
基于虚拟教师蒸馏模型的说话人确认方法
2022-04-21 05:19肖金壮李瑞鹏纪盟盟
计算机工程与应用 2022年8期
肖金壮,李瑞鹏,纪盟盟
河北大学 电子信息工程学院,河北 保定 071000
无文本说话人确认(text-independent speaker verification,TI-SV)的任务是判定任意一个语音段和模型中给定目标之间是否匹配[1],语音段是不做任何限定的,因此该技术可以在生活场景中广泛应用。相比说话人辨认(speaker identification,SI),属于声纹识别(voiceprint recognition,VR)中较难的任务[2]。以高斯混合-通用背景模型和全因子空间与概率线性判别式分析相结合的确认模型为代表[3-4]的传统方法缓解了数据量缺乏、信道补偿等问题,但识别精度与应用仍存在差距。随着人工智能技术的发展,利用神经网络特征提取优势,结合传统方法后端判别特点的模型出现,识别精度得到一定提升[5],但在面对十万级及以上的数据集时,训练效率受限,导致性能降低。基于深度学习的说话人确认技术可以充分利用大数据集,使确认精度大幅提升,于是逐渐成为研究热点。
基于深度学习的说话人确认技术包括两个大方向,其一,是追求性能的提升,但忽略了能否走出实验室的可能性;其二,是面向实际应用,追求性能和应用的统一性。前者主要有两种方式,第一,扩展说话人模型的深度和宽度以提高学习能力,早期使用VGG网络来提取具有辨别性的声纹特征[6],取得了明显的效果,之后便采用可以延伸到上百层的网络ResNet,说话人确认模型的性能有显著提升[7],但同时带来收敛缓慢和过拟合的问题;第二,改进损失函数增强声纹模型的特征分辨能力,例如中心损失函数(center loss)、三重损失函数(triplet loss)以及基于softmax函数进行边界调整的损失函数,均专注于增强说话人确认模型对于类别的表征特性[8-10]。
这些方法虽然解决了说话人确认技术精度低的问题,但也伴随着出现了模型计算参数量庞大、消耗内存资源过多等情况,不利于模型部署在资源有限的轻量级设备中,如门禁系统、金融交易系统等,因为它们需要的是高精度和低功耗。
此时面向实际应用的后者,使用紧凑神经网络设计和知识蒸馏(knowledge distillation,KD)的模型压缩技术[11-12]缓解了该问题。
紧凑神经网络设计在学习前者大模型改进思路的基础上,以不损失声纹模型性能的方式,减少每秒浮点运算次数并降低模型体积。其中以MobileNe网络为架构的声纹模型利用深度可分离卷积来减少计算量和加快网络计算速度,改善了声纹模型的分类效果和准确性[13]。相比之前的大型声纹确认模型,在参数量和计算资源需求上,已经达到了部署的基本要求,但存在识别精度下降的现象。
基于知识蒸馏中产生的知识迁移,把前者研究出的大型声纹确认模型训练得到的软输出(soft target)迁移到轻量化小模型中指导其学习,进而让小模型在保持规模较小的同时,精度得到提升,实现压缩模型的目标[14]。其中,把大模型称为教师模型(teacher model),小模型称为学生模型(student model)。文献[15-16]分别把该方法应用在有文本和无文本的说话人确认任务上,但是学生模型的性能仍差于教师模型,特别是在特征分辨和模型泛化能力方面达不到大模型的标准,影响了实际的使用效果。
针对在该技术应用中如何既能保留前者大模型的性能又能满足后者压缩模型体量的需求,本文在说话人确认方法中引入新型知识蒸馏技术——虚拟教师架构(teacher-free framework)[17],提出一种基于Resnet18的轻量化虚拟教师说话人确认模型,它包含一个有百分之百正确率的虚拟教师,同时,在该模型中加入附加角裕度损失函数[18](additive angular margin loss,AAM-Softmax)和空间共享而通道分离(spatial-shared and channel-wise)的动态激活函数[19],在小计算成本下,提升模型的泛化能力,实现无文本的说话人确认任务既能取得和大模型一致甚至略高的效果,又能达到在资源受限设备上使用的目的。
1 声纹确认模型压缩方法
1.1 虚拟教师声纹确认模型
基于知识蒸馏的声纹确认模型是把教师模型训练得到的软输出(soft target)迁移到轻量化的学生模型中,相比硬标签可以提供更多的声纹特征类别内和类别间的信息,从而让学生模型学习到和教师模型一致的效果,达到压缩模型满足实际应用的目的,其工作流程如图1所示,CE代表交叉熵函数(cross entropy),α是占比参数。
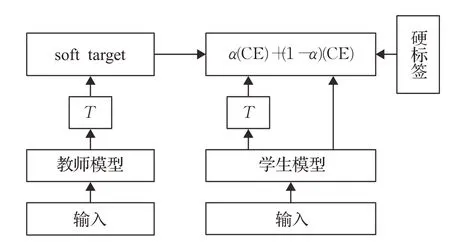
图1 传统知识蒸馏声纹确认模型Fig.1 Traditional knowledge distillation voiceprint verification model
上述是基于传统知识蒸馏的声纹确认模型的基本原则,但是文献[17]论证了新的知识蒸馏观点:
(1)手动设计的100%正确率轻量级虚拟教师知识蒸馏模型(Tf-KD)可以达到传统知识蒸馏方法中教师模型的性能,证明了虚拟教师能够给学生模型带来更多的特征分辨信息;
(2)该模型自身的标签正则化作用,比单独使用标签平滑归一化的优化效果更佳。
Tf-KD框架具有通用性,可直接用于轻量级神经网络,且没有额外的计算成本,因此,针对在实际应用中说话人确认(SV)任务更有难度以及要满足高性能的需求,本文提出将该框架应用于无文本声纹确认任务上,并称其为虚拟教师说话人确认模型(teacher-free speaker verification model,Tf-SV)。
1.2 虚拟教师说话人确认模型性能分析
Tf-SV模型关于类别的输出分布设计为:

其中,K是类别总数,k是某个语音段,c是正确标签,a是正确类别的正确概率。令a≥0.9,则一个正确类别的概率要远高于一个错误的类别。这可以使虚拟教师说话人确认模型对于之后用到的声纹数据集有100%的分类正确率。
Tf-SV模型的总损失函数为:

其中,DKL是KL散度函数,T是用来把式(1)设计的分布pd软化为pdT,q是真实的类别分布,p是输出的类别分布。这样,手动设计的虚拟教师说话人确认模型输出的soft target不仅具有100%的分类正确率,还带有标签平滑归一化的平滑分布特性,模型的工作流程如图2所示。对比图1可以发现:
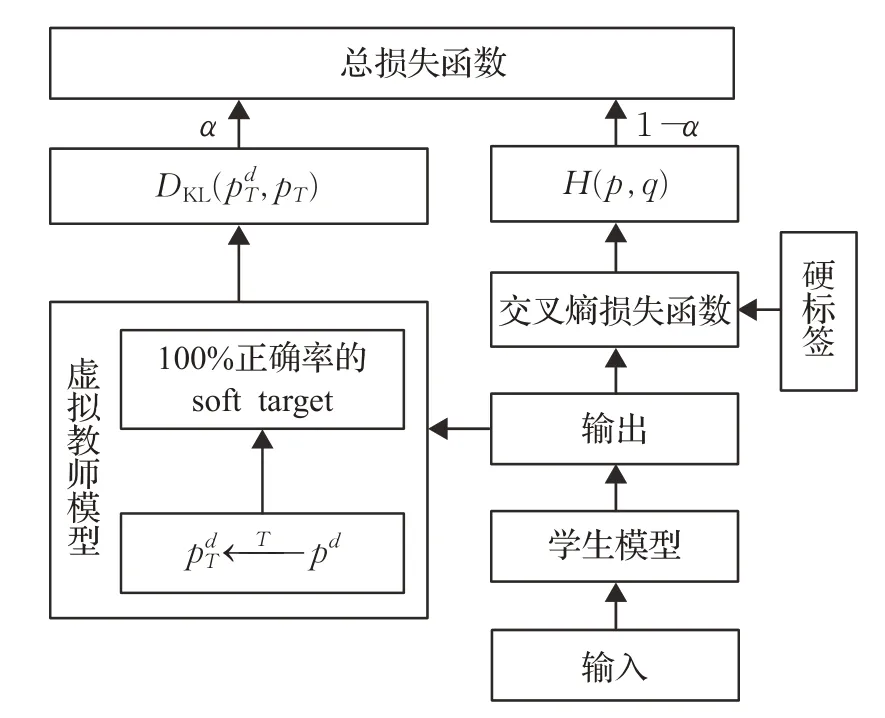
图2 虚拟教师说话人确认模型Fig.2 Teacher-free speaker verification model
(1)传统声纹模型需要先单独训练教师,再迁移知识训练学生两个步骤,而Tf-SV模型可以将其合二为一,大幅提高说话人确认模型的工作效率。
(2)采用手动设计的拥有100%正确率的平滑分布,相比随机学习得到的分布,能提升Tf-SV模型的学习能力。
(3)在交叉熵函数中加入附加角裕度损失函数,即把式(2)中的第一项调整为H( )q,p=CE+AAM,则总的损失函数更新为:

该函数在增强类内紧凑性和类间差异性的效果上更为显著[16],同时配合软目标提供的类别间信息,可以大幅增强Tf-SV模型对类别的分辨能力。
2 声纹模型的新型激活方式
2.1 空间共享而通道分离的动态激活函数
由于语音片段的上下文有相互关联的信息,虽然修正线性单元[20](rectified linear unit,ReLU)和leaky ReLU[21]可以提高声纹模型的性能,但它们的静态特性,使其对不同的输入执行方式完全相同,导致遗漏部分语音信息。
根据文献[19,22]在图像分类中提到的动态激活函数(dynamic rectified linear units,DY-ReLU)机制,本文采用空间共享而通道分离(spatial-shared and channelwise)的动态激活函数,其效果如图3所示。即首先对输入语音的全局信息在超参数上进行编码,再调整分段激活函数,这样,每个通道内的激活方程不同,但通道内空间的各个部分共享同一个激活方程,相比静态和其他动态激活函数更容易提取到不同的特征,在训练过程加强类内相似性和类间差异性,提升Tf-SV模型的表达和泛化能力。尤其对于类似Mobilenet或者Resnet18等轻量级网络模型。

图3 Spatial-shared and channel-wise激活效果Fig.3 Spatial-shared and channel-wise activation effects
2.2 动态激活函数的性能分析
对于一个维度为C×H×W的语音输入向量x,首先通过全局平均池来压缩空间信息,然后是两个完全连接的层(两者间有ReLU函数),最后是一个规范化层,其流程如图4所示。其输出函数被记为初始值和残差的和,即:



图4 Spatial-shared and channel-wise动态激活函数Fig.4 Spatial-shared and channel-wise DY-ReLU
该函数除了提供更多的语音信息,增强模型的泛化能力,还具备计算高效的特性,与1×1的卷积层相比,其产生的计算量更少。从图4和表1可知,平均池化层的计算复杂度是O(CHW),第一个全连接层是O(C2/R)以及分段方程是O(CHW),第二个全连接层是O( 2KC2/R),而1×1的卷积层是O(C2HW)。
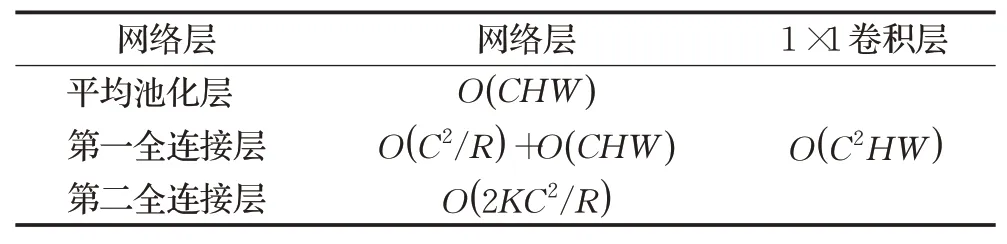
表1 动态激活函数和卷积层的计算复杂度Table 1 Computational complexity of dynamic activation function and convolutional layer
在ImageNet图像分类任务上,轻量级的网络模型MobilenetV2、MobilenetV3以及Resnet18,已经证明了该动态激活函数对数据的拟合和表征能力,这是静态激活函数做不到的。考虑到说话人确认任务的输入同样是二维的声谱图,与图像识别的具有一定的相似性,故将该激活函数引入到Tf-SV模型中。
3 实验过程
3.1 数据集选择
VoxCeleb1数据集[3]是一个免费的大规模数据集。它从上传到YouTube®的视频中提取了1 251个名人的超过100 000种语音。数据集中有55%来自男性说话者,以满足性别平衡。与在高质量环境(如声学实验室)中录制的语音不同[23],Voxceleb1数据集更接近嘈杂的外部生活环境。以“E”开头的名称被分为测试集,其余名称仍保留在训练集中,详细划分如表2所示。

表2 说话人确认数据集统计Table 2 Statistics of speaker verification dataset
3.2 轻量级网络结构
为了验证虚拟教师的有效性,提出两个教师模型,分别是Resnet34和手动设计的一个准确率为100%的Tf_Resnet18虚拟教师模型,学生模型均为Resnet18,其中ReLU函数用DY-ReLU函数代替,具体参数如表3所示。

表3 网络模型参数Table 3 Network model parameters
为轻量化模型,所有的卷积核改为3×3,同时把维度为M×N(频率×时间)的FC1替换为两层,即M×1的卷积层和一个1×N的平均池化层,这样相对直接使用全连接层,可以大幅提高模型的训练效率,根据3.3节所提输入尺寸,降低了8倍的参数量。
3.3 语音预处理
语音作为一维信号,需将其处理成二维特征,才能发挥残差网络的性能。本文提出使用对数能量声谱图作为模型的输入,其流程如图5(a)。
采用宽度为25 ms,步长为10 ms的汉明窗对3 s的一维语音信号进行分帧、加窗,然后经N=512点的快速傅里叶变换处理生成大小为257×300(频率×时间)的二维声谱图,对其取绝对值,会得到振幅谱,振幅谱平方除以N得到能量谱,能量谱取10倍的lg再减去最大值得到对数能量声谱图,如图5(b)所示。

图5 语音预处理Fig.5 Speech preprocessing
未采用MFCCs和Fbank作为输入特征是因为二者均为针对传统声纹模型人工设计的特征[24],在设计过程中会主动丢弃一部分信息,而这些信息在深度卷积模型中却可以起到一定的作用,因此该语音预处理方式,不仅简单易操作,而且可以最大程度地保留语音本身所携带的信息,同时对数能量声谱图也表现出了更好的抗噪能力[3],在预处理过程中无需端到端检测的操作。
3.4 训练参数设置
初始学习率设为0.1,通过动量随机梯度下降(SGD)法对模型进行优化,其中动量为0.9,权重衰减为1E-4,最小批量为128,将学习率初始化为0.1,在第10轮、第20轮和第30轮迭代后皆令学习率除以10。占比参数和温度系数分别设置为0.1和30。模型采用PYTORCH深度学习框架,并在NVIDIA RTX 8000 GPU上实现。
4 实验结果与分析
为验证所提方法在说话人确认任务上的有效性,分别使用传统的教师-学生知识蒸馏模型和虚拟教师说话人确认模型在Voxceleb1数据集上进行实验,并与其他代表性模型进行效果的比较和分析,最终结果如表4所示。采用余弦距离作为评分方法,使用等错误率(equal error rate,EER)作为说话人确认任务的性能评价指标。在表4中ResnetA-B中的参数分别代表教师模型是A,学生模型是B。

表4 说话人确认的模型效果对比Table 4 Comparison of model effect of speaker verification
作为对比项,模型(1)、(5)来自于传统知识蒸馏说话人确认模型[16]中的实验对比组,模型(2)来自基于Asoftmax损失函数模型[25]的实验项,均在当时取得了较好的效果。未做标注的模型(3)、(4)、(6)、(7)、(8)皆为本文采用控制变量的原则所做的实验组,用于证明所提算法的有效性。
分析结果可知,同样的模型基础,采用动态激活函数的模型(3),优于作为传统知识蒸馏实验项的模型(1)的静态激活函数效果,证明空间共享而通道分离的动态激活函数提高了声纹模型的对特征的表达能力。
在保持激活函数和损失函数相同的情况上,虚拟教师说话人确认模型(8)的EER达到了3.4%,比本文所做的传统知识蒸馏模型(6)降低了0.8个百分点,效果提升了19%,同样的,虚拟教师说话人确认模型(7)比基于传统知识蒸馏的模型(5)的EER也提升了18%,比单独使用Resnet34的模型(2)提升了24%,甚至比Resnet18的模型(4)提升了2倍的性能。这些对比实验证明了手动设计百分百正确率的虚拟教师说话人确认模型(Tf-SV)可以提供在说话人确认任务中提供更多的类别信息,增强模型的学习和辨别能力。
再由表5的对比可知,VGG-M、Resnet34、Resnet50三个模型均是基于Voxceleb1数据集为提升性能而提出的,虽然性能得到了提升,但也带来参数量和计算量(Madds)的攀升,尤其是Resnet50对于移动设备是很大的负担,而通过减少残差模块通道数来压缩参数的Resnet10,会导致提取特征不明显,性能变差。本文所提模型却能够在模型压缩的情况下,保证性能满足应用的标准,证明了该压缩方法在说话人确认上的有效性。

表5 各模型性能的比较Table 5 Comparison of performance of each model
5 结语
本文采用虚拟教师模型(Tf-KD)的知识蒸馏方法来构建虚拟教师说话人确认模型(Tf-SV)并且在该模型中引入动态激活函数(DY-ReLU)和附加角裕度损失函数(AAM-Softmax)。在Voxceleb1数据集上进行的实验对比表明,使模型参数量和计算量压缩一半,可以降低在硬件设备上功耗和有限的计算负载,并提升模型在无文本说话人确认任务上的训练效率和泛化表达能力,达到了移动式设备低功耗、高性能的基本标准,为把该技术应用在实际生活场景提供了可能性,也为说话人识别任务的研究提供了新的思路,接下来准备进一步地压缩学生模型和提升性能评价指标EER来满足不同的需求。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信产业报(2018年32期)2018-11-24
科技创新与品牌(2018年2期)2018-09-18
微型计算机(2009年4期)2009-12-23
祝您健康(2009年4期)2009-04-08
