
融合实体描述信息和邻居节点特征的知识表示学习方法
2022-05-07 07:07焦守龙段友祥孙歧峰庄子浩孙琛皓
计算机应用 2022年4期
焦守龙,段友祥,孙歧峰,庄子浩,孙琛皓
(中国石油大学(华东)计算机科学与技术学院,山东青岛 266555)
0 引言
随着大数据和人工智能的发展,知识图谱作为一种可以将知识结构化的重要技术而受到广泛关注。在知识图谱中,大众所熟知的现实世界中的知识通常被表示为多个三元组(头实体、关系、尾实体)组成的多关系网络形式。知识图谱集合了人类世界的广泛知识,在知识问答、信息抽取、智能搜索等人工智能领域拥有广阔的应用空间,但知识图谱使用符号化的表示方式,大规模知识图谱存在计算效率低下和数据稀疏的问题,而且随着深度学习的发展和应用,人们希望知识图谱有更简单高效的表示形式。因此许多研究者提出了基于深度学习的知识表示学习方法,目标是将三元组从高维独热向量空间映射到一个连续的低维稠密实值向量空间中,以解决知识库中数据稀疏问题,实现高效计算,对知识图谱的推理、补全、应用等都具有重要意义。
在现有的表示学习研究中,翻译模型是最具代表性的经典方法,它因训练时只需要较少的参数并取得了较好的知识表达效果而受到大量研究者的重点关注和应用,但这类方法普遍独立学习每个三元组的结构特征,没有应用知识图谱中存在的语义信息和知识图谱外的描述信息,后来随着研究的深入,知识表示学习模型不断改进,许多方法开始在学习三元组结构特征的基础上融入多源信息来提高模型的表达能力。其中KBGAT 模型将图注意力网络(Graph Attention Network,GAT)应用到知识表示学习中,进一步解决了大多数模型中独立处理每一个三元组,无法表达三元组之间特征信息的问题,KBGAT 不仅考虑到相邻实体之间的向量表示,还考虑了两个实体间的关系向量,从而丰富了实体的语义信息。但是该模型还存在缺陷:第一,知识图谱中的实体拥有丰富的实体描述信息,在此模型中没有被利用;第二,对每个三元组中关系和实体向量进行拼接后使用GAT 的方法对三元组中实体和关系的特征获取不够充分;第三,分步训练编码器解码器的方法容易产生错误传播。
因此,为了融合更多的三元组语义信息,提高知识表示的准确性,本文提出了一个基于BERT(Bidirectional Encoder Representations from Transformers)和GAT 的知识表示学习(knowledge representation learning based on BERT And GAT,BAGAT)模型。该模型既考虑了三元组外的实体描述文本信息,又充分利用了知识图谱三元组中隐藏的复杂实体关系特征向量对目标实体的表示。具体来说,首先对三元组中每个实体关系通过GAT 计算基于知识图谱内部实体邻居节点信息的向量表示,然后使用BERT 词向量模型实现对实体描述信息的向量表示,最后将两者在相同向量空间中进行联合知识表示学习。
1 相关工作
知识表示学习通过将实体和关系向量化来实现对实体和关系的语义信息准确描述。近年来,有多种不同类型知识表示学习模型提出,首先是Bordes 等提出的翻译模型TransE(Translating Embeddings),它将三元组中头实体通过关系联系尾实体的过程当作翻译过程,然后用得分函数衡量每个三元组的合理性,最后通过不断优化损失函数获得最准确的向量表示结果。尽管TransE 简单高效,但处理复杂关系时容易出现不同实体间的语义冲突,为克服这种缺陷,Wang等提出通过将关系建模超平面并将头实体和尾实体投影到特定关系超平面的方法 TransH(Translating on Hyperplanes)来解决三元组的复杂关系问题。此外Lin 等提出TransR(Translation in the corresponding Relation space),即将实体和关系分别映射到不同的空间,然后将实体向量表示从实体空间投影到关系空间实现翻译过程。Ji 等提出TransD(Translating embedding via Dynamic mapping matrix),即分别设置头实体和尾实体的投影矩阵,然后将实体从实体空间投影到关系空间中,并使用向量操作取代矩阵操作来提高模型的计算效率。这些方法尽管取得了不错的效果,但都是对三元组结构特征的表示,对三元组的语义信息应用不足。此后Xie 等提出了融入多源信息的知识表示学习模型(Representation Learning of Knowledge graphs with entity Descriptions,DKRL),它将实体分为基于结构的表示和基于描述的表示两部分进行联合训练,使用连续词袋(Continuous Bag Of Words,CBOW)模型和卷积神经网络(Deep Convolutional Neural Network,CNN)模型两种不同方法训练得到实体描述信息向量,然后将该向量与基于结构的表示向量放在相同的连续向量空间中学习,实验结果表明该模型对不同实体有更好的区分能力。
除了上述模型外,神经网络也被应用到研究知识表示学习。比如,Dettmers 等提出基于CNN的知识表示模型ConvE(Convolutional Embedding),它使用头实体和关系组成输入矩阵,然后送到卷积层提取特征,将特征矩阵通过线性变换向量化后通过和尾实体向量内积得到表示三元组合理性的得分。Nguyen 等在ConvE 的基础上提出更注重三元组整体特征的基于CNN 的知识库嵌入模型(embedding model for Knowledge Base completion based on Convolutional neural network,ConvKB),它将每个三元组都表示为3 个特征向量组成的矩阵形式,然后将该矩阵使用多个卷积核经过卷积操作生成不同的特征图,将这些特征拼接成代表输入三元组的特征向量,最后通过特征向量与权重向量相乘返回一个得分,该分数便是预测此三元组是否有效的标准。此外,Schlichtkrull 等提出了首个使用图卷积网络(Graph Convolutional Network,GCN)建模知识图谱实体关系网络的模型R-GCN(modeling Relational data with GCN),它在使用图卷积网络的基础上考虑了三元组中关系的方向,并根据不同的关系学习到不同的特征信息,通过对实体的邻域特征和自身特征进行加权求和得到新的实体特征,此模型虽然使用图卷积网络建模复杂实体关系网络,但在知识表示学习中表现不够优秀。Nathani 等提出了KBGAT 模型,该模型第一个实现了将GAT 应用到知识图谱表示学习中,它使用了GAT和ConvKB 组合的分步编码、解码器结构,在编码器阶段,首先将三元组的实体、关系通过向量拼接后执行线性变换作为该三元组向量表示,通过将不同的权重分配给目标节点构成的三元组向量表示来得到对目标节点的向量表示,在此之上进一步挖掘N
跳邻居的特征信息来增加目标节点的语义丰富性,最后将向量表示送入到ConvKB 解码后执行链接预测任务,该模型在实验中取得了更好的效果。2 本文模型
在知识图谱中,实体关系之间存在潜在联系,能够对实体语义进行补充,而且实体常常拥有大量描述信息,因此本文在使用GAT 基础上引入实体描述信息,并且不使用KBGAT 中分步训练的编码器―解码器结构,而是参考DKRL的训练方法,旨在学习到三元组的结构信息的同时,以外部描述信息与内部邻居节点信息作为补充进行联合训练。具体来说,BAGAT 模型采用GAT 获取N
阶邻居节点对目标节点的加权表示,使用BERT 预训练模型获取实体的描述信息向量表示。KBGAT 模型已经证明了使用GAT 建模实体关系网络在知识表示学习中的作用,以图1 为例,当要推理的目标节点U.S.A 中融合了像(Google,Belong_to)、(New York,Located_in)等邻居节点的语义信息时,节点U.S.A 的向量表示会更加丰富,在进行三元组推理时结果也会更准确。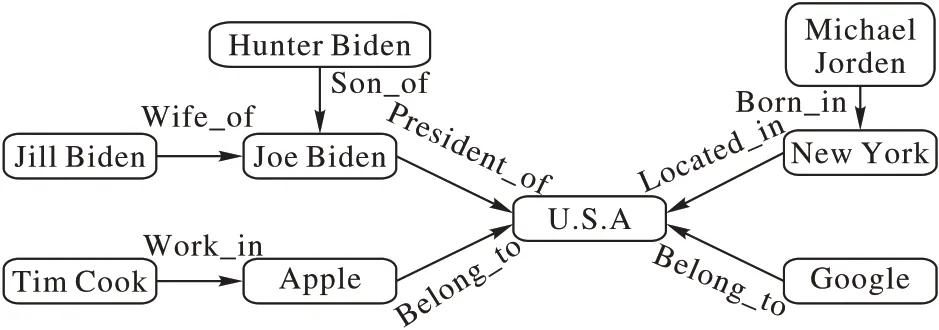
图1 知识图谱网络结构Fig.1 Knowledge graph network structure
2.1 基于GAT的实体向量表示
传统的GAT 通过学习邻居节点的权重,从而实现对邻居特征的加权求和,为了在知识图谱的三元组中将关系作为一部分重要信息加入训练同时结合三元组的结构特征,在使用GAT 对节点进行表示时,除了将实体作为初始输入向量外,也将关系作为重要信息添加到图注意力模型中。具体来说,为了将注意力机制应用在目标节点与邻居节点上,首先将邻域内实体与关系进行加权求和,对目标节点和邻居节点的构建方法如式(1)、(2):

h
、t
分别代表头实体、尾实体的初始向量表示;r
代表关系的初始向量表示;权重参数ρ
∈(0,1)用于调整关系向量与实体向量构成邻居节点时所占的比重,从而将每个三元组的实体和关系都参与到图注意力模型的计算中。为了计算h
对目标节点h
的影响权重,定义两者的注意力值v
如式(3):
W
代表投影矩阵;注意力机制a
是单层前馈神经网络。将式(3)展开得到具体计算公式(4)。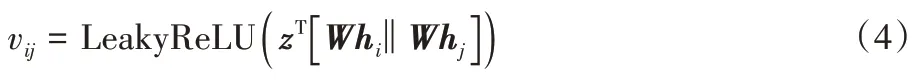
z
做一次线性变换,再使用LeakyReLU 函数做非线性激活,最后使用Softmax 函数对每个节点与所有邻居节点的注意力值做归一化处理。归一化后的注意力权重即为最后的注意力系数,如式(5):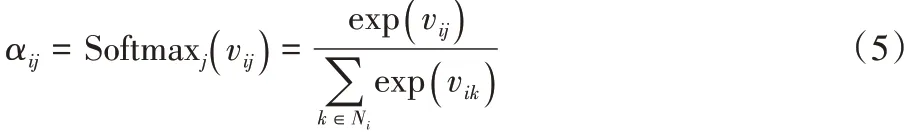
N
表示目标节点h
的邻居节点,即由式(2)中与目标节点t
相邻的h
和两者之间的关系r
构成。注意力机制简要图示如图2 所示。将计算的注意力系数进行加权求和,如式(6):

h
′是基于GAT 输出的对于每个节点i
的新特征向量,新的向量表示融合了知识图谱中实体的邻域信息;σ
是激活函数,目标节点的输出与所有邻居节点的特征向量都相关。为使模型更稳定地学习邻居节点的特征,将采用多头注意力机制获得不同特征进行集成;为防止过拟合现象,将K
个独立的注意力机制得到的向量表示拼接。具体表示如式(7):
||
表示拼接。在图注意力模型的最后一层,将对得到的向量表示进行K
平均计算而不再拼接,如式(8):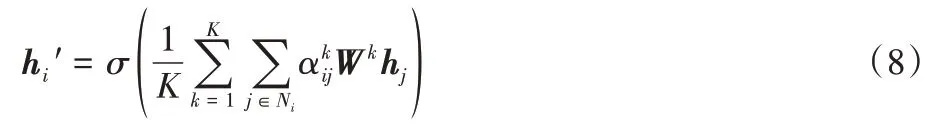
为了获得与实体向量变换后同样的关系向量表示,将使两者共享输出维度,在完成一次图注意力的计算后对关系向量做线性变换,如式(9):

R
代表输入关系向量集合;W
∈R代表线性变换矩阵,T
代表转换前向量维度,T′
代表转换后的维度。此外,在获得新的实体向量表示过程中可能会造成原来结构特征信息的损失,所以在最后得到的实体表示中添加经过线性变换的初始实体向量来解决,如式(10):
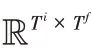
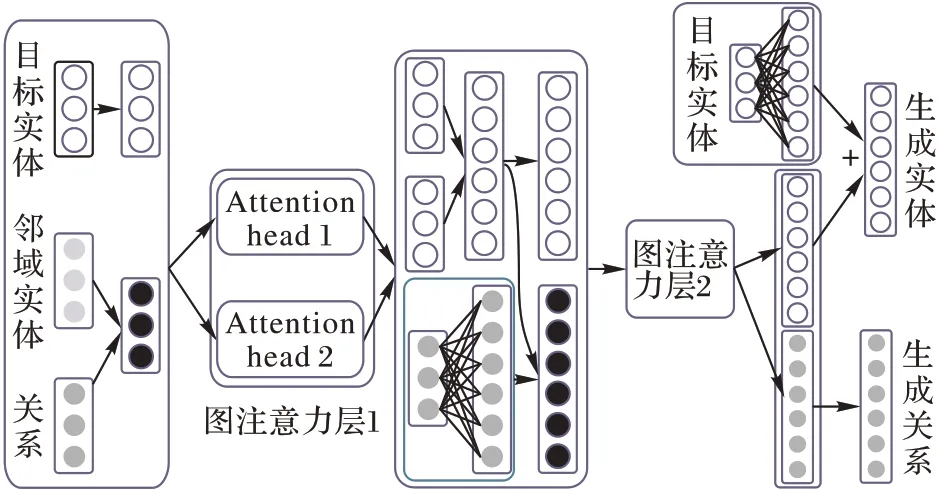
图3 图注意力层网络结构Fig.3 Graph attention layer network structure
除了结合一阶邻居节点外,进一步挖掘N
阶邻居节点对目标节点的向量表示,将此类节点看作组合的三元组,表示为(头实体,多个关系组成的关系路径,尾实体)的形式,例如在图1 中,对Jill Biden 与U.S.A 建立(Jill Biden,Wife_of/President_of,U.S.A)的组合三元组形式,对高阶邻居中的多个关系进行加和后取平均值作为最终关系向量表示,如式(11):
R
代表N
阶实体间的关系表示集合;r
代表它们的向量表示。2.2 基于BERT模型的实体向量表示
使用基于实体描述信息的向量表示可以捕捉更准确的文本信息特征,对各类实体有更好的区分效果,DKRL 中将描述信息分别作了连续词袋编码和卷积神经网络编码,改变了翻译模型中仅考虑实体间结构特征而忽略其他信息的方式,在知识表示学习中取得了更好的效果,但连续词袋编码没有脱离Word2vec(Word to Vector)词向量所带来的问题,它产生的向量表示是静态的,并且对上下文语义的考虑不够充分,卷积神经网络虽然考虑了词序信息,但输入只用了部分短语,对实体描述信息语义表示不足。本文采用BERT 模型对实体的描述信息进行向量表示,它使用双向Transformer 作为算法主要框架,核心是注意力机制,经过编码器可以学习到每个词左右两侧的信息,因此可以获得更准确的词向量表示。使用BERT 模型得到的词向量是由三种嵌入特征求和而成,具体方式如图4 所示。

图4 BERT的输入表示Fig.4 Input representation of BERT
它分为三部分:词向量编码(Token Embeddings)、对句子进行切分(Segment Embedding)、学习出来的位置向量(Position Embedding)。在词向量编码任务中,本文使用BERT 预训练模型完成,这样就不需要再用大量的语料进行训练。此次任务不改变预训练模型的参数,只把句子作为输入放入预训练模型,以标识符[CLS]代表句子开始,得到的输出向量作为特征向量输入到下一个任务中。由于任务只需要编码实体描述的句向量,所以在选择保留原始单词顺序下,对部分长度超过510 词的句子,只取前510 个词作为输入,然后得到输出句向量,最后通过式(12)的线性变换来获得与图注意力模型向量同样维度的实体向量表示。

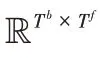
2.3 得分函数
为了将三元组的结构特征信息、三元组实体关系语义信息和实体描述信息结合起来,本文将两种嵌入向量放在相同的连续向量空间中进行联合知识表示学习,其中包括通过GAT 训练得到的向量表示和通过BERT 模型得到的向量表示,为了将两种向量表示融合,根据DKRL 的训练方法,定义能量函数如式(13):

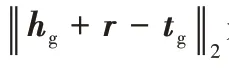

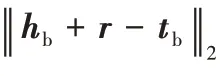
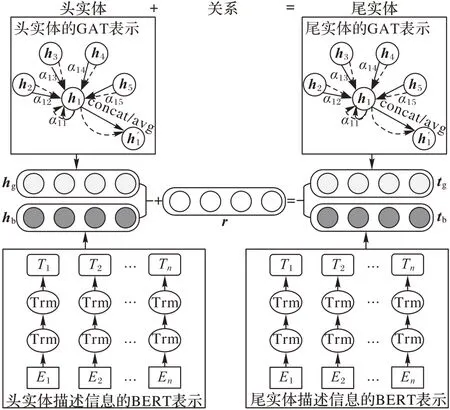
图5 BAGAT模型结构Fig.5 BAGAT model structure
2.4 损失函数
在模型训练中,与翻译模型的训练目标相同,采用基于边际的得分函数作为训练目标,定义如式(15):
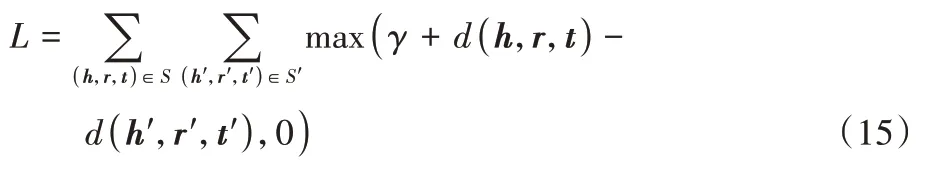
γ
为最大间隔参数;S
为正例三元组的集合;S′
代表头实体或尾实体被随机替换后生成的负例三元组的集合,S′
的定义为。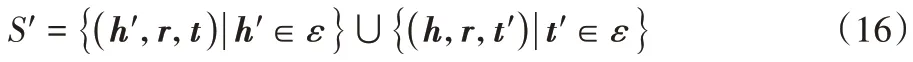
ε
代表实体的嵌入表示,随机构建的负例三元组可能本身就作为正确的三元组存在数据集中,因此剔除这些已存在于数据集中的正确三元组。3 实验与结果分析
3.1 实验数据集
FB15K-237数据集是Freebase的子集,它相对于FB15K 数据集删除了多余的关系,其中每个实体的实体描述信息使用DKRL 模型中的实验数据。WN18RR 数据集是WordNet的子集,它相较于WN18 数据集消除了反向关系,很大程度增加了推理的难度,将WordNet 中对实体的定义作为实体的描述信息数据。实验数据集的具体信息如表1所示。

表1 实验数据集统计信息Tab 1 Experimental dataset statistics
3.2 实验设置
基于实体描述信息的向量使用Google 官方预训练模型Bert-Base-Uncased 获取,它使用12 层的Transformer 训练,每层加入12 个多头注意力获取数据特征,隐藏层单元768 个,最后将实体嵌入维度变换为200。在获取基于GAT 的表示时,使用TransE 的训练向量作为实体和关系的初始化结构特征向量表示,初始嵌入向量维度为50。在选择N
阶邻居节点对目标节点的表示时,因节点间距离越远在训练中所占权重越小,所以本文选取2 阶邻居节点,模型最后输出实体和关系向量维度设为200,LeakyReLU 的alpha 参数设置为0.2。为防止模型的过拟合,采用L2 正则化。在FB15K-237 数据集上,Drop_out 设置为0.3,ρ
值选择为0.6,训练迭代3 000次,训练批次大小为20 000,基础学习率为0.001,边界值γ
为1.5。在WN18RR 数据集上,Drop_out 设置为0.3,ρ
值选择为0.5,训练迭代3 600 次,训练批次大小为10 000,基础学习率为0.001,边界值γ
为1.0。训练中采用Adam 优化算法。3.3 三元组分类任务实验
三元组分类任务是确定给出的三元组(h
,r
,t
)是否符合客观事实,即是否成立,可以视为二分类问题,实验使用3.1节中实验数据集中的FB15K-237 和WN18RR。错误三元组的构建采用与上文训练时构建负例三元组同样的方式,为保证测试数据的合理性,本文选取同样数量的正确与错误三元组进行测试。分类规则是对于一个给定的三元组,通过比较其得分函数和给定阈值δ
的大小确定分类效果,若得分比阈值低,则判定为正确三元组,反之为错误三元组。每种关系的阈值由验证集中关于特定关系的最大化分类准确率决定。三元组分类结果如表2 所示。相较于DKRL,本文模型在数据集FB15K-237 和WN18RR 上分别提高了5.8 和1.5 个百分点,与KBGAT 相比分别提高了3.7 和1.1 个百分点,本文模型分类准确度更优于其他基准模型。这说明使用GAT和实体描述信息所得到的联合向量表示能够更好地区别语义相近的不同实体,更有效地表示复杂的实体关系特征,在对三元组的分类中使正确三元组得分更低、错误三元组得分更高,说明了本模型有较优的分类性能。
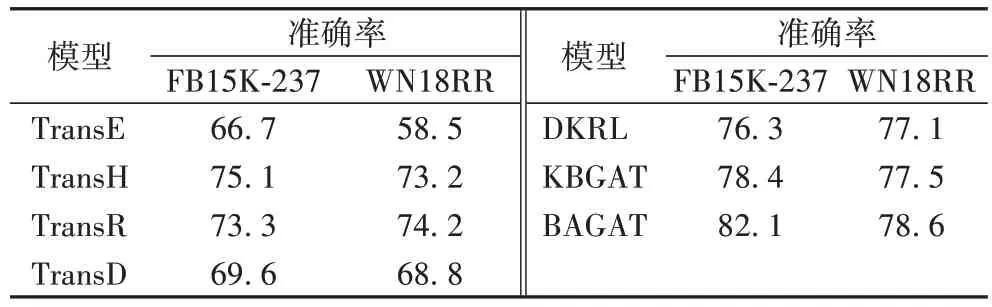
表2 三元组分类准确率 单位:%Tab 2 Accuracy of triple classification unit:%
3.4 链接预测任务实验
链接预测旨在测试模型的推理预测能力,对给定的一个正确三元组(h
,r
,t
),在缺失头实体h
或尾实体t
后,在原实体集中随机选择头尾实体补全,对于缺失位置,通过模型计算出重组的三元组的得分后升序排序,最终正确三元组的排名会被记录下来。在随机替换头尾实体时,可能会出现替换后三元组本身就是知识图谱中的正确三元组的问题,那么这种三元组可能会排在目标三元组的前面,所以为了最终实验的准确性,实验时采用“Filter”方式将存在的干扰三元组过滤掉后排序。
为了对比分析,实验采用以下评价指标:1)MeanRank(MR),正确实体得分排名平均值,该指标值越小说明预测结果越好;2)Hits@n
,正确实体排名在前n
名的比例,该值越大说明预测模型越准确,在测试中n
值分别取1、3、10。模型在FB15K-237 数据集的实验结果如表3 所示:BAGAT 在四项指标上的表现都超过了其他对比模型,尤其是在Hits@1 和Hits@10 的表现:与TransE 相比,BAGAT 分别提升了25.9 和22.0 个百分点;与KBGAT 相比,BAGAT 分别提高了1.8 和3.5 个百分点。
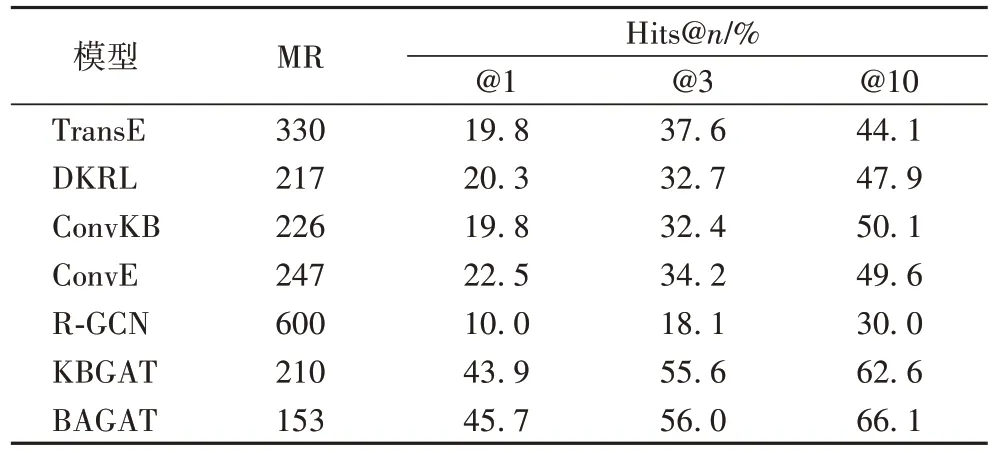
表3 FB15K-237数据集上的链接预测结果Tab 3 Link prediction results on FB15K-237 dataset
在WN18RR 数据集上的实验结果如表4 所示,BAGAT 在Hits@3、Hits@10 两项指标上超过了其他对比模型,而在MR和Hits@1 上没有达到最好表现,最主要原因是数据集中训练数据比较稀疏,实体描述信息不足,这导致模型不能学习到很好的三元组特征。但每个实验结果都要优于KBGAT 模型,其中在Hits@10 指标上提高了1.2 个百分点。
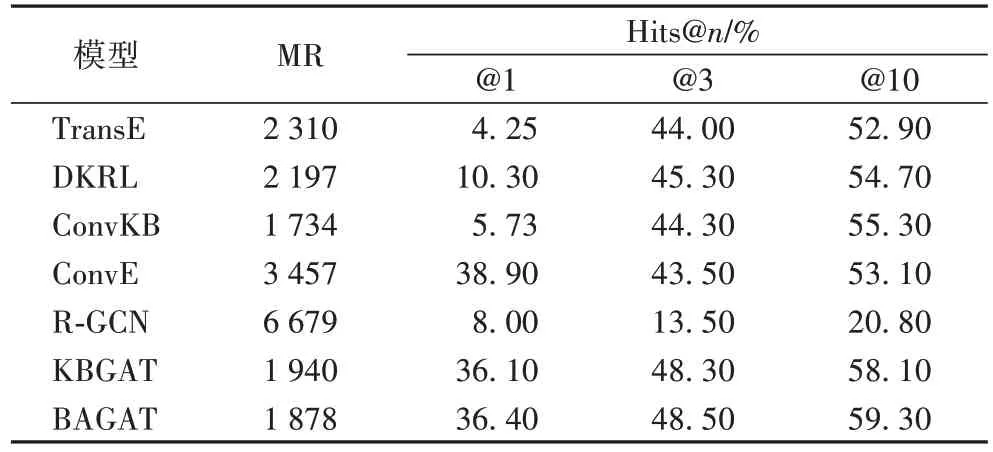
表4 WN18RR数据集上的链接预测结果Tab 4 Link prediction results on WN18RR dataset
综合实验结果可以看出,本文模型使用BERT 编码实体的描述信息使每个实体有了更丰富的语义信息,其次就是通过应用GAT 将实体和关系联合构造邻居节点的方法使目标节点结合了更多邻域内实体和关系的信息,使模型的推理能力得到了提高,验证了对于KBGAT 模型的改进是有效的。另外,实验结果还表明,模型在使用联合训练方法而去掉KBGAT 模型中使用ConvKB 作为解码器的训练步骤后仍然具有高效的链接预测性能。
4 结语
本文在KBGAT 模型基础上进一步考虑了基于实体描述的向量表示模型,同时将GAT 应用到三元组中使其更适应于知识图谱的知识表示学习任务;此外本文使用了多源信息联合训练方法,取代了分别训练编码器与解码器的步骤。实验结果显示使用GAT 和BERT 模型联合编码数据的方法在两个数据集上分类性能均有不同程度的提高。本文模型重点使用了实体的描述信息和三元组内部的实体关系特征信息,但对于知识图谱中的诸如类别信息,其他知识库信息、图像信息等还没有利用,所以多源的联合知识表示学习方法仍然是未来研究和改进的方向。
