
知识图谱增强的科普文本分类模型
2022-05-07 07:07唐望径仝美涵韩美奂王黎明
计算机应用 2022年4期
唐望径,许 斌,仝美涵,韩美奂,3,王黎明,钟 琦
(1.清华大学计算机科学与技术系,北京 100084;2.北京交通大学计算机与信息技术学院,北京 100044;3.清华大学深圳国际研究生院,广东深圳 518055;4.中国科普研究所,北京 100081)
0 引言
文本分类是信息处理和数据挖掘的重要研究方向,是自然语言处理(Natural Language Processing,NLP)的核心任务之一,广泛应用于新闻分类、舆情分析、推荐系统等领域。随着互联网的发展,网络科普资源呈指数级增长,与此同时,海量的科普文本对人工进行文本分类提出严峻的挑战。一方面,传统人工识别文本类型的方法耗时耗力、效率低下;另一方面,由于科普文章涉及领域广泛,科普工作者对科普文章类型识别往往受到自身专业领域知识的限制,难以掌握科普所有领域。因此,利用计算机智能辅助专家对文本进行自动分类,能够帮助科普工作者快速、准确地对文章归档。
早期浅层学习模型通常使用人工特征工程的方法获取适当的文本特征来表征样本,之后将特征输入到机器学习分类模型中,如朴素贝叶斯(Naive Bayes,NB)、支持向量机(Support Vector Machine,SVM)、和K
近邻(K
-Nearest Neighbor,K
NN)等。浅层学习模型需要设计特征提取方法,往往代价昂贵。随着深度学习理论及计算机硬件的发展,深度学习模型在文本分类领域得到广泛应用。深度学习模型将特征工程集成到模型拟合过程中,简化了分类流程,降低了模型的成本开销。深度学习常用模型主要有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及近些年效果表现优异的预训练模型BERT(Bidirectional Encoder Representation from Transformers)。Kim在2014 年首次提出用于文本分类的CNN 模型,其表现与复杂的基于特征学习的分类器模型相比毫不逊色,激发了深度学习文本分类模型的研究热潮。然而,当文本长度较长时,CNN 难以提取较好的全局特征。RNN 能够对复杂的单词序列学习特征,有利于在较长的文本中提取单词的全局时序特征,但是存在梯度消失和梯度爆炸等问题。预训练神经网络模型通过在大规模无监督的语料上预训练,再在文本分类任务上微调从而达到目前最优的效果;但是预训练神经网络模型输入的长度受限,无法捕获长文本语义,同时由于是端到端模型,缺乏知识的引导。
基于上述模型的问题,针对科普文章篇幅超过千字导致模型难以聚焦分类关键信息、性能不佳的问题,本文提出了知识图谱增强的科普文本分类模型。首先,采用四步法构建了科普领域知识图谱,之后将图谱中的实体信息作为远程监督器,训练一个二分类模型作为信息过滤器,对句子进行打分、排序并完成筛选,从而使得到的句子特征表示包含更多分类类别相关信息,以缓解层次模型无法突出关键语义信息的缺陷。然后,为了进一步降低主题无关信息干扰,提高分类模型性能,本文引入句级别注意力模型,对筛选后的句子信息进行二次过滤。最后,在构建的科普文本分类数据集(Popular Science Classification Dataset,PSCD)上进行对比实验,根据实验结果,本文所提模型取得良好的分类效果,验证了模型的有效性。相较于传统神经网络模型,本文模型在召回率和F1 指标上有所提升。
本文的主要工作如下:1)提出了知识图谱增强的科普文本分类模型,通过科普知识图谱来进行主题句筛选,并引入句级别注意力模型,最终通过一个全连接神经网络实现科普文本分类;2)构造了一个科普文本分类数据集,包含了13 372篇科普文章,且本文模型在该数据集上取得了最优效果。
1 相关工作
1.1 文本分类
传统的NB 和SVM 等文本分类模型通常需要将分类流程划分为特征工程设计和分类器设计两部分,构建代价昂贵。随着深度学习的发展,深度学习模型将特征提取融合进模型拟合过程中,使得模型能够直接从输入中学习特征表示,无需过多的人工干预和先验知识。此外,由于深度学习模型具有更高的复杂度,相较于浅层模型具备更优异的效果。TextCNN作为一次成功的尝试,激发了研究人员在文本分类领域应用CNN 的热情。由于TextCNN 无法通过卷积获取文本的长距离依赖关系,为解决该问题,Johnson 等提出了深度金字塔CNN(Deep Pyramid CNN,DPCNN),通过不计成本地增加网络深度,模型能够更精准地抽取长距离的文本依赖关系。RNN 能够通过递归计算捕获长距离依赖关系,但存在梯度消失和梯度爆炸问题。人们通常使用RNN的改进模型长短期记忆(Long Short-Term Memory,LSTM)网络。RNN 能够更好地捕捉上下文信息,但对于局部信息的提取能力欠佳。Lai 等提出了用于文本分类任务的循环CNN(Recurrent CNN,RCNN)模型,利用双向LSTM 结构替换CNN 中的卷积层,对文本进行编码,较好地捕获了长文本上的序列信息;同时,通过CNN 的最大池化层,较好地捕获了文本的局部特征。
1.2 注意力机制
神经网络能够很好地与注意力机制结合,在文本建模时将注意力聚焦于分类的关键信息上,从而提高文本分类效果。注意力机制在计算机视觉领域首先被提出,随后因被应用到机器翻译的端到端模型而引入NLP 领域。注意力机制通过目标向量对输入序列进行打分,将注意力聚焦于输入序列中更为重要的部分,使输出结果更加精确。因此,注意力机制逐渐被应用于文本分类等NLP 任务中。
在处理由许多句子组成的长文本时,直接将文本作为长序列进行处理往往容易忽略文本层级结构中蕴含的信息,因此Yang 等提出了基于层级注意力网络(Hierarchical Attention Network,HAN)的文本分类模型,该模型以双向门控循环单元(Gate Recurrent Unit,GRU)作为编码器,通过两层注意力机制使模型更好地捕获文本中的重要信息,提高了长文本分类的模型性能表现。文献[13]通过一种无监督的段落向量生成模型PV-DM(Distributed Memory model of Paragraph Vectors),基于结合注意力的CNN 分类模型在长文本分类任务中取得了较好的效果。Choi 等以ALBERT(A Lite BERT)作为编码器,通过类别表示层提取分类的类别信息,使用类别信息对句子信息进一步增强,之后通过句注意力机制对句子信息进行筛选,获取了文本重要信息,有效提高了长文本分类模型性能。
2 本文模型
图1 为本文所提知识图谱增强的科普文本分类模型总体架构。
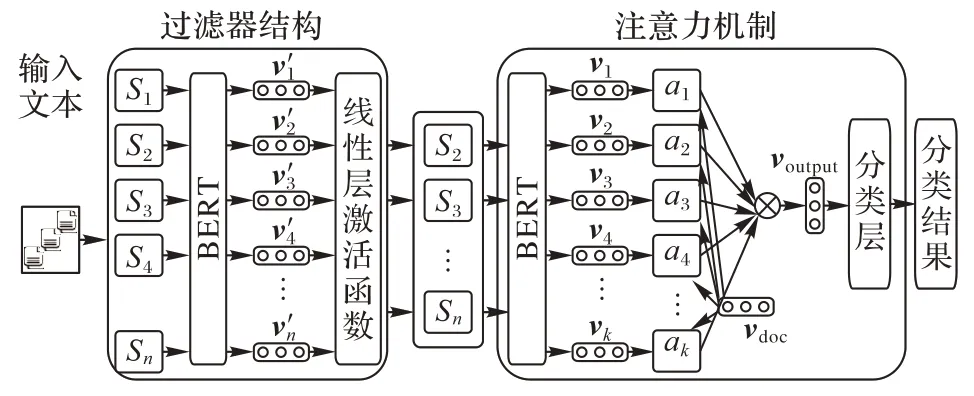
图1 知识图谱增强的科普文本分类模型架构Fig.1 Achitecture of popular science text classification model enhanced by knowledge graph
通常,语料中的所有文本表示为T
={t
,t
,…,t
,…,t
},t
表示语料中第i
篇文本,|T
|表示语料中包含的文本数量;每篇文本可以被表示为t
={S
,S
,…,S
,…,S
},S
表示文本中的第j
个句子,n
=|t
|表示文本中包含的句子数量;经过特征提取后,句子S
被表示为句向量v
,句向量维度为768。本文分类模型的建立流程如图2 所示。
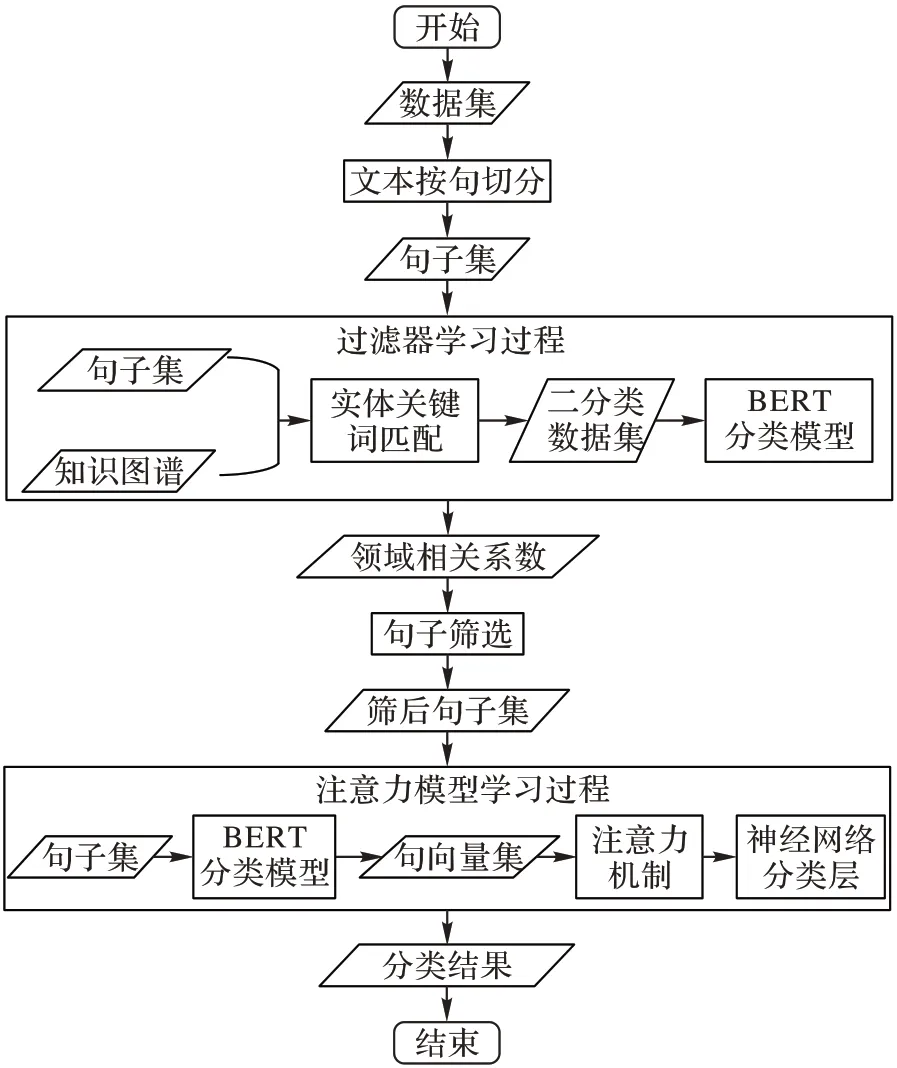
图2 模型流程Fig.2 Model flowchart
流程主要由以下四部分组成:
1)科普领域知识图谱构建。借鉴“四步法”构造科普领域知识图谱。
2)文本信息筛选。首先将文本切分为句子集,使用预训练模型BERT 作为编码器,将句子编码为连续空间下的句向量,以实现对文本句子特征提取。以二分类器作为过滤器,利用知识图谱中蕴含的实体信息对文本句向量进行筛选过滤,实现文本的信息筛选。
3)注意力机制。使用注意力机制对信息筛选后结果做进一步的增强。
4)通过全连接层和Softmax 函数实现科普文本分类。
2.1 构建科普领域知识图谱
本文借鉴了领域知识图谱构建方法“四步法”。首先,对果壳网、环球科学、Science 科学等共68 家科普微信公众号进行数据采集,获取近20 万篇科普文章。构建领域图谱首先需要进行本体构建,通过使用统计方法结合人工归纳、借鉴高质量通用图谱和专家指导构建了图谱本体。首先通过词频―逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法和TextRank 算法提取采集文章的关键词,同时通过K
-Means 聚类算法对文章进行聚类,通过人工观察关键词和聚类结果,得到了初步的领域概念。之后结合百度百科、Wikipedia 等通用图谱对领域概念进行修改并定义领域关系及其约束。其中:一级概念共10 个,分别为军事、农业、科学文化、医学、健康、生态环境、信息科技、空间科学、基础学科、生活百科;二级概念共45 个。最后,根据中国科普研究所专家指导,对构建本体进行检查和评估,修改完善后得到最终的科普领域本体。根据定义好的科普领域本体结构,从互联网上公开的知识图谱(如:百度百科、Wikipedia、XLORE 等)以及其他结构化较好的网站中获取大量结构较好、质量较高的实体数据,并结合半监督和远程监督方法,通过人工筛选获取实体间关系。2.2 文本信息筛选
文本信息筛选是本文模型对文本信息进行提取过滤的部分,本节将按顺序分别介绍以下两步:第一步,以预训练模型BERT 作为编码器对文本中所有句子进行特征提取;第二步,以科普知识图谱为监督源构建二分类过滤器,使用构建的过滤器计算句子领域相关系数,并按照该系数对每篇文本句子进行定量筛选。
2.2.1 特征提取
Google 的Devlin 等在2018 年提出了大规模预训练模型BERT,在特征提取任务上取得了极佳效果。BERT 模型由多层双向的Transformer解码器构成,Transformer 模型的核心是注意力机制。BERT 采用多头注意力(Multi-Head Attention)机制,能够更好地获取目标字在多种语义场景下与其上下文构造的语义信息。H
的计算公式为: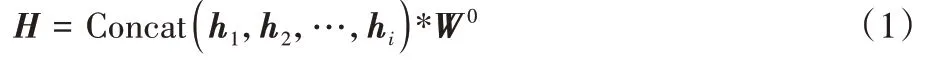
W
表示权重矩阵,为输出向量重新分配权重;h
表示第i
个头的输出向量。h
的计算公式为: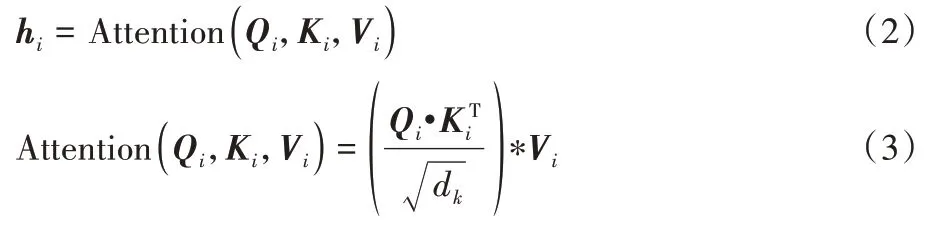
Q
、K
、V
表示输入向量经过线性映射后得到的矩阵;d
表示K
向量的维度。2.2.2 信息过滤
本文通过四步法构建了科普领域知识图谱,该图谱的实体类别与科普文本分类类别一致。首先将科普文本分类数据集中的测试集按照7∶3 比例划分出用于训练信息过滤二分类器的训练集和测试集,对所得训练集和测试集进行句子切分,得到以句子为单位的训练句子集和测试句子集。之后,将科普图谱中实体与上述所得句子集中句子进行链接,为句子赋予标签L
=[0,1],实体链接成功句子标签赋1,链接失败句子标签赋0。通过上述预处理,将语料测试集转化为如下所示数据二元组: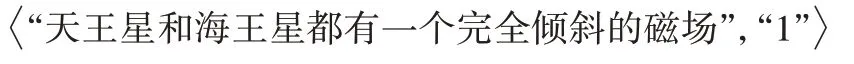

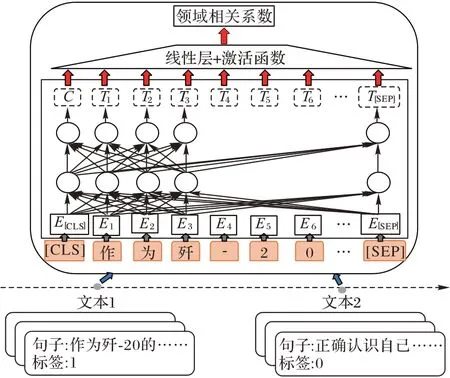
图3 句子过滤器结构Fig.3 Structure of sentence filter
将输入文本切分为句子集合,集合中句子S
输入训练好的二分类模型后,模型通过预训练模型BERT 对句子进行特征提取,提取的特征信息将会通过输出层得到输出。输出层包括线性层、激活函数,计算公式如下所示:
L
=1 的概率,将其视为领域相关系数q
∈[0,1],计算公式如下: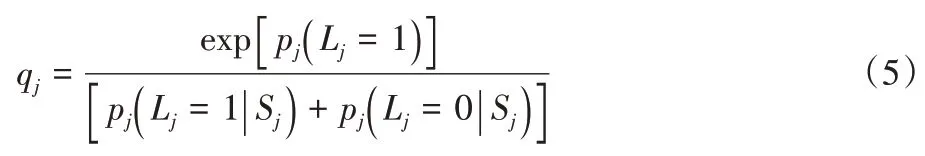
q
对相应的句向量v
进行排序,选出分数值排名靠前的n
个句向量V
=[v
;v
;…;v
]作为下一部分注意力模型输入。同时,保持了各句向量在原文本中的先后顺序,以避免造成位置信息丢失,影响模型分类性能。2.3 注意力机制
文章中不同的句子对于文章内容理解的贡献程度不同。为计算句向量对于区分文章类别的贡献程度,本文引入了注意力机制,其具体结构如图4 所示。
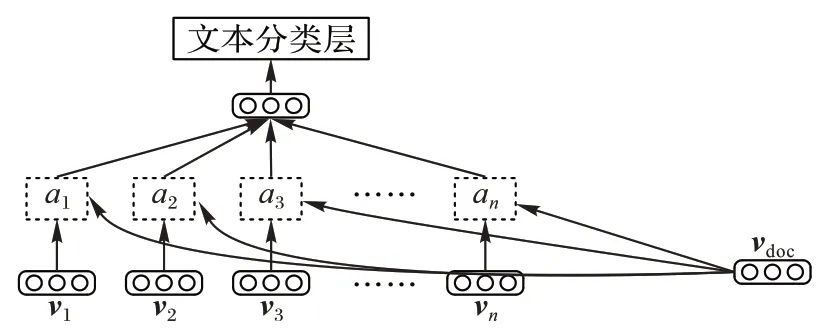
图4 注意力机制结构Fig.4 Structure of attention mechanism
注意力模型的计算公式如下:
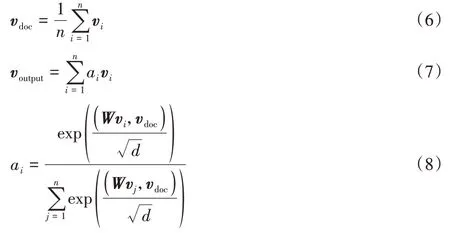
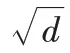
2.4 文本分类
通过注意力机制,得到了句向量对应分类的注意力。通过注意力对句向量进行聚合,得到v
,该向量包含了经过过滤器和注意力机制双重筛选后的文本信息。将v
输入由全连接层和Softmax 函数构成的多分类器中,得到类别概率:
通过最小化分类的交叉熵误差,以有监督的方式训练模型。损失函数如下:

N
为样本数;C
为多分类类别总数;若预测类别和样本所属类别相同则y
为1,否则为0;p
为文本t
属于类别c
的概率。3 实验与结果分析
3.1 实验数据
为了验证模型效果,本文构建了科普文本分类数据集PSCD。首先,对照科普领域知识图谱实体分类,从科普中国等国内著名科普网站中爬取相应栏目的科普文章。剔除内容过短和过长的科普文本,对筛选后文本进行去重和数据清洗,最终得到科普文本分类数据集。科普长文本分类数据集中单个文本长度为102~26 722。数据集中包含10 个分类,共13 372 篇文本,其中短文本730 篇,长文本11 195 篇,超长文本1 447 篇。实验随机选取80%作为训练数据,20%作为测试数据。数据集具体细节统计如表1 和图5 所示。
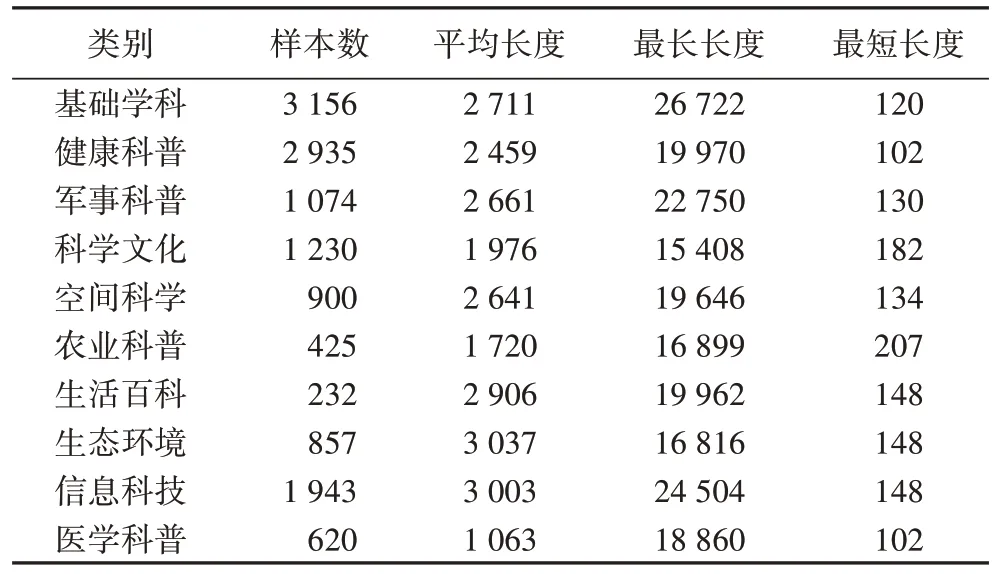
表1 数据集详细情况Tab 1 Dataset details
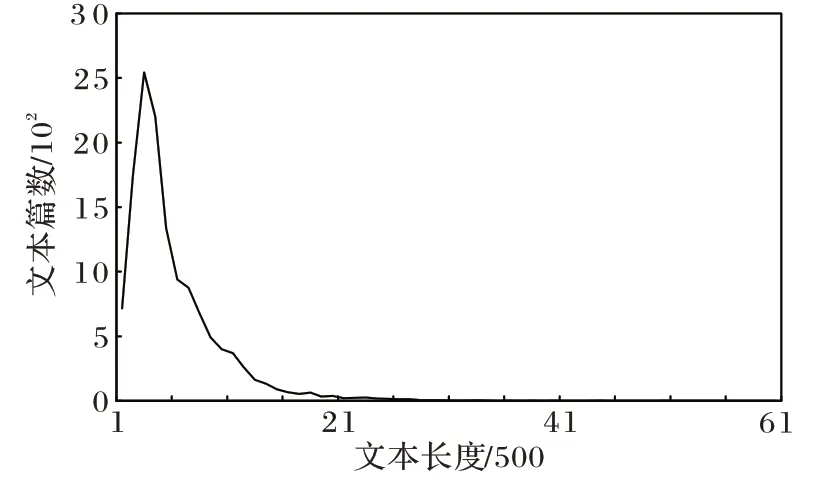
图5 输入文本长度分布统计情况Fig.5 Statistics on length distribution of input text
3.2 基线方法及实验设置
3.2.1 基线方法
为评价模型在长文本分类任务上的性能,引入了多种典型模型进行实验对比,以下详细描述了所有进行比较的模型:
1)FastText:该模型是一个使用浅层神经网络实现的快速文本分类算法,不需要使用预训练词向量,模型会在训练过程中训练词向量。该模型分类效果较好,需要的训练时间极少,是一种高效的工业级分类模型。
2)TextCNN:该模型是CNN 在NLP 中的一次成功的应用,能够利用CNN 对局部特征捕捉的特性,获取不同抽象层次的语义信息。
3)TextRNN:该模型是一种RNN,将经过预训练词向量模型后的词向量表示按顺序输入双向LSTM 中,将LSTM最后一个时间步长中的隐藏状态输入Softmax 层后输入全连接层进行分类,最终输出文本分类。
4)TextRCNN:RNN 能够更好地捕捉上下文信息,而CNN 能够有效地捕捉局部特征。该模型结合了RNN 和CNN的特点,将CNN 中的卷积层换成了双向的循环结构,使其能够有效减少噪声,最大限度地捕捉上下文信息。同时该模型保留了最大池化层,保证了模型对局部特征的提取能力。
5)BERT:该模型为2018 年谷歌提出的大规模预训练模型,模型框架基于Transformer,实现了多层双向Transformer 编码器。该模型一经发布,就在多项NLP 任务中取得了SOTA 结果。虽然该模型主要任务并不是文本分类,但由于其优秀的文本表征能力,本文使用中文BERT 预训练模型作为编码器,将结果输入Softmax 函数和全连接层,实现文本分类任务。
3.2.2 实验设置
所有基线模型均为基于字级别的分类模型。由于BERT输入长度限制为510 字,且原数据集中文本长度较长,故对BERT 模型输入文本进行预处理,对长度超过510 字文本,从文本开头截取长度为510 字文本作为模型输入,对长度未超过限制的文本则不做处理。
对比实验中,TextCNN、TextRNN、TextRCNN 均使用预训练词向量模型Word2Vec 生成词向量,设置单词嵌入维度为300,文本长度均未作处理。
实验运行服务器配置为Intel Core i9-10900K CPU,显卡为RTX 3090。
3.3 评测标准
本文采用准确率Acc
(Accuracy)、召回率R
(Recall)以及F1 值(F1-score)作为对本文分类模型效果的评价指标。计算公式如下: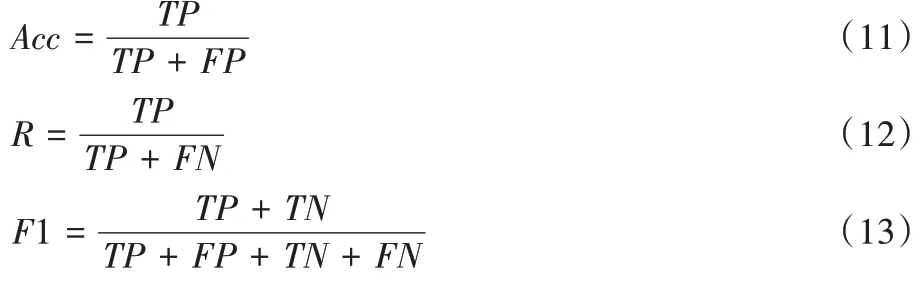
TP
(True Positives)表示预测为正的正样本,FP
(False Positives)表示预测为正的负样本,FN
(False Negatives)表示预测为负的正样本,TN
(True Negatives)表示预测为负的负样本。3.4 实验结果分析
表2 为上述各基线模型与本文模型在科普文本分类数据集PSCD 上分类表现。由表2 可知,本文模型在平均召回率以及平均F1 值上最高,相较于TextCNN 和BERT,分别提高了2.88 和1.88 个百分点;BERT 在所有基线模型中表现最佳,TextCNN、TextRCNN 均在数据集上取得了较好的分类效果。虽然TextRNN 使用LSTM 替代普通RNN,解决了处理较长文本时会出现的梯度消失问题,但是由于科普文本中长文本数量多、字数长,该模型在PSCD 上的分类表现仍较差。FastText 表现仅优于TextRNN,但其模型的训练耗时明显少于其他模型,同时不需要预训练词向量,故其仍是一个非常优秀的分类模型。
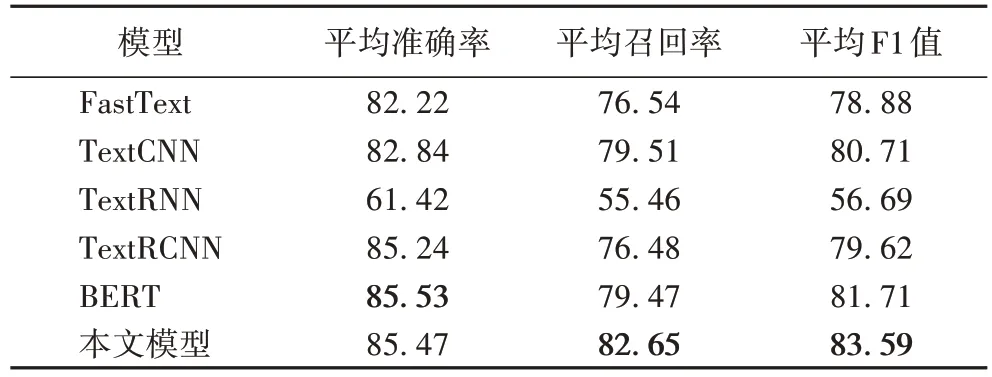
表2 PSCD上各模型的表现 单位:%Tab 2 Performance of each model on PSCD unit:%
为了更进一步探索模型的效果,故对测试集中分类错误案例进行了分析。当文本句子个数上限设置为30 时,共在测试集中得到类别错误划分案例453 例,其中,文本句子数量少于30 的案例共272 例,文本句子数多于或等于30 的案例共181 例。即文本中句子数量对于模型的分类效果造成了一定的影响。之后,对案例中各分类数量占比进行了统计,发现错误常常出现在涉及学科领域交叉应用的文章的分类中,如图6 所示。

图6 错误案例Fig.6 Error case
该文章开头提及了以色列国防军配备了一种装载人工智能系统的坦克,并在后续对该坦克进行了详细介绍,之后花费了大量篇幅对军事领域内容进行了描述。文章中大量出现“国防军”“坦克”“装甲战斗”等军事领域词汇和科普图谱中属于军事科普分类下的“MerkavaMk4Barak 坦克”“IronViewVR 头盔”等军事实体。虽然该文本主要内容为人工智能技术在军事领域应用及相关的伦理问题,应属于信息科技分类,但大量的军事领域词汇和军事领域实体形成的噪声误导了分类器,以至于将本属于信息科技分类下的文本划分到军事科普分类中。类似情况在错误案例中频繁发生。
上述结果表明,利用知识图谱实体信息构建的过滤器,对长文本进行句子筛选,能够有效地提取包含领域相关实体、领域词汇句子,对长文本分类模型性能有所提升。
4 结语
本文研究基于领域知识图谱的文本分类模型,提出了知识图谱增强的科普文本分类模型。首先,将输入文本切分为句子集,使用BERT 作为句子编码器,将所有句子转化为句向量集;然后,构建了一个以科普领域图谱实体信息作为监督数据源,科普文本句子集作为输入的二分类过滤器,基于过滤器,对输入文本进行筛选,输出固定数量且排名靠前的句子向量;最后,通过注意力模型获得对文本信息高度总结的输出向量,将其输入分类层获得文本对应类别概率,以实现文本分类。通过在科普分类数据集PSCD 进行对比实验表明,所提出模型在分类性能优于基线模型中召回率最高的TextCNN 模型以及F1-Score 最高的BERT 模型,与BERT 模型相比,召回率和F1-Score 分别提升了3.18 个百分点和1.88个百分点。对错误案例的分析可知,仅利用实体及类别信息不足以解决交叉领域中次要领域信息对分类造成影响的问题。在后续工作中,将尝试通过引入更多图谱信息解决上述问题。
致谢:此项工作得到了中国科普研究所2020年委托合作项目“自然语言处理方法在科普领域的应用研究”(200110EMR028)支持。
