
面向车联网数据隐私保护的高效分布式模型共享策略
2022-04-29 05:15莫梓嘉高志鹏杨杨林怡静孙山赵晨
通信学报 2022年4期
莫梓嘉,高志鹏,杨杨,林怡静,孙山,赵晨
(北京邮电大学网络与交换技术国家重点实验室,北京 100876)
0 引言
在5G 和人工智能等新一代信息和通信技术的支撑下,由车辆、路边单元(RSU,roadside unit)、基站(BS,base station)组成[1]的车联网(IoV,Internet of vehicles)[2]通过车与车、车与人、车与路边环境等多维交互方式实现智能化交通管理、动态信息服务以及车辆智能化控制。车联网场景中车辆与各节点之间的数据共享对于改善驾驶体验、增强车载服务起着至关重要的作用。海量的车载数据包含大量关于个人的敏感信息,例如轨迹、交通信息和多媒体数据等,泄露这些敏感信息对用户有着直接和明显负面的影响[3-5]。因此,如何在保护隐私的前提下高效地共享数据是一个关键的研究课题。
联邦学习[6-7]为车联网数据共享提供了一种去中心化的分布式安全解决方案。通过将本地数据保存在车辆节点上,中心服务器聚合多个节点模型参数的方式来训练模型,从而将数据共享问题转化为模型共享问题,在很大程度上解决了隐私问题,同时降低了数据传输成本。但是,传统联邦学习方法缺少鼓励和吸引车辆节点参与学习的激励机制,为联邦学习引入激励机制可以有效地提高联邦学习获得信息的能力。而区块链[8]凭借着分布式存储特性天然地保证了联邦学习中多个节点的模型参数一致性,同时为模型共享提供激励,鼓励车辆节点参与系统学习以提升整体性能。
然而在车联网场景中,由于车辆的移动性和不可靠的车间通信,将区块链与联邦学习集成到车联网中面临新的问题。随着车联网中车辆数量的增加和网络带宽的限制,通信效率成为在车联网场景中进行大规模数据共享的瓶颈之一。在这种情况下,本文主要面对3 个挑战:首先,区块链产生的额外计算和通信开销给予系统较大的通信压力;其次,联邦学习模型参数的同步聚合方式造成了难以忽视的计算效率问题;最后,由于车辆及路边单元等设备懈怠导致准确率降低,系统整体性能受限。因此,为解决上述挑战,本文为车联网设计了基于主从链体系的异步联邦学习架构,旨在保护数据隐私的同时,实现高效的分布式模型共享。本文的创新点如下。
1) 提出了基于主从链体系的异步联邦学习(AFL-MSC,asynchronous federated learning based on master-slave chain)机制,与传统基于区块链的方法相比,本文提出的分层架构可以有效降低通信成本,适用于动态多车辆场景。
2) 摒除了联邦学习同步聚合的等待时间限制,结合遗传算法(GA,genetic algorithm)构造了基于通信资源优化的异步联邦学习算法,提高了通信效率。
3) 弥补了联邦学习架构中参与节点积极性差的弱点,依靠联邦学习的参数更新方式,提出了基于共识交易的节点训练激励机制,将联邦学习的模型参数以交易格式进行存储和传输,从而降低了参数传输的通信成本以及共识时间。
4) 改进了拜占庭容错共识算法的不足,构造了轻量化的区块链共识机制——混合拜占庭容错的改进委托权益证明共识机制(DPoM,delegated protocol of model),实现了快速共识,减少了系统运行时间。
1 相关工作
车联网的重要特征在于协作环境数据传感、计算和处理[9]。分布式场景下的多方数据共享是缓解车联网中计算和存储资源受限问题的一种有效方法,联邦学习技术的出现为车联网数据共享提供了有力的技术基础支撑[10]。Mcmahan 等[7]提出了一种基于迭代模型平均的联邦学习方法,该方法在学习过程中将训练数据分布在移动设备上,通过聚合本地计算的更新来学习共享模型,大大降低了数据泄露的风险。进一步地,Zhao 等[11]将联邦学习框架引入车联网环境中,为了避免隐私威胁并降低车辆之间的通信成本,将联邦学习和本地差分隐私(LDP,local differential privacy)相结合,提出了一种 LDP-FedSGD 算法来协调云服务器和车辆协同训练模型。该模型提出了4种差分隐私机制来扰乱本地模型输出的梯度,同时提出了三输出机制,为隐私预算引入3 种不同的输出可能性,并用两位编码以降低通信成本。类似地,为了减少节点和中央服务器之间的通信成本,Chen 等[12]提出一种基于深浅层异步参数更新的增强联邦学习(ASTW,temporally weighted asynchronous federated learning)技术,此外,在中央服务器上引入了时间加权聚合策略,以提高中心模型的准确性和收敛性。然而,这种方法存在一个集中式的管理服务器,显著增加了系统单点故障的风险。
为规避单点故障风险,Lu 等[13]将区块链技术扩展到车联网分布式数据共享架构中,设计了一种由许可区块链和本地有向无环图组成的混合区块链架构,以提高模型参数的安全性和可靠性。此外,Lu等[13]还提出了一种异步联邦学习方案,通过深度强化学习进行节点选择以提高效率。遗憾的是,该方案并未采取有效方法来提高异步联邦学习参数传输中的通信效率。类似地,Chai 等[14]提出了适用于车联网数据共享的分层区块链和分层联邦学习(HBFL,hierarchical blockchain-enabled federated learning)算法。知识在联邦学习过程中以学习参数的形式共享,HBFL 算法将车辆和基础设施根据其区域特征分组并维护其专属区块链账本来记录联邦学习模型。同时,Chai 等[14]还提出了一种轻量级共识机制——知识证明(PoK,proof of knowledge),将知识共享过程建模为交易市场中的多领导者和多人非合作博弈。与传统区块链框架相比,该算法虽然充分考虑了计算成本问题,但忽略了联邦学习的参数共享造成的通信成本问题。针对通信效率问题,Pokhrel 等[15]依靠联邦学习的更新奖励方法,设计了一个包含区块链参数的数学框架(例如,重传限制、块大小、块到达率和帧大小),通过对端到端时延的严格分析量化来推导出最佳块到达率,从而最小化系统时延。该框架忽略了联邦学习中同步聚合导致的时延问题,从而影响了系统的整体运行时延。
已有研究方案对比如表1 所示。通过以上调研发现,大多数面向车联网场景的数据共享方案忽略了用户激励以及共识算法对系统效率的影响。同时,联邦学习的聚合方法也是保障共享机制高效性与有效性的一个重要因素,为此,本文提出了面向车联网数据隐私保护的高效分布式模型共享策略。

表1 已有研究方案对比
2 系统模型
2.1 网络架构
车联网由车辆、路边单元、基站3 个部分组成,如图1 所示。其中,基站具有较高的计算和通信能力;路边单元配有移动边缘计算(MEC,mobile edge computing)服务器,具有一定的边缘侧计算和通信能力;车辆装有智能车载系统负责车辆数据实时处理和多传感器数据融合,保证车辆在各种复杂的情况下稳定、安全行驶。路边单元通过无线信道通信链路向上与基站相连接,向下与其覆盖范围内的车辆相连接。
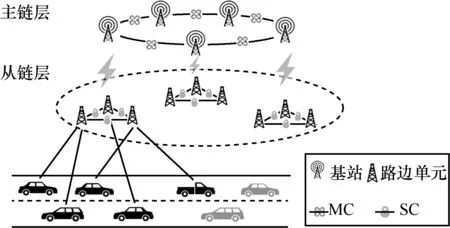
图1 主从链架构
本文所提机制由基站组成的主链(MC,master chain)和多个由路边单元维护的从链(SC,slave chain)构成。本文假设参与学习的节点都是安全可信的,不存在恶意上传错误参数的可能性,但是,节点本身存在懈怠状态,有一定可能无法及时尽力地参与计算与共享过程。
本文所提主从链架构将全局计算与共享过程分为3 个步骤,车辆层的本地计算过程、从链层的学习过程以及主链层的学习过程。系统参数如表2 所示。

表2 系统参数
1) 车辆层的本地计算过程
车辆在本地执行基于机器学习的模型训练过程,一段时间后将训练结果向上发送给邻近的路边单元。在本地训练阶段,每个车辆基于其本地数据来训练模型,车辆在训练数据集上的损失函数为

其中,f u(w,xu,yu)是损失函数在数据样本(xu,yu)上的值,w是所训练模型的参数,是数据集所含有的样本数目。在不同的算法中,损失函数有不同的计算方式,本文采用梯度下降的算法来计算损失函数
2) 从链层的学习过程
路边单元收到所有参与训练的车辆发来的模型参数后执行全局聚合,其目标是通过全局聚合将损失函数值最小化。本文采用的加权聚合方式为
聚合后的新模型参数以交易的方式由主记账节点发起共识,从链层中多个路边单元共识后的结果被记录到区块链上由主记账节点向上发送给邻近的基站。
3) 主链层的学习过程
同从链层的学习过程相似,基站收到由路边单元发送的模型参数及计算结果后将其存储在本地,同时将所有收到的参数聚合,此处全局聚合的损失函数定义为

2.2 计算时延模型
本文所提机制的系统时延主要分为计算时延和通信时延,其中,计算时延包括节点本地计算的时间以及多节点参数聚合的时间。为了简化分析过程,本文以一次迭代过程为例进行分析,V I是所有参与学习的车辆集合,对于车辆∈VI,其所持数据集用表示,车辆的CPU 主频用f()表示;为训练单位数据的CPU 周期个数。那么在本地计算中,每辆车每轮的训练时间为

类似地,f()和分别为路边单元的CPU 主频以及训练单位数据的CPU 周期个数为路边单元在一段时间内收到的来自所属区域内各车辆上传的参数值。在侧链层,路边单元用来聚合区域内车辆上传的模型参数所需的计算时间为

类似地,f(bn)和Cn分别为基站bn的CPU 主频以及训练单位数据的CPU 周期个数,为基站在一段时间内收到的来自所属区域内各路边单元上传的参数值。在主链层,基站用来聚合区域内路边单元上传的模型参数所需的计算时间为

在本文的系统模型中,相比于本地计算以及上传时间,模型聚合所需要的时间非常少,所以,本文不把聚合时间作为一个重要影响参数衡量。
2.3 通信时延模型
本文考虑使用时分多址(TDMA,time division multiple access)方法来实现数据的传输并用加性白高斯噪声信道(AGWN,additive white Gaussian noise)计算方式来表示AFL-MSC 机制中的信道状态。本文所提AFL-MSC 机制中的模型参数通过无线信道进行数据传输的过程主要分为2 个部分,下载全局模型参数的时延和上传本地模型参数的时延。假设数据传输中总带宽为B,可用的信道数为c0,对于车辆,其上行链路可达到的数据传输速率为
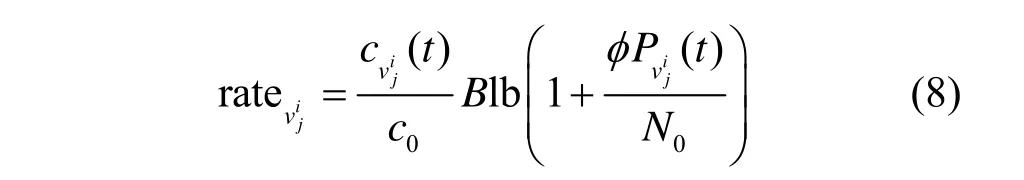
其中,cvij(t)是第t次迭代轮数被分配的子信道数,N0是噪声强度,Pvij(t)是车辆的发射功率,φ是车辆与上行路边单元之间的无线信道增益,(t)是车辆客户端传输的模型参数量,为固定值。车辆上传模型参数至路边单元的传输时间为


由于系统的下行带宽远大于上行带宽,因此本文不考虑下行时间。
3 算法设计
3.1 基于通信资源优化的异步联邦学习算法
本文设计了一种基于通信资源优化的异步联邦学习算法,通过降低联邦学习中单轮次所需通信资源来降低系统的整体通信开销,提升共享效率。
以从链层中车辆上传参数至路边单元的过程为例,传统的联邦学习通信过程如图2 所示。由于车辆计算和通信资源的异构性,不同车辆的本地计算完成时间不同,路边单元等待所有参与学习的车辆完成本地计算并上传参数后才开始聚合,冗余的等待时间降低了系统的通信效率。

图2 传统的联邦学习通信过程
本文提出的基于通信资源优化的异步联邦学习算法根据车辆当前的计算能力和信道状态信息,自适应地将通信资源分配给参与的车辆,以减轻通信性能的不平衡。如图3 所示,计算能力较差的车辆被分配更多的通信资源,而计算能力较强的车辆被分配更少的通信资源。

图3 优化的联邦学习通信过程
车辆的数据传输速率为

其中,∈{0,1}表示当前子信道是否分配给车辆,=1表示当前子信道分配给车辆,=0表示当前子信道不分配给车辆。对于车辆,本文算法在第t次迭代期望的平均执行时间为

基于以上内容,本文算法的优化问题可以表示为

其中,λ i表示车辆是否参与此次联邦学习,λi=1代表是,λi=0代表否。为了找到式(13)的最优解,本文引入遗传算法。遗传算法具有良好的全局搜索能力,利用它的内在并行性可以方便地进行分布式计算,加快求解速度。基于遗传算法的车辆选择和通信资源分配算法如算法1 所示。
算法1基于遗传算法的车辆选择和通信资源分配算法


3.2 基于主从链架构的DPoM 共识机制
由于传统区块链共识机制的密集资源消耗以及高时延特性,将其应用于本文提出的主从链联邦学习框架中不利于系统的整体性能。因此,针对区块链共识效率及激励问题,本文提出了一种轻量级的共识方案来提高整体的通信效率。
3.2.1 交易格式及激励机制
本文所提机制的交易过程如图4 所示。
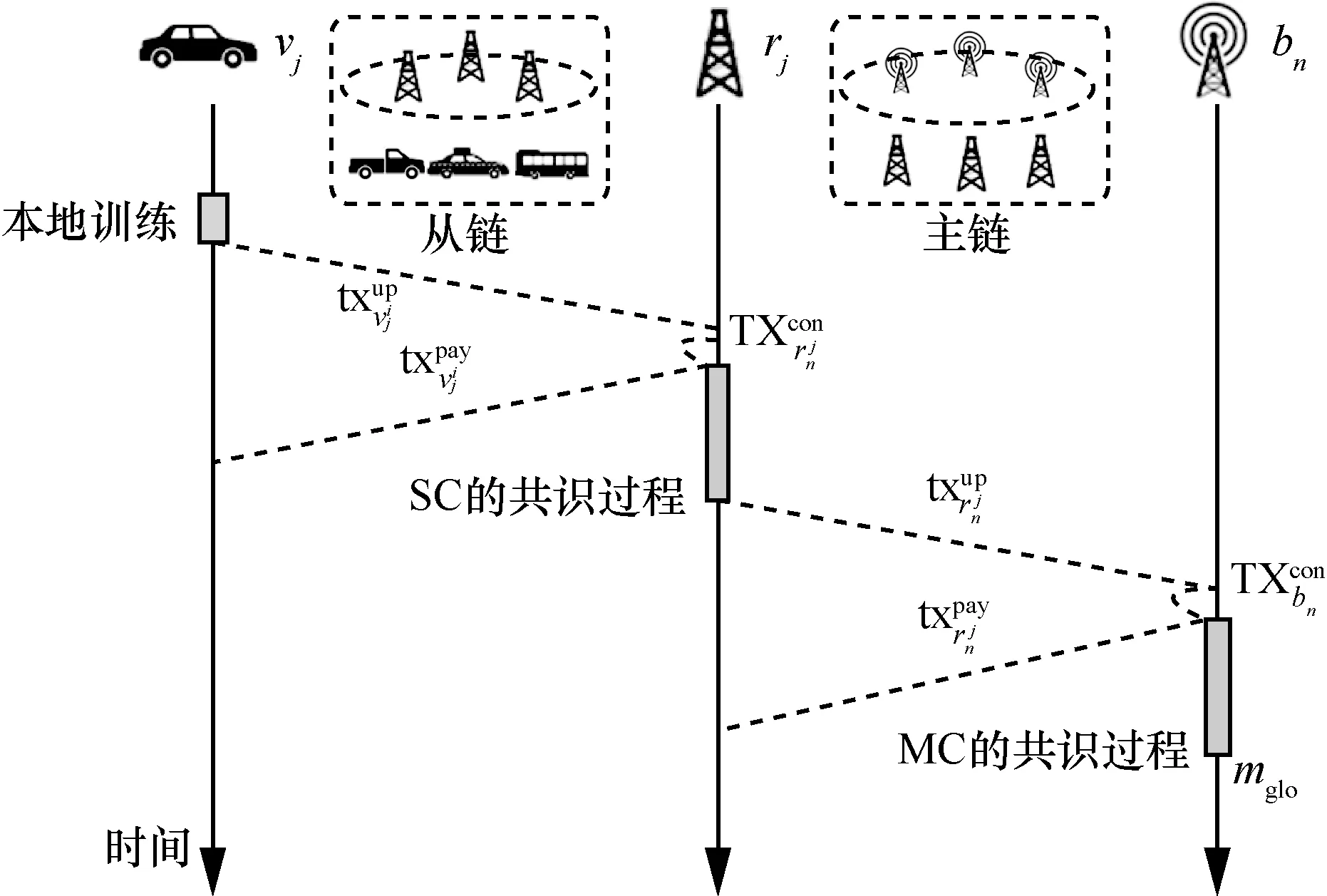
图4 本文所提机制的交易过程
在从链层,所有参与学习的车辆通过计算本地数据集得到模型参数以及训练结果的损失函数下降比例,每个车辆将上述参数打包为交易的格式发送给邻近的路边单元

交易中的第二项为0 意味着该交易为车辆上传训练好的模型参数,在收到该笔交易后,路边单元先检查该笔交易的真实性,然后提取交易中的参数为后续的聚合过程做准备,并返回一个奖励给车辆。针对车辆的工作懈怠问题,本文提出了相应的激励机制:将收到的所有车辆上传的结果按照损失函数值减少的比例进行倒序排序,本文期望车辆能够将更多的计算资源贡献给学习过程,以达到系统的最快收敛。对于排序好的队列,假设上传的交易排第n个位置,则其所获得的奖励为

其中,I为参与学习的所有车辆数;为路边单元的本地奖励,初始值设为1。路边单元返回奖励给相应车辆的交易为

在下一步的共识过程中,路边单元负责锻造新的区块。本文期望提升通信效率,因此在共识过程中用哈希来代替原有交易中的参数内容。因为联邦学习的模型参数量相比于一般区块交易中值来说是巨大的,常用的数据集如MNIST 数据集每次更新的参数量大概在1 MB 左右[16],所以本文在区块交易中记录模型参数的方法是记录它的哈希值,当智能合约验证交易时,它需要查询星际文件系统(IPFS,inter planetary file system)以获得链下值。此时,路边单元在共识阶段发起的区块包含的交易格式为

其中,Addrrnj是确认区块发起者的身份,是这笔交易在达到共识后的奖励,H()是模型的哈希值,是该模型的准确率。共识通过后,主记账节点将新交易上传至邻近基站

与从链层类似,基站收到后提取交易中的参数值,在本文的设定中,路边单元和基站都不会产生懈怠,所以此时基站返回的奖励为
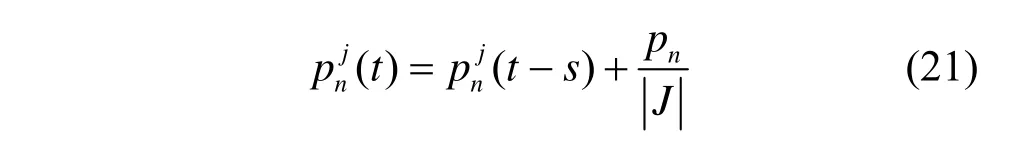

基站聚合所有参数后开始锻造区块并发起共识,此时的交易为

所有基站通过共识后得到新的全局模型wglo并将全局模型下发。本文提出的框架结合区块链和联邦学习技术来解决隐私问题。分层联邦学习方法利用参数上传机制取代传统的数据上传方法,有效地保护参与者的隐私,此外,区块链技术利用非对称加密技术和数字签名技术将参数本身替换为哈希值,进一步保护用户的隐私。
3.2.2 DPoM 共识机制
在本文提出的区块链框架中,模型聚合后的参数共享过程通过共识来达到。本文使用多个路边单元来聚合车辆在其覆盖范围内生成的本地模型,并利用区块链来同步这些模型,在不同的路边单元和基站之间达成共识。由于全局模型需要确认为区块链交易,因此区块链的运行效率对整个学习过程至关重要。由于本文提出的框架分为两层,而在从链和主链这两层的共识内容是相似的,为了方便分析,本文只给出了从链层的共识过程。
传统共识机制比如工作量证明(PoW,proof of work)机制采用哈希难题来确定候选区块的发布者,其中能够最快解出难题的获得记账权,但是该方法拥有较低的吞吐量和较高的确认时延;代理权益证明(DPoS,delegated proof of stake)机制作为主流共识算法中最平衡的算法,采用选举部分特殊节点代理网络中其余节点的方式,减少了参与区块生产和验证的节点数量,既能满足公有链对吞吐量的需求,又可以在一定程度上降低确认时延。基于此,本文提出了代理模型证明(DPoM,delegated proof of model)机制,将实用拜占庭容错(PBFT,practical Byzantine fault tolerance)算法引入DPoS的节点验证部分,能够进一步降低验证时延,同时引入惩罚机制,对节点生产区块的质量进行评估,以提高系统整体性能。
1) 节点类型
本文见证人选举模型涉及4 种角色节点:普通节点、候选节点、见证人节点、备选见证人节点。
普通节点是系统中占比最大的节点类型,具有投票权和被选举权。被普通节点选举出来的节点称为候选节点。候选节点通过排序分为见证人节点和备选见证人节点2个集合。见证人节点具有区块打包的权力。备选见证人节点则负责对见证人节点生产的区块进行验证以及替换效率低的见证人节点。
2) 选举机制
在本文的方案中,所有参与的路边单元都充当区块链用户。它们持有的股份代表它们对训练模型的贡献,本文将其设为模型的质量。区块链用户根据路边单元计算和通信能力投票选择首选的路边单元作为验证者。持股节点在投票选举阶段会将手中的股份作为票数通过赞成投票的方式给支持的节点进行投票,每个节点允许给其他节点投一票。当投票结束后,系统计算所有节点的有效得票数,选择有效得票数排名前2TN个节点作为候选见证人节点(TN是系统通过至少50%投票的持股节点认为足够去中心化的见证人节点数目),并将其分为两组,得票数排名前TN个节点作为本轮的见证人节点集合A1={x0,x1,…,xTN-1},另一组作为备选见证人节点集合A2={xTN,xTN+1,…,x2TN-1}。
3) 见证人节点出块
DPoS 算法通过选择一部分称作“见证人”的节点,代为行使区块链系统中区块生成和区块验证的工作。每个见证人节点排好序后在规定的时间间隔内按序生产区块,如果没有生产成功则跳过该见证人,由下一见证人继续锻造区块。这样可以有效避免见证人出块错误导致的系统时延问题。
4) 区块验证
针对DPoS 算法目前存在的节点生成区块后验证时延过长的问题,引入PBFT 算法,将见证人节点生成的区块立即通过PBFT 算法进行验证,新的机制可以在更短的时间内完成区块的验证,从而大大降低交易的确认时延。
在原始DPoS 算法中,选举出的见证人节点会被随机打乱序列,然后在规定的时间内按照序列生产区块,新生成的区块随着见证人节点的序列交由后续的见证人节点进行区块验证。当一个区块生成后需要得到的验证确认数为总见证人节点数目的时,才能被加入区块链中,这样大大延长了验证时间。为了提升区块验证时延并更好地利用选举出的备选见证人节点集合A2,本文通过A2集合中的节点对A1生成的区块进行立即验证。
基于DPoS 的见证人选举模型选举产生了2 个节点集合:见证人节点集合A1和备选见证人节点集合A2。A1节点的主要作用是对网络中产生的交易进行打包,生产区块,A2节点则作为备选节点用户运行PBFT 算法,A1生产的区块立即广播给A2集合中的节点进行验证工作,从而更快地完成区块的验证工作,降低区块内交易的时延。
除此之外,在区块验证过程中,以主链层为例,每个基站将其聚合模型发送给其他验证节点进行验证。除了常规的验证外,验证者还根据模型是否对最后一个全局模型进行更新做出了积极贡献来验证接收到的模型。主验证节点从所有验证节点收集验证结果并确认事务。审核后的区块被添加到区块链中,并广播到其他基站进行存储。
见证人节点将产生的区块向备选见证人集合中广播。备选见证人集合中的主节点接收到该区块信息后,会封装信息并签名,主节点的选取遵循

其中,v为PBFT 的视图编号,为备选见证人节点个数。主节点将封装并签名的消息向A2中的其余节点广播,当其余备选见证人接收到区块消息时需要验证,验证的规则如下。
①签名是否正确。
②消息中的视图编号和该节点的视图编号是否一致。
③该区块消息是否已经接收过。
④消息中的区块高度是否和该节点的区块高度一致。
⑤模型是否对最后一个全局模型做了积极贡献。
满足上述条件的区块消息才会被备选见证人节点承认。当备选见证人节点承认接收的区块消息有效时,该节点状态就会进入准备状态,之后会继续封装准备消息并进行签名,准备消息会继续向其余节点广播,当检验通过累积达到后,节点会进入提交状态,然后封装并签名确认消息,同样地,当确认消息个数达到时,该消息得到验证,该轮验证区块完成,验证结果会被返回给生产区块的见证人节点,意味着该区块可加入区块链中。基于改进PBFT 的优化区块验证算法如算法2 所示。
算法2基于改进PBFT 的优化区块验证算法


4 仿真与性能分析
4.1 仿真设置
4.1.1 参数设置
为了验证本文所提机制的有效性,分别在MNIST[17]数据集和SVHN[18]数据集上对其进行了评估。二者均为来自真实世界的数据集,可代表本地设备所收集的复杂度中等的数据,也被大量基于车联网场景的联邦学习算法作为测试数据使用。其中,MNIST 作为一个大型手写数字数据库广泛应用于图像分类任务,由60 000 个训练示例和10 000 个测试示例组成。SVHN 摘自Google 街景图像中的门牌号,适用于车联网中车载传感器读取车辆周围图像数据场景,SVHN 中包含了超过60 万张数字图像,其中训练集有73 257 张图像,测试集有26 032 张图像,以及额外531 131 张图像作为训练使用。
为了更好地评估本文所提机制,数据集被平均分为100 个子集分配给100 个节点。实验使用卷积神经网络(CNN,convolutional neural network)作为训练模型,该网络由2 个5×5 的卷积层、一个全连接层和一个softmax 输出层组成。在每个迭代周期中,包含一次全局聚合和10 次本地训练时隙。基于上述设置,本节将对本文所提机制进行性能验证。
4.1.2 对比方案
在本文所提机制的仿真过程中,有以下3 种对比方案。
1) 激励机制评价。通过对比本文所提机制AFL-MSC 与FedAVG 和ASTW-FedAVG,可以看出本文所提激励机制对提升系统通信效率的有效性。
2) 共识机制评价。通过对比本文所提DPoM 共识机制与PBFT 和DPoS 在区块确认时间上的差异,可以看出本文所提共识机制对提升系统通信效率的有效性。
3) 综合性能评价。通过改变参与训练的节点数量,可以清晰地看出本文所提机制的可扩展性;通过与ASTW-FedAVG 以及本地CNN 算法的对比,可以看出本文所提机制的准确率以及对不同数据集的通用性。
4.2 仿真结果分析
4.2.1 激励机制评价
为了验证本文所提激励机制的效果,本节采用2 个指标来衡量比较算法的性能。一个是中心模型在200 轮内的最佳准确率,另一个是在中心模型的准确率达到95%(SVHN 数据集为90%)。相同的计算轮次意味着相同的通信成本。MNIST 数据集和SVHN 数据集均被分为100 个子集并部署于100 个节点上,由于数据集切分的随机性,本文采用3 次随机分配结果,例如,第一次数据集的随机分配被称为1@MNIST,比较本文所提机制AFL-MSC 与FedAVG 和ASTW-FedAVG 在MNIST 和SVHN 数据集上的结果,如表3 所示。
从表3 可以看出,ASTW-FedAVG 和AFL-MSC在所有数据集上的通信轮数、准确率都优于FedAVG,这是由于FedAVG 未采用任何激励机制或其他优化算法对联邦学习中的通信效率进行优化。以1@MNIST 为例,AFL-MSC 需要31 轮通信即可达到95%的准确率,优于需要61 轮才能达到相应准确率的ASTW-FedAVG 以及需要75 轮才能达到相应准确率的FedAVG。实验说明,AFL-MSC 在大多数数据集上的通信轮数和准确率方面都取得了最优结果,证明本文所提激励机制加速了学习的收敛速度并提高了学习性能,显著降低了联邦学习的通信成本。

表3 激励机制性能测试
4.2.2 共识机制评价
时延是衡量共识算法效率的指标,本文所指区块确认时延是区块从见证人节点生成后到最终被备选见证人节点验证可添加到区块链的时间间隔。作为比较,对比分析相同环境下本文所提DPoM 与DPoS 和PBFT 的确认时延,如图5 所示。

图5 区块确认时延对比
从图5 可以看出,本文所提DPoM 在区块的验证上做到了及时确认,所以时间上只需要800 ms左右,而原本DPoS 算法因为需要得到至少个总验证人节点的验证确认,所以验证时间至少需要6 s。同时,因为采用了PBFT 算法的核心思想,所以DPoM 与PBFT 的验证时延基本一致。由于本文所提DPoM是通过选举部分见证人节点的方式代为生产区块,且见证人的数量在很长一段时间内是固定的,因此区块的吞吐量和验证时延都不会随着全网节点的增加而有很大的变化,这一特性较好地保证了区块链网络的稳定性。
4.2.3 综合性能评价
图6 和图7 给出了在不同训练节点数量的情况下本文所提机制在MNIST 和SVHN 数据集上的准确率。为了更加符合车联网中真实场景,实验将随机选取3 个节点设置为低质量的参与者,这3 个节点的通信和计算能力较差,通过随机噪声干扰原始参数为模型聚合过程提供较差的模型参数质量。实验结果表明,本文所提机制具有良好的精确度,由于数据集本身结构更加复杂,本文所提算法在SVHN 上的全局准确率结果略低于MNIST,但是同样能够达到较高的精度,证明了本文所提算法对不同数据集的通用性。

图6 MNIST 数据集上不同数量节点的全局准确率
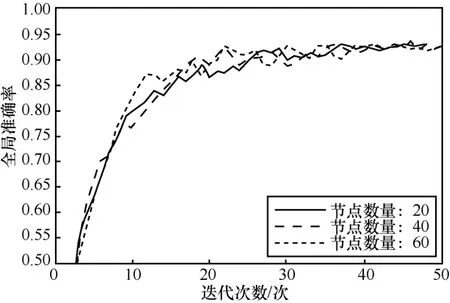
图7 SVHN 数据集上不同数量节点的全局准确率
当参与训练的节点数量分别从20、40 变为60时,随着迭代次数的增加,全局准确率结果有小幅的降低但整体差异不大。实验结果变化的幅度较小,说明了本文所提机制具有良好的可扩展性并且能够有效减少低质量节点对整体学习结果的影响。
在综合性能评价的算法对比实验中,本节将本文所提机制与本地CNN 和ASTW-FedAVG 进行比较。数据集被随机分为100 个子集以分配给100 个训练节点,本地CNN 中节点使用被分配的子集进行模型训练,ASTW-FedAVG 在节点的子数据集上进行局部模型训练,并在中央服务器采用加权平均聚合算法更新全局模型。图8 和图9 表明,本文所提机制的准确率略优于ASTW-FedAVG。本地CNN的准确率远低于其他2 种机制,原因是在本地CNN训练算法中,本地训练的目标是最小化本地数据集的损失,这样导致其可以得到局部最优解,但可能离全局最优解仍有一定距离,因此准确率较低。实验证明,本文所提机制在保障数据安全和隐私保护的情况下仍可以达到较高的准确率。

图8 MNIST 数据集上3 种算法的全局准确率

图9 SVHN 数据集上3 种算法的全局准确率
图10 评估了系统总体运行时间。对于相同数量的用户,系统的运行时间随着数据集大小的增加而增加,最终趋于平稳,这是由于本文所提机制在一定程度上优化了联邦学习的计算效率以及区块链的共识效率,从而提高了系统的运行效率。对于不同数量的用户,系统的运行时间随着用户数量的增加而增加,原因是用户越多,实现协同工作所需的时间就越多。
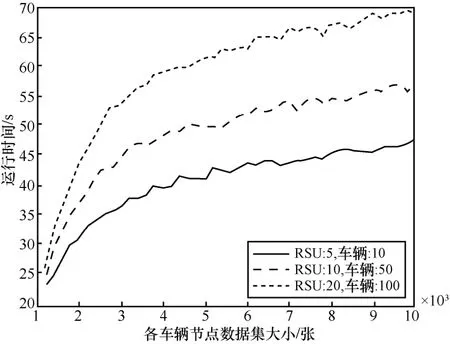
图10 系统总体运行时间
通过以上实验可以发现,用户数量的增加对本文所提机制的准确性影响不大,但运行时间则会明显增加。稳定的准确率是因为所提方案中的主从链模式保证了稳定的学习精度,然而用户的增加使更多的本地模型需要被更新和计算,同时更多的路边单元需要执行共识,这增加了训练和更新传输的时间开销。尽管运行时间略有增加,但多个用户的参与扩大了用于计算的数据规模,从而使数据共享的内容更加准确。
5 结束语
为解决车联网场景中隐私数据共享的效率问题,本文提出了基于主从链体系的异步联邦学习架构AFL-MSC,为分布式边缘计算在数据隐私方面提供了一个安全高效的解决方案。进一步地,为提高系统效率,本文提出基于PBFT 的改进DPoS 共识算法DPoM,将激励机制引入异步联邦学习主从链架构中。仿真实验证明,相较于ASTW-FedAVG,本文所提机制拥有更高的准确率和更低的运行时间,最终实现了安全可靠、智能高效的数据共享。
在未来工作中,将进一步对本文所提机制进行改进和完善。一方面,针对异步联邦学习时间决策问题对用户节点的选择进行优化,考虑多个因素对节点选择的影响,如能耗、通信开销、计算成本等;另一方面,改进共识算法,增强其对动态环境的适用性,以进一步提高算法的可扩展性及稳键性。
猜你喜欢
法制博览(2022年16期)2022-11-22
网络安全与数据管理(2022年1期)2022-08-29
家庭影院技术(2020年10期)2020-12-14
通信电源技术(2020年8期)2020-07-21
家庭影院技术(2019年7期)2019-08-27
电子制作(2019年23期)2019-02-23
党的生活(黑龙江)(2018年8期)2018-09-14
伴侣(2018年7期)2018-07-25
现代防御技术(2016年1期)2016-06-01
党的生活(黑龙江)(2014年12期)2014-12-15
