
基于改进Mask R-CNN+LaneNet的车载图像车辆压线检测
2022-04-27 14:42:34孙建波常旭岭
光学精密工程 2022年7期
孙建波,张 叶,常旭岭
(1.中国科学院 长春光学精密机械与物理研究所 应用光学国家重点实验室,吉林 长春130033;2.中国科学院大学,北京100049)
1 引 言
车辆压线检测是指对车辆在行驶过程中轧越实线(白色实线、单黄实线、双黄实线、黄色虚实线)通行的违章行为进行检测,因为车辆压线会占用同向车道或对向车道,造成拥堵、刮蹭甚至事故,危害公众的财产及生命安全[1],因此,基于车载图像的车辆压线检测研究是辅助驾驶乃至自动驾驶技术中环境感知不可或缺的一部分,对于提高自动驾驶系统的可靠性和保障行车安全具有重要意义[2]。
在车载图像的车辆压线检测研究中,车道线的提取和车辆压线判断是关键。车道线检测是车辆压线判断的重要前提环节。其算法大体上分为:基于特征的算法、基于模型的算法和基于深度学习的算法。基于特征的车道线检测方法主要根据车道与周围环境的特征差异再结合其他方法提取车道线。常用的特征包括颜色[3]、灰度[4]、梯度[5]和边缘宽度[6]等,在根据特征识别出车道线的前提下结合Hough变换[7]、粒子滤波[8]或Kalman滤波[9]等进一步提取最终的车道线。这种传统的车道检测算法需要根据不同的街道场景人工手动调节滤波算子和参数,工作量大且鲁棒性较差,当行车环境出现明显变化时,易出现误检、漏检的问题,效果不佳,且对于车道特征的完整性依赖较大,适用性较差。
基于模型的车道线检测方法通过利用道路车道线的先验知识,建立合适的数学模型来描述真实的车道线。为提高对于弯曲车道线检测的适应性,文献[10]提出一种基于Hough变换的分段直线模型,以此检测拟合弯曲车道线,但此算法对于急弯道车道线的检测容易失效。为解决传统Hough变换方法在弯道工况下识别能力不足的问题,文献[11]提出了一种动态区域规划的双模型车道线检测算法,根据“微元”理论进行图像动态细化分区对各区域局部独立识别,利用直线和B样条曲线双模型完成车道线拟合。为解决实际交通场景中光照条件恶劣引起的车道线检测性能降低的问题,Yoo等[12]提出了一种基于梯度增强转换的具有光照鲁棒性的车道线检测算法。然而,这种检测方法在车道线间断或存在遮挡的场景下不能很好地工作,针对具体场景需要建立对应的成像模型,具有较大的局限性。总的来说,这类算法对于特定道路的车道线检测准确性较高,比基于特征的车道线检测算法的鲁棒性强,但是有较强的局限性,计算成本过大,不适应复杂的环境。
与传统算法相比,基于深度学习的车道线检测算法表现出更准确、鲁棒性更强的特性。起初的深度学习算法大部分基于分类器进行车道检测,文献[13]从图像感兴趣区域提取车道线的Haar特征并引入级联的车道线分类器,对车道线进行粗检测,然后借助线段检测器对粗检测结果进行车道线拟合。基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习方法通过强大的表现学习能力将场景理解推向了一个新的水平,但对于具有长结构区域并且可以被遮挡的车道线,仍然表现不佳。针对这一问题,文献[14]提出了空间CNN(Spatial CNN,SCNN),SCNN将feature map的行或列视为层,并顺序地应用卷积、非线性激活和求和操作,形成了一个空间上的深度神经网络,因为空间信息可以通过层间传播来加强,在CNN不连续或杂乱的情况下,SCNN可以很好地保持车道标记的平滑性和连续性;但是其检测速度较慢(7.5 frame/s),实际适用性较差。文献[15]提出了一种自注意蒸馏模块,基于信息蒸馏解决大主干网络对速度的影响,可以聚合文本信息。该方法允许使用更轻量级的骨干,在保持实时效率的同时实现了高性能。类似YOLOv3或SSD的单阶段模型,文献[16]提出了基于锚点的车道检测注意机制,该机制表现SOTA达到了250 frame/s,但以上两种网络难以保证存在遮挡及光线条件恶劣场景下车道线的检测精度,应用场景受限。
现有的压线检测算法大部分基于卡口监控设备获取的固定区域图像进行检测判断。文献[17]根据压线重叠区域特征进行综合判断实现压线检测。文献[18]利用帧数统计判断当前图像的车道线边界状态,然后根据车道线的不同状态分别采用检测车前部的均匀灰度区域和检测车头复杂边界信息的方法,来实现车辆的越线检测。文献[19]针对道路中间的单双实黄线区域,采用相邻两幅图像逐行平均灰度值进行比较的方法实现压线判断。不同于固定卡口图像的压线检测,基于车载图像的车辆压线检测算法可以应用于更加复杂多变的交通场景,但相关研究较少。文献[20]综合利用车道线的几何特征与图像特征,基于小波变换提取车道线区域,提出了一种基于图像掩蔽局部匹配的越线行为判定方法,但该方法易受到非车辆遮挡车道线的干扰,从而造成误判。文献[21]在提取车道线的基础上提出根据车载图像中左右车道线夹角来判断车辆压线的方法,此方法简单易实现,但只限于直线、无大面积遮挡的车道,测试得出的压线车道线的夹角范围对于多车道(三车道以上)路况并不适用。文献[22]利用GoogleNet-FCN语义分割网络来识别车道线和wheel-line线,根据车道线和wheel-line线的交点位置设置阈值判断是否压线,但此方法中最佳阈值的设定取决于不同的压线数据,需要根据不同场景对模型进行针对性训练,泛化能力差。
针对上述问题,本文提出基于改进的Mask R-CNN+LaneNet的车载图像车辆压线检测方法。采用双立方插值取代Mask R-CNN网络中感兴趣区域(Region of Interest,RoI)Align层的双线性插值算法,将特征候选框内的图像缩放为固定大小的RoI feature;改进随机擦除(Random Erasing,RE)算法进行训练数据的增强,强化网络对车辆更多局部特征的认知,提高Mask RCNN对于环境的鲁棒性和检测准确度;将VGG16全连接层卷积化取代LaneNet网络的ENet解码器,以减少参数计算量和内存消耗,提升车道线的检测速度;采用Gamma校正算法根据不同图像的灰度分布自动调节校正算子,以适当扩大图像中高灰度区域的动态范围并提升图像亮度,提高车载图像中车辆车道线的辨识度从而降低漏检率、误检率;最后,结合车辆分割与车道线拟合结果,提出基于简化的RoI图像提取wheel_line和车道拟合直线的方法判断车辆压线。
2 算法原理
2.1 算法总体流程
基于车载图像的车辆压线检测算法分为两个阶段实现,如图1所示。在训练阶段,分别改进Mask R-CNN车辆检测网络和LaneNet车道线检测网络;为了应对实际交通场景下实体或阴影遮挡以及远景小目标带来的漏检问题,通过改进RE算法进行数据增强提升网络对于复杂环境的鲁棒性。在检测阶段,为解决欠曝光或光线不足等对车道线、车辆检测的干扰,改进Gamma算法校正图像,并基于改进的Mask R-CNN,LaneNet网络训练生成的权重模型进行车道线、车辆的提取,最后完成车辆压线的判断。
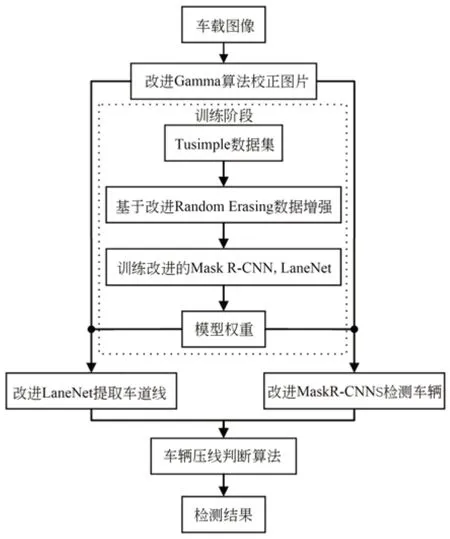
图1 车辆压线检测算法流程Fig.1 Flow chart of vehicle pressing line detection algorithm
2.2 Random Erasing数据增强
在实际交通场景中,车辆会存在阴影或实体遮挡的情况,而Mask R-CNN模型的实例分割建立在其目标检测分支获取预测框的基础上,所以本文参考RE数据增强算法[23],在模型训练过程中,通过随机擦除目标车辆的局部特征模拟不同的遮挡效果,使模型在训练过程中仅通过局部特征识别车辆,强化模型对于车辆局部特征的辨识能力以提高车辆的查全率。
改进后的RE算法流程如图2所示。首先对数据集中的车辆目标进行标注得到标签文件,由标签内容获得车辆在图像中的位置信息,遍历图片中的目标车辆以概率P在其真实框内创建矩形区域,并用图像三通道的平均像素值擦除区域内的像素,最终得到擦除后的图像。其中,Sh,Sl分别是需要随机擦除的矩形面积的上下阈值,r1是矩形长宽比r的阈值上限(r1∈(0,1)),(xe,ye)是擦除区域左下角的坐标。经改进的RE算法处理后的增强图片如图3所示。
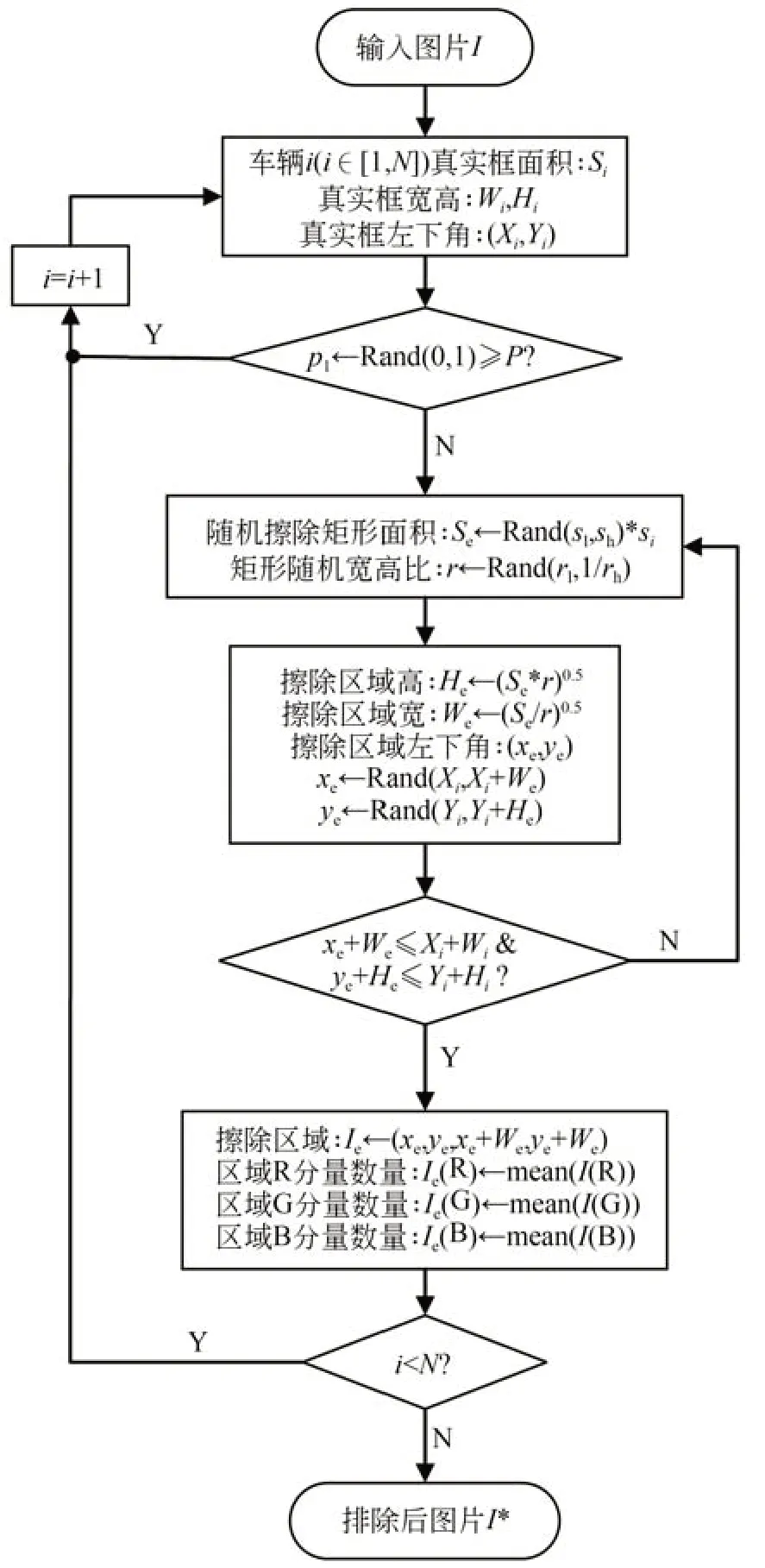
图2 改进的随机擦除算法流程Fig.2 Flow chart of improved random erasing algorithm

图3 随机擦除后的训练图片Fig.3 Training images after random erasure
2.3 基于改进Gamma算法的图像校正
为了提高欠曝光或阴影场景下车道线和车辆检测的查全率和准确率,图像预处理阶段加入改进的自适应Gamma校正算法[24]进行图像正则化处理,步骤如下:
(1)将输入图像从RGB色彩空间转换到HSV空间记为图像I,并提取I的亮度分量IV;
(2)利用双边滤波处理从图像亮度分量IV中提取出光照分量IS,得到(包含空域核和值域核):
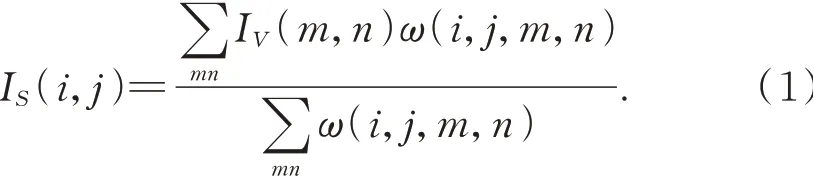
由于双边滤波算法处理图像时考虑了空域信息和灰度相似性,可在尽可能保留车道线、车辆的边缘信息的同时抑制图像噪声,滤波核ω包括空域核和值域核,其数学描述如下:
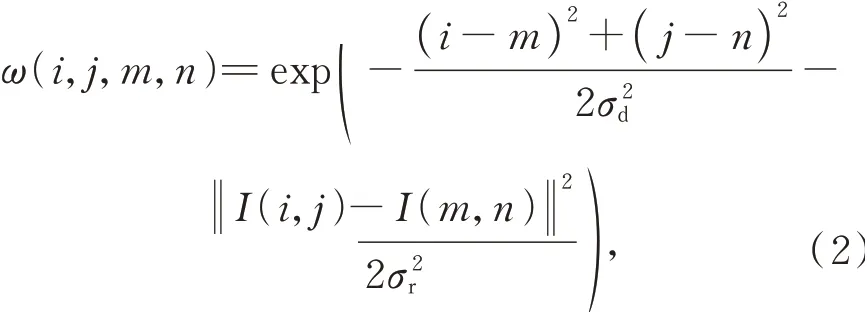
式中:IS(i,j),IV(m,n)分别为坐标(i,j)和(m,n)处的光照分量与亮度分量;σd,σr分别为空间邻近高斯函数标准差和像素值相似度高斯函数标准差。
(3)改进后的Gamma校正算法根据每一像素的光照分量IS(i,j)自适应调整校正参数γ,如下:

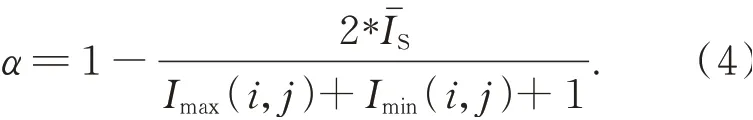
校正后的像素光照分量为:
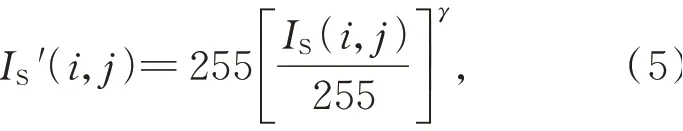
图4为车载图片校正前后的效果、灰度分布直方图和累积曲线。显然通过改进Gamma算法可以增加中高灰度区域的动态范围,改善像素低灰度区域集中的现象,增强车辆、车道线与周围环境的对比,提升了图像的质量。

图4 改进Gamma校正算法效果Fig.4 Effect of improved Gamma correction algorithm
2.4 基于改进Mask R-CNN的车辆检测
Mask R-CNN[25]的整体框架如图5所示。主干特征提取网络Resnet101(结构见图6)提取输入图片不同阶段输出的有效特征图;由于有效特征层的高层特征语义较强,但位置和分辨率较低,不利于小物体的检测,底层特征反之,特征金字塔网络(Feature Pyramid Network,FPN)[26]可以实现底层到高层有效特征的多尺度融合;融合后的多尺度特征经区域建议网络(RPN)[27]得到候选框(RoI);RoIAlign层通过双线性插值将生成的不同尺寸RoI进行区域匹配,即特征图和固定的RoI特征图的像素对应,原图和特征图的像素对应,从而将RoI映射为两种固定尺寸(7×7×256,14×14×256)的RoI特征。
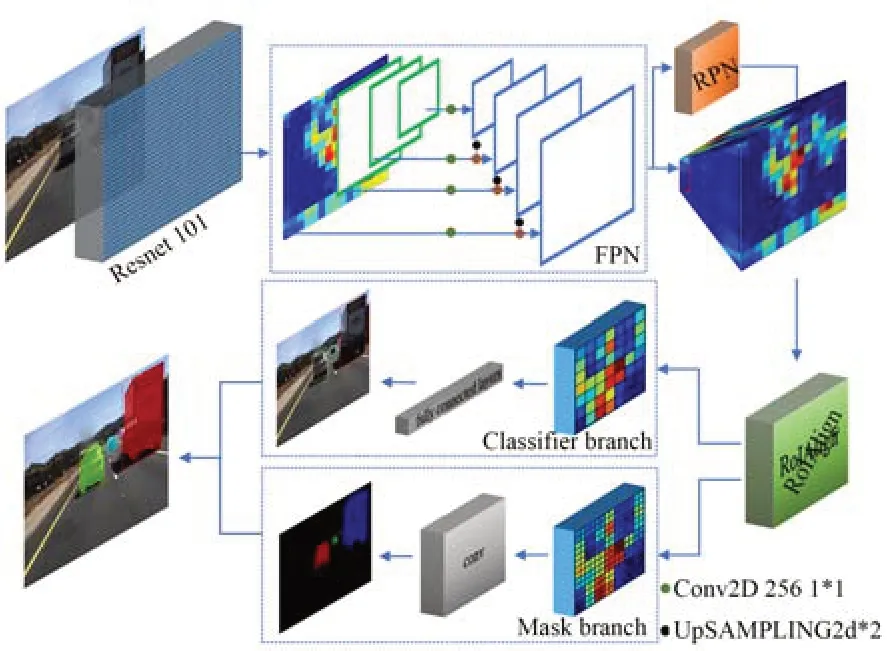
图5 Mask R-CNN整体框架Fig.5 Overall framework of Mask R-CNN
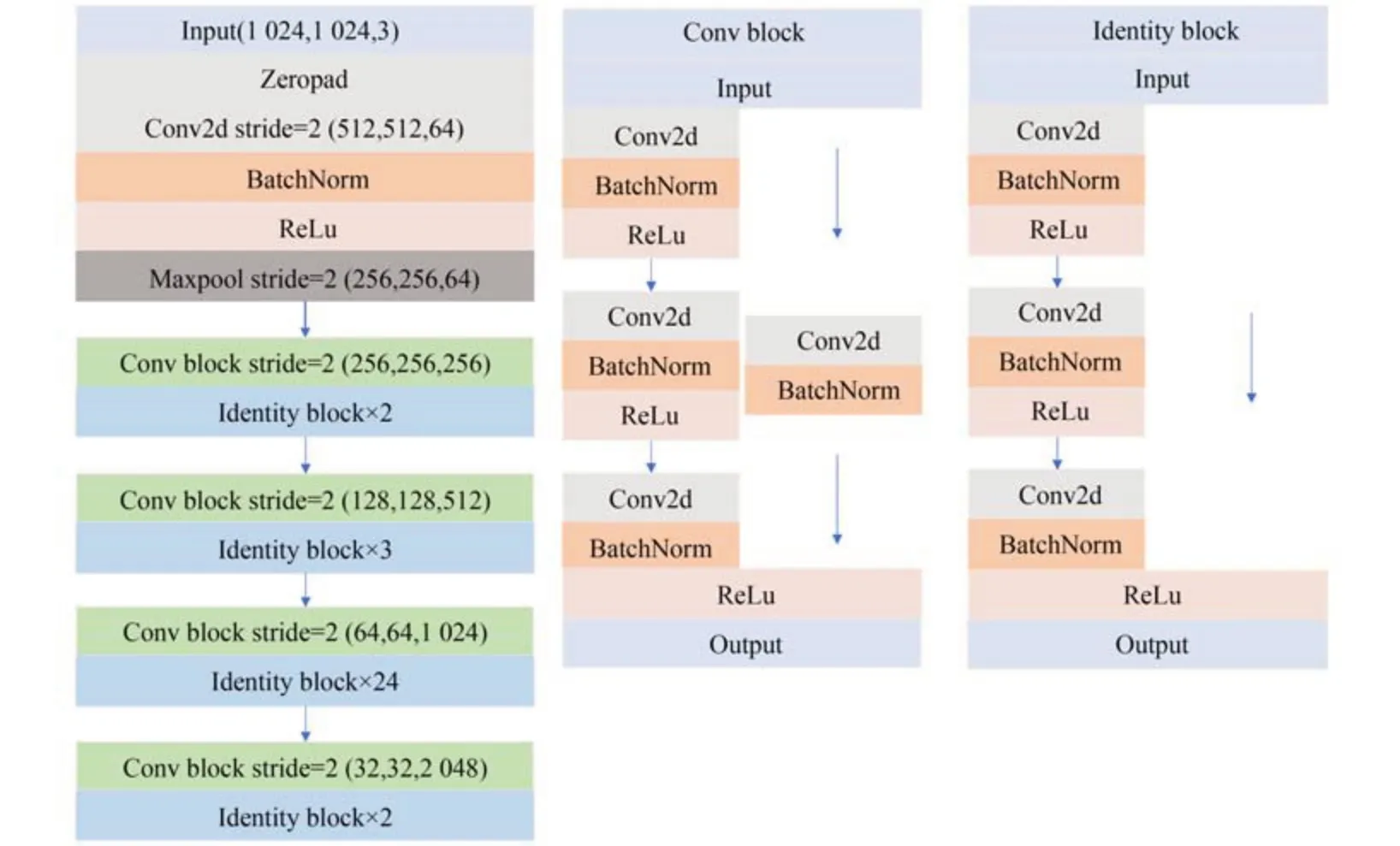
图6 Mask R-CNN主干特征提取网络结构Fig.6 Mask R-CNN backbone networks
如图7所示,目标检测分支利用一次通道数为1 024,大小为7×7的卷积和一次通道数为1 024,大小为1×1的卷积模拟两次1 024的全连接,对RoIAlign获得的7×7×256的RoI特征进行卷积,然后再分别全连接到类别总数(num_classes)和4倍的类别总数(num_classes×4)上(分别代表建议框内的物体、预测框的4个调整参数),实现目标的分类预测和回归预测;实例分割分支首先对7×7×256的RoI特征进行4次3×3的256通道的卷积,再进行一次反卷积提升分辨率、一次通道数为类别总数(num_classes)的卷积,最终输出28×28×num_classes的掩膜板,实现像素级实例分割。
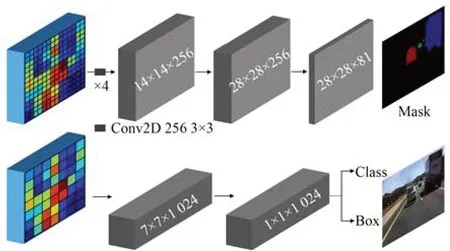
图7 目标检测分支和实例分割分支Fig.7 Classifier branch and mask branch
2.4.1 RoI Align层算法改进
为了从RPN网络确定的不同尺寸的候选框中导出固定大小的RoI特征图,Mask R-CNN模型在RoI Align层采用双线性插值来解决Faster R-CNN模型采用的RoI Pooling操作中两次量化(特征图与原图对应像素的坐标取整,RoI特征图与特征图对应像素的坐标取整)造成的原图与RoI特征图中的像素区域不匹配问题。但双线性插值算法未考虑各相邻像素点点间灰度值变化率的影响,而各邻点间灰度值的斜率不连续会造成缩放后图像的高频分量受到损失,细节信息退化,RoI Align层输出的RoI特征图中的边缘信息较为模糊,进一步影响车辆分割精度和后续的车辆压线判断。
双立方(三次卷积)插值(Bicubic Interpolation,BI)[28]不仅考虑到待插值点周围4个直接相邻像素点灰度值的影响,还兼顾了各相邻点间灰度值变化率的影响,所以利用插值点周围4×4邻域像素的灰度值进行插值,缩放后的图像边缘更为平滑,像质损失更少。故本文采用BI替代双线性插值,提高RoI Align层输出的RoI特征图的边缘质量,以提高车辆检测的精度和车辆的实例分割效果。
根据连续信号采样定理可知,对采样值用理论上最佳插值函数sinπx/πx进行插值,当采样频率不低于信号频谱最高频率的两倍时可以准确恢复原信号。BI核函数sinπx/πx采用的三次近似多项式如下:
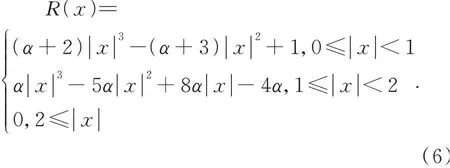
参数α的取值为-1,-0.5,0.25,0.75等。卷积过程的矩阵乘积表示如下:
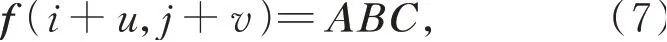
其中:
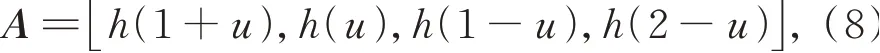
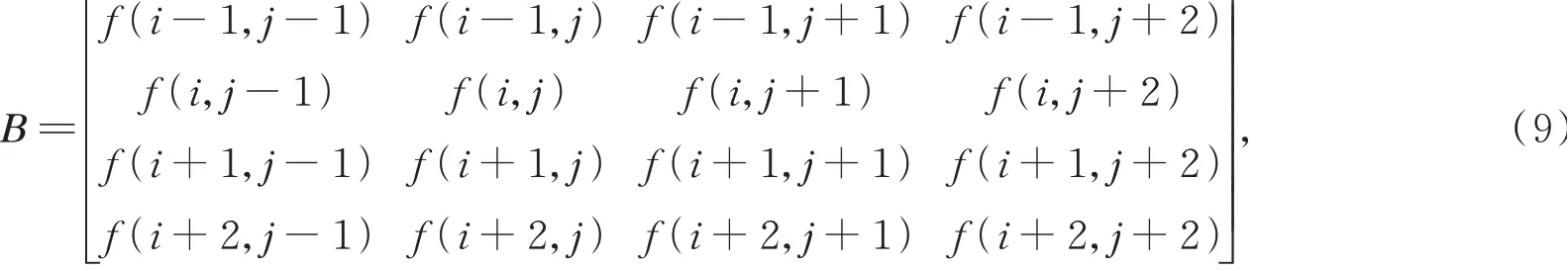
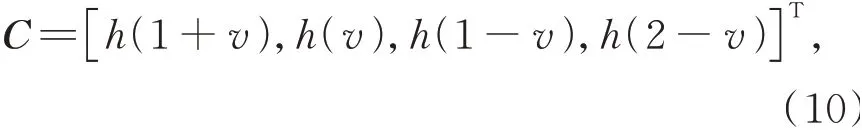
其中:(i,j)表示待求的插值像素邻域中某个像素位置,f(i,j)为对应的灰度值,(u,v)表示待插值点相对(i,j)的位移,即待插值点位置表示为(i+u,j+v),f(i+u,j+v)为待插点的灰度值,h(x)为插值核函数:
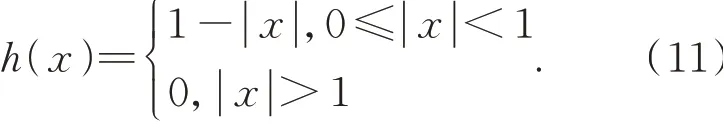
以上插值过程可以用图8表示,实心圆点表示已知原图像像素,虚线圆点是求出的中间插值点,网格圆点为待求的插值像素。
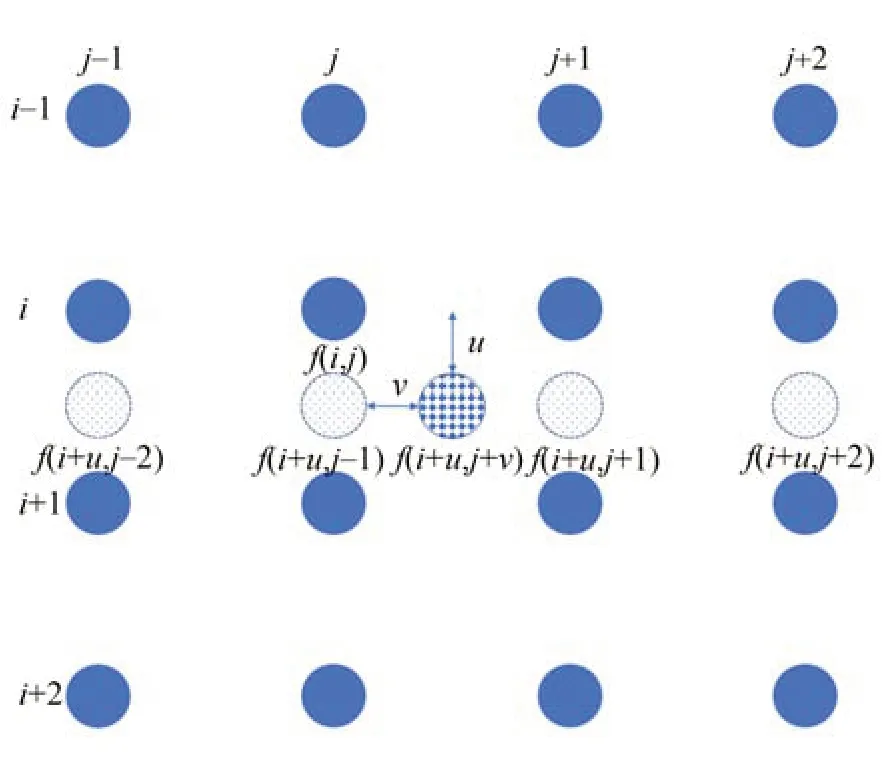
图8 双立方卷积插值过程Fig.8 Bicube convolution interpolation process
2.5 基于改进LaneNet的车道线检测
本文通过改进LaneNet[29]网络的编码器解码器结构实现车道线检测,网络架构如图9所示。图像经过编码器提取到的共享特征分别流入到两个解码器来恢复细节和空间尺度,其中二值分割分支根据交叉熵损失函数生成车道线与背景的二值图像,像素嵌入分支基于聚类的判别损失函数得到区分不同车道线的特征图,对特征图做聚类得到车道线的数量和像素所属的车道线id,结合两分支结果实现车道线的实例分割。神经网络H-Net根据原图片训练出预测变换矩阵H,并利用转换矩阵对同属一条车道线的所有像素点进行重新建模,完成车道线的拟合。
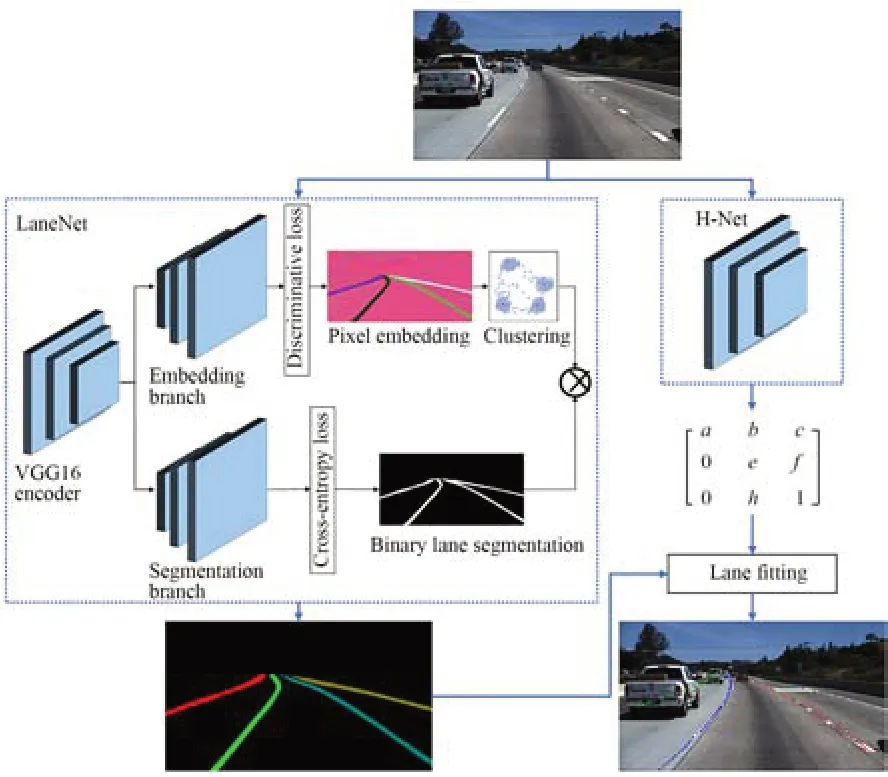
图9 LaneNet车道检测网络架构Fig.9 Framework of improved LaneNet for lane detection
为进一步提升车道检测速度,本文采用改进的VGG16代替原网络中的共享解码器E-Net。VGG16的网络复杂度远少于E-Net,广泛应用于图像分割的特征提取上,将VGG16网络的最后3个全连接层改为卷积层,最后一卷积层中卷积核数量由4 096减少到1 024,以降低参数的计算量和内存消耗;同时编码网络全部采用3×3小卷积核和2×2的最大池化层,相比于大卷积核(5×5或7×7),不仅获得相同的感受野且进一步减少了参数量,达到了更好的特征提取能力,改进的VGG16编码器结构如表1所示。
因为档案的类型具有多样性,不同结构的档案具有不同类型的特征信息,同时信息特征提取方式也有较大差异。笔者认为按照档案特征提取方式对档案进行分类则可以将档案划分为文本类档案和图片类档案两大类,其中音频类档案通过语音识别技术预处理之后特征提取方式同文本类档案,视频类档案通过拆帧处理之后特征提取方式同图片类档案。

表1 VGG16共享编码器的结构参数Tab.1 Architecture parameters of VGG16 shared encoder
2.6 车辆压线判断
如何利用二维空间的车载图像对压线车辆进行检测是本文的关键。本文在改进的Mask RCNN和LaneNet提取出车载图像中车辆和车道线的基础上完成车辆压线的判断,具体步骤如下:
(1)考虑到车载摄像头与目标车辆距离较近,并且车道线的拟合准确度在远景处较差,存在相交现象会干扰压线的判断,故对检测完的图像(10(a))截取RoI区域(图10(b)),其宽度保持不变,高度取为图像底部与拟合的车道线交汇点的距离;

图10 压线判断过程Fig.10 Line pressing judgement process
(2)采用零值像素遮滤掉所有未检测到的图像信息,只保留检测到的与车道线和车辆轮廓相关的特征,得到简化后的RoI图,如图10(c)所示;
(3)根据实例分割结果提取车辆轮廓的点集合,筛选出高度方向上坐标数值最小的两点即为车辆后车轮与地面相切线段wheel_line的两端点,并采用改进的概率Hough[30]变换对RoI内每条车道线上的点进行直线拟合,如图10(d)所示;
(4)分析简化后RoI图中车辆的wheel_line与所有车道拟合线的位置关系,若相交则判断为压线违规。
3 实 验
3.1 数据集及实验环境配置

表2 实验的软件及硬件配置Tab.2 Experimental software and hardware configuration
3.2 实验结果
实验首先基于数据集MS COCO[32]对改进后的Mask R-CNN网络进行预训练,预训练最大迭代次数设置为3 000,初始学习率设置为0.001。为了防止训练陷入局部最优,在迭代2 000次后将学习率调整为0.000 1完成预训练,并选取损失最小的最优权重对网络参数进行初始化;然后在Tusimple训练集上采用批处理的随机梯度下降法重新训练网络,学习率调整为0.000 01,训练轮数设为50,批处理数据量(batch size)设置为4,最终损失函数值在4.6附近小幅波动不再下降,说明模型收敛,完成Mask RCNN网络的训练。同时,利用Tusimple训练集对改进后的LaneNet网络进行训练,训练轮数设置为12 000,batch size为4,训练权值衰减采用L 2归一化,并采用Adam优化器优化训练效率,训练完成后保存损失最小的权重文件用于测试。
然后,分别利用原始网络和改进后的网络在相同的Tusimple测试集中进行检测,采用目标检测中常用的误检率(FP)、漏检率(FN)和每秒传输帧数(FPS)作为Mask R-CNN网络车辆检测以及LaneNet网络车道线检测的性能评价指标。计算公式如下:

式中:Fpred为误判为车道线或车辆的数目,Npred为检测到的车道线或车辆总数,Mpred为未检测到的车道线或车辆数目,Ngt为值标签中的车道线或车辆数量。改进前后两种网络的检测性能比较如表3所示,可见改进后的网络在误检率和漏检率上均大幅下降,车辆漏检率、误检率分别降低了38.93%,89.04%,车道线漏检率、误检率分别降低了67.21%,87.05%,车辆检测速度保持不变,车道线检测速度提升了28%。相比于现有的实 例 分 割 主 流 算 法(BlendMask[33]和YOLACT[34]),本文提出的算法在检测精度上性能更优;相比于现有的车道线检测算法(PINet[35]和Line CNN[36]),本文算法在检测精度和速度上均具有优势。
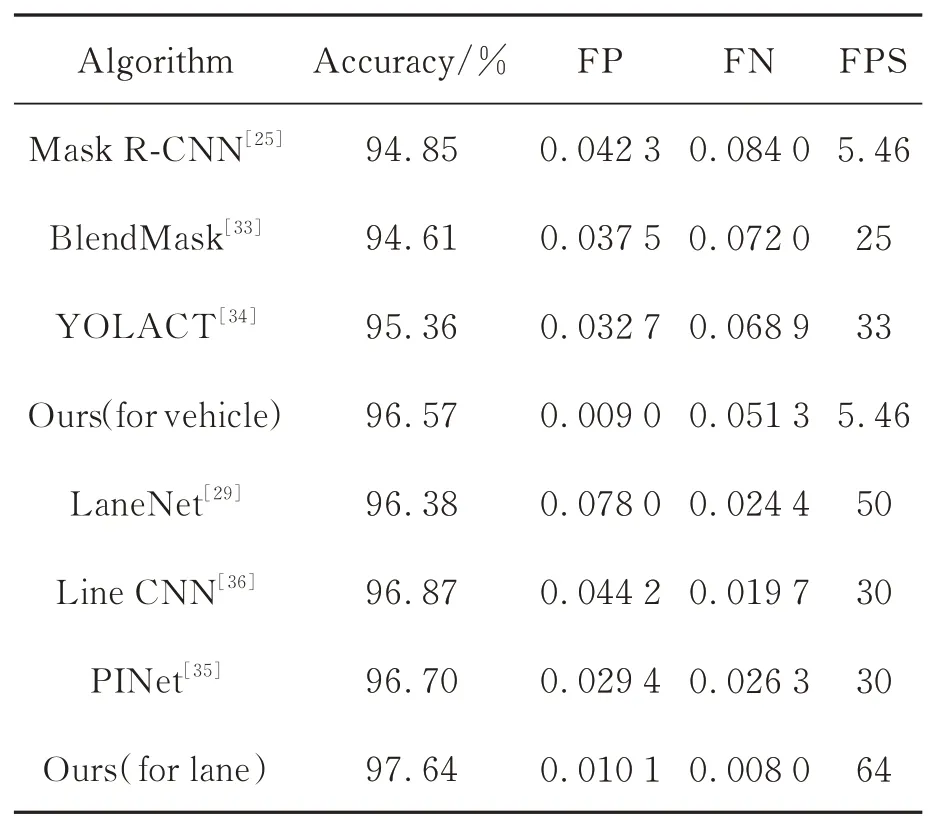
表3 基于TuSimple测试集的算法性能对比Tab.3 Comparisions of algorithm performance on T uSimple testing set
类激活图(Class Activation Map,CAM)是指网络对输入图像生成的类激活的热力图,是与特定输出类别相关的二维特征分数网络。网格每个位置的颜色信息表示对该类别判断依据的重要程度[37](由蓝到红重要程度递减),可以显示模型更侧重于根据哪一部分特征进行类别和目标判别。为验证改进后的RE算法对于Mask RCNN网络识别车辆特征能力的提升,如图11所示,获取有无增强数据训练的网络在不同场景下车辆检测输出的3种网格尺度(13×13,26×26,52×52)的类激活图,为避免干扰,不对输入图片进行Gamma校正预处理。网格尺度小的类激活图反映了网络对于远处目标车辆特征的识别情况,通过对比图11(a2)与图11(a5)及图11(a3)与图11(a6),可以看出图11(a5)、图11(a6)中远处更多的车辆特征被捕捉到,说明采用增强数据训练后的模型对于小目标车辆的检测准确度有所提升。原始网络对于车体存在大面积遮挡的车辆存在无法识别的问题(如图11(b2)与图11(b3)左车道存在的两处被遮挡车辆),改进后的网络增强了车辆局部特征的识别能力,体现在图11(b5)、图11(b6)中,被遮挡车辆的局部特征被激活为其他颜色。阴影遮挡限制了网络对车辆特征的识别(图11(c1)~11(c3)阴影下的车辆特征未被激活),通过数据增强网络,阴影环境的鲁棒性明显提升,如图11(c4)~11(c6)阴影下的车辆特征均被捕捉到。

图11 不同场景下的类激活图Fig.11 Class activation maps in different scenarios
如图12所示,在道路场景1,2中原始网络(Baseline)均存在车辆误检的问题,场景2,3,4中均存在车辆漏检的现象。改进后的网络不仅改善了车辆的误检问题,而且对于欠曝图片中辨识度不高或远景的车辆的检测精度有所提升,场景2,3,4中原始网络漏检的车辆均被改进后的网络召回并检测到。在对4个场景中远景小车辆目标和处于阴影中车辆的检测上,Blend Mask与YOLACT算法都存在不同程度的漏检,本文算法表现出更高的检测精度,而且在场景2,3中,改进后的网络对于车辆边缘的分割效果要优于前两种网络。此外,通过在场景2,4中对比网络改进前后车道线的检测效果,改进后的网络对于车体或阴影遮挡、欠曝、弯曲的车道检测方面鲁棒性有所提升。图13进一步对比了本算法与其他主流算法的车道线检测效果。

图12 车辆检测效果对比Fig.12 Comparison of vehicle detection results
如图13所示,5个场景中的车道线存在欠曝、阴影遮挡和不同程度的缺损,导致原网络存在不同程度的漏检甚至完全检测不到(如场景3),Line CNN存在漏检(如场景1,2,3)和单车道不完全拟合(如场景4,5),PINet存在漏检(如场景1,2,3)、单车道拟合不完全(如场景2,3,5)和误检(如场景4)。本文基于LaneNet改进后的车道线检测算法一方面降低了漏检率和误检率,另一方面,完整的拟合效果为车辆压线判断提供了更加准确可行的前提条件。

图13 车道线检测效果对比Fig.13 Comparison of lane line detection results
4 结 论
本文以Mask R-CNN实例分割算法和LaneNet车道线检测算法为基础,实现了车载图像的车压线检测。通过改进RE算法扩展增强Tusimple数据集并训练Mask R-CNN网络,提升了网络对于阴影或实体遮挡的鲁棒性,改善了原模型在小目标车辆检测上存在的漏检问题;Gamma校正算法根据车载图像的灰度分布自动调整算子,从而扩大中高灰度区域的动态范围、提升欠曝区域的亮度,改善了欠曝图像中车辆及车道线的辨识度,进一步解决了车道线与车辆的漏检误检问题,使得最终车辆的漏检率、误检率分别下降了38.93%,89.04%,车道线的漏检率和误检率分别下降了67.21%,87.05%;采用双立方插值算法改进Mask R-CNN网络中RoIAlign层的双线性插值算法对候选框内的图像信息进行缩放,提高了RoI Align层输出的RoI特征图的边缘质量;将LaneNet的解码器E-Net替换为全连接层卷积化的VGG16,减少了参数计算量和内存消耗的同时车道线检测速度提升了28%,可以满足实时检测的需求;在保证车辆与车道线的检测效率的同时,对车载图像RoI区域进行简化处理,在此基础上提取车辆后轮的wheel_line线段,通过其与车道拟合直线相交点的个数判断有无车辆压线违规,该方法具有一定的可行性。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
卫星应用(2021年11期)2022-01-19 05:13:02
中国建筑金属结构(2021年10期)2021-11-07 00:52:18
科学大众(2021年9期)2021-07-16 07:02:50
中国交通信息化(2020年11期)2021-01-14 03:30:34
意林(2019年17期)2019-10-07 12:28:52
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
上海包装(2018年8期)2018-09-05 08:47:48
文体用品与科技(2016年7期)2016-06-15 06:52:32
