
一种基于改进YOLOv5s的电动车头盔佩戴检测方法
2022-04-25 13:54陈正宇
金陵科技学院学报 2022年1期
徐 栋,陈正宇
(1.南京邮电大学电子与光学工程学院,江苏 南京 210023;2.金陵科技学院电子信息工程学院,江苏 南京 211169)
驾驶电动车时佩戴安全头盔可在事故发生时缓冲头部撞击,保护生命安全。电动车驾乘人员佩戴头盔成为保障道路安全的一项重要工作。通过人工智能算法构建电动车驾乘人员佩戴安全头盔的检测系统对促进道路安全具有重要意义,也是迈向交通智能化的关键一步。
目前,针对道路场景下电动车头盔佩戴检测的研究较少,不少研究是针对工地安全帽的佩戴检测,二者检测方法存在相似之处,但是道路场景下电动车头盔佩戴检测对检测速度的要求更高。传统的安全头盔检测方法如使用支持向量机作为分类器、通过梯度直方图进行特征提取等,存在主观性强、特征提取困难、泛化性差等问题,需要进一步改进[1]。深度学习卷积神经网络在提取图像特征时不需要手动设计特征,给安全头盔的佩戴检测提供了一个新的方向。目前主流的基于深度学习的头盔佩戴检测算法分为两类:一类是以Fast R-CNN[2]和Faster R-CNN[3]为代表的双阶段检测算法;另一类是以SSD[4]、YOLO[5]为代表的单阶段检测算法。双阶段算法模型体积较大,训练时间长,检测速度不高,不利于模型部署;单阶段算法的泛化能力较弱,对小目标的检测性能有待提升。此外,上述基于深度学习的研究大多数是基于GPU工作站,缺乏对部署嵌入式平台的考虑,难以满足道路场景下电动车骑行者头盔佩戴的检测要求。
因此,本文通过降低卷积参数、改进特征提取结构、加入注意力机制对YOLOv5s模型进行优化,提出了一种基于改进YOLOv5s模型的电动车头盔佩戴检测方法,以期对小目标和遮挡目标有较好的检测效果,在NVIDIA Jetson Xavier NX开发板上具有较高的检测速度。
1 YOLOv5s模型
YOLOv5是在YOLOv3、YOLOv4模型基础上不断创新的模型,该模型的特点是适用于移动端、模型小、速度快。YOLOv5包括YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。YOLOv5s是其中网络深度最浅、特征图宽度最小的模型,体积只有14 M,非常适合嵌入式设备的部署,因此本文选用YOLOv5s模型作为基准模型。
YOLOv5s模型结构如图1所示,主要由主干网络(backbone)和头部(head)两部分构成。backbone包含Focus结构、SPP[6]结构和参照CSP[7]结构设计的C3结构,head部分使用了PANet[8]结构。
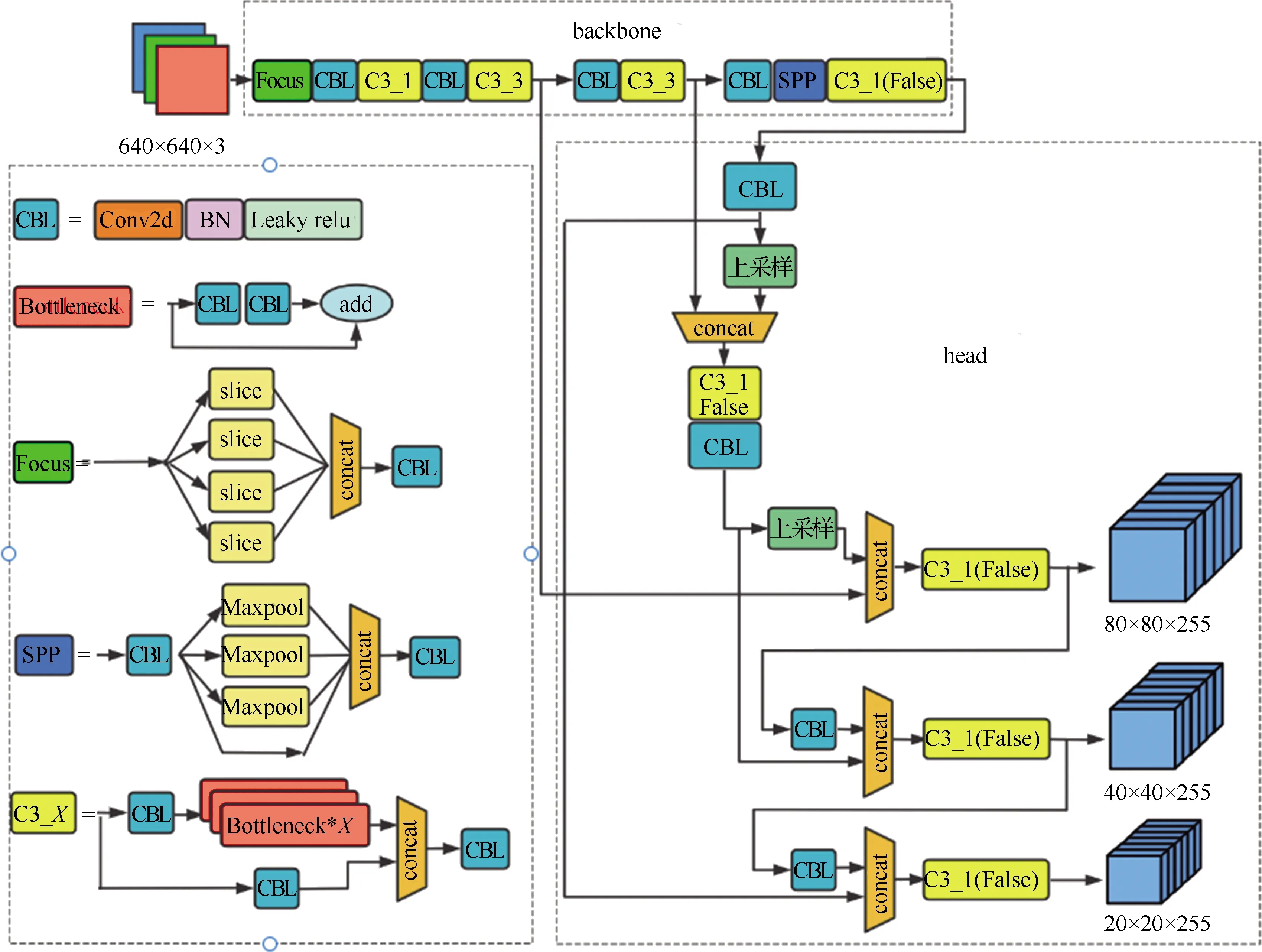
图1 YOLOv5s模型结构
YOLOv5s创造性地采用了Focus结构,先通过间隔采样对输入图像进行四倍通道扩充,再经过卷积操作得到无特征信息损失的二倍下采样特征图。Focus模块对普通卷积操作进行了优化,以更少的计算成本实现下采样并增加通道维度,降低了参数量并提升了速度。
YOLOv5s根据跨阶段合并策略设计了C3模块,该模块是对残差特征进行学习的主要模块。C3模块根据堆叠的Bottleneck[9]有无侧向连接设计了两种CSP模块,分别是C3_X(True)和C3_X(False),X是Bottleneck的堆叠数量。前者用于backbone部分的特征提取,后者用于head部分的特征融合。
PANet 是在特征金字塔网络(FPN)[10]的基础上加上一个自底向上的特征传递路径,然后将不同深度的特征进行融合。该结构使得顶层特征图也可以有效利用底层特征丰富的位置信息,从而提升了多尺度目标的检测效果。
2 改进的YOLOv5s模型
YOLOv5s模型对目标检测中常见的问题都做了一定的优化改进,在性能上同时兼顾检测速度和检测精度,具有较好的工程实用性,但在一些实际场景下仍有待提升。为了满足电动车驾乘人员头盔佩戴检测需要,本文从模型计算量、体积、精确度出发,将YOLOv5s模型进一步优化,以提升检测精度。
2.1 GhostCSP-Bottleneck 的设计
YOLOv5s模型中,C3模块使用了较多的标准卷积,带来了计算量大的问题。因此,本文引入Ghost模块,该模块能够通过高效操作以更少的参数量和计算量生成特征图[11]。Ghost模块的实现分为两部分,一部分是普通卷积,另一部分是更为高效的线性操作。先通过普通卷积得到一组特征图,再将得到的特征图通过线性操作生成另一组特征图,最后把两组特征图拼接起来。
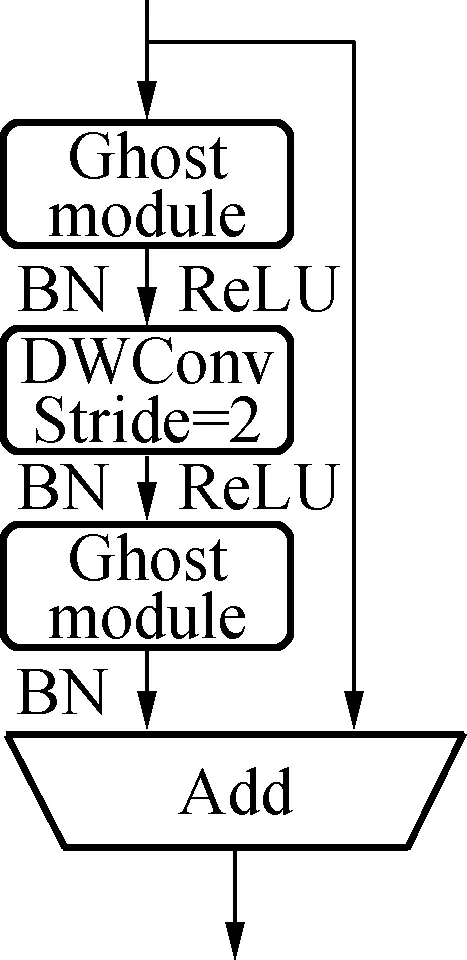
(a)结构一
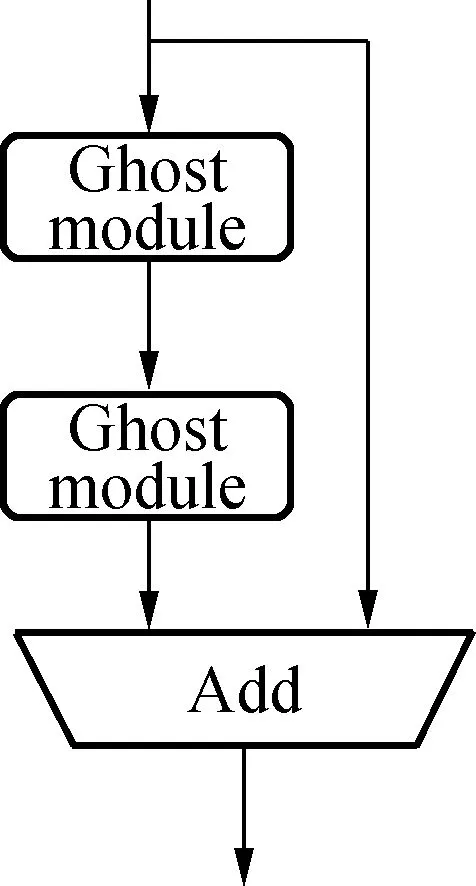
(b)结构二
为了更高效地提取特征,本文使用GhostNet[11]中的GhostBottleneck结构代替YOLOv5s主干网络的标准卷积,结构如图2(a)所示。该结构在两个Ghost模块之间通过一个步长(stride)为2的深度卷积(DWConv)进行向下采样连接,最后将这两个Ghost模块的输入和输出合并。第一个Ghost模块用于增加通道数,第二个Ghost模块用于压缩通道数,这构成了逆残差结构,使得信息损失更少,结构表征能力更强。根据MobileNetV2的思想,将通道压缩后,不使用ReLU函数激活可以避免特征信息丢失[12]。因此,除了最后一个Ghost模块不使用ReLU函数外,在每一层后均通过批标准化(BN)和ReLU函数进行非线性激活。将该结构替换YOLOv5s中backbone部分的CBL卷积结构,减少了模型的参数量和计算量。
假设输入特征图的通道数、高度和宽度分别为c、h和w,输出特征图的通道数、高度和宽度分别为n、h′和w′,普通卷积中卷积核的大小为k×k。Ghost模块中通过普通卷积生成的特征图数量为m,每个线性运算的平均内核大小为d×d。根据文献[11],GhostBottleneck模块的计算量可表示为2[mh′w′ckk+ddh′w′(n-m)]。根据图1,Bottleneck模块的计算量可表示为2nh′w′ckk。因此Bottleneck模块与GhostBottleneck模块的计算量之比可表示为:
(1)
其中,k和d的大小相同,m 图3 GhostCSP-Bottleneck结构 图4 SE注意力模块示意图 虽然GhostBottleneck模块能够大幅压缩YOLOv5s模型的参数量和计算量,但不可避免地导致检测精度小幅度下降。为了提升检测精度,本文在主干网络部分引入SE[13]注意力模块(图4),该模块能够解决卷积池化过程中由于特征图不同、通道占比不同带来的损失问题。SE注意力模块首先是挤压操作Fsq,将输入特征图X进行全局池化,生成1×1×c的一维矩阵,该矩阵具有全局大小的感受野;然后是激励操作Fex,通过两个全连接层(FC),利用非线性操作拟合通道之间的相关性,在第一个全连接层后加入ReLU函数增加通道间的非线性,在第二个全连接层后加入Sigmoid函数进行权值归一化操作,得到附带通道权值的1×1×c矩阵;最后是缩放操作Fscale,将得到的1×1×c特征图与输入特征图做全乘操作,将权重加权到输入特征图上,这样就得到了附带不同通道权重的特征图Y。 SE注意力模块为即插即用模块,通常用在卷积模块之后[14]。因此本文在YOLOv5s主干网络的第二个和第三个C3模块后加入SE注意力模块,为不同尺度的特征层赋予更高的权重;再在SPP层后加入SE注意力模块,强化融合后的局部特征和全局特征,丰富特征图的表达能力。在主干网络加入SE注意力模块后参数量增加了43 008,仅占YOLOv5s模型总参数量的0.61%;学习到的特征信息被进一步优化,赋予通道小目标的权值比重,能大幅提升模型精度。 改进的YOLOv5s模型网络结构如图5所示。 图5 改进的YOLOv5s模型结构 GhostCSP-Bottleneck模块的True和False表示有无残差边,后面的数字(YOLOv5s中是1和3)代表GhostBottleneck的堆叠次数。经计算,改进前后的YOLOv5s模型参数如表1所示。 表1 改进前后YOLOv5s模型参数对比 从表1可以看出,改进的YOLOv5s模型参数量(params)为 3.7 M,每秒浮点运算次数(FLOPs)为8.2 G,模型体积(weight)为7.6 MB,三者分别为原始YOLOv5s模型的51.39%、47.95%和52.78%,实现了较大幅度的压缩。 由于所需的检测类别没有公开的数据集,所以自行制作了包含5 000张图片的原始数据集。数据集图片来源包括两部分:一是利用Python网络爬虫从百度图片获取,二是从金陵科技学院的道路监控缓存视频截取图片。为了提高模型的泛化性能,使用随机缩放、裁剪、翻转、旋转等方式来增加原始数据集的多样性。 本实验的数据集由motorcycle、helmet、person三个类别构成,分别对应电动车目标、头盔目标和未佩戴头盔的人脸目标,其中helmet和person为两种对立的状态。先使用标注工具将图片中出现的三类目标进行标注,生成YOLOv5s模型训练格式的标签,最后按照7∶2∶1的比例划分训练集、验证集和测试集,完成数据集的构建。 实验所使用的设备是云服务器平台,操作系统为Ubuntu 18.04,GPU为GeForce RTX 2080Ti,搭配CUDA10.2和CUDNN7.6加速工作站。训练完成后将模型移植到嵌入式平台NVIDIA Jetson Xavier NX上进行部署。实验使用的深度学习框架为Pytorch 1.8.0,对应的torchvision版本为1.9.0。训练时设置初始学习率为0.01,动量设置为0.937,衰减系数为0.000 5,epoch为300,batchsize为32。 为了定量评价实验结果,使用准确率(precision)、召回率(recall)、平均准确率均值(mAP)作为指标,如式(2)—式(5)所示。此外还采用模型体积、参数量、每秒浮点运算次数(FLOPs)、检测速度(单位为FPS)作为衡量模型大小、计算量、推理速度的指标。 (2) (3) (4) (5) 式中,TP表示被正确分类的正样本,FP表示被错误分类的正样本,FN表示被错误分类的负样本,n表示总类别数。 在验证改进后的完整模型之前,通过消融实验探究改进方法对于YOLOv5s的影响。消融实验以YOLOv5s模型为基础,按照2.1节和2.2节所述的改进方法将GhostBottleneck(以下简称GBk)模块、GhostCSP-Bottleneck(以下简称GhostCSP)模块、SE注意力模块加入到YOLOv5s模型中,得到的结果如表2所示,图片输入尺寸为640×640。 表2 以YOLOv5s为基础的消融实验结果 由表2可知,加入SE注意力模块后模型精度有较大的提升,比原YOLOv5s模型mAP提升了2.4个百分点,且计算量几乎没有增加,但是召回率有所下降。在模型中同时加入GBk模块和GhostCSP模块后,计算量减少了52.0%,mAP下降了0.8个百分点,因此GBk和GhostCSP 能够以更少的计算量提取特征信息。 根据消融实验可以发现,在主干网络不同尺度特征层加入SE注意力模块,能够为不同通道赋予权重信息,而且在后续的特征融合中可以将权重信息继续传递,最终以少许计算量为代价显著提高检测精度;GBk模块由于以更高效的方式提取特征,对计算量和模型体积有较明显的压缩;GhostCSP模块减少了特征信息的损失,以少量准确率为代价将模型的计算量和参数量进一步压缩。可见,SE注意力模块、GBk模块和GhostCSP模块对于模型整体性能提升十分必要。 为了验证改进后模型的效果,选用同类型轻量级模型YOLOv4-tiny和MobilenetV3-YOLOv5s进行对比实验,后者是由MobilenetV3的backbone部分替换掉YOLOv5s的backbone得到。将模型按照3.2节的配置进行训练,将训练好的模型放在测试集上测试模型的性能,测试集包含500张图片,测试结果如表3所示。 表3 不同模型的检测性能 从表1和表3可以看出,改进后模型的mAP为84.2%,在四种模型中最高,较改进前提升了1.3个百分点,但是召回率下降了3.3个百分点。虽然改进后的模型在参数量、计算量、体积上稍逊色于MobilenetV3-YOLOv5s,但是mAP比MobilenetV3-YOLOv5s高2.1个百分点。实验结果表明,相较于YOLOv5s,本文所提方法在大幅度减小参数量和计算量的同时提高了检测精度。 将训练好的模型部署到NVIDIA Jetson Xavier NX开发板上,比较不同模型的检测速度。由表4可知,在640×640 的图像输入尺寸下,由于嵌入式设备性能限制,YOLOv5s的检测速度仅有20.2 FPS,实时性不佳。本文提出的模型的检测速度达到28.6 FPS,较改进前提升了8.4 FPS,可以满足实时性的检测需求。在512×512 的图像输入尺寸下,改进后模型的检测速度达到了36.3 FPS,比YOLOv4-tiny略快。结果表明,本文提出的模型在电动车驾乘人员头盔佩戴检测方面更有优势。 表4 不同模型在不同尺寸下的检测速度 FPS 除了在数据集上验证模型的性能外,还从实际道路采集图像以直接检验模型的检测效果。图6—图8是改进前后模型的部分检测结果,(a)图为原始YOLOv5s模型的检测结果,(b)图为改进后模型的检测结果。从图6可以看出,在场景良好的情况下改进前后的模型都能将电动车驾驶人员的头盔佩戴情况检测出来,即二者均满足检测需求。在图7中,YOLOv5s模型没能检测出图片左下方被遮挡的电动车目标和右上角远处模糊的电动车目标,而改进的模型能够将这两个目标检测出来,说明改进的模型对遮挡目标和小目标有更好的检测效果。在图8(为了便于观察做了标签隐藏处理)中,左侧的自行车目标(蓝色框标出)和右侧的电动车目标在特征上有较高的相似度,原始YOLOv5s模型没能将二者区分开来,将自行车错误地识别为电动车目标,而改进后的模型成功地区分出了这两个相似的目标。由此得出,改进后的模型不但在常规场景下可以成功识别出电动车驾乘人员的头盔佩戴情况,而且对遮挡目标、小目标和相似度较高的目标也有较好的检测效果。 (a)YOLOv5s (b)改进的YOLOv5s (a)YOLOv5s (b)改进的YOLOv5s (a)YOLOv5s (b)改进的YOLOv5s 本文针对电动车驾乘人员头盔佩戴检测任务,以YOLOv5s模型为基础,引入GhostBottleneck优化网络结构,设计GhostCSP-Bottleneck模块替换C3模块,并在主干网络加入SE注意力模块,形成了一种适用于嵌入式平台的轻量化电动车驾乘人员头盔佩戴检测方法。实验结果表明,改进的模型在精度上稍高于原模型,且具有更少的计算量、更小的模型体积和更快的检测速度。在640×640 的图像输入尺寸下,平均准确率均值mAP为84.2%,在四种模型中最高,比YOLOv5s提高了1.3个百分点;在嵌入式平台NVIDIA Jetson Xavier NX上的检测速度可以达到28.6 FPS,比YOLOv5s提高了8.4 FPS,可以很好地满足实时性的检测需求。本文提出的模型在精度上和检测速度上取得了良好的平衡,适合嵌入式平台的部署检测。下一步工作目标是要丰富检测场景,提升模型在夜晚、雾天、雨雪天等环境下的检测效果。

2.2 SE(squeeze and excitation)注意力模块
2.3 改进的YOLOv5s模型
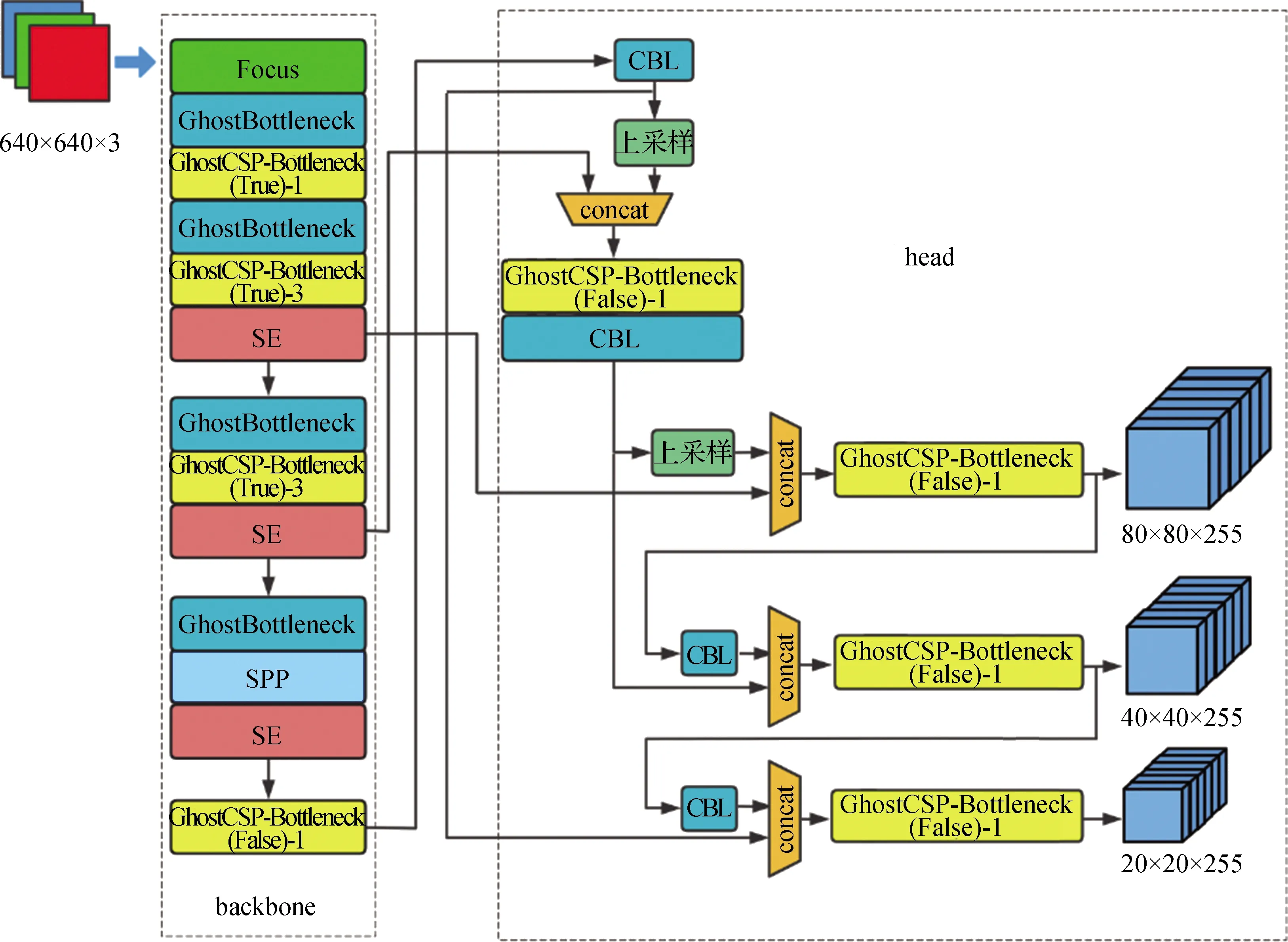

3 实验结果与分析
3.1 数据集及实验环境
3.2 实验平台和模型训练配置
3.3 评价指标
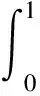
3.4 消融实验

3.5 不同模型在数据集上的对比实验


3.6 不同模型在实际道路上的对比实验






4 结 语
猜你喜欢
消费电子(2022年7期)2022-10-31
小雪花·成长指南(2022年1期)2022-04-09
小学科学(学生版)(2021年10期)2021-12-28
21世纪商业评论(2020年12期)2020-01-14
红领巾·探索(2018年11期)2018-12-10
小哥白尼(军事科学)(2018年9期)2018-12-08
传媒评论(2017年3期)2017-06-13
中国公路(2017年5期)2017-06-01
第二课堂(课外活动版)(2016年2期)2016-10-21
小学生导刊(低年级)(2016年8期)2016-09-24
