
基于视觉的火灾检测研究
2022-04-26 03:24:06缪伟志陆兆纳王俊龙王焱
森林工程 2022年1期
缪伟志 陆兆纳 王俊龙 王焱







摘 要:为解决传统传感器在检测火灾的过程中受到环境、安装距离等因素影响导致适应性差的缺点,本文基于视觉传感器,通过视觉目标检测技术对火灾进行检测,从而实现火灾的预警。首先,为了提高轻量级的目标检测网络(You Only Look Once v4 Tiny, YOLOv4-Tiny)在检测火灾目标时的准确率,本文基于森林火灾的数据集,运用二分K-Means聚类算法重新生成锚定框(Anchor Box)。然后,在传统YOLOv4-Tiny网络的基础上通过增加大尺度预测结果的方式,降低漏检率。最后,本文结合预训练权重重新训练火灾检测网络,并在英伟达板卡上进行部署实验。实验结果表明,本文的火灾检测网络在测试数据集上的准确率为97.81%,漏检率为4.83%,与原始YOLOv4-Tiny相比,准确率提高了3.13%,漏检率降低了6.44%,检测速度达到了16帧/s,综合性能良好,满足火灾检测的需求。
关键词:火灾检测;YOLOv4-Tiny;二分K-Means;锚定框;多尺度预测
中图分类号:S762.2 文献标识码:A 文章编号:1006-8023(2022)01-0086-07
Fire Detection Research Based on Vision
MIAO Weizhi, LU Zhaona, WANG Junlong, WANG Yan
(School of Automotive Engineering, Nantong Institute of Technology, Nantong 226002, China)
Abstract:Aiming at the disadvantage of poor adaptability of traditional sensors due to factors such as environment and installation distance in the process of detecting fires, this paper detected the fire through visual target detection technology based on visual sensor, so as to realize fire warning. Firstly, the binary K-Means clustering algorithm was used to regenerate the Anchor Box to improve the detection accuracy of the lightweight target detection network (You Only Look Once v4 Tiny, YOLOv4-Tiny) according to dataset in this paper. Then, the large-scale prediction results were added on the basis of the traditional YOLOv4-Tiny network to reduce the missed detection rate. Finally, combined with the pre-training weights, fire detection network was retrained and deployed on NVIDIA board. The experimental results showed that the accuracy rate of the fire detection network in this paper was 97.81% and the missed detection rate was 4.83% on the test data set. The accuracy rate had increased by 3.13% and the missed detection rate had been reduced by 6.44% compared with the original YOLOv4-Tiny. The detection speed had reached 16 frames per second. The overall performance was good and met the needs of fire detection.
Keywords:Fire detection; YOLOv4-Tiny; binary K-Means; Anchor Box; multi-scale prediction
0 引言
無论是森林火灾还是室内火灾都会带来了巨大的损失,特别是在我国东北林区。如何及时准确地检测火灾的发生,并向相关人员发出预警信号,对于降低人民群众的生命财产损失具有重要的意义。在火灾检测方面,传统的传感器通过火灾产生的烟雾、温度等特征检测火灾,该方法对火灾产生的环境以及传感器与火焰的距离都提出了较高的要求[1-2]。因此,该方法并不适用于各种场景下的火灾检测。随着摄像头的普及,通过视觉目标检测技术检测火灾能够有效克服传统传感器的缺陷,能够运用于各种场景。
在利用视觉目标检测技术实现检测火灾的过程中,主要分为2种方法。一种是通过手工提取图像中火灾目标的特征,再运用各种分类算法对提取的特征进行分类[3-4]。Horng等 [5]通过研究图像中火灾目标在HIS色彩空间上的特征实现火灾的检测;Treyin等 [6]通过研究图像中火焰的特征实现火灾的检测;Chen等 [7]提出了一种基于多特征融合的火灾检测方法,该方法通过将高斯混合滤波与火焰颜色滤波相结合的方式实现火灾检测。上述这种通过手工提取特征,再结合分类算法的火灾检测算法在抗干扰方面表现较差,检测准确率也得不到保证。另一种是基于深度学习的火灾目标检测算法[8-10]。与传统手工提取特征的方法相比,深度学习在目标检测领域具有抗干扰能力强、准确率高的优点。目前基于深度学习的目标检测算法主要分为2类,一类是以R-CNN(Regions with CNN features)系列[12-14]为代表的两阶段的算法,该算法将目标检测的过程分为2步,首先通过卷积神经网络获取可能包含目标的感兴趣区域,然后再利用卷积神经网络在这些感兴趣区域上回归出目标的位置;另一类是以YOLO(You Only Look Once) [15-17]、SSD(Single Shot MultiBox Detector)[18-20]系列为代表的单阶段的算法,该算法不产生可能包含目标的感兴趣区域,因此在检测速度上远远优于上述两阶段的算法,在实际工程中得到广泛的运用。Bochkovskiy等 [21]于2020年提出的YOLOv4在众多单阶段的算法中表现出良好的准确率和实时性。YOLOv4-Tiny作为YOLOv4的一种轻量级网络完美地继承了YOLOv4的优点,并且由于其参数数量较小,更适合在各种嵌入式设备上进行部署。
综合上述分析,本文以YOLOv4-Tiny网络作为基础,结合火灾发生的特点,通过改进YOLOv4-Tiny的網络结构搭建火灾检测网络,并在嵌入式设备上进行部署实验。
1 YOLOv4-Tiny基本结构
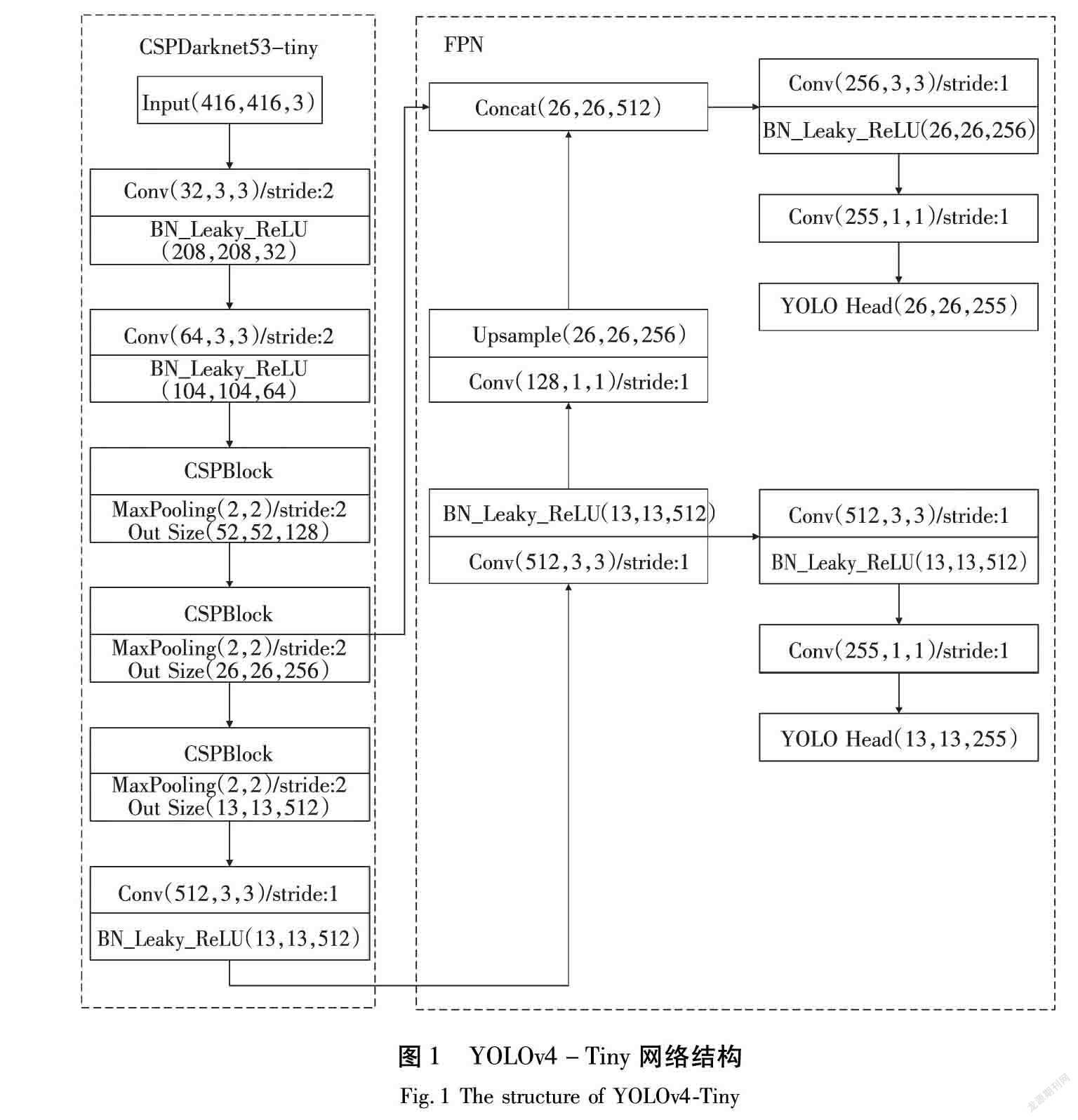
作为YOLOv4的轻量级版本,虽然YOLOv4-Tiny的网络结构较小,但是完美地继承了YOLOv4的优点,YOLOv4-Tiny网络的结构如图1所示。
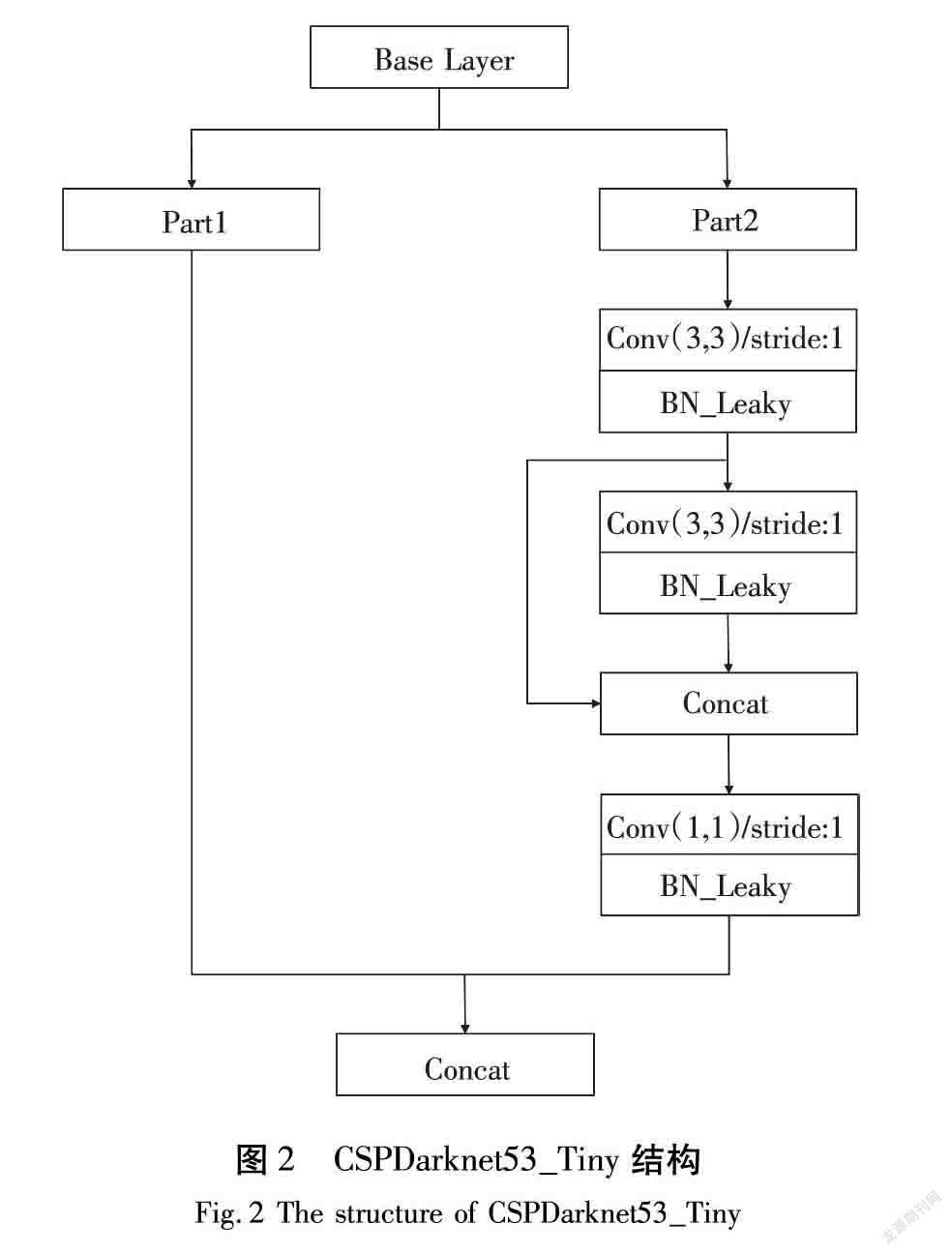
在YOLOv4-Tiny网络中主要分为2个部分,一部分为主干网络,其主要作用是提取图像中目标的特征;另一部分为FPN(Feature Pyramid Networks)网络,其主要作用是对主干网络中提取得到的2个有效特征层进行特征融合,最终输出2个不同尺度的预测结果。在YOLOv4-Tiny的主干网络中,使用CSPDarknet53_Tiny(Cross Stage Partial Network to Darknet53_tiny)的结构如图2所示。与YOLOv4中的CSPDarknet(Cross Stage Partial Network to Darknet)结构相比,CSPDarknet53_Tiny将激活函数重新修改为Leaky ReLU,从而提高计算速度。CSPDarknet53_Tiny利用了传统的残差结构的思想,在传统的残差结构中再嵌入一个残差结构,从而形成一个新的类似于残差结构的网络结构,使用这种CSPDarknet53_Tiny结构能够有效提高特征提取的效果。假设输入图像的尺寸为(416,416,3),经过YOLOv4-Tiny的主干网络提取特征后,最终的输出结果的尺寸为(13,13,512)。在FPN网络中,输入为主干网络的最后一层和倒数第二层的输出结果,其尺寸分别为(13,13,512)和(26,26,256)。将(13,13,512)卷积后的结果再次进行卷积并进行上采样操作后与FPN网络的另一个输入进行拼接,形成另一个中等尺度的输出结果。至此,YOLOv4-Tiny网络在13×13和26×26这2个尺度上产生预测结果,这2个预测结果的具体尺寸计算公式为:
Size=B×B×(nAnchor×(5+cn))。 (1)
式中:B为输出尺寸大小,在YOLOv4-Tiny中为13和26; nAnchor为每个尺度上提前设置的锚定框(Anchor Box)的个数,在YOLOv4-Tiny中为每一尺寸的输出结果配3个锚定框,因此,nAnchor=3; “5”表示在产生的预测框中将包含5个参数,具体为目标的位置参数xoffset、yoffset、w、h和目标种类的置信度c;cn为一共所需预测的目标种类的总数。
综合上述分析可知,YOLOv4-Tiny最终输出结果的尺寸分别为13×13×18和26×26×18。
在YOLOv4-Tiny完成预测后,通过使用非极大值抑制的策略筛选预测结果,从而提高预测精度,但是该预测结果并非直接对应目标在原始图像中的原始位置,还需要对其进行解码操作。在解码的过程中,首先,需要对预测结果进行“重整”(reshape),reshape后的结果分别为13×13×3×6和26×26×3×6;然后,将每个格点加上对应的偏移量xoffset、yoffset,即可计算出预测框的中心坐标;最后,利用宽高比例w、h计算出最终预测框的长和宽,将最终的预测结果在原始图像上绘制即可完成目标检测。如图2所示。
2 火灾检测网络的搭建及改进
2.1 火灾检测网络的搭建
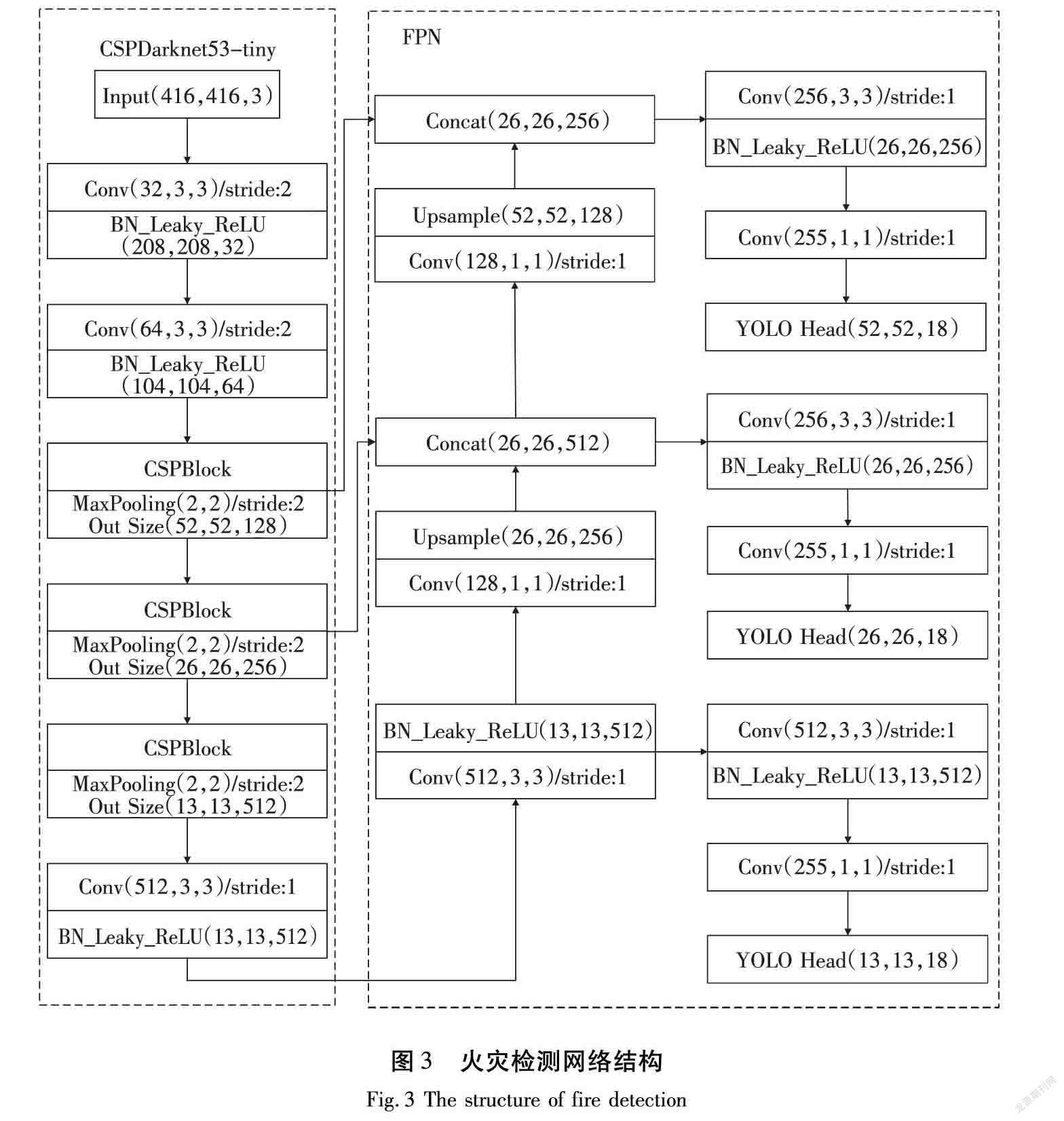
分析可知,YOLOv4-Tiny保留了YOLO系列多尺度预测的思想,但是为了提高实时性,仅在中小尺度进行预测,从而导致了YOLOv4-Tiny漏检率较高的缺点。为了提高火灾检测的性能,本文重新引入大尺度预测的结果,搭建的火灾检测网络的主要结构如图3所示。
在主干网络中,使用YOLOv4-Tiny的主干网络结构,但是在FPN网络中,增加一个大尺寸的输入,即将主干网络在52×52这个尺度上的输出作为FPN网络的另一个输入。将26×26这个尺度上的结果进行卷积和上采样操作,并与52×52这个尺度进行拼接,形成一个新的输出。由公式(1)可知,本文中的火灾检测网络的3个输出结果的尺寸分别为13×13×18、26×26×18和52×52×18。
2.2 基于二分K-Means的Anchor Box设计
根据分析可知,YOLOv4-Tiny在最终进行预测的过程中,在每个尺度的网络上产生3个Anchor Box,根据本文搭建的火灾检测网络需要在大、中、小3个尺度上进行预测,因此,需要9个Anchor Box。在原始的YOLO系列的算法中,使用K-Means聚类算法计算Anchor Box的大小,K-Means聚类算法能够充分考虑数据集中真实目标框(ground truth)的大小,但是,K-Means聚类算法存在局部最优的缺点。针对上述缺点,本文基于二分K-Means聚类算法重新生成Anchor Box。在运用二分K-Means聚类算法生成Anchor Box的步骤如下。
(1) 将数据集中所有的数据初始化为一个簇,并将此簇分为2个簇。
(2) 以误差平方和SSE作为聚类代价函数,筛选满足聚类代价函数可分解的簇。
(3) 运用K-Means聚类算法将(2)中可分解的簇再分为2个簇。
(4) 重复上述步骤(2)和(3),直至得出最终的9个Anchor Box。
为了使得预测框与ground truth之间尽量重合,本文通过IOU计算聚类代价函数SSE(公式中用ESS表示),SSE的具体计算公式为:
ESS=∑ni=1(1-IOUi(b,g))2 。 (2)
式中,IOUi(b,g)为第i个目标的预测框与ground truth之间的IOU值。
经过本文的二分K-Means聚类算法后,最终得出的9个Anchor Box的大小(18,28)、(22,75)、(28,49)、(41,99)、(43,47)、(60,74)、(92,57)、(93,106)、(144,183)。
2.3 損失函数
在本文搭建的火灾检测网络中,使用YOLOv4-Tiny网络的损失函数作为本文中的损失函数。在YOLOv4-Tiny中的损失函数主要由3个部分组成,分别为位置损失loss_loc(公式中用lloc表示)、置信度损失loss_con(公式中用lcocn表示)和分类损失loss_c(公式中用lc表示)。因此,损失函数的计算公式为:
l=lloc+lcon+lc 。 (3)
其中, loss_loc、loss_con和loss_c的计算公式分别为:
lloc=1-IOU(p,g)+ρ2(pctr,gctr)/c2+α·v。 (4)
lcon=∑K×Ki=0∑Mj=0IobjijC^ilogCi+1-C^ilog1-Ci+
λnoobj∑K×Ki=0∑Mj=0InoobjijC^ilogCi+1-C^ilog1-Ci。 (5)
lc=∑K×Ki=0Iobjij∑c∈classesp^i(c)logpi(c)+1-p^i(c)log1-pi(c) (6)
式中:IOU(p,g)为预测框与ground truth之间的IOU值;ρ2(pctr,gctr)为预测框与ground truth之间的距离;c为预测与ground truth的最小包围框的对角线长度;α与v的乘积为长宽比的惩罚项,其具体计算公式分别为:
α=v(1-IOU)+v (7)
v=4π2arctanwgthgt-arctanwh2 (8)
式中:wgt、hgt分别为真实框的宽和高;w、h分别为预测框的宽和高。
3 火灾检测网络的训练结果分析
3.1 火灾检测数据集的制作
在目前公开的数据集中,用于火灾检测的数据集比较少,主要有韩国启明大学(Keimyung University)CVPR实验室的火灾视频库、土耳其比尔肯大学(Bilkent University)公开的部分火灾视频数据集以及在火灾数据集网站(Ultimate Chase)的主页上公开的部分火灾视频。本文从上述这些公开的数据集中选择30段典型的火灾场景视频,并将其切分成每一张图片,从中筛选比较清晰的图像,除了从上述公开的数据集中选择图片外,从网络上另外收集各种场景的火灾图像,从而丰富数据集。经过从各种渠道收集图像后,本文最终制作的数据集包含6 000张图像,其中,1 200张图像作为测试数据集。为了测试本文中的火灾检测网络的实时性,在测试数据集中补充5段火灾视频。剩余4 800张图像用于训练本文的火灾检测网络,在这4 800张图像中抽取90%的数据用于训练,10%的数据用于验证。在上述6 000张图像中,包含了室内、室外各种简单和复杂环境,白天和黑夜等不同光照条件以及各种大小不同的火焰,从而保证了本文的火灾检测网络较高的鲁棒性。
3.2 结果分析
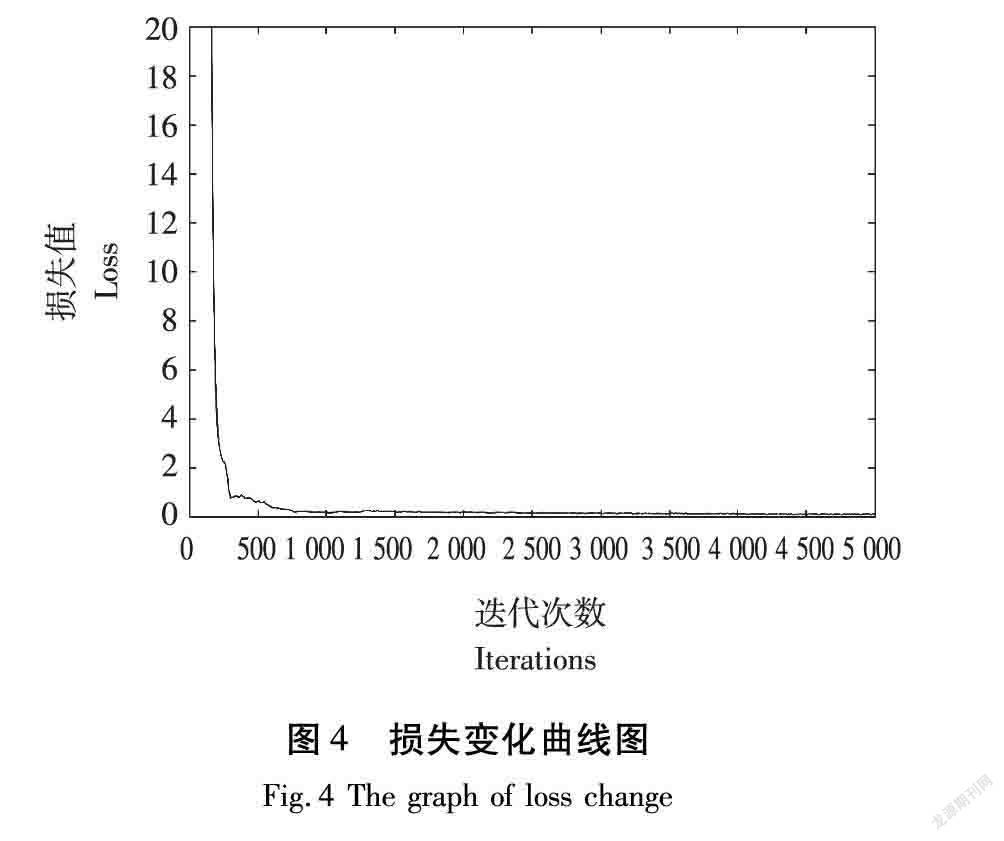
本文的火灾检测网络训练平台的操作系统为Ubuntu18.04,深度学习框架为Darknet,硬件配置为NVIDIA RTX2080Ti显卡。为了提高训练的效率,主干网络采用预训练权重,设置输入图像的尺寸为(416,416),共训练5 000个批次,批处理大小为64,初始学习率设置为0.001。在训练过程中,损失变化曲线如图4所示。
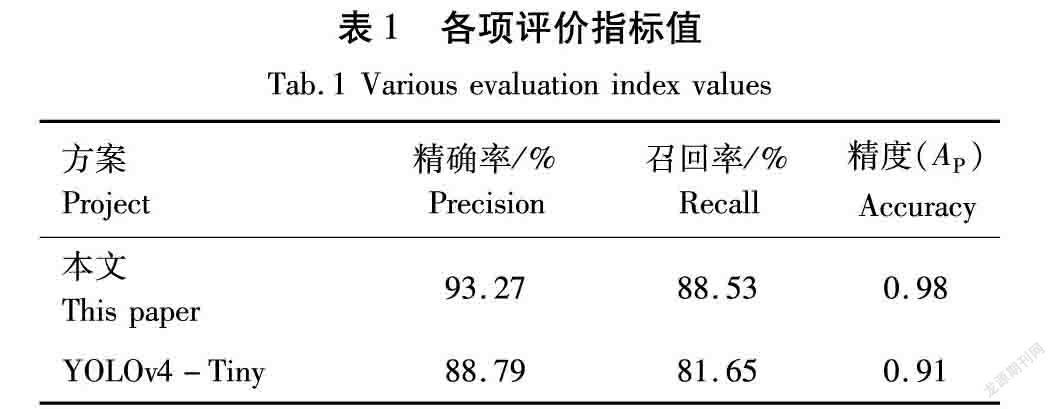
由图4可以看出,由于主干网络使用了预训练权重,在训练了150个批次后,损失值快速下降,在训练1 000个批次后,损失值下降较慢,在训练2 500个批次后,损失值基本不再变化。根据精确率(Precision,公式中用Precision表示)、召回率(Recall,公式中用Recall表示)[22]计算公式并结合验证集,本文的各项指标见表1。为了综合评价本文的火灾检测网络的性能,需要综合考虑精确率和召回率,即精度(AP)(公式中用AP表示),在本文中由于待检测的目标只有一个,所以在本文中的平均精度(mAP)即为火灾目标的AP。
Precision=TPTP+FP; (9)
Recall=TPTP+FN。 (10)
式中:TP为真正例; FP为假正例; FN为假负例。
由表1可以看出,本文的火灾检测网络与YOLOv4-Tiny相比,在精确率方面提高了4.48%,在召回率方面提高了6.88%,在AP值方面提高了0.07,并接近1。由此可见本文中的火灾检测网络体现了良好的性能。
为了验证本文中的火灾检测网络在嵌入式设备上的性能,将本文的火灾检测网络在NVIDIA Jetson Nano上进行部署实验。NVIDIA Jetson Nano作为一款入门级嵌入式AI计算平台,具有较高性价比,其软硬件配置见表2。
在各种场景下的检测效果如图5所示,图5中图像的分辨率分别为600×399、900×600、523×308、640×424、500×306、275×183,从图5可以看出,本文中的火灾检测网络基本能够准确识别不同大小的火焰,并且在黑暗环境中同样能够准确检测,对于高空拍摄的图像基本能进行准确检测,只有少量目标漏检。
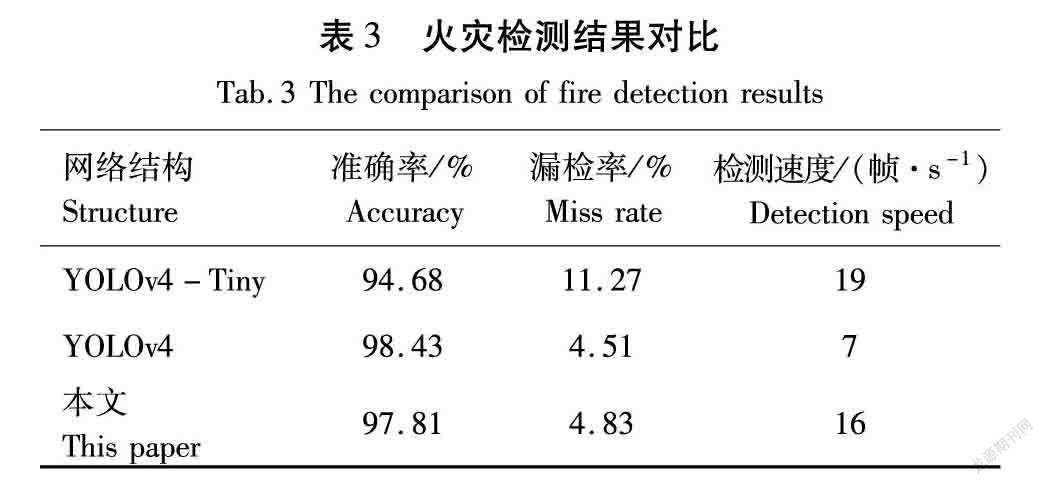
为了能够精确评估本文中的火灾检测网络的性能,从准确率、漏检率和检测速度的角度出发,结合本文数据集中的测试集,与传统的YOLOv4-Tiny、YOLOv4进行对比分析,对比结果见表3。
由表3可以看出,在准确率方面,本文的火灾检测网络相比原始YOLOv4-Tiny网络提高了3.13%,与YOLOv4几乎持平;在漏检率方面,由于本文在3个尺度上输出预测结果,因此比YOLOv4-Tiny降低了6.44%,几乎与YOLOv4持平;在检测速度方面,由于计算量远小于YOLOv4,因此检测速度远优于YOLOv4,稍慢于YOLOv4-Tiny,同样能够达到16帧/s。
本文中的火灾检测网络发生漏检的情况主要为受到周围环境干扰和火灾目标较小,如图6所示,其中蓝色框中的火灾目标由于较小,所以检测失败,绿色框中的火灾目标受到周围环境的干扰导致检测失败。
综合来看,本文中的火灾检测网络表现出了良好的综合性能,能够在各种场景、各种角度成功检测各种大小不同的火焰。
4 结论
由于传统火灾传感器在检测火灾的过程中容易受到周围环境、安装距离等因素的影响,因此,本文在现有YOLOv4-Tiny目标检测网络的基础上搭建火灾目标检测网络。在现有的YOLOv4-Tiny网络中的FPN结构中引入大尺度预测层,解决原始YOLOv4-Tiny网络漏检率高的问题;运用二分K-Means聚类算法重新生成Anchor Box提高火灾检测准确率,从最终在NVIDIA Jetson Nano上的实验结果可以看出,本文搭建的火灾检测网络具有良好的性能,可以在各种角度、各种环境中检测各种大小不同的火焰;在测试数据集上的准确率达到了97.81%,漏检率为4.83%,并且检测速度FPS达到了16帧/s。但仍然存在一定不足,主要表现在较小目标和受外界环境干扰的目标无法成功检测,未来将从提高检测准确率和降低漏检率的角度进一步提升本文中的火灾检测网络的性能。
【参 考 文 献】
[1]韦海成,王生营,许亚杰,等.样本熵融合聚类算法的森林火灾图像识别研究[J].电子测量与仪器学报,2020,34(1):171-177.
WEI H C, WANG S Y, XU Y J, et al. Forest fire image recognition algorithm of sample entropy fusion and clustering[J]. Journal of Electronic Measurement and Instrumentation, 2020, 34(1): 171-177.
[2]张为,魏晶晶.嵌入DenseNet结构和空洞卷积模块的改进YOLOv3火灾检测算法[J].天津大学学报(自然科学与工程技术版),2020,53(9):976-983.
ZHANG W, WEI J J. Improved YOLO v3 fire detection algorithm embedded in DenseNet structure and dilated convolution module[J]. Journal of Tianjin University (Science and Technology), 2020, 53(9): 976-983.
[3]HAN X F, JIN J S, WANG M J, et al. Video fire detection based on Gaussian mixture model and multi-color features[J]. Signal, Image and Video Processing, 2017, 11(8): 1419-1425.
[4]劉凯,魏艳秀,许京港,等.基于计算机视觉的森林火灾识别算法设计[J].森林工程,2018,34(4):89-95.
LIU K, WEI Y X, XU J G, et. Design of forest fire identification algorithm based on computer vision[J]. Forest Engineering, 2018, 34(4):89-95.
[5]HORNG W B, PENG J W, CHEN C Y. A new image-based real-time flame detection method using color analysis[C]//Proceedings of 2005 IEEE Networking, Sensing and Control, 2005. March 19-22, 2005, Tucson, AZ, USA. IEEE, 2005: 100-105.
[6]TOREYIN B U, DEDEOGLU Y, GUDUKBAY U, et al. Computer vision based method for real-time fire and flame detection[J]. Pattern Recognition Letters, 2006, 27(1): 49-58.
[7]CHEN J, HE Y P, WANG J. Multi-feature fusion based fast video flame detection[J]. Building and Environment, 2010, 45(5):1113-1122.
[8]周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(6):1229-1251.
ZHOU F Y, JIN L P, DONG J. Review of convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(6): 1229-1251.
[9]姜俊鹏,吕斌,胡够英,等.基于机器视觉的木材种类识别技术研究[J].林业机械与木工设备,2021,49(10):36-38.
JIANG J P, LYU B, HU G Y, et al. Research on wood species recognition technology based on machine vision[J]. Forestry Machinery & Woodworking Equipment, 2021, 49(10): 36-38.
[10]朱泓宇,謝超.基于可逆卷积神经网络的图像超分辨率重建方法[J].林业机械与木工设备,2021,49(3):20-25.
ZHU H Y, XIE C. Image super-resolution reconstruction method based on invertible convolutional neural networks[J]. Forestry Machinery & Woodworking Equipment, 2021, 49(3): 20-25.
[11]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. June 23-28, 2014, Columbus, OH, USA. IEEE, 2014: 580-587.
[12]GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[13]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[14]ZHANG Q X, LIN G H, ZHANG Y M, et al. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images[J]. Procedia Engineering, 2018, 211: 441-446.
[15]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 779-788.
[16]REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017:7263-7271.
[17]REDMON J, FARHADI A. YOLOv3: an incremental improvement[J]. Journal of Computer and Communications, 2018, 6(11):1804.02767.
[18]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]. Cham: Springer International Publishing, 2016.
[19]LI Z X, ZHOU F Q. FSSD: feature fusion single shot multibox detector[EB/OL]. 2017, eprint arXiv:1712.00960.
[20]FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[EB/OL]. 2017, arXiv: 1701.06659[cs.CV].
[21]BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. 2020, arXiv:2004.10934[cs.CV].
[22]DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: a benchmark[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. June 20-25, 2009, Miami, FL, USA. IEEE, 2009: 304-311.
