
基于ExtraTree的软件缺陷预测方法研究
2022-05-05 07:21:26王馨煜崔艺凝段盈盈
智能计算机与应用 2022年3期
王馨煜,崔艺凝,段盈盈
(北京信息科技大学 计算机学院,北京 100101)
0 引 言
随着时代的发展和科技进步,计算机在人们的生活中越来越多地被使用。软件是计算机领域中非常重要的一部分,软件存在的缺陷也不可小觑。软件缺陷预测技术旨在预测出模型中的缺陷数和缺陷倾向性,从而根据预测结果对资源进行合理的分配,是缺陷检测技术的重要辅助手段。早期,研究人员通过经验来估计模型中可能存在的缺陷;后来出现了软件体积度量元和缺陷的关系式,用关系式来计算系统在测试之前存在的缺陷数;有研究者将代码对应具体文档位置,从而给出了缺陷率的公式;也有研究者假设模块规模符合指数分布,给出了缺陷密度的估算公式。
融合多分类器模型对软件缺陷预测技术有重大的研究意义,通过融合多分类器模型,不仅可以发现不同模型之间潜在的联系,还可以度量软件的可靠性。另外,融合多个效果较弱的分类器为一个性能较好的多分类器,还可以提高弱分类器的预测性能。
本文首先通过选择不同的分类器模型对提取的软件模块进行预测并输出结果;其次,对单个分类器模型与融合后的分类器模型的预测结果进行比对;采用基于集成学习的静态软件缺陷预测方法对软件模块缺陷进行预测。
1 相关研究
1.1 背景
软件缺陷预测技术旨在预测出软件模块的缺陷,明确存在缺陷模块的缺陷数和缺陷倾向性。软件模块存在缺陷可能会造成财产损失和安全隐患。如:1996年6月因导航系统的计算机软件故障导致欧洲“阿丽亚娜”号航天飞机坠毁;1999年美国火星探测飞船坠毁事件,不包括损失时间,其工程成本耗费3.27亿美元。软件缺陷预测技术是避免软件运行故障,减少不必要损失的重要手段,该技术自开始研究后就受到了众多的关注。
早期的软件缺陷通过员工的经验来估计,后来Akiyama明确给出了最早的软件缺陷与代码行的关系量化式,但只是在程序开始前初步对可能存在的软件缺陷进行估算,并不完美。随着测试软件的规模与其复杂度的逐步提高,开发者更加重视的是软件缺陷预测技术的精准度及模块测试的正确率是否能够保证在一个稳定的范围里,是否可以更加高效地完成测试。成熟的软件缺陷预测技术可以在软件发布之前预测出真正有缺陷的程序模块,从而提高软件的质量,减少资源消耗。
1.2 国内外研究现状
目前,国内外研究人员从不同的角度研究了静态缺陷预测和数据驱动缺陷预测等方法。在异常值检测和处理、高维度数据、类不平衡问题和数据差异等方面进行了研究,主要使用机器学习和统计方法来预测缺陷模块。如:Freund和Schapire研究的Adaboost迭代算法,可以增强预测模型的精度;Wolpert提出的Stacking算法,可以集成若干基分类器的分类性能,从而提高分类效果等。
越来越多的预测模型的出现使研究者的注意力更多地集中在模型预测精度上,实验数据集的差异性和单一分类器预测性能的局限性是影响软件缺陷预测精度的两大原因。针对数据集的差异性,Sun等提出了通过特征选择提高预测精度的方法;Xu等提出了Logistic方法通过寻找最佳拟合参数来提高预测效率;针对单一分类器预测性能局限性的问题,Zhu等人提出了无监督的特征选择方法。除此之外,集成学习方法也是解决单一分类器的预测性能不够泛化问题的重要途径,通过将多个弱分类器集成为一个强分类器,进而提高软件缺陷预测的性能。
1.3 本文研究内容
本文针对不同预测模型对软件缺陷预测结果差异性较大的问题,对结构复杂、类别不平衡、缺乏历史数据的静态软件缺陷模块采用基于集成学习的软件静态缺陷预测方法,利用已有的缺陷数据集,选择Extra-Trees(极度随机树)来将多个弱分类器集成,并通过实验对多个分类模型进行了验证,并对融合前后各个模型的预测结果进行了比对。
在实验中使用SMOTE方法(Synthetic Minority Oversampling Technique)对数据集进行预处理,选择5种基分类器并结合Extra-Trees集成方法进行验证。为了能够有效评价分类结果,本文选择了准确率、召回率、F值3个业界认可的评价指标对预测结果进行评价。
2 相关理论与技术基础
2.1 SMOTE采样
为解决样本少,特征缺失的问题,Chawla等人提出了SMOTE过采样方法,可以减少模型的过拟合。在训练模型时,样本数量少的类所能提供的信息也比较少,SMOTE方法通过对少数类样本的分析,将少数类样本合成新的样本并加入数据集中,重复分析、合成过程直到达到数据样本平衡。
生成新样本的方法如式(1)所示。

其中,P表示新样本;x是少数类样本点,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为y;N表示生成样本数量。
2.2 基于ExtraTree的缺陷预测方法
集成学习是解决类不平衡问题的方法之一,从数据中显式或隐式地学习多个模型,将这些模型有效结合,得到可靠、准确的预测。单一分类器模型的测试能力逐渐趋于饱和,并且对缺陷模块预测的范围并不具有广泛性,通过结合多个单一学习器,并聚合其预测结果的学习任务,聚集多个分类方法来提高分类的精度,可以获得比单一学习器更显著的泛化性能,也可以称作多分类系统。
目前,集成学习的主要问题就是如何将多个弱分类器合成一个强分类器,有效提高预测的精度。在实验中采用了ExtraTree(极度随机树)来集成多分类器模型,但使用这种方法前需要检查样本的数据是否适用ExtraTree缺陷预测方法。ExtraTree具有很少的关键超参数和用于配置这些超参数的合理启发式方法,能够处理很高维度的数据。相比于从训练数据集的引导样本开发每个决策树的随机森林,ExtraTree更适合整个训练数据集上的每个决策树,每个决策树都采用原始训练集,不会随机采样,训练速度更快。
2.3 分类器模型评价指标
软件缺陷预测模型可用于对软件模块的缺陷情况作分类处理,评价指标用于区分预测模型的优劣。在本次实验中选取了软件缺陷预测常用的评价指标:准确率(Accur acy),精确率(Precision),召回率(Recall)以及F1。
准确率()又叫查准率,是被正确预测出的有缺陷的样本数量与被预测为无缺陷的样本数量之比,如式(2):

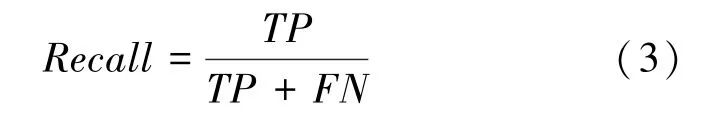
1可以看作是模型精确率和召回率的一种调和平均,如式(4):

其中,表示被正确预测出的有缺陷的样本数量;表示被预测为有缺陷的无缺陷样本数量;表示被预测为无缺陷的有缺陷样本数量;表示被正确预测出的无缺陷样本数量。
3 实验与结果分析
3.1 数据集
本实验采用数据集为NASA公布的MDP软件缺陷数据集,来自于十三个实际软件项目,数据集的基本信息包括样本集名称、模块总数、缺陷模块数、属性个数以及缺陷所占比例,不同数据集缺陷所占比例不同。从NASA MDP数据集中选取缺陷所占比例不同的数据子集KC1、KC3、MC2、MW1、PC1、PC3、PC4作为本文的实验数据集,见表1。

表1 NASA MDP数据子集Tab.1 NASA MDP Subset of the data
召回率(),又叫查全率,也就是被正确预测出的有缺陷的样本数量与实际有缺陷的样本数量之比,如式(3):
3.2 实验方法
选择的是决策树分类器、随机森林分类器、梯度提升分类器、基于直方图的梯度提升分类器、自适应增强分类器5种基础模型,通过极度随机树的集成学习方法融合5个基础模型。
为了保证所对模型的数据对比的有效性,每个实验的过程是相同的,5种基础模型以及极度随机树集成学习方法在NASA的数据子集上进行一次十字交叉验证,使、、13个对比指标数据进行同一数据集不同模型的数值对比。
3.3 实验结果分析
5个基础模型以及极度随机树集成学习方法在7个数据集中进行实验,得到的指标数据见表2。从表2可以看出,极度随机树集成学习方法在KC3、MC2、MW1、PC3这4个数据集上达到了比其他5种基础模型更好的1值,说明极度随机树对于特定数据集可以将弱分类器集成融合成一个较强分类器。随机森林分类器、基于直方图的梯度提升分类器、自适应增强分类器分别在KC1、PC4、PC1这3个数据集上1值达到最佳,该现象与KC1、PC4、PC13个数据集的类不平衡有一定关系。
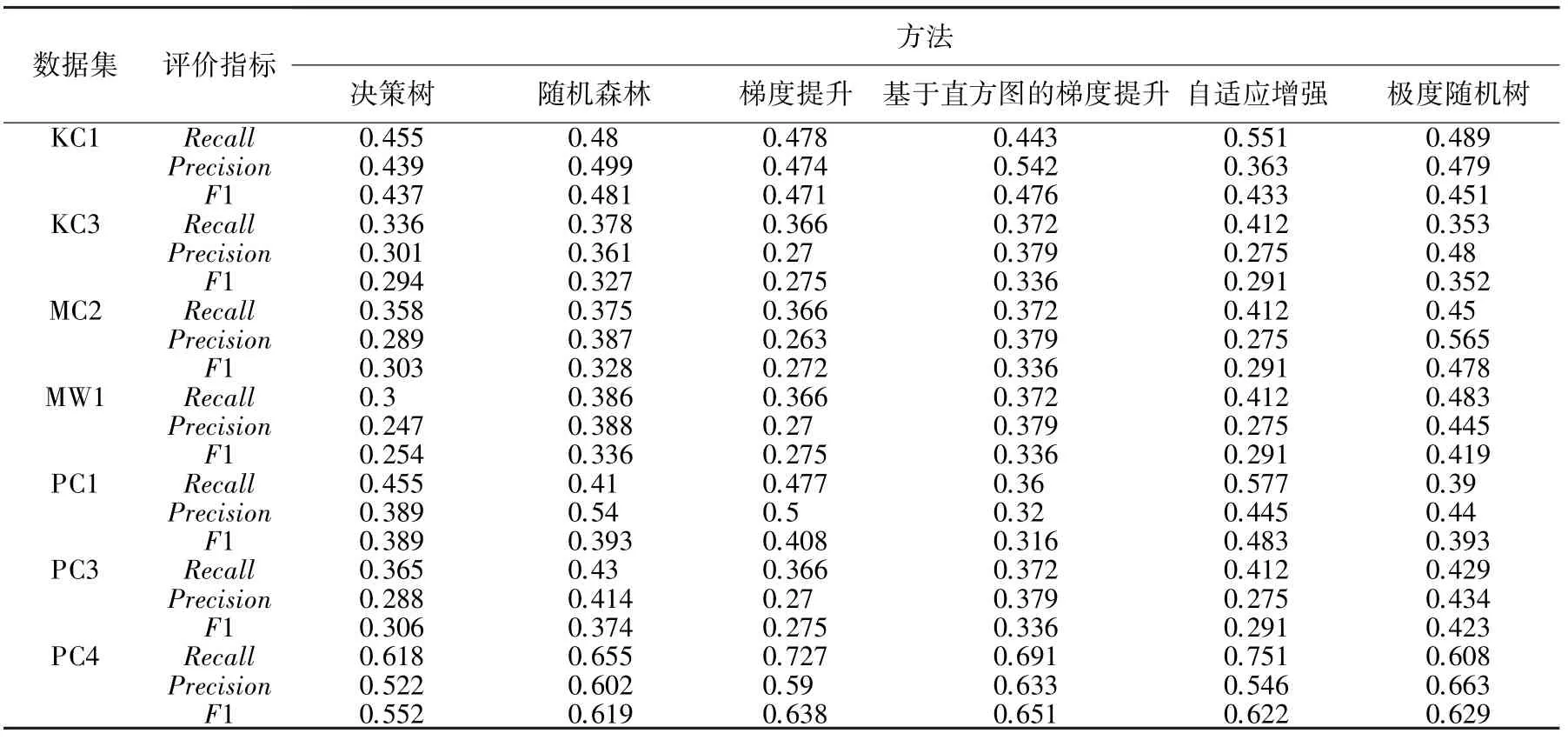
表2 NASA MDP数据集实验结果Tab.2 NASA MDP Experimental results of the data sets
4 结束语
本文基于极度随机数集成学习方法对决策树分类器、随机森林分类器、梯度提升分类器、基于直方图的梯度提升分类器和自适应增强分类器5个单个弱学习器进行了融合;用各个单分类器及基于ExtraTree的集成分类器分别对7个数据集进行了缺陷预测。本文就是选用了极度随机树这一集成学习方法,对5个性能较差的弱分类器进行了融合得到一个多分类器融合模型,然后对比单个分类器的预测结果和多分类器的预测结果,比较两者的预测性能,对软件缺陷预测模型的预测性能问题进行了研究。预测的结果得出融合后的学习器在选中的7个数据集中有4个数据集预测出的F1值都是优于任何一个单分类器的,在其他3个数据集中预测出的F1均处于第二或第三的位置。该集成学习方法无法在每个数据集中都达到最好的预测性能,后续将改进缺陷预测模块分布的稀疏性引起的相关问题。
猜你喜欢
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
电子测试(2018年1期)2018-04-18 11:52:35
三联生活周刊(2017年37期)2017-09-11 19:00:12
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
三联生活周刊(2015年26期)2015-06-26 09:38:23
电测与仪表(2014年15期)2014-04-04 12:05:20
电脑与电信(2014年10期)2014-03-13 08:18:44
