
基于优化YOLOv4算法的行驶车辆要素检测方法
2022-04-25 07:36陈耀祖谷玉海徐小力
应用光学 2022年2期
陈耀祖,谷玉海,成 霞,徐小力
(北京信息科技大学 机电工程学院,北京 100192)
引言
车辆给人们的生活带来了方便,但在车辆急剧增加的同时也带来了一系列问题,特别是如何提高车辆的管理效率。车牌、前窗及驾驶员的面部、手部等行驶车辆要素检测在车辆管理当中起到了一定的作用。其中车牌检测是生活中最常见的车辆要素检测,如停车场的收费处[1]、高速路口的收费站[2]、红绿灯路口的车牌识别[3]等,杨鼎鼎提出了一种首先通过车牌背景和字符固定颜色对车牌进行粗定位,然后采用改进的Canny 边缘检测算法对粗定位的车牌区域进行边缘检测,并通过投影定位法和车牌的几何特征完成车牌的定位[4]。王亮亮提出一种将车窗代替车体作为被检测目标物的标注方法,利用残差连接和多尺度特征提取方法,构建了只有24 个卷积层的检测网络,在车流量较大的场景中可有效提高检测算法的检出率[5]。代少升提出利用一种改进多任务卷积神经网络(multi-task convolutional neural network,MTCNN)算法检测人脸,然后通过浅层卷积神经网络进行手持电话行为检测,同时利用嘴巴宽高比的变化检测驾驶员讲话进行判别,最终利用两种行为相“与”方法进行驾驶员打电话的行为判别[6]。刘明周提出了一种基于面部特征以及手部运动特征的驾驶员疲劳融合检测算法,该算法提取眼部、嘴部的特征参数以及手部的运动特征参数,并将特征参数输入到基于 BP(back propagation)神经网络构建的特征参数分类器,综合判断驾驶员的行为状态[7]。
但上述4 种方法在实际场景应用时,对环境要求较高,鲁棒性较差。基于颜色进行定位的方法,在车牌和车身颜色较接近时定位效果不理想,容易将车身的某些部位误判为车牌;基于面部特征以及手部运动特征的疲劳融合检测算法容易将车座的某些部位误判为驾驶员脸部及手部。即使将几种方法结合起来,虽然在一定程度上能够提高车牌的定位准确率,但是在一些如雨雾天气等光线较暗的环境下还是难以取得理想的定位效果,而且传统的车牌检测方法对于车辆前窗、驾驶员人脸、手部等要素并不适用。
近年来,深度学习在物体检测方面取得了巨大进步,但无论是R-CNN(region-based convolutional neural network)系列网络还是SSD(single shot multibox detector)网络在检测速度以及检测如车牌、人脸、手部等小目标物的准确率来说,都不如YOLO(you only look once)系列的网络,YOLO 系列甚至能在确保较高精度的前提下达到实时检测[8]。YOLOv4 网络是一种高效的、仅用单GPU 就能得到理想训练效果的深度学习神经网络。因此,本文提出一种基于优化YOLOv4算法的检测方法,对车牌、车辆前窗、驾驶员人脸、手部等要素进行定位检测。为了更加适应驾驶室中人脸、手部等极小目标,将YOLOv4 网络增加一个感受野更小的检测尺度,用于对驾驶室中的人脸以及手部进行定位检测,并且为了更好地适应各种尺寸的检测对象,调整原网络中先验框(anchor boxes)检测框数目。
1 YOLOv4 网络模型
YOLOv4 网络沿用了YOLOv3 网络中的先验框,选用CSPDarknet53 网络作为主干网络(BackBone)及PANet 网络作为特征融合模块(Neck)连接于主干网络之后,在其中加入SPP(spatial pyramid pooling)模块,整个网络结构如图1[9-10]所示。
在MS-COCO 数据集上的训练结果如图2所示,YOLOv4 网络的识别准确率为43.5%,帧频为65 帧/s,与YOLOv3 相比,准确率和帧频分别提高了10%和12%,检测准确率以及运行速度都远高于YOLOv3 网络,而且YOLOv4 网络的运行速度是谷歌所开发的EfficientNet 网络的2 倍[11]。
1.1 BackBone 模块
BackBone 模块选用CSPDarknet53 网络进行特征提取,原因有以下3 点:1)与同类型网络相比,此网络能够增强CNN 的学习能力,使得在轻量化的同时保持准确性;2)能够降低计算瓶颈;3)能够降低内存成本[12]。CSPDarknet53 网络包含29 个卷积层和725×725 像素的感受野,共有27.6 M 参数,在原Darknet53 网络每个大残差块的基础上增加了5 个CSP 模块,CSPDarknet53 整体网络结构以及CSP 模块结构如图1 中BackBone 模块所示。其中,CSP 模块前面的卷积核的大小都是3×3,stride 值为2,用以对图像的特征进行下采样。608×608 像素的原始图像经过每个CSP 模块后,像素尺寸分别为304、152、76、38、19,整个CSPDarknet53网络最后输出尺寸为19×19 像素的特征图。各网络层均采用Mish 作为激活函数。
1.2 Neck 模块
Neck 模块整体结构如图3所示,选用两个PANet 作为主要的特征融合网络,并引入SPP 作为附加模块。PANet 结构在原有YOLOv3 的FPN 层后增加了一个自底向上的特征金字塔,使得FPN(feature pyramid networks)层自顶向下传达强语义特征,特征金字塔自底向上传达强定位特征,从不同的主干层对不同的检测层进行参数聚合,达到进一步提高网络的特征提取能力的目的。
其中增加的SPP 模块用以增加网络的感受野,采用1×1 像素、5×5 像素、9×9 像素、13×13 像素的最大池化的方式进行多尺度融合,然后将最大池化的结果在Concat层实现数据拼接,得到特征图层,最后通过1×1 池化将特征图降维到512 个通道。相较于使用单纯的k×k最大池化方式,使用SPP 模块能够更有效地增加主干特征的接收范围,显著分离重要的上下文特征。
1.3 数据增强技巧
采用Mosaic 数据增强对随机4 张图片进行如图4所示缩放、裁剪、排布等拼接操作。经过数据增强后的数据集增加了图片的数量,丰富了小目标样本,从而增强了网络的鲁棒性。在训练过程中,可以直接计算4 张图片的数据,降低了每批次的训练中对数据量的需求,从而降低了网络对硬件的需求,仅使用1 个GPU 就可以达到比较好的训练效果。
采用自对抗训练(self-adversarial training)的方式对数据进行训练。其包括2 个阶段,每个阶段分别进行1 次前向传播和1 次反向传播。第1 阶段,CNN 通过反向传播改变图片信息,而不是改变网络权值,通过这种方式,CNN 可以进行对抗性攻击,改变原始图像,造成图像上没有目标的假象。第2 阶段,训练神经网络,以正常的方式在修改后的图像上检测目标。
采用交叉小批量规范化(cross mini-batch normalization)对数据进行规范化处理,仅在当前批次中进行批规范化处理,仅在单个批次内的小批次之间收集统计信息,进行归一化,这样能够使得检测器更适合在单个GPU 上进行训练。
2 YOLOv4 模型优化
2.1 优化网络模型
原始YOLOv4 网络如图1所示,使用3 个尺度对图像进行训练,识别效果较差。这是由于原网络仅存在3 个检测尺度,对于大中小对象检测效果良好,但对于极小的目标物检测效果较差。因此本文提出一种改进的YOLOv4 网络,在原有3 个检测尺度上加入一个152×152×255 像素的检测尺度,用以检测更小的目标,新设计的网络结构如图5所示。
2.2 模糊ISODATA 动态聚类
模糊ISODATA(iterative self-organizing data analysis techniques algorithm )动态聚类是一种基于目标函数的模糊聚类分析方法,通过动态修正聚类中心的局部优化算法,可以有效地消除传递偏差[13]。在聚类中心数未知情况下,使用模糊ISODATA 动态聚类,同时合理调节迭代参数,聚类效果要好于K-means算法。
用 K-means 和 ISODATA 在 Iris 数据集(鸢尾花数据集)上进行聚类分析,设置不同的初始中心数量,K-means算法和ISODATA算法的聚类效果如图6所示,横坐标分别对应K和Nc,纵坐标F是综合评价信息检索的准确率和召回率的指标。由图6 可知,ISODATA 动态聚类效果优于K-means聚类[14]。
2.3 优化先验框的个数数据集及实验环境
原始YOLOv4 网络由于只有3 个检测尺度,因此先验框的个数只能设置为3 的倍数,在COCO数据集中采用K-means 聚类算法得到9 个先验框(anchor box)的具体尺寸。此聚类方法在新的数据集中通常需要通过人为设置先验框个数,通过对比不同数量先验框时的IOU(交并比)值确定最终的先验框个数。为优化聚类流程,本文采用模糊ISODATA 动态聚类[15]确定先验框的个数以及尺寸。此算法与K-means 相比,增加了模糊矩阵,并且在迭代过程中增加了合并与分裂两个步骤,其目标函数如(1)式所示:
(1)式中:μij为隶属度矩阵中的元素,计算方式如(2)式所示;L为迭代次数;m为类间模糊程度;Xj为第j个样本;Zj为第i个聚类中心。(2)式中:dij为第j个数据到第i个聚类中心的欧式距离。
通过对隶属度矩阵和聚类中心的迭代从而获得目标函数J的极小值。根据最优的目标函数值,即可获得样本最优的聚类中心,根据车辆数据集,利用模糊ISODATA 聚类算法聚类出anchor box 的步骤为
1)根据数据集的标注信息,随机选取聚类中心,初始化12 个anchor box。
2)根据(2)式计算隶属度函数。
3)根据隶属度矩阵以及(3)式计算聚类中心。
4)判断是否进行分裂运算。若满足以下两种情况则,需要进行分裂:一是最终聚类数小于初始设定值的1/2,且需满足迭代运算次数不是偶数次或聚类数不大于初始设定值的2 倍;二是一个聚类中样本距离标准差向量最大值大于样本标准差的阈值,分裂时形成新的聚类中心,其表达式如(4)式所示,其中f为分类系数,σjmax为样本距离标准差向量最大值。
5)判断是否进行合并运算。若各类之间的距离小于各类样本中心之间距离的阈值或某类中样本个数小于设定的数值,则进行合并运算,新的聚类中心计算方式如(5)式所示,其中Zk为第k个聚类中心,Ni为第i样本的个数。
6)计算各样本到各个新的聚类中心之间的距离。
7)计算新的隶属度矩阵。
8)返回步骤3,继续迭代,直至完成计算。
3 实验分析
3.1 数据集及实验环境
本文数据集为人为采集,取自吉林省吉林市某交通路口,从天桥由上至下拍摄图片,图片大小为2 614×1 766 像素,图片总量6 000 张,选择1 000 张作为测试集,其余5 000 张作为训练集。实验需检测的挡风玻璃、车牌、面部和手部不区分类别。实验使用的软硬件环境如表1、表2所示。

表2 软件配置环境参数Table 2 Software configuration environment parameters
3.2 动态聚类结果
经ISODATA 动态聚类,在增加检测尺度后,最佳先验框的个数增加为20 个。为验证此算法的准确率,分别令先验框的个数为4、8、12、16、20、24、28、32,使用K-means 对车辆训练集进行分类,在设置不同先验框个数时,将IOU 的值作为聚类准确率进行对比,此处IOU 值的计算方法为首先计算各类聚类所得出的先验框的尺寸和ISODATA动态聚类中所有标注框的平均IOU 值,再计算各类的IOU 值平均值,此处IOU 值仅计算不同框间的面积,不进行定位,对比结果如表3 及图7所示。由图7 可见,当设定类别大于20 之后,曲线趋于平稳,由此可知,设定类别为20 类比较理想,故而证明,对于车辆要素信息,使用模糊ISODATA算法可以在相对较短的时间内获得较为精确的分类类别,与原网络中所用的K-means 聚类算法相比,不需要提前设定聚类数目;不会由于初始聚类中心的设置而产生较大偏差,具有一定的鲁棒性;实验样本集数据量较大,K-means 聚类算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,算法的时间复杂度较大,而本文所用的模糊ISODATA算法能够较快收敛。
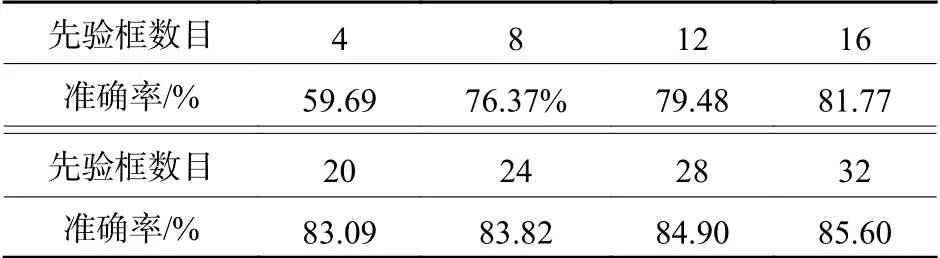
表3 对比结果Table 3 Comparison results
3.3 实验结果
网络batch 设置为64,subdivisions 设置为16,训练次数设置为30 000 次,初始学习率设置为0.001,训练达到15 000 次后,学习率调整为0.000 1。本次实验设置anchors box 为20,原YOLOv4 网络及本文优化YOLOv4 网络在车辆训练集上收敛情况分别如图8(a)、8(b)所示,可见在网络复杂度增加后,收敛速度并没有降低。这说明所设计的新网络在对微小目标物的定位检测时,具有较快的模型训练收敛速度。类间平均准确率、平均IOU、召回率及速度进行对比分析,结果如表4所示。其中:Map.5 表示iou_threash 取值为0.5 时,行驶车辆各检测目标的类间平均准确率;Map.75 表示iou_threash 取值为0.75 时行驶车辆各检测目标的类间平均准确率;R.5 表示iou_threash 取值为0.5 时,各检测目标的类间平均召回率;R.75 表示iou_threash取值为0.75 时,各检测目标的类间平均召回率;Av-IOU 表示平均IOU;FPS 表示每秒检测的图片数量。iou_threash是在计算准确率及召回率时IOU(交并比)的阈值,当预测框与真实框的IOU 大于iou_threash 时才认为预测正确。召回率代表网络检测的效果,召回率越大则网络漏检率越低。Av-IOU 表示回归框的预测准确度,该值越大则表示回归框的大小及位置的预测越准确。在同一个iou_threash 值下,准确率越接近召回率,表明有部分预测框与真实框的IOU 值小于iou_threash 值,则效果越好。本文对比了优化YOLOv4 网络与原YOLOv4网络在iou_threash 为0.5 和0.75 时的召回率(R.5、R.75)、准确率(Map.5、Map.75)和平均IOU(Av-IOU),结果表明本文优化YOLOv4 网络的检测效果优于原YOLOv4网络。

表4 训练集的实验结果Table 4 Experimental results of training set
由实验可知,iou_threash 取0.5 时,YOLOv4 网络的准确率和漏检率的效果最为理想,且优化后的YOLOv4 网络在不同参数时均优于原网络。取iou_threash 为0.5,在测试集中对优化后的网络进行测试,测试后的结果如表5所示,其中使用原始YOLOv4 网络对车牌的识别率最高为98.70%,识别效果较为理想,高于李良荣提出的基于SVM(support vector machine)算法实现车牌的字符识别[16]所用的传统图像处理方法95% 的定位成功率,但驾驶员手部与人脸的识别率较低,尤其是对于驾驶员手部的识别率仅为65.77%,识别效果较差。优化后的YOLOv4 网络的各目标准确率均高于原网络,且优化后的网络平均准确率(mAp)高于原网络9.59%。

表5 测试集的各目标物准确率Table 5 Accuracy rate of each target in test set %
测试集中检测出的部分结果如图9所示。图9(a)中检测效果较理想,均成功识别车牌、车窗、驾驶员脸部以及手部。图9(b)中黄色标签为挡风玻璃,紫色标签为驾驶员面部,绿色标签为驾驶员手部,蓝色标签为车牌,除在强光状态下未识别到驾驶员手部外,在弱光和正常光状态下均可准确检测出挡风玻璃、车牌以及驾驶员的面部和手部动作。在正常光状态下,手部标签位于面部标签左侧,检测出驾驶员正在使用手机通话,属于危险驾驶行为。在强光状态下,由于挡风玻璃反光和驾驶员手部未出现在视线内,导致未识别出驾驶员手部标签。
4 结论
在开放的交通路口,受天气、距离、角度、光照等因素的影响,造成传统车牌检测方法漏检率及误检率较高,在诸多因素影响的复杂环境下,运用YOLOv4算法对车牌进行检测的效果优于传统的车牌检测,但对驾驶员面部等行驶车辆的关键要素检测效果较差,尤其对于手部的检测甚至低于70%。而提出的优化后的YOLOv4 网络不仅在车牌这一目标物中的检测效果表现优秀,测试集上的准确率为98.97%,而且对车体前挡风玻璃、驾驶员人脸以及手部等目标物的检测表现均比较理想。因此,使用优化YOLOv4 网络进行行驶车辆要素定位是一种有效的方式。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
中国卫生统计(2022年2期)2022-05-28
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
自动化学报(2017年5期)2017-05-14
电子制作(2017年22期)2017-02-02
岁月(2016年5期)2016-08-13
探测与控制学报(2015年4期)2015-12-15
中国医疗美容(2015年1期)2015-07-12
中华皮肤科杂志(2014年4期)2014-12-19
