
基于情感词典和堆叠残差的双向长短期记忆网络的情感分析
2022-05-07 07:07罗浩然
计算机应用 2022年4期
罗浩然,杨 青
(1.华中师范大学伍伦贡联合研究院,武汉 430079;2.华中师范大学计算机学院,武汉 430079;3.国家语言资源监测与研究网络媒体中心,武汉 430077)
0 引言
教育类机器人是教育行业和工业界的一次基于发展的人工智能技术的尝试,然而对这一部分用户反馈的研究大部分仍停留在人工分析使用自然语言的购物评论的阶段。对于此类新兴技术的文本分析,仅使用标准的情感词典或某类神经网络是不够的,因为针对该领域的情感词汇极少,也没有有效、科学的分类模型或情感得分量化的算法。基于此,本文的工作主要在于:1)通过无监督学习、聚类算法的结合,合理设置情感分类的一、二级影响因素;2)通过构造情感词典和深度学习模型并将两者结合,提高特定领域的情感分类的精准度。
二分法的思想被普遍应用于情感分析中,其中情感分为“积极”和“消极”,一些学者添加了“中立”情感作为补充。对于情感分析来说,情感分类是核心步骤。在这一步中,研究人员需要识别指定文本的主观观点,并判断文本的正面和负面倾向。早年,基于情感词典的方法是根据经验总结和整理广泛使用的情感词,并将预处理后的输入与词典中的情感词进行匹配。具体来说,需要在输入中搜索与情感词典中重叠的情感词,判断这些词的极性,然后得到整个句子的情感取向。分类效果取决于情感词典的完整性。Kim 等利用词典将手工采集的种子情感词集进行扩展来获取大量的情感词,但是这种方法的效果对种子情感词集的个数和质量依赖性比较大。在接下来的十几年里,许多学者在情感词汇的研究中不断探索,李勇敢等通过以词序流表示文本的LDA(Linear Discriminant Analysis)-Collocation 模型,采用吉布斯抽样法推导了算法,实现中文微博情感倾向性自动分类。Tan 等提出了一种基于半监督特征提取的情感分类系统,该系统融合谱聚类、主动学习、迁移学习等不同方法提取情绪特征,应用迁移学习的方法完成整个情感分析系统的构建。在搜狐学习评论、搜狐股票评论和中关村电脑评论语料库的实验中,这种半监督特征提取的方法的最小f
值可达82.62%。然而,传统的情感分类方法往往需要高质量的特征构造,如N
元模型(N
-Gram)。基于深度学习的抽象特征可以避免人工特征提取,通过词的嵌入模拟词与词之间的关系,具有局部特征提取和记忆存储的功能。Johnson 等在深层金字塔卷积神经网络(Deep Pyramid Convolutional Neural Network for text categorization,DPCNN)中引入了残差结构,增加了多尺度信息,并且增加了用于文本分类卷积神经网络(Convolutional Neural Network,CNN)的网络深度,以提取文本中远程关系特征,并且并没有带来较高的复杂度。Rajasegaran 等通过借助CNN 的成功经验引入“DeepCaps”这一种深囊网络结构,并在其中使用基于3D 卷积的动态路由算法。借助DeepCaps,该方法在CIFAR10、Street View House Number(SVHN)和Fashion Mixed National Institute of Standards and Technology(FashionMNIST)性能上超越了最新的胶囊域网络算法,同时减少了68%的参数量。Zhang 等针对特定任务,对于每个方面层级设计了基于注意力机制的注意力向量,该机制涉及两个子向量,即维度注意力向量和情感注意力向量,从语义空间的角度解决了神经网络设计过于复杂的问题。但是,这类具有特定领域属性、短文本、复合情感的评论的情感分析模型存在着诸多局限性:单一使用情感词典存在情感词汇覆盖率低,编纂、维护词典工作量大,无法洞察语句中上下单词的联系的问题;而单独使用深度学习方法,在处理一些特定领域的文本时容易出现过度过滤和错误处理语气助词、修饰词的情况。因此,本文以科大讯飞、小度、狄刺史、天猫精灵四个智能教育机器人品牌为例,通过爬取在线评论数据、数据清洗并构建一种基于堆叠残差的双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络和人工构建的情感词典结合的情感分析算法来判断评论的情感取向,量化产品质量、性价比和外观的情感指数,然后将情感指数标准化为某个情感极性的概率,以完成分类任务。研究路径如图1 所示。
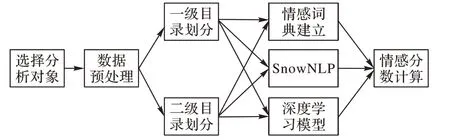
图1 研究路径图Fig.1 Research roadmap
1 数据处理
1.1 数据预处理
本文选取中国四大知名教育机器人品牌旗下的最新型号机器人作为研究对象,包括天猫精灵CC10、小度智能机器人旗舰版、科大讯飞阿尔法大蛋2.0、狄刺史H2,同时选取的四款产品也属于不同价位,以便于纵向对比。通过基于Python 的爬虫软件“后羿采集器”,在淘宝、京东、苏宁易购等电商平台上收集了2019 年至2021 年每个品牌的15 000 条在线评论,最终获得60 000 条评论。
由于自然语言的随机性和非标准化,原始数据中存在很多噪声,如语法结构混乱、错别字模糊、传统字符和重复注释,无效的评论、广告和其他问题。如果这些数据被直接输入到情感分析模型中,深度学习模型将会学习到大量无意义的数据,模型的分类精准率将严重降低。为了过滤冗余数据,本文采取了两个步骤进行数据清理:首先,使用正则表达式来清理字符串。然而正则化虽然可以初步过滤数据,但仍达不到使用标准,这是因为在评论中仍有许多经常被广泛使用但没有实际意义的汉字或英文字母。因此本文以中国科学院开发方汉语词法分析系统的停用词表作为基础停用词表,结合购物评论的特殊性,添加了部分特定领域内的停用词,如机器人品牌、颜色、型号、html 标签名称等。最终,本文使用的停用词列表的条目总数为2 072。最后,使用“庖丁分词”对经过正则表达式和停用词表处理过后的文本数据进行分词。
1.2 数据分析
1.2.1 词频统计
为了初步了解关键词的分布情况可以计算数据的词频。NLTK(Natural Language Toolkit)工具包可以用来计算单词特征,并建立频率分布表,导入matplotlib 用来可视化单词频率。四个品牌的词频可视化结果如图2 所示。
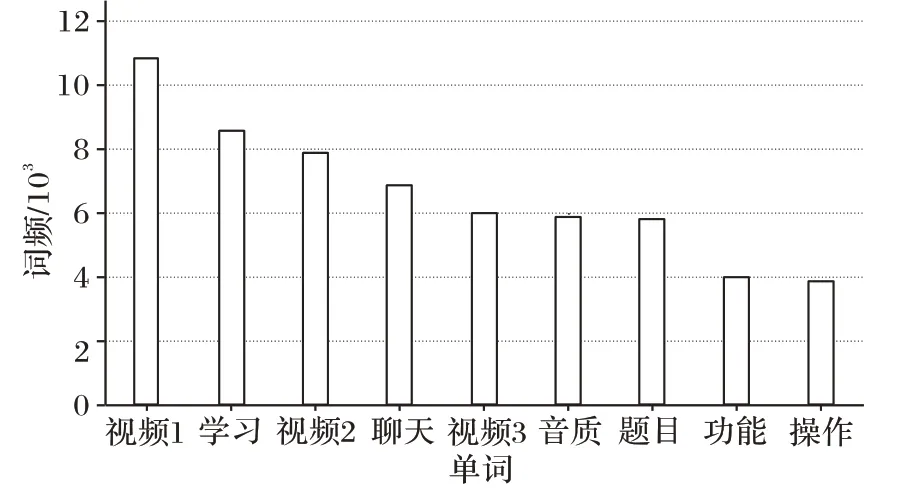
图2 词频统计Fig.2 Word frequency statistics
1.2.2 关键词提取
本文需要对产品的衡量维度进行划分,主要采取“两级”划分法则。主要思路是:首先,通过数据处理和关键词提取技术得到一定数量的关键词作为一级分类,使用聚类算法衡量语句相似度划分一级目录下的二级目录;然后,通过人工情感标注处理后的文本放置在各个分类目录下,经过词向量转化过程进入情感分析的步骤。这样划分后的文本评论会根据所属的不同维度被初步分类,方便观察分类算法对于不同维度分类下的文本的分类效果,以上过程如图3 所示。
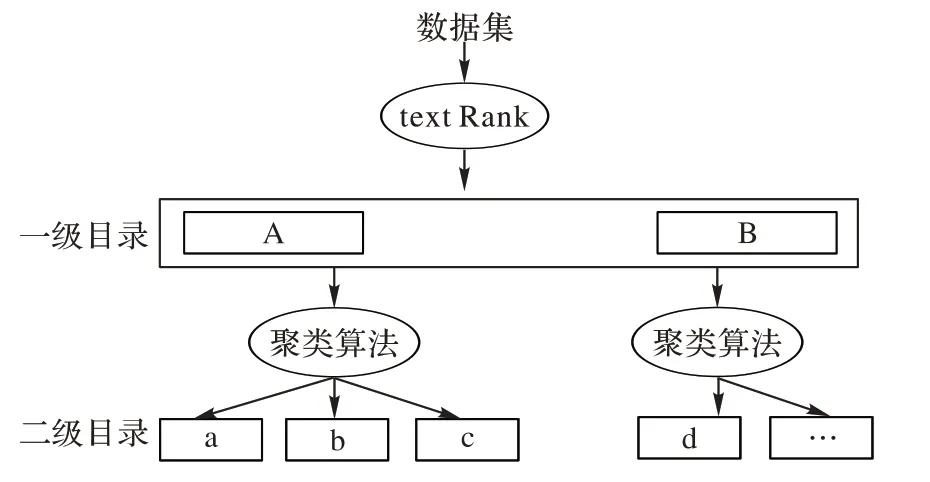
图3 两级划分规则Fig.3 Two-level division rules
1)一级关键词提取。在进行关键词提取时,主要有三类方法:基于统计的词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)方法、基于词共现图的TextRank 方法和基于词语网络的方法。其中:单独使用TFIDF 无法同时精准地反映单词在一篇文本中的重要程度和特征词的分布情况;而词语网络的构造相对复杂,各类参数设置复杂。因此本文采用基于词共现图的方法进行关键词提取。
TextRank 算法是一种基于图的排序算法,通过移动共现窗口表示词语之间的联系程度,对后续关键词排序的同时从文本中提取出关键词。TextRank 是对PageRank 的改进算法,该算法着力构造词汇网络图模型,词语间的相似关系被看成是一种投票关系,计算每一个词语的重要程度,具体计算如式(1)所示:
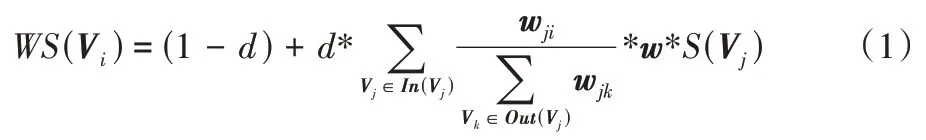
WS
(V
)体现词语的重要程度,d
为阻尼系数,w
表示两个节点之间的边连接具有不同的重要程度,In
(V
)是节点V
的入度点的集合,Out
(V
)是节点V
的出度点集合。下面结合本文的中文文本评论数据集对上述公式做具体分析:首先将每个品牌的评论的评论集T
按照句子进行分割,即T=
[S
,S
,…,S
],对于每个分割结果S∈T
进行分词和词性标注,在过滤停用词后只保留指定词性为名词的词语,即S=
[d
,d
,…,d
],其中d
代表候选关键词,并由此构建关键词图G=
(V,E
),其中V
是上一步得到的候选关键词的集合;然后根据共现关系(若两个关键词在长度为k
的窗口中同时存在则认为存在共现关系)构造两点之间的边集E
。此外,本文中设置d
为经验值0.85。根据式(1),递归传播各关键词的权重,直至收敛。将关键词的权重进行倒序排序,取权重值最大的t
个单词作为关键词。虽然TextRank 可以用来计算词语的重要性,但是算法不能解决词语的重要性的差异对相邻的节点权值转移的影响问题,基于此本文最终使用了一种TextRank 的改进算法,即使用TF-IDF 和平均信息熵两个特征来计算词语的权重,用计算得到的综合特征信息来改进TextRank 词汇节点的初始权重大小以及概率转移矩阵从而共同决定关键词的选取。经计算分析,得到一级关键词如下:学习、影视、交互、用户体验、价格。2)二级关键词提取。经过独热编码转化后的数组作为数据输入,使用Word2Vec 的CBOW(Continuous Bag-Of-Word)模式下的神经网络层对二级影响因素的单词进行向量化处理。因此,为了得到某一领域中某个词的向量,首先要对该领域的评论集进行预处理,然后利用Gensim 模块的API 接口添加Word2Vec 训练词向量模型。本文使用文本聚类方法K
均值(K
-Means)聚类算法获得词向量的聚类结果,使用轮廓系数评价聚类质量。在获得每个单词的词向量后,绘制上一步收集到的特征词的向量表示。在使用K
-Means进行聚类分析时,首先初始化K
个质心,计算属于数据集的每个待算数据与K
个质心之间的欧氏距离,找出最小值,将数据添加到相应的簇类中。然后,计算聚类集之间的均方误差,并对聚类类中每个向量与质心之间的距离进行累加。通过不断调整K
值和迭代次数,最终发现当K
=5 时,均方误差达到最小值 0.334 7,轮廓系数达到最大值0.796 8(图4)。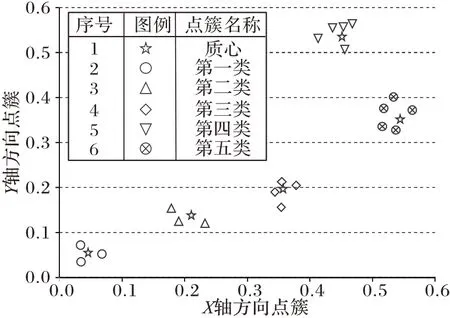
图4 K-Means聚类结果Fig.4 K-Means clustering result
综上所述,结合文本聚类技术和电子商务点评系统的相关研究和一级分类因素得到二级分类因素,其中:学习分类下包括教学、做题、问题、搜题;影视分类下包括视频、音质、娱乐;交互分类下包括语音、对话、聊天、回答、陪伴;用户体验分类下包括颜色、手感、尺寸、外形;价格分类下包括便宜、性价比。共计一类分类因素5 个,二类分级因素18 个。
2 情感分析模型构建
构建情感分析模型是情感分析里的核心任务。本文基于传统方法和深度学习模型相结合的思想提出了如下方法进行情感分类:将Python 的文本数据库SnowNLP、传统情感词典和Bi-LSTM 共同作为情感评分模型的参考维度,通过合理设置各部分参数比重最终得到用户的整体情感得分和各种影响因素的个人得分,并标准化为概率值作为预测结果。通过预测结果和真实值的比较,可以反映模型预测的精准度。
2.1 情感分类模型设计
在计算每个评论的情感评分时,首先要完成文本分类。目前常用的情感分类方法有机器学习中的分类算法(如支持向量机和朴素贝叶斯)和深度学习中的分类算法。
机器学习的方法主要用有监督的(需要人工标注类别)机器学习方法来对文本进行分类。循环神经网络(Recurrent Neural Network,RNN)是一种基于时序逻辑的神经网络结构,因此适合处理诸如天气预测、人类自然语言语义预测等关注前后事件发生的顺序及其联系的任务。RNN 的基本结构如图5 所示。
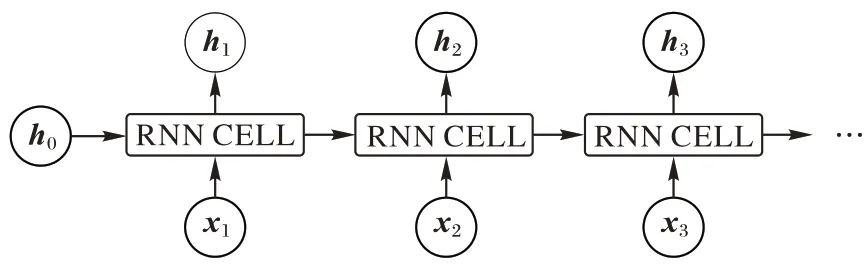
图5 RNN结构Fig.5 Structure of RNN
如图5 所示,拆分的RNN 结构由初始状态h
、输入时间序列x
和输出时间序列h
组成,对于每一个RNN 的单元细胞都具有相同的隐层结构,根据任务需求可以增减每个细胞内隐层的层数。每一轮生成的更新状态h
在输出的同时还参与到下一组的运算当中,和输入序列x
共同作为输入参数进入细胞内的隐层迭代运算。RNN 虽然可以一定程度上处理句内前后文之间的联系,但是在反向传播训练时,如果维度过大、参数过度会出现梯度弥散的问题。LSTM 是RNN 的一种改进版本,主要用来解决RNN 梯度消失和梯度爆炸的问题。Bi-LSTM 是前向LSTM 和反向LSTM 的组合。
如图6 所示,LSTM 的一个环节中包括t
时刻的输入数据x
、细胞状态C
、隐层状态h
、遗忘门f
、记忆门i
、输出门o
。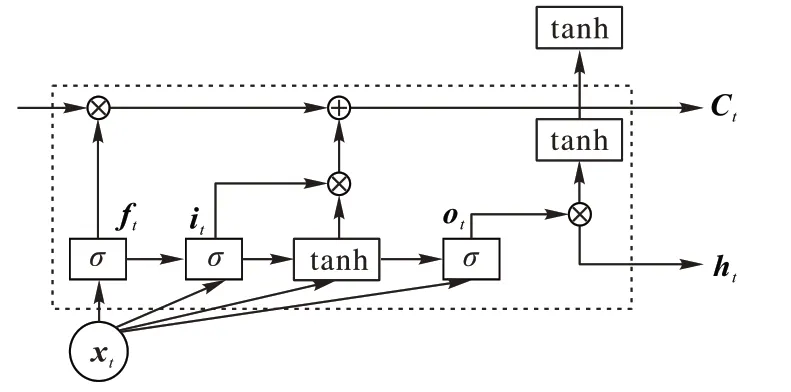
图6 LSTM结构Fig.6 Structure of LSTM
LSTM 的具体计算流程如下:传递遗忘细胞状态下的部分信息,并记住新的信息,在随后的时刻计算有用数据时使用这些信息。无效信息被丢弃的同时,输出每个时间步的隐藏层状态h
,其中忘记步骤、记忆步骤和输出步骤被遗忘门f
、记忆门i
和输出门o
以及前一时刻的隐层状态h
和当前输入间的x
共同控制计算。在一些分析情况下,预测可能需要由前一个输入和后一个输入来确定,后者将更准确;因此,双向RNN 被提出,其网络结构主要包括四个层次:词向量层、前向传播层、反向传播层和连接层。在分析时,首先将句子分词,然后经过词映射层将单词转化为词向量并传入前向LSTM 层,而前向层和反向层与输出层相连。前向层从时间1 到时间t
进行正向计算,每次得到并保存隐含层的输出。反向层沿时间t
到时间1 进行反向计算,获取并保存反向隐含层每时每刻的输出。最后,将每一时刻前向层和后向层对应时刻的输出结果相结合,得到每一时刻的最终输出。就文本分类任务来说,学术界普遍认为改进的LSTM 或Bi-LSTM 相较于早期版本的RNN 有着更好的分类效果;然而,即便使用标准的Bi-LSTM,因为模型深度有限,所以在处理一下语义关系比较复杂、前后文关系比较强的文本时分类的精准度仍然有待提高。
近年来,随着诸如VGG(Visual Geometry Group)、InceptionNet和ResNet等层数很多的神经网络架构被提出,增加神经网络的深度来提高学习模型的性能的猜想得以证实。由于能够学习到更好的特征表示,对于语言建模任务,应用深层架构从理论上来说具有可行性。其中,一种较为流行的做法是使用堆叠的LSTM 模型,但是相较于DAN(Deep Averaging Network)这一类层数较浅的模型,堆叠模型很容易遇到“退化”问题。
此时,无论是增加隐层层数还是叠加LSTM 数量都无法有效地提高预测的精确度,模型也趋于饱和。由此可见,模型的优化难度和堆叠的层数是正相关的。基于此,本文将构造一种基于残差网络和堆叠的LSTM 结合的神经网络预测给定文本的情感类别,将每个LSTM 层中引入残差连接块解决退化问题。
如图7 所示,n
个模型层的隐层状态h
和每一轮的输入向量x
相加,通过残差连接进行学习,隐层状态h
的更新公式如式(2)所示: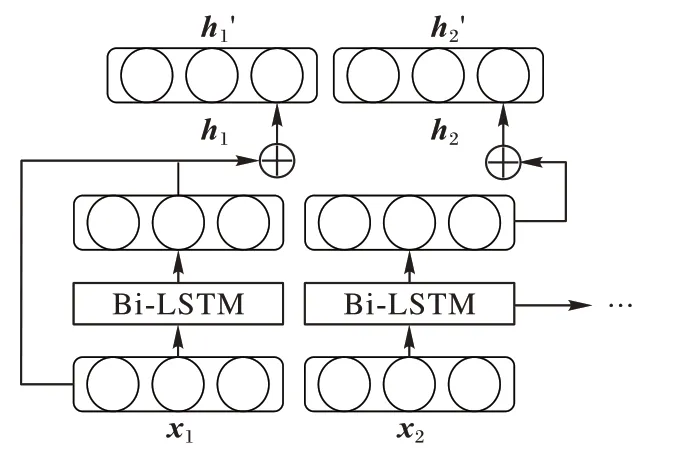
图7 残差连接的Bi-LSTM单元Fig.7 Bi-LSTM units with residual connection
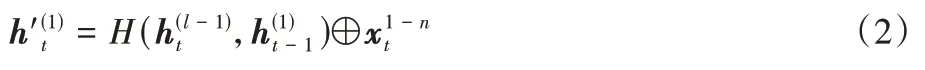
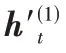
图8 堆叠残差的Bi-LSTMFig.8 Stacked residual Bi-LSTM
如图8 所示,该模型为一个8 层的堆叠残差Bi-LSTM 结构,每两个堆叠层后连接一个残差层。对于每个残差连接的矩阵加法无需学习参数,从而避免模型复杂度的增加。同时由于LSTM 是以结果偏置的模型,因此句尾单词相较于句首有更高的影响程度,然而这一点对于文本预测而言是不利因素,因为自然语言中,关键词的出现位置不具有固定规律。基于此,该模型使用平均池化层学习文本向量,从而使得每个单词对于预测结果具有同等程度的贡献。最后,使用Sigmoid 激活函数输出二分类的预测结果。
2.2 情感分类
市场上一些收费的自然语言处理(Natural Language Processing,NLP)功能集成平台虽然具备一定的泛化能力,也能处理多个互联网领域(餐饮、汽车)的情感极性分析工作,但是对于短文本的教育类产品评价的分类效果较差,本文将结合深度学习和机器学习类库、情感词典的方法构建基于情感词典和堆叠残差的Bi-LSTM 的情感分析模型。具体的构造思想是:根据预处理后的数据建设程度副词词典、否定词词典、机器人产品用户评论词典,SnowNLP 情感词典计算基本情绪分值,结合Bi-LSTM 模型,将Softmax 激活函数输出极性是0(消极)或1(积极)的概率,将概率转化为极性对应的得分,与基本得分共同计算得到最终的情感得分;然后再通过标准化算法,输出为0~1 的数值,当数值大于0.5 时认为是积极情感,当数值小于0.5 时认为是消极情感,从而完成情感分类工作。
2.2.1 词典结构
1)程度副词词典。本文根据知网程度水平词构建程度副词词汇库,并根据极值(权重2)、高值(权重1.75)、中值(权重1.5)和低值(权重1.25)分别赋予权重,计算情感得分,以上权重皆基于程度副词词典构造一般经验赋值。
2)否定词词典。本文收集了80 个负面词汇作为负词词典的组成部分,权重设为-1。当否定词在句子中出现的次数为奇数时,表示否定意义;当一个否定词在句子中出现的次数是偶数时,表示肯定意义。
3)教育机器人情感词典。本文构造的评论情感词典充分考虑了当代电商平台用户在各种电子商务平台和论坛上的公众言论和用户习惯,并结合了互联网上的各种流行词汇,这使得情感词典具有及时性和全面性。本文在台湾大学NTUSD 简体中文情感词典的基础上根据5 个分类标准和332个对应于学习、影视、交互、用户体验和价格方面的常见情感词,通过删除多余情感词、增加适用情感词构造了教育机器人评论情感词典(见表1)。
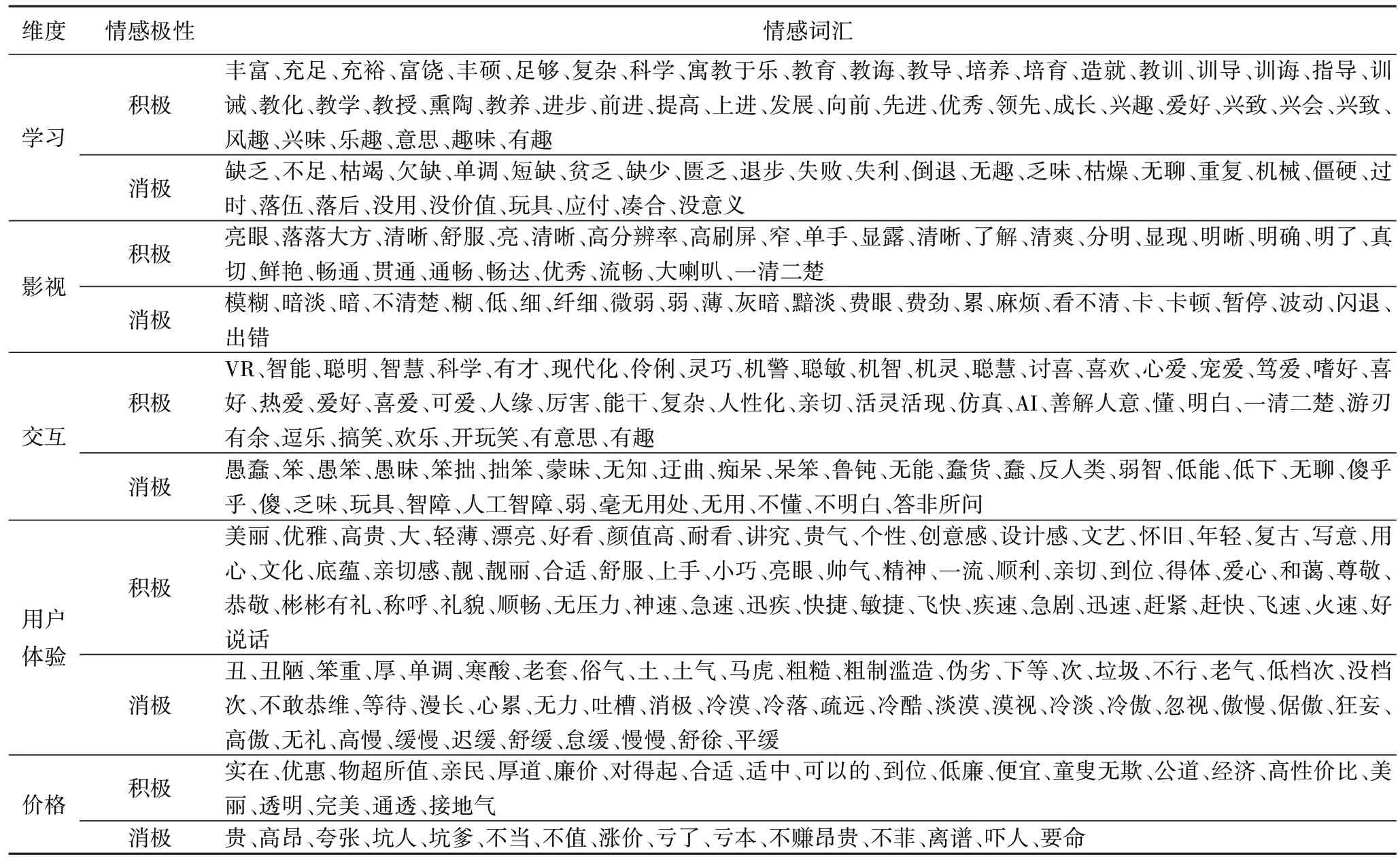
表1 教育机器人补充情感词典Tab 1 Educational robot supplementary sentiment lexicon
2.2.2 情感得分计算
基于情感辞典的情感得分计算:当每次要分析的单词与机器人评论词典中的积极情感单词匹配时得分+1 分;当与机器人评论情感词典中的负面情感词汇匹配时-1 分。从语句的第一个单词开始遍历,如果单词前面存在一个程度副词,则用程度副词权重乘以单词分数。如果在程度副词之前仍然有否定词,则将否定词的权重、程度副词的权重和词的分数相乘。遍历整个评论直到没有情感词出现,累加每个部分的分数得到机器人评论情感词典计算的总分。基于深度学习的情感得分计算:Bi-LSTM 是一种深度学习模型,用于预测文本极性值的概率。
模型中隐层的Softmax 激活函数可以输出判别结果的概率p
,1-p
得到相反结果的概率值。Bi-LSTM 可以通过学习大量的文本特征来反映句子中单词和单词之间的关系,因此,通过判断一个句子是积极的还是消极的概率,可以从侧面反映出句意是积极(消极)的程度,这种抽象意义上的度量可以量化为情感得分。在本文中,从激活函数输出的概率值被转换为情感得分:以判断一处句意为积极的语意为例,当输出概率在[0.8,1]时,情感得分+2 分;当输出概率在[0.5,0.8)时,情感得分+1 分;当输出概率在[0.2,0.5)时,情感得分-1分;当输出概率在[0,0.2)时,情感得分-2 分。在计算出情感辞典和Bi-LSTM 对文本的得分计算之后,再使用SnowNLP 进行得分计算。SnowNLP 情感得分的计算方法是将句子的情感程度转化为[0,1]的情感得分。在得到基于教育机器人评论情感词典、SnowNLP 和Bi-LSTM 的情感得分后,可以计算总分并将其标准化到[0,1]。以评论“东西然贵,但非常智能,物流神速,视频无比清晰”为例,从机器人评论情感词汇中可以看出,“贵”是负面情感词,“智能”“神速”“清晰”是正面情感词,“非常”“无比”是极端程度副词,基于机器人评论情感词汇的得到分数S1(+4);分析Bi-LSTM输出的结果为0.73,属于范围(0.5,0.8],因此得分S2(+1);基于SnowNLP 计算的整句情感得分为S3(+0.89)。最后,将总分标准化为[0,1]上的概率值,完成一次情感评分,并根据评分判定评论的情感极性(得分大于或等于0.5 判定为积极,得分小于0.5 判定为消极)。
根据图9 示例语句,经过本文构造的补充机器人情感词典后根据分值权重计算出了初步得分4 分,经过堆叠残差的Bi-LSTM 模型后获得情感得分1 分,经过SnowNLP 后获得0.89 分的情感加分,最终得分5.89 分,经过标准化后得到0.83 分,根据判断规则该语句情感倾向为积极。
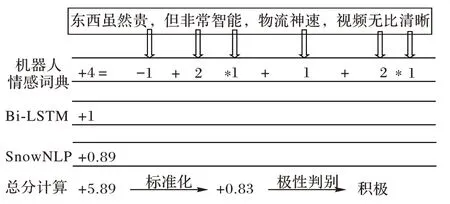
图9 情感得分计算Fig.9 Sentiment score calculation
在这个过程中,三个部分的情感得分计算是可以同步进行的,因为它们彼此并不需要其他部分的得分或者结算数据作为自身计算时的参数,所以并不强调先后顺序上的差别。
在本文实验环境下,对于该情感得分计算模型而言,在情感倾向极为强烈时情感词典的得分占比较大,而在情感倾向不太强烈时深度学习模型的得分占比较大。而总分计算和标准化的过程必须置于情感得分计算模型中的三个计算步骤之后。
3 实验与结果分析
3.1 实验数据集
在实验阶段,本文使用经过清洗的数据集中48 000 条评论作为训练集在数据预处理后进行模型训练,训练的模型包括两种分类模式(机器学习和深度学习),其中机器学习分类模式分为两种特征提取方法(基于单词的特征提取方法和基于双词的特征提取方法),共7 种分类算法;深度学习包括6种既有分类算法以及本文构建的基于堆叠残差的Bi-LSTM和情感词典的分类模型。在训练集结束训练后,对于训练好的分类模型再使用带有积极的标签和消极的标签的12 000 条评论作为测试集,用以测试不同的分类算法在各个二级分类下的准确率,最后,将各个二级分类目录下的分类准确率累加求均值,得到一类分类目录下的分类准确率,选择分类准确率最高的方案。
在将该套方案存为备选之后,后续过程中如果更新、拓展数据集(该模型分类的准确率依赖于数据集的状态,过时的数据集学习出的分类模型将损失很多准确率),会产生新的分类模型,分类准确率可能也会因此而改变,因此需要适时更新分类方案。
其中,在与其他机器学习和深度学习模型进行分类性能对比时,本文选取了机器学机器学习模型算法包括伯努利朴素贝叶斯(BernouliNB)分类器、多项式朴素贝叶斯(MultinomialNB)分类器、线性回归(Linear Regression,LR)、支持向量机(Support Vector Machine,SVM)、线性支持向量机(Linear SVM,LinearSVM)、核支持向量机(Nuclear SVM,NuSVM)。测试的分类维度分为500、1 000、1 500、2 000、2 500 和3 000;深度学习模型包括LSTM、深层循环神经网络(Deep Recurrent Neural Network,DRNN),双向循环神经网络(Bi-directional Recurrent Neural Network,BiRNN),RNN,BERT(Bidirectional Encoder Representation from Transformers),Elmo(Embeddings from Language models)。以上模型均为机器学习、深度学习领域进行NLP 尤其文本分类任务较为常用的模型。除此以上模型外,也可以使用其他的分类模型进行对比。
3.2 实验准备
根据上述构建的影响因素规则和情绪评分系统,得到教育机器人每条评论的情感得分,再结合各影响因素的整体情感评分和情感极性,计算各二级、一级分类下评论的情感得分均值,判定不同二级、一级分类整体的情感极性。如表2所示,在一级因素中,“交互”的情感极性最倾向于负面,而对应的二级因素中大部分的品牌在“语音”“对话”“聊天”中得到的分数较低,低于0.5 的得分也对应了判定为“消极”的预测结果,而“影视”对应的评论中积极情感占据主导。从表2中可以得到以下推论:智能教育机器人在当前阶段更多地承担起一个影音、娱乐、学习、陪伴性质的工具,而在交互方面很难达到较高层次的“智能”。因此,一些AI 机器人和传统的MP4 等影音播放器的边界较为模糊,这一方面受限于现有人工智能技术的应用能力,一方面也和产品的价位有关。然而,虽然多数产品在“交互”分类下的“语音”“对话”“聊天”等二级分类的表现不佳,但是普遍在“陪伴”分类中获得了较高的分数,这表明对于幼儿、儿童来说,即便是提供了传统的影音娱乐功能的机器仍然能一定程度上满足用户的心理需求。
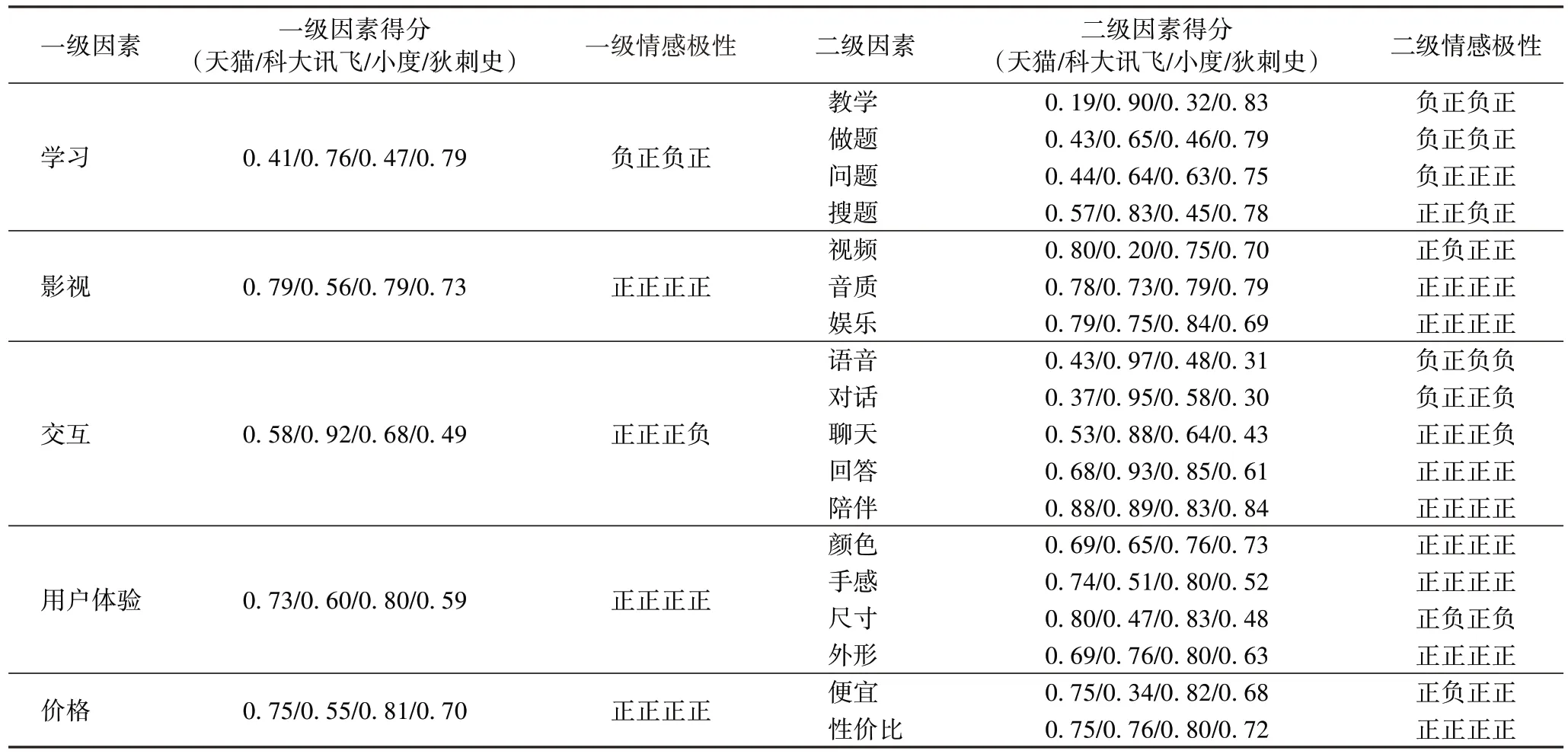
表2 各个维度情感得分及极性判别Tab 2 Sentiment score of each dimension and polarity discrimination
在搭配了一些网络教育资源和较为成熟的教育系统后,很多AI 机器人也能满足低年级学生的学习需求。对于一些价格较高、搭配了较强的人工智能技术的早教机器人,在“性价比”一项上得分较低,这从侧面反映了许多用户在对于该类高端产品时仍然保持观望态度。在获得了构建的模型的分类情况后,可以将预测结果与人工标注的真实值从不同维度做误差分析,本文用精确率、召回率、准确率和F1 值来综合衡量不同算法的性能表现。
3.3 结果与分析
对比分析环节将详细对比本文模型和其他模型在训练集上的准确表现。为对应1.2.2 节中的二级目录,分为一级因素和二级因素分别测试每个目录下的分类准确率情况。训练集情况和训练后基于本文构建的复合文本分析模型在验证集上的准确率结果以及所属关键词的评论数目情况如表3 所示。
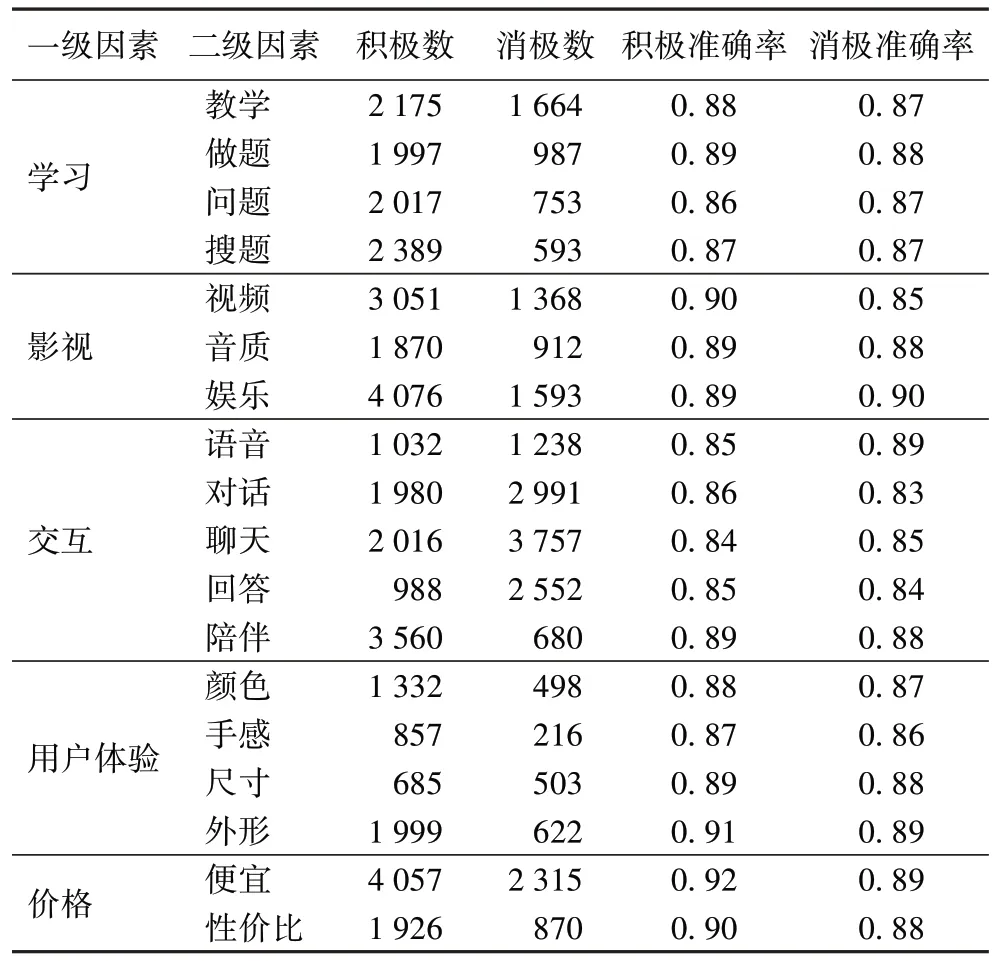
表3 基于情感词典和堆叠残差的Bi-LSTM的模型准确率Tab 3 Accuracy of sentiment lexicon and stack residual Bi-LSTM based model
从表3 中简单计算可知:该模型对于积极感情的整体预测准确率约为0.883,对消极情感的整体预测准确率约为0.874,整体准确率约为0.879。对于积极情感的预测准确率高于消极情感,其中:在“价格”方面预测的整体准确率最高,约0.910;在“交互”方面预测的整体准确率最低,约0.858。回顾数据集,这和用户在交互领域评论更趋向于使用反语、讽刺语、俗语、比喻等较难为机器理解的修辞手法和文法、语法有关,而在价格领域的评论较为直白,基本情感词典都能做到覆盖。
接下来使用机器学习的7 种分类算法分两种特征提取方法计算多个维度下的准确率,结果如图10 所示。对比以所有词为特征提取方法的机器学习领域的分类算法和以所有双词搭配为特征选取方法结果的机器学习领域的分类算法可以发现,虽然准确率随着分类维度的上升有所提高,但是普遍处于0.8 的分类准确率之下,其中:BernoulliNB 算法在所有维度始终低于0.8;NuSVM 算法的表现最好,整体的情感分类准确率维持在0.836 和0.840。
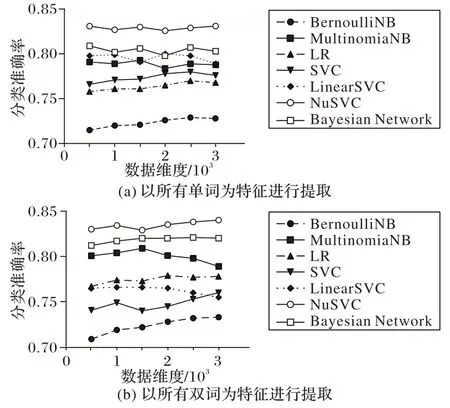
图10 2种特征方法下提取的分类精度Fig.10 Classification accuracy extracted by two feature methods
接下来,使用几类深度学习模型在训练集上进行训练,并通过验证集计算分类算法的精确率、召回率、准确率和F1分数。为方便对比,将本文模型和其他深度学习模型并列。
观察图11,本文模型在四项标准上均获得最高值,其次BERT 在各项分类指标上的数据表现最好,准确率达到0.859,LSTM 的整体准确率约为0.834。说明基于情感词典和堆叠残差的Bi-LSTM 模型在预测结果为积极情感的样本空间中的成功率较高;而RNN 的整体表现较差,这可能是因为RNN 存在梯度消失和梯度爆炸问题。虽然基于本文模型取得最高的准确率,但是在“交互”领域的分析效果仍不够理想。经分析推测原因如下:1)在该领域下存在较多的学术专业词汇,它们应该比普通词汇享有更高的情感权重;2)一些专业术语词汇由较长的英文单词或者英文和中文单词的组合构成,这些词组可能被正则表达式和停词表过滤掉了词组中的一部分,导致分词不完整、语义破碎的情况,从而影响了最终的准确率。纵观所有分类算法,对于正标签的分类效果普遍稍高于负标签、精确率普遍稍高于召回率,这说明负面情感的评论对情感词典的覆盖率以及模型的分析能力有着更高的要求,这可能是因为负面评论中有着更多的讽刺语、反语和借助特殊形式的表达。
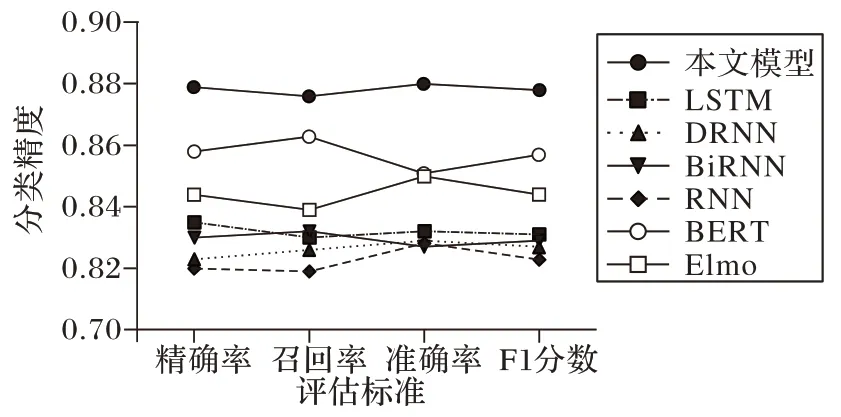
图11 深度学习模型分类结果Fig.11 Classification results of deep learning models
本文模型相较于其他机器学习、深度学习模型分类性能评估更好的原因主要在于克服了分类问题在两方面的不足:1)对特定领域的专业词汇的解读能力的不足。通过定性分析,结合二级分类目录的设置,补充了AI 教育机器人领域情感词汇,从而提高了对于特定词汇的分类准确率。2)堆叠LSTM 时模型精度上限的不足。通过在堆叠的LSTM 中加入残差连接,有效避免了高层数模型存在的网络“退化”问题,从而提高了通过增加模型深度从而实现性能提升的上限。
4 结语
本文虽然是针对于“AI 教育机器人”的评论建立的分析模型,但整套分析逻辑对于其他各类型评论类型的短文本情感分类工作都具有一定的重构意义,通过上文分析可以论证:将针对某个领域而编纂的情感词典和深度学习模型相结合,可以提高分析模型的准确率;而针对某个领域的情感词典可以在一套标准化的情感词典上根据该领域的特定情况而调整词典的范围,添加对于分析工作有价值的词汇,减少对分析工作有误导的词汇。本文实验的限制主要在于:1)数据集仅限于国内电子商务平台,对海外用户的分析仍然稀缺;2)Bi-LSTM 模型在处理带有多个负面单词的句子时表现不佳。增加注意机制将使模型的拟合度更高。此外,随着时代的发展,情感词典需要不断更新和修改,特别是对于像中文这类结构较为复杂的语言,建立词典的工作量相对庞大。
