
基于改进Inception结构的知识图谱嵌入模型
2022-05-07 07:07余晓鹏何儒汉张俊杰胡新荣
计算机应用 2022年4期
余晓鹏,何儒汉,黄 晋,张俊杰,胡新荣
(1.纺织服装智能化湖北省工程研究中心(武汉纺织大学),武汉 430200;2.武汉纺织大学计算机与人工智能学院,武汉 430200;3.湖北省服装信息化工程技术研究中心(武汉纺织大学),武汉 430200)
0 引言
知识图谱(Knowledge Graph,KG)是一种表示世界事实的结构化语义网络。其中,节点代表实际存在的事实,边代表事实之间的关系。KG 可以被表示为三元组(h
,r
,t
),h
代表头实体,t
代表尾实体,r
代表头实体和尾实体之间的关系。现存的大规模KG 包括Freebase、WordNet和YAGO等,并已被应用在不同的领域,如推荐系统、智能问答等。由于知识源的各种缺陷,现存的KG 多数并不完整。针对这个问题,基于知识图谱嵌入(Knowledge Graph Embedding,KGE)的知识图谱补全应运而生。KGE 是将KG的实体和关系映射到低维连续的向量空间中,使得可以在低维向量空间中高效计算实体和关系之间的语义联系。目前,以TransE(Translating Embedding)为代表的基于翻译的KGE 模型,采用简单的浅层结构,计算效率较高,能有效学习KG 的直接关系;但是,该模型仅对简单关系数据效果较好,难以处理复杂的关系数据。而以双线型模型Rescal为代表的基于语义匹配的KGE 模型,能有效捕获丰富的特征交互信息,但参数量大,计算效率低。
目前,基于神经网络的模型逐渐应用到了KGE。卷积神经网络(Convolutional Neural Network,CNN)具有多层网络结构,能有效提高模型的表达能力,能捕获丰富的特征交互信息并限制参数数量以提高计算效率。以ConvE(Convolution Embedding)模型为代表的基于神经网络的嵌入模型,能够有效地捕捉三元组特征且泛化能力强,但捕捉实体和关系的特征交互信息能力有限,特征表达能力较弱。
受Inception结构在图像处理算法的启发,将实体和关系输入重塑为二维特征向量后输入到Inception 结构中,通过多种不同的操作方式,可提高捕捉特征交互信息的能力。Inception 结构主要是加深传统的高尺寸卷积层,通过增加网络深度来提高捕捉特征交互信息的能力。在Inception 结构中采用高尺寸混合空洞卷积(Hybrid Dilated Convolution,HDC)来代替原来高尺寸普通卷积,混合空洞卷积无池化损失信息,感受野更大。此外,为了解决深度神经网络固有的信息丢失的缺点,使用了残差网络结构进行优化。
本文针对特征交互能力受限的问题,提出一种KGE 模型——InceE(Inception Embedding)模型,该模型基于一种改进的Inception 结构,通过进一步增强关系和实体嵌入之间的交互能力,以提高特征表达能力;并使用了残差网络的模型结构,以改善深度神经网络结构易丢失特征信息的问题;此外,在Inception 中,将原来的高尺寸普通卷积改为混合空洞的卷积方式,以更好地获取特征信息。
本文主要工作如下:
1)提出了一种基于改进Inception 结构的KGE 模型,将Inception 结构引入到KGE 中,通过使用Inception 结构的不同卷积核和池化层的感受野不同的特性,来获取多种表示特征,以提高特征表示能力。
2)提出使用混合空洞卷积来代替Inception 结构中的标准卷积。混合空洞卷积无池化损失信息,并加大感受野,使得每个卷积输出都包含较大范围信息。在两种不同尺寸的标准卷积操作中,都替换为混合空洞卷积,以提高特征交互能力。
3)使用了残差学习的方式,以防止深度神经网络造成的信息丢失。
1 相关工作
本章主要介绍了目前主流的三类KGE 模型。
1.1 基于距离的模型
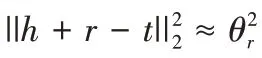
1.2 基于语义匹配的模型
语义匹配模型是利用基于相似性的得分函数。它们主要是通过匹配实体的语义和向量空间表示中包含的关系来度量事实的可行度。语义匹配模型最具代表性的模型是Rescal 模型,将KG 编码为一个张量,三元组存在于KG 中,则对应量的值设置为1,否则为0。Rescal 模型的缺点就是需要大量的参数,计算率较低。为解决以上问题,SimplE(Simple Embedding)模型独立学习每个实体的两个嵌入,并且复杂度随着嵌入维度线性增加。DISTMULT模型将关系矩阵简化为对角矩阵,通过双线性对角模型学习实体和关系的向量表示。ComplEx(ComplEx embeddings)模型,使用元素之间的点积使DISTMULT 模型通用化。Analogy模型扩展了Rescal,进一步对实体和关系属性进行类比建模。
1.3 基于神经的模型
近年来,神经网络受到了越来越多的关注。较早提出的多层感知器(Multi-Layer Perceptron,MLP)模型将头实体、关系、尾实体合并,然后传入到一个隐藏层来计算合理性得分。神经张量网络(Neural Tensor Network,NTN)模型维持内部权重的张量,通过外部乘积和标准值相结合的函数来计算实体的神经层,与关系相结合,得到合理的分数。ConvE 和ConvKB使用CNN 来定义给定的三元组的得分函数。ConvE 模型是通过将实体和关系向量联合起来看作一张二维图特征,通过卷积获取特征张量,通过线性变换将特征张量映射到d
维的向量,然后通过点积计算得分合理性。InteractE(Interactions Embedding)模型证明了通过提高特征交互数量来提高模型效果的有效性。因为KG 也是一种特殊的图结构,图卷积神经网络也被用到KGE 中,如R-GCN(Relational data with Graph Convolutional Network)等。表1列出了几种主流模型。
表1 知识图谱嵌入模型及评分函数Tab 1 Knowledge graph embedding model and scoring function
2 InceE模型
本文所提出的基于改进Inception 结构的KGE 模型的流程如图1 所示,将实体和关系的一维特征向量联合重塑为二维特征向量输入到Inception 结构中,其中在高尺寸的混合空洞卷积部输出与初始的二维特征拼接,最终将Inception 结构的四个输出特征向量与初始二维特征向量拼接后的特征向量重塑为最终预测的一维特征向量。

图1 InceE模型流程Fig.1 InceE model flow
2.1 符号定义
KG 用Ω
=(E
,R
)表示,E
代表KG 中的所有实体向量集合,R
代表所有关系向量集合。三元组定义为(e
,r
,e
),其中头实体和尾实体向量e
,e
∈E
,关系向量r
∈R
。KGE 目的是学习给定的实体e
和关系r
的低维向量表示e
,r
∈R,其中d
表示嵌入的维度。2.2 InceE网络模型结构
本文提出了一种基于Inception 结构的KGE 模型。InceE模型的网络模型结构如图2 所示。把KG 中的实体和关系映射为d
维的向量空间中的具体的向量,每个KG 三元组可以表示为(e
,r
,e
)。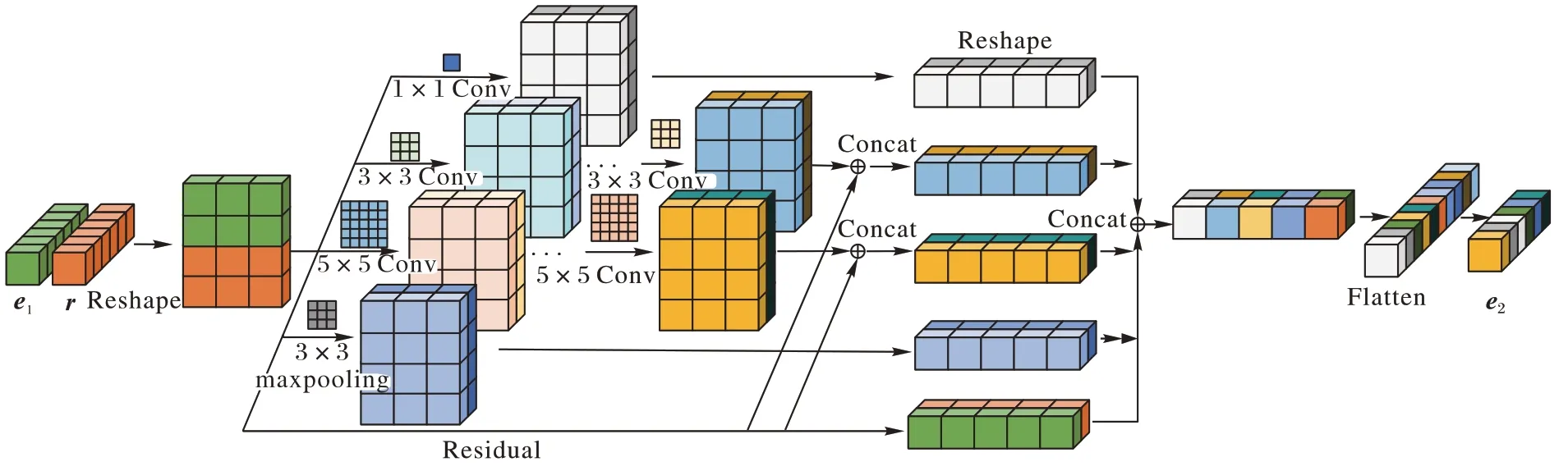
图2 InceE网络模型结构Fig.2 Structure of InceE network model
在该模型中,首先将实体e
和关系r
重塑为a
×b
的二维特征表示,这里重塑后的二维特征维度a
×b
=2 ×d
。然后并行地分别执行卷积核kernel_size
=1、3、5 的卷积操作和kernel_size
=3 的最大池化操作。在kernel_size
=3、5 的卷积操作中,采用了混合空洞卷积的方式来提高捕捉特征交互信息的能力,然后为防止深度神经网络造成的特征丢失严重,采用基于残差学习的方法将以上两种卷积输出向量和初始二维特征向量进行拼接。2.3 得分函数
在本文中,使用[e
;r
]来表示重塑后的初始二维特征向量,其中:e
表示实体向量,r
表示实体之间的关系向量,e
,r
∈R,[e
;r
]∈R。基于1×1 卷积核卷积学习。在基于二维重塑后的特征向量上的1×1 的卷积计算公式为:
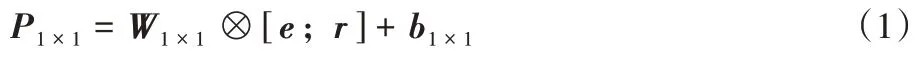
W
∈R是kernel_size
=1 的卷积核;b
是偏置量。基于kernel_size
=3,5 的混合空洞卷积学习。混合空洞卷积是以上一次卷积的输出作为下一次卷积的输入,卷积的计算公式为:
l
代表空洞卷积采用的步幅。完整的混合空洞卷积计算公式为:
P
表示上一次卷积操作的输出;W
是卷积核;b
是偏置量。基于初始二维特征向量的最大池化操作计算公式为:

b
是偏置量。不同的卷积操作获得多个不同的特征向量,将获得的特征向量与初始二维特征向量进行整合,表示为:
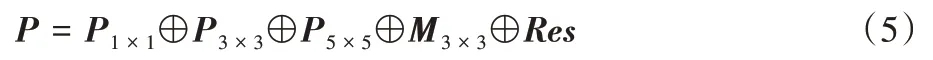
P
、P
、P
表示不同卷积核大小的输出特征向量;M
代表最大池化所得特征向量;Res
代表初始二维特征向量。最后,整个模型的最终输出是将以上所得特征向量P
展平重塑为一维特征向量。最终的特征计算公式为:
e
,定义的得分函数为:
f
代表Sigmoid 函数;W
是变换举证;b
是偏置量。在InceE 模型中,使用与ConvE 模型相同的损失函数来训练本文所提的模型参数,具体定义如式(8)所示:
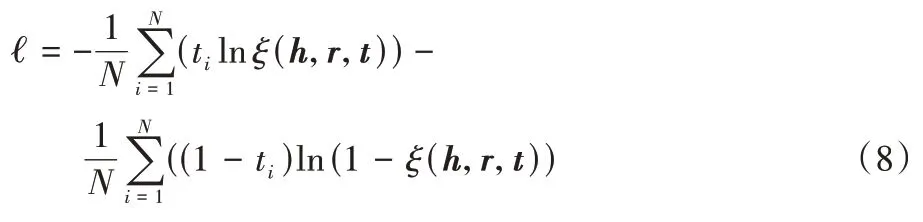
N
是KG 的实体数量,t
是存在关系的实体的标签向量,否则为0。3 实验与结果分析
3.1 实验数据
本文的评估模型使用了3 个数据集,分别是FB15k、WN18和Kinship。FB15k 是Freebase 的子集,主要 包含的三元组以电影和体育相关的主题为主。WN18 是WordNet的子集,包含18 种关系和49 000 种实体。Kinship 数据集是一个新提出的数据集,主要是包括亲属关系的数据集。具体的三个数据集包含的数据如表2 所示。
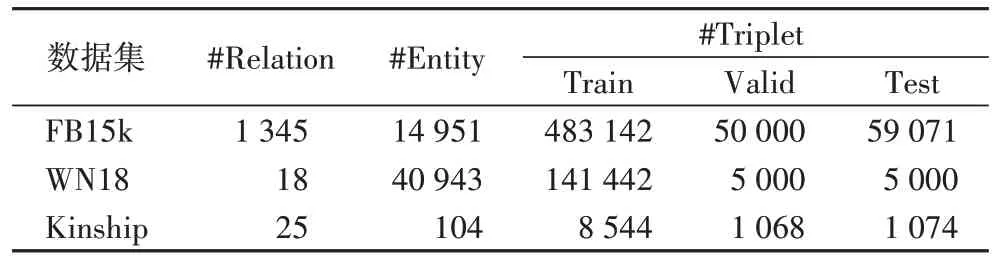
表2 数据集数据统计Tab 2 Dataset statistics
3.2 实验设置
3.2.1 实验环境
本模型的实验环境是:操作系统Linux 32 位,独立显卡型号NVIDIA GeForceGTX1080ti,显存11 GB。实验工具是PyCharm,Python3.6 版本,深度学习框架Pytorch1.0。
在FB15k、WN18、Kinship 上实验超参数设置分别为学习率lr
={0.001 25,0.000 65,0.000 75},epoch
=500,batch
_size
={128,256,256}。3.2.2 实验指标
本实验使用链接预测任务来验证模型的有效性,即三元组缺失实体或者关系。在链接预测任务中,采用以下四个指标作为模型的最终评估指标:
MRR(Mean Reciprocal Rank):正确实体的平均倒数排名,越大越好。
Hit@10:正确实体进入前十的百分比,越大越好。
Hit@3:正确实体进入前三的百分比,越大越好。
Hit@1:正确实体是第一的百分比,越大越好。
3.3 实验结果
InceE 与 HAKE(Hierarchy-Aware Knowledge graph Embeddings)、CompGCN、CoKE(Contextualized Knowledge graph Embedding)、ArcE(Atrous convolution and residual learning Embedding)等模型在数据集Kinship 上的实验结果如表3 所示。InceE 模型在MRR 指标和Hit@1 指标上都取得了最优的结果分别为0.873 和80.1,较次优的模型分别提高幅度为0.009 和1.6,取得了较大幅度的提升;在Hit@3 和Hit@10 上也仅比最好的模型低0.2 和0.4。
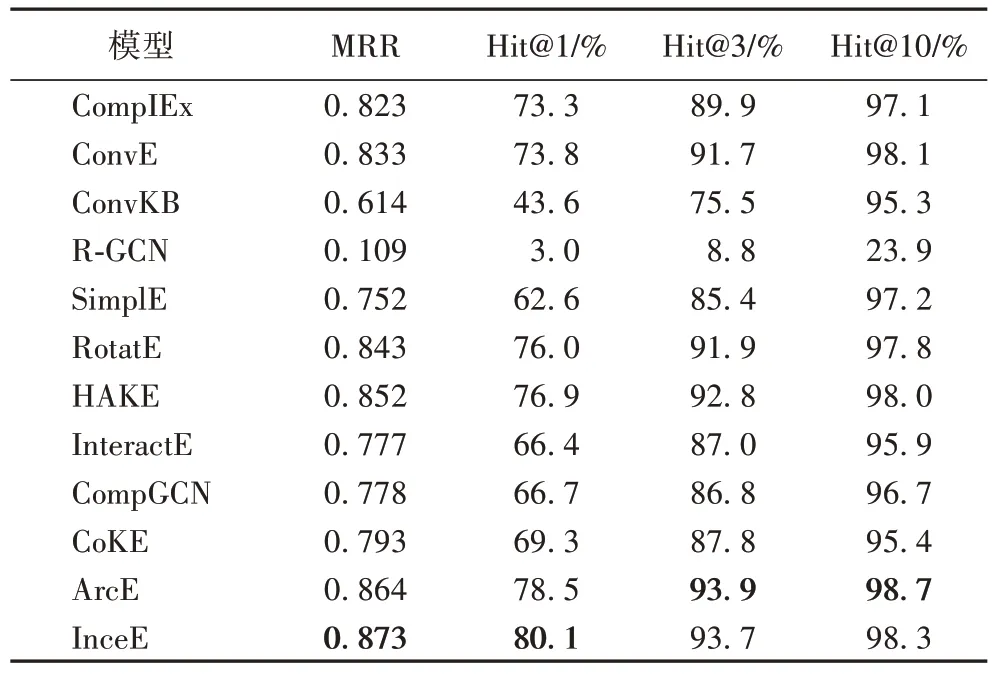
表3 不同模型在Kinship数据集的实验结果Tab 3 Experimental results of different models on Kinship dataset
表4 列出了InceE 和HOIE(Holographic Embeddings)、RSNs、QuatRE(Relation-Aware Quaternions Embedding)等模型在数据集FB15k 上的实验结果。如表4 所示,InceE模型的MRR 比QuatRE提升了0.007,Hit@1提升了1.5,Hit@10 的效果和最好的模型效果相同,Hit@3 也仅比最好的模型小0.1。
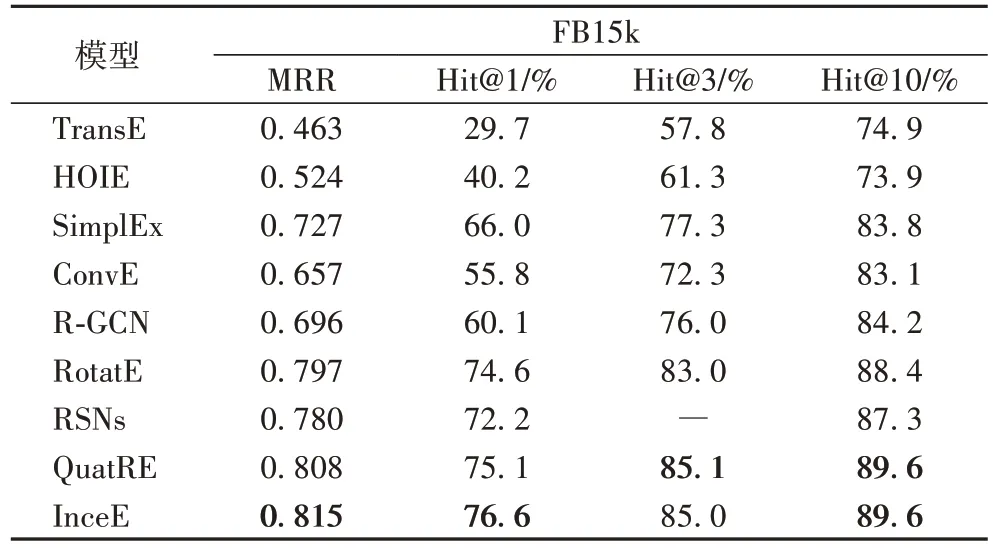
表4 不同模型在FB15k数据集的实验比较结果Tab 4 Experimental comparison results of different models on FB15k dataset
表5 列出了InceE 模型和其他模型在数据集WN18 上的实验结果。由表5 可知,InceE 模型在数据集WN18 上的实验效果提升相对有限,在MRR 上达到了和最好模型同样的效果为0.949;在Hit@1 上的实验效果为94.5,比最好的模型效果提升0.01;在Hit@3 和Hit@10 的效果分别为95.1 和95.5,比最好的模型仅差0.2 和0.8。
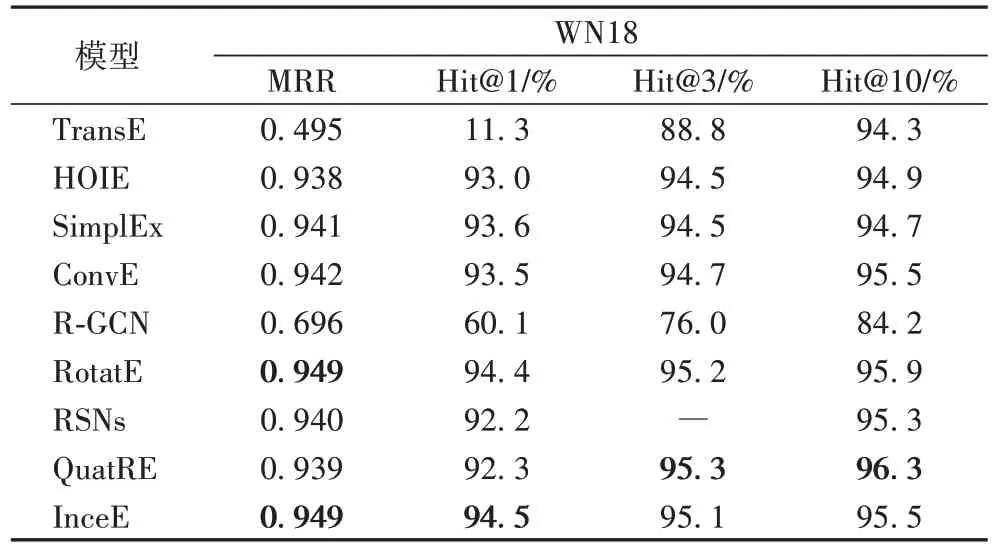
表5 不同模型在WN18数据集的实验比较结果Tab 5 Experimental comparison results of different models on WN18 dataset
3.4 实验分析
由表3~5 可知,本文模型在WN18 数据集上的表现,多数情况下是高于在其他两个数据集上的结果;在Kinship 数据集上的结果要高于FB15k 数据集的结果。在三个不同数据集上的实验,本文模型在多数指标上都取得了最好的结果,或者和最好结果相差不多的效果。
由表5 的实验结果可知,本文模型在WN18 数据集上的结果与其他模型相比,提升效果相对较低。由表2 可知,WN18 数据集关系更少,实体数量较多,且平均每个实体节点的相互连接比较稀疏,存在很多可逆的关系,多数模型都取得了很好的效果,与其他模型在WN18 数据集上的结果相比,本文模型每个指标所获得的结果也提升较低或者相近。
在FB15k 数据集上,InceE 模型的实验结果比其他模型更好,达到了现有模型的最好效果或者更高,本文模型在关系复杂的数据集上相较于对比模型结果也取得了一个不错的提升,尤其与同类的ConvE 模型相比,MRR、Hit@1、Hit@3和Hit@10 分别提升了0.158、20.8、12.7 和6.5,说明本文模型通过提高捕捉特征交互信息的能力来提高特征表达能力的有效性。
基于CNN 的四个不同模型在Kinship 数据集上的实验结果如表6 所示。在MRR 和Hit@1 指标上,InceE 模型都相较于其他三个模型取得了最好的结果,并且在Hit@3 和Hit@10指标上也和ArcE 模型相差不多,从而证明了本模型是有效的。
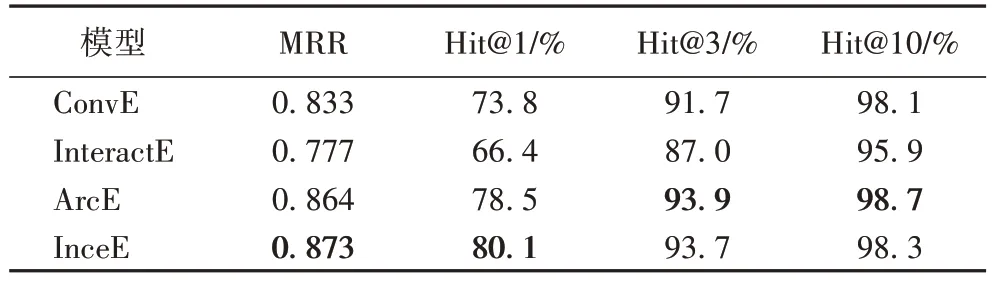
表6 基于CNN的不同模型在Kinship数据集上的实验结果Tab 6 Experimental results of different models based on CNN on Kinship dataset
3.5 消融实验
本文还在Kinship 数据集上进行了多组消融实验。通过表7 可以看到,是否添加残差学习模块,对实验模型的实验结果存在较大的影响,通过添加残差学习防止深度神经网络造成的信息的效果是有效的,取得最好的结果。

表7 InceE模型是否添加残差学习在Kinship数据集上的实验结果Tab 7 Experimental results of InceE model whether to add residual learning on Kinship dataset
此外,为了验证不同的卷积方式对模型性能的影响,在Kinship 数据集上进行了实验,实验结果如图3 所示,分别使用了标准卷积和混合空洞卷积的方式。由图3 可知,在使用标准卷积时,四个指标都会有不同程度的下降。而采用混合空洞卷积四个指标中的MRR、Hit@和Hit@3 都取得了提升,在Hit@10 指标上和标准卷积的结果取得了相同的结果,由此证明了通过使用混合空洞卷积的方式来提高特征的表达能力是有效的,且效果提升明显。
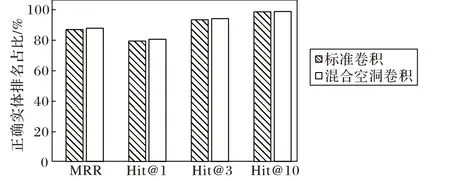
图3 标准卷积和混合空洞卷积对比结果Fig.3 Comparison results of standard convolution and hybrid dilated convolution
4 结语
本文针对知识图谱嵌入(KGE)提出了一种基于改进Inception 结构的KGE 模型——InceE。实验采用链接预测任务实验来评估InceE 模型,证实本文模型在三个基准数据集WN18、FB15k、Kinship 上的MRR、Hit@10、Hit@3、Hit@1 上大部分指标上有明显的提升。实验结果表明,InceE 模型借助Inception 结构通过不同尺寸的卷积核的不同感受野的优势,能有效增加特征的交互数量。为了进一步提高模型的准确率,在今后的工作中会考虑特定三元组与附近三元组的路径信息,以及实体本身的描述文本信息。
