
基于DRL的PHEV综合优化控制策略
2022-04-27 06:22赵春领吴化腾
西安文理学院学报(自然科学版) 2022年1期
赵春领,吴化腾
(重庆交通大学 机电与车辆工程学院,重庆 400074)
插电式混合动力汽车(Plug-in Hybrid Electric Vehicle,PHEV)被认为是平衡长久里程和低能耗的可行性技术途径[1],而插电式柴电混合动力汽车因为频繁的启动和停止发动机运行,会引起发动机排气的温度变化大,而在插电式柴电混合动力汽车的后处理系统中选择性催化还原(Selective Catalytic Reduction,SCR)技术对排气温度比较敏感,因此会使得NOX排放恶劣[2].所以在插电式柴电混合动力汽车上制定既保证尽量低的油耗又保证尽量低的NOX排放的控制策略,具有很重要的意义.
目前PHEV的整车控制策略研究得到了成熟的发展[3].基于规则的策略在工程中被大量应用,其简单,有很高的实时性[4][5],但策略需要根据大量实验和专家经验来制定.基于优化的控制策略的分为瞬时优化和全局优化,其利用优化算法最小化目标函数实现整车能量的最佳分配[6],但其效率和实时性不高.基于学习的策略利用历史数据或实时数据进行学习和应用[7],可以适应不同的工况,但依赖精确的车辆系统模型和专家经验.近年来大量学者将强化学习应用到混合动力控制策略的开发中,如LIU T[8-9]等人提出基于Q-learning和DYNA算法的混合动力车辆能量管理策略,并且证明了其可行性.但在传统强化学习中面对高维或者连续状态会导致维度灾难,难以收敛,深度强化学习可以灵活的解决复杂控制情况,很好的解决了这些问题.如王勇[10]等人提出基于深度强化学习DDPG算法的PHEV能量管理策略,并证明了其优越性,有效的降低了油耗.
本文提出了基于TD3算法的PHEV经济性和排放性的综合优化控制策略,采用行动-评价算法(Actor-Critic,AC)的架构和经验回放机制,解决车辆复杂的动作空间和连续动作空间的问题,最后将结果与DP策略进行比对分析,证明其策略有很好的效果.
1 PHEV动力系统建模
如图1所示的单轴并联式插电式柴电混合动力汽车为本文的研究对象,其动力系统的各部件以及相关参数如表1所示:
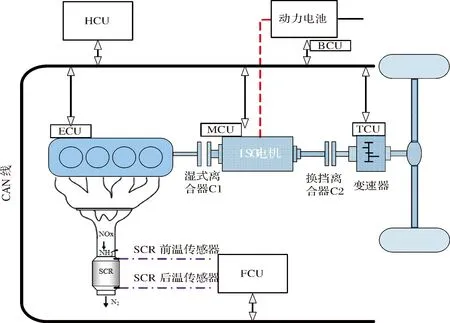
图1 PHEV动力系统结构

表1 整车各部件相关参数
1.1 发动机模型
在建立发动机模型时只考虑发动机的输入与输出的映射关系,发动机转矩、转速和燃油消耗量之间的关系,以及发动机转矩、转速和NOX的排放量之间的关系,由发动机台架实验得到,然后通过插值实验稳态数据建立发动机油耗和NOX排放数值模型如图2、图3所示.

图2 发动机燃油消耗

图3 发动机NOX排放
数值模型表达式为:
(1)
(2)
式中:ge、gNOx、mfuel、mNOx分别为发动机瞬时燃油消耗率、发动机出口瞬时NOX排放率、发动机燃油消耗质量和发动机出口NOX排放质量;ωe为发动机转速;Te为发动机转矩;
1.2 电池模型
本文不考虑温度对电池内部特性的影响,建立如图4所示的电池模型:

图4 电池内阻模型
电池输出电压:
Ub=V(SOC)-R(SOC)Ib
(3)
电池电流:
(4)
电池SOC:
(5)
式中:V为开路电压,R为电池内阻
1.3 后处理模型
SCR后处理技术的作用原理是利用催化剂在富氧的环境下作用在还原剂上将氮氧化物选择性还原成N2和H2O,是降低柴油机NOX排放的有效手段之一[11].将复杂的SCR反应简化,假设废气不能压缩并且流动为等熵流动,建立SCR温度的模型为:
(6)
式中:TSCR为SCR催化器温度,k;
Mexh为发动机出口废气流速,kg/s;
CSCR为催化层比热容;h为热传递系数;
Tamb为发动机环境温度,k;
Teng为发动机出口温度,k;
Cexh为废气比热容.
1.4 整车纵向动力学模型
在建立整车纵向动力学模型时,首先侧向动力学因素的影响忽略不计,然后假设整车质量集中在重心上,建立驱动力平衡方程为:
(7)
式中:Fj为加速阻力;Ff为滚动阻力;Fj为加速阻力;Fw为空气阻力;M为汽车质量;g为重力加速度;f为滚动阻力系数;α为道路坡度;CD为空阻系数;A为汽车迎风面积;v为车速;σ为汽车旋转质量换算系数.
不考虑坡度因素的情况下,即α=0,给定车速v,根据上述方程计算出车辆需求功率和车轮需求转速分别为:
(8)
(9)
2 基于DRL的综合优化控制策略
2.1 深度强化学习TD3基础
强化学习的目标就是通过智能体与环境之间的试错学习,找到最优策略π*,使得累积回报的期望最大[12],其原理如图5所示:
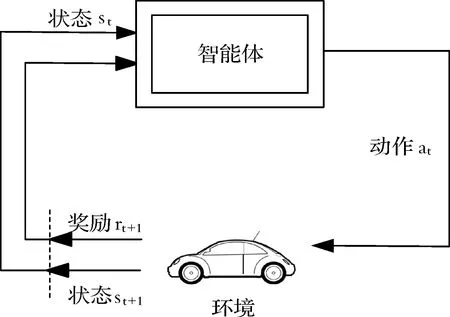
图5 强化学习示意图
其中智能体是学习者和决策者,在每个时间步长采用策略π的智能体根据观测环境的状态st(st∈S),选择对应动作at(at∈A),然后动作作用到环境中,得到对应的回报rt+1和下一步的状态st+1,智能体根据rt+1的大小不断学习改进其行为策略,以便获得最大累积回报.
定义t时刻开始的累积回报为:
R(st,at)+γR(st+1,at+1)+γ2R(st+2,at+2)+…
(10)
简化为:
Rt+γRt+1+γ2Rt+2+…
(11)
式中:Rt为奖励回报函数,γ为奖励衰减因子.
最大期望累积回报为:
Ε[Rt+γRt+1+γ2Rt+2+…]
(12)
定义基于策略π的状态-动作值函数:
(13)
简化为:
(14)
基于Q(s,a)定义强化学习的目标为找到最优的策略π*,使每一个状态的价值最大化,即:
π*=argmaxπQ(s,a),∀s,a
(15)
深度强化学习将深度学习和强化学习相结合,具备解决复杂控制问题的能力[13].深度强化学习TD3算法网络框架如图6所示.TD3算法是一种针对连续行为动作的策略学习方法,采用了行动-评价算法(Actor-Critic,AC)的架构,用深度神经网络去拟合最优状态-动作值函数Q(s,a),其是以DDPG算法为基础的算法[14],具有6个网络.

图6 TD3算法架构
与DDPG相比TD3算法具有的优点:
(1)采用双Critic网络去估算Q值,相对较小的作为更新的目标,防止Q值的过估计;
(2)延迟Actor网络更新,本文中增加了算法的稳定性;
(3)并且在用于计算目标动作值函数的目标动作上添加基于正太分布的噪声,增加了算法的鲁棒性.
2.2 基于TD3算法的控制策略问题建模
基于上述理论基础,选取的控制动作变量为电机的输出功率Pm,状态变量为需求功率Preq、SCR的温度和SOC,目标函数定义为带奖励衰减的累积回报:
(16)
式中:γ为奖励衰减因子用来保证函数收敛,γ∈[0,1];R(t)为奖励回报函数.
强化学习中,奖励回报函数在指导智能体的学习方向上发挥着重要作用,本文中策略的目标是整车油耗和排放的综合指标最小化,因此奖励回报函数定义如下:
R(t)=ω1R1(t)+ω2R2(t)+ω3(SOC-0.4)
(17)
(18)
(19)

系统控制变量为:
U(t)=Pm(t)
(20)
系统状态变量为:
S(t)=[Preq(t),SOC(t),TSCR(t)]
(21)
系统物理约束条件为:
(22)
系统的边界条件为:
(23)
基于上述理论将整车的综合优化问题转化为寻找最优的控制策略π*对应的控制动作序列,将最优状态-动作值函数定义为:
Q*(s,a)=maxπΕ[Jt|st=s,at=a]
(24)
可简化为:
(25)
2.3 基于TD3算法的控制策略问题求解
本文提出的基于TD3算法的PHEV综合优化控制策略原理如图7所示:
基于TD3算法的控制策略的核心是采用深度神经网络来拟合策略函数和动作值函数,分别对应图中的6个网络,即Actor估计网络πω、Actor目标网络πω*、Critic估计网络Qθ1、Critic估计网络Qθ2、Critic目标网络Qθ1*、Critic目标网络Qθ2*,每个网络的作用和更新规则如下:
Actor估计网络πω:负责迭代更新参数ω,根据当前状态St选择当前最优动作At,用于和环境进行交互产生下一时刻状态St+1和立即奖励R;
Actor目标网络πω*:根据下一时刻状态St+1选择最优下一动作At+1;
Critic估计网络Qθ1、Qθ2:根据状态St和Actor估计网络选取的动作At计算动作值函数Q(st,at|θi),并计算出当前Q值梯度传递给Actor估计网络指导最优动作的选取.同时,还负责估计网络参数θi的迭代更新,i=1,2.
Critic目标网络Qθ1*、Qθ2*:根据下一时刻车辆环境动态St+1和最优动作At+1计算目标Q值中的Q(st+1,at+1|θi*)部分,θi*为Critic目标网络的网络参数.
Actor目标网络πω*和两个Critic目标网络的参数更新采用软更新,即每次参数更新都以微小量变化逼近估计网络参数,其表达式为:
(26)
式中:τ为更新系数,且τ<<1,这里取0.001.
Critic估计网络Qθ1、Qθ2通过最小化损失函数来进行参数的迭代更新,损失函数定义为目标Q值与估计Q值的误差平方,表达式如下:
(27)
L(θi)=Ε[(yt-Q(st,at|θi))2]
(28)
其中y(t)为目标Q值,Q(st+1,at+1|θi*)为两个Critic目标网络的输出,选取其中更小的来计算目标Q值,Q(st,at|θi)为两个Critic估计网络的输出,采用自适应矩估计(Adaptive Moment Estimation,Adam)优化算法来最小化损失函数实现值网络参数的更新.
Actor估计网络πω参数的更新需要依据Critic估计网络提供的Q值梯度,其损失梯度定义为:

(29)
式中:∇aQ(s,a|θi)为Critic估计网络的Q值梯度,表示Actor估计网络的动作选取要朝着获得更大的Q值方向移动;∇ωμ′(s|ω)为Actor估计网络的梯度,表示Actor估计网络参数更新要向着加大这个动作执行概率的方向调整.
将Actor估计网络的损失简化为得到的反馈Q值越大损失越小,因此Actor估计网络的损失函数定义为:
(30)
为了提高算法的鲁棒性,在Actor目标网络选择出的下一动作At+1上添加基于正太分布的噪声,同时在Actor估计网络输出的控制动作A上加上随机噪声ε,来保证在训练过程中能学习到更加优化的算法,即:
(31)
μ′(st)=μ(st|ωt)+ε
(32)
其中,ε是添加的随机噪声,服从截断正太分布clip(N(0,σ),-c,c),c>0.
搭建的Actor策略网络和Critic价值网络均采用5层全连接层神经网络,其具体参数如表2所示:

表2 Actor策略网络和Critic价值网络参数
其中Actor策略网络和Critic价值网络的输入层神经元个数分别为3和4,对应系统状态和控制动作.
两个网络的隐含层神经元个数都为30,100,30,使用ReLU激活函数,其输出层的神经元个数都为1,分别对应策略函数μ(st|ωt)的动作输出和动作值函数Q(st,at|θi).
基于TD3算法的综合优化控制策略算法流程如表3所示:

表3 基于TD3算法的综合优化控制策略算法
3 仿真分析
本文将TD3算法应用到PHEV的能量管理控制策略问题中,进行PHEV性能的综合优化控制策略.在NEDC工况下对TD3算法进行训练评估分析,相关参数如表4所示:

表4 TD3算法参数
图8所示为回合累积回报变化曲线,其回报值越大,学习效果越好,可以看出回报值曲线震荡变化,总体呈上升趋势,说明智能体不断调整策略以获得最大的回合累积回报.
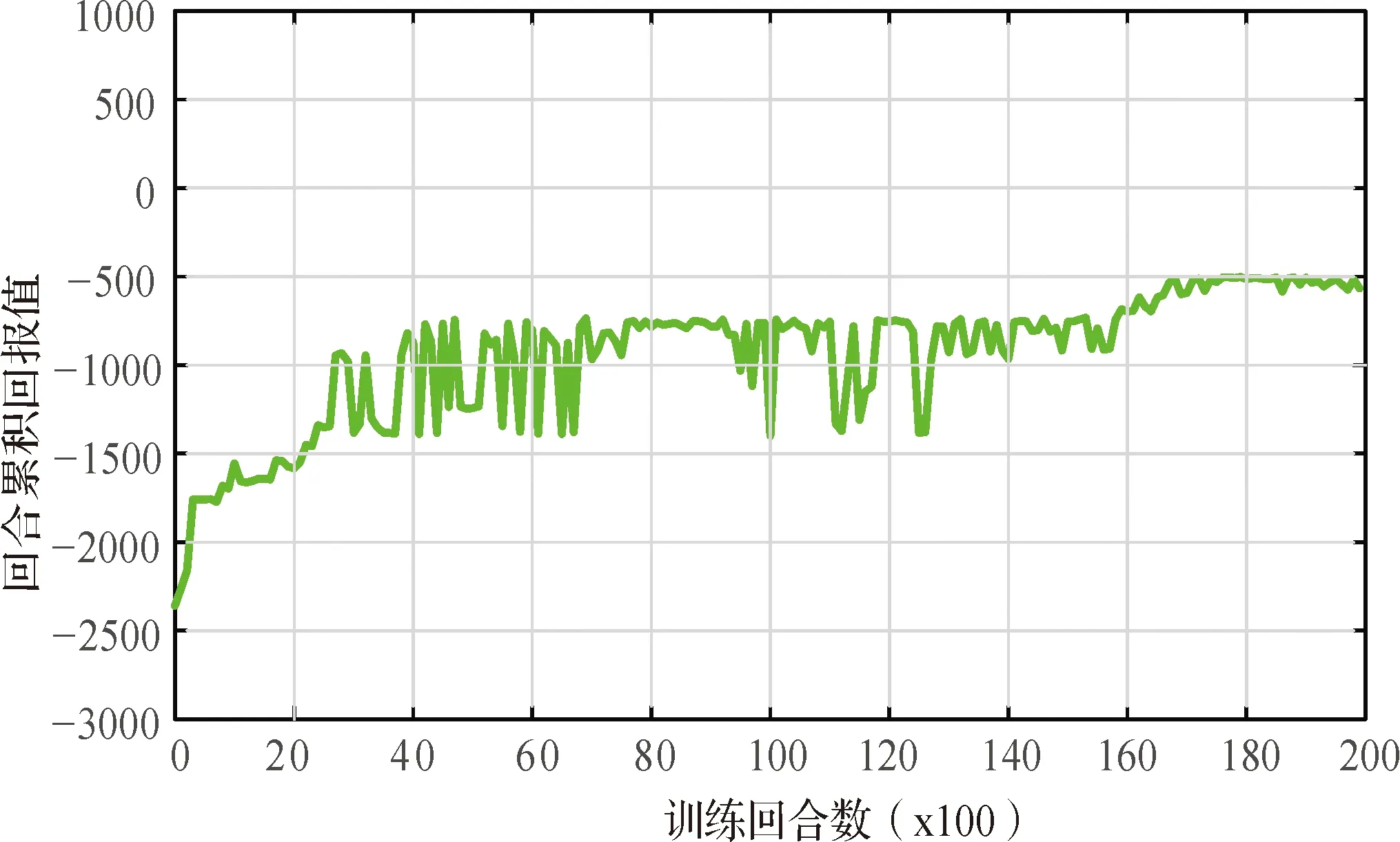
图8 回合累积回报值
图9、图10所示为TD3和DP策略下的SOC变化曲线和电机功率分配曲线,可以看出两种策略在相同工况下SOC的轨迹曲线变化和电机功率分配曲线变化都基本保持一致,说明TD3能得到DP全局最优解的近似解.
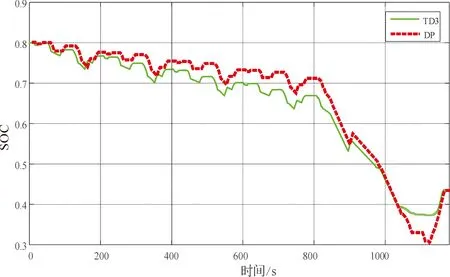
图9 TD3和DP控制策略的SOC曲线

图10 TD3和DP控制策略的电机功率分配
图11、图12所示为在油耗和NOX排放MAP图上发动机工作点的分布状况,可以看出在本文策略下发动机主要工作在中等负荷区域,比较稳定,所以发动机燃油消耗量和NOX排放量相对较低,对应发动机燃油消耗量和NOX排放量为2.477 L/100 km、0.202 8 g/km,分别达到DP控制的94.1%和89.4%.

图11 发动机工作点在油耗MAP图分布

图12 发动机工作点在NOX排放MAP图分布
表5为DP和TD3策略的效果对比,可以看出,提出的基于TD3算法的PHEV控制策略取得了很好的效果.

表5 TD3和DP控制策略仿真结果对比
4 结论
本文为实现PHEV的油耗与排放综合优化的目标,提出并构建了基于深度强化学习TD3算法的控制策略,在NEDC工况下进行离线训练得到最优的电机功率分配情况.仿真结果表明,策略取得了较好的节油和减排效果,其燃油消耗为 2.477 L/100 km,达到DP策略94.1%的效果,SCR催化器出口NOX的排放量为0.202 8 g/km,达到DP策略89.4%的效果,相对DP控制策略具有实时在线应用的潜力.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
民用飞机设计与研究(2019年2期)2019-08-05
山东冶金(2019年3期)2019-07-10
消费导刊(2018年10期)2018-08-20
山东工业技术(2016年15期)2016-12-01
通信电源技术(2016年1期)2016-04-16
汽车与新动力(2015年1期)2015-02-27
