
门控多特征提取器的中文命名实体识别
2022-04-21 05:16杨荣莹杜逆索
计算机工程与应用 2022年8期
杨荣莹,何 庆,杜逆索
1.贵州大学 大数据与信息工程学院,贵阳 550025
2.贵州大学 贵州省公共大数据重点实验室,贵阳 550025
3.贵州大学 贵州省大数据产业发展应用研究院,贵阳 550025
命名实体识别(named entity recognition,NER)最早是在MUC-6[1]会议上作为一个子任务被提出,目的是将文本数据中具有特定含义或信息的实体识别并抽取出来,这些实体包括地名、人名、机构名、生物术语、医学术语等,是自然语言处理(natural language processing,NLP)任务中信息检索和信息抽取的基础核心任务。命名实体识别在NLP下游任务如机器翻译、舆情分析与监测、知识图谱、情感分析中均有广泛应用,在情感分析中,要准确预测情感极性,前提是确定感情实体,在知识图谱中,需要在输入文本中识别抽取命名实体以进行实体关系对的生成。
英文NER在深度学习领域的成功,激发学者对非英语语种NER的探索。与英语不同,中文缺乏明确的单词边界,需使用分词工具对其分词,若错误分词,将导致实体划分错误,标签分离,实体不完整,句子被错误解读,最终影响模型的性能。为了解决中文单词边界模糊的问题,一些学者将分词模型与NER模型共同训练,或在词向量中直接添加分词信息,这为NER任务带来相应的噪声,不能有效克服NER模型受分词效果的约束。
于中文而言,中文具有“一词多义”、句式复杂等特征,如在“我好了”/“你的喜好”两个句子中,“好了”表示完成某事,而“喜好”中的“好”表示喜欢;此外中文结构复杂,倒装句式、双重否定、省略句式等普遍存在,若想完全掌握某句所传达的意思,确定某个单词的实体类别,需要参考上下文乃至全文本的语境,对于NER模型来说,更好地捕获上下文长距离依赖,深度挖掘文本特征,提取序列局部和全局依存关系,是一直探索且具挑战性的研究问题。
现阶段NER模型大多基于BiLSTM-CRF架构,而双向长短期记忆网(bidirectional long short-term memory network,BiLSTM)在面对超长文本时,样本无法并行计算,且信息传输通道单一,导致计算速度慢。且多数NER模型中,条件随机场(conditional random fields,CRF)层只能从一个特征提取器中获取最终特征,特征多样性差,致使CRF预测序列标签的准确性低,性能弱。
针对以上问题,本文在不采用分词模型条件下,利用词向量模型提取信息丰富的词嵌入,克服NER模型受分词效果的影响;基于多头自注意力机制,通过多特征提取器多层次挖掘文本全局、局部特征,精准掌握文本信息,捕获文本更长距离依赖;采用迭代膨胀卷积(iterated dilated convolutional neural network,IDCNN)网络作为其中一个特征提取器实现并行计算,并引入门控制机制实现信息的流量控制和多通道传输;构建双CRF网络处理具有不同分布特点的特征。基于以上操作最终实现提升中文NER模型实体识别性能的目标。
1 相关工作
命名实体识别一般被作为序列标注问题来解决,其从传统的概率统计方法进化至现今基于神经网络的主流方法。应用较为普遍的神经网络有循环神经网络(recurrent neural network,RNN)[2]、卷积神经网络(convolutional neural network,CNN)以及RNN的两个变体长短期记忆网络(long short-term memory network,LSTM)[3]和门控循环单元(gated recurrent unit,GRU)[4]等。其中,Collobert等人[5]利用CNN网络进行序列建模,捕捉序列局部信息,进而使用CRF模型约束输出标签的连续性。Huang等人[6]采用双向LSTM网络作为序列编码器,捕捉序列前向和后向的信息,将CRF作为解码器构成BiLSTM-CRF模型,在很多公开NER数据集上达到了最佳效果。
由于分词性能的好坏极易影响基于词嵌入模型的NER[7],许多中文NER以分词模型、单词边界为研究核心。Cao等人[8]提出了一种对抗迁移模型,将任务共享边界信息整合到中文NER中,再从中文分词(Chinese word segment,CWS)任务中学习任务共享的单词边界信息,并过滤CWS中的特定信息,以捕获句子中任意两个字符之间的长距离依赖关系,但该方法无法杜绝分词效果给NER模型带来的影响,且过滤的信息中可能也会包含一些重要信息;Wu等人[9]提出了基于CNN-LSTMCRF架构的联合训练模型,以解决中文上下文高度依赖、边界识别困难、中文NER训练数据不足等问题,然而该模型词嵌入层获取的词信息不够丰富。基于分词模型的NER虽能在一定程度上改善实体识别性能,但不能完全解决分词效果对NER的约束。
为提取文本长距离依赖,深度挖掘文本特征,一些NER模型基于辅助特征对模型进行改进。如Xuan等人[10]在引入汉字字形信息情况下,基于滑动窗口和切片注意捕获上下文依赖和符号特征之间的潜在信息,然而构造字形数据需要耗费一定资源,且使用的辅助特征泛用性差;Zhou等人[11]基于片段的方法,引入位置相关特征和外部词典生成表征性更强的字符特征;李健龙等人[12]基于注意力机制对BiLSTM进行扩展,利用CNN提取字向量,融合字词信息作为输入向量输给模型,在军事文本语料库中,F1值达到了87.38%,然而CNN提取信息时仅能得到输入信息部分特征,提取的字向量信息表征性能弱;Zhu等人[13]利用基于局部注意力CNN来获取相邻字符的局部信息以及全局注意力GRU提取序列上下文约束,构建适合中文NER的CAN卷积神经注意网络,而该模型无法控制数据流量、使数据多通道传输。
上述NER模型中,均基于一种特征提取器进行特征提取,且多数采用BiLSTM网络,该网络虽然能有效捕获序列双向信息,但其无法并行计算,在面对长文本时,不能有效发挥该网络优势;当研究者采用可并行计算的CNN模型进行特征提取时,网络感受野较小,获取的信息表征性较弱。以上模型中,CRF层采用的特征分布单一,致其无法依据更多特征分布充分考量序列间、标签间的约束关系。
综上,针对中文文本缺乏明确词边界,放弃分词模型而采用预训练词嵌入模型提取丰富的单词信息,从根本杜绝NER模型受分词效果的约束;为精准掌握全文信息,捕获文本深层次特征、提取长距离约束及全局依赖,本文在不借助其他细粒度特征条件下,聚焦文本自身,采用多特征提取器多层次、多维度挖掘文本特征;引入多头自注意力机制以提升特征提取效率和精度,使模型将注意力聚焦于关键特征而忽略影响力较弱的信息;将IDCNN作为其中一个特征提取器,在实现并行处理基础上扩展卷积网络的感受野以提取表征性更强更丰富的序列特征,此外,为达到流量控制,使特征跨层、多通道传输,在膨胀门控线性单元(dilated gated linear unit,DGLU)的启发下,为IDCNN网络引入门控机制;为使CRF层依据多样特征多角度预测标签序列,使用两个CRF模型并构造最终的损失函数。通过以上策略,基于实验对比分析其他中文NER模型,结果表明,采用多特征提取器可挖掘文本深处特征,获取表征性强、语义丰富、更长距离依赖的特征信息,在一定程度上可提高中文命名实体识别性能。
2 模型
文献[8]将分词信息与词向量信息融合输入到私有特征提取器和共享特征提取器中,受此启发,本文模型将词向量信息分别输入两个特征提取器中,最后通过共享BiLSTM网络整合两个模型所提取的文本信息,构建两个CRF模型实现标签序列预测,具体模型如图1所示。
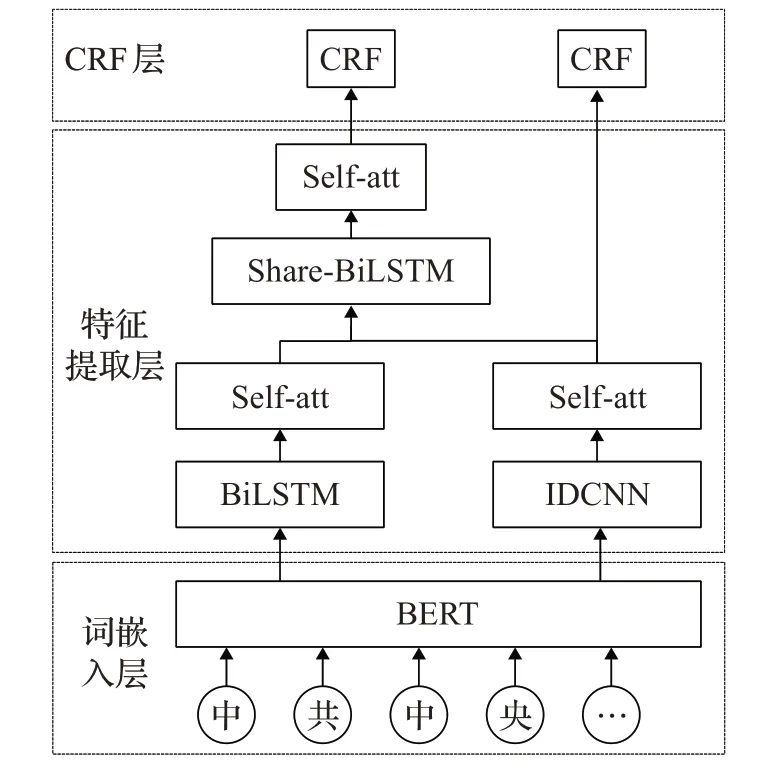
图1 模型结构图Fig.1 Model structure diagram
2.1 嵌入层(BERT)
BERT[14]预训练语言模型的问世,开创了NLP领域的新纪元。BERT继承了Tranformer网络的双向编码方式,运用遮掩机制对输入文本随机遮盖,并采用句子级负采样,学习句子与句对间的关系,增强了模型的泛化能力,充分提取字符级、词级、句级、句间的特征。
BERT在NLP领域的卓越成绩,致使学者对BERT进行二次开发,衍生出许多预训练模型。然而,训练BERT需要耗费大量资源,现实中很难满足BERT训练要求。因此,大多数NLP研究均使用已训练好的BERT。本文为提高训练效率,采用已训练好的中文BERT模型,将文本数据向量化处理。
2.2 特征提取层
为了获取更深层、表征程度更强、上下文依赖更长距离的特征,在编码层采用三个特征提取器进行特征提取,即BiLSTM、IDCNN、share-BiLSTM。
首先,将BERT生成的词向量分别输入BiLSTM和IDCNN模型中,基于多头自注意力机制实现特征提取。由于BiLSTM和IDCNN提取出的特征具有自身特点,若将BiLSTM和IDCNN的输出分别输入到CRF层,CRF只能依据单个编码模型的单调特征进行序列预测,特征单一、表征性欠佳。因此,构建一个share-BiLSTM特征提取器,拼接BiLSTM和IDCNN提取的特征信息,将其送进share-BiLSTM编码器中。通过该操作,实现了编码模型的特征共享,共享编码器利用共享特征再次进行特征提取,既可增加特征多样性,又增强特征表示强度,可为CRF层提供泛化能力更强、分布形式更多样的特征信息,提高序列预测的准确性。特征提取层各编码器的输入输出如下所示:

w为BERT模型预训练的词向量,Y b为BiLSTM的输出,Y c为IDCNN的输出。output作为share-BiLSTM的输入。
2.2.1BiLSTM
在RNN网络中加入输入门、遗忘门、输出门,得到RNN的变体长短期记忆网络(LSTM),以此解决RNN中梯度消失和梯度爆炸问题。而LSTM只能获取单向信息,为提取文本上下文信息特征,本文采用双向LSTM(BiLSTM),BiLSTM由前向LSTM和后向LSTM组合而得,其目的是整合序列前后向信息,获取范围更广的上下文依赖。BiLSTM计算过程如下:

其中,x t为序列的输入,hf∈Rd h表示当前时刻前向LSTM的隐藏状态,记忆序列的“过去”的信息,hb∈Rdh表示后向LSTM的隐藏状态,记忆序列的“未来”的信息,ht表示当前t时刻的最终隐藏状态,W1、W2分别为模型的参数。
2.2.2基于门控机制的IDCNN
CNN在进行卷积操作时,仅能得到原始输入中的一小块信息,而序列标注问题中,要尽可能提取输入序列全局、局部特征。若运用CNN处理序列标注问题,需添加更多的卷积层以实现对输入信息的大范围覆盖,这将降低模型的训练效率。为解决该问题,Yu等人[15]提出Dilated Convolutions(膨胀卷积)模型,与CNN不同,膨胀卷积为了减小信息丢失而去掉池化步骤,通过增大感受野来扩展特征覆盖范围。Strubell等人[16]以膨胀卷积为基础,拼接4个相同结构的膨胀卷积block,改造编码器的扩张架构,建成IDCNN。与BiLSTM相比,CNN拥有更强的并行计算能力,而IDCNN的训练速度比CNN更高,感受野比CNN更宽,覆盖的特征信息更广,因此本文采用IDCNN作为另一个特征提取模型,将词向量输入IDCNN中捕获序列特征。
为提取更高维、更抽象的信息特征,本文对IDCNN的卷积进行改进。受膨胀门控线性单元门控机制的启发,本文将门控机制引入IDCNN的卷积核中,IDCNN的卷积形式变为:
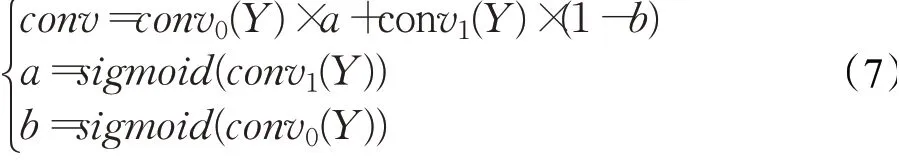
Y为卷积核的输入,conv0和conv1是两个形式一样的卷积核,但超参数与权重均不同,sigmoid函数最终的输出值范围为(0,1)。
式(7)中,分别构建两个卷积核,采用sigmoid函数为每个卷积核添加一个阈值。其中,卷积核conv0以概率sigmoid(conv1(Y))通行,conv1以1-sigmoid(conv0(Y))的概率通行。基于此操作,两个卷积核在阈值函数的作用下,根据彼此间的卷积信息进行流量控制,为两个独立的卷积核搭建信息共享桥梁,实现彼此间信息的共享流通。此外,两个卷积核的构建,可实现信息多通道传输,基于概率的通行实现了特征信息的控制性、选择性流动,更清楚特征提取器中信息数据的流量与流向。基于以上改进策略,将模型内的信息共享交互,多通道传输数据,提高模型性能和效率。具体结构如图2所示。
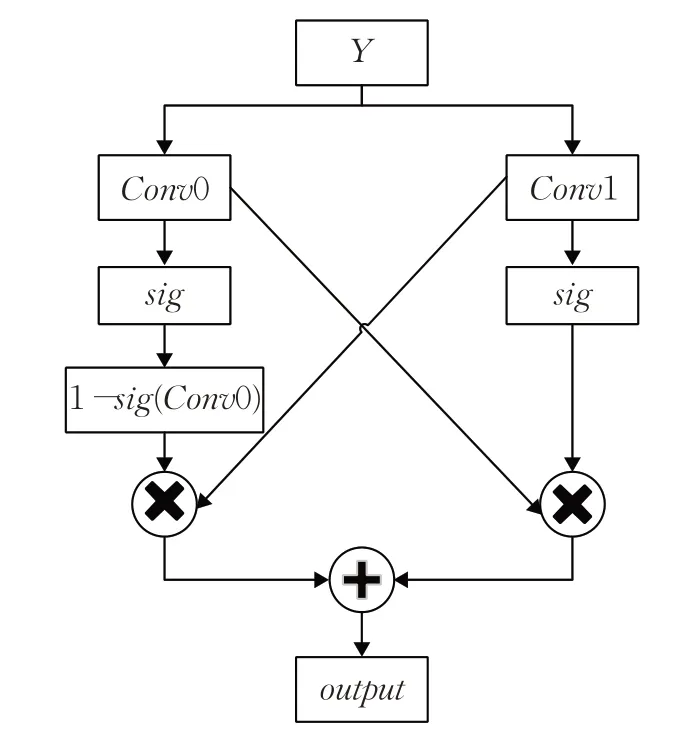
图2 基于门控机制IDCNN卷积核结构Fig.2 IDCNN convolution kernel structure based on gating mechanism
2.2.3多头自注意力机制
在人脑认知方式的启发下,研究者开发了注意力机制。在提取特征过程中,该机制聚焦于重要特征而忽略影响较弱的信息,以提高特征提取的效率与能力,捕捉文本中的长距离依赖。
Vaswani等人[17]于2017年提出自注意机制,与注意力机制相比,自注意力策略找寻的是序列内部的特征,利用来源相同的查询和键值对在序列内部进行注意力计算[18]。为从不同子空间获取相关特征信息、多维度地提取文本特征、捕获更长距离依赖,本文采用自注意力变体—多头自注意力机制。该注意力机制先利用不同参数得到值矩阵V、查询矩阵Q以及键矩阵K,将V、K、Q映射到多个不同的子空间中,独立计算各个子空间的注意力,最后将其拼接整合,利用线性计算得到最终注意力值。“多头”即划分的子空间数。计算方式如下:
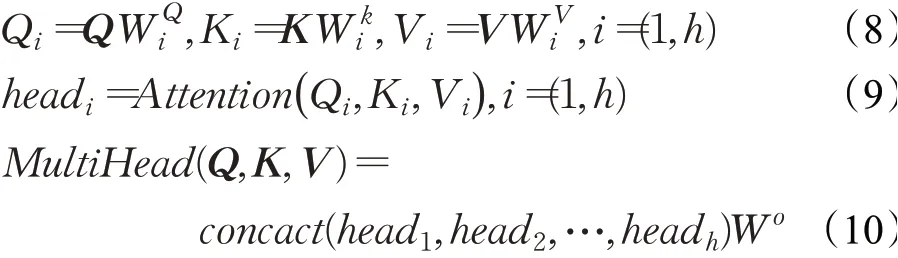
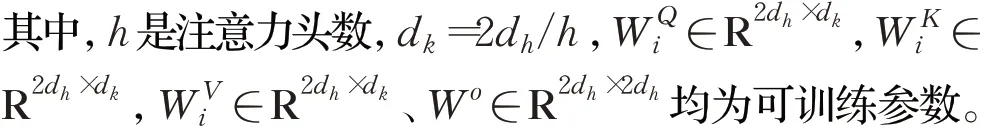
在特征提取层,BiLSTM和IDCNN提取器虽然具有相同的输入,但其特征提取的机制不同,share-BiLSTM与BiLSTM虽具有相同提取机制,但两者输入不同,最终每个特征提取器得到的信息特征分布不同,特征表征也存在差异。为增强特征提取器挖掘文本特征的效率,增加模型提取特征的深度,三个特征提取器均加入多头自注意力机制,以在不同的特征信息分布和表征下,使模型专注于关键文本信息,从不同的子空间中挖掘更具代表性的特征表示,提取文本长距离依赖。
2.3 CRF层
序列标注问题在获取文本特征后,需对当前标签进行预测。虽然特征提取器也能预测序列标签,其只能依据所提取的序列特征对当前序列进行预测,仅考虑字词自身特征而忽略了标签与标签之间的约束关系。字间、词间、文本间的关系不仅与语义环境、全局文本有关,还受标签彼此间与相邻标签的影响。因此,在解码层,采用基于判别式概率无向图学习模型的条件随机场(CRF)预测序列标签。CRF以全局序列为关注区域,可充分挖掘文本序列间、标签序列间的依赖,提取优质的全局特征,得到最优的标签序列,最终实现实体识别。CRF利用极大似然估计构建条件概率模型,并利用负似然函数计算损失函数值,损失函数具体如下:

概率P数学表达式为:
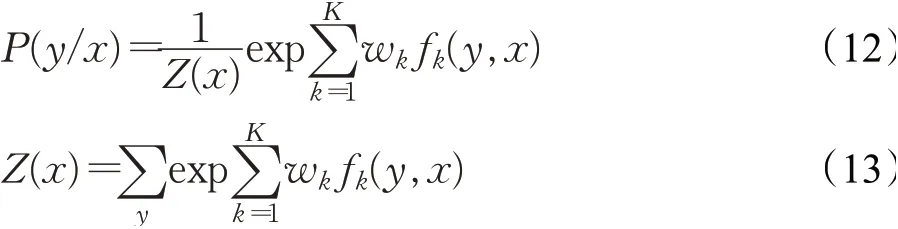
式中,x=(x1,x2,…,x n)为观测序列,y=(y1,y2,…,yn)为对应的状态序列,fk是x、y的特征函数,w k是训练权重,Z(x)为归一化因子。
在本中,使用两个CRF模型,一个用来预测share-BiLSTM的输出,另一个用来预测IDCNN模型的输出。share-BiLSTM得到的是BiLSTM与IDCNN融合后的特征,代表两个特征提取器融合后的特征分布。而融合前的特征也表征序列特征分布,因此将IDCNN提取的特征输入到另一个CRF模型中,使CRF模型了解融合前的特征分布,增强标签序列的特征表示,实现特征信息的跨层传输,使CRF依据更多样的特征形式实现标签预测,提升预测准确性。
分别计算share-BiLSTM和IDCNN的输出经过线性映射后得到的每个标签的得分:


其中,losssb表示share-BiLSTM的经过CRF模型得到的损失函数,lossid表示IDCNN经过CRF得到的损失函数,∂=0.01是lossid的权重值。
损失值是指导模型训练学习的参数,过大或过小影响着模型的训练结果。如果直接将两个CRF模型所得的损失值进行相加,会导致损失值过大,不利于模型训练。share-BiLSTM特征提取器接收的是前两个特征提取器所提取到的特征,IDCNN提取的仅代表着为融合前序列的特征分布,特征单一。因此,为由IDCNN提取的特征输入到CRF所得的损失值添加权重,确保损失函数值的有效范围,为模型训练提供合适的损失值。
3 实验与分析
3.1 实验环境与参数
本文所有实验均在Ubuntu Server 18.04操作系统、显卡为TITAN-XP 12 GB×6、内存为32 GB×4的服务器上进行,本文的实验环境是在TensorFlow1.9.0框架下搭建,Python版本为3.6.10。
为保证模型的泛化性、实验的公平性及说服力,最大化确保参数的一致性,仅改变模型中个别参数,依据数据集大小为每个数据集设置不一样checkpoints步数,其余参数为:batch_size为64,学习率lr为0.001,dropout为0.5,clip为5,句子最大长度max_len为128,LSTM隐藏层的大小为128,优化器为Adam。本文不对BERT模型进行微调,直接使用已训练过的中文BERT模型进行预训练。
3.2 数据集
本文主要进行中文的命名实体识别,因此,采用两个中文NER数据集对本文所提模型测试。其一为MSRA[19],是由微软亚洲研究院提供的中文命名实体识别的简体中文数据集,该数据采用BIO标注机制,包含人名、地名、机构名实体,实体标签包括:O、B-ORG、I-ORG、BPER、I-PER、B-LOC、I-LOC等;另一个数据集为中文简历数据集Resume[21],该数据集采用BMES标注方式,实体包含:B-NAME、M-NAME、B-CONT、B-EDU、S-CONT、S-EDU等。数据集具体情况如表1所示。
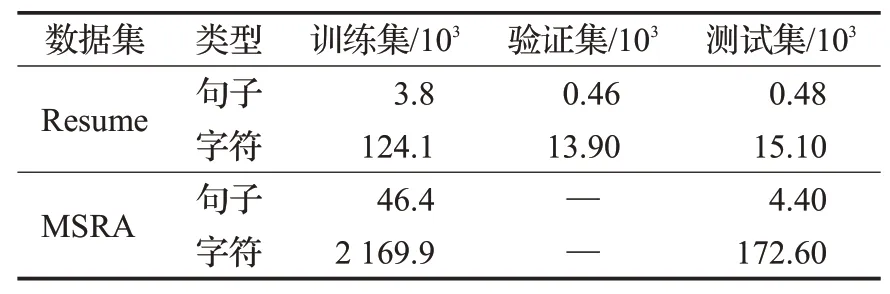
表1 数据集统计结果Table 1 Statistics of datasets
3.3 评价指标
为了检测模型的性能,采用准确率P、召回率R和F1值作为评价指标,具体的计算公式如下:
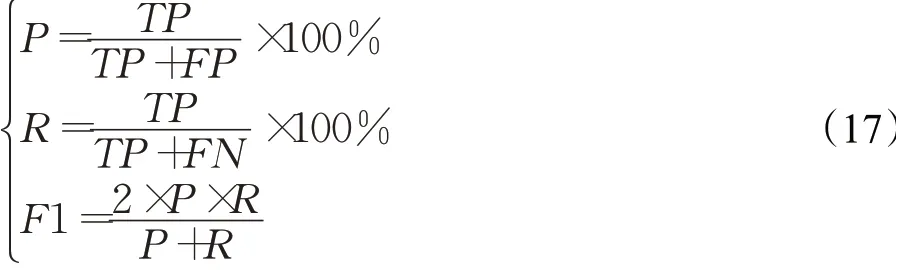
式中,TP为正确识别命名实体的个数,FP表示错误识别命名实体的个数,FN表示没有被识别命名实体的个数。
3.4 实验结果与分析
为了验证所提模型的有效性,使实验更具可比性,将本文所提模型与以下几个模型进行比较(为保证比较公平性,所比较的模型均采用BERT模型进行词嵌入的预训练)。
BERT-Tagger[14]:BERT-Tagger是对BERT微调后得到的模型,其为BERT添加一个额外的输出层,以获取更丰富的上下文表示。
Lattice LSTM[BERT]:其在Lattice LSTM[20]模型的基础上采用BERT作为预训练模型,Lattice LSTM显式地利用单词和序列信息,对字符序列、词典匹配的所有潜在单词进行编码。
LR-CNN[BERT]:LR-CNN[21]使用重新思考机制,通过高维特征反馈来解决单词冲突问题,以此对所有与句子匹配的字符和潜在单词进行向量化。LR-CNN[BERT]在LR-CNN基础上,利用BERT模型进行预训练。
PLTE[BERT][22]:PLTE利用位置关系提升自注意力,引入多孔机制增强局部性特征并捕获长距离依赖,该模型可实现数据批处理。最后在PLTE中使用BERT实现预训练。
3.4.1总体性能比较
在实验中,采用P、R、F1作为评价指标,而F1代表着准确率、召回率的调和均值,准确率、召回率的大小决定F1的大小。因此本文采用F1值作为观察基点。具体实验结果如表2、3所示。
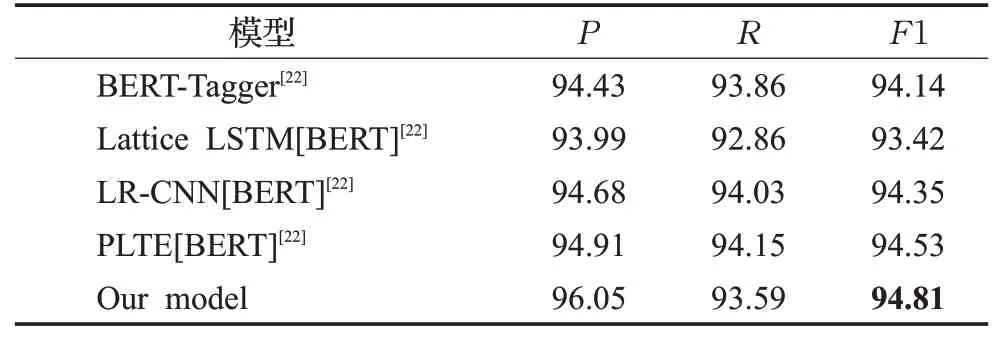
表2 MSRA数据集的测试结果Tabel 2 Test results on MSRA dataset %
其中,表2是各模型在MSRA数据集上的测试结果。从表中可得,本文所提模型的F1均优于其他四个模型。与微调BERT(BERT-Tagger微调BERT的输出层)方式相比,所提模型F1值提高0.67个百分点;与基于加入字词信息的NER模型比较(Lattice LSTM[BERT]加入了词信息),本文模型F1值提升了1.39个百分点;与引入字词相对位置信息的PLTE模型相比,本文模型F1值提升了0.28个百分点。但从表中明显可见,在MSRA数据集中,本文模型的召回率略低于其他模型,表明在该数据集中,所提模型从所有样本数据中正确识别并提取实体的能力弱于其他模型;观测准确率,其明显优于其他模型,标志着本文模型实体预测能力较强,预测精度较优。
表3是在Resume数据集中的测试结果。由表可知,F1值最大提升1.09个百分点,最小提升0.05个百分点,准确率P和召回率R值均有所提高。与PLTE模型相比,本文模型F1值仅提升0.05个百分点,优势不明显。其原因可能是,相比MSRA数据集,Resume数据集包含的实体类型更多样,且Resume数据集采用BMES标注机制,模型不仅要识别实体开始部分,还需识别实体中间、末尾部分以及单个字词实体,而MSRA数据集采用BIO标注策略且实体种类较少,只需以“B”和“I”判别实体位置确定实体包含的字符个数。
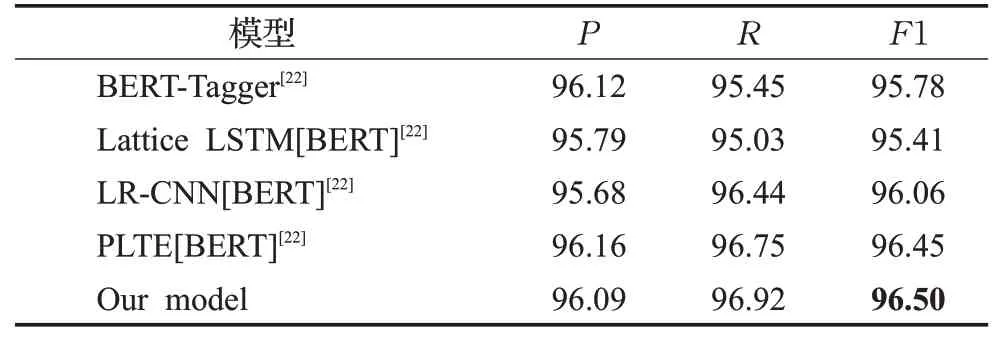
表3 Resume数据集的测试结果Tabel 3 Test results on Resume dataset %
通过与其他改进策略的NER模型比较,本文在不引入其他细粒度特征、不使用词典、不对BERT进行微调的情况下,基于预训练模型和多头注意力机制,通过构造多个特征提取器和预测模型,将特征提取器之间的信息进行共享、交互、融合,扩展特征信息的多样性,可使NER模型多维度、多层次地挖掘序列更抽象、更深层的序列特征,提升NER模型的识别提取预测能力。
3.4.2方法验证
本模型主要目的是提取深层、抽象、高维的特征,因此,为了全面验证改进模型的有效性,设立几个基线模型进行对照实验,递进式验证模型性能。对照的基线模型如下:(1)Baseline1,该基线使用BiLSTM和IDCNN进行特征提取,其中,IDCNN没有引入门控机制,最后将提取的特征进行拼接,并输入到同一个CRF中进行序列预测;(2)Baseline2,该模型在Baseline1的基础上,加入share-BiLSTM特征提取器,以此融合前两个特征提取器所挖掘的特征信息,两个特征提取器之间实现信息共享,最后将share-BiLSTM获取的特征输入到CRF层;(3)Baseline3,基于Baseline2,再构造一个CRF模型,将融合前的特征信息加入CRF中,以致CRF可以根据融合前的特征分布预测标签,为CRF提供更多样的特征,最后将两个CRF的损失函数值相加作为最终损失,不添加权重系数,不使用门控机制;(4)Baseline4,为验证IDCNN对模型的影响,构建Baseline4,该基线去掉IDCNN网络,仅保留BiLSTM和share-BiLSTM以及一个CRF(即仅保留图1左边)解码器;(5)Baseline5,该基线在采用门控机制和损失权重的基础上,三个特征提取器均不使用多头自注意力策略,以从侧面展现注意力对NER模型的影响;(6)Baseline6,该基线保留本文模型的整体架构,仅在损失函数中去掉损失权重,从而验证本文损失函数的有效性。
由于Resume数据集的实体类型较丰富,标注形式比MSRA复杂,实体识别与提取比MSRA数据集更难,为了验证改进方法的有效性,选取Resume数据集作为基线模型的测试数据。测试结果如表4所示。
从表4可知,若将两个特征提取器所挖掘的特征直接拼接并输入到CRF中进行实体识别时,其准确率和F1值较低。将由两个不同特征提取器捕获的特征直接拼接,可能会扰乱特征分布,以致CRF利用混乱的特征进行实体提取,导致预测能力弱,精准度低;若将前两个特征提取器挖掘的特征分布融合再输入到共享特征提取器中,共享特征提取器将依据两个模型的特征分布再次提取特征,得到的特征信息包含着两个模型的特征分布,特征表示得到增强,多样性增加,NER模型性能得到改善,P、R、F1值得到一定程度的提高;若仅利用融合后的特征进行序列预测,模型将无法了解融合前文本特征的分布情况,因此,再构建一个CRF模型,使模型根据融合前的特征情况预测序列,由结果可知,准确率提高3.53个百分点,F1值提高1.72个百分点,模型性能得到明显改善。若为模型的IDCNN引进门控机制,使特征数据选择性流动、多通道传输,并在流通过程中共享交互,以提取高维、抽象特征;为损失函数添加权重,保证损失函数的合适范围,确保模型训练效果,最终以增强模型识别预测实体能力。从结果可知,该策略在一定程度上提升了NER模型的实体识别性能。
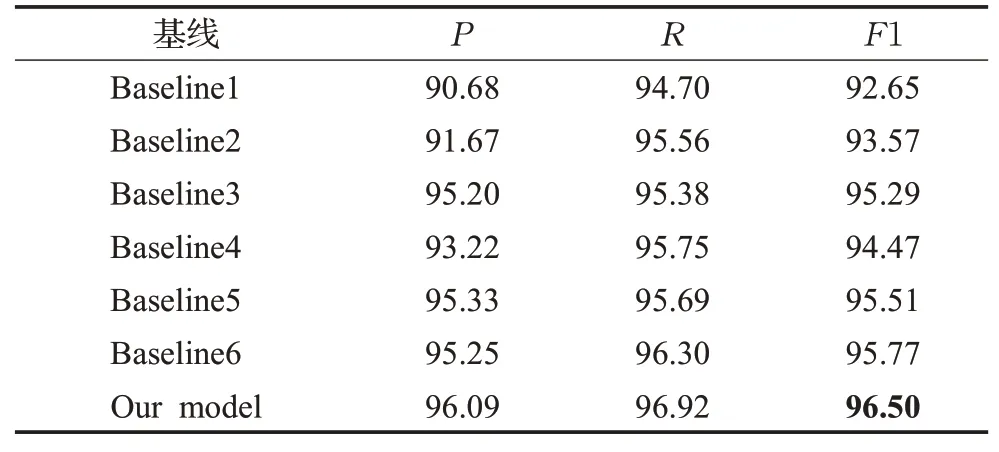
表4 基线测试结果Tabel 4 Test results on baseline %
如果仅采用一种类型的特征提取器而去掉IDCNN,提取的特征多样性会降低,表征程度得不到加强,同时,阻碍了特征信息的跨层传输,以至CRF无法真正了解融合前的特征分布,与本文所提模型相比,Baseline4的F1值降低至少2个百分点;多头自注意力机制使模型专注于输入的关键特征信息,多空间地提取长距离依赖,由表4的Baseline5可知,若不采用注意力机制,模型提取的特征依赖度不强,特征挖掘深度不够,导致NER模型F1值下降近1个百分点;由Baseline6与Our model比较可得,若去掉损失权重(即为两个损失值直接相加),损失值增大近一倍,这将影响模型训练效果从而导致模型预测精度下降,由此可知有效的损失函数对命名实体识别模型具有重要影响。
综上所述,以文本自身作为研究材料,不引入其他细粒度信息、不添加辅助工具,在采用词向量模型获取表征丰富的词向量以及利用多头注意力策略基础下,通过构造多个特征提取器,将各模型内的特征信息进行融合交互,可深度挖掘抽象深层的序列特征、捕获更长距离依赖、深刻认知文本全局信息;门控机制的使用,增加数据的流通途径,控制了数据流量;使用双CRF网络,在扩展特征多样性基础上实现特征信息的跨层传输。从实验结果看,以上策略可提升命名实体识别模型的预测识别性能,改善NER模型。
4 总结
本文提出了一种专注于特征提取的命名实体识别模型。以文本数据作为开发核心,在BERT词向量模型和多头注意力机制基础上,通过构建多个特征提取器并将各特征提取器挖掘的特征进行交互共享,从不同层次、不同维度挖掘抽象的文本特征;在序列预测阶段,为CRF加入不同分布的特征信息,以增强特征多样性;为增强高维特征的提取能力,在IDCNN中引入门控机制,在控制数据流量和流向的情况下实现信息多通道传输;最后构造合适的损失函数以保障模型训练效果。在两个数据上与其他NER模型进行比较,本文模型的F1值有一定程度的提高。相比其他中文NER数据集,本文采用的数据集较大,下一步计划是将该模型应用于更小量级数据中,以检测特征提取方法在轻量数据中的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中国外汇(2019年18期)2019-11-25
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
当代陕西(2019年5期)2019-03-21
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
