
基于YOLOv4-Efficient的目标检测和识别
2022-05-05 07:20史健婷刘文斌安祥泽
智能计算机与应用 2022年3期
史健婷,李 旭,2,刘文斌,安祥泽,2
(1黑龙江科技大学 计算机与信息工程学院,哈尔滨 150022;2黑龙江科技大学 研究生学院,哈尔滨 150022)
0 引 言
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于视频监控、自动驾驶、航空航天等诸多领域。近年来目标检测成为研究和应用的主攻领域,再加上深度学习的广泛运用,目标检测得到了更加快速的发展。
目前主流的目标检测算法大概可以分为两大类:
(1)One-Stage目标检测算法,这类算法不需要候选区域阶段,直接对物体进行检测和识别。YOLO系列就是一阶段的代表性算法,速度较快,但精确度较差;
(2)Two-Stage目标检测算法,这类算法主要分为两个阶段,第一阶段是产生候选区域,也就是目标的大概位置;第二阶段对所产生的候选区域进行类别和位置信息的预测识别。R-CNN是两阶段的代表性算法,虽速度较慢,但有较高的精度。两类算法各有优势,随着研究的不断深入,两类算法都在做着改进,并能在速度和准确度上取得很好的表现。
随着网络的深度不断加深,为了获得更多的目标信息,势必要扩大网络的通道数,这样就会带来大量的参数运算。本文将 EfficientNet网络和YOLOv4中的检测网络相结合,以达到参数量的大量减少,检测速度尽可能提高的目标检测算法。
1 相关算法
1.1 YOLOv4算法
YOLOv4是YOLOv3的改进版,在其基础上融合了许多创新性的小技巧。YOLOv4可以分为4部分,其中包括:输入端、BackBone主干网络、Neck、Prediction。
输入端的创新,主要是训练时对输入端的改进,包括Mosaic数据增强等;BackBone主干网络是将各种创新结合起来,其中包括:CSPDarknet53、Mish激活函数、Dropblock等;Neck部分是在BackBone和最后的输出层之间插入一些层,如YOLOv4中的SPP模块、FPN+PAN结构;Prediction部分主要改进训练时的损失函数_。YOLOv4的网络结构如图1所示。
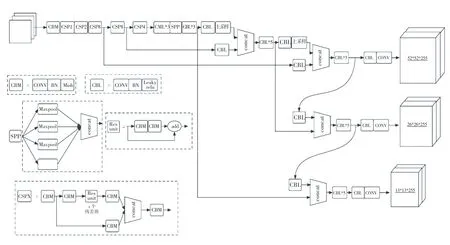
图1 YOLOv4网络结构图Fig.1 YOLOv4 network structure diagram
若以输入的图像尺寸为416×416为例,其处理过程如下:
图像进行Mosaic数据增强后,主干提取网络CSPDarknet53进行特征提取,将提取到的特征进行SPP 3次不同尺度的最大池化,并通过PANet进行特征融合;将不同尺度的特征图进行融合,获得3种尺度的特征图(52×52、26×26、13×13);最后分别对这3种不同尺度的特征图进行分类回归预测结果。
1.2 EfficientNet算法
EfficientNet算法具有的特点:利用残差结构来提高网络的深度,通过更深层次的神经网络实现更多特征信息的提取;改变每一层提取的特征层数,实现更多层的特征提取,来提升宽度;通过增大输入图片的分辨率,使网络学习到更加丰富的内容,达到提高精确度的目的。
EfficientNet使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率,网络可以平衡缩放,进入网络中图像的分辨率、网络宽度和网络深度,减少了模型参数量,增强了特征提取能力,使网络的速度和精度达到最佳。EfficientNet有多个MBConv模块。其总体的设计思路是Inverted residuals结构和残差结构,首先进行1∗1卷积操作进行升维,在3∗3或5∗5的深度可分离卷积后,增加了一个通道的注意力机制,最后利用1∗1卷积进行降维后,增加一个大的残差边,进行特征层的相加操作。MBConv模块如图2所示。
1.3 CIOU损失函数
YOLOv4在损失函数方面,将作为回归。为了使目标框回归更加稳定,收敛的更快,考虑了多重因素。其中包括:目标框与锚框之间的距离,重叠率、尺度以及惩罚项,提高定位的精度,防止出现与(真实框和预测框的交集和并集之比)在训练过程中相同的发散问题。如式(1):

式中:、b分别表示锚框和目标框的中心点;为计算两个中心点的欧式距离;为权重系数;为长宽比相似性;、分别表示预测框的宽度和高度;w、h分别表示真实框的宽度和高度。

图2 MBConv模块结构Fig.2 MBConv module structure diagram
2 YOLOv4-Efficient网络结构
2.1 主干提取网络
YOLOv4中CSPDarknet53主干特征提取网络的提取能力和检测精度非常强,在各个领域都有非常优秀的表现。但主干巨大的参数量对计算设备的性能有着较高的要求,使其对车辆的实时监测和算法的移植有较高的难度。YOLOv4-tiny虽然具有较低的参数量,较快的检测速度,但是特征提取能力和泛化能力较差,在复杂的场景变化中检测能力较差,对物体识别效果不太理想。
依据上述分析结果,为了解决既提高速度又具备较强检测能力的问题,将特征提取的主干换成EfficientNet轻量级网络,因其具有较少的参数量和较高的特征提取能力,可以大大减少运算时间提高实时监测能力,并且该算法可以移植到较低算力的设备上。YOLOv4-Efficient网络结构如图3所示。
EfficientNet系列网络有8种不同类型的模型,可以应对不同的场景。如:应对自动驾驶中对车辆的检测时,考虑到速度和精度,可选择EfficientNet-B2模型,将EfficientNet-B2最后的池化层和全连接层去掉之后,代替YOLOv4原始的CSPDarknet53特征提取网络。EfficientNet-B2网络结构见表1。

图3 YOLOv4-Efficient网络结构Fig.3 YOLOv4-Efficient network structure
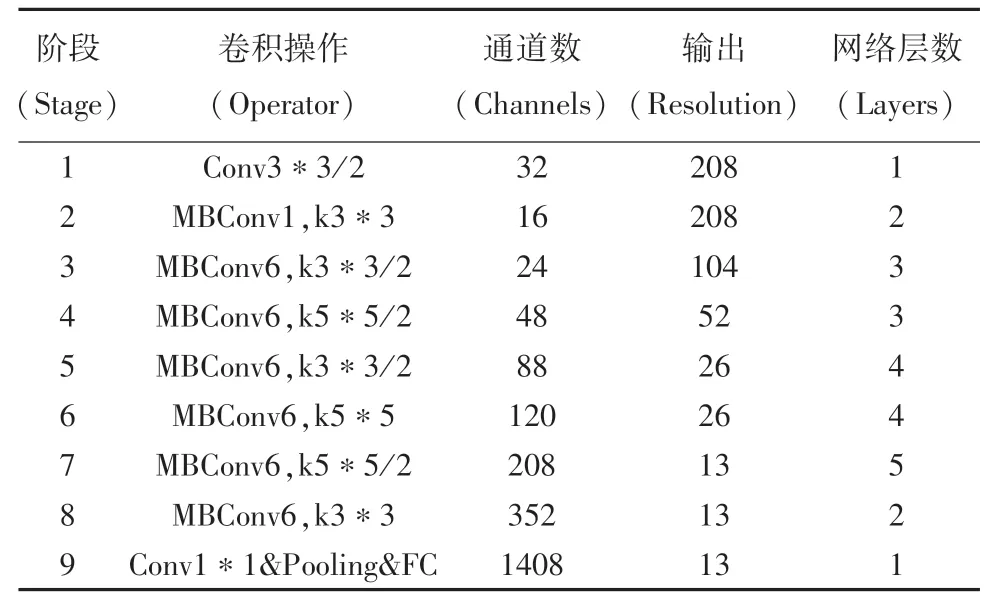
表1 EfficientNet-B2网络结构Tab.1 EfficientNet-B2 network structure
2.2 改进PANet特征融合
本文对PANet特征融合的改进主要涉及两个方面:一是引入深度可分离卷积,二是在进行特征融合上采样时,加入了SENet注意力模块。
由于PANet中使用了大量的卷积,会导致巨大的参数量,所以在PANet中引入了深度可分离卷积,使PANet特征金字塔部分的参数量大幅度减少,提高整个模型的检测速度。
深度可分离卷积分为逐通道卷积和逐点卷积。在逐通道卷积中,一个卷积核负责一个通道,一个通道只被一个卷积核卷积。如图4所示。
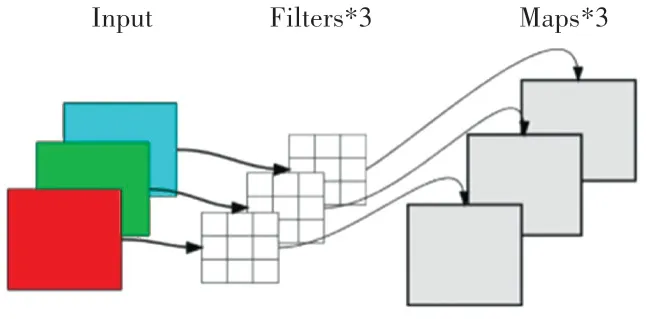
图4 逐通道卷积结构Fig.4 Channel by channel convolution structure
逐点卷积运算和常规卷积运算类似,其卷积核尺寸为1×1×M(上一层的通道数)。这里的卷积运算会将逐通道卷积产生特征图,在深度方向上进行加权组合,生成新的特征图。有几个卷积核就输出几个特征图。
为了使不同的特征层进行融合时保证其关键信息得到加强,所以在PANet特征融合进行上采样时加入SENet(Squeeze-and-Excitation Network,即“压缩和激励”SE块)。SE块通过控制scale的大小,将一些重要特征进行增强,而对一些不重要的特征进行抑制,从而让提取到的特征有更强的指向性。SE模块的结构如图5所示。

图5 SE模块结构图Fig.5 SE module structure diagram
图中:sq()代表Squeeze过程;ex()代表Excitation过程;sc()是将Excitation得到的结果作为权重,乘到输入特征上。
3 实验结果与分析
本次实验环境配置中,软件环境为:python3.6编程语言、CUDA版本为11.2、深度学习框架pytorch1.2;硬件环境配置:GPU为RTX1050,CPU为i7-7700HQ。通过标注和处理1521张来自BDD100K自动驾驶的图片,构成本次实验的数据集。
实验中,将改进的YOLOv4-Efficient模型与YOLOv4模型、YOLOv4-tiny进行对比。在输入图片分辨率为416∗416的情况下,通过精度()、参数量()、召回率()和平均准确率()等性能指标进行评价。计算公式如式(5)(6):

式中:为图像中车的区域,预测为车的正确情况;为图像中为车的区域,预测为不是车错误情况;为实际不是车的区域,但是预测此区域是车的情况。
将YOLOv4-Efficient与YOLOv4,YOLOv4-tiny模型进行对比测试,测试结果见表2。

表2 模型检测性能对比Tab.2 Performance comparison of models
通过表中数据可以看出,本文算法整体性要优于YOLOv4和YOLOv4-tiny。在平均准确率()和召回率()对比中,明显高于YOLOv4-tiny;在参数量和精度方面要优于YOLOv4;在平均准确率和召回率方面略低于YOLOv4。进行综合对比后,在减少近4倍的参数量后,仍然有较好的检测性能。pr曲线和精度曲线如图6~7所示。

图6 pr曲线Fig.6 Pr curve

图7 精度曲线Fig.7 Precision curve
利用YOLOv4-Efficient测试结果如图8所示。

图8 测试结果Fig.8 Test result
4 结束语
本文在YOLOv4的基础上提出了一种轻量级的车辆检测算法YOLOv4-Efficient,将YOLOv4的主干提取网络改为EfficientNet-B2后,在保证检测精度的情况下,减少了模型的参数量,提高了检测速度。相比YOLOv4的参数量,改进后的模型参数量少了近4倍。经过实验对比,在YOLOv4-Efficient对车辆的检测中,参数量和精度方面要优于YOLOv4,其精度达到了94.29%,参数量也仅仅有60.52 M,改进后的模型更适合于移动端的设备。后期工作中,在提高模型数据量来增强鲁棒性的同时,还要进一步研究在不同复杂环境和天气下对目标的检测。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电机与控制学报(2018年9期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2017年9期)2017-05-27
计算机应用(2016年10期)2017-05-12
电子技术与软件工程(2016年24期)2017-02-23
