
殊途同归:认知诊断与知识追踪*——两种主流学习者知识状态建模方法的比较
2022-04-24 01:29顾小清
现代教育技术 2022年4期
戴 静 顾小清 江 波
殊途同归:认知诊断与知识追踪*——两种主流学习者知识状态建模方法的比较
戴 静 顾小清[通讯作者]江 波
(华东师范大学 教育信息技术学系,上海 200062)
学习者知识状态建模是建立个性化学习系统的重要任务之一。目前,学习者知识状态建模的主流方法有两种,分别是心理测量领域专家提出的认知诊断方法和人机交互领域专家提出的知识追踪方法。为了更恰当地将这两种方法应用于智能教育领域,文章围绕以何建模、如何建模、结果为何、如何应用这四个学习者建模的关键问题,从输入维度的可扩展性、模型参数的可适应性、输出结果的精益求精、助力个性化推荐服务四个方面,对认知诊断方法和知识追踪方法进行论述比较。总的来说,认知诊断方法适用于静态评估且在输出结果方面更为精细化、多样化,而知识追踪方法适用于动态预测且在输入维度方面更具可扩展性。通过研究,文章期望为研究者合理应用这两种方法以服务于个性化学习系统提供参考。
学习者建模;知识状态;认知诊断;知识追踪

近年来,《教育信息化2.0行动》、《中国教育现代化2035》等系列政策均强调利用智能技术辅助实现个性化学习。个性化学习的本质在于,根据学习过程数据对学习者进行全面刻画,据此适时进行学习路径与学习资源推荐等个性化干预[1]。学习者模型作为个性化干预的依据,是个性化学习系统的重要组成模块,可将其看作一组学习者特征的集合,包括知识状态、情感状态、能力状态等[2]。但是,针对学习者情感、能力的建模研究目前还处于探索阶段,个性化学习系统仍以学习者知识状态作为主要的推荐依据[3]。也正因此,如何对学习者知识状态进行建模一直是个性化学习领域关注的重点内容。为此,本研究选取认知诊断与知识追踪这两种学习者知识状态建模的主流方法进行比较,以期为研究者合理应用个性化学习系统提供参考。
一 学习者知识状态建模概述
学习者知识状态建模指通过学习者个体的作答行为与结果数据对个性化的知识状态进行刻画的过程[4]。截至2021年7月24日,在中国知网数据库以“学习者建模”或“学习者模型”为关键词、以“CSSCI”为来源类别,检索到86篇文献;在Web of Science-SSCI引文索引数据库以“Learner model”或“Student model”为关键词,检索到141篇文献。文献分析表明,学习者建模研究关注四个关键问题:①“以何建模”,即采用何种数据作为建模输入;②“如何建模”,即关注模型本身,如模型参数类别与数量等;③“结果为何”,即模型的输出是什么、如何改善当前方法所得结果的局限性等;④“如何应用”,即如何用学习者建模结果服务个性化学习。
就学习者知识状态的建模方法而言,目前有覆盖模型、微分模型、摄动模型、认知诊断、偏差模型、知识追踪等[5]。其中,覆盖模型是通过比较学习者知识与专家知识来发现学习者缺乏的知识技能,而微分模型和摄动模型是基于覆盖模型的改进;认知诊断是对具体的认知加工过程或子技能进行评估;偏差模型是通过学习者的问题解决路径与专家解决路径的偏差,来发现学习者特定知识点的不足;知识追踪是通过学习者与习题的交互数据,预测学习者的知识状态。
认知诊断和知识追踪是被广泛采纳的两种学习者知识状态建模方法[6],但认知诊断来源于心理测量领域,而知识追踪来源于人机交互领域。这两种由跨学科专家提出的看似不相关的方法,在个性化学习系统兴起后相互碰撞,为建立学习者模型提供了有力手段。然而,在个性化学习的实践中,选用哪种方法一般取决于研究者自身特长,鲜有研究对这两种方法进行比较。因此,本研究围绕以何建模、如何建模、结果为何、如何应用这四个学习者建模的关键问题,比较认知诊断和知识追踪这两大学习者建模方法,研究思路如图1所示。
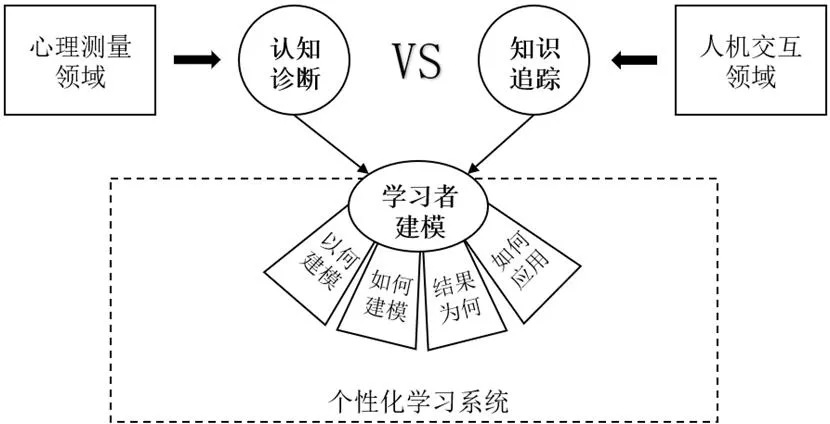
图1 研究思路
二 认知诊断:心理测量领域的建模方法
1 起源
认知诊断(Cognitive Diagnosis,CD)是心理测量领域对认知加工过程或知识技能进行诊断评估的产物[7]。20世纪80年代,随着心理测量学的发展,人们不满足于从宏观上测量和评价学生能力,因而开始探索学习者内部心理的加工过程。于是,继经典测量理论(Classical Test Theory,CTT)、概化理论(Generalizability Theory,GT)和项目反应理论(Item Response Theory,IRT)之后,认知诊断成为新一代测验理论的核心。
2 发展历程
认知诊断的发展历程中有两个里程碑式的模型:一个是1973年Fischer[8]提出的线性逻辑斯蒂特质模型(Linear Logistic Trait Model,LLTM),该模型考虑了正确回答问题所需的认知成分,以各个认知属性的难度代替Rasch模型(单参数逻辑斯蒂模型)中的题目难度参数,由IRT向CD跨越了一大步,但此时LLTM还不能进行认知属性的评估;另一个是1983年Tatsuoka[9]提出的规则空间模型(Rule Space Model,RSM),该模型首创性地使用Q矩阵来代替LLTM中的认知属性难度成分,此后Q矩阵的建立便成为了认知诊断的关键步骤。基于Q矩阵,产生了一系列认知诊断模型,如针对选择题、填空题、判断题等的二级评分认知诊断模型和针对计算题、应用题、作文题等的多级评分认知诊断模型。
3 典型模型
(1)二级评分认知诊断模型
二级评分认知诊断的典型模型包括DINA[10]、DINO[11]、NIDA[12]、NIDO[13]、C-RUM[14]、R-RUM[15]、M2PL[16]等,具体如表1所示。在公式中,q=1,表示题目考察了属性;q=0,表示未考察。a=1,表示学生掌握属性;a=0,表示未掌握。X=1,表示学生对于题目作答正确;X=0,表示作答错误。除通用参数外,每个模型均包含特有参数,如DINA模型包含两个定义在题目水平上的参数,即失误参数s和猜测参数g:若学生掌握了题目考察的所有属性,则作答正确的概率为1-s;反之,则作答正确的概率为g。
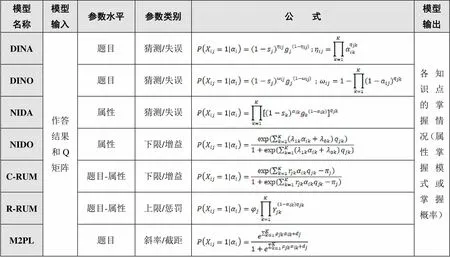
表1 二级评分认知诊断的典型模型
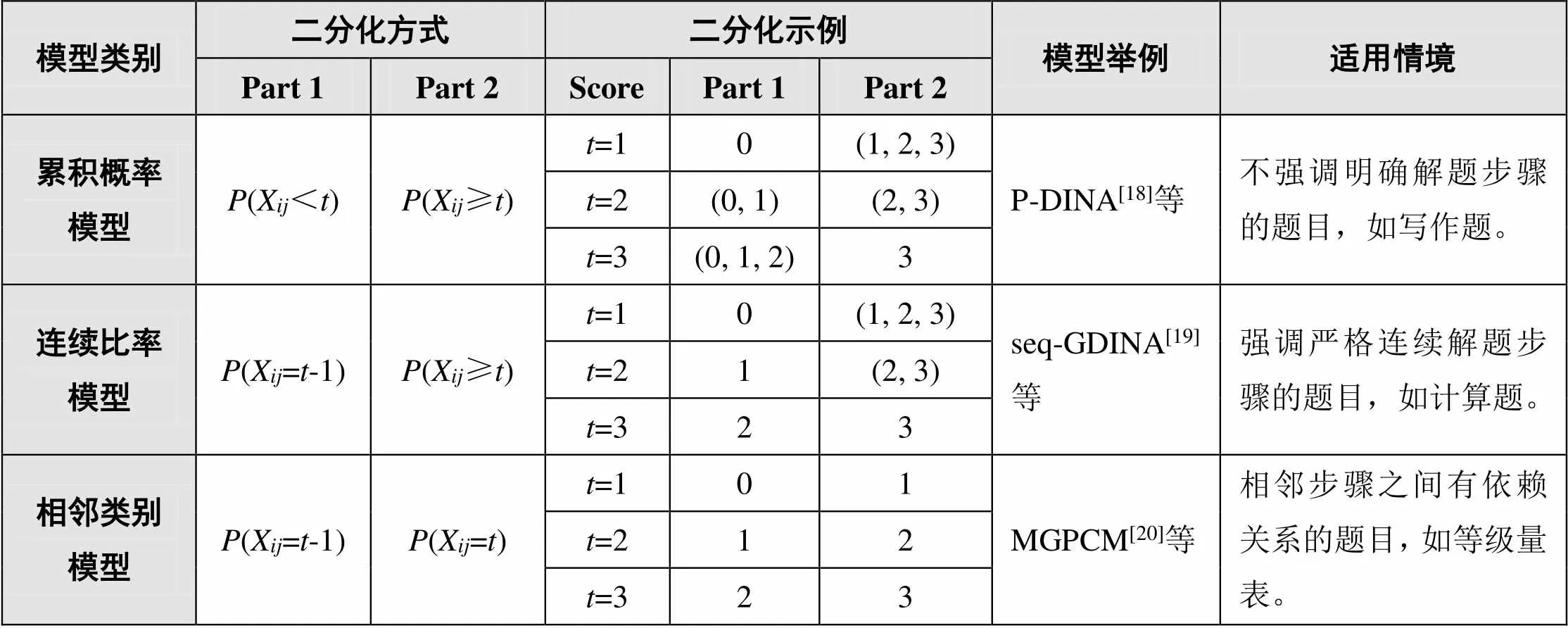
表2 多级评分认知诊断的典型模型
(2)多级评分认知诊断模型
针对多级评分题目的认知诊断模型,本质是对每一个得分等级进行建模,从而将多级评分问题转化为二级评分问题。按照具体二分化转换方法的不同,多级评分认知诊断模型可分为累积概率模型(Cumulative Probability Model)、连续比率模型(Continuation-Ratio Model)和相邻类别模型(Adjacent-Category Model)[17],如表2所示。其中,表示得分等级(Score),若题目的满分为3分,则的取值为{0, 1, 2, 3}。四种得分等级可简单理解为未答对(0)、答对一个步骤(1)、答对两个步骤(2)、全部答对(3)。例如,累积概率模型针对每个得分等级或步骤,将其二分化为(X<)和(X≥);被试在第题恰得分的概率为得分及以上的概率减去得+1分及以上的概率,即(X=t|a)(X≥t|a)-(X≥+1|a)。
三 知识追踪:人机交互领域的建模方法
1 起源
知识追踪(Knowledge Tracing,KT)是计算机科学与心理学结合的产物,由卡内基梅隆大学计算机科学学院人机交互研究所专家Corbett等[21]于1995年引入智能教育领域,后成为个性化学习系统中学习者知识状态建模的主流方法。知识追踪的初衷是对知识习得过程中的知识状态动态建模,确定学习者何时掌握了一项特定技能。知识追踪根据学习者的历史作答行为数据,包括作答题目、题目对应的知识点、作答结果序列,预测下次给定题目的作答结果与知识状态。
2 发展历程
早期的知识追踪研究以贝叶斯知识追踪模型为主,后因深度学习技术的发展,深度知识追踪模型也成为研究热点[22]。自1995年以来,贝叶斯知识追踪的研究主要围绕改善其本身的局限性展开,如贝叶斯知识追踪假设知识状态只分为掌握和未掌握两种、学习者不会遗忘知识点、只针对单个知识点建模等。直至2015年,第一个深度知识追踪模型才出现,即Piech等[23]提出使用循环神经网络(Recurrent Neural Network,RNN)及其变体长短期记忆(Long Short-Term Memory,LSTM)神经网络,来预测学习者的作答结果和知识状态。之后,研究者主要通过增加输入特征[24]、改进神经网络等[25],尝试进一步提升预测效果。
3 典型模型
(1)贝叶斯知识追踪模型
贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)模型本质上可以看作是隐马尔可夫模型(Hidden Markov Model,HMM),如图2所示。其中,(a)部分为HMM的一般形式,包括隐状态(S)、观测状态(y)、初始概率分布、转移概率矩阵和发射概率五个元素。(c)部分为BKT实例,结合(a)部分来看,可知BKT针对单个知识点建模,隐状态为知识点掌握情况,包括掌握(M)或未掌握(N);观测状态为作答结果,包括正确(1)或错误(0)。(b)部分则显示了BKT中影响状态转换的参数,具体有四个:(0),即开始学习之前掌握该知识点的概率;(),即通过学习之后该知识点从未被掌握到被掌握的概率,结合BKT不存在遗忘现象的假设可得转移概率矩阵;(),即未掌握该知识点却答对题目的概率;(),即掌握了该知识点却答错的概率。
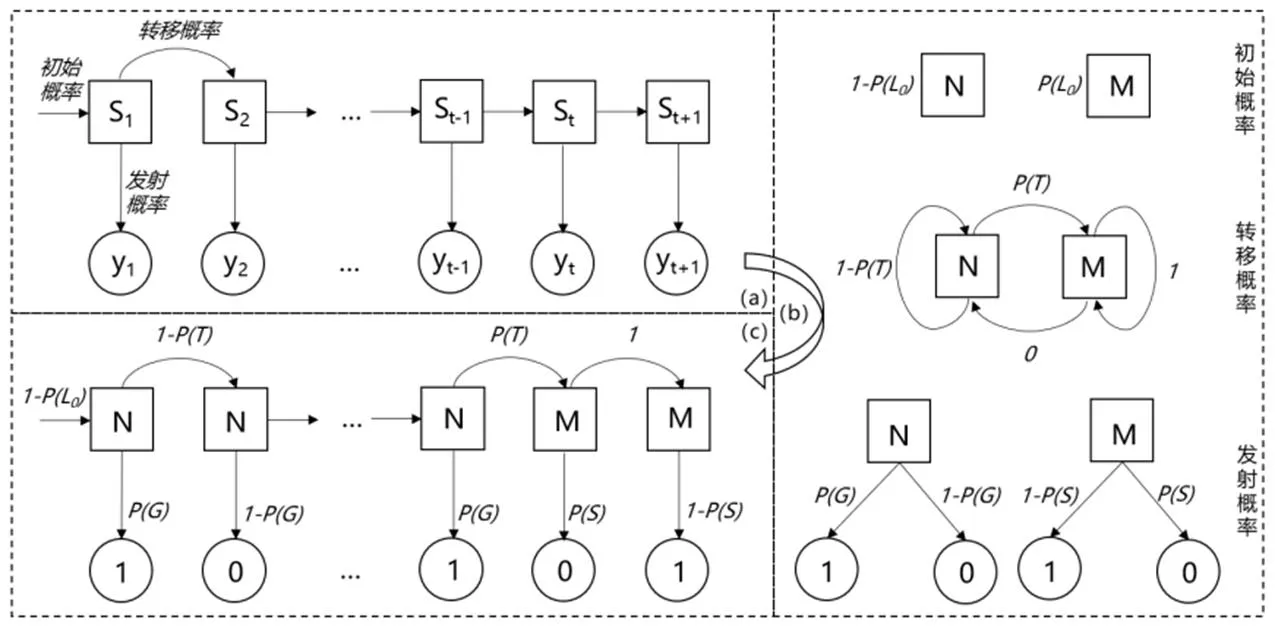
图2 贝叶斯知识追踪模型
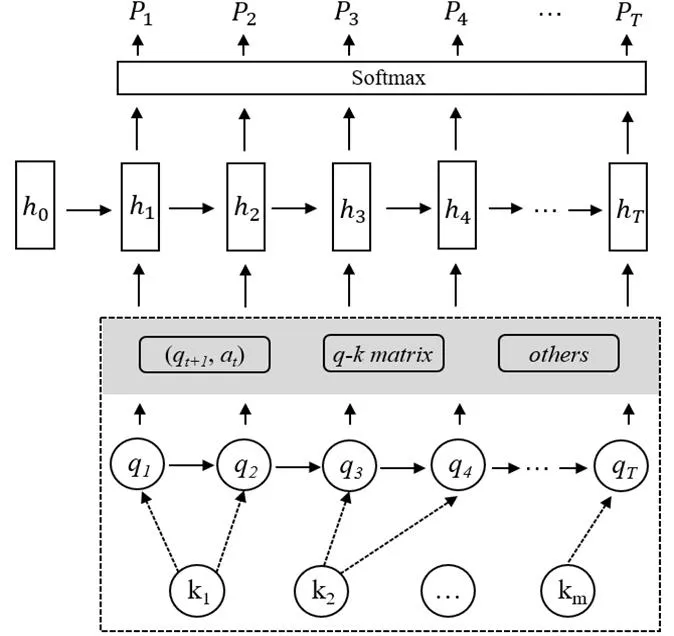
图3 深度知识追踪模型
(2)深度知识追踪模型
深度知识追踪(Deep Knowledge Tracing,DKT)模型将深度学习技术应用于知识追踪任务,如图3所示。学习者在学习过程中进行了多次题目练习(1,2, …,T),每一道题目都标注了知识点(1,2, …,m),将学生在第次之前的作答结果(t={t,t})序列、下一道题编号(t+1)、所有题目与知识点的对应关系矩阵以及其他相关信息作为输入,经过神经网络的隐藏层,在输出层预测第+1次作答时的知识点掌握概率向量t+1。
四 认知诊断与知识追踪的比较
针对学习者建模的四个关键问题“以何建模”“如何建模”“结果为何”“如何应用”,结合对表1、表2、图2和图3的分析,本研究从输入数据、模型参数、输出结果、应用初衷四个维度,对认知诊断和知识追踪的典型模型进行初步比较,结果如表3所示。其中,多级评分认知诊断可以转化为二级评分认知诊断问题,故两者未分开论述;而贝叶斯知识追踪模型与深度知识追踪模型的差异较大,故在下文中将两者分开论述。
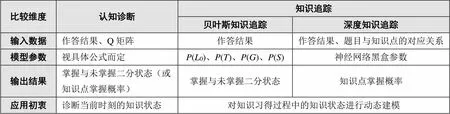
表3 认知诊断与知识追踪典型模型的初步比较
由表3可知,认知诊断与深度知识追踪的输入数据相近,区别在于Q矩阵不仅包括题目与知识点的对应关系,还隐含了知识点之间的层级关系;而贝叶斯知识追踪并非不考虑题目与知识点的对应关系,只是其针对单个知识点建模,所有题目只对应当前这一个知识点,故不会特意列出。从模型参数维度来看,认知诊断的参数根据不同的统计公式而定,表1中已有说明;贝叶斯知识追踪采用HMM统计模型,最典型的贝叶斯知识追踪包括初始掌握概率(0)、学习概率()、猜测概率()、失误概率()四个参数;深度知识追踪则采用不同于统计模型的神经网络结构,其内部参数在教学方面不具有可解释性。从输出结果维度来看,认知诊断和贝叶斯知识追踪通常以掌握或未掌握二分状态来呈现,但前者也可以计算知识点的掌握概率;深度知识追踪通常以知识点掌握概率呈现。从应用初衷维度来看,认知诊断是为了诊断学习者当前时刻的知识状态,而知识追踪是为了通过动态监测来发现学习者何时掌握了某一知识点,但两者本质上都是评估学习者的知识状态。总体而言,认知诊断与知识追踪的输入数据和输出结果相近、模型参数有明显差异,在学习者知识状态建模方面有殊途同归之效。
然而,大规模个性化学习趋势的发展对学习者建模提出了进一步的要求。就“以何建模”而言,需在输入数据中尝试增加各项影响学习者知识状态的因素;就“如何建模”而言,需探索能够体现知识状态个性化特征的模型参数;就“结果为何”而言,需不断思考如何改善当前方法所得结果的局限性;就“如何应用”而言,需明确各建模方法的应用场景与应用方法。为满足这四个方面的需求,认知诊断与知识追踪都进行了持续的扩展研究。
1 以何建模:输入维度的可扩展性
学习者建模的输入维度正在从单一化向多维化转变,可扩展性成为学习者建模的需求之一。以往,评估学习者的知识状态多从作答结果(对错、得几分)单一维度来看;后来,随着大数据技术及各种数据采集设备的完善,学习者信息维度(如作答行为、情绪、个性特征)、知识点信息维度(如知识点之间的层级关系)等影响评估结果的因素也被纳入建模维度。
①学习者信息维度。贝叶斯知识追踪模型一般通过增设节点变量或外生变量的形式,来扩展学习者信息维度;节点变量扮演外显证据的角色,如Spaulding等[26]尝试通过增加情绪观测节点(微笑、困惑等)来提高预测性能;外生变量扮演影响因素的角色,如González-Brenes等[27]提出了一个类似非齐次隐马尔可夫模型的知识追踪框架,该框架可纳入影响状态转移概率、发射概率的各种特征。深度知识追踪模型的本质形式是深度神经网络,本就可以接受多维输入,如Zhang等[28]增加学习者第一次作答尝试的时间、尝试的次数等行为数据,作为深度知识追踪的输入维度。相比而言,在认知诊断模型中增加学习者信息维度的研究目前并不多见。
②知识点信息维度。认知诊断模型的Q矩阵中已隐含了知识点之间的层级关系,即大多数认知诊断模型已默认将知识点之间的关系维度作为输入。贝叶斯知识追踪模型只针对单个知识点进行建模,一般不考虑知识点关系维度;但也有少数研究者对此进行了尝试,如Huang等[29]提出了融入知识层级关系的贝叶斯网络建模框架。深度知识追踪模型可对多个知识点进行建模,知识点之间的关系作为一个研究点备受关注,如Chen等[30]尝试以顺序配对的形式将知识点之间的先决关系作为模型的输入。值得一提的是,深度知识追踪模型中每道题或每道题的某一个步骤通常只与一个知识点挂钩,将多个知识点一起考察,本质上是不同知识点顺序上的交叉练习,而非真正的混合练习。
总体来说,认知诊断模型均为概率公式的形式,无法灵活地增加学习者行为、情绪等维度。贝叶斯知识追踪模型只针对作答结果单一维度建模,但可利用贝叶斯网络本身的可塑性来增加其他维度。深度知识追踪模型以人工神经网络为载体,扩展输入维度正是其优势的体现。因此,在输入维度方面,知识追踪模型比认知诊断模型更具可扩展性。
2 如何建模:模型参数的可适应性
认知诊断与知识追踪的建模过程相同,大体可分为数据采集和参数估计(或模型训练)。模型的参数是体现模型差异的重要方面,通过各类参数以准确表征每一个学习者的知识状态是建模的关键任务。刻画知识状态的参数大致可分为三个层面:题目层面、属性层面和学习者层面,这三个层面分别针对每一道题、每一个属性或每一个学习者设置适应性参数。以“猜答案”这一现象为例,若将参数置于题目层面,可解释为不同题目被猜对的概率是不同的;若将参数置于属性层面,可解释为不同知识点未被掌握却被成功应用的概率是不同的;若将参数置于学习者层面,则可解释为不同学习者猜对题目的概率是不同的。无论是典型模型的常规参数,还是后期扩展研究的新增参数,都体现了这三个层面的适应性。
①常规参数。在认知诊断模型中,既有针对题目层面的参数建模,如DINA、DINO模型中的猜测和失误参数;也有针对属性层面的参数建模,如NIDO模型中的下限和增益参数;还有针对属性和题目交叉层面的参数建模,如R-RUM模型中的惩罚参数。贝叶斯知识追踪模型是针对属性层面的参数建模,即当所有学习者就同一知识点对所有题目进行作答时,其所拥有的初始掌握概率、学习概率、猜测概率、失误概率这四个参数是一样的。后来,有研究者在题目层面进行了适应性尝试,如Pardos等[31]提出KT-IDEM模型,赋予每道题一个猜测概率和一个失误概率,那么道题就有2×+2个参数。也有研究者在学习者层面进行了适应性尝试,如Pardos等[32]提出对于同一知识点,每个学习者应拥有个性化的初始掌握概率和学习概率;Lee等[33]的研究表明,拥有适应性参数的模型比典型模型更具有教学指导意义。而在深度知识追踪模型中,由于深度学习技术的“黑盒”特质,神经网络层之间的权重等参数暂不具有可解释的教学意义。
②新增参数。遗忘特性是后期研究尝试最多的新增参数。贝叶斯知识追踪模型假设学习者不存在遗忘现象,但Qiu等[34]发现该模型对于学习者的预测表现(一天或更长时间之后)优于实际情况,于是提出可按照是否为学习当天分别采用不同属性层面的遗忘参数——当天的遗忘参数(s)和第二天及以后的遗忘参数(n);而Nedungadi等[35]依据上次尝试作答和当前尝试作答的具体时间间隔,提出以时间衰减函数的形式引入遗忘参数。深度知识追踪模型虽然无法直接增加具有显著教育意义的遗忘参数,但可在输入参数中增加同一知识点最近两次作答之间的时间间隔、无知识点限制情况下最近两次作答之间的时间间隔等体现遗忘特性的信息[36]。认知诊断模型本意是针对测验情境而未考虑遗忘特性的典型模型。
总体来说,在认知诊断模型中,针对题目层面、属性层面、属性与题目交叉层面的参数建模均已进行了尝试,并已开发出相应的模型。贝叶斯知识追踪模型的参数都属于属性层面,但可通过题目层面和学习者层面进一步细化,以赋予每一道题或每一个学习者个性化的特征。深度知识追踪模型的参数不可解释,暂不具有显著的教学意义。值得一提的是,选择不同层面的参数,仅意味着采用不同的建模思路,并无优劣之分。
3 结果为何:输出结果的精益求精
学习者建模的目的就是获得准确、精细的知识状态。就输出结果的精细化程度而言,有些模型仅可展示是否掌握的离散值,有些模型却可展示具体掌握程度的连续值。就输出结果的准确度而言,除增加输入数据、丰富模型参数外,建模时还应在一定程度上考虑各种因素,如一道题考察多个知识点,掌握一道题中涉及几个知识点才可能答对该题、该知识点是否被标全等。
①输出结果的精细化程度。认知诊断模型通常以是否掌握二元状态来描述,但实质上二元状态是在计算概率值后划分而来的;也有少数多维IRT模型以能力值(通常取值范围为[-4, +4])来表征每一个知识维度的掌握情况。贝叶斯知识追踪模型的输出结果依赖于HMM框架中的隐状态,通常为掌握、未掌握两种;也有研究者尝试进行更为精细化的划分,如Zhang等[37]提出在二分知识掌握情况中间加入过渡状态,将建模结果分为三种:掌握、可能掌握、未掌握。深度知识追踪模型可获得学习者对每一个知识点的掌握概率,其范围为0~1之间的连续值。
②输出结果的准确度。对于一道题考察多个知识点的现象,现实生活中并不少见。认知诊断模型相关研究对此思考较多,并衍生出各种模型。例如,掌握一道题中涉及的几个知识点才可能答对该题,针对这一问题,不同的认知诊断模型采用了不同的假设:DINA模型假设所有知识点全部掌握才能答对;DINO模型假设只要掌握其中一个知识点就可能答对;R-RUM模型则假设随着掌握的知识点数量增加,答对的概率随之增加。又如,针对一道题考察了多个知识点但知识点并未标注完全的情况,RUM模型作为R-RUM简化前的版本,增加了一个参数表示Q矩阵以外被忽略的残余能力。贝叶斯知识追踪模型并没有考虑到这一问题,但也有Xu等[38]尝试采用动态贝叶斯网络追踪每一个知识点。深度知识追踪模型的相关研究也不多,Xiong等[39]表示DKT在处理该问题时将单条作答记录扩展成多条记录,这是DKT的效果显著优于BKT的原因;但是,DKT的输出结果存在波动性,即调换答题顺序后所得的知识状态结果不同。
总体来说,认知诊断模型的建模结果既可以是连续值,也可以是离散值,且对一道题考察多个知识点等细节问题做出了良好的应对。贝叶斯知识追踪模型的建模结果只有掌握或未掌握两种值,虽然也有研究尝试突破二元状态,但由于HMM模型本身隐状态的限制,使其只能在离散状态的个数上进行突破,并不能将离散过渡改为连续过渡。深度知识追踪模型可通过权重参数计算0~1之间的连续值,准确度也优于贝叶斯知识追踪,但存在结果波动性的问题。
4 如何应用:助力个性化推荐服务
学习者建模的价值不止于获得学习者知识状态,更重要的是应用建模结果进行个性化推荐。首先,需明确认知诊断和知识追踪两种方法在个性化学习系统中的应用场景,这是保证建模结果的第一步。然后,根据建模结果,应用可行的方法为学习者提供个性化学习资源推荐等服务。
①应用场景。认知诊断适用于短时间内可完成的测试或作业场景,而知识追踪更适用于持续性的日常练习场景。具体来说,用于认知诊断模型的作答数据,一般是在学习者知识状态未发生改变的时间范围内;而知识追踪是为了在学习者进行知识习得的过程中,对动态变化的知识状态进行建模。从模型本身也可看出,用于贝叶斯知识追踪的贝叶斯网络和用于深度知识追踪的循环神经网络本就是针对时序问题的模型;对于相同的题目和相同的答案,若做题顺序不同,知识追踪模型得到的知识状态结果也会不同。
②应用方法。根据认知诊断和知识追踪方法获得认知优势与劣势后,一方面可直接推荐与未掌握知识点相对应的资源,以进行针对性补救;另一方面可与协同过滤、矩阵分解等推荐领域常用的方法结合提供学习者知识状态信息,以提高推荐的有效性。除此通用方法之外,认知诊断特有一种已成体系的推荐方法——认知诊断自适应测试(Cognitive Diagnostic Computerized Adaptive Testing,CD-CAT)中的选题算法,其本意是高效测量学习者的知识状态及能力水平,本质上也是针对每一个学习者予以个性化题目推荐。
总体来说,认知诊断和知识追踪方法的出发点不同,前者为静态诊断,尤其适用于测试场景;后者为动态预测,更适用于能够体现知识状态变化的知识习得过程。认知诊断和知识追踪均可与协同过滤、矩阵分解等常用方法相结合,以实现学习资源的有效、个性化推荐。但相较于知识追踪而言,认知诊断还可借鉴自适应测试中的选题策略向每个学习者推荐个性化题目。
五 结论与建议
本研究围绕学习者建模需要考虑的四个关键问题,即以何建模、如何建模、结果为何、如何应用,论述分析认知诊断和知识追踪这两种方法的特点及优劣势。总结来说,在输入维度方面,知识追踪比认知诊断更具可扩展性;在模型参数方面,两者采用的建模思路不同,因而参数类别不同;在输出结果方面,认知诊断比知识追踪更为精细化、多样化;在建模应用方面,认知诊断适用于静态评估,而知识追踪适用于动态预测。
为了合理采用这两种方法以服务于智能教育领域,本研究提出以下建议:①针对两种方法的优劣势进行算法的整合与改进研究。例如,Wang等[40]提出神经认知诊断框架,既保留了认知诊断方法的准确性和可解释性,又纳入了神经网络结构较强的函数拟合能力,可以说综合了认知诊断和深度知识追踪两种方法的优势。②根据场景和数据源来选择学习者建模方法。若是根据个性化学习系统中的自适应测试或普通测试场景做题数据来刻画学习者知识状态,建议选择认知诊断方法;若是根据有智能提示的导学场景做题数据来刻画学习者知识状态,则建议选择知识追踪方法——若是拟纳入学习风格、答题时长、作答尝试次数等数据来刻画学习者知识状态,尤其建议选择深度知识追踪模型。
[1]Pardo A, Jovanovic J, Dawson S, et al. Using learning analytics to scale the provision of personalised feedback[J]. British Journal of Educational Technology, 2019,(1):128-138.
[2]Normadhi N B A, Shuib L, Nasir H N M, et al. Identification of personal traits in adaptive learning environment: Systematic literature review[J]. Computers & Education, 2019,(3):168-190.
[3]万海鹏,余胜泉,王琦,等.基于学习认知地图的开放学习者模型研究[J].现代教育技术,2021,(4):97-104.
[4]黄涛,王一岩,张浩,等.智能教育场域中的学习者建模研究趋向[J].远程教育杂志,2020,(1):50-60.
[5]张舸,周东岱,葛情情.自适应学习系统中学习者特征模型及建模方法述评[J].现代教育技术,2012,(5):77-82.
[6]Abyaa A, Khalidi I M, Bennani S. Learner modelling: Systematic review of the literature from the last 5 years[J]. Educational Technology Research and Development, 2019,(5):1105-1143.
[7]Henson R, Douglas J. Test construction for cognitive diagnosis[J]. Applied Psychological Measurement, 2005,(4):262-277.
[8]Fischer G H. The linear logistic test model as an instrument in educational research[J]. Acta Psychologica, 1973,(6):359-374.
[9]Tatsuoka K K. Rule space: An approach for dealing with misconceptions based on item response theory[J]. Journal of Educational Measurement, 1983,(4):345-354.
[10][12]Junker B W, Sijtsma K. Cognitive assessment models with few assumptions, and connections with nonparametric item response theory[J]. Applied Psychological Measurement, 2001,(3):258-272.
[11]Templin J L, Henson R A. Measurement of psychological disorders using cognitive diagnosis models[J]. Psychological Methods, 2006,(3):287-305.
[13]Rupp A A, Templin J, Henson R A. Diagnostic measurement: Theory, methods, and applications[M]. New York: Guilford Press, 2010:131-135.
[14]Maris E. Estimating multiple classification latent class models[J]. Psychometrika, 1999,(2):187-212.
[15]Hartz S, Roussos L. The fusion model for skills diagnosis: Blending theory with practicality[R]. Princeton, NJ: Educational Testing Service, 2008:5-10.
[16]Reckase M D. Multidimensional item response theory[M]. New York, NY: Springer, 2009:86.
[17]高旭亮,龚毅,王芳.多级评分认知诊断模型述评[J].心理科学,2021,(2):457-464.
[18]涂冬波,蔡艳,戴海琦,等.一种多级评分的认知诊断模型:P-DINA模型的开发[J].心理学报,2010,(10):1011-1020.
[19]Ma W, Torre J de la. A sequential cognitive diagnosis model for polytomous responses[J]. British Journal of Mathematical and Statistical Psychology, 2016,(3):253-275.
[20]Yao L, Schwarz R D. A multidimensional partial credit model with associated item and test statistics: An application to mixed-format tests[J]. Applied Psychological Measurement, 2006,(6):469-492.
[21]Corbett A T, Anderson J R. Knowledge tracing: Modeling the acquisition of procedural knowledge[J]. User Modeling and User-adapted Interaction, 1995,(4):253-278.
[22]张暖,江波.学习者知识追踪研究进展综述[J].计算机科学,2021,(4):213-222.
[23]Piech C, Spencer J, Huang J, et al. Deep knowledge tracing[A]. Proceedings of the 28th International Conference on Neural Information Processing Systems[C]. Massachusetts: MIT Press, 2015:505-513.
[24][28]Zhang L, Xiong X, Zhao S, et al. Incorporating rich features into deep knowledge tracing[A]. Proceedings of the 4th ACM Conference on learning@scale[C]. New York: Association for Computing Machinery, 2017:169-172.
[25]Zhang J, Shi X, King I, et al. Dynamic key-value memory networks for knowledge tracing[A]. Proceedings of the 26th International Conference on World Wide Web[C]. New York: Association for Computing Machinery, 2017:765-774.
[26]Spaulding S, Breazeal C. Affect and inference in Bayesian knowledge tracing with a robot tutor[A]. Proceedings of the10th Annual ACM/IEEE International Conference on Human-Robot Interaction Extended Abstracts[C]. New York: Association for Computing Machinery, 2015:219-220.
[27]González-Brenes J, Huang Y, Brusilovsky P. General features in knowledge tracing to model multiple subskills, temporal item response theory, and expert knowledge[A]. Proceedings of the 7th International Conference on Educational Data Mining[C]. Massachusetts: International Educational Data Mining Society, 2014:84-91.
[29]Huang Y, Hollstein J D G, Brusilovsky P. Modeling skill combination patterns for deeper knowledge tracing[A]. Proceedings of the 24th International Conference on User Modeling, Adaptation, and Personalization (Extended Proceedings)[C]. Berlin: Springer, 2016:1-9.
[30]Chen P, Lu Y, Zheng V W, et al. Prerequisite-driven deep knowledge tracing[A]. Proceedings of 2018 IEEE International Conference on Data Mining (ICDM)[C]. Piscataway: The Institute of Electrical and Electronics Engineers, 2018:39-48.
[31]Pardos Z A, Heffernan N T. KT-IDEM: Introducing item difficulty to the knowledge tracing model[A]. Proceedings of the 19th International Conference on User Modeling, Adaptation, and Personalization[C]. Berlin: Springer, 2011:243-254.
[32]Pardos Z A, Heffernan N T. Modeling individualization in a Bayesian networks implementation of knowledge tracing[A]. Proceedings of the 18th International Conference on User Modeling, Adaptation, and Personalization[C]. Berlin: Springer, 2010:255-266.
[33]Lee J I, Brunskill E. The impact on individualizing student models on necessary practice opportunities[A]. Proceedings of the 5th International Conference on Educational Data Mining[C]. Massachusetts: International Educational Data Mining Society, 2012:118-125.
[34]Qiu Y, Qi Y, Lu H, et al. Does time matter? Modeling the effect of time with Bayesian knowledge tracing[A]. Proceedings of the 4th International Conference on Educational Data Mining[C]. Massachusetts: International Educational Data Mining Society, 2011:139-148.
[35]Nedungadi P, Remya M S. Incorporating forgetting in the personalized, clustered, Bayesian knowledge tracing (pc-bkt) model[A]. Proceedings of 2015 International Conference on Cognitive Computing and Information processing[C]. Piscataway: Institute of Electrical and Electronics Engineers, 2015:353-357.
[36]Nagatani K, Zhang Q, Sato M, et al. Augmenting knowledge tracing by considering forgetting behavior[A]. Proceedings of the 28th International Conference on World Wide Web[C]. New York: Association for Computing Machinery, 2019:3101-3107.
[37]Zhang K, Yao Y. A three learning states Bayesian knowledge tracing model[J]. Knowledge-Based Systems, 2018, 148:189-201.
[38]Xu Yanbo, Jack Mostow. Using logistic regression to trace multiple sub-skills in a dynamic Bayes net[A]. Proceedings of the 4th International Conference on Educational Data Mining[C]. Massachusetts: International Educational Data Mining Society, 2011:241-246.
[39]Xiong X, Zhao S, Van Inwegen E G, et al. Going deeper with deep knowledge tracing[A]. Proceedings of the 9th International Conference on Educational Data Mining[C]. Massachusetts: International Educational Data Mining Society, 2016:545-550.
[40]Wang F, Liu Q, Chen E, et al. Neural cognitive diagnosis for intelligent education systems[A]. Proceedings of the AAAI Conference on Artificial Intelligence[C]. Palo Alto: Association for the Advancement of Artificial Intelligence, 2020:6153-6161.
All Roads Lead to Rome: Cognitive Diagnosis and Knowledge Tracing——A Comparison of Two Modeling Methods for Mainstream Learners’ Knowledge State
DAI Jing GU Xiao-qing[Corresponding Author]JIANG Bo
The modeling of learners’ knowledge state is one of the important tasks to build a personalized learning system. At present, there are two main mainstream methods for modeling learners’ knowledge state, namely the cognitive diagnosis method proposed by experts in the field of psychometrics and the knowledge tracking method proposed by experts in the field of human-computer interaction. In order to more properly apply the two methods to the field of intelligent education, this paper focused on the four issues of what to model, how to model, what the result is, and how to apply, discussed and compared cognitive diagnosis and knowledge tracking methods from four aspects of the scalability of input dimensions, the adaptability of modeling parameters, the refinement of output results, and the assistance of personalized recommendation services. In conclusion, the cognitive diagnosis was suitable for static evaluation and was more refined and diversified in terms of output results, while the knowledge tracking model was suitable for dynamic prediction and was more scalable in terms of input dimensions. Through research, this paper hoped to provide reference for researchers to apply these two methods reasonably to serve the personalized learning system.
learner modeling; knowledge state; cognitive diagnosis; knowledge tracing
G40-057
A
1009—8097(2022)04—0088—11
10.3969/j.issn.1009-8097.2022.04.010
基金项目:本文受上海市“科技创新行动计划”人工智能科技支撑专项“教育数据治理与智能教育大脑关键技术研究及典型应用”(项目编号:20511101600)资助。
戴静,在读博士,研究方向为学习分析与计算机测评,邮箱为925613528@qq.com。
2021年7月30日
编辑:小时
猜你喜欢
法律方法(2021年4期)2021-03-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
科技资讯(2014年13期)2014-11-10
科技经济市场(2014年5期)2014-09-09
郑州大学学报(理学版)(2014年2期)2014-03-01
现代防御技术(2014年6期)2014-02-28
