
基于CNN 的乳腺癌病理图像分类研究
2022-05-06 03:25:32易才键王师玮
智能计算机与应用 2022年3期
易才键, 陈 俊, 王师玮
(福州大学 物理与信息工程学院, 福州 350108)
0 引 言
据世界卫生组织国际癌症研究机构(IARC)2020 年发布的研究数据显示,乳腺癌正式取代肺癌,成为全球第一大癌症。 其中,女性癌症患者中乳腺癌的占比最高,远超其他癌症类型。 目前对乳腺癌的诊断主要是依靠组织病理学分析,乳腺癌的最终诊断,包括分级和分期,大都由病理学家对组织病理图像进行分析得到,因此这是诊断乳腺癌的金标准。
随着计算机技术的发展,已有许多学者尝试将计算机辅助诊断(CAD)应用在乳腺癌病理图像的自动分类中,并取得了一系列的研究进展。 在传统机器学习领域中,自动诊断的方法主要是基于人工的特征提取,结合分类器实现的。 Roy 等人设计了特征提取器,提取了纹理和统计特征,将这些特征组合起来,生成一个包含782 个特征的数据集,通过使用多种分类器进行训练和分类,得到的最优识别率为92.55%;Spanhol 等人公开了BreakHis 数据集,并基于此数据集,使用了6 种不同的特征提取器,并为每个特征提取器结合了4 种分类器,最终的识别准确率为80%-85%。 但基于人工的特征提取不仅需要耗费大量的时间和精力,还要求特征提取人员具有相应的专业领域知识。 此外,特征提取人员的经验和精神状态都会影响到特征提取的质量,严重影响了计算机辅助诊断技术在实际中的应用。
近年来,随着计算机运算能力和人工智能的快速发展,深度学习技术在许多领域得以应用,尤其在图像处理方面取得了很大的进展。 利用深度学习技术可以自动的从图像中提取特征,避免了传统机器学习中人工提取特征的局限性,节省了人力。如今已有很多的学者将深度学习技术应用在乳腺癌诊断中,在一定程度上提高了乳腺癌诊断的准确性。Spanhol 等人在BreaKHis 数据集上应用AlexNet网络,得到的识别率比传统机器学习算法高出6%;Nawaz 等人使用DenseNet CNN 模型对乳腺肿瘤的亚型进行预测,准确率达到95.4%;邹文凯等人对GoogleNet 中的Inception 结构进行调整,并采用所有放大倍数统一训练、独立测试的方法,以患者级别作为评价标准,其准确率为87%-90%。 上述方法虽然已经具有一定的准确率,但还需进一步提高识别的准确率和模型的鲁棒性。
针对上述问题,本文以VGG16 网络为基础,对网络结构进行调整,同时结合数据增强和迁移学习策略,在公开的BreakHis 数据集上进行训练,训练得到的模型将用作于乳腺癌病理图像的良恶性分类;为解决数据集存在的样本不均衡问题,本文使用焦点损失函数(Focal Loss)作为实验的损失函数,能在一定程度上缓解样本不均衡问题;对4 种不同放大倍数的图像统一训练,让网络能够学习到更深层次、更复杂的特征,提高模型的鲁棒性,在测试时则对不同放大倍数的图像进行独立测试,更好地模拟实际应用场景中的乳腺癌病理图像分类。
1 本文方法
1.1 卷积神经网络
在2012 年的ImageNet 图像分类竞赛上,AlexNet 网络强势夺冠,该网络的分类效果远超当时的其他模型,深度学习技术从此受到广泛的关注。与传统的机器学习方法相比,深度学习的优势在于不需要人为的提取特征,而是依靠神经网络本身去学习样本的特征,提高了特征提取的便利和准确性。
卷积神经网络(Convolutional Neural Network,CNN)作为最常用的深度学习模型之一,在图像处理领域表现优异,本文使用CNN 来构造图像分类模型。 CNN 通常由输入层、卷积层、池化层和全连接层组成,如图1 所示。 将2D 或3D 图像输入,由卷积层提取图像的特征,池化层对提取到的特征进行降维、压缩数据和参数的数量。 经过一系列的卷积和池化操作,CNN 可以同时学习到数据的低层特征和高层特征,在全连接层得到易被网络区分的特征,便于后续的分类。
相较于传统的神经网络,CNN 具有两大优势:局部连接和权值共享。 局部连接是相对于全连接而言的,全连接是指网络中的每个结点都相连,而局部连接则是部分结点相连。 实际处理过程中,图像的像素点通常与临近的像素点关联较大,与远处的像素点关联较小,局部连接可以形成具有高区分性的局部特征。 权值共享是指使用同一卷积核对整幅图像进行卷积运算,可以减少运算时的参数量,加快运算速度。

图1 卷积神经网络典型结构Fig. 1 Typical structure of convolutional neural network
1.2 迁移学习
迁移学习是将从一个任务训练得到的模型移植到其他任务上。 目前,迁移学习方法主要有实例迁移、特征迁移、共享参数迁移和关系知识迁移。本文采用参数迁移方法,用已经在其他数据集(源域)上训练好的模型来初始化本文的网络,之后在本文使用的数据集(目标域)上重新训练,对网络的参数进行调整。 卷积神经网络在开始训练时,是随机初始化每个参数的,如果此时训练的数据量较小,容易导致模型无法学习到数据的规律,进而影响模型的性能。 借助迁移学习技术,可以在一定程度上缩短训练时间,有效的抑制欠拟合和过拟合现象,提高模型的泛化性能。
ImageNet 数据集是一个用于计算机视觉的大型可视化数据集,该数据集有超过1 000 万幅的自然图像,共1 000 个类别的手动标注。 本文将ImageNet 数据集作为源域,先将网络模型在该数据集上训练,训练得到的模型参数用作本文数据集训练时网络的初始化。 考虑到自然图像和医学图像存在的差异,本文仅将源域的模型参数用作网络初始化,且构造新的全连接层,在BreakHis 数据集上对网络层的所有参数进行新的训练和调整。
1.3 VGG16 网络
VGG 网络是由牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind 公司的研究员一起研发的,该网络取得了ILSVRC2014 比赛分类项目的第二名,具有良好的特征提取能力。 本文以经典的VGG16 网络为基础,对网络的全连接层进行调整,调整后的网络结构如图2 所示。
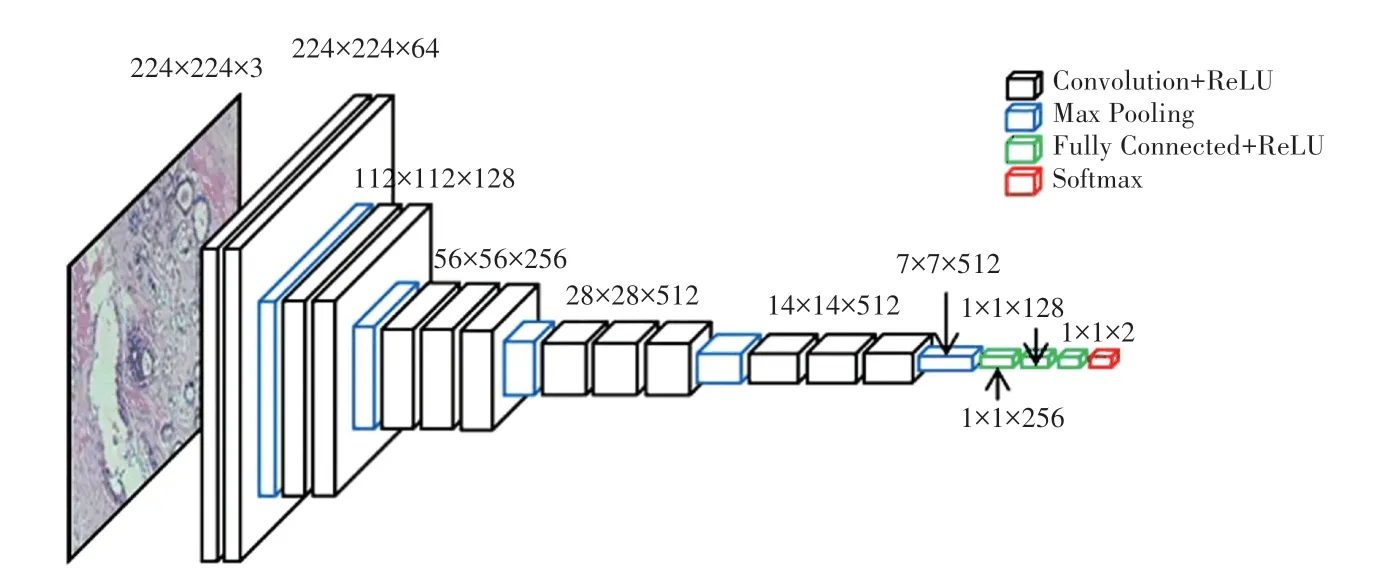
图2 调整后的VGG 网络结构Fig. 2 Adjusted structure of VGG network
网络的输入采用224×224 的RGB 彩色图像,共包含13 个卷积层,5 个最大池化层以及3 个全连接层。 3 个全连接层对应的神经元节点个数调整为256,128,2,原网络的全连接层神经元节点个数为4 096,4 096,1 000。 调整后的VGG16 网络具有以下特点:
(1)使用小尺寸的卷积核,以3×3 大小的卷积核为主。 相较于5×5 或7×7 的大尺寸卷积核,小尺寸的卷积核不但计算量小,而且更能提取到图像的细节信息;
(2)全连接层神经元的个数较少,由于卷积神经网络的大部分参数量都集中在全连接层,对全连接层的维度进行压缩,可以轻量化模型,降低过拟合的风险。
深度学习算法的缺点是网络训练困难,通常要消耗较多的时间,且利用梯度下降法容易陷入到局部最优解。 为了解决这些问题,本文将批量归一化(BN)算法加入到网络中,来缩小每个训练批次间的分布差距,加快网络训练速度。 BN 算法的公式(1)和公式(2):


综上所述,本文使用网络参数量少,训练速度快,分类性能优秀,用该网络对BreakHis 乳腺癌组织病理图像数据集进行训练和分类,取得了良好的效果。
2 数据集
2.1 数据集来源
本文采用公开的数据集BreakHis,该数据集包含来自于82 位患者的7 909 幅已标注的乳腺癌组织病理图像,其中良性肿瘤图像2 480 幅,恶性肿瘤图像5 429 幅。 每幅病理图像均采用4 种不同的放大倍数(40X、100X、200X、400X),大小均为700×460的R、G、B 三通道图像。 BreakHis 数据集的部分图像如图3 所示;该数据集的具体分布情况见表1。
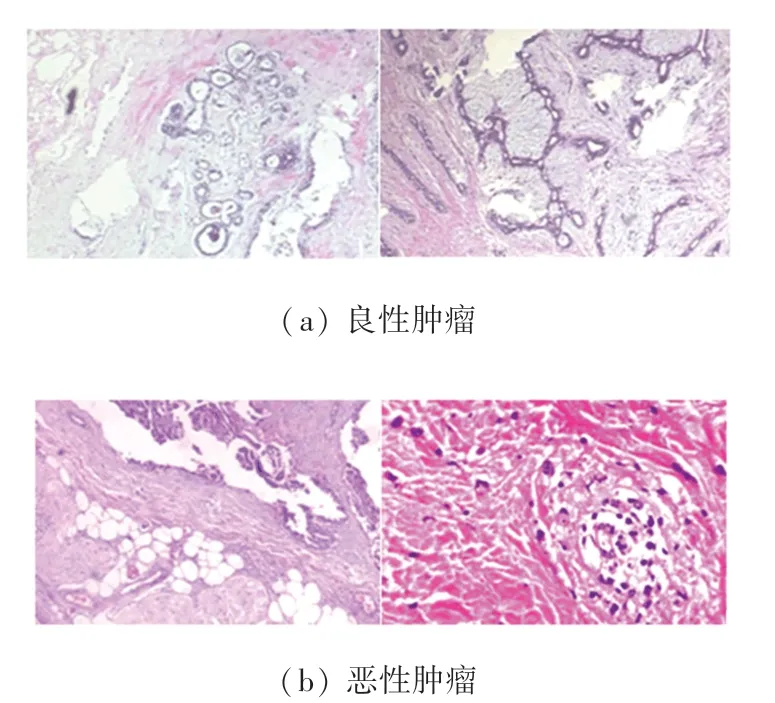
图3 数据集部分图像Fig. 3 Partial image of data set
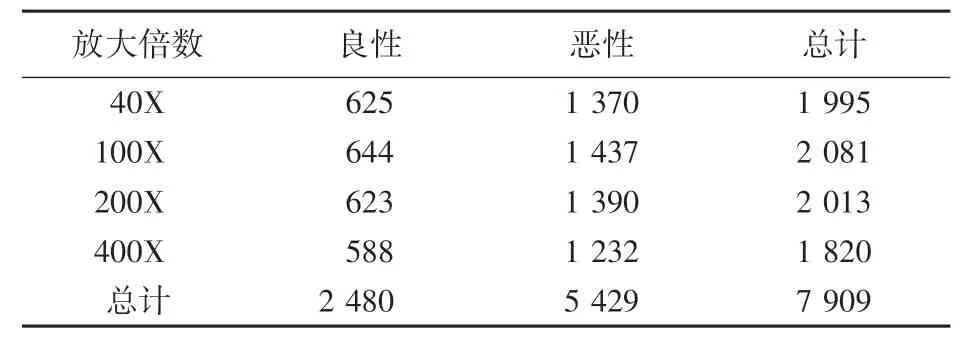
表1 不同放大倍数的良、恶性肿瘤图像分布Tab. 1 Image distribution of benign and malignant tumors with different magnification
2.2 数据增强
BreakHis 数据集仅有7 909 幅乳腺癌病理图像,这对于神经网络的训练来说是远远不够的,因此需要利用数据增强来增加训练数据,降低模型过拟合的风险,提高模型的泛化性能。 常用的数据增强方法包括:翻转、旋转、裁剪、平移、高斯噪声,模糊等。
本文按照7:3 的比例将原数据集划分为训练集和测试集,且仅对训练集的数据进行6 种方式的数据增强。 首先,将训练集数据进行水平翻转、垂直翻转、逆时针旋转90°、180°、270°共5 种操作,将数据扩充至原来的6 倍;再对上述图像按照0.8 的比例缩放。 经过这6 种方式的变换,训练集数据扩充至原来的12 倍,其中训练集图像66 444 张,测试集图像2 372 张。 扩充后的数据集的分布情况见表2。

表2 数据增强后的图像分布情况Tab. 2 Image distribution after data enhancement
3 实验及结果分析
本文的实验基于开源的深度学习框架Pytorch,CPU 型号为IntelCore i7-9000K,内存为16 GB,显卡型号为NVIDIA GeForce RTX 2080 Ti。
3.1 训练策略
为了更好地训练分类模型,本文模型的参数通过迁移学习策略进行初始化。 在实验过程中,将所有训练数据的尺寸统一为224×224×3,然后分为小批次训练,每个小批次包含32 幅图像。 采用Adam 作为本次实验的优化器,在训练过程中自动调整学习率,提高模型分类的准确率,本次Adam 优化器的参数均采用默认参数,使用函数作为激活函数。
3.2 焦点损失函数
通常在分类任务中,会使用交叉熵函数作为损失函数,以二分类为例,二分类交叉熵(Binary CrossEntropy,BCE)的公式(3)为:

其中,代表损失值;为病理标签,=0 代表良性,=1 为恶性;^∈(0,1)为神经网络输出的预测值。
交叉熵函数虽然有着广泛的应用,但也存在明显的缺陷,即交叉熵函数会受到简单易分类样本的影响,导致训练过程中偏离正确的优化方向,对分类效果产生一定的影响。 从表1 可知,BreakHis 数据集存在样本类别不均衡问题,经过数据增强后,训练集中的良、恶性肿瘤图像数量分别为20 856 和45 588张,两种类别的图像数量差距明显,故采用焦点损失函数代替二分类交叉熵函数,其公式(4)为:

实验结果表明,引入焦点损失函数能够在一定程度上缓解类别不均衡问题,提高模型的分类效果。
3.3 评价标准
医学图像的分类通常可以从两个方面评价模型的分类性能:患者级别和图像级别。
本文不考虑患者级别,仅从图像级别来计算识别准确率,则图像级别的识别率可表示为公式(5):
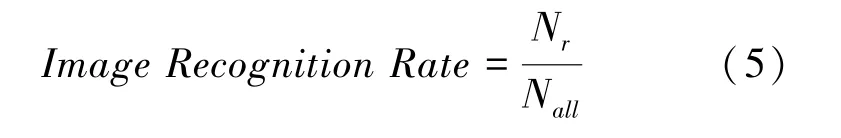
其中,N代表测试集中病理图像总的数量,N代表被正确分类的图像数量。
3.4 实验对比分析
3.4.1 不同损失函数下的准确率对比
2) 配置连接核心交换机CS6509的端口属性Switch Port Configuration→Port Groping Parameters,设置所属的端口组为student1,启用端口聚合协议PAgP(Port Aggregation Protocol),端口模式采用desirable模式[15].
本次实验将焦点损失函数(Focal Loss)与分类任务中应用广泛的二分类交叉熵(BCE)对比,分别使用这两种函数作为训练过程中的损失函数,实验结果见表3。 从表3 可以看出:
(1)Focal Loss 作为损失函数时,良恶性肿瘤的分类准确率仅相差0.29%;而使用BCE 的情况下,相差3.44%,此时模型对于较多样本(恶性肿瘤)产生了倾向性,不利于对肿瘤的诊断;
(2)使用Focal Loss 时,虽然对恶性肿瘤的分类准确率略低于使用BCE 的情况,但对于良性肿瘤的分类准确率却得到了很大的提升,这样的模型更接近实际生活,具有更强的鲁棒性;
(3)模型的平均准确率有所提高。
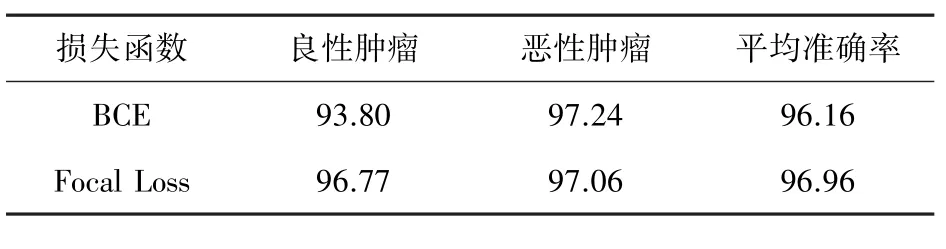
表3 不同损失函数下的准确率对比Tab. 3 Comparison of accuracy with different loss functions
3.4.2 不同训练策略下的准确率对比
使用不同的训练策略,共进行4 次实验,实验均采用Focal Loss 作为损失函数。 这4 种策略分别是数据增强结合迁移学习策略、数据增强策略、迁移学习策略、无数据增强和迁移学习策略,结果为网络迭代10 000次过程中的最佳模型在测试集上的准确率,如图4 所示。

图4 4 种训练策略下的准确率Fig. 4 Accuracy under four training strategies
由图4 可知,采用迁移学习策略,无论是否进行数据增强,准确率都得到了大幅度的提升(图4 中红色和蓝色曲线对比),证实了迁移学习策略的有效性;采用数据增强策略后,无论是否使用迁移学习对网络进行初始化,训练的准确率都得到了一些提升(见图4 中红色和绿色曲线对比),证实了数据增强策略的有效性。 实验表明,本文采用有效的训练策略防止了训练过程中过拟合的现象,并大大的提高了模型的泛化能力,在BreakHis 数据集上的识别率为94%-98%。
3.4.3 与其他的分类方法对比
为了更好的评价本文的模型,本文选择与应用在同一数据集BreakHis 上的其他分类方法进行对比,这些方法采用与本文相同的评价标准,即以图像级别的识别率作为评价标准,见表4。 通过与其他分类方法的对比可知,本文方法在4 种不同放大倍数下的识别准确率均高于其他的分类方法,表明了本文训练策略的有效性及本文深度学习模型的鲁棒性。
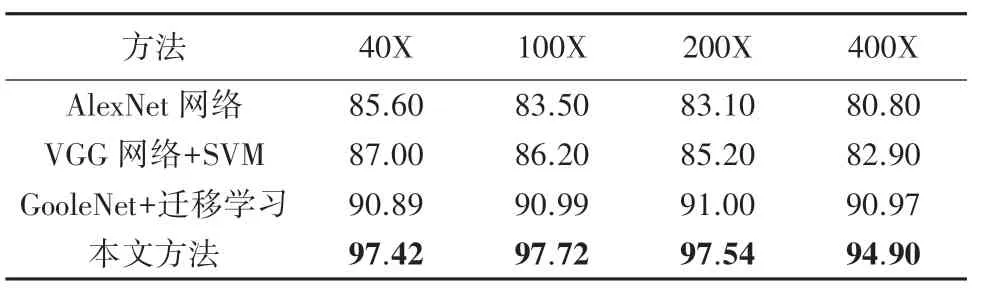
表4 不同放大倍数下各方法识别准确率的对比Tab. 4 Comparison of recognition accuracy of various methods with different magnifications
4 结束语
为解决传统机器学习在病理图像分类任务中存在的不足,提高乳腺癌病理图像的分类准确率,本文提出了基于CNN 的乳腺癌病理图像分类模型。 在公开的BreakHis 数据集上进行训练与参数优化,最终在4 种放大倍数下的平均识别率达到96.96%,其中40X、100X 和200X 倍数下的识别率均超过97%,展现出了优秀的分类能力;为解决医学图像数据集较少的问题,本文采用迁移学习和数据增强策略,利用迁移学习初始化网络,同时将数据集扩充至原有的12 倍,避免了过拟合现象的发生;为解决BreakHis 数据集存在的类别不均衡问题,本文采用焦点损失函数代替传统的交叉熵函数。 通过多个对比实验,验证了本文模型的优异性和训练策略的有效性,能够为早期发现和诊断乳腺癌提供有力指导。
猜你喜欢
中老年保健(2022年6期)2022-08-19 01:41:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国生殖健康(2019年2期)2019-08-23 08:11:42
电子制作(2019年11期)2019-07-04 00:34:38
中国生殖健康(2019年6期)2019-01-06 09:20:12
中国交通信息化(2018年5期)2018-08-21 03:37:40
祝您健康(2018年5期)2018-05-16 17:10:16
