
基于PSO-XGBoost的患者心脏病诊断方法
2022-04-29 19:35秦唯栋张超群周文娟刘文武易云恒
计算机与网络 2022年18期
秦唯栋 张超群 周文娟 刘文武 易云恒
摘要:在使用机器学习方法预测心脏病患病情况案例中,传统机器学习模型训练过程耗时较长,尤其是在数据较多情况下实时性无法保障。基于粒子群(PSO)算法和极端梯度提升(XGBoost)算法,新建一种心脏病预测模型,该模型利用PSO算法的全局寻优能力对XGBoost初始参数进行优化,结合XGBoost算法得到最优的决策树即患者的患病情况。实验结果表明,PSO算法相较于普通的调参方式具有更好的效果,且迭代收敛速度大,可在短时间获得最适合模型的超参数,PSO-XGBoost模型(PSO-XGBoost)的准确率达到了92.69%,逻辑回归与KNN算法分别为77.05%,65.57%。PSO-XGBoost模型在进行疾病预测时有着更优的诊断准确率,且适用于预测其他疾病。
关键词:极端梯度提升算法;粒子群算法;準确率;集成学习;收敛速度
中图分类号:TP391文献标志码:A文章编号:1008-1739(2022)18-68-05

0引言
随着时代的发展,人们的生活水平逐渐提高,但一些不良的生活方式与饮食习惯同时也使心血管疾病有机可乘。目前的医疗诊断方式大多是通过医生的专业知识直接判断或依靠专门的医疗设备对患者进行检查,诊断时间过长且对医生与检测设备要求较高,不利于获取患者完整的患病情况从而进行相应的后续治疗,且会加重患者的治疗成本。如今,医学正经历着由过往普通医学模式向准确医学模式转化的过程,将人工智能技术进一步运用到医疗工作中已成为主流趋势[1-2]。在一些医疗诊断方面的工作中,机器学习与智能决策技术起着不可替代的作用。医院通过一系列医疗信息技术准确把握患者的患病情况,能够有效对患者进行及时的治疗并在一定程度上降低医疗检测的成本。因此,本文对于构建高效、经济的医疗诊断系统具有重要的意义。
国内外相关学者提出不同的机器学习方法应用到心脏病预测中,以辅助医生做出更准确的心脏病诊断。许多机器学习方法广泛应用于心脏病的预测中,Kumari等[3]在2020年通过支持向量机检测心律失常。Patidar等[4]将最小二乘支持向量机应用于心电图信号的分析中,并通过对支持向量机的核函数[5]进行改进来预测心脏病的发生。Birjais[6]采用K-近邻(K-NearestNeighbor,KNN)对缺失数据进行填补,梯度提升决策树(Graddient Boosting Decision Tree,GBDT)的准确率达到86%。
然而,经典的机器学习方法在实际进行心脏病诊断过程中往往存在过拟合与准确率不高等问题,尤其是针对根据患者相关特征进行心脏病诊断的工作中,通常需要挑选出较为重要的特征,即对最终判定是否患心脏病有一定贡献度。由此,本文以Kaggle数据竞赛中使用到的心脏病患者特征数据集为主,在分析患者相关特征重要性的基础上,运用极端梯度提升(eXtreme Gradient Boosting,XGBoost)算法构建患者心脏病诊断模型,并采用PSO算法对模型参数进行调整,进一步提高模型的预测准确率,为医疗机构进一步完善疾病诊断系统打下基础。
1相关工作
1.1 XGBoost算法


(3)基于最大得分对应的划分特征和特征值分裂子树。
(4)若最大得分为0,则目前决策树建立完成,计算全部叶子区域的,得到弱学习器( ),更新强学习器( ),展开下一次弱学习器迭代;若最大得分不为0,则转至第(2)步继续尝试分裂决策树。
另一方面,XGBoost算法通常根据结构得分的增益计算出选择哪个特征作为分割点,而某个特征的重要性就是它在树中出现的次数之和。换言之,一个属性越多地被用来在模型中构建决策树,其重要性就越高。对于输入模型前的数据,可通过XGBoost中的get_score获取特征重要性,选择更有利于进行预测的特征。
1.2粒子群算法
PSO算法为一种模拟鸟群觅食行为的基于群体互助的随机搜索算法。该算法假设一群鸟在随机搜索食物,在这个区域只有一块食物。所有鸟都不知道食物在哪儿,但知道当前位置离食物还有多远。而找到食物的最优策略是搜寻离食物最近的鸟的周围区域。具体原理如下:

1.3基于PSO-XGBoost模型建模
由Kaggle提供的数据集,可得到303位患者的13个属性特征信息,在模型构建过程中选取70%样本数据集训练与优化参数,其余30%划为测试集将提出的模型性能进行评估。XGBoost使用到的超参数为最大深度(max_depth)、学习率(learning_rate)、L2正则化项的权重(Lambda)。为防止调参中遇到随机性或计算量较大的情况,采用粒子群优化算法对模型超参数进行调整,从而提高模型的预测性能。
在PSO-XGBoost模型训练过程中,随机初始化对应粒子种群数,确定模型每个参数的初值与取值范围,采用PSO算法优化相应的参数取值。之后,将验证集对该次训练进行评判,由适应度值确定当前是否为最优值,如果是最优值,将替换原本参数;若不是,则保留当前确定的参数。根据有无达到最大迭代次数,若达到则保留最优参数值;反之,则继续使用PSO进行迭代。PSO-XGBoost模型构建图如图1所示。
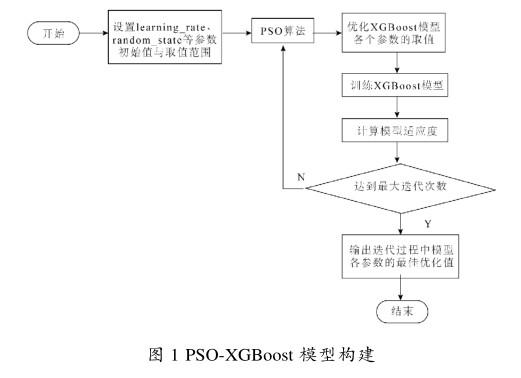
2实验分析
2.1实验条件
本次实验是在Windows10 64位操作系统上完成的,其中PC机处理器为Intel(R) Core(Tm) i7-10700 CPU @ 2.90 GHz,内存为16 GB。本实验使用Pycharm2020作为代码的实现工具,使用python语言的机器学习框架scikit-learn来编写。
2.2数据说明
实验选用来源Kaggle数据挖掘比赛官网的关于心脏病分类预测的数据。该数据集由费德索里亚诺以及瑞士巴塞尔大学医学院于2021年9月整理,共有13个属性,303条数据,其中target代表该病人是否患有心脏病。部分数据集属性如表1所示。
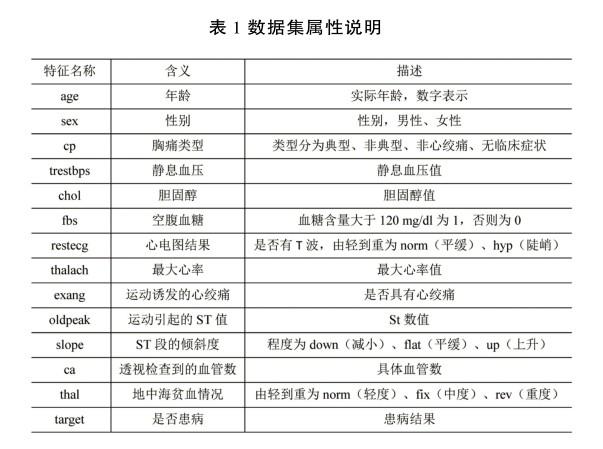
2.3数据预处理
原数据中,没有数据缺失的状况。但在某些特征取值中,使用文字表示具有二值类、多值类的特征取值。为方便算法模型识别,将文字数据转化为数字。如胸痛字段,将使用0,1,2,3等来表示typical(典型)、atypical(非典型)、non-anginal(非心绞痛)、asymptomatic(无临床症状)胸痛等级。其他多值类字段也按该逻辑处理。将数据集分为70%的训练集与30%测试集,使用交叉验证方式,得到不同的训练集与测试集,防止测试结果片面与训练数据不足的问题。
原数据集中影响患病的属性有13个,但并不是所有属性都与患病的关联性很大,本文使用XGBoost自带的get_score进行关键特征的选择,删除关联性不大的属性以此提高运算效率。

式中,*为输入的特征变量;max,min为每个独立样本数据的最大值与最小值。
2.4实验结果
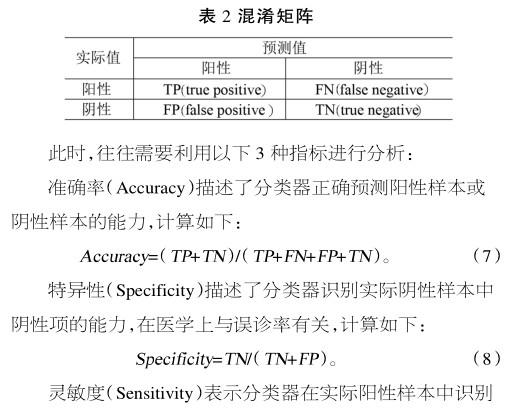
本文患病预测为一个二分类问题,可简单划分为正类或负类。在实际中,会有如表2所示情况出现。

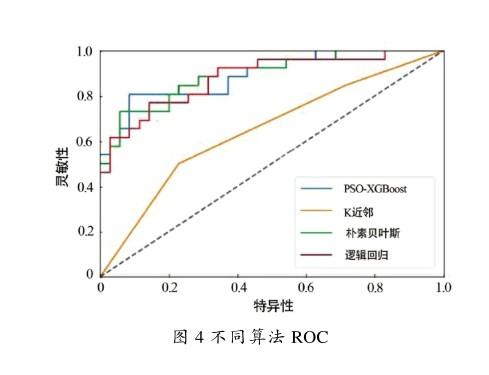
受試者工作特征曲线(Receiver Operating Characteristic Curve,ROC)是反映灵敏度和特异性连续变量的综合指标,以敏感性为纵坐标、特异性为横坐标绘制成曲线。在ROC上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。ROC下面积(AUC)是ROC的数量指标,指ROC下方的面积,面积越大,诊断准确性越高。理论上AUC取值为[0,1],在理想分类器中,AUC的值为1。
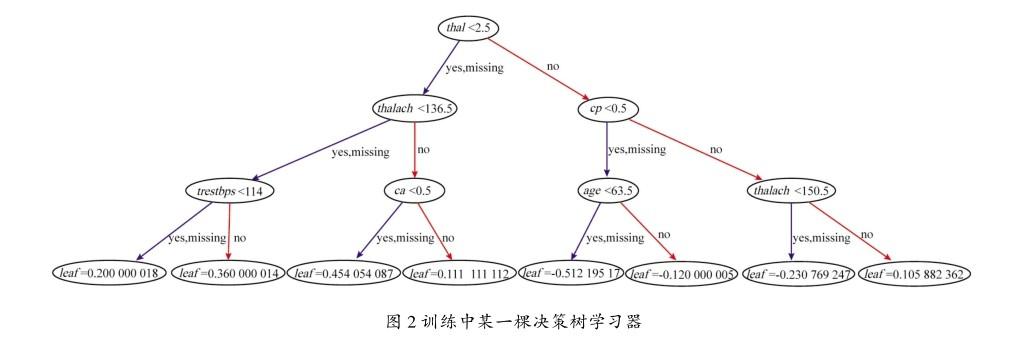
XGBoost本质与随机森林算法一样,由多个弱学习器进行决策,以少数服从多数的方式对分类问题进行决策。而每一次的迭代都会产生新的学习器添加到模型中,模型的复杂度同时也随着学习器的增加而提高,当模型复杂度与数据样本复杂度较为接近时即可达到最优训练效果,部分训练的学习器如图2所示。
为验证PSO-XGBoost在各阶段的性能,设计多组对比实验。除提到的组合算法外,另外选择了贝叶斯(Bayes)、逻辑回归(LR)等分类算法进行实验。为表示预测结果与实际情况的关系绘制出混淆矩阵,如图3所示。
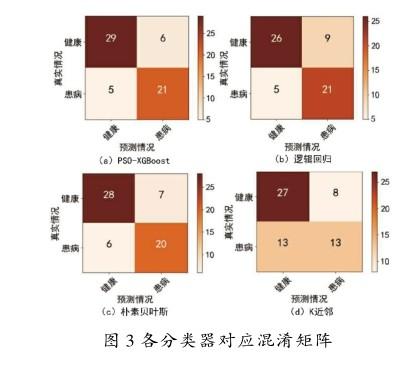
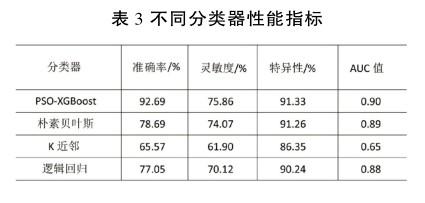
根据混淆矩阵可得出各模型性能指标如表3所示,并绘制ROC如图4所示。显而易见,PSO-XGBoost相比其他分类器拥有更好的分类准确性,且AUC值也最大,对于灵敏度与特异性2项指标也更出色,可显著减少误诊率与漏诊率。朴素贝叶斯算法虽AUC值较小,但在预测小规模数据时分类效率稳定且对缺失数据不敏感。因此,需要结合实际情况选择合适的分类器。
3结束语
针对心脏病预测,本文综合运用了各类机器学习算法对数据集训练并得出算法模型的性能评价,其中,PSO-XGBoost表现性能较好,准确率为92.69%,灵敏度为75.86%,特异性为91.33%,AUC值为0.90,可以做出合理特征选择处理高维度数据。此外,该算法训练效率高,树与树之间相互独立从而易于并行化展开训练。针对不平衡数据集,XGBoost可平衡误差。当存在分类不平衡的情况时,XGBoost能提供平衡数据集误差的有效方法。另外,机器学习预测的方法可应用到其他类似的疾病诊断中,有效帮助医生给出准确决策并预防病人患病。
参考文献
[1]赵鹏,陆志,蒋珍华,等.基于随机森林回归分析的脉管制冷机性能预测模型[J].红外,2021,42(8):33-37.
[2]尤志军,俞秋峰,汪晓晖,等.基于随机森林法的精神分裂症患者病情复发的预测[J].国际精神病学杂志,2021,48(4): 631-636.
[3] KUMARI C, MURTHY S D A, PRASANNA L B, et al. An Automated Detection of Heart Arrhythmias Using Machine Learning Technique: SVM[J].Materials Today: Proceedings, 2020,45(2):1393-1398.
[4]PATIDAR S, PACHORI R B, ACHARYA U R. Automated Diagnosis of Coronary Artery Disease Using Tunable-Q Wavelet Transform Applied on Heart Ratesignals[J]. Knowledge-based Systems,2015, 82: 1-10.
[5] MANIRUZZAMAN M, KUMAR N, MENHAZUL A, et al. Comparative App-roaches for ClasSification of Diabetes Mellitus Data:Machine Learning Paradigm[J].Computer Methods and Programs in Biomedicine, 2017,152:23-34.
[6] BIRJAIS R, MOURYA A K, CHAUHAN R, et al. Prediction and Diagnosis of Future Diabetes Risk: A Machine Learning Approach[J].SN Applied Sciences,2019,1(9):1-8.
[7]趙金超,李仪,王冬,等.基于优化的随机森林心脏病预测算法[J].青岛科技大学学报(自然科学版),2021,42(2):112-118.
[8]李国成,陆俊,王赟,等.基于Bagging二次加权集成的孤立森林窃电检测算法[J].电力系统自动化,2022,46(2):92-100.
[9] SINGH V K, MAURYA N S, MANI A, et al. Machine Learning Method Using Position-specific Mutation Based Classification Outperforms One Hot Coding for Disease Severity Prediction in Haemophilia A[J]. Genomics,2020,112(6):5122-5128.
[10]赵勇,赵姜雪慧.基于随机森林模型的滑行艇剩余阻力预测[J].华中科技大学学报(自然科学版),2021,49(11): 118-122.
[11]罗超.面向高维数据的随机森林算法优化探讨[J].商,2016(4):207.
[12] VIN CIUS M, DIONATR K, MATHEUS L,et al. ML-driven Classification Scheme for Dynamic Interference-aware Resource Scheduling in Cloud Infrastructures [J].Journal of Systems Architecture,2021,116:9-12.
[13] SIMONA-VASILICA O, ADELA B. Machine Learning Classification Algorithms and Anomaly Detection in Conventional Meters and Tunisian Electricity Consumption Large Datasets[J].Computers and Electrical Engineering, 2021,94:5-8.
猜你喜欢
科教导刊·电子版(2017年22期)2017-09-20
时代金融(2016年36期)2017-03-31
科技创新与应用(2017年6期)2017-03-23
中小企业管理与科技·中旬刊(2016年11期)2017-02-17
现代电子技术(2017年1期)2017-02-16
南水北调与水利科技(2016年5期)2016-12-27
预测(2016年5期)2016-12-26
电脑知识与技术(2016年12期)2016-06-14
商(2016年5期)2016-03-28
中国市场(2016年10期)2016-03-24
