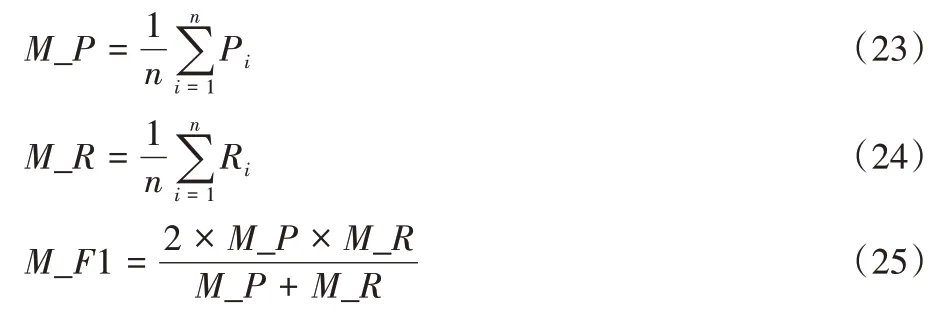
4.4 实验参数
本文所提出的结合BERT 和FPnet 的新闻主题分类方法的两种实现方式的基本参数设置相同,主要包括BERT 模型参数和综合模型训练参数设置,BERT 模型采用谷歌开源的BERT-BASE 中文预训练语言模型。模型主要参数如表3所示。
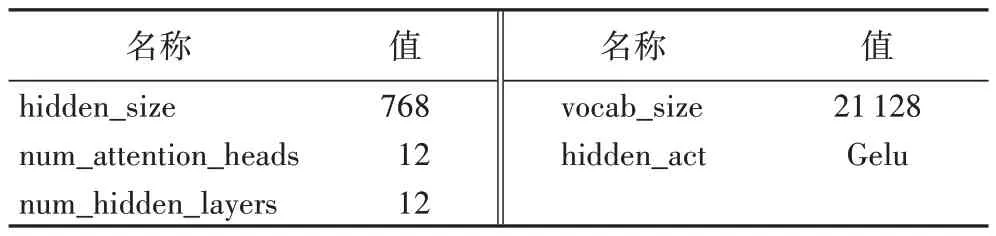
表3 BERT模型主要参数Tab 3 Major parameters of BERT model
优化策略使用更适合于BERT 模型的BertAdam 优化器,warmup 模型预热设置为0.05,模型学习率设置为5E-5,并且使用动态学习率策略进行学习率衰减,衰减系数为0.9。
由于四个数据集的平均长度都在20 左右,多次微调长度超参数后选取文本输入长度超参数pad_size
=32,梯度反转GRL 超参数λ
设置为[0.05,0.1,0.2,0.4,0.8,1.0],随着模型训练梯度下降变化,可以有效提取共性特征,具体如表4所示。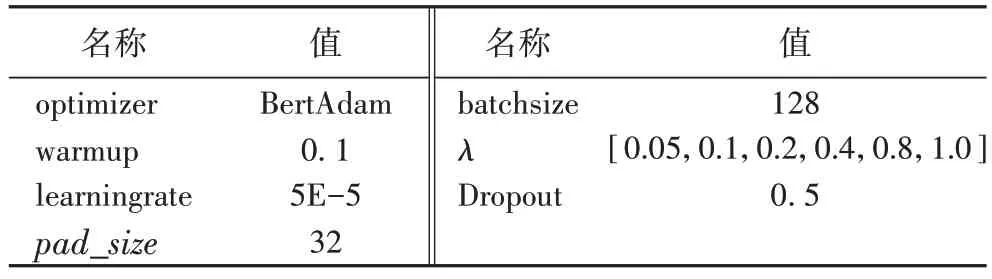
表4 BERT-FPnet模型超参数Tab 4 Hyperparameters of BERT-FPnet model
在BERT-FPnet-2 中,对BERT 模型各个隐藏层进行特征投影,对比各个隐藏层特征投影分类效果:
1)单层投影:分别对BERT 模型第3、6、9、12 层隐藏层进行特征投影;
2)双层投影:分别在第3、6、9、12 层隐藏层以及最后一层MLP 层进行特征投影;
3)所有层投影:在BERT 模型的12 个隐藏层均进行特征投影。
4.5 实验结果分析
如表5 所示,在搜狐新闻数据集上进行BERT-FPnet-2 隐藏层特征投影实验,3、6、9、12 分别表示在BERT 的单层隐藏层特征投影层;3-MLP、6-MLP、9-MLP、12-MLP 分别是表示双层特征投影;ALL 代表所有层均进行特征投影;MLP 为BERT-FPnet最后一层MLP 层。
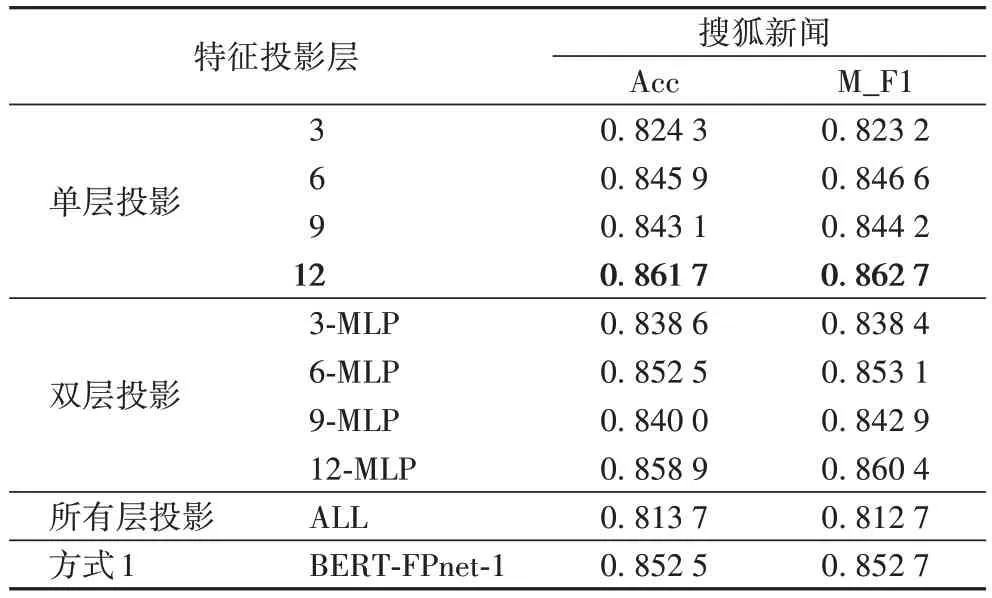
表5 搜狐新闻数据集上BERT-FPnet-2隐藏层特征投影实验结果Tab 5 Experimental results of BERT-FPnet-2 hidden layer feature projection on Sohu News dataset
在单层特征投影对比可以看出,第12 层隐藏层特征投影效果最好,准确率和F1 值分别达到了0.861 7 和0.862 7。从双层特征投影对比实验可以看出,6-MLP 投影和12-MLP层特征投影效果最好,但是双层投影效果相较于单层第12层隐藏层投影效果有所降低。而使用所有层进行特征投影分类效果下降较多。对比BERT-FPnet-1 可以发现,在BERTFPnet-2 使用第12 层隐藏层进行特征投影效果最好。
为进一步验证BERT-FPnet 第12 层隐藏层特征投影的效果,将其在THUCNews-S 数据集上进行对比实验,实验结果如表6 所示。可以看到在THUCNews-S 数据集下隐藏层投影分类效果和BERT-FPnet-1 效果接近。
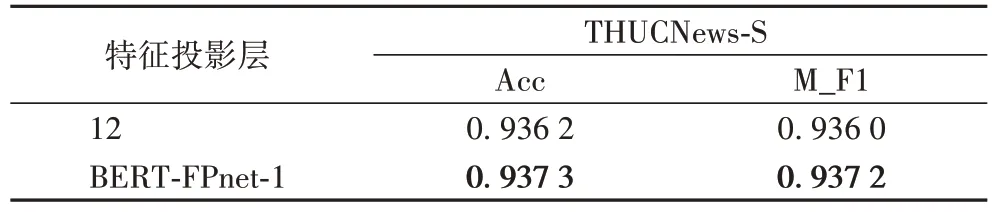
表6 THUCNews-S数据集上BERT-FPnet的特征投影结果对比Tab 6 Comparison of BERT-FPnet feature projection results on THUCNews-S dataset
上述实验通过在BERT 模型部分隐藏层进行层次特征投影实验对比,表明BERT 模型融合特征投影层适合在语义特征提取层进行特征投影。
在四个数据集上进行多个模型实验对比实验,实验结果如表7 所示,其中BERT-FPnet-1 为在模型MLP 层最终特征输出进行特征投影,而BERT-FPnet-2 为在BERT 输出的第12 层隐藏层进行特征投影后再放入MLP 层进行分类。
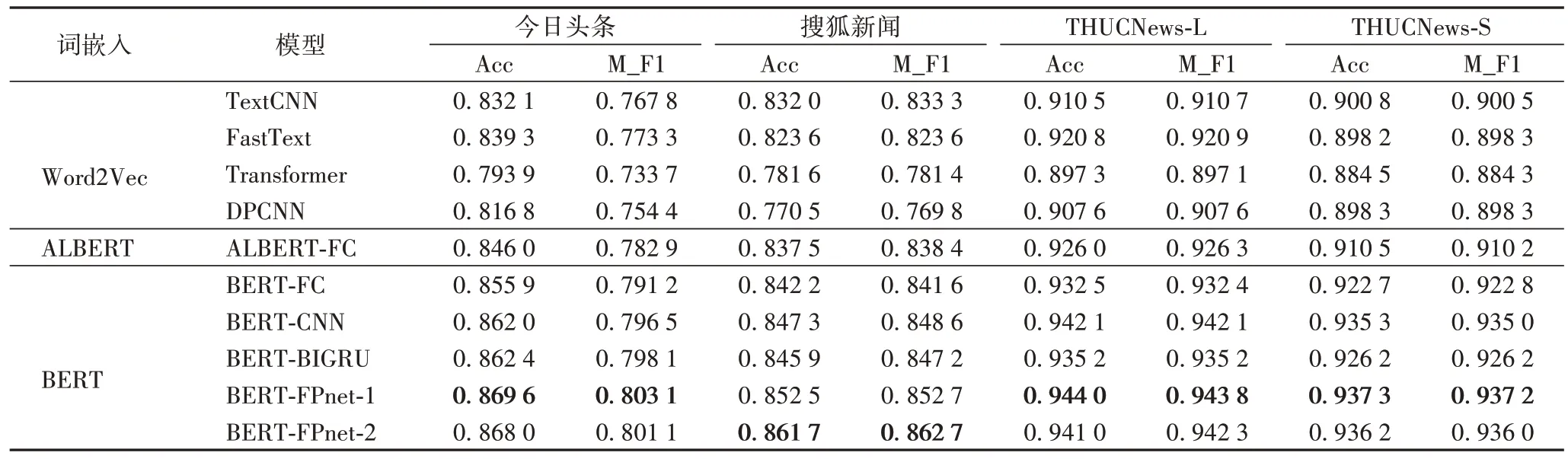
表7 各模型在不同数据集上的实验结果Tab 7 Experimental results of different models on different datasets
从表7 可以看出本文所提出的结合BERT 和FPnet 的新闻主题分类方法的两种实现方式,在准确率、宏平均F1 值都优于其他文本分类模型,尤其优于目前基于BERT 模型融合较好的BERT-CNN 和BERT-BIGRU。为更加直观地对各模型性能进行分析,采用柱状图的形式对各模型的M_F1(宏平均F1 值)实验结果进行展示,如图6 所示。
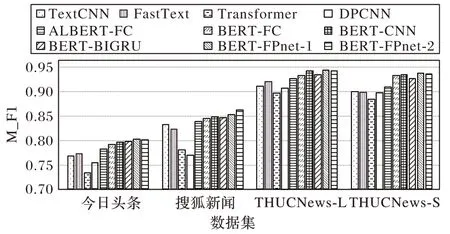
图6 各模型在不同数据集上的宏平均F1值Fig.6 M_F1 value of different models on different datasets
从图6 可以看出,本文模型在各个数据集上效果均优于其他对比模型,在THUCNews-L 和THUCNews-S 数据集上只有BERT-CNN 模型F1 值接近本文模型。
并且分析表7 中数据可知,使用Word2Vec 向量的TextCNN、FastText、Transformer、DPCNN,分类效果显然差于融合预训练模型的ALBERT-FC、BERT-FC、BERT-CNN 和BERT-BIGRU 方法,说明预训练语言模型在提取的句子语义特征表示比Word2Vec 更好,这也是本文使用BERT 模型融合特征投影的原因。而ALBERT 模型虽然在BERT 模型上进行创新,消减了BERT 模型的参数,但是在一定程度上降低了模型准确率。
在今日头条、THUCNews-L、THUCNews-S 这3 个数据集上BERT-FPnet-1 在MLP 层投影效果更好,而搜狐新闻数据集上在BERT-FPnet-2 使用BERT 模型第12 层隐藏层投影效果更好,因此可以针对不同数据集选择不同的特征投影方式得到最好的分类效果。
4.6 超参数影响
本文所提新闻主题文本分类模型影响最终分类效果的参数主要包括:新闻主题文本输入长度pad_size
、GRL 梯度反转参数λ
以及双网络学习率。新闻主题文本一般长度不一,模型输入长度pad_size
不宜过长也不宜过短:过短的输入长度显然无法有效获取完整语义信息;而设置过长的pad_size
进行数据对齐时,填充值会造成噪声影响语义提取效果,并且由于BERT 模型注意力机制的特性,模型的计算时间也会呈指数增长,从而影响模型分类性能。GRL 梯度反转参数主要作用在于帮助C-net 提取有效的共性特征。双网络学习率在微调时可分为同步学习率和异步学习率。同步学习率是指双网络采用相同梯度下降策略和学习率,异步学习率是指双网络采用不同的梯度下降策略和学习率。虽然在DANN 中采用的是ADam 和SGD的双网络不同优化策略,文献[22]中也是使用这种方式,但是本文使用同步学习率获得了更好的效果。在THUCNews-S 数据集上进行参数对比实验,结果如表8 所示。可以看出pad_size
取值从平均长度18 到40,本文模型的准确率和F1 值变化。从实验结果中可以看到pad_size
值依次取18、24、32 时,模型的准确率和F1 值逐步提升,但当pad_size
值取40 时,模型准确率和F1 值并未得到有效提升。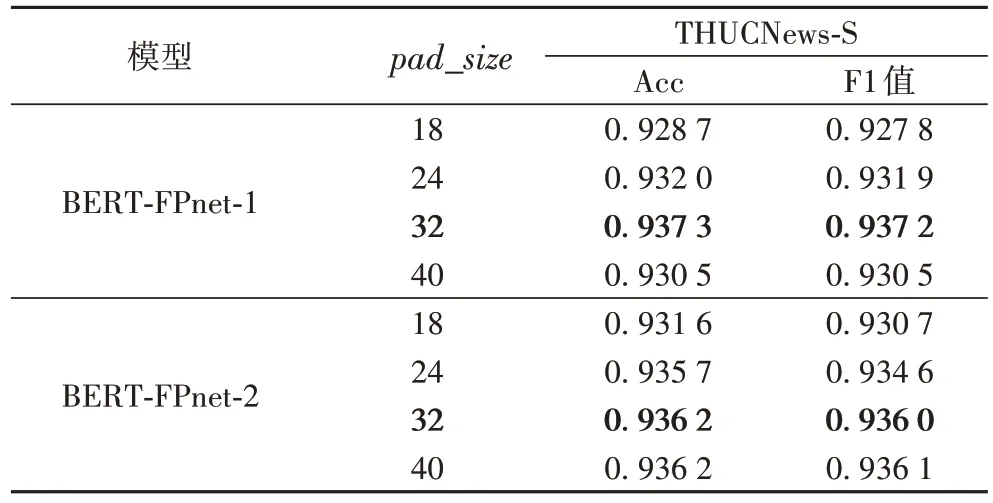
表8 各pad_size 下本文模型在THUCNews-S数据集上的性能对比Tab 8 Perfomance comparison of proposed models under different pad_size on THUCNews-S dataset
GRL 超参数λ
分别取静态值1 和两种动态λ
进行实验对比,实验结果如表9 所示。可以看出不同的λ
值对模型分类效果会产生细微影响,更加细腻度的λ
变化幅度对模型的分类效果更好,更有助于C-net 提取共性特征。
表9 各λ下本文模型在THUCNews-S数据集上的性能对比Tab 9 Performance comparison of proposed models under different λ on THUCNews-S dataset
在双网络优化策略方面,本文对比了文献[22]中所用的ADam 和SGD 的双网络不同优化策略,以及本文所用的双BERTAdam、同步学习率方式。实验结果如表10 所示。可以看出本文所用方法对以BERT为基础的FPnet分类效果更好。
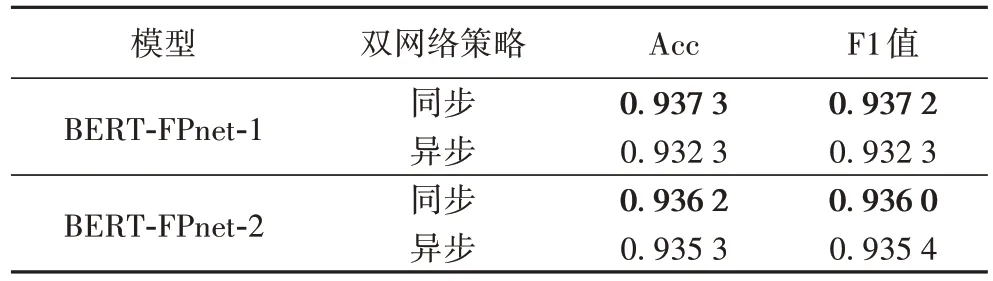
表10 各优化策略下本文模型在THUCNews-S数据集上的性能对比Tab 10 Performance comparison of proposed models under different optimization strategies on THUCNews-S dataset
因此最终各数据集实验对比部分并未参照文献[22]中在FPnet 的双网络结构中使用Adam 和SGD 两种梯度下降优化策略,而是使用了更适合于BERT 模型的双BERTAdam 优化器。
5 结语
本文提出两种结合BERT 和FPnet 的新闻主题文本分类方法。利用BERT 模型对新闻主题文本的完美语义特征提取能力,使用双BERT 模型以特征投影的方式结合完成新闻主题文本分类任务。在其中一个BERT 网络中加入GRL 梯度反转层,提取新闻主题文本的共性特征;然后使用另一个BERT 网络OPL 将提取的特征在共性特征上进行投影,从而提取特性特征,提升文本分类效果。在四个新闻主题数据集上进行大量对比实验,验证了本文所提出的结合BERT 和FPnet 的新闻主题文本分类方法的有效性。
本文模型缺点在于模型参数量较大,可尝试使用知识蒸馏消减模型参数。在下一步工作中,将使用BERT 的字序列向量通过CNN、RNN 进行特征提取后融合特征投影进行网络融合,以完成新闻主题分类任务。
