
注意力引导网络的显著性目标检测
2022-04-24 09:53何伟潘晨
中国图象图形学报 2022年4期
何伟,潘晨
中国计量大学信息工程学院,杭州 310018
0 引 言
视觉注意是人类视觉系统的有效机制,可将有限的脑资源用于场景中最重要信息的处理,是人类视觉高效率、高精度与通用性的基础。计算机视觉的目标之一是通过建模模拟视觉注意,称为视觉显著性检测,主要有注视点预测(Huang等,2015)和显著目标检测(Borji等,2015)两个研究分支。注视点预测是预测人眼视线在自然图像上的落点;显著目标检测则是定位场景中显著目标的位置,分割出显著物体的形状,已经广泛应用于图像编辑(Qin等,2018;Cheng等,2010)、图像分割(Mechrez等,2018)、视觉跟踪(Lee和Kim,2018;Ma等,2017)和机器人导航(Craye等,2016)等领域。视觉注意可以分为自底向上(bottom-up)的注意和自顶向下(top-down)的注意。其中自底向上的注意机制是数据驱动的、快速而不依赖具体任务的;而自顶向下的注意常常是任务驱动的,即在人的意识控制下对图像目标进行关注。
传统方法(Liu等,2011;Wang等,2017a;Yan等,2013)通常是bottom-up注意,依赖对物体的启发性假设,如对比度先验、边界先验、中心先验(Aksac等,2017;Liang等,2018)和背景先验等,使用底层视觉特征如亮度、颜色和运动等检测显著物体,但由于缺乏高层语义信息,限制了传统方法在复杂场景中检测显著物体的能力。
近年来,深度学习模型实现了top-down注意。其中,卷积神经网络(convolutional neural network,CNN)的金字塔结构能实现对浅层语义信息的提取,并可通过多次卷积和池化操作获得高层语义信息。鉴于卷积神经网络,特别是全卷积神经网络(fully convolutional neural network,FCN)展现的强大特征提取能力,学者们提出了多种显著性检测模型,极大促进了显著目标检测技术的发展。众所周知,浅层网络能保持较大空间尺寸的低层特征,其中包含了细节信息(Luo等,2017;Zhang等,2017),如纹理、边界和空间结构等,但同时也包含着更多的背景噪声。而网络深层产生的高级特征则包含更多抽象的语义信息,有利于定位显著对象的准确位置和抑制噪声,但在下采样过程中丢失了一些目标的细节信息。所以在显著性检测任务中,高层特征往往用于显著目标在输入图像上的粗定位,而包含丰富细节信息的浅层特征则用来细化显著目标的边界。Liu和Han(2016)以递归的方式细化特征映射,结合多尺度特征信息(Hou等,2019)或者在显著性映射上添加额外的约束(如边界损失项(Qin等,2019;Zhang等,2018b))。该模型与U-Net(Ronneberger等,2015)网络类似,分为编码与解码两个阶段。编码器部分通常使用迁移学习的方法,由一个预先训练好的分类模型如ResNet(residual neural network)(He等,2016)构成,用于提取输入图像在不同语义层次和分辨率的多层特征;在解码器阶段,主要是将编码部分提取出来的多层特征进行适当的组合,生成相应的显著图。
深度学习模型中具有注意力机制。通道注意力机制即学习单个像素点在各个通道维度上的权重关系,并应用到所有像素区域;空间注意力机制则是学习特征在单通道空间尺寸上各个像素的权重关系,并应用到不同通道的特征图上。注意力机制可以通过对不同位置和通道的图像特征加权,自适应地关注重要区域,并且应用于不同的计算机视觉任务(Chu等,2017)。由于注意力机制的优越性,一些学者将注意力机制运用于显著性检测任务(陈凯和王永雄,2020;项圣凯 等,2020),但是通常只使用单种注意力机制。
尽管基于FCN的方法已经取得了良好的性能,但仍然存在许多挑战。1)没有考虑不同特征对显著目标的贡献差异。在编码阶段,不同层次的特征信息具有不同的特征分布,而在解码阶段需要将高层抽象的语义信息逐渐传递到较浅的层,在上采样过程中,从较深层获取的位置信息可能会逐渐稀释。所以为了生成更精确的显著图,通常将不同层次的特征结合起来,但是如果不对结合的信息进行合理的筛选控制,来自低层的噪声以及高层的模糊边界等冗余信息会导致精度下降。2)在显著性检测任务中,通常使用二元交叉熵(binary cross-entropy,BCE)损失作为损失函数训练监督显著图与真实图之间的关系,然而交叉熵损失是平等对待每一个像素,往往置信度比较低。3)忽略了上下文信息对提取显著区域的重要性,导致生成的显著图会遗漏整个目标的一部分。如图1(c)(d)所示。
本文在特征金字塔网络(feature pyramid network,FPN)(Lin等,2017)的基础上提出了一个基于通道—空间注意力引导的聚合网络AGNet(attention-guided network)用于显著性目标检测。图1展示了本文模型与同样使用注意力机制的PAGR(progressive attention guided recurrent network)和RANet(recurrent attentional networks)模型的可视化对比。本文模型改进措施如下:1)为了获取更丰富的上下文信息和更大的感受野,在编码器模块之后引入特征提取模块(feature extraction module,FEM),以不同采样率的空洞卷积并行采样,多比例捕捉图像的上下文。如图1(e)第1行所示,本文模型用大的卷积核获取更大的感受野和上下文信息,很好地获得了显著目标的全部信息,而参与对比的两个注意力机制的模型PAGR和RANet存在目标信息缺失的问题。2)高级语义可以提供显著目标的位置信息,而浅层特征提供纹理和边界细节。为了实现不同层次结构间特征的有效融合,设计了通道—空间注意力聚合模块(channel-spatial attention aggregation module,C-SAAM)。在高级语义上使用通道注意力机制,以选择显著物体的特征;在较浅特征层使用空间注意力机制提取高级特征和浅层特征之间的共享部分,筛选图像纹理细节。这种有选择性的融合策略有助于抑制冗余信息,减少特征间的干扰,更突出重要特征,产生精细的边界和自适应语义信息。与Zhang等人(2018c)提出的PAGR(progressive attention guided recurrent network)和Chen等人(2018)提出的RANet(reverse attention network)相比,本文设计了新的结构,使用1 ×k和k× 1的卷积操作作为模块中空间注意力机制的基底,可以给予特征左右和上下方向的注意,对背景噪声的过滤更加有效。同时在此模块的最后,将通道注意力引导的深层特征与空间注意力引导的浅层特征进行结合,有助于避免空间注意力过滤掉目标信息导致信息缺失。如图1(e)第2行所示,本文模型将深层特征和浅层特征进行聚合,检测结果更加精确,而对比模型没有过滤掉属于背景的鱼。3)为了获取更精细的边界,设计了注意力残差细化模块(attention residual refinement module,ARRM)对聚合的特征图进一步处理,使生成的显著图更清晰精确。如图1(e)第3行所示,本文模型生成的目标显著图边界更清楚。

图1 不同模型的可视化对比图Fig.1 The visual comparison of different methods((a)original images;(b)ground truth;(c)PAGR;(d)RANet;(e)ours)
本文工作的贡献可概括如下:1)为了实现显著性目标检测,提出了多重注意力机制引导的渐进聚合细化网络(AGNet),该网络包括特征提取模块(FEM)、通道—空间注意力聚合模块(C-SAAM)和注意力残差细化模块(ARRM)。2)在特征提取模块(FEM)引入多尺度空洞卷积,获取更丰富的上下文信息和更大的感受野。3)设计了通道—空间注意力引导的特征聚合模块(C-SAAM)提取高分辨率信息特征和高语义信息特征间的共享部分,利用高层特征指导浅层特征的选择,实现了显著目标的位置信息和边缘细节信息有效融合。4)AGNet模型在5个公开数据集上达到了最优性能,证明了该方法的有效性和优越性。
1 相关工作
传统的SOD(salient object detection)模型通常依赖于对物体的启发假设,如对比度先验(Cheng等,2015)、边界先验、中心先验(Jiang和Davis,2013)和背景先验等。但因为这些方法缺少高层语义信息,所以在复杂场景中检测显著物体的能力有所欠缺。深度学习由于其强大的特征提取能力,在显著性目标检测方面取得了优异成绩,并且逐渐超越基于手工特征先验的传统显著性检测模型。这得益于全卷积神经网络(FCN)应用于显著性检测研究,学者们在此基础上通过聚合提取的局部特征和全局特征生成显著图。Liu和Han(2016)通过使用深度循环卷积神经网络逐渐组合较浅的特征细化显著图。Zhang等人(2017)提出一种无监督显著性检测模型,将传统的无监督方法生成的噪声显著图与深度模型产生的潜在显著图融合。Zhang等人(2018a)通过孪生体系结构和结构损失函数预测显著图,提出了新的双向信息传递模型,自适应地融合不同层的特征图,以获得准确的预测图。Wang等人(2018b)利用眼动预测的结果图确定并分割场景中的显著性目标,并利用LSTM(long-short term memory)的层次结构为分割图的连续细化提供了有效的循环机制。Hu等人(2018)以循环方式将多层深度特征聚合到每个层的特征,相比简单集成多级特征,能够更有效地利用在不同层中生成的特征中编码的补充信息。Hou等人(2019)通过在跳跃层中引入短连接组合来自不同级别的特征,得到的体系结构在每一层提供丰富的多尺度特征图。Wang等人(2019)通过迭代修正预测误差,设计了用于显著性检测的递归FCN网络。
为了捕捉更精细的结构和更精确的边界,学者们提出了许多边界细化策略。Wang等人(2017c)使用金字塔池化模块和用于显著性映射细化的多级细化机制捕获全局上下文信息。Deng等人(2018)开发了一个用于显著图细化的递归剩余细化网络,通过构建一系列残差细化块(residual refinement block,RRB)交替结合浅层和深层特征以逐步改进显著图,可以在增强显著目标细节的同时,抑制显著图中的非显著区域,更精确地预测显著目标。Wang等人(2018a)提出全局定位显著对象,然后通过局部边界细化模块进行细化。Qin等人(2019)提出残差细化模块(residual refinement module,RRM)细化编码—解码结构产生的粗糙显著图。这些方法虽然提高了显著性目标检测的标准,但在精细结构和边界恢复精度方面仍有提高空间。
在模型中引入注意力机制可以解决迭代过程中冗余信息无法得到有效过滤的问题,注意力机制与迭代法等结合能够获得更好的检测结果。Liu等人(2018)利用全局和局部的像素级上下文注意力机制学习每个像素的信息性上下文特征,然后将其嵌入到U-Net结构自上而下路径中,从而分别关注全局和局部的情况,获得丰富的上下文特征。Zhang等人(2018c)使用空间注意力,通过对不同的卷积层赋予不一样的权重,有选择地集成多路径之间的连接,将全局信息从深层传输到较浅层以生成强大的注意特征,增强网络的特征提取能力。Chen等人(2018)在残差学习的基础上,进一步提出反向注意以指导侧输出的残差学习,通过抹去当前预测,网络可以有效且快速地发现丢失的对象部分和残留的细节,从而提高性能。Feng等人(2019)采用每个编码块与其相应的解码块构建注意力反馈模块(attention feedback module,AFM)逐比例地细化显著图。
计算机视觉中的注意力机制的基本思想就是使机器学会注意——能够忽略无关信息而关注重点信息,这也是显著性检测的目的。将不同层次的注意力机制融入到显著性检测模型中必定会有利于系统性能的提升。本文注意到上述多种方法依靠不同设计思路均提高了显著性检测性能。然而,如何综合考虑不同层次的注意力机制,设计更加有效的特征聚合方法仍有研究空间。
2 AGNet
2.1 网络结构概述
本文提出了一种注意力引导网络AGNet,如图2所示。AGNet是类U型结构,分为编码部分和解码部分。编码部分使用预训练好的ResNet-50分类网络提取多层次特征,任务是输入图像后,通过卷积得到输入图像的特征图f2,f3,f4,f5,这样的结构能够同时得到浅层的细节信息和深层的语义信息。解码器则在编码器提供特征图后,逐步融合多层特征信息,最终在有监督的情况下生成像素级显著图。本文中的解码部分由特征提取模块(FEM)、通道—空间注意力聚合模块(C-SAAM)和注意力残差细化模块(ARRM)组成。具体来说,首先使用FEM模块通过对深层特征进行多比例采样扩大感受野,并且丰富上下文信息;然后通过ARRM模块对特征进行细化和增强,生成第1阶段的高级特征;最后通过C-SAAM和ARRM有选择地融合浅层和较深层特征,并且细化生成的聚合特征。如此重复3次逐渐生成精确的显著图。此外,在每个阶段都使用双线性插值策略将生成的显著图进行上采样,将其调整到输入图像的尺寸,并使用人工标注图GT(ground truth)对其进行监督训练。

图2 AGNet的总体网络架构Fig.2 The overall network architecture of AGNet
2.2 特征提取模块(FEM)
卷积神经网络通过多次卷积和池化操作,可以得到抽象的语义特征,但是输入图像的多样性意味着得到的显著目标的尺度和位置具有不确定性,而且理论上的感受野往往与实际的感受野有一定的差距,导致网络无法有效融合全局特征信息。如果直接使用单尺度的深层特征,可能因语义信息的缺失导致无法获得正确的显著物体信息。对此,本文使用特征提取模块(FEM),通过全局平均池化(global average pooling,GAP)操作获取图像的全局上下文信息,但是这样直接简单地将信息压缩,容易丢失有用的信息,因此采用多个空洞卷积扩大感受野,并采取1×1,5×5,7×7,8×8采样率的空洞卷积并行处理高层特征,相当于以不同比例获取上下文信息互补局部信息,获得更加丰富的语义信息,增强特征的表达能力。
2.3 通道—空间注意力聚合模块(C-SAAM)
FCN网络自提出以来,广泛运用于显著性目标检测领域。众所周知,浅层特征包含的主要是物体的细节信息,同时也存在噪声信息,所以浅层特征对于细化显著图十分重要。由于多次下采样操作,高层特征丢失了许多边缘细节信息,但是提供了显著物体的位置信息以及抽象的全局语义信息。因此现有的显著性检测网络框架常常将浅层特征和高层特征简单相加或者结合生成特征图。但其实不同层的特征表述的信息均不同,信息的重要程度也都不同,若无差别地处理不同特征,会导致生成次优的结果。而注意力模型借鉴了人脑的注意力机制,旨在从众多信息中选择出对当前任务更关键的信息,给予其较大的权重,正好可以解决对不同特征进行无差别处理的问题。因此本文分层次地使用通道注意力模块和空间注意力模块聚合浅层特征和高层特征。
因为上一个阶段的输出是由不同通道信息的特征结合而成,因此本文首先对输入的信息给予通道维度上的注意力,自适应地提取有效高级语义信息。如图3下半部分所示,本文先使用双线性插值策略对输入的特征图上采样至较浅层特征图的大小。然后利用全局平均池化以及全局最大池化两种全局池化操作分别将多通道特征图进行压缩,使H×W×C的特征图变成1×1×C的权重向量,这样不仅使其具有全局的感受野,而且可以提取丰富的高层次特征。随后利用共享MLP(multi-layer perceptron)建立通道之间的相关性,合并两个输出得到各个特征通道的权重。最后使用sigmoid函数得到每一个通道的权重值,其中的参数被学习用来显性地表示特征通道间的相关性,并将其逐通道乘以上采样后的特征以完成对原始特征在通道维度上的重标定,选择适合显著性目标的语义特征。
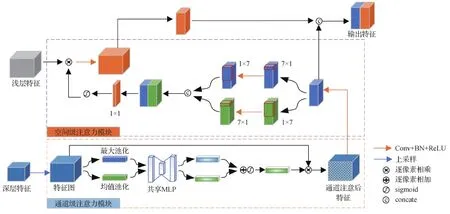
图3 通道—空间注意力聚合模块结构Fig.3 Channel-spatial attention aggregation module structure
较浅层特征相对于高层特征含有更多细节信息,但同时也存在背景噪声,此外,在复杂的场景和嘈杂的背景下,不显著区域的干扰可能导致效果欠佳。因此,网络最好不要在所有空间位置均等地对待特征向量,这也是在显著性检测任务中引入空间注意力的初衷。本文引入空间注意力强化显著区域并且抑制属于背景的目标,同时强调背景中的线索。具体来说,使用大小为1×k和k×1的卷积核分别执行水平方向和垂直方向上的注意,使每个像素同时记忆水平和垂直方向的上下文,同时也扩大了特征图的感受野。然后将特征图进行并行卷积处理,再使用1×1大小的卷积核混合不同通道的信息,形成新的H×W×1的特征图,通过sigmoid函数求得相应的权重,并将得到的空间注意力权重与浅层特征图逐像素相乘,从而更有效地增强较浅层特征中显著目标的响应,同时抑制冗余的背景噪声。最后将通过通道注意的高层特征与经过空间注意的浅层特征结合起来,作为此模块的输出。
综上所述,本模块采用分层次的处理引导高层特征和较浅层特征的融合。通道注意处理输入特征的高级语义,空间注意处理细节信息,同时消除属于背景的图像噪声。这种注意力机制设计可以自适应地处理低层和高层特征,使一个更关注语义特征的选择,另一个更关注背景噪声的过滤,将它们聚合以产生更好的显著图。
2.4 注意残差细化模块(ARRM)
在C-SAAM中,结合通道注意后的高层特征和空间注意后的浅层特征可以得到较全面的互补特征。此时,也可以直接使用sigmoid函数训练生成显著图,但是生成的显著图存在不清晰且内部残缺现象,这是因为不同特征层在融合过程中存在矛盾。为了得到更加完善的显著图,本文提出了一个特定的注意力残差细化模块(ARRM),在FEM模块和C-SAAM模块后添加ARRM模块,以进一步细化和增强每个阶段的特征图。如图4所示,ARRM同样使用通道级的注意力机制,与C-SAAM中的通道注意不同,此处仅通过对输入特征图fin进行全局平均池捕获全局上下文,并计算一个注意力向量指导特征学习,然后通过1×1卷积,将通道统一为256,用sigmoid函数计算相应的通道权重。
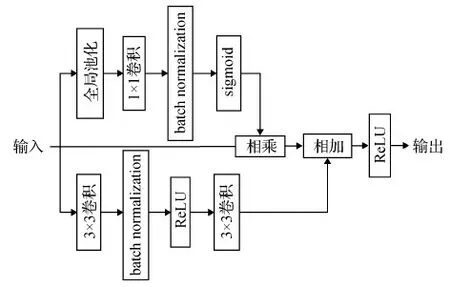
图4 注意力残差细化模块结构Fig.4 Attention residual refinement module structure
但是对通道内的信息直接全局平均池化是比较简单的做法,会忽略每个通道内的局部信息,因此添加了一个残差路。采用两个3 × 3卷积核将输入特征进行压缩混合,然后通过与经过通道注意的特征进行加法运算填充有效信息,得到优化后的特征输出fout。这种设计可以方便地集成全局上下文信息,细化上下文路径中每个阶段的输出特性。主要过程可以表示为
fα=δ(conv1(AvgPool(fin)))
(1)
fr=conv3(conv2(fin))
(2)
fout=γ(fin⊙fα+fr)
(3)
式中,δ表示sigmoid操作,γ表示ReLU函数,conv1配备了BN (batch normalization)和ReLU激活函数,conv2仅配备BN。
2.5 损失函数
在显著性检测任务中,二元交叉熵(BCE)损失是应用最广泛的损失函数。然而,BCE损失有3个缺点:1)独立计算每个像素的损失值,忽略了图像的全局结构;2)在背景占主导地位的图像中,稀释了前景像素的损失;3)平等对待所有像素。因此,本文使用像素位置感知(pixel position aware,PPA)损失(Wei等,2020)替换常用的二元交叉熵损失。PPA损失综合考虑局部结构信息,为所有像素生成不同的权值,同时引入加权交叉熵损失Lwbce和全局约束Lwiou,以更好地指导网络的训练。即
Lppa=Lwbce+Lwiou
(4)

(5)
式中,1(·)是指示函数;γ是超参数,设置为5;l∈{0,1}表示两种标签;Sij和Gij是图像中(i,j)位置处像素的预测和真实性;ψ表示模型的所有参数;Pr(Sij=l|ψ)表示预测的概率。
交并比(intersection over union,IOU)损失的目标是优化全局结构,而不是只关注单个像素,并且不受分布不平衡的影响。同样加权的IOU损失为目标像素分配了更多的权重以强调它们的重要性。具体为

(6)
在Lwbce和Lwiou中每一个像素都赋予了不同的权重值αij。αij通过中心像素与其周围环境的差异计算得到,与目标相关的重要像素的αij较大,反之较小。αij的具体计算为
(7)
式中,Aij表示像素(i,j)周围的区域,对于所有像素点的αij∈[0.1]。如果αij很大,则(i,j)处的像素与周围环境非常不同,因此可能是个重要的像素点(如边缘),值得给予更多的关注。
在解码模块,对每个子解码块都给予辅助监督,所以总损失由两部分组成,即主损失和各子级的辅助损失,即
(8)
式中,λi表示不同子级损失的权重,分别设置为0.8、0.6和0.4。
3 实验
3.1 实验细节
实验的软硬件环境为Ubuntu16.0.4操作系统,Intel(R)Core(TM)i7-7800X @3.5 GHz CPU,16 GB内存,GTX 2080ti GPU(11 GB内存)显卡,使用Pytorch 1.1.0框架训练和测试网络。
本文采用ResNet-50作为编码器的主干网络,并且将在ImageNet上训练好的参数载入并初始化网络。与其他显著模型一样,使用DUTS-TR数据集训练网络。在训练阶段,首先将每个图像调整到320 × 320像素,然后随机裁剪成288 × 288像素进行训练。采用小批量随机梯度下降法(stochastic gradient descent,SGD)进行优化,学习率设置为0.05,动量设置为0.9,权重衰减设置为5E-4,batch size设置为24。在不使用验证集的情况下,训练30个epoch,整个训练过程耗时3 h。在测试过程中,简单地将输入图像的大小调整为320 × 320像素,然后送入训练好的网络中生成相应的显著图,不需要进行其他后处理。对于320 × 320像素的图像,测试耗时为0.02 s(速度为50 帧/s),达到实时标准。
3.2 数据集
1)训练数据集。本文在DUTS-TR(Dalian University of Technology-train)上训练提出的网络。DUTS-TR是DUTS数据集的一部分,包含10 553幅图像,是用于显著目标检测的最大和最常用的训练数据集。本文通过水平翻转对其扩充,最终获得21 106幅训练图像。
2)测试数据集。本文使用了5个常用的公开数据集评估提出的模型,包括DUT-OMRON(Dalian University of Technology-OMRON)(Yang等,2013)、DUTS-TE(test)(Wang等,2017b)、HKU-IS(Hong Kong University-image saliency)(Li和Yu,2016)、ECSSD(extended complex scene saliency dataset)(Yan等,2013)和PASCAL-S(pattern analysis,statistical modeling and computational learning)(Li等,2014)。
DUT-OMRON数据集包含5 168幅高质量图像,该数据集的图像具有一个或多个突出对象和相对杂乱的背景,因此在该数据集上进行显著目标检测非常具有挑战性。DUTS数据集是目前最大的显著性检测基准数据集,由10 553幅训练图像(DUTS-TR)和5 019幅测试图像(DUTS-TE)组成。HKU-IS数据集包含4 447幅图像,其中大多数图像的对比度较低或有多个突出物体。ECSSD数据集包含1 000幅从互联网上手动收集的图像。PASCAL-S数据集是从PASCAL VOC数据集(Everingham等,2010)中精心挑选出来的,共850幅自然图像。
3.3 评价指标
显著性目标检测模型的输出通常是与输入图像具有相同尺寸的概率图。预测图的每个像素值都在[0,1]或[0,255]范围内。人工标注图通常是二进制掩码,其中每个像素都是0或1(或0和255),其中0表示背景像素,1表示前景显著目标的像素。
为了综合评估本文模型的性能,采用精确率—召回率(precision-recall,PR)曲线、F-measure(Fβ)的分数和曲线、平均绝对误差(mean absolute error,MAE)和E-measure(Em)作为模型的性能度量指标。
1)PR曲线。对模型生成的显著图,通过比较不同阈值下的二值掩码与真实掩码计算其精度和召回率。通过将阈值从0变为1,可以得到一系列精确召回对,由此绘制PR曲线。
2)F-measure。通过计算加权调和平均值综合考虑精度和召回率,具体为
(9)
式中,P表示精确率,R表示召回率,β2设置为0.3。
3)平均绝对误差(MAE)。用来计算二元真实值G和预测显著图S之间的平均误差,具体计算为
(10)
式中,W和H是图像的宽度和高度,S(i,j)表示(i,j)处的显著值。
4)E-measure。同时考虑图像和局部像素匹配的全局平均值,具体计算为
(11)
式中,φs是增强的对准矩阵,其分别反映减去S和G的全局平均值之后的相关性。
3.4 实验对比
本文将所提模型与现有的13种最先进方法进行比较,包括Amulet(aggregating multi-level convolutional features for salient object detection)(Zhang等,2017)、C2S(contour knowledge transfer for salient object detection)(Li等,2018)、RADF(recurrently aggregating deep features for salient object detection)(Hu等,2018)、RANet(Chen等,2018)、DGRL(detect globally,refine locally)(Wang等,2018a)、PAGR(Zhang等,2018c)、R3Net(recurrent residual refinement network)(Deng等,2018)、BMPM(a bi-directional message passing model)(Zhang等,2018a)、PiCANet-R(pixel-wise contextual attention network-ResNet50)(Liu等,2018)、CPD-R(cascaded partial decoder-ResNet50)(Wu等,2019)、BASNet(boundary-aware salient network)(Qin等,2019)、AFNet(attentive feedback network)(Feng等,2019)和CAGNet-R(content-aware guidance network-ResNet50)(Mohammadi等,2020)。为了公平比较,不同方法的显著图采用原方法提供的显著图或者在默认参数下运行发布的原方法代码得到。表1给出了MAE、Fβ和Em得分的定量比较结果。很明显,在不同的度量条件下,本文模型达到或者超过现有最新方法的性能。尤其在最大、最复杂的DUT-OMRON数据集上,F-measure指标与性能第2的模型相比提高了1.9%,MAE降低了1.9%,这证明了所提出模型的有效性。
为了评估分割出的显著对象的质量,对各方法在5个数据集上的PR曲线和F-measure曲线进行对比,如图5和图6所示。可以看出,本文方法的PR曲线在各数据集上都有突出的部分,F-measure曲线在不同阈值下与其他方法相比在大多数情况下都是突出的,尤其在DUT-OMRON数据集上突出明显,这与表1中的测量值是一致的。

图5 不同方法在5个数据集上的PR曲线Fig.5 PR curves of different methods on 5 datasets((a)DUTS-TE;(b)ECSSD;(c)HKU-IS;(d)PASCAL-S;(e)DUT-OMRON)
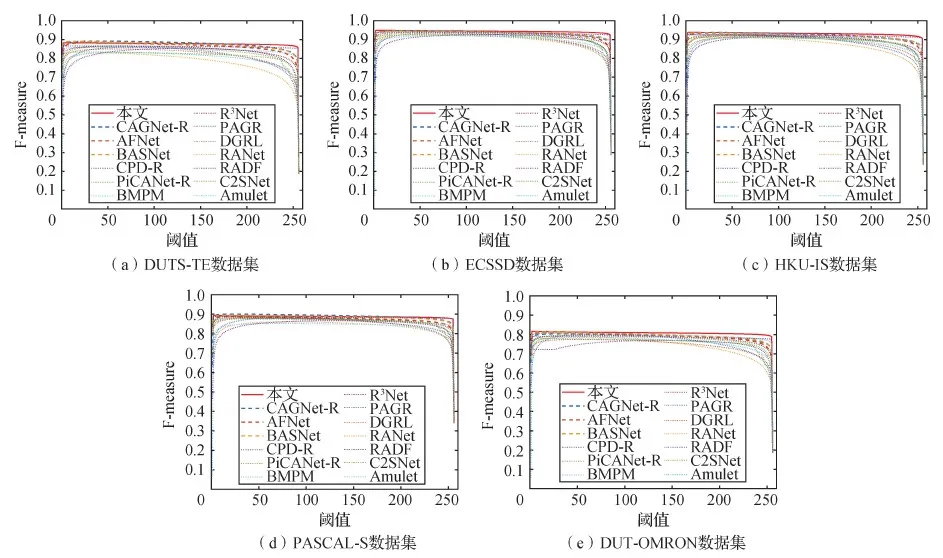
图6 不同方法在5个数据集上的F-measure曲线Fig.6 F-measure curves of different methods on 5 datasets((a)DUTS-TE;(b)ECSSD;(c)HKU-IS;(d)PASCAL-S;(e)DUT-OMRON)
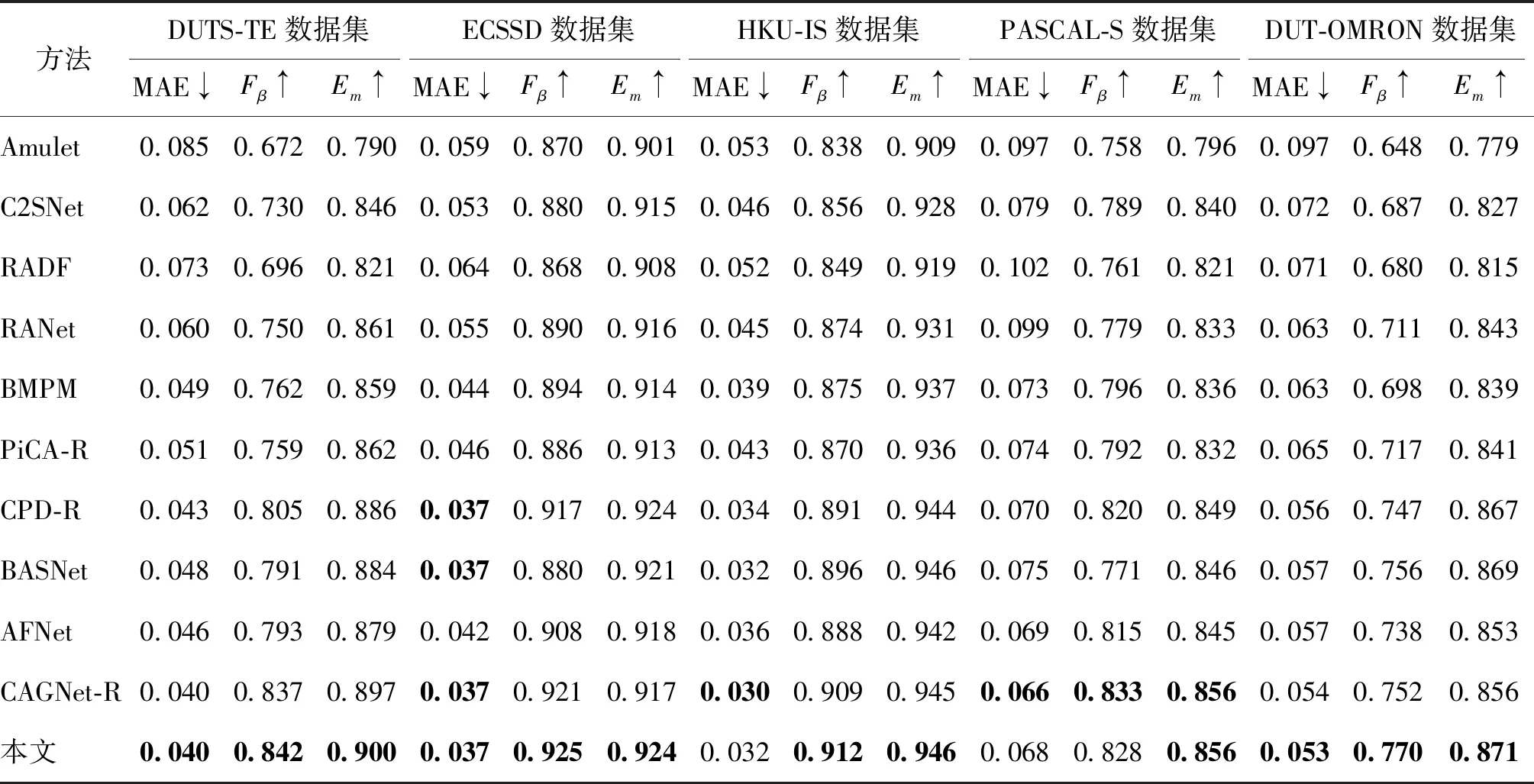
表1 不同模型的性能比较Table 1 Performance comparison of different models
为了进一步验证本文方法的性能,与一些对比方法进行了可视化对比,结果如图7所示。实验结果表明,本文方法能清晰地检测目标区域,很好地抑制背景噪声,可以处理各种具有挑战性的场景,包括细粒度结构(图7第1行)、低对比度图像(图7第2、3行)、背景干扰(图7第4行)、相似对象干扰(图7第5、6行)和前景干扰(图7第7行)等,生成的显著图更清晰和准确。值得注意的是,本文模型对前景/背景干扰(图7第4、5、7行)更为鲁棒,能够充分过滤掉冗余信息。这说明了引入通道注意力和空间注意力来引导不同特征层之间信息融合的重要性。由于深层的特征具有目标的空间方位信息,浅层的特征虽然有背景噪音,但包含目标边界细节信息,本文通过对深层特征进行通道注意力机制处理,并且使用空间注意力机制引导与浅层特征的融合。通过深层特征确定浅层特征中目标的位置,并由浅层特征补充目标的边界信息。这样可以有效保留目标的信息,过滤掉冗余的噪音信息。此外,多尺度特征提取丰富了特征信息,边界细化操作使显著图更加清晰。更重要的是,本文方法不需要任何后处理就可以得到这些结果。

图7 本文模型与其他最新方法的可视化对比Fig.7 Visual comparison the proposed model in this paper with other state-of-the-art methods((a)original images;(b)ground truth;(c)CAGNet-R;(d)AFNet;(e)BASNet;(f)CPD-R;(g)PiCANet-R;(h)PAGR;(i)RANet;(j)DGRL;(k)ours)
3.5 消融实验
为验证各模块的有效性,以ResNet-50为编码主干,分别使用BCE函数和PPA函数作为训练网络的损失函数,在DUT-OMRON数据集上进行主要模块的消融实验,采用在上采样中简单连接高层次特征和低层次特征的U-Net模型作为基准(Base)网络,然后逐步添加每个模块。消融实验结果如表2所示。可以看出,在基准网络的基础上添加C-SAAM模块后,用BCE损失函数和PPA损失函数训练得到的显著图的Fβ值分别提升了11.7%和11.8%。分别添加FEM和ARRM模块后,Fβ值均略有提高,但是同时添加FEM和ARRM两个模块后,显著图的Fβ值分别提升了11.4%和9.0%,证明了各个模块的有效性。此外,使用PPA函数作为损失函数训练网络得到的结果均优于使用BCE函数,显著图的Fβ值平均提升了约0.02,证明了PPA损失函数的优势。使用PPA作为损失函数,添加C-SAAM、FEM和ARRM模块的模型性能最好,表明各模块对本文模型获得最佳显著性检测结果都是必要的。

表2 DUT-OMRON数据集上本文各模块的消融研究Table 2 Ablation study of each module in this paper on the DUT-OMRON dataset
3.6 速度对比实验
为全面验证本文模型的性能,与BASNet、AFNet和CAGNet-R模型的速度进行比较。对比算法使用原方法提供的模型和参数权重,并且在相同的实验环境中运行测试。实验结果如表3所示。从表中可以得知,本文模型处理一幅320 × 320像素图像的速度达到50帧/s,基本超过其他算法。表明本文模型在保证不错检测效果的同时,还保持着不错的速度表现。

表3 不同模型的速度对比Table 3 Speed comparison of different models
4 结 论
本文提出的AGNet通过通道—空间注意力引导的特征融合模块(C-SAAM)和注意力残差细化模块(ARRM),探讨了注意力机制在显著目标检测中的应用潜力。本文主要工作包括:1)通过多尺度特征提取模块FEM获得足够丰富的特征。2)在FPN架构中,使用通道注意提取适应于显著目标的语义信息,使用空间注意过滤浅层的外观线索。通过注意力机制引导深层特征与浅层特征之间的融合,可以有效捕捉显著目标在不同特征层之间的关系。3)在C-SAAM后对融合后特征进行残差注意,给予目标更大的权重以细化背景和前景信息。实验结果表明,AGNet在5个广泛使用的显著目标检测数据集上表现出优于其他13种模型的性能,并且在可视化实例中可以看到,在许多环境下,本文模型生成的显著图更清晰,很好地过滤了具有“类似显著”外观的非显著区域,并且能在没有任何后处理的情况下获得高质量显著图。同时,本文模型在速度上也极具竞争力。
虽然模型在实验中能得到较好的显著图结果,但仍有改进的空间。由于上采样操作存在信息的缺失,所以使用上采样后的深层特征引导与浅层特征的融合可能会忽略掉细小的目标特征。因此,接下来将继续探索更有效的策略聚合高级语义和浅层细节信息,更好地提高显著性检测网络的通用性和鲁棒性。
猜你喜欢
水土保持学报(2022年5期)2022-10-10
建材发展导向(2021年24期)2021-02-12
大东方(2019年1期)2019-09-10
红领巾·萌芽(2019年8期)2019-08-27
中国知识产权(2018年12期)2018-12-29
河南科技(2018年9期)2018-09-10
中国知识产权(2017年5期)2017-05-25
吉林农业(2016年4期)2016-05-14
CHIP新电脑(2016年3期)2016-03-10
意林(2013年16期)2013-05-14
