
融合协同过滤信息的知识图注意力网络
2022-05-07 07:07顾军华李宁宁张素琪
计算机应用 2022年4期
顾军华,王 锐,李宁宁,张素琪
(1.河北工业大学人工智能与数据科学学院,天津 300401;2.河北省大数据计算重点实验室(河北工业大学),天津 300401;3.天津商业大学信息工程学院,天津 300134)
0 引言
近年来,随着互联网、大数据技术的快速发展,用户面临着信息过载的问题。为了缓解信息过载,推荐系统在电子商务、社交平台和新闻媒体等提供信息服务的应用中发挥着不可替代的作用。在传统的推荐系统中,协同过滤算法由于其高效性和健壮性,得到了广泛的研究和应用。协同过滤算法假设具有相似交互历史的用户对物品有相似的喜好,因此需要丰富的用户交互历史,使推荐的结果更可靠。然而,基于协同过滤的推荐系统面临着数据稀疏和冷启动问题。
知识图谱(Knowledge Graph,KG)中包含了丰富的物品属性信息和关联信息,将知识图谱作为辅助信息引入推荐系统,可以缓解数据稀疏和冷启动问题。因此,基于知识图谱的推荐模型得到了研究人员越来越多的关注。Wang 等提出的知识感知路径循环网络(Knowledge-aware Path Recurrent Network,KPRN)将用户物品二部图和知识图谱组合成一个新的知识图谱,然后使用长短期记忆(Long Short-Term Memory,LSTM)网络处理新的知识图谱中连接用户、物品的多条元路径,输出用户对物品的点击率。Wang 等提出的知识图谱卷积网络(KG Convolutional Network,KGCN)受到图卷积网络的启发,通过在知识图谱上聚合物品的邻居节点信息计算物品的向量表示,用于预测用户对物品的评分。Wang 等提出知识图谱注意力网络(KG Attention Network,KGAT)将用户―物品二部图与知识图谱结合,构建协同知识图,并使用图注意力网络计算用户向量和物品向量,最后采用向量内积的方式计算用户对物品的评分。Wang 等的协同知识感知注意力网络(Collaborative Knowledge-aware Attentive Network,CKAN)中提出用户的向量表示与知识图谱中实体的向量表示不在同一个向量空间,CKAN 基于图注意力网络计算知识图谱中物品的向量表示,然后结合用户交互历史中的物品向量表示计算用户的向量表示,最后依据用户向量和物品向量的相似度预测用户对物品的点击率。
现有的基于KG 推荐模型存在一个不足:这些模型将用户物品二部图(User Item bipartite Graph,UIG)视作KG 的一部分,采取相同的策略处理这两种信息。但实际上用户物品二部图中的协同过滤信息和KG 中实体间的关联信息的含义并不相同,如果采用相同的方式处理这两种信息,会导致学习到的用户向量和物品向量无法准确地表达用户和物品的特征。举例来说:如图1 所示,从UIG 上看,用户A 与用户B的交互历史极为相似,所以《泰坦尼克号》很可能是用户A 未来会交互的电影。从KG 上看,用户A 交互历史中的电影都有相同的属性“喜剧”和“剧情”,这表明用户A 对电影的偏好包含“喜剧”和“剧情”。如果将UIG 的信息和KG 的信息混合,那么通过{用户A,阿甘正传,用户B,泰坦尼克号}的信息传播路径,KG 中与用户A 无关的实体“爱情”和“悲剧”的信息将会传递给用户A,这将导致推荐结果中出现与用户偏好完全不符的电影《罗密欧与朱丽叶》。实际上,用户A 的向量中应该包含《泰坦尼克号》的信息,因为《泰坦尼克号》《阿甘正传》和《放牛班的春天》都是奥斯卡奖提名电影,看过《阿甘正传》和《放牛班的春天》的用户中绝大多数都会观看《泰坦尼克号》,而这种关联与KG 的属性信息无关,所以用户A的向量中不应该包含《泰坦尼克号》的属性“爱情”和“悲剧”。
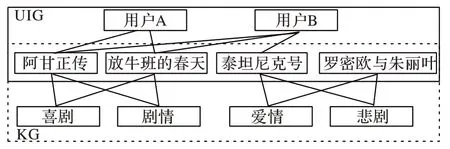
图1 用户物品二部图和知识图谱结合的例子Fig.1 Example of the combination of user item bipartite graph and knowledge graph
为了克服上述基于KG 推荐系统的局限性,本文提出了融合协同过滤信息的知识图注意力网络(Knowledge Graph Attention Network fusing Collaborative Filtering information,KGANCF)。该模型采用协同过滤层和知识图注意力层充分挖掘协同过滤信息和KG 中实体关联信息,避免了将二者相混淆影响推荐结果的准确性;在知识图注意力嵌入层中,模型结合用户和物品的协同过滤信息计算KG 中用户、物品关联实体的注意力权重,充分地利用了用户物品二部图中包含的用户与用户、物品与物品的相似性,强化了相似项目的特征表示。
1 相关工作
下面从协同过滤推荐和基于KG 的推荐两个方面介绍与本文相关的工作。
协同过滤推荐算法是推荐系统中应用最为广泛的算法。协同过滤算法认为:用户的交互物品表达了用户的直接偏好信息;物品的交互用户表达了物品的特征信息。以此为依据,协同过滤算法分为基于物品的协同过滤和基于用户的协同过滤。基于物品的协同过滤计算物品间的相似度矩阵来衡量目标物品与用户交互历史中物品的相似度,从而预估用户对目标物品的喜好程度;基于用户的协同过滤计算用户间的相似度矩阵,寻找与当前用户相似的用户,然后依据相似用户的交互历史进行推荐。
基于KG 的推荐在协同过滤推荐方法的基础上结合从KG 中学习到用户、物品的属性信息,计算用户和物品的向量表示,然后用向量内积的方式评价用户对物品的喜好程度。这类方法的研究重点在于如何将KG 中的属性信息融入到用户向量和物品向量中。近年,受卷积网络的启发,基于图信息传播的方法得到快速发展。KGCN对KG 中每个节点的邻居进行采样,基于节点间的关系计算邻居的权重,最终依据邻居的权重聚合邻居信息到中心节点上;KGAT结合用户物品二部图和KG,构造协同知识图,然后在协同知识图上应用图注意力网络聚合用户和物品的邻域信息。这类方法能够结合KG 的全局信息丰富用户和物品的向量表示。
2 本文模型
如图2 所示,KGANCF 模型主要分为三个部分:1)协同过滤层,对于输入的目标用户u
和待推荐物品v
,从UIG 中提取相应的协同过滤信息,得到用户的协同过滤向量u
、物品的协同过滤向量v
和用户所有交互物品的协同过滤向量集合{v
,v
,…,v
};2)知识图注意力嵌入层,基于注意力机制,从KG 中聚合用户交互物品集合{v
,v
,…,v
}和待推荐物品v
在KG 中的邻域信息,得到用户和物品的KG 属性向量u
和v
;3)预测层,通过神经网络结合前两步中得到的协同过滤向量(u
和v
)和KG 属性向量(u
和v
)得到用户和物品的最终向量表示u
和v
,预测用户对物品的点击率y
(u
,v
)。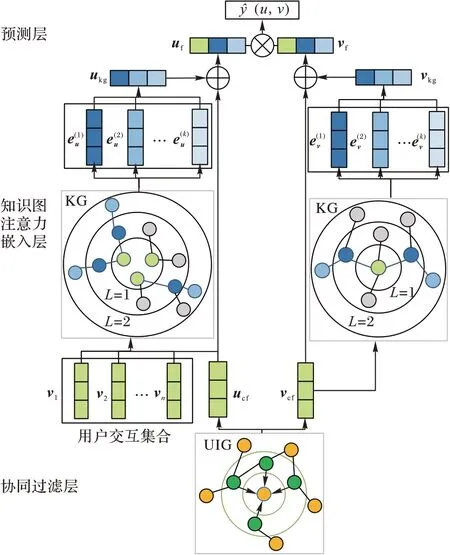
图2 本文模型架构Fig.2 Proposed model architecture
2.1 协同过滤层
本文模型首先通过协同过滤层提取UIG 中包含的协同过滤信息。协同过滤信息是从用户交互历史中反映出的影响用户决策的潜在因素。例如用户观看一部电影,除了该电影符合用户的偏好以外,还有可能受到从众心理(许多用户都观看了这部电影)、宣传效应(看到了该电影的广告)等外在因素影响,这些因素对用户的影响直接反映在用户的交互历史上。因此,协同过滤信息包含的范畴大于KG 中包含的特定属性信息,正如图1 的例子,《泰坦尼克号》和《阿甘正传》《放牛班的春天》同为广受用户好评的奥斯卡奖电影,但是这个信息并不包含在KG 中。
在第1 章介绍协同过滤算法的相关工作中提到,协同过滤算法认为:用户的交互物品表达了用户的直接偏好信息;物品的交互用户表达了物品的特征信息。基于该假设,协同过滤层通过图卷积操作聚合UIG 中节点的邻域信息,得到用户和物品的协同过滤向量表示。图卷积操作的定义如下:
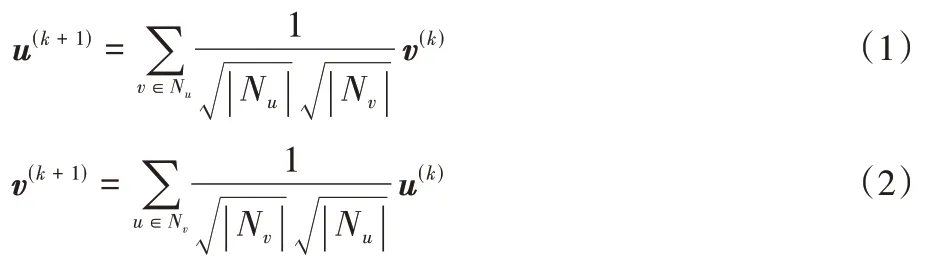
u
和v
为经过k
层卷积后的用户u
和物品v
的向量表示,N
代表用户u
的交互物品集合,N
代表物品v
的交互用户集合。经过K
层卷积后,模型结合各层卷积的结果获得用户和物品的协同过滤向量:
α
是每层嵌入向量的权重,其值被设置为1/(K+
1)。为了从整体角度理解图卷积,便于进行批处理,这里给出每一层卷积的矩阵形式:

A
是用户物品二部图中节点的邻接矩阵,D
是用户物品二部图中节点的度矩阵,E
是用户物品二部图中节点的嵌入向量矩阵。2.2 知识图注意力嵌入层
在2.1 节提到,用户的交互物品表达了用户的偏好信息。更进一步,用户的交互物品在KG 中关联的实体体现了用户偏好的具体物品属性。同样的,待推荐物品的具体属性由其在KG 中的关联实体确定。用户u
和物品v
在KG 上的初始属性实体集合如下:
G
代表KG 中所有实体和关系的集合;y
为用户和物品的交互关系,值为1 为用户u
交互过物品v
。从初始实体集合出发,模型对集合中实体的邻居进行逐层采样,从而得到用户u
和物品v
在KG 上的属性信息。采样得到的属性实体集合定义如下: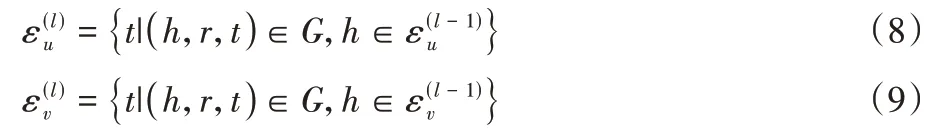
u
和物品v
的邻居节点,可以得到用户和物品在KG 中的相关属性实体信息,从而丰富用户和物品最终的向量表示。KG 中,由不同的关系连接的属性实体对用户(或物品)的重要程度是不同的,相似的用户(或物品)会有相似的偏好(属性)特征。举例来说,用户A 观看某部电影,因为这部电影与他之前看过的电影有相同的主演;用户B 挑选电影的时候可能更关心电影的导演;而与A 相似的用户C,同样会更关注电影的主演。为了描述这种关系,知识图注意力嵌入层在聚合KG 中的实体信息时,结合用户(或物品)的协同过滤信息和KG 中实体间的关系来确定某个属性实体的重要程度。
假设三元组(h,r,t
)是用户u
的第l
层属性实体集中某个实体t
所在的一个三元组,定义t
添加注意力权重后的向量表示为a
:
u
是2.1 节得到的用户协同过滤向量,e
和e
分别为关系r
和实体t
的向量表示,π
(u
,e
)是t
的注意力得分函数。π
(·)的定义如下: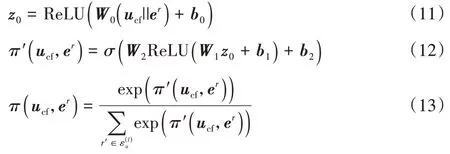
||
为拼接操作,W
和b
是待学习的参数,r′
为与属性实体t′
对应的关系。聚合多层属性信息得到用户的第l
层属性向量表示:
l
层属性向量表示:
u
和物品v
各自的k
层属性向量拼接,得到用户和物品的KG 属性向量:
2.3 模型预测
模型的预测层将前两步得到的协同过滤向量和KG 属性向量结合在一起得到用户u
和物品v
最终的向量表示: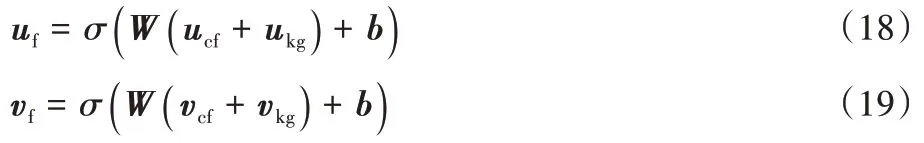
u
与v
的向量内积来衡量用户u
对物品v
评分:
最终,模型的损失函数定义为:

Γ
是交叉熵损失函数;P
是用户交互的正例集,P
是用户交互的负例集;θ
是模型待训练的参数;λ
是超参数,用来控制L
2 正则化项。3 实验与结果分析
本章基于电影和音乐领域公开的数据集进行实验验证模型的有效性,并讨论模型结构和参数对实验结果的影响。
3.1 数据集
实验选用电影推荐和音乐推荐两个场景下的公开数据集测试模型的性能。Last.FM 数据源自Last.FM 在线音乐平台,数据集中包含大约2 000 名用户的音乐交互信息。MovieLens-20M 是电影推荐场景下应用最广泛的公开数据集之一,其中包含了约2 000 万条用户的电影评分信息。实验将数据集按照6∶2∶2 的比例随机分为训练集、验证集和测试集。详细的数据统计结果见表1。
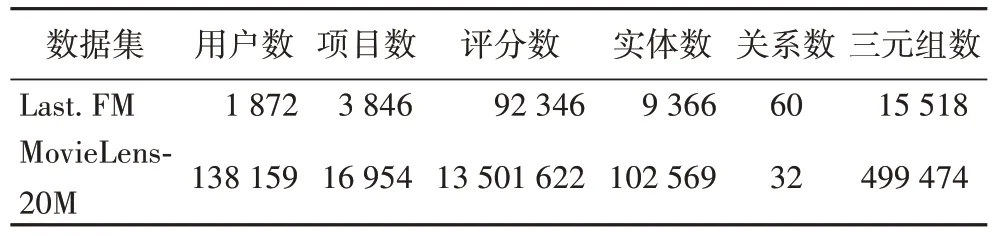
表1 实验使用的数据集Tab 1 Datasets used for experiment
3.2 参数设置
模型采用Xavier initializer来初始化模型参数,训练的批次大小设置为1 024。
超参数值的选取范围如下:学习率Lr
在{10,5×10,10,5×10}中选择,L
2 正则化项的系数λ
在{10,10,10,10}中选择,嵌入向量的维数d
在{8,16,32,64,128}中选择,用户和物品KG 属性集的大小S
和S
在{4,8,16,32,64}中选择。经过实验验证,模型最佳参数设置见表2。
表2 实验参数设置Tab 2 Experiment parameter setting
3.3 实验对照
为了验证模型的有效性,将KGANCF 与以下模型进行对比:
1)协同知识嵌入(Collaborative Knowledge base Embedding,CKE)是一个经典的将协同过滤算法与KG、文本等辅助信息相结合的模型。CKE 基于TransR 算法从KG 得到物品的属性信息,用于增强用户、物品的向量表示。
2)KGCN将图卷积网络推广到知识图推荐领域。通过对知识图节点进行邻域信息的聚合从而挖掘KG 中实体间的高阶关联信息,用以丰富用户和物品的向量表示。
3)KGAT将用户物品二部图与KG 结合为协同KG,并采用注意力机制聚合用户和物品的邻居信息,得到用户和物品的向量表示。
4)CKAN基于注意力机制提取KG 的属性信息,然后通过协同过滤传播将KG 属性信息传递给用户和物品,从而得到用户和物品的向量表示。
3.4 实验结果
模型按照3.2 节中的参数设置,采用F1 分数(F1-score)和曲线下面积(Area Under Curve,AUC)作为推荐结果的评价指标,经过多次实验后得到表3 所示的结果。采用召回率(Recall)作为Top-k
推荐实验的评价指标,得到实验结果见图3。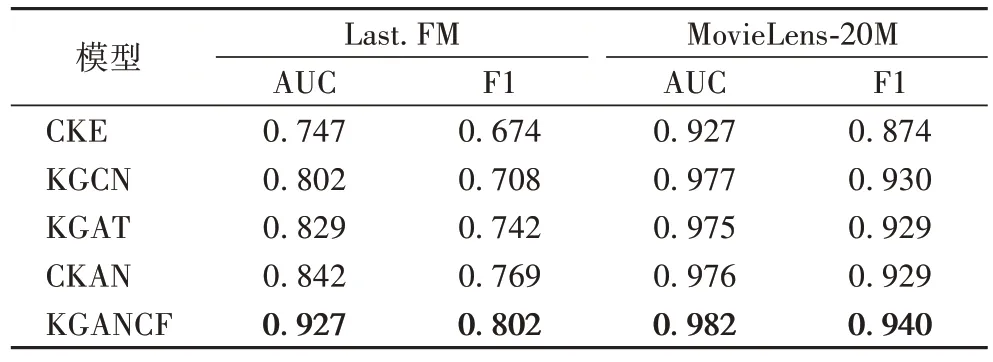
表3 点击率预测的AUC和F1结果Tab 3 Results of AUC and F1 in CTR prediction
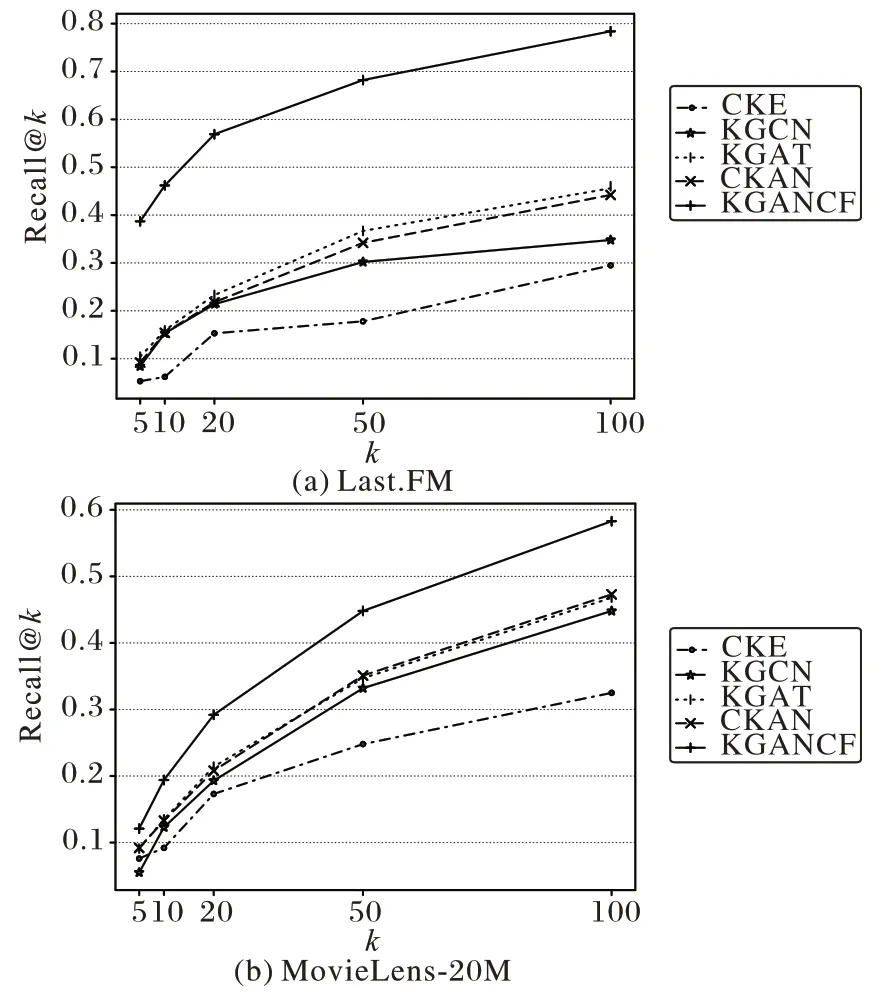
图3 Top-k推荐的Recall@k结果Fig.3 Results of Recall@k in Top-k recommendation
观察实验结果可以发现,KGANCF 性能相较于对比模型在音乐推荐和电影推荐场景下取得了明显的提升。可以得出如下结论:
1)经典的嵌入方法(CKE)的表现整体逊色于基于信息传播的方法(KGCN、KGAT)。这是因为基于信息传播的方法可以更好地挖掘出KG 中的高阶关联,从而获得更好的用户物品向量表示。
2)与KGCN 相比,加入注意力机制的模型(KGAT、CKAN和KGANCF)取得了更出色的结果,说明结合注意力机制得到的用户向量和物品向量可以更加准确地表达用户和物品的特征信息。
3)本文KGANCF 在Last.FM 数据集上的表现远超其他对比方法,原因是Last.FM 数据集相较于MovieLens-20M 数据更为稀疏,侧重对KG 建模的方法难以从KG 复杂的关系中准确地提取出对用户、物品有用的特征。KGANCF 可以更有效地从用户交互历史中提取出用户物品的协同过滤信息,然后结合KG 属性信息得到更可靠的用户特征和物品特征。
4)在KG 数据量更大,数据更稠密的MovieLens-20M 数据集上,KGANCF 同样取得了最好的表现,说明充分挖掘协同过滤信息对推荐的重要性。
3.5 模型结构分析
为了讨论协同过滤层和知识图注意力嵌入层对实验结果的影响,本节通过进一步实验讨论对比不同网络结构下AUC 值的大小。
首先固定知识图注意力嵌入网络层数为1,调整协同过滤层网络的结构,层数分别设置为1、2、3、4。实验结果见表4。观察结果可以得到结论:在协同过滤网络取3 层,知识图注意力嵌入网络取1 层时模型取得了最佳性能。这说明了充分挖掘UIG 中用户行为特征的必要性;此外,当网络层数较小时,模型无法充分挖掘协同过滤信息,而模型层数较深时,引入了无关节点的特征信息,导致推荐结果准确性开始下降。
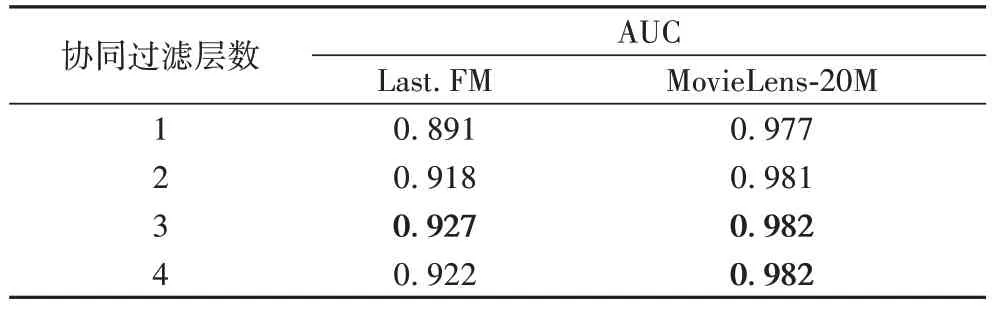
表4 协同过滤层数对AUC的影响Tab 4 Influence of number of collaborative filtering layers on AUC
下一步,在协同过滤网络取3 层的基础上调整知识图注意力嵌入层的网络层数,对比AUC 的大小,结果见表5。观察实验结果可以发现,随着知识图注意力嵌入网络层数加深,AUC 值逐渐下降。出现该结果的原因是KG 中物品高阶邻居实体包含了与用户、物品不相关的属性信息,这部分“噪声”干扰了推荐结果。因此,在提取KG 中的属性信息时,精简网络层数可以取得更好的结果。
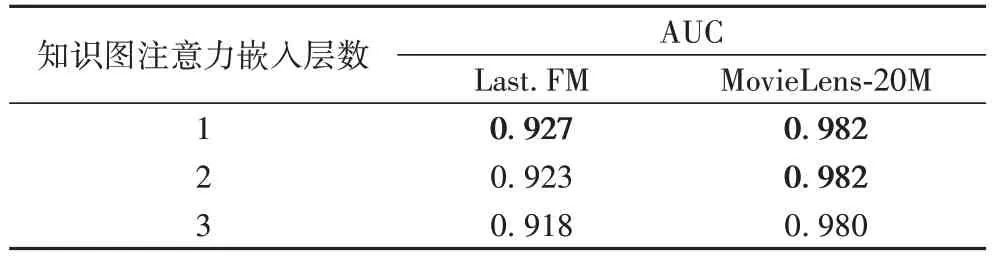
表5 知识图注意力嵌入层对AUC的影响Tab 5 Influence of number of knowledge graph attention embedding layers on AUC
4 结语
本文提出了一个推荐模型KGANCF。该模型深入挖掘用户交互历史中的协同过滤信息得到用户和物品的协同过滤向量,然后通过知识图注意力嵌入层,结合协同过滤信息筛选与用户、物品密切相关的KG 属性信息进一步丰富用户、物品的向量表示,避免了将协同过滤信息和KG 属性信息相混淆,干扰推荐结果准确率的问题。实验结果表明,本文模型的效果优于对比方法。在未来的工作中,模型需要进一步解决的问题有:1)KG 节点的高阶邻域信息对中心节点特征的重要性;2)在协同过滤层中,特征向量间的权重目前靠手工设置的超参数确定,未来可以通过自适应的方法学习这个参数。
