
基于全局注意力机制和LSTM 的连续手语识别算法
2022-04-25 07:16杨观赐韩海峰刘赛赛蒋亚汶李杨
包装工程 2022年8期
杨观赐,韩海峰,刘赛赛,蒋亚汶,李杨
(贵州大学 a.机械工程学院 b.现代制造技术教育部重点实验室 c.省部共建公共大数据国家重点实验室,贵阳 550025)
据全国残疾人调查情况数据显示:中国的听障人数超过2 000 万[1]。听障患者因沟通障碍导致难以融入社会工作,给他们带来沉重压力。手语是听障患者与人交流的最常用方式,但是手语比较抽象,学习成本较高,若不经过系统训练,人们与听障患者交流较为困难[2]。随着人工智能技术的发展,越来越多的研究关注手语识别,试图通过手语识别技术将手语翻译成文本或者语音输出,进而缓解人们与听障患者的沟通障碍[3]。
根据手语数据获取方式的不同,手语识别类型可以分为基于传感器的识别和基于视觉的识别[4]。数据手套和臂环等传感器可以捕获佩戴者的手部关节信息和运动轨迹并识别佩戴者的表达意图。文献[5]针对使用者个体差异的问题,使用双线性模型来处理肌电信号,然后使用LSTM 网络对20 个手语动作进行识别,表现出了较高的识别精度。为减少环境对传感数据的影响,文献[6]针对九轴惯性传感器特性,利用反馈控制融合姿态计算提高姿态获取的实时性,然后对支持向量机、K-近邻法和前馈神经网络分类器进行自适应模型集成进行手语分类,识别率有所提高。文献[7]通过臂环收集手臂的表面肌电信号和惯性传感器数据,经过归一化和滤波处理后,运用滑动窗口分割数据。将单个手语词信号平均分为n组,并每次取出n–1 组按原顺序组合成新数据,进行多次识别,提高连续手语语句识别率。虽然基于传感器的手语识别精度较高,但依赖于硬件设备,并且需要穿戴传感器,导致用户体验较差。
文献[8]使用上下文信息作为先验知识,使用一个生成器从视频序列中提取时空特征来提高手语语句识别连贯性,并用一个判别器对文本信息进行建模以评估生成器的预测效果。文献[9]改进了融合双流3维卷积神经网络模型的相关参数和结构以提高模型的收敛速度和稳定性,使用批量归一化优化网络,在中国手语数据集(CSL)[10-11]识别率达到了90.76%,但是存在网络层数较深、超参数较多等问题,导致网络的训练和优化较困难。关键帧是包含关键手势和语义变换的视频帧,文献[12]根据关键帧图片特征和日常手语习惯,利用卷积自编码器提取视频帧的深度特征,对其进行K-means 聚类,在每类视频帧中选取最清晰的视频帧作为关键帧;再利用手语动作中关键手势时的停顿,通过点密度筛选出视频关键帧以消除冗余信息构建最优序列,但仍然存在一些关键帧丢失的问题。
为提高连续手语识别准确率,围绕手语的手部形状、位置和方向变化多样性等导致的特征信息丢失问题,文中研究了基于全局注意力机制和LSTM 的连续手语识别算法(Continuous Sign Language Recognition Algorithm Based on Global Attention Mechanism and LSTM,CSLR-GAML)。
1 基于全局注意力机制和LSTM 的连续手语识别算法
1.1 CSLR-GAML 算法流程
为快速精确识别视频中的连续手语,此节提出了基于全局注意力机制和LSTM 的连续手语识别算法,见图1。首先,使用帧间差分方法提取手语视频的关键帧,进而去除冗余信息;其次,采用深度残差网络逐个对视频关键帧进行特征提取,并将其转换为时序特征序列;再次,利用LSTM 网络处理经过注意力加权的有用信息,学习到上下文关系;最后经过Softmax网络输出完整的文本信息以达到手语视频识别的目的。算法1 详细流程如下所述。

图1 算法1 的网络架构Fig.1 Network architecture of algorithm 1
算法1:基于全局注意力机制和LSTM 的连续手语识别算法(CSLR-GAML)
输入:Kinect 摄像头采集的时序视频流V。
输出:手语文本S。
步骤1:初始化残差网络、全局注意力机制和LSTM 网络参数,关键帧序列K=Ø,时间窗口大小为8 s,初始时刻t=0 s。
步骤2:如果t能被8 整除,则采用基于差分方法的关键帧提取算法(详见1.2 节)获得V的关键帧序列K。
步骤3:采用基于ResNet 的特征提取算法(详见1.3 节),将关键帧序列K输入至残差网络中,经过卷积和池化操作,提取图像的局部特征f,通过全连接层进行拼接,获得关键帧序列特征向量F。
步骤4:将F作为初始状态输入到LSTM 网络,计算出手语词预测的概率P。
步骤5:采用基于全局注意力机制的LSTM 手语语义信息提取算法(详见1.4 节),更新特征向量权重W输出手语文本S。
步骤6:如果摄像头数据为空,则结束,否则返回步骤2。
1.2 基于差分方法的关键帧提取算法
针对手语视频中存在大量冗余信息的问题,使用差分方法提取关键帧以筛选出视频中的关键信息。通过衡量帧间图像相对平均像素的强度变化来确定关键帧,从而设计基于差分方法的关键帧提取算法。算法2 详细流程如下所述。
算法2:基于差分方法的关键帧提取算法
输入:手语视频流V。
输出:关键帧序列K。
步骤1:初始化K=Ø。
步骤2:对视频流V逐帧进行灰度化处理,经过滤波处理后得到由q张图片构成的集合P={p0,p1,…,pt,…,pq}。
步骤3:对P进行图像二值化操作并求和输出绝对差分值I={I0,I1,…,It,…,Iq}。
步骤4:使用平滑方法去除干扰项峰值,获得新的I={I0,I1,…,It,…,Iq}。之后,计算所有相邻帧间的差分值 |It-It-1|的算术平均值作为标准差分值T。
步骤5:从t=1 开始到t=q,将 |It-It-1|与T进行比较,若 |It-It-1|>T,则K=K∪pt。
步骤6:输出关键帧序列K。
需要说明的是,在步骤2 中,原始图像大小为1 280×720×3,利用加权平均方法的灰度化图像,然后通过高斯滤波,统一图像大小为224×224×3。计算过程见式(1)。

式中:x、y为像素坐标值;σ为像素标准差。
在步骤3 中,利用灰度图像计算所有像素值的均值作为阈值,实现图像二值化。
在步骤4 中,计算标准差分值过程见式(2)。

步骤5 中,通过判定相邻帧间的差分值与T的关系,确定关键帧,判定过程见式(3)。

1.3 基于ResNet 的特征提取算法
ResNet[13]在获取局部特征方面具有优势。为了获得由于光照及背景变化而丢失的特征,设计了基于ResNet 的特征提取算法,以获得更多有效的特征信息。其计算过程见图2,算法3 详细流程如下所述。

图2 基于ResNet 的特征提取过程Fig.2 Feature extraction process based on ResNet
算法3:基于ResNet 的特征提取算法
输入:关键帧序列K。
输出:关键帧序列特征向量F。
步骤1:初始化网络参数,残差块数量n=8,卷积核大小为3,步长为2,F=Ø。
步骤2:对于∀kt∈K:
步骤2.1:将kt输入第一层网络进行卷积和池化操作,得到特征向量。
步骤2.4:i=i+1,若i>8,输出特征向量ft,否则跳到步骤2.3。
步骤 2.5:将ft输入到全局平均池化层生成1×1×512 维的特征向量ft。
步骤2.6:F=F∪ft;t=t+1。
步骤2.7:若t>m,转到步骤3,否则,转到步骤2.1。
步骤3:F={f0,f1,…,ft,…,fm}。
步骤2.1 中输入图像维度为224×224×3,卷积后得到的特征图大小为112×112×64,再经过池化后得到56×56×64 的特征向量,作为残差单元的输入。步骤2.2 中采用线性整流函数作为激活函数,以避免梯度爆炸和梯度消失的问题。
1.4 基于全局注意力机制的LSTM 手语语义信息提取算法
LSTM 作为针对时间序列的训练模型,虽然能够考虑历史信息对当前状态的影响,但是在网络层数多及时间跨度大的情况下,容易丢失有效信息。针对上述问题,文中在LSTM[14]中引入全局注意力机制[15]作为解码器,来考虑每一个时间步长的隐藏状态,与解码器前一步的输出一同输入到下一步解码器中进行运算。与此同时,研究者注意到全局注意力模型的中心思想是在推导上下文向量时考虑编码器的所有隐藏状态。此模型通过对有效信息加权,以提高其与当前隐藏层状态的关联程度,避免信息丢失,以提高识别的准确率。受上述启发,此节提出了基于全局注意力机制的LSTM 手语语义信息提取算法,详细流程见算法4。
算法4:基于全局注意力机制的LSTM 手语语义信息提取算法
输入:F={f0,f1,…,fk,…,fm},手语词库L={l0,l1,…,lt,…,lz}。
输出:文本信息S。
步骤1:随机初始化权重W,S=Ø,k=0;
步骤2:将手语词库L={l0,l1,…,lt,…,lz}导入到Embedding 网络层,利用word2vec 词向量模型生成词向量L′= {l0',… ,lt' , …,lz'}。
步骤3:将高维语义特征向量F与词向量L′经过Padding 操作转换成相同的维度;
步骤4:将fk和L′作为LSTM 网络的原始状态输入,通过注意力加权解码器计算L中每个词lt的预测概率分布;
步骤5:通过softmax 输出概率最大的词lt,S=S∪tl。
步骤6:k=k+1;若k<=m,转到步骤4。
步骤7:输出S。
在步骤1 中,生成空序列S,用于存储手语语义信息;在步骤2 中,手语词库L={l0,l1,…,lt,…lz}包含演示视频所有动作所对应的单词,用于网络识别判断与输出;在步骤4 中,利用LSTM 网络计算由注意力加权过的词向量l't输出词lt的概率tlP,选取概率最大的单词作为输出,解码器输出见式(4)。

式中:ft表示特征向量;lt为手语词库的子集;htw-1表示上下文隐藏状态。遍历F和L′,利用Softmax函数输出预测结果。
2 性能测试与分析
2.1 数据集
选用中国科学技术大学公开发布的中文连续手语视频数据集CSL 作为测试数据集。CSL 数据集由微软 Kinect 摄像头记录,提供RGB 信息、深度信息和肢体骨架信息。文中实验取RGB 信息。选取语料库中100 个主要用于日常交流的句子,每个句子平均由4 个单词组成,共178 个中文单词,数据集中每个句子由50 个不同的表演者完成。其中每一个表演者演示5 次,在这个数据集中一共有25 000 个手语视频。
2.2 评价指标
采用识别准确率(A)评价算法识别性能,以词错误率(W)、B1、Cr、RL及MR评价翻译性能。
1)准确率。识别准确率A的计算过程见式(5)。

式中:TP表示预测样本为正例且实际为正例;TN表示预测样本为负例而实际样本为负例,FP表示预测样本为正例而实际为负例;FN表示预测样本为负例而实际为正例。
2)词错误率。词错误率(W)常用于评判识别出来的词序列和标准的词序列之间的一致性,计算过程见式(6)。

式中:s表示替换词数目;d表示删除词数目;i表示插入词数目;n表示标签句子中的单词数目。在测试时,首先在真实文本中替换、插入或删除一个单词,然后重复这个操作几次。插入或替换的新单词从训练集中的词汇表中选取。这样可以得到一个伪视频文本,与标准文本进行比对从而得到词错误率(W)评价指标。
3)BLEU-1(B1)[16]是手语识别任务中的常见评价指标,主要用于评估翻译语句中的词准确率,其结果可以表示为翻译结果中词的正确匹配次数与所有词出现次数的比值。ROUGE-L(RL)[17]是一种基于召回率的相似性度量方法。用于评价预测结果与实际文本中词的共现率。用于评价手语识别中译文的流畅性METEOR(MR)[18],考虑了基于整个语料库上的准确率和召回率,能够得出最佳识别结果和目标标签之间的准确率和召回率的调和,解决了BLEU 标准中一些固有的缺陷。CIDEr(Cr)[19]指标将每个句子看成文档,通过计算TF-IDF 获取向量余弦距离来度量文本相似性。
2.3 实验设置与比较算法
实验在Dell Tower 5810 工作站上完成,使用Microsoft Kinect V2 深度摄像头,显卡配置为NVIDIA Tesla V100,处理器为Intel Xeon 5218,内存为32 GB,软件环境为:Ubuntu18.04,Python3.7,PyTorch1.7.0,Opencv3.4.2。
实验参数设置如下:epoch 为50,批处理参数为4,编码器学习率设置为0.001,解码器学习率设置为0.004,权重衰减率为0.000 5。
实验过程中将100 个中文句子细分为4 个小的类别,见表1。在每个类别下取10%的视频作为测试数据集,剩余部分作为训练数据集。

表1 数据集的句子类别情况Tab.1 Sentence category of data set
选取5 种手语识别算法作为对比算法进行实验,分别是HLSTM-attn[20]、HMM-DTC[21]、HRF-Fusion[22]、LSTM&CTC[14,23]及S2VT(3 layers)[18]。
2.4 结果与分析
根据表1 的设置运行所提出的CSLR-GAML 算法。c1、c2、c3和c4类别下连续手语视频训练过程中的算法训练准确率统计结果见图3。观察图3 可知,c1的准确率最高,为92.094%;c2的准确率为91.848%;c3的准确率为91.294%;c4的准确率最低,为89.099%。训练过程中,网络在迭代5 次后开始收敛,c1和c2中句子的类型较为单一,组成成分基本为主谓宾结构,在训练过程中表现良好。c3的句子成分稍微复杂,但是重复出现的单词较多,也取得不错的识别效果。c4句子成分复杂,且语句之间差别较大,在训练过程中没有特别好的表现。
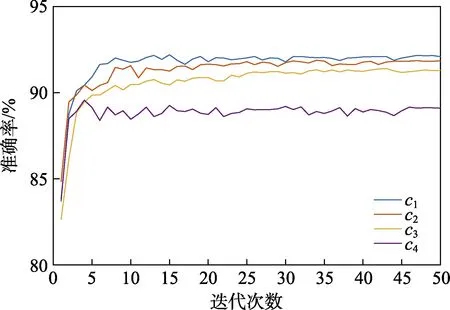
图3 训练准确率Fig.3 Training accuracy
针对以上4 个类别的手语视频识别,分别运行CSLR-GAML,HLSTM-attn[20]、HMM-DTC[21]、HRFFusion[22]、LSTM&CTC[14,23]及S2VT(3 layers)[18]算法,识别准确率A的统计结果见图4 所示。从图4a 可知,HLSTM-attn 算法准确率较高,但算法在不同类别下的识别准确率波动较大,表现不稳定;观察图4b 可知,HMM-DTC 算法在不同类别下的识别准确率波动较小,但识别精度不高;而由图4c—图4e 可知,这些算法对应的盒子图矩形框面积大,这表明在单一类别上的识别准确率分布较散。相反,文中所提算法对应的图4f,不同类别间的矩形分布高度相对一致,矩形框的面积也相对较小,精度也高于比较算法,在4 类数据集的平均识别率准确率是90.08%,这表明此文算法具有更好的识别准确率和鲁棒性。

图4 识别准确率AFig.4 Recognition accuracy a
各算法的B1、Cr、RL、MR及W统计结果见表2。由表2 可知,对比算法在4 个分类中的平均W值分别为0.419、0.728、0.716、0.761、0.608,此文算法的平均W值为41.2%,比其中最好的结果高出0.7%,但是在c4类别中,文中算法的W值略低于HLSTMattn 算法的结果,这表明在小样本无规律词组下此文算法依旧有待改进。在其他指标下,此文算法的表现依然优于其他算法的结果。与最好的HLSTM-attn 算法相比,B1、Cr、RL及MR指标下此文算法分别提高了0.3%、0.9%、0.5%及0.8%。与最差的LSTM&CTC相比,B1、Cr、RL以及MR指标下,文中算法分别提高了27.6%、36.4%、28%以及13.8%。

表2 B1、Cr、RL、MR 及W 统计结果Tab.2 Statistical results of B1, Cr, RL ,MR and W
为了观察各算法的运行效率,分别从4 个类别中选取20 个手语视频段统计其识别的时间,不同算法识别相同数量手语视频段的时间统计结果见表3。观察表3 可知,HLSTM-attn、HMM-DTC、HRF-Fusion、LSTM&CTC 和S2VT 这5 种算法平均运算时间分别为0.564、0.706、0.698、0.656 和0.642 s,此文算法平均运算时间为0.646 s,虽然略差于HLSTM- attn和S2VT 的表现,但优于其他3 种算法。这表明文中算法虽然在识别率上与其他算法存在优势,但是在运算效率上还需要进一步改进。

表3 时间统计结果Tab.3 Time statistics
综上所述,在识别准确率与翻译性能上文中算法优于所比较的5 种算法。
3 结语
高性能的视觉手语识别算法在帮助听障人群日常交流中具有广阔的应用前景,对促进听障人群无障碍融入社会方面具有非常积极的意义。文中提出了一种基于全局注意力机制和LSTM 网络的连续手语识别方法。首先,利用差分方法进行关键帧提取,有效去除冗余帧;然后,使用ResNet 提取图片特征,有效解决由于手语的手部形状、位置和方向变化多样性等导致的特征提取困难问题,避免特征丢失;最后利用全局注意力机制获取更加全面的序列信息,保证算法的识别准确性。实验表明,此文方法在连续手语识别中具有较高的识别性能以及翻译性能。本研究的实验数据集选用RGB 信息,GRB+深度信息实验也是值得深入的工作。与此同时,结合具体的应用场景,研制使用友好的系统是值得进一步推进的方向。
猜你喜欢
中国医院院长(2022年13期)2022-08-15
现代计算机(2022年4期)2022-04-24
作文周刊(高考版)(2019年9期)2019-04-29
计算机与网络(2018年21期)2018-09-10
软件导刊(2018年4期)2018-05-15
电脑知识与技术(2017年3期)2017-03-27
现代电子技术(2016年24期)2017-01-19
感悟(2016年8期)2016-05-14
青少年科技博览(中学版)(2015年8期)2015-10-28
当代贵州(2014年13期)2014-09-21
