
基于深度学习岩性分类的研究与应用
2022-04-29 03:22马陇飞萧汉敏陶敬伟张帆罗永成张海琴
科学技术与工程 2022年7期
马陇飞, 萧汉敏, 陶敬伟, 张帆, 罗永成, 张海琴
(1.中国科学院大学工程科学学院, 北京 100049; 2.中国科学院渗流流体力学研究所, 廊坊 065007; 3.中国石油勘探开发研究院, 北京100083; 4.上海帕科信息科技有限公司, 上海 200235; 5.中国石油大学(北京)非常规油气技术研究院, 北京 102249)
根据第三轮油气资源评价结果,中国石油陆上剩余石油资源中,岩性地层油气藏占42%,这是中国陆上今后相当长一个时期内最有潜力、最实现油气勘探的领域[1]。地下地质地层岩性是储层表征和资源估算的关键因素[2]。它影响着岩石物理性质,如孔隙度和渗透率,从而影响着油气饱和度。岩性描述是油气藏勘探的关键,影响着油气藏储层类型的分类。储层类型分类是油藏精细描述的重要内容之一,对于准确定量评价油气储量具有十分重要的意义[3-5]。传统的岩性识别通过钻井取心将岩心切割可视化、岩心观察和测井数据得到。由于测井曲线通常适用于所有的井,测井岩性解释提供了一种方法[6]。早期试图基于测井曲线测量原理建立测井响应与地层岩性之间的映射关系,形成了测井岩性解释的理论基础[7]。尽管前人在岩性识别方面做了大量的研究,但忽略了大多测井数据中未标记数据的价值。
近年来,数学方法得到了发展,并被广泛应用于测井岩性的识别;人工神经网络作为一种自动非线性分类器,在测井岩性分类中得到了广泛应用[8-9]。现有的大多数基于机器学习的岩性识别研究中,岩性的标记通常是由专家根据测井解释或录井来完成工作,对专业领域知识的依赖度高[10]。深度学习的出现是机器学习的一次重要革命,是人工智能发展巨大推力[11-12]。而在深度学习中,学习到的是网络的隐含节点从输入信号中经过自动提取变换后的特征,这些特征将逐层越来越抽象,从而建立高维的映射关系来解决复杂的非线性问题[13]。深度学习技术主要有常规的全连接深度神经网络(deep neural network,DNN),适用于解决序列化问题的循环神经网络(recurrent neural network,RNN),适用于解决空间结构问题的卷积神经网络(convolution neural network,CNN)及可用于数据生成的生成对抗网络(generative adversarial network,GAN)等网络结构[13-16]。人工智能领域应用发展突飞猛进,被广泛用于与人们生活息息相关的各种领域,中外学者做了大量的研究工作。Amedi等[17]利用人工神经网络预测硫化氢在不同离子浓度、温度、压力下的溶解度,Ahmadi等[18-27]利用人工神经网络预测油田盐水中溶解碳酸钙浓度的估算[18],渗透率和孔隙度估算[19],油藏化学驱油效率评价的预测[20],预测自然损耗导致的沥青质沉淀[21],在此基础上用统一粒子群算法(unified particle swarm optimization, UPSO)对神经网络模型进行优化[22],预测自然损耗导致的沥青质降水[23],求解凝析气藏产液的露点压力(pd)[24],监测凝析气藏中的凝析气比(condensate gas ratio,CGR)[25],预测硫化氢(H2S)在各种离子中的溶解度[26-27]; Moosavi等[28]发展了包含优化多层感知器(multi-layer perceptron,MLP)和径向基函数(radial basis function,RBF)神经网络的预测模型;Gu等[29-31]利用循环神经网络、智能预测器CRBM-GA-PSO-CRBM进行岩性的预测,基于集成学习的数据驱动CRBM-LD-AFSA-LightGBM的岩性预测; Feng[32]采用标度算法提高机器学习方法岩相分类的不确定性。
深度学习网络的出现使得石油工程师能够解决很难通过分析去解决一些石油工程问题。然而测井资料失真或漏失的现象普遍存在,且钻井取心井的数量不多,严重影响了油田的开发。在实际应用中,对于已经完井的井来说,重新测井成本高,实施难度大,这迫使我们不得不放弃全部测井数据[33]。且传统的储层岩性分类方法是从储层物性的控制因素入手,在明确构造、沉积或成岩等地质因素对储层岩性建设性或破坏性作用的基础上,通过判定不同地区各地质因素作用性质及地质因素的耦合关系来评价储层岩性[34-37],并以建设性地质因素叠合发育区作为储层岩性分类。该方法能够从储层岩性的成因角度分析,对油气勘探的指导意义重大,但很难给出岩性分类评价的量化标准。
针对上述问题,通过构建深度学习网络模型来预测储层岩性。首先利用已有的测井资料训练模型,根据实际工作区域进行验证,之后预测同井中岩性信息缺失的岩性数据;其次,预测未钻井取心井的岩性数据,为油田测井解释奠定了一定的基础。生成了目标区单井储层岩性分类图,为储层的精细勘探开发提供了规划和方法。
1 深度学习网络原理
深度学习神经网络是一种先进的机器学习技术,它能够自主地识别复杂且有效的高阶特征,避免了人工提取特征的烦琐性。神经元之间能够共享权值,减少了参数的优化。通过增加隐藏层数,使深度学习网络可以表示复杂性不断增加的函数。模型给定,训练数据集足够多,就能够通过深度学习将输入向量映射到输出向量,能够迅速地处理复杂问题。
深度学习神经网络从结构上一般分为三类:输入层、隐藏层、输出层。有时需要在隐藏层与输出层之间增加一层全连接层。各层之间均为全连接的方式,同层之间神经元无连接且相互独立。以岩性预测为例,输入层为8组特征向量,通过隐藏层特征提取、激活函数的选择、损失函数的定义和优化器的选择来输出岩性的预测值。
1.1 向前传播算法
前向传播描述了前馈神经网络的计算过程。计算向前传播的过程需要三部分信息:神经网络的输入,传播过程中提取的特征向量数据,其次就是网络的连接结构,通过连接结构就可以得出确定的运算关系,最后就是每个神经元中的参数。以全连接神经网络为例,用图1所示的模型并加入偏置项,组成一个简易的单个神经元网络。从输入数据开始,往输出层传递,最后求出预测值,并与目标值构成的代价函数J。

图1 判断硬件是否合格的三层神经网络Fig.1 A three-layer neural network to determine whether the hardware is qualified
假设训练样本为(x,y),其中x为输入向量,x=[x1,x2,x3]T,y为目标值。将输入数据与权重w=[w1,w2,w3]相乘求得z,然后通过一个sigmoid函数,得到输出a,最后a与y构成代价函数J。具体的传播过程为

(1)
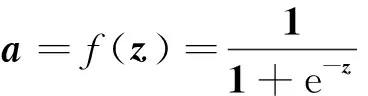
(2)

(3)
1.2 反向传播算法
反向传播算法在网络中的作用可以概括为:如果说梯度下降算法优化了单个参数取值,那么反向传播算法则给出了一种高效地在所有参数上使用梯度下降算法的方式。以代价函数开始,从输出到输入,求取各节点的偏导。在这里分为两步,先求取关于权重w及偏移量b的偏导。求取J关于中间变量a和z的偏导,即

(4)
式(4)中:J是a的函数,而a是z的函数,应用链式求导法则可得
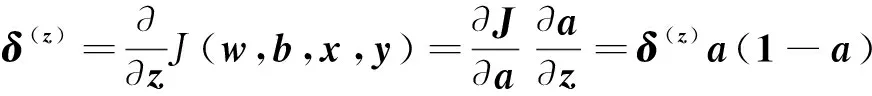
(5)
再根据链式法则,求取J关于w和b的偏导数,即得到w和b的梯度

(6)

(7)
不失一般性,多层网络的前向传播与反向传播与上述一致。
2 深度学习网络岩性预测模型
2.1 研究区岩性特征
鄂尔多斯盆地为一个叠合的克拉通坳陷盆地,现今表现出总体构造为东部宽缓、西部相对陡窄的不对称形矩形盆地,可以划分为6个一级构造单元。研究区构造发育符合鄂尔多斯盆地的构造特征,总体上构造较为平缓,没有明显的构造起伏,也没有明显的断裂发育,主要以岩性油藏为主。其岩石的形成受到沉积环境及后期的成岩作用改造的多方面影响,使得同一地区存在不同含量的矿物类型,通过钻井取芯和岩心的观察,研究区致密砂岩储层岩性主要为深灰色细砂岩、粉砂质泥岩和暗色泥质粉砂岩(图2)。并对研究区5口井长7储层岩性做统计(表1)。从表1可以看出长7储层岩性以泥岩和细砂岩为主,从而我们可以得出其发育了一套完整的烃源岩和储层,形成了大面积连续分布的致密砂岩油藏。但致密砂岩储层构造极其复杂,岩性多样。且每个井岩性不一,有的只有两种,有的多达9种,岩性中存在泥质、粉砂质、碳质/炭质、钙质、凝灰质等,这给测井岩性的识别带来较大的困难。

图2 鄂尔多斯盆地岩心照片 Fig.2 The Ordos Basin core photo
根据岩心分析、岩屑录井、井壁取心和测井曲线等,将研究区岩性共划分为5种,分别为:泥岩、碳质泥岩/炭质泥岩、泥质粉砂岩、粉砂质泥岩、细砂岩。图3为不同岩性的测井曲线交会图。可以看出凭借1条或多条常规测井曲线是无法有效的识别岩性,因此,通过深度学习网络进行岩性识别成为解决岩性解释这一问题的关键。
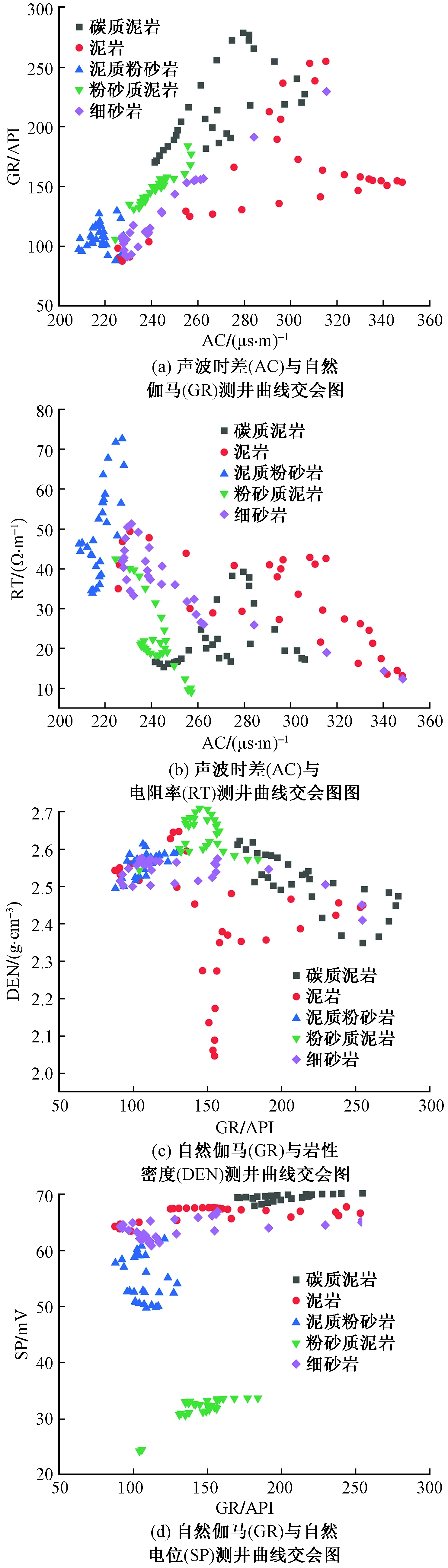
图3 不同岩性常规测井曲线交会图Fig.3 The intersection of conventional logging curves of different lithologies
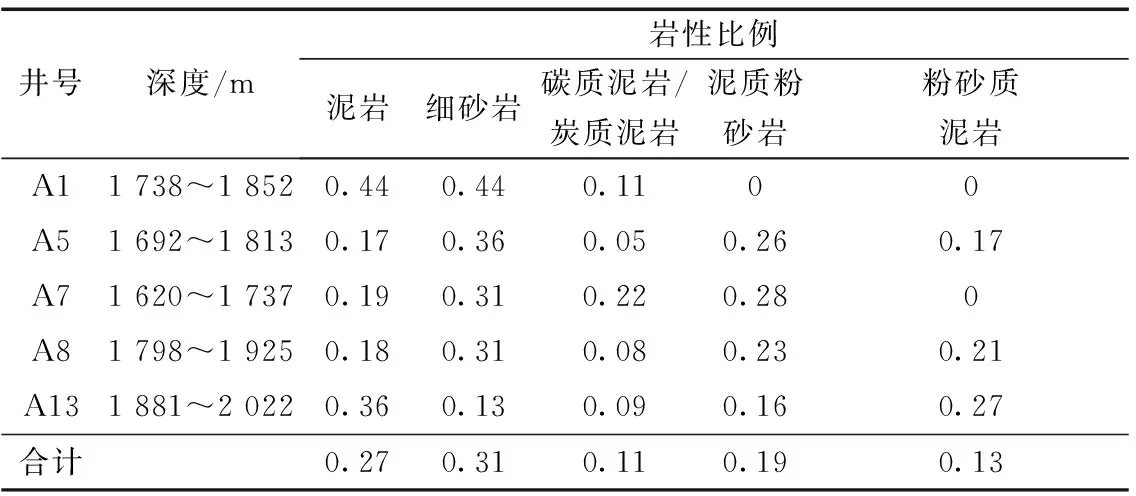
表1 研究区致密长7储层岩性比例
2.2 数据集与数据预处理
本次研究利用40口井测井曲线共45 000组数据样本,以Python第三方包TensorFlow2.0为平台搭建全连接神经网络模型,岩性作为预测对象。测井曲线采样间隔为0.125 m,选取声波时差(AC)、自然伽马(GR)、电阻率(RT)、泥质含量(SH)、自然电位(SP)、有效孔隙度(POR)、含水饱和度(SW)、密度(DEN)8种测井曲线作为网络的输入特征变量。按6∶2∶2的比例将原始数据划分为训练集、测试集、验证集,需要将训练集数据和测试集数据严格区分,测试数据集作为深度学习模型准确率的判别标准,一般不能在前期工作中对测试数据集做任何分析。
由于参数测量误差以及原始数据各个特征量大小、单位不一,为减小误差带来的不利影响,降低干扰数据带来的网络计算误差,对样本数据采用式(8)归一化处理,数据归一化后有助于梯度下降算法的收敛,提高模型的预测精度。

(8)
式(8)中:xi、yi为原始参数值与归一化后参数值;maxxi为原始参数最大值;minxi为原始参数最小值。本文中采用交叉熵损失函数来评估模型的准确率,该函数反映目标参数与预测参数之间最大的误差,其公式为
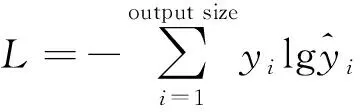
(9)
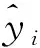
2.3 Dense模型预测结构
在样本数据预处理的基础上,将声波时差(AC)、自然伽马(GR)、电阻率(RT)、泥质含量(SH)、自然电位(SP)、有效孔隙度(POR)、含水饱和度(SW)、密度(DEN)8种测井变量特征作为网络的输入,即输入层的神经元个数为8;隐藏层为5层,选择的激活函数为Relu函数,损失函数为交叉熵损失函数,优化器为Adam函数;输出层为需要预测的岩性类别,神经元个数为5。利用Python第三方包TensorFlow2.0编写岩性预测模型并进行训练(图4),以实现致密砂岩储层岩性的预测。
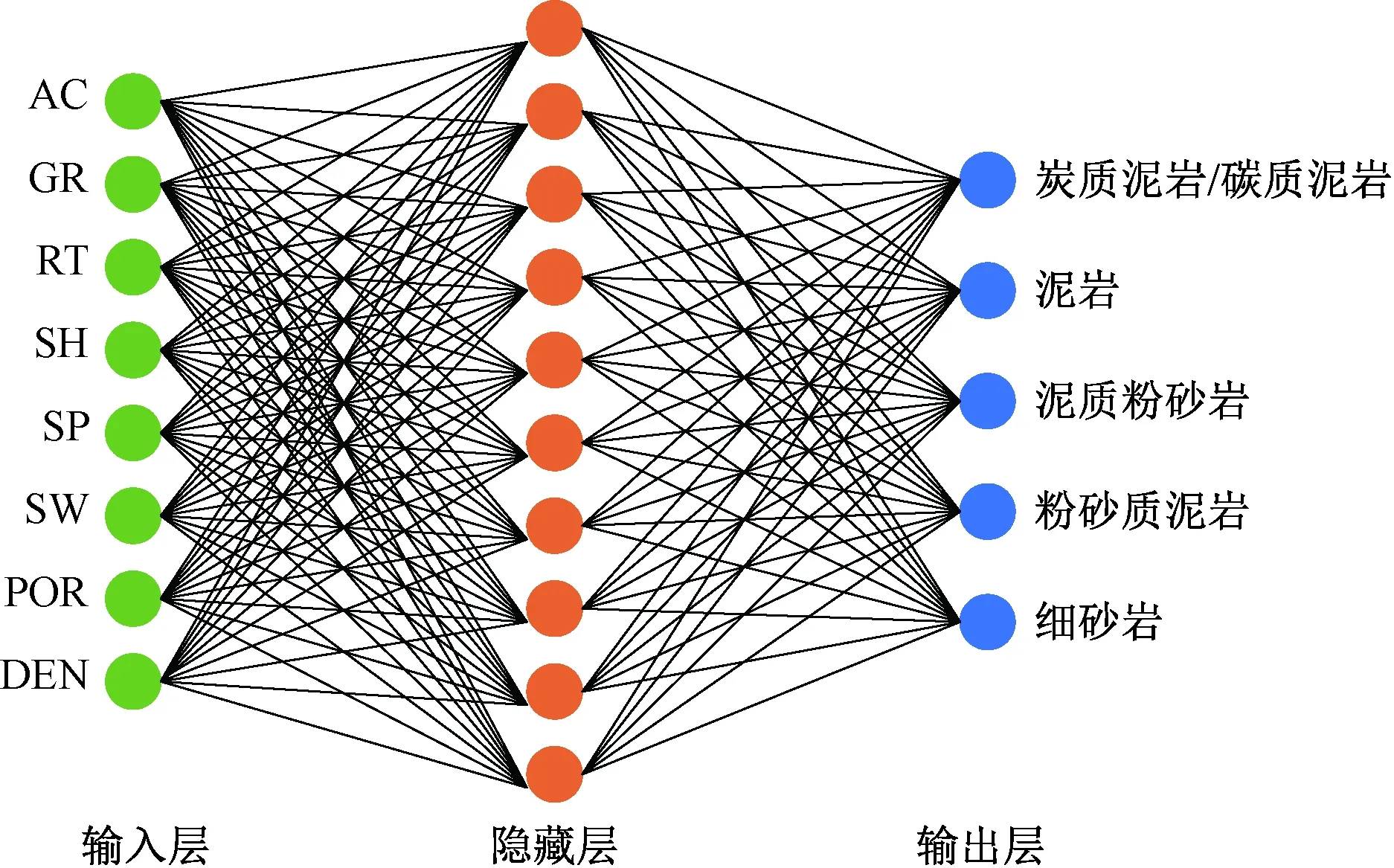
图4 岩性预测模型结果Fig.4 The results of lithology prediction model
本文模型属于典型的多分类问题,输出为5种岩性,对于标签y值使用one-hot使其对应的一维标量扩展为6维向量(表2)。从技术上来讲,noe-hot将复杂的多分类问题简化为若干而二分类问题,简化了模型的复杂度。

表2 one-hot编码处理数值表
2.4 模型训练与测试
根据上述构建的神经网络模型,选择原始测井曲线中声波时差(AC)、自然伽马(GR)、电阻率(RT)、泥质含量(SH)、自然电位(SP)、有效孔隙度(POR)、含水饱和度(SW)、密度(DEN)八种测井曲线作为网络的输入变量特征,这些测井曲线未经过“剔除明显异常点、适当补充典型样点”处理,这样做的目的在于使模型的泛化能力增强。在油田实际生产过程中,这些测井曲线无需做预先处理,可直接作为模型的输入变量,对目标区域储层岩性进行识别。本次选用的数据:每一种岩性数据只有9 000份,由于数据偏少,数据夹杂噪声。初始神经网络隐藏层设置为5层,起初参数设置过大,一轮训练得到过拟合的模型(图5)。出现这种情况的原因:训练参数过大,导致对训练数据中的噪音拟合,从而使得模型无法对未知数据做出很好的判断。通过对模型的不断优化以及模型参数调整,使得模型训练与验证拟合中准确率与误差率趋于稳定,并且达到期望的结果(图6)。从图6中可以看出,岩性预测模型的训练与验证准确率达到80%以上[图6(a)],相对误差值接近0.5[图6(b)]。为检测模型的预测精准度,将训练好的模型输入未经过模型训练与验证的数据,模型的预测准确率为67%(图7),由图7可见,模型对泥岩识别准确率只有10%,这也是导致模型整体预测准确度偏低的原因。

图5 岩性预测模型的过拟合训练和验证迭代Fig.5 The overfitting training and validation iterations of the lithology prediction model
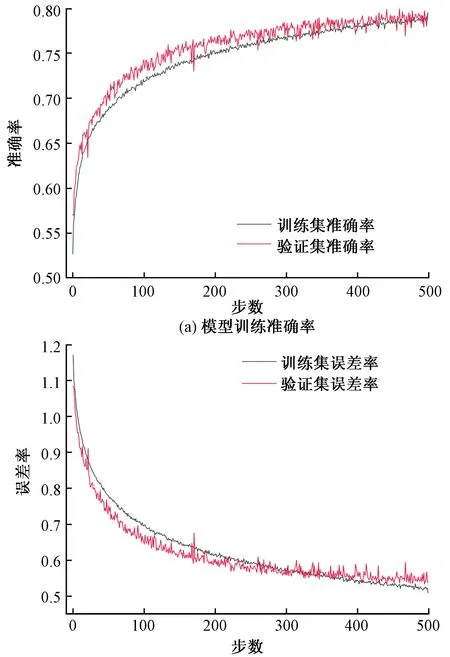
图6 岩性预测模型训练与验证迭代图Fig.6 The lithology prediction model training and verification iteration diagram
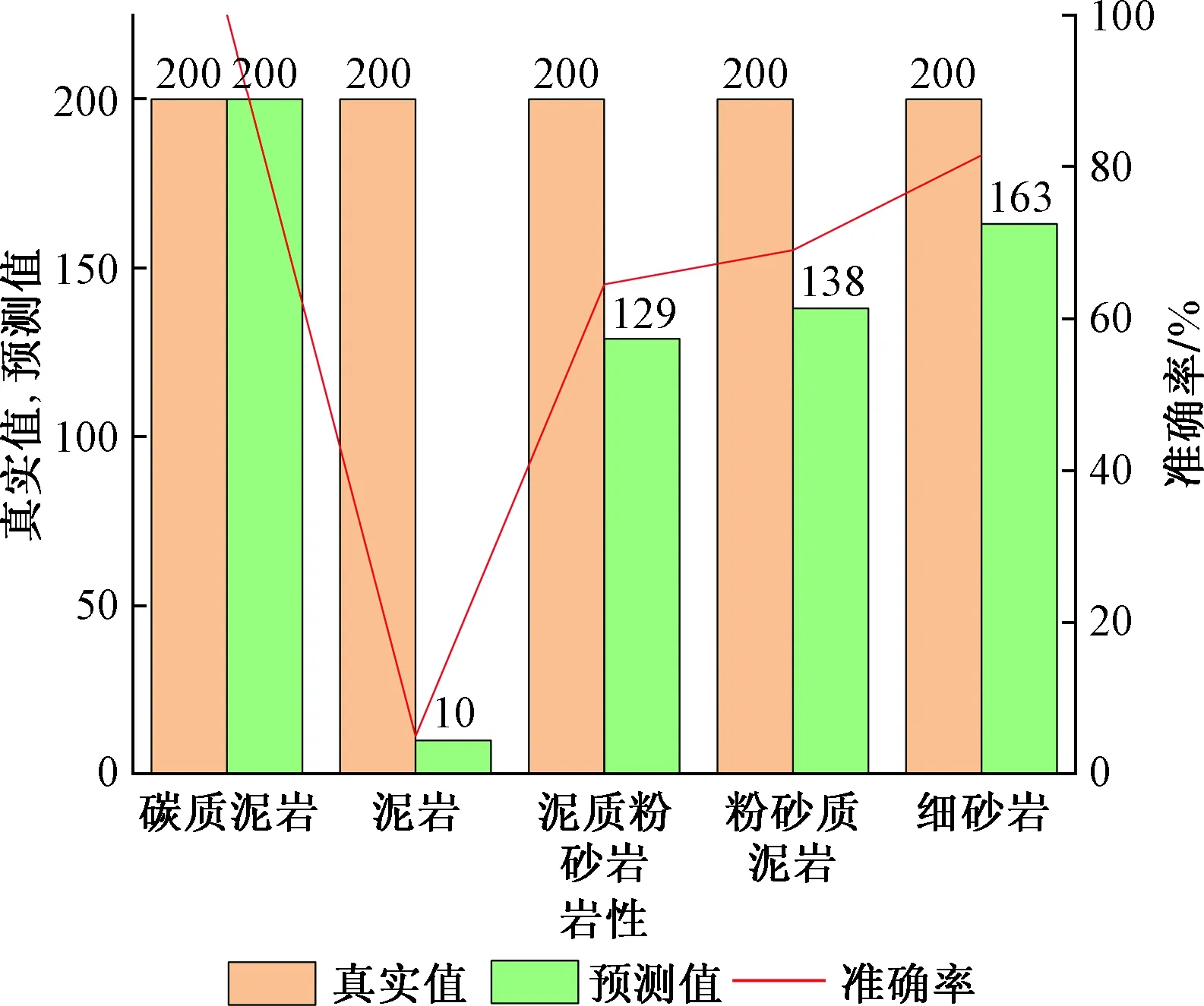
图7 模型预测值与真实值对比Fig.7 The comparison of predicted value and true value
经过反复调整,得到最佳模型后,利用该模型对6 500个岩性测试样本预测,将泥岩、碳质泥岩/炭质泥岩、泥质粉砂岩、粉砂质泥岩、细砂岩五种岩性预测值与真实值对比,发现泥岩预测存在较大误差。统计1 000个岩性预测数据量,并作出分布直方图(图8)。由图8可见,模型对碳质泥岩/炭质泥岩预测数量占总数量的31.5%,而泥岩预测数量占总数量的3.3%。为研究模型对泥岩预测准确度低的原因,进一步对泥岩预测部分做分布直方图(图9),由图9可见,模型将泥岩大部分识别为碳质泥岩/炭质泥岩与粉砂质泥岩。进一步对输入的测井曲线做关联度分析(图10),由图10可见,声波时差(AC)、自然伽马(GR)、密度(DEN)测井曲线相似较大,而对测井曲线相似的样本进行预测。结果有两种,即实测值与预测值一致,或者实测值与预测值不一致。模型预测在训练过程中将碳质泥岩/炭质泥岩、粉砂质泥岩与泥岩模糊化区分,造成模型预测岩性时,对泥岩未能精确识别。本文中认为出现这种情况原因在于:①模型的训练数据少,模型未到达最优;②研究区域泥岩中含有大量火山灰,使得测井曲线中的电阻率(RT)出现异常值,这些异常值造成模型对泥岩的识别精确度降低。

图8 测试样本岩性预测数量分布图Fig.8 The distribution map of lithology prediction quantity of test sample
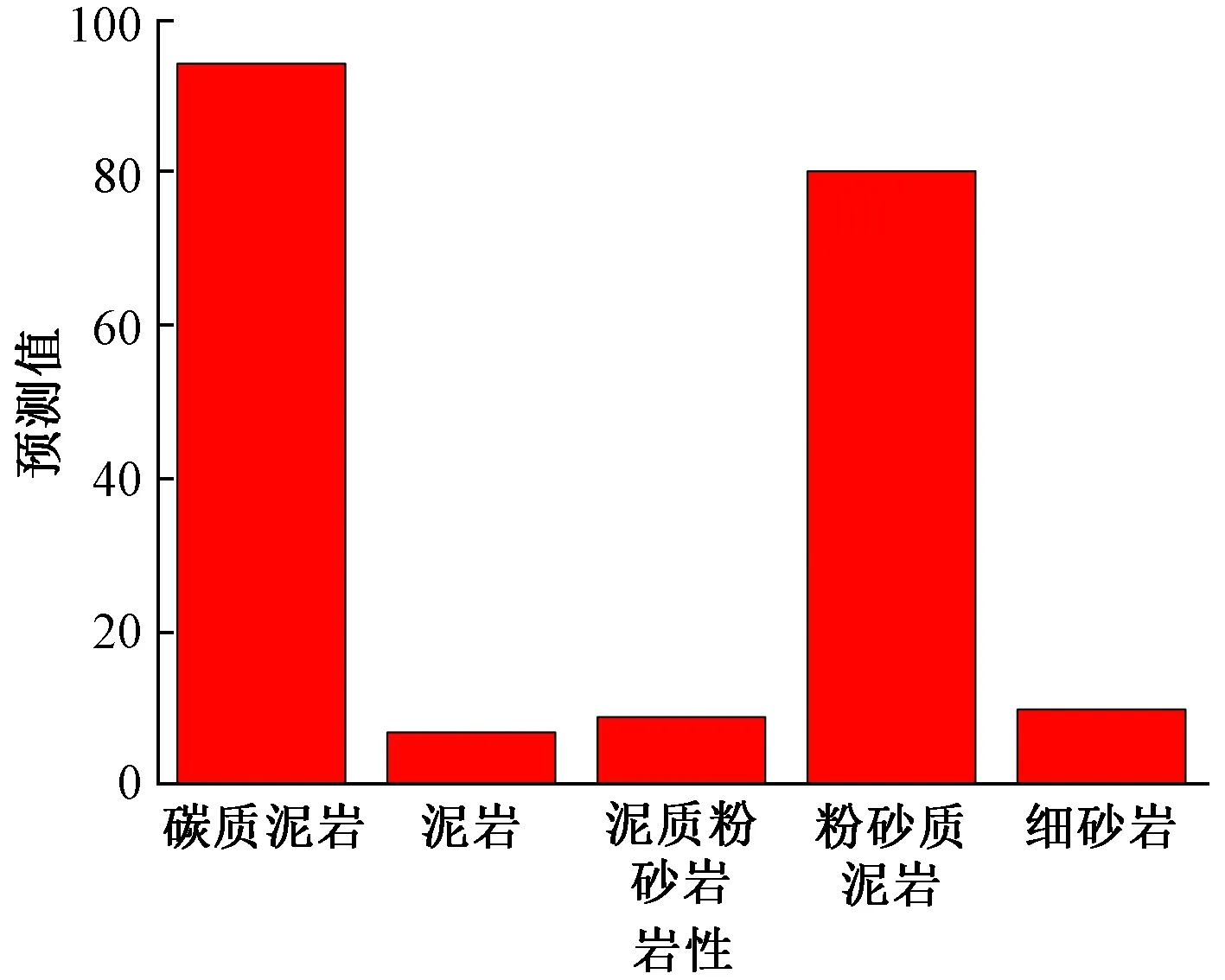
图9 泥岩预测值分布图Fig.9 Mudstone prediction result distribution map

图10 输入特征变量关联度分析图Fig.10 The input characteristic variable correlation analysis graph
由测试结果分析与评价,可见模型能够解释鄂尔多斯盆地致密砂岩储层岩性数据。对于泥岩、粉砂质泥岩与碳质泥岩/炭质泥的识别,可进行一个二分类,先判别出泥岩,之后再预测其他四种岩性或者选用长短期记忆神经网络考虑层序地层,以提高对泥岩、粉砂质泥岩与碳质泥岩/炭质泥的预测的精准度。
3 模型应用
将上述经过测试与检验后的全连接神经网络应用于实际的一批生产井岩性解释,解决了前面提到的泥岩、粉砂质泥岩与碳质泥岩/炭质泥的识别模糊的问题。其中将一口井标准化后的声波时差(AC)、自然伽马(GR)、电阻率(RT)、泥质含量(SH)、自然电位(SP)、有效孔隙度(POR)、含水饱和度(SW)、密度(DEN)八条测井曲线输入到训练好的全连接神经网络,预测其对应储层的岩性(图11)。由图11可见,预测的准确率达到71%,总体来看模型取得了非常理想的效果。

图11 常规地层岩性划分与预测地层岩性划分对比Fig.11 The comparison of conventional stratum lithology division and prediction stratum lithology division
从结果中可以看出电阻率对深度学习模型岩性类型特征作用不大,传统的根据测井曲线岩性分类方法,电阻率是区分泥岩重要因素。在深度学习中并未起到决定因素,反而对模型区分泥岩造成一定影响。从分类结果来看,模型达到了预期的结果,这也反映出深度学习的优势,即从大量的数据中自主学习数据特征,自主学习高维数据复杂的特征,继而解决油田实际生产中的非线性问题。而利用常规岩性分类方法,电阻率这一参数会导致出现较多的错误。
4 结论
利用深度学习建立了测井曲线与岩性数据之间的非线性映射关系。将声波时差(AC)、自然伽马(GR)、电阻率(RT)、泥质含量(SH)、自然电位(SP)、有效孔隙度(POR)、含水饱和度(SW)、密度(DEN)八种常规测井曲线作为深度学习的输入特征量,45 000个训练样本训练深度神经网络,并将训练好的网络模型应用在6 500个样本中测试并验证,测试结果准确率达71%。可指导同一研究区未取心井岩性识别,为油田开发提供了一种可靠、快速的方法,从而提高储量估算和生产计划效率。
猜你喜欢
山西建筑(2022年23期)2022-12-08
测井技术(2022年3期)2022-11-25
复杂油气藏(2021年1期)2021-05-27
天然气与石油(2019年6期)2020-01-13
建材发展导向(2019年5期)2019-09-09
建材发展导向(2019年10期)2019-08-24
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国煤层气(2015年4期)2015-08-22
中国海上油气(2015年3期)2015-07-01
中国质量与标准导报(2015年2期)2015-02-28
