
结合广义自回归预训练语言模型与循环卷积神经网络的文本情感分析方法
2022-05-07 07:07张海丰温超东郝儒松
计算机应用 2022年4期
潘 列,曾 诚,2,3*,张海丰,温超东,郝儒松,何 鹏,2,3
(1.湖北大学计算机与信息工程学院,武汉 430062;2.湖北省软件工程工程技术研究中心(湖北大学),武汉 430062;3.智慧政务与人工智能应用湖北省工程研究中心(湖北大学),武汉 430062)
0 引言
随着网民数量的增长,越来越多的评论信息不断涌现。网民可以在政府网站、微博等公众平台发表对各类事情的看法,表达自己的情感态度。自然语言处理中的情感分析任务在其中扮演越来越重要的角色,发挥重要的作用。从政府的角度来看,通过舆论来分析公众对社会热点事件的情感,了解公众舆论,对政府及管理部门防范危险事件的发生具有一定的意义;从企业角度来看,可以利用舆情提高自身的综合竞争力;从公众角度来看,可以利用舆情导向为自身生活工作提供重要的参考依据。当前,无论是在政府平台,还是网络电商行业都有情感分析方面的应用,但由于语言的复杂性、多样性,以及随着时间发展不断涌现的网络词汇等因素的综合影响,中文文本情感分析任务仍具有挑战性,且具有较大的研究价值。
为了更好地应用文本的语义信息、上下文信息以及各通道之间的关联信息,提升模型对文本情感分析能力,本文将广义自回归预训练语言模型XLNet 与循环卷积神经网络(Recurrent Convolutional Neural Network,RCNN)相结合,提出了一种基于XLNet-RCNN 的文本情感分析方法。在三个公开情感分析数据集上与其他现有方法进行对比实验,结果验证本文方法在文本情感分析任务中的有效性。
1 相关工作
文本分类任务中的二分类问题情感分析主要包含两个重要步骤,首先是文本特征提取,其次是文本特征分析与分类。其中对文本特征的提取与表示,许多相关专业研究者耗费大量时间精力对其进行探索研究。例如传统机器学习中的分类算法有朴素贝叶斯(Naive Bayes)、支持向量机(Support Vector Machine,SVM)、K 最邻(K-Nearest Neighbors,KNN)方法等,这些机器学习方法都曾被普遍应用于工业领域,但其缺点是构造分类器之前,需要构建复杂的特征,工程成本较高,并且采用传统词袋(Bag-of-Words,BoW)模型表示文本,导致文本特征数据存在维数高、矩阵稀疏等问题,因此导致文本分类效果不佳。
在深度学习研究中,出现了更为有效的文本表示方法。Mikolov 等在2013 年提出Word2Vec 模型对提取到的文本特征进行表示,Pennington 等在2014年提出全局向量(Global Vectors,GloVe)对文本特征进行表示。上述两种文本特征表示方法虽能有效解决特征表示维度的问题,但是这两种方法均采用静态方式对文本特征进行表示,未考虑文本的位置信息,对于同一词在不同上下文关系却表示为相同的词向量,也不能解决一词多义问题。
为了解决文本信息表示不准确问题,Peters 等提出了基于双向长短期记忆网络的语言模型嵌入(Embeddings from Language MOdels,ELMO),Radford 等提出了生成式预训练(Generative Pre-Training,GPT)模型,其中GPT使用了Transformer 的decoder 结构,但其在文本encoder 方法存在不足。Devlin 等提出了基于Transformers的双向编码预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)避免了GPT 模型出现的问题;Lan 等在2019年提出了轻量化的BERT 模型ALBERT(A Lite BERT);曾诚等提出的ALBERT-CRNN 情感分析方法对情感分类效果进行了提升,但其未充分考虑文本语序问题。基于Transformer-XL特征提取器的提出,Yang 等提出了XLNet,该模型将Transformer-XL 的分割循环机制和相对编码范式(relative encoding)整合到训练中,并对Transformer-XL的网络参数进行修改,移除其模糊性,相较于其他模型提升了效果。
情感分析任务中文本特征分析分类方法可分为三种:词典和规则方法、传统机器学习方法和深度学习方法。其中前两种分析分类方法实现简单,原理容易理解,但对于不同领域的泛化能力和迁移能力较差,分类的准确度也不高,因此基于深度学习的情感分析分类方法越来越受到关注。Socher 等将循环神经网络(Recurrent Neural Network,RNN)结合上下文信息应用到自然语言处理任务中。Kim为解决传统算法不足,提出文本卷积神经网络(Text Convolutional Neural Network,TextCNN)对输入文本进行卷积、池化计算,获取文本的多维信息。Cho 等提出了基于循环神经网络的长短期记忆(Long Short-Term Memory,LSTM)。在此基础上,Dey 等改进出LSTM 的另一个变体门控循环单元(Gated Recurrent Unit,GRU)网络,该模型将长短期记忆网络的输入、遗忘门合并修改为更新门,同时也融合细胞、隐含两种状态,使得新模型更加简单实用。由于卷积神经网络(Convolutional Neural Network,CNN)不能获得输入文本中的长期依赖关系,循环神经网络在提取评论文本特征时可能出现训练不稳定无法提取深层语义信息的情况,并且对整个评论文本进行单向建模有可能会忽略一些对文本分类重要的局部上下文信息,导致其在一些文本分类任务上出现性能不佳等问题。针对以上所述问题,Lai 等提出了一种结合CNN 与BiGRU 的RCNN 模型,该模型使用BiGRU双向抽取深层语序信息,并使用CNN获取文本的重要成分,充分利用了CNN和BiGRU各自的优势,显著提升了模型的效果。
2 相关基础模型
2.1 广义自回归语言模型XLNet
现有的预训练语言模型可分为自回归(AutoRegression,AR)语言模型和自编码(AutoEncoder,AE)语言模型。AR 仅能学习到依赖关系,AE 仅能学习到深层双向语义信息,两种模型单独使用都存在一定的不足。
XLNet结合了AR 和AE 的优势,弥补了单独使用AR和AE 语言模型的不足,在AR 上实现双向预测。XLNet 的核心思想是使用排列语言模型(Permutation Language Model,PLM)方法,将句子中的token 随机排列组合,然后用AR 来预测末尾的token,这样既可以利用当前token
的双向位置信息,也可以学习到各token 之间的依赖关系。具体PLM 实例如图1 所示。假设原始输入文本为{1,2,3,4,5},使用PLM 随机打乱序列顺序,然后依次使用AR 预测token,每个token 都可以利用前token 信息。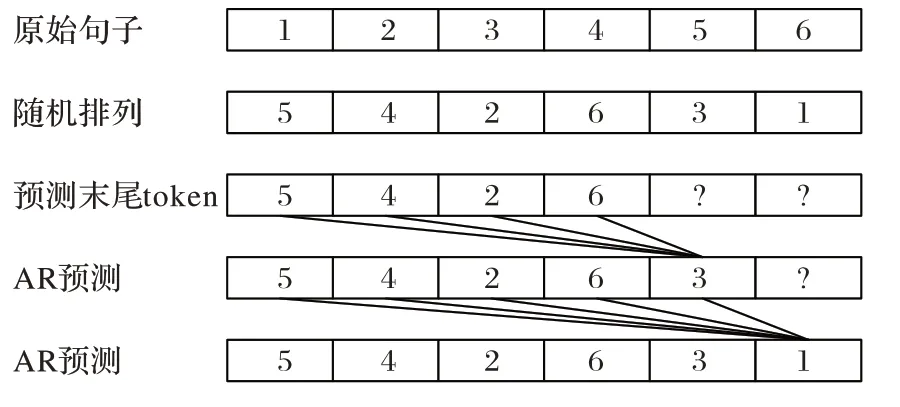
图1 排列语言模型实例Fig.1 Permutation language model instance
XLNet 是一种可以获得双向上下文信息的自回归语言模型,该模型是在大规模无监督语料上训练所得,可以通过上下文动态计算向量,用来表示字的多义性。该模型的核心是以排列组合的方式重构输入文本。由于重构方式打乱了句子的顺序,而在预测时token 的初始位置信息也非常重要,并且在预测时需要将token 的内容信息遮蔽,如果将待预测的信息输入,模型就无法学到知识。因此XLNet 采用双流自注意力(Two-Stream Self-Attention)方法计算:Query Stream 计算每个token,其中包含token 在原始句子中的位置信息,而Content Stream 用于计算每个token 的内容信息。具体计算方法如图2 所示。
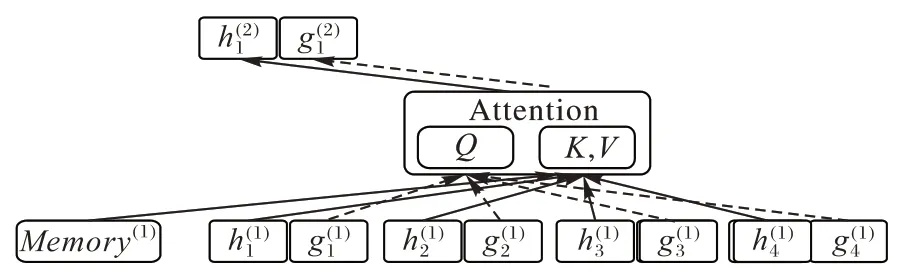
图2 双流自注意力计算Fig.2 Two-stream self-attention calculation
Query Stream 用g
表示,Content Stream 用h
表示,使用其对位置进行预测时,Q
(Query)向量是用g
计算得到的,包含token 的位置信息,而K
(key)和V
(value)是通过h
计算得到,其中包含其他token 的内容信息。其中Memory
表示前一个XLNet 中的内容信息。对于XLNet 中的Transformer-XL 在继承了Transformer 结构的基础上引入循环机制和相对位置编码的概念。为了更加快捷地处理数据,首先在评论文本数据输入阶段把文本序列划分为固定长度的文本片段,其次使用Transformer 提取评论文本片段信息,但是这样就会遗失相邻文本序列的语序相关信息,长期以来甚至比不上机器学习模型RNN。因此,引入RNN 来提取隐藏状态信息,作为文本长期依赖的基础,Transformer-XL 将隐藏的状态信息插入片段中,并存储前一阶段提取的文本片段信息,最后将其提供给下一个片段进行预测。这样不仅可以防止序列信息的丢失,而且可以更充分地挖掘和保留长距离文本信息。图3 所示为评论文本序列间引入循环机制,从而实现隐性状态信息循环传递,其中灰线表示储存的状态信息。因为BERT 模型提取语义信息时没有储存前一序列的信息,所以在预测X
时没有可以利用的信息,从而导致预测过程存在不足。而XLNet 模型则可以利用前一序列中储存的X
、X
、X
信息,帮助下一序列进行预测,实现了信息的循环传递。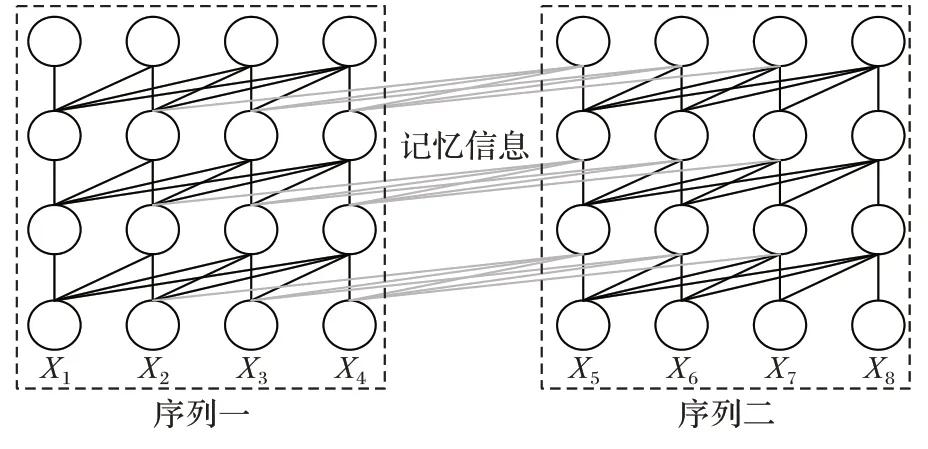
图3 XLNet循环机制信息传递Fig.3 XLNet cycle mechanism for information transmission
基线Transformer 未充分考虑不同片段中出现同一词的可能性,而在对评论文本位置编码过程中这种情况是存在的,如果仍然使用绝对位置编码,那么同一字在不同语境的表示完全一样,则不能体现同一个字在不同语境中的区别。绝对编码公式如下所示:
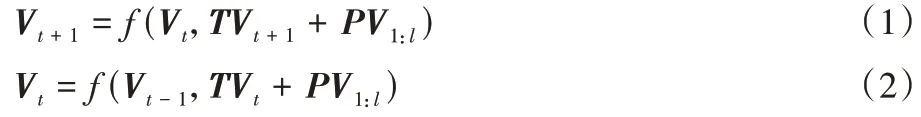
V
表示当前序列向量编码;V
表示上一序列向量编码;TV
表示当前片段文本向量编码;PV
表示当前序列位置编码。可以发现不同序列中PV
是不变的,即若文本序列中存在相同的字,则字的编码表示是一样的。因此,为了更直观地体现绝对位置编码与相对位置编码之间的区别,列出了基线Transformer 中各文本序列的自注意力机制公式: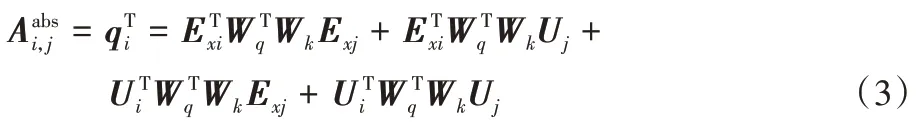
E
、E
分别表示i
,j
的文本序列向量;U
、U
分别表示字i
,j
的位置向量,因为使用的是绝对位置向量,所以U
=U
;W
表示权重矩阵。引入相对位置编码后,基线Transformer 的自注意力机制公式变为: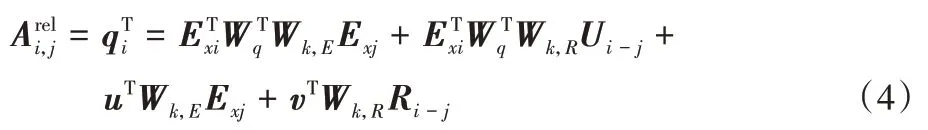
R
表示第i
字与第j
字之间的相对位置距离。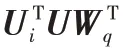
XLNet 以Transformer-XL 框架为核心,通过引入循环传递机制和相对位置信息编码,可以充分利用文本语境信息,并且结合每个字上下文的信息,更好地表征字的多义性,体现了自回归模型的优越性。
2.2 RCNN
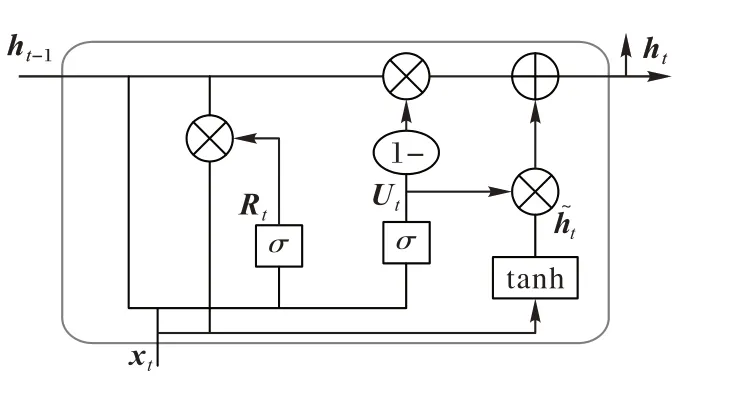
图4 GRU结构Fig.4 GRU structure
RCNN 由循环神经网络与CNN 结合而来,网络结构如图5 所示。RCNN 主要由双向门控循环网络BiGRU 层和池化层组成。式(5)、(6)将文本预处理得到的特征X
,X
,…,X
输入到双向循环神经网络BiGRU 中学习输入文本的上下文语境信息得到F
、F
;式(7)将BiGRU 层输出的上下文特征与预训练输入的特征相拼接,并通过tanh 激活函数计算归一化后文本特征F
;式(8)将计算输出的文本特征F
进行池化MaxPool 操作得到文本特征F
,池化操作可以使神经网络将有利于分类的特征放大,提高分类的准确性,最后使用Softmax 进行分类,从而得出文本的情感极性。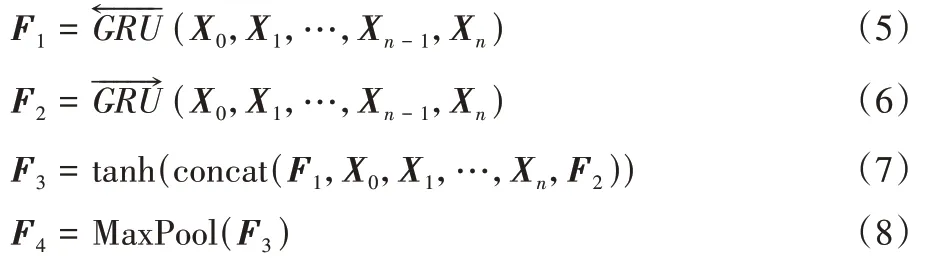
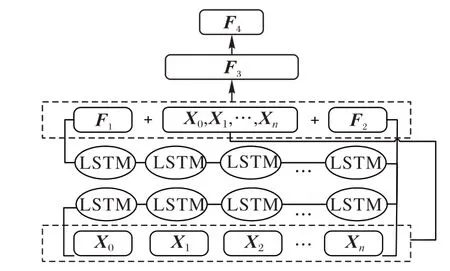
图5 RCNN结构Fig.5 RCNN structure
3 XLNet-RCNN情感分析方法
本文提出的XLNet-RCNN 文本情感分析方法主要包括以下步骤:1)对数据集进行清洗,剔除不规范或会对分析结果产生影响的噪声数据;2)在自回归语言模型XLNet 上使用截取文本平均长度的方法进行微调(fine-tuning)训练,得到最优效果,并保存文本的动态特征;3)使用结合BiGRU 与MaxPool 的神经网络模型RCNN 对文本的动态特征进行训练,从而获得每条文本数据的深层语义特征;4)利用Softmax函数对文本的深层语义特征进行分类,最终计算出每条输入文本数据的情感极性。
XLNet-RCNN 方法的结构如图6 所示,主要由以下6 个部分组成:输入层、XLNet 层、RCNN 层(包括BiGRU 层和池化层)、池化层、Softmax 层和输出层。
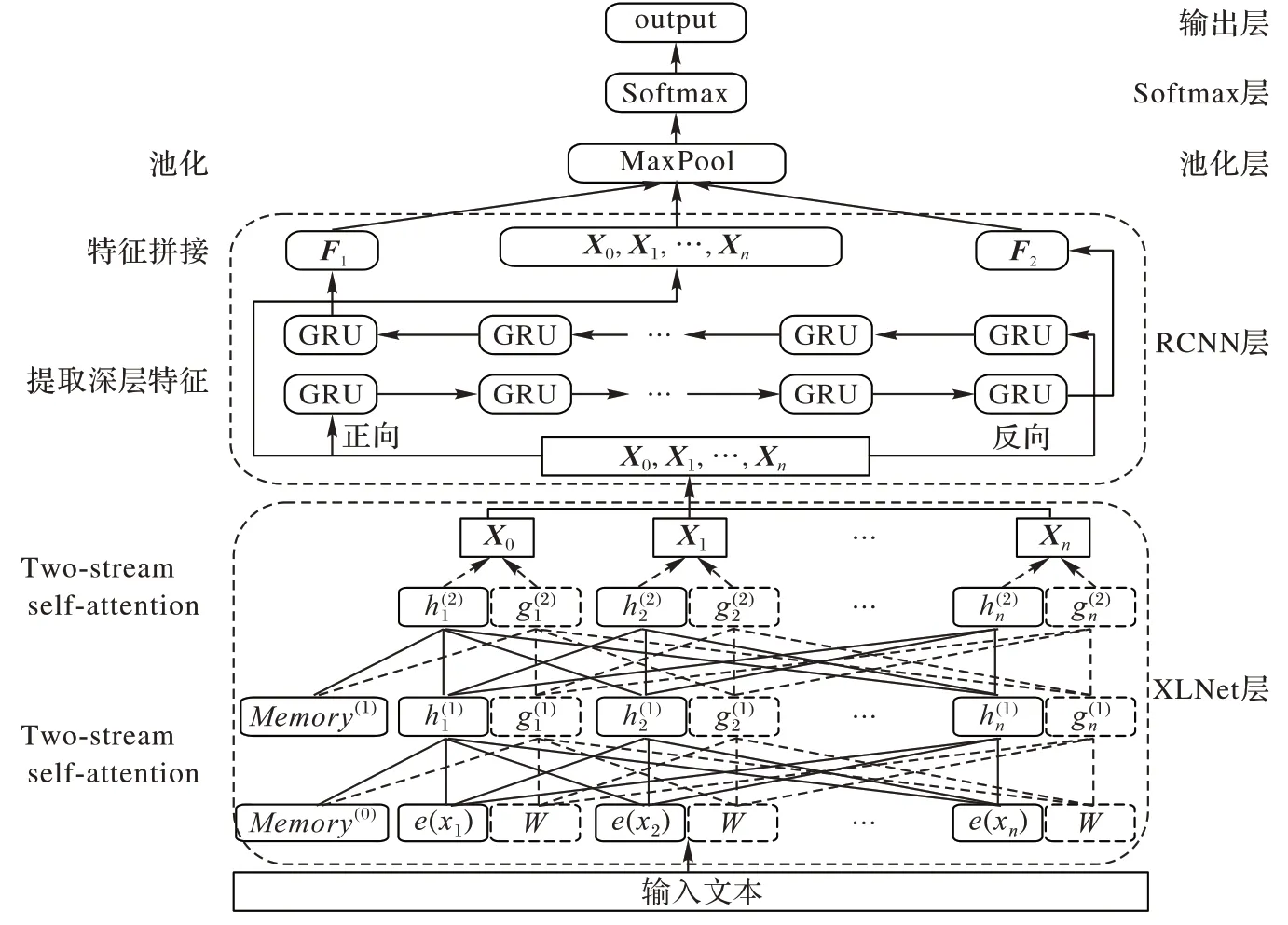
图6 XLNet-RCNN方法结构Fig.6 XLNet-RCNN method structure
具体实验流程如下:
步骤1 数据预处理。将数据文本进行正则化处理,删去影响情感分析的文本片段,例如微博数据集中评论的用户名会对分类结果产生影响,剔除不必要的用户名片段,提高数据的规范性。
步骤2 数据输入。在输入层将清洗后的文本数据输入到模型XLNet,输入的文本数据X=
(X
,X
,…,X
),其中X
表示该文本的第i
个字。步骤3 提取文本特征。将XLNet 层输入的文本数据序列化处理,并将文本数据X
中的每个字转化为其所在字典中所对应的编号,以获得序列化的文本数据E=
(E
,E
,…,E
),其中E
表示文本中第i
个字的序列化表示。利用Transformer-XL 自回归编码器对序列化后的文本进行训练,获取文本数据的动态特征表示。文本数据的特征表示为T
=(T
,T
,…,T
),其中T
表示第i
个字的特征向量。在使用Transformer-XL 自回归编码器提取文本特征时,首先计算当前文本中每个字与其他字之间的相对位置关系,然后利用这些相对位置信息去调整每个字的权重,从而获得句子中每个字新的表征。通过这种方法训练出的文本特征表示T
充分利用了句子中字的相对位置关系,使得一个字在不同上下文语境中有更好的表达,较好地区分了一个字在不同上下文语境中的不同含义。步骤4 提取深层语义特征。将文本特征T
分别传给BiGRU 层的前向GRU 层和后向GRU 层。前向GRU 顺序提取文本T
的深层语义特征,后向GRU 逆序提取文本深层语义特征,通过多个GRU 隐藏单元的训练,最终得到两个文本向量的上下文语义特征,分别记作F
和F
。步骤5 文本特征拼接及分类。将正向深层语义特征F
、文本数据特征T
和反向深层语义特征F
拼接,得到完整的语义特征,最后通过激活函数和全连接层输出分类。步骤3 中的XLNet 对文本进行排列组合是在Transformer-XL 内部通过Attention Mask 矩阵来实现的,通过Attention Mask 矩阵可以得到不同的输入文本排列组合,使模型能够充分提取并融合输入文本的上下文信息,避免有效信息丢失,弥补了BERT 模型的不足。图7 所示为XLNet 中Mask 机制实现方式的实例,假设原始输入文本为{1,2,3,4,5},随机生成文本序列为{3,2,1,5,4},而在输入阶段输入的文本仍然是{1,2,3,4,5},那么XLNet 中的掩盖机制如下所示。对于“1”,它只能利用“2”和“3”两个的信息,所以在第一行中只保留第二、三位置的信息(图中用实心表示),而其他位置的信息被掩盖(图中用空心表示)。再比如“3”位于第一个位置,没有可以利用的信息,因此在第三行全部以空心表示。
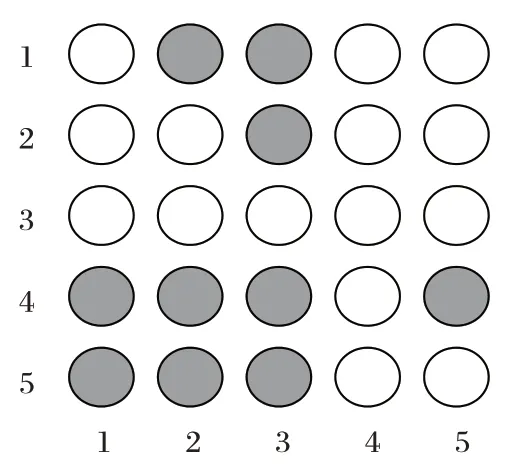
图7 XLNet模型Mask机制实例Fig.7 Mask mechanism instance of XLNet model
这种特征提取方式在最大限度上利用了XLNet 模型语义提取的优势,因此得到了更优的分类效果。
4 实验与结果分析
4.1 实验环境与数据
通过对比实验来验证所提方法的效果,实验开发工具使用Pycharm-2021.1,开发语言Python-3.6.8,采用深度学习框架Pytorch-1.2.0,操作系统为Windows,硬件设备为Intel Xeon Gold 5218处理器和NVIDIA GeForce GTX5000-16G显卡。
本文实验采用文本情感分类任务中的三个公开中文情感分析数据集weibo_sentiment(简称wb)、waimai_10k(简称wm10)和ChnSentiCorp(简称Chn)测试方法处理情感分析任务的性能。wm10 数据集来源于百度外卖平台收集的用户评价,其中包含4 001 条正向情感数据和7 987 条负向情感数据。Chn 数据集来源于哈尔滨工业大学谭松波老师收集整理的酒店、笔记本与书籍三个领域的评论语料,其中包含5 322 条正向情感数据和2 444 条负向情感数据。wb 数据集来源于新浪微博评论,其中包含59 994 条正向情感数据和59 996 条负向情感数据。由于本文使用三个不同的数据集进行模型训练,因此在训练时需要对每个数据集的文本长度进行分析,取数据文本平均长度作为最大序列长度,通过数据集文本长度统计将Chn 数据集最大序列长度设置为140、wm10 数据集最大序列长度设置为40、wb 数据集最大序列长度设置为80,并且对超过平均序列长度部分的进行截取剔除,对文本序列长度低于平均序列长度的文本进行空白填充,具体数据集统计情况如表1 所示。
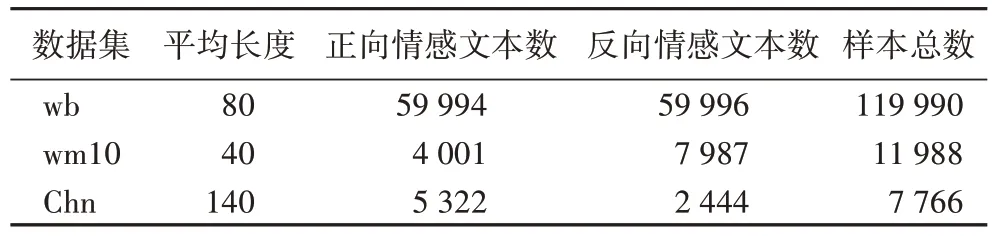
表1 数据集统计信息Tab 1 Dataset statistical information
由于这些数据集正负情感倾向分布极为不均,因此本文对以上数据集进行数据预处理,其中包括剔除影响用户名信息、将繁体字转化为汉字、将所有字母转化为小写字母等处理。数据清洗清洗过程及结果如表2 所示。最后按照8∶1∶1的比例划分为训练集、测试集和验证集。

表2 数据清洗结果Tab 2 Data cleaning result
4.2 评价指标
为评价方法的情感分析效果,本文采用混淆矩阵(confusion matrix)对结果进行统计验证,并通过4 个实验评价指标:准确率(Acc
)、精确率(P
)、召回率(R
),F
1 值对分类结果进行分析。计算公式为: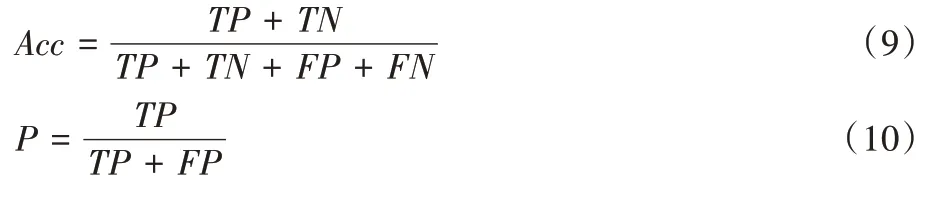

TP
表示正样本被预测为正,FP
表示负样本被预测为正,TN
表示负样本被预测为负,FN
表示正样本被预测为负。4.3 实验参数设置
实验中参数的选取直接影响最优的实验结果。如表3 所示,本文XLNet 模型实验参数主要包括XLNet 和RCNN 模型的参数。其中XLNet 采用科大讯飞AI 研究院与哈尔滨工业大学社会计算与信息检索研究中心联合发布的XLNet中文自回归语言模型XLNet-base-Chinese,可根据具体训练来调整超参数值,从而达到最优实验效果。通过训练调整参数值,XLNet、RCNN、XLNet-RCNN 方法的训练参数如表3 所示。
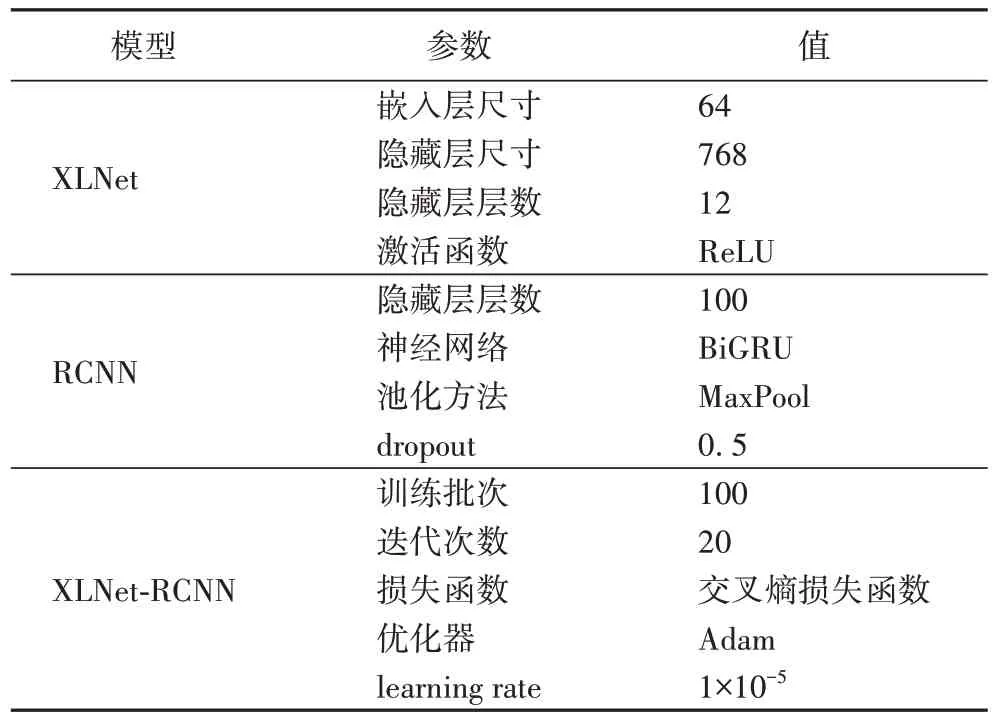
表3 模型的训练参数Tab 3 Model training parameters
4.4 对比模型
为验证本文方法的有效性,将本文方法与TextCNN、TextRCNN、BERT、XLNet、XLNet-CNN 和XLNet-RCNN 在wb、wm10、Chn 三个数据集上分别进行对比实验,其中:TextCNN、TextRCNN 均基于Word2Vec 构建词向量;BERT 采用Google 发布的中文预训练模型;XLNet 采用科大讯飞AI 研究院与哈尔滨工业大学社会计算与信息检索研究中心联合发布的XLNet-base-Chinese 来进行文本特征表示,并在此模型上进行fine-tuning,微调至结果最优。
4.5 实验结果分析
在三个公开数据集上的精确率P
、召回率R
、和F
1 值结果如表4 所示。由实验结果可以看出,相较于TextCNN、TextRCNN、BERT、XLNet 和XLNet-CNN,XLNet-RCNN 方法在wb 数据集上的F
1 值分别提高了9.0、8.0、1.4、0.5 和0.3 个百分点;在wm10 数据集上的F
1 值分别提高了6.3、7.6、3.9、0.9 和-0.1 个百分点;在Chn 数据集上的F
1 值分别提高了11.2、10.2、6.0、0.8 和0.7 个百分点。从表4 可以看出,对于wm10 数据集,本文方法相较于XLNet-CNN 效果欠佳,原因是该数据集平均文本长度较短约为40;TextRCNN相较于TextCNN效果较差,原因是TextRCNN 针对短文本数据时无法发挥其优势导致结果较差。这说明了RCNN 在文本分类任务中较擅长处理中长文本,而对于短文本本文模型提升有限,因此出现以上结果。
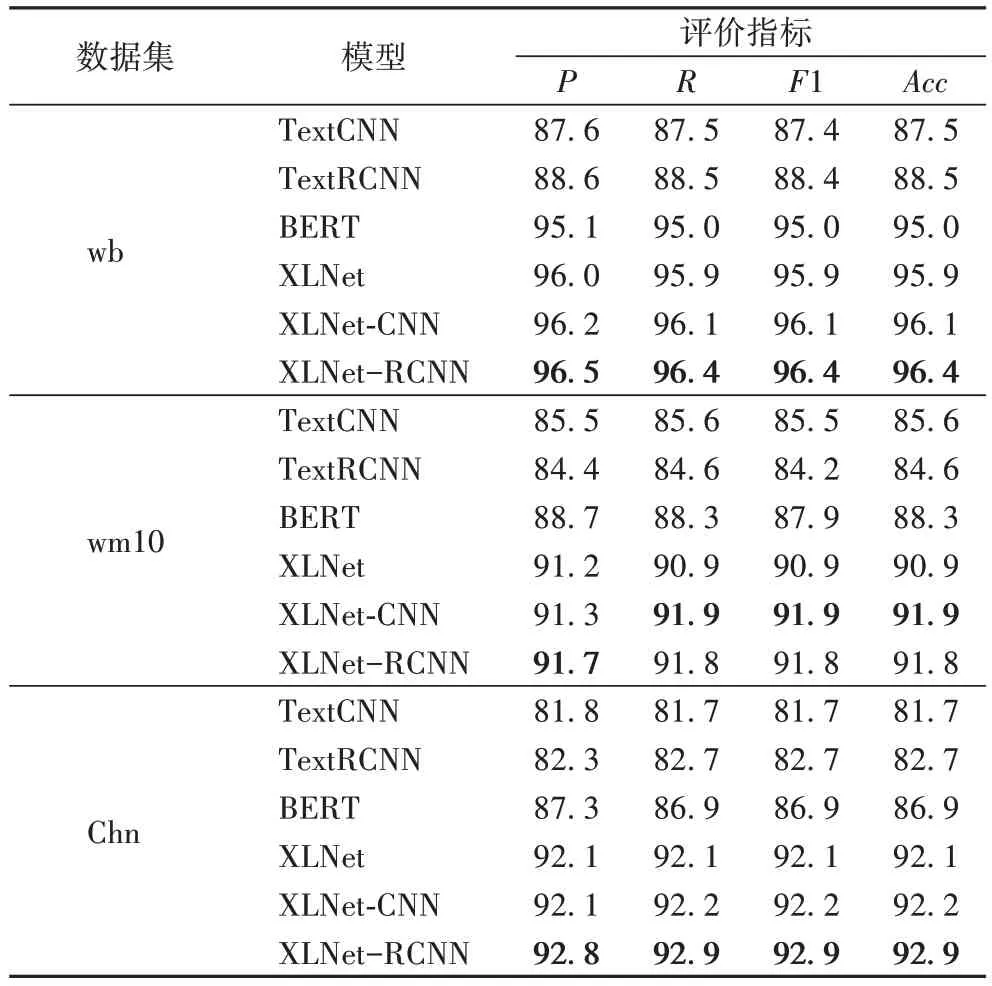
表4 各模型在三个数据集上的评价结果 单位:%Tab 4 Evaluation results of models on three datasets unit:%
由实验结果可以得出,相较于其他Word2Vec 构建词向量的模型,XLNet 和XLNet-RCNN 在文本情感分析领域分析有明显的优势,证明自回归语言模型提取的文本特征能够利用句子中字的上下文信息,较好地区分了一个字在不同上下文的不同含义,从而提升了模型在情感分析任务中的效果。总体上来看,XLNet-RCNN 相较于XLNet 及其他模型在文本情感分析任务中有更优的表现,证明融合RCNN 模型能够充分获取文本深层语义信息,使本文方法在情感分类任务的效果得到了提升。
由表4 可以发现,相较于TextCNN、TextRCNN、BERT、XLNet,XLNet-RCNN 在文本情感分析中有更优的效果,在三个公开数据集上的准确率分别达到了96.4%、91.8%、92.9%,本文方法在文本情感分析任务中有更好的效果。
使用实验保存的最优模型,预测单个评论文本数据的情感极性,以验证本文方法在真实场景下的情感分类准确性。文本样例测试结果如表5 所示。

表5 文本样例测试结果Tab 5 Text sample test results
为验证输出结果情感极性的正确性,将预测值大于0.5视为正向情感,将预测值小于0.5 视为负向情感。从表5 中的预测结果可以看出,XLNet-RCNN 对文本情感分析结果都是正确的,能够应用于真实场景中的情感分析任务。
5 结语
为了更好地将自回归语言模型XLNet 应用于文本情感分析任务中,本文提出一种结合XLNet 和RCNN 的文本情感分析方法XLNet-RCNN。使用XLNet 解决了传统情感分析方法在不同语境下无法区分同一个词的不同语义问题,根据每个字的相对位置来表征字向量;使用RCNN 模型进行特征训练能够充分关联文本的上下文关系,能较好地提取文本的深层文本语义特征。在wb、wm10、Chn 三个公开数据集上进行对比实验,验证了XLNet-RCNN 方法在文本情感分析任务中的优越性。但针对短文本数据,本文方法仍存在改进空间。在实验过程中发现,由于模型参数量较大,对于数据量较大的数据集,短文本分类任务效果提升不明显,出现实验花费时间较长、对硬件设施要求高等问题。在下一阶段的研究中,考虑将本文方法应用到多情感分析任务中,探究该方法在多情感任务的中的适用性;对XLNet 进行改进,探究影响方法结果的因素,使用知识蒸馏的方法压缩模型,在不降低较多准确率的情况下,提升模型训练的速率。将本文技术应用于实际生活,为分析网络言语情感提供技术支持。
