
基于神经网络模型的电子病历文本提取及质量缺陷分析
2022-04-25 05:53曹新志沈君姝袁雪王泽川胡欣马存宁王至诚王杰
中国医疗设备 2022年4期
曹新志,沈君姝,袁雪,王泽川,胡欣,马存宁,王至诚,王杰
江苏省中西医结合医院 a. 信息中心;b. 设备科,江苏 南京 210028
引言
医院的电子病历是医院进行医疗服务的凭证,全面记录了在医院进行的所有医疗工作[1],反映了对患者疾病诊断、治疗和转归的全过程,不仅充分体现了医疗质量,也是保障医疗安全的重点[2],同时也是鉴定医疗事故和处理医患纠纷的法律依据[3]。其在书写中瑕疵或质量缺陷会涉及医患双方权利及义务[4],而随着人们法律意识的提升与医疗技术进步的不平衡性,医患矛盾发生的概率逐年增加。为避免因电子病历质量缺陷引发医疗纠纷,对病例的真实性和规范性要求越来越严格[5],各医院也分别采取有力的规范措施提升电子病历的书写质量。所以医院强化电子病历质量管理对加强电子病历质量控制有重要意义。
随着电子信息技术和人工智能的发展,神经网络模型在医学中的应用越来越广泛,用于文本分类任务的卷积神经 网 络(Text Convolutional Neural Networks,TextCNN)模型作为其中一种,可利用多个不同大小的卷积核来提取句子中关键信息,能更好地捕捉局部相关性。在筛查文字、图片等信息中的问题方面有一定优势,现在多应用在病例首页问题中的筛查,可识别和分类所提取的首页问题[6],目前较少用于筛查电子病历所遇到的质量问题。为更好地预测和筛查电子病历文本提取及质量缺陷,本文通过建立TextCNN模型,探讨和分析其预测电子病历文本提取及质量缺陷的情况。
1 资料与方法
1.1 资料来源
选择并抽取我院于2020年1月1日至2021年10月31日归档的电子病历9万份,其中门诊病例7万份,住院病例2万份。
1.2 方法
1.2.1 电子分组和抽取情况分析
本次研究的样本量共有9万份,按照7∶3的比例把所有电子病历分为训练集和测试集,其中训练集有63000份电子病历(11540份有质量缺陷,51460无质量缺陷),测试集有27000份电子病历(5145份有质量缺陷,21865例无质量缺陷)。训练集采用K折交叉验证(K=10)。
1.2.2 运用自然语言处理技术提取信息
本研究是运用中文自然语言处理系统从电子病历系统中提取出临床有用信息。处理方法如下:① 预处理:先将系统内的电子病历转换成TXT可编辑的文本格式,同时清除掉文中的空白行和空格;② 句子分割:全文分割应用的是常在文档中词语或句子间断开的标点符号,包括“,”“。”“!”“?”“;”等;③ 段落筛选:应用段落筛选排除不必要的信息以便简化工作量;例如入院记录和首程中主诉这一行,从“主诉:”后的句子内容均是临床上的关键信息,这需要设定两个固定的边界筛选文本内容,而影像或病理学中的结论报告与上述问题类似;④ 关键词识别和值的提取:按照预定义的关键词提取电子病历中的关键词,在匹配过程中按顺序进行逐步的运算算法(如果遇到文本中无法识别的预定义字段,程序会跳过此段处理下一个)。
1.2.3 构建人工神经网络
采用TextCNN探索卷积神经网络深度与其性能间的关系,TexTCNN构建了包含嵌入层、卷积、最大池化层、全连接输出层的卷积神经网络(图1),通过以词为单位进行文本表示形成词向量,再将词向量按照词在句子中出现的顺序进行拼接,形成代表句子的矩阵,从而实现句子特征的自动提取和学习。本研究使用TextCNN模型进行迁移学习,其中嵌入层为采用经自然语言处理技术提取后的关键词,并将之转化为词向量,构成文本特征向量作为循环层的输出(文本会转变成一个二维矩阵,假设文本的长度为|T|,词向量的大小为|d|,则该二维矩阵的大小为|T|×|d|);卷积层则采用列数与循环层相等的卷积矩阵窗口,并将矩阵中的列矩阵块由上到下依次进行卷积运算,将矩阵所有相同位置的元素相乘后再求和并提取矩阵特征;在池化层中采用最大池化的方法取每个卷积窗口卷积得到的卷积层向量中最大的元素作为特征值,通过降低特征的维度,进一步提高分类效率;输出层与池化层全连接,以池化层向量为输入对向量进行分类,并输出最终的分类;而后将输出结果与之前预先基于中文医学主题词表构建好的医学主题词模型进行比对,并将所有比对完成的TextCNN模型的参数定义为集合,并采用随机梯度下降方法训练,得到最终模型,最后将验证集输入模型中以进行验证。

图1 TextCNN 模型结构略图
1.2.4 人工神经网络模型的评估
根据选出的测试集为验证对象,用TextCNN构建出模型进行验证,先通过疾病诊断相关分类系统(Diagnosis Related Groups,DRGs)对测试集内所有电子病历分组,将提取出问题的电子病历同时由一名具有中级职称并有5年以上审核病案工作经验的主治医师和此次建立的神经网络模型进行核查,如果二者审查结果不一致时交由病案室内具有副主任医师以上职称的专家医师进行复测,此结论是此病历质量检验的最终判定结果。统计所有神经网络模型判断错误的电子病历数并计算出人工网络模型的准确率、特异度和敏感度。
1.3 统计学分析
实验数据分析采用的硬件平台为i7-7700K+GTX1060(6G),软件平台为Python 3.7.10及TensorFlow-gpu 2.4.0人工神经网络库建立TextCNN模型,从预训练基线卷积层中提取特征优化的优化策略。准确率比较采用χ2检验,P<0.05为差异具有统计学意义。
2 结果
2.1 电子病历质量缺陷统计
纳入研究的9万份电子病历中,通过DRGs筛查后总共有16685份电子病历存在质量缺陷,质量缺陷发生率是18.54%(16685/90000),分析系统运行界面如图2所示,统计结果如表1所示。通过人工复检后发现存在质量缺陷病历中的问题主要有以下几个方面:对病情和医嘱变化或检查报告等病程记录不全;部分检查报告缺失不全;入院记录或首程填写不全;病程内容书写错误或重复;医生未能在规定时间内及时书写病程或签字提交;首页填写不全或错误;部分知情同意书等内容缺失;医嘱打印不全;出院记录对病情记录不全。
图2 电子病历质量缺陷分析系统界面
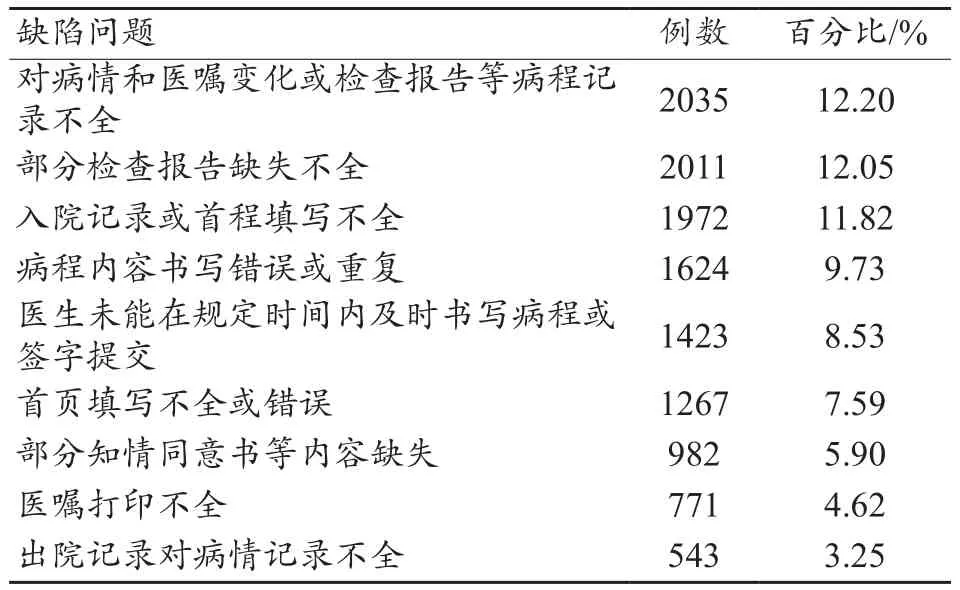
表1 电子病历质量缺陷统计
2.2 预测模型的内部验证和外部验证结果
通过收集预测模型及人工复审的预测矩阵,见表2。计算比较TextCNN模型与人工复审的预测指标之间的差异结果显示:TextCNN模型的准确率、敏感度、特异度、阳性及阴性预测值显著高于人工复审,差异具有统计学意义(χ2=253.249、57.091、197.199、186.241、57.547,P值均<0.001),见表3。

表2 TextCNN模型和人工复审预测质量缺陷的混淆矩阵(份)

表3 TextCNN模型和人工复审预测测试集质量缺陷的效能对比(%)
2.3 应用CNN模型后逐月筛选出问题病案的情况对比
由2021年2—10月间DRGs筛选出问题病案的数量结果显示(图3),自开始采用TextCNN模型分析后,随着模型系统应用逐渐熟练,DRGs每月筛选出有质量缺陷病的问题病案数逐渐下降,在3月份下降最明显,后下降趋势逐渐减缓,系统应用逐渐熟练、性能逐渐稳定。DRGs筛选出有质量缺陷病的问题病案发生率显著下降(χ2=16.830,P<0.001)。
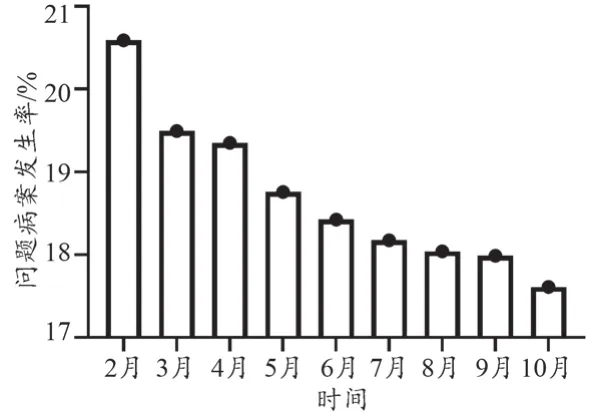
图3 DRGs筛选出问题病案发生率
3 讨论与总结
病历是医师基本医学知识、技能与实际相结合的客观体现,也是处理医患纠纷及其他涉及医学纠纷的法律依据[7],因此病历质量和病历质量管理在医院管理中一直占据着重要地位。而且好的病历还是医院进行教学科研的重要资料,为医师的成长提供帮助[8]。而随着社会信息化的发展,电子病历已逐渐代替了手写病历,成为医院的组成部分,而电子病历的质量缺陷也成为病历质量管理中的关键部分[9]。如何提高电子病历的质量也成为目前临床研究的重要课题。TextCNN作为一种深度前馈人工神经网络可用于提取文本中的关键信息,也可以识别和处理图像,目前逐渐应用于处理病历首页,对识别首页缺陷有较好的效果,有助于提高病历质量[10],较少用于电子病历的质量管理。
在本研究结果中发现,近两年我院的电子病历质量缺陷发生率是18.54%,说明我院在提高电子病历质量方面仍有较大的提升空间。而通过复检后发现最重要的质量缺陷问题主要包括对病情和医嘱变化或检查报告等病程记录不全、部分检查报告缺失不全等,一方面考虑与患者多、周转快、医师工作强度大、书写病历时间少有关;另一方面考虑与部分医师法律观念薄弱、缺乏自我保护意识、对电子病历质量重要性的认知程度不够、容易出现错别字或记录不严谨等情况有关[11],而且电子病历有复制粘贴等功能,在打电子病历时容易出现病程内容书写错误或重复、与病情不符或忘记签字等低级错误。在沈占英等[12]的研究中也列举了包括病程记录缺陷、病案首页缺陷、入院记录缺陷等在内的病历质量缺陷,与本文研究结果类似。也说明了如何提高电子病历质量是目前大多数医院所面对的重要问题。
通过预测模型内部和外部验证发现TextCNN模型准确率、敏感度、特异度、阳性及阴性预测值均高于人工复审。这说明了TextCNN预测模型在预测电子病历质量缺陷中有一定优势。在现今的通用技术中,机器学习对大规模数据处理有较大的优势,TextCNN可以通过构建模型对提取的数据反复对比筛查,可提高缺陷的检出率,特别是对电子病历中的图像、文字和表格等多个方面的识别和提取有较大的优势[13]。而人工检测由于人的固有观念及对问题的主观意识不同,对不同问题的看法不一致,而且病案审查人员数量少、工作量繁重,均会导致人工检测的敏感性和特异性降低[14]。在我院,通过应用TextCNN模型分析后发现DRGs筛选出问题病案发生率显著下降。观察我院每月有质量缺陷的问题病例检出率发现,随着应用TextCNN模型时间的延长,问题病例检出率逐渐降低。主要是在刚开始使用DRGs系统时,由于对诊断、格式、系统等模不熟悉,使得早期问题病历的检出率相对较高,而随着对DRGs系统的熟悉,缺陷病历的检出率明显降低。而且网络系统具有记忆性,能共享模型中各分层的实现参数,并且能储存各种长度不等的数据片段,增加了数据片段的识别性[15],减少了由于数据长度增加引起的不能识别文本的情况。TextCNN模型还能在局部感知和权值共享时通过模型进一步减少模型内训练参数的数目,提高模型效率,减少电子病历质量缺陷检出率[16],对提高电子病历质量有良好的效果。
综上所述,神经网络模型在电子病历文本提取和筛查质量缺陷病历中的效果较好,可用于临床推广以提高病历质量。虽然系统使用后有质量缺陷的电子病历检出率下降,但由于电子病历的复杂性,仍有部分电子病历质量缺陷检测存在误差,需要更完善的系统进一步检测,也需要进一步完善质量管理规定,提高电子病历质量。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
趣味(语文)(2021年9期)2022-01-18
昆明医科大学学报(2021年12期)2021-12-30
现代临床医学(2021年2期)2021-03-29
首都食品与医药(2020年13期)2020-12-25
数学小灵通·3-4年级(2020年9期)2020-10-27
作文评点报·低幼版(2020年25期)2020-07-23
科技与创新(2019年13期)2019-11-29
中国社区医师(2016年8期)2016-12-20
中国纤检(2015年8期)2015-05-08
