
中国公募基金择时方法比较与择时能力研究
2022-04-26 13:56吴唱唱
技术经济与管理研究 2022年4期
吴唱唱,唐 瑄
(1.北京大学 经济学院,北京 100871;2.北京大学 光华管理学院,北京 100871)
一、引言与文献综述
随着中国金融体制的不断改革和发展,公募基金无论是发行数量还是发行规模都在不断增长,公募基金已经成为中国资本市场的重要组成部分。在这样的历史环境下,对于中国的公募基金研究就显得愈发重要。在西方,由于资本市场起步较早,资本市场制度、投资者的投资理念更加成熟,以公募基金为代表的机构投资者在资本市场中占有大量份额。从20 世纪60 年代开始,就开始有学者对其进行系统研究。
研究公募基金核心的问题在于如何评估公募基金的业绩表现,学者们采用不同方法对其进行测量。Jensen(1968)提出可以通过观察基金的表现来对基金经理预测未来的能力以及减少投资组合风险的能力进行研究,认为基金经理的预测能力应该分为选股能力和择时能力。Gallo&Swanson(1996)使用了Treynor&Mazuy(1966)的择时模型测试了美国的国际共同基金并发现没有基金有显著的择时能力,Jiang 等(2007)得到了同样的结果。
沈维涛、黄兴孪(2001)发现基金经理的择股能力普遍较好,但是否具有择时能力没有得到充分验证。张新、杜书明(2002)的研究认为,中国基金不具有选股和择时能力。邓溯麒和尚宏丽(2008)、吴金旺和贾丹丹(2008)研究结果表明,大部分基金具有较强的选股能力,少量基金具有较强的择时能力。总的来说,国外针对公募基金业绩的研究已经比较成熟,而国内这方面的研究文献还相对较少。同时由于公募基金发展极其迅速,早年的研究无论是从样本量还是数据可得性都存在很多问题,研究得出的结论也不尽相同。因此结论是否可靠需要进一步验证。
据文章收集到的文献来看,还没有文献对于各种针对择时能力测量方法进行统一标准的测试,因此针对每种测量方法的测量准确性还没有一致的结论。因此文章首先参考Jiang(2003)与Cai 等(2018)的方法构造了模拟数据来对各种方法进行测量,结果发现基于日度数据的TM 与HM 模型有着更好的测量准确性。
之后基于Bollen & Busse(2001)的日度数据TM 与HM 模型对于中国公募基金的择时能力进行测试,得出了部分公募基金存在择时能力的结论。在使用Bootstrap 方法调整标准误后择时能力依然显著存在。最后文章分别根据日度TM 与HM 模型的择时指标滚动构造了资产组合,并发现横截面上择时能力高的基金有着正向的资金流入,并且也有着更大的基金规模;在时间序列上,择时能力高的基金在长期比其他基金有着显著较高的收益率。
文章的贡献有:一是通过模拟数据的方法对各种针对基金择时能力的方法准确性进行统一的比较;二是在前人研究的基础上,选取更多的样本,使用Bollen&Busse(2001)的方法,利用日度数据对中国公募基金的择时能力进行研究,并证实了部分中国公募基金是有择时能力的;三是发现择时能力指标能够在横截面上解释基金的正向资金流入,时间序列上能够使用构建的择时指标筛选出较高收益率的基金。
二、方法回顾
文章共搜集到四类关于公募基金择时能力的研究方法:
第一类为Treynor&Mazuy(1966)提出的传统二次项回归模型(TM 模型),回归模型如式(1)所示。
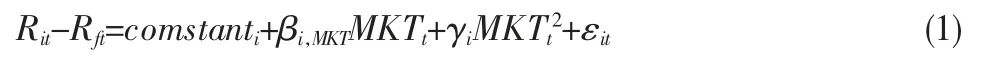
该模型是针对每只基金进行收益率与市场收益率及其二次项的时间序列的回归,其中Rit为i基金在t期的收益率,Rft为无风险收益率,comstanti为回归的截距项,MKTt为t期的市场收益率,MKTt2为t期市场收益率的平方,εit为回归式在t期的残差项,βi,MKT与γi为回归估计的系数。回归式中若γi正向显著,则证明基金存在正向择时能力。
第二类为Henriksson&Merton(1981)提出的二项式随机变量模型(HM 模型),回归模型如式(2)所示。

Rit、Rft、comstanti、MKTt、εit均与(1)中定义相同,MKTt*的定义为MKTt*=max{MKTt,0}。Bollen&Busse(2001)提出由于基金经理调仓的频率大于月度,如果使用月度的收益率对择时能力进行衡量会导致低估其择时能力。由此Bollen&Busse(2001)分别使用TM 和HM 模型使用基金日度收益率对其择时能力进行测试。
第三类为Jiang(2003)提出的非参数回归方法,针对每只基金评估其收益率针对市场收益率的凸性,若以基金的收益率为自变量、市场收益率为因变量的函数为凸函数则其有正向择时能力,若其为凹函数或凹凸性不显著,则其没有择时能力。针对每只基金构建了一个三阶U 统计量来识别其凹凸性。针对i基金构造的统计量如式(3)所示。


第四类为基于股票持仓对基金择时能力进行测试(Jiang 等,2007)。由于存在调仓频率等问题,传统的月度收益率的方法无法准确估计出基金的择时能力。使用按照持仓加权的股票风险暴露得到基金的风险暴露,由此对基金的择时能力进行分析。在传统的TM 和HM 模型中,从式(1)与式(2)可以推导出式(7)。
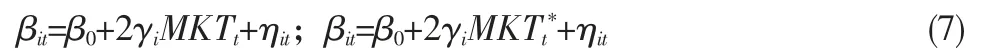
因此TM 与HM 估计γi的本质为每一只基金针对市场风险载荷βit与市场收益率MKTt或市场收益率非线性项MKTt*的线性关系斜率项。但是在实际估计中,是采用基金过去的收益率估计出β0与γi的。由于存在基金调仓较观测收益率频繁等问题,针对这两项的估计不一定准确,即使存在如式(7)这样的线性关系,也有可能估计错误。因此Jiang 等(2007)提出使用式(8)所示的方法对βit进行估计,即β^it。实质上该估计方法是用基金持仓资产的β 加权平均从而获得基金的β。因此式中ωit为权重,而bit为资产的市场风险载荷。

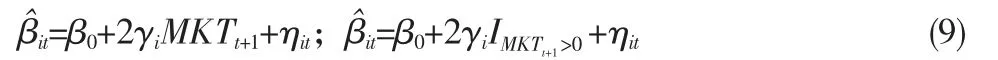
三、数据模拟
文章使用模拟数据的方法对上述提到的四类方法进行检验,根据CAPM 模型各生成有择时能力与无择时能力的100 只基金的模拟数据,通过这四种方法对其择时能力的识别结果,来测试哪种方法的检验力度较高。在模拟过程中参考了Jiang(2003)与Cai 等(2018)的设计。该模拟方法的特点为:一是虽然基金具有择时能力,但是收到的信号有着不一样的噪声,最终导致基金实际表现出无择时能力;二是基金在根据收到的信号进行调仓时,并不会规律地进行调仓,而是根据收到信号的确定程度进行不规则调仓。具体的设定如下所示:
第一,设定总时长T=600,假设每期为一日;

第三,假设市场完美有效,即每只基金的收益来源均为对风险的承担。针对没有择时能力的基金i,其收益率为rit=βirmt+εit,其中εit~N(0,0.02/30),而每支无择时能力的基金针对市场风险的载荷不同,但在时间序列上是相同的,假设βi~U(0.5,1.5)。
第四,针对有择时能力的基金j,其收益率生成表达式为rjt=βjt-1rmt+εjt。与无择时能力基金不同的是,其在t期的收益率rjt会与上一期决定的市场风险载荷βjt-1相关。同时假设其会在t时收到一个关于t+1 时刻市场收益率的信号,信号为未来时间点市场收益率加上标准差为市场因子标准差不同倍数的扰动项(扰动倍数noisej∈[0.5,1,2]),如式(10)所示。具有择时能力的基金会根据收到的信号调整其针对市场风险的风险载荷βjt-1。同时假设基金经理能够知道扰动系数,即基金经理对自己的择时能力有充分的认识。

同样的,假设基金j的初始风险暴露βj,0~U(0.5,1.5)。在随后的时间中,假定基金经理有不同的风险偏好,分别设定λj∈[0.1%,1%,10%],即稳健型、中等型与激进型。当且仅当基金经理有充分把握下一期市场收益率显著不同于期望收益率时,才会调整其风险暴露。由于市场的期望收益率与方差以及基金经理收到信号中扰动项的方差是公开信息,因此基金收到一个信号后,能够根据已有的信息算出其与期望收益不同程度的置信度。如式(11)所示,t期根据收到的信号yjt与市场收益率E(rm)、市场收益率方差与干扰系数noisej能得到z统计量zjt。
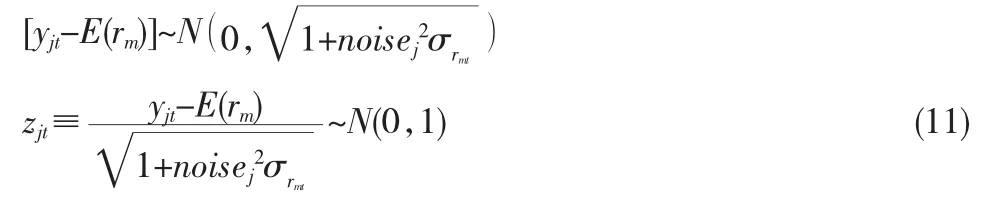
之后基金根据z统计量的大小与自己的风险偏好对市场的风险暴露βjt进行调整。当基金经理收到确定的信号下一期市场收益率大于期望市场收益率时,会将市场的风险暴露调整为初始值的2 倍;同理,若下一期市场收益率小于期望市场收益率时,其风险暴露为初始值的0.5 倍,如式(12)所示。其中假定基金经理有不同的风险偏好,分别设定λj∈[0.1%,1%,10%],即稳健型、中等型与激进型。

图1 为按照上文所述办法分别生成一组有择时能力(λj=0.1,noisej=0.5)的基金收益率与无择时能力基金收益率的βt与市场收益率rmt的关系。左图为有择时能力的基金,右图为无择时能力的基金。从图中可以看出有择时能力基金的beta会以β0为基准而变动,而无择时能力基金的风险载荷βt是一个常数。

图1 模拟β 数据
表1 为按照不同的noisei与λi生成的针对有择时能力的基金调仓的描述性统计。其中λi与noisei代表不同的风险偏好与择时噪声,Change_time 指基金调整其βi的次数,Corr 为βi与市场收益率rmt的相关系数,这个系数衡量了基金调仓方向的准确性。可以看到的是随着风险偏好的增加,基金调仓的次数逐渐减少,由于调仓次数的减少,基金的风险载荷βj与市场上收益率的相关系数逐渐降低。同时随着收到信号噪声的增加,基金调仓的准确性也随之降低。
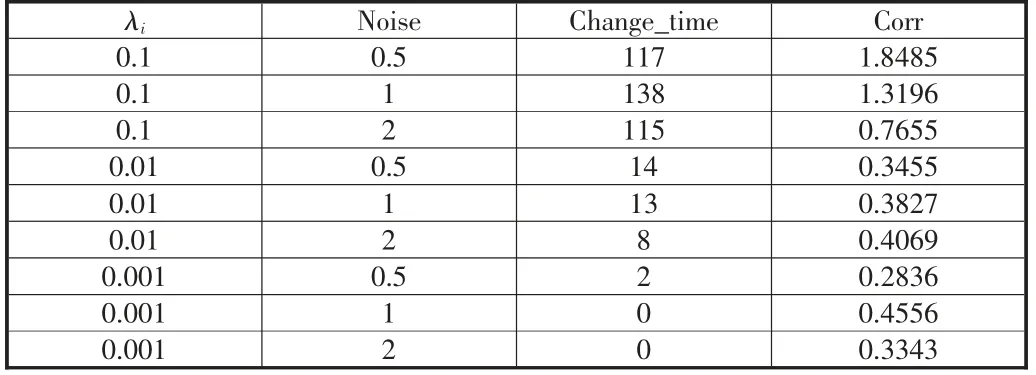
表1 模拟数据场景分析
在模拟中,为检验Jiang 等(2007)提出的基于持仓获得β 测试基金择时能力。文章使用模拟时为生成基金收益率而生成的真实βit时间序列代入式(8)。同时文章也模拟了月度收益率的情况,文章设定1 个月为30 天,将日度的收益率通过式(13)进行月度聚合,并针对选择每月末的betait代入式(8)进行分析。

模拟的结果如表2 所示,文章使用t值1.96 作为显著性评判标准,若评估择时能力的系数t值大于1.96,则文章认为该模型对此基金识别为有择时能力。Panel A 为日度数据的测试结果,最左边一列代表着不同的风险偏好λ 与择时噪声系数noise;表头中TM,HM,Jiang,Beta 分别代表着使用Treynor&Mazuy(1966),Henriksson&Merton(1981),Jiang(2003、2007)提出的测试择时能力的方法。每一单元格中的数字代表在对应的情境与对应的模型中为100 只基金中正确识别的比例。可以看到,在日度数据中,若基金经理为激进型(λi=10%),而且其能够较准确地收到下一期市场收益率的信号(noise=0.5),基于日度数据的TM 模型和HM 模型都能较准确地识别出基金经理的择时能力。识别的正确率分别为84%与81%。随着信号中扰动项方差的增加,识别的概率也随之下降。随着基金经理更加谨慎,其收益率与市场的风险暴露更加倾向于一个常数,从结果上来说也导致了无法展现出择时能力。从正确地识别非择时能力来看,基于TM 和HM 模型无论在何种情境下都能准确地识别出无择时能力的基金。识别的准确率均在95%以上。Jiang(2003)的方法在日度数据中无法准确地识别出择时能力,由于其判断择时能力的方式是对基金收益率与市场收益率函数的凸性进行判断。而这里的日度数据可能存在大量噪声,对其凸性的判断进行了误导(原文中使用的是月度数据)。Jiang 等(2007)的方法在日度数据中判断不准确,正确识别择时能力的比率均小于20%,同时识别非择时能力的比率也仅在60%~80%。

表2 数据模拟结果
Pannel B 为月度数据的数据模拟,总的来说识别的效果均不如日度数据。从TM 与HM 模型来看,两者正确识别有择时能力的基金的正确率极低,但是相对能正确识别出非择时能力的基金。这也证实了Bollen&Busse(2001)所提及的,基金换仓频率与收益率的观测频率不同会导致评估基金择时能力时的低估。Jiang(2003)的方法从测试结果上来说针对风险和噪声的影响较为稳健,这也与原文的结果相符,但是其正确识别率最高仅为62%,同时在无择时能力的一些情境中识别正确率为0,这使得使用该方法无法区别基金是否有择时能力。Jiang 等(2007)的方法在是月度数据中依然无论是对于有择时能力基金还是无择时能力的基金的识别正确率均较低。在模拟数据中,其使用的β 为真实的β,而在现实的测试实施中,其还需要面对针对基金β 估计的误差。因此在实际操作中,该方法的误差会更高。
综上所述,文章认为基于日度数据的TM 与HM 模型在模拟数据中的测试准确性最高。不过从测试结果中也能看到,基于日度数据的TM 与HM 模型对于基金的择时能力是偏低的。
四、数据来源与实证方法
数据模拟对择时评估方法进行对比后,文章选用识别准确率最高的基于日度数据的TM 与HM 方法对中国的公募基金择时能力进行研究。
文章用以计算日收益率的开放式基金的日单位净值(NAV)来自wind 数据库。数据期限是2003 年1 月1 日至2020 年12月31 日,由于文章主要研究基金的择时能力,与Bollen &Busse(2001)类似,首先基金样本为开放式基金中的股票型基金与混合型基金①分类依据为证监会自2014年8月8日起施行的《公开募集证券投资基金运作管理办法》。;其次文章也删除了股票型基金中属于被动指数类型②分类依据来自wind,分类主要依据为基金招募说明书中所载明的基金类别、投资策略以及业绩比较基准。的基金,仅保留投资于大陆股票市场的基金,针对分级基金,由于分级基金风险与收益特征相同,文章将各分级基金删去,仅保留母基金。最终文章形成了时间跨度为2003 年1月1 日至2020 年12 月31 日共计4372 只基金的样本③具体做法为在wind数据库中加入非被动指数型的股票型基金、混合型基金以及基金状态中为已清算与已摘牌的基金,再根据其基金类别进行二次匹配与筛选。。
文章采用Bollen & Busse(2001) 的方法计算每日基金收益率,同时加入拆分与分红的调整如式(14)所示。

其中,rt为需要计算的t日的每日收益率,NAVt为t期的基金单位净值,Divt为基金在t期的分红;SFt为根据基金拆分数据构建的累计拆分因子,如果t期发生比例为st的拆分,则SFt=stSFt-1。
由于极少情况时开放式基金会出现大额的申购和赎回,此时大量的申购赎回费用会显著影响基金的日净值,从而导致计算出的日收益率出现少数极端值情况,因此文章对基金的日收益率作了1/1000 分位的winsorize 处理。
文章所用因子数据来自Liu 等(2019)的研究。样本基金的描述性统计如表3 所示。

表3 描述性统计
Pannel A 为全体样本基金的日度收益率的描述性统计,可以看到收益率有着负偏度和正峰度。使用JB 正态测试法得出值为6698.9858,拒绝了该收益率分布为正态分布的假设。由此使用一般估计的标准误差可能会对择时能力估计错误。因此文章随后使用了Bootstrap 方法对其标准误进行调整。
与Bollen&Busse(2001)的做法相同,文章使用TM,HM 以及factor-TM,factor-HM 四种时间序列计量模型对基金的择时能力进行度量,针对两种因子模型,由于文章主要研究股票型基金,因此文章选用Liu 等(2019)中的CH4因子对原式进行调整。四种计量模型除式(1)与式(2)外,加入了如下两式,其中MKTt*=max{MKTt,0}。
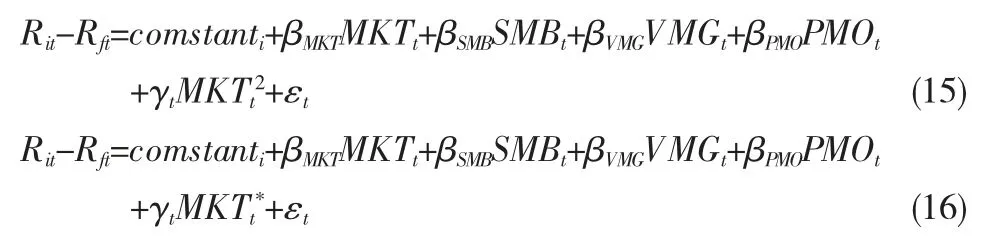
Brown 等(1996)提及基金经理会根据实时的市场情况改变投资策略;Busse(1999)也提供证据说明基金会根据市场的波动性来改变其投资组合针对市场的暴露;以及如表4 所示,基金的日收益率存在非正态性。在这种情况下标准的方差协方差矩阵无法准确估计出系数的标准误,文章采取了Freedman&Peters(1984)提出的bootstrap 对标准差和t 统计量进行修正。
五、实证结果
文章首先针对样本内的4372 只基金,时间序列上分别进行TM、TM-factor、HM 与HM-factor 模型的回归,根据其在市场收益非线性项的系数γ 判断其是否具有择时能力。在显著性上,当γ 的t值大于1.96 时,则认为该基金有着显著的择时能力,回归结果如表4 所示。
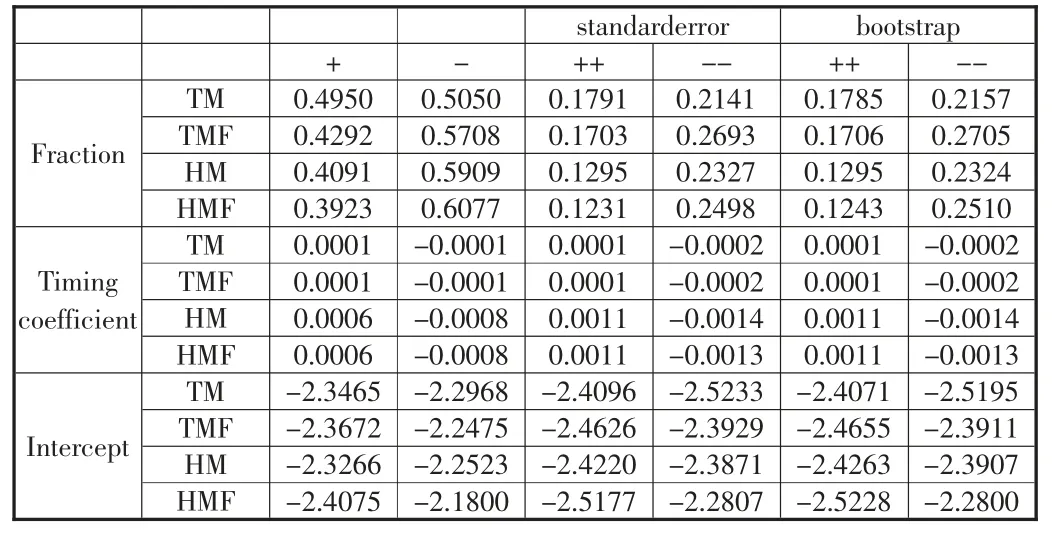
表4 择时能力测试结果
表头的+,-,++,-分别对应正γ,负γ,显著为正的γ与显著为负的γ。standarderror 与boostrap 分别为标准误与Bootstrap 调整后的标准误下算出的显著性。左侧的Fraction、Timing coefficient 与Intercept 分别对应该列下的比例、平均的γ,以及截距项。TM、TMF、HM 与HMF 分别对应着使用TM、TMfactor、HM 与HM-factor 模型进行回归所得参数。可以看到分别根据TM、TM-factor、HM 与HM-factor 模型在所有的基金中有17.91%、17.03%、12.95%、12.31%比例的基金是有择时能力的。但是同样可以看到反向择时的基金分别为21.41%、26.93%、23.27%、24.98%。在通过bootstrap 调整标准误后,大体趋势相同。由前文模拟数据测试所得结果与实际测试结果来看,至少存在一部分基金是有择时能力的,他们能够预测市场的收益率,并根据市场收益率对其持仓针对市场风险的暴露进行调节。这在另一方面也说明了中国的市场收益率是可被预测的。
文章也对择时能力公司的特征进行了研究。使用TM-factor与HM-factor 模型在每一年年末对每只基金使用过去一年的日度数据对其择时能力系数γ 进行了估计,并根据该系数的分位数将基金分为5 组,然后分别在组内构建等权重资产组合与等市值资产组合对其特征进行分析,结果如表5 所示。表中针对各基金资产组合过去一年的收益率、资产规模、资金流入与基金成立年限进行分析。表格分为Pannel A 与Pannel B,分别为使用TM-factor 与HM-factor 模型使用过去一年估计除择时能力系数进行分组。

表5 构造资产组合横截面分析
第一个分析的指标是monthly_return,即构建的5 个资产组合在2003—2018 年每月的收益率时间序列上的均值与标准差。可以看到无论是等权重资产组合还是市值加权资产组合、TM-factor 或HM-factor 模型横截面而言,高择时能力的基金资产组合并没有显著更高的收益率;
第二个指标是log(tna),即每年年末的资产组合资产净值均值的对数,再在整个时间序列上所求的平均数与之标准差。可以看到使用TM-factor 模型估计出High-Low 资产组合的均值为0.0766,HM-factor 估计出均值为0.1136,这说明在横截面上高择时能力的公司在年末会有着更高的资产;
第三个指标为fund_flow,单位为亿元。可以看到分别根据TM-factor 和HM-factor 模型估计出高择时能力的资产组合平均比低择时能力资产组合的现金流入多3.059 亿元与3.5458 亿元,即高择时能力的资产组合在过去一年流入的资金显著高于低择时能力的资产组合。因为高择时能力基金资产能够吸引更多现金流入,因此有着更高的期末资产净值。
最后针对该择时能力是否能预测未来收益率也进行了研究。因为择时能力是基金经理针对未来市场收益率的预测而带来的,可以假设择时能力强的基金可能存在着能获取更高收益率的技能,因此应该能使用择时能力指标筛选出获取更高收益率的基金。在每月月末使用基金过去一年的日度收益率分别使用TM-factor 模型与HM-factor 模型对其择时能力进行滚动评估,并使用评估的择时能力系数γ 的5 分位数对基金进行了分组,构建等权重资产组合,并分别计算未来6 个月、12 个月、24 个月与36 个月的收益率进行分析。结果如表6 所示。表格的Pannel A 与Pannel B 分别代表着使用TM-factor 与HM-factor模型估计系数进行分组,行名中的Low-High 代表着使用γ 进行分组,列名代表着未来的收益率。可以看出在TM 模型中随着预测区间的增加,High-Low 资产组合的收益逐渐增加,到36 月时High-Low 有2.24%的收益率差,使用HM-factor 模型所估计的High-Low 资产组合的均值也大体呈现逐渐增加的趋势,但是始终并没有显著的区别。
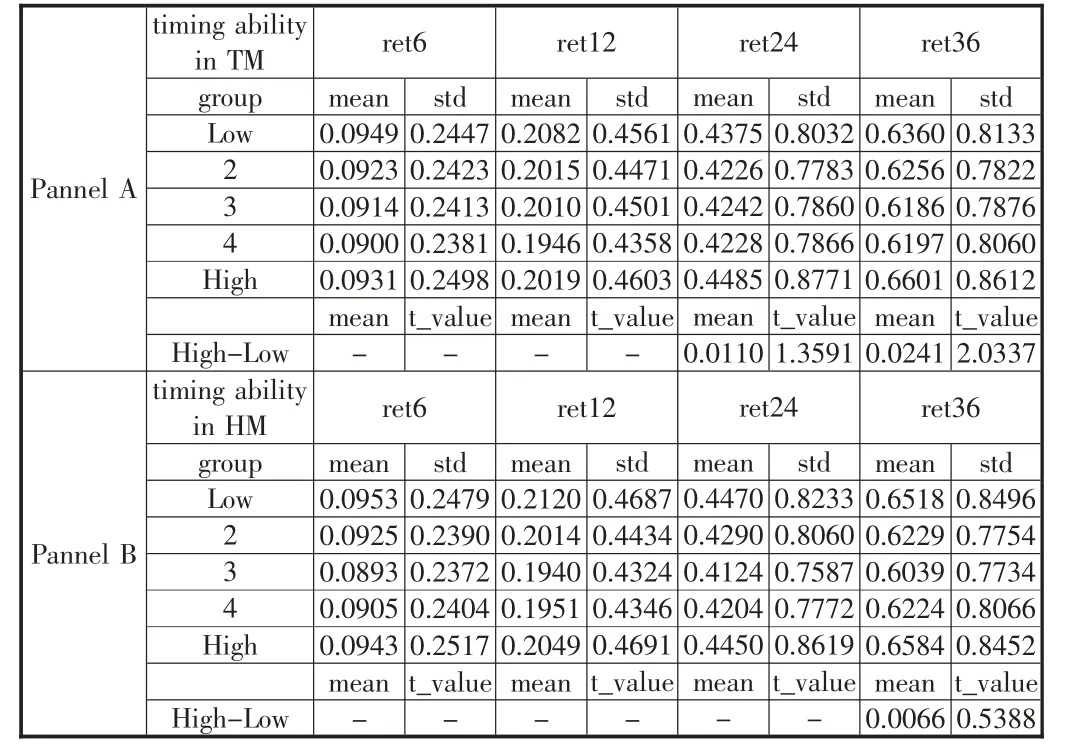
表6 收益率预测分析
六、结论与政策启示
文章通过分析中国公募基金的择时能力试图对公募基金业绩以及资本市场增进了解。首先针对基金择时能力方法的选择,通过数据模拟的方法比较了文献中存在的四种针对公募基金择时能力方法,认为基于日度数据的TM 模型与HM 模型有着对于公募基金择时有着较高的判断准确性;其次针对中国公募基金择时能力,选用基于日度数据的TM 模型与HM 模型对中国公募基金择时能力进行评估,收集了中国股票型与混合型4372 只基金的日度数据,发现存在部分公募基金有着显著的择时能力,这样的择时能力在使用bootstrap 调整了标准误之后依然显著;最后针对择时能力对公募基金的特征进行研究,发现有着更高择时能力的公募基金横截面上有更高的资产净值,并且有着更多的资金流入。同时发现依照TM-factor 模型构造变量能够在未来3 年时间跨度里微弱地筛选出表现更好的基金。
根据以上结论,得到如下两点启示。第一,从结论来看,部分公募基金对市场收益率有着显著为正的择时能力。这可能是因为中国资本市场发展还不够完善,市场有效性不足,导致基金能够通过技术面或基本面等分析方法对市场收益率进行有效的判断。金融市场监管机构应该继续加强投资者教育,提高广大投资者的投资知识与技能,提高资本市场有效性;第二,基金的择时能力有利于筛选出有更高收益率的指标,这表示有更高择时能力的基金能够给投资者带来更高的收益率。这部分地说明了中国的公募基金市场还处于不断发展与完善的窗口期,政府应该对公募基金的发展给予更多的引导和支持,加大机构投资者在中国资本市场的参与度。
猜你喜欢
学生天地(2019年33期)2019-08-25
小学生学习指导(中年级)(2018年4期)2018-09-06
小学生作文(中高年级适用)(2018年4期)2018-05-14
债券(2016年11期)2017-01-12
债券(2016年11期)2017-01-12
债券(2016年10期)2016-11-28
债券(2016年10期)2016-11-28
现代企业(2015年6期)2015-02-28
投资与理财(2009年21期)2009-11-17
投资与理财(2009年18期)2009-09-30
