
利用改进型VGG标签学习的表情识别方法
2022-04-21 08:02程学军邢萧飞
计算机工程与设计 2022年4期
程学军,邢萧飞
(1.河南工业大学漯河工学院 信息工程学院,河南 漯河 462000;2.广州大学 计算机科学与网络工程学院,广东 广州 528225)
0 引 言
人脸表情是最直接、最明显的情感表达方式,对其有效的识别具有重要的理论意义和实用价值[1,2]。而实际中,光照变化致使人脸表情识别面临着各种挑战,研究有效适用性强的人脸表情识别方法显得更为迫切[3]。
对于计算机来说,人脸表情识别技术的本质是对采集图像中海量数据进行优化处理。因其采集图像存在多样性和复杂性,计算机处理系统会面临样本数据非线性不确定性的问题[4]。而传统处理方法如主成分分析、尺度不变特征转换等方法,也存在模型简单、参数设置复杂等问题。
深度神经网络则可实现对图像数据的深度提取,并基于自身网络的不断学习,对于网络模型参数也可进行及时调整,以满足识别场景多样性和表情识别准确性的需求[5,6]。
借鉴于现行深度学习技术,提出了一种利用高斯特征提取结合改进型VGG-16网络模型的人脸表情识别方法。主要创新点总结如下:
(1)为更好支撑VGG-16神经网络对被测图像的表情识别,基于改进的高斯混合模型对图像数据及采集数据进行图像重建并实现特征的提取;
(2)针对传统神经网络的图像识别忽略表情关联性问题,基于VGG-16神经网络模型对图像特征采集进行相关情感标签分布学习和正则化学习,实现判别性区分,从而提高识别准确度;
(3)面向在线表情实时识别的需求,采用小批量梯度下降法简化网络训练模型目标函数,减小运行内存,提高模型对于表情识别的时效性。
1 相关工作
人脸表情识别研究涉及特征提取、图像理解、数据分析和表情分类等内容,其研究成果对于计算机视觉、认知科学、心理学等领域有着重要意义。目前已有一定研究人员对人脸表情识别展开研究,其目的是对面部图像6种基本情绪表情准确分类识别,包括[7,8]:愤怒(An)、厌恶(Di)、恐惧(Fe)、快乐(Ha)、悲伤(Sa)和惊讶(Su)。
传统的人脸表情识别方法主要为表观特征法和模型法两种方法。主成分分析法作为表观特征法的代表方式之一,基于近似理论通过寻找最小均方值[9,10],获取原始数据的最大可能投影方向,但其运算量较大,且不计及图像细节机构信息;Gabor滤波算法可有效提供测图像数据细节信息[11],实现多数据多维度识别分析,但存在决策数据维数过高的问题,不满足实时表情识别的需求;点分布模型(point distribution model,PDM)是一种模型化的图像识别方法,其可计及图像表情的形状特征和纹理特征进行综合考虑统一建模,实现图像特征准确提取,但同样面临计算复杂的问题,并且存在场景自适应能力差的缺陷[12]。
机器学习可通过网络模型中多层网络结构的迭代分析决策,基于海量数据进行自主分析决策,以强大的学习能力实现人脸表情识别的实时性和准确性。针对面部表情识别问题,文献[13]提出了一种基于概率融合的卷积神经网络模型,采用卷积整流线性层作为第一层并实时调整模型训练参数和架构来适应CNN的体系结构,具有较好的识别准确性;文献[14]采用多任务深度卷积网络(multiple task deep convolution neural network,MTCNN)检测人脸的界标点,并通过冗余去除和降维改进实现图像微表情中光流特征的高效提取,基于对课堂教学中的实际应用验证方法合理性;文献[15]提出一种基于深度信念网络(deep belief network,DBN)使用简化特征的半监督情感识别算法,首先将特征提取应用于面部图像,然后进行特征约简,降低错误和无效的特征数据信息。
但以上方法均没有对各种表情之间的关系进行阐释分析,表情是由多个面部动作模块组合而成,其面部动作模块的变化并不是完全相同;其次,同一面部动作模块的运动存在于不同的表情中。根据普鲁奇克的情绪之轮理论,大多数情绪都是以基本情绪的组合、混合或复合形式出现的。同时,人类的面部表情往往是不同情绪的融合或复合,而不是单一的基本感觉。从这个意义上说,面部表情是模糊的或相关的,即可以使用多个表情数来描述人脸的外观。因此,以上方法存在复杂场景下可能无法描述不同情绪中的相关性或模糊性,导致图像表情识别低下的问题。VGG网络结构非常简洁,可通过不断加深网络结构可以提升性能,以实现多场景多噪声环境下图像表情准确区分与识别[16]。文献[17]提出了一种改进的VGG网络的表情识别模型,该模型优化了网络结构和网络参数,并通过迁移学习技术来克服图像训练样本的不足。文献[18]基于VGG网络模型对面部表情和人声变化进行识别,评估3种不同数据模式输入中的躁动级别分类的有效性:单独的语音观察、单独的视觉面部观察以及组合的语音和面部观察,显著提升表情和人声的识别率。
基于VGG深度神经网络的易扩展、自适应能力强等优点,结合高斯特征提取方法,提出了一种近红外人脸表情识别方法,该方法能更好地提取图像特征,并通过面部表情的基本情绪赋值,实现表情的准确识别。
2 红外人脸特征提取
为了更好地支撑VGG-16神经网络对图像特征的训练和学习,以满足更加精确的人脸表情识别,通过极大化数据模型对高斯混合模型进行改进,实现对图像采集数据的图像重建和特征提取。
2.1 红外人脸图像的重建
由于采集的红外人脸图像存在图像像素分布不均匀问题,需要对其进行图像重建的操作。首先通过极大化数据模型的相似度对图像模型数据参数进行针对性提取,并基于极大似然拟合算法计算该模型的熵值和高斯度数值,继而可将模型转化为高斯混合模型,以此将采集模型转化为热红外人脸高斯混合模型[19]。
图像重建操作具体操作如下:
(1)模型期望概率数值计算:对采集图像的各像素隶属k区域概率。C为模型概率矩阵,cik为图像中像素xi可归于区域k的期望数值,具体计算公式为
(1)
式中:pk为当前估计值计算概率矩阵C中元素cik的期望概率。
(2)模型邻域概率计算:对每个像素相邻8个邻域隶属概率值进行加权值计算。需要注意的是,在该步骤计算时需要对概率矩阵C和权重系数P′i进行迭代更新:
首先,对采集图像的像素xi的邻域隶属概率的加权平均系数Pik进行计算;将加权平均值矩阵P设为n×K的矩阵,矩阵中元素Pik可通过下式进行计算表示
(2)
式中:∑8(xi)为像素xi邻域的8个附邻区域;υij为像素xi的邻域像素xj对其的影响量化因子;cjk为邻域像素xj可隶属区域的概率。
其次,对模型概率矩阵C进行更新迭代计算,判断xi像素是否为自由像素,若xi是,将概率cik的类归属于元素Pik的相同类;若xi否,则将加权平均参数Pik替换为更新后的概率矩阵。
再次,依据更新后的模型期望矩阵计算相应像素的权重值,计算公式为
(3)
(3)混合模型参数获取:基于极大化数据模型的似然度计算获取混合模型的相应参数。计算公式为
(4)
(5)
(6)

L[X|φ(pk,μk,σk)]=f[X|φ(pk,μk,σk)]=

(7)
(8)
(4)模型转换:采用极大似然拟合将图像模型转换成高斯混合模型,主要可以分为3个步骤:
1)首先对模型对应像素Rk的理论最大熵值进行计算
(9)

2)计算模型像素Rk的真实熵值
(10)
其中,采集图像中像素Rk邻域所对应的总频率记为frj。
3)实现模型似然度最大化,并计算模型的高斯度G
(11)
若模型中高斯度G→0,证实采集图像数据模型已完整转换为高斯混合模型,完成相应的热红外高斯混合人脸图像重建。
2.2 红外特征提取
在上文对于采集图像高斯混合模型化的基础上,选择图像中区域特征点标注为圆心Os,s=1,2,…,nk。为保证不出现重叠圆的现象,对相应区域的像素计算距离图像边缘的欧几里得距离d并获取相应的图像半径rjk
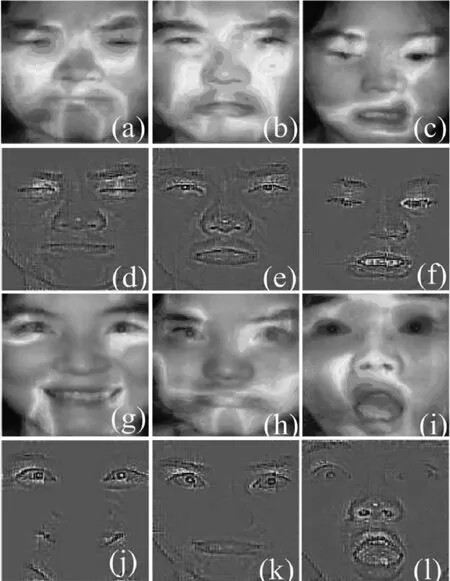
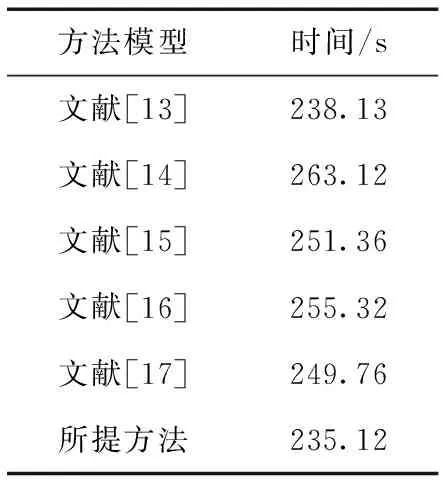
Bk(Os,rjk)={xi∈Rp|i=1,2,…,n,d(Os,Oi) (12) 式中:Oi为圆心标注位置,依据对象像素的位置确定;Bk(Os,rjk)为采集图像中的第s个圆;d(Os,Oi)为Oi、Os两圆间的欧几里得距离。则重建人脸等温特征集Yη为 Yη={Bl}l=1 to η (13) 式中:η为圆标标注参数;Bl为采集图像中第一个最大半径的第l个圆,Bl∩Bm=∅,Bm∈Yη,l≠m。 经极大化数据模型和高斯混合模型处理后,采集图像情感特征的提取结果如图1所示。 图1 各种情感提取结果 在高斯混合模型对图像特征提取的基础上,基于VGG-16神经网络模型对图像特征采集进行相关情感标签分布学习和正则化学习,实现表情识别分类;进一步采用小批量梯度下降法简化目标函数,减小运行内存,提高模型对于表情识别的时效性。 VGG神经网络提出于2014年,其中VGG16模型因训练学习过程简洁实用,广泛用于图像处理和目标识别的研究工作中。VGG16神经网络采用3×3的卷积核,较传统的较大的卷积核,可保证其在对于模型数据的训练学习过程中更为深入。 值得注意的是,对于VGG-16网络模型的讨论分析需要对于其各卷积层进行明确,表1为各卷积层的细节描述[20]。表中,参数conv为卷积层,其数字后缀表示为感受野的尺寸和信道数量。若采样层的初始化为0时,对于下一采样层需要基于一定规律实现梯度计算,表2为各层参数设置情况。 表1 各卷积层设置 表2 参数变量设置 VGG-16网络模型输入为特征提取后的图像: 第A,A-LRN层卷积层结构为128个3×3卷积核; 第B层卷积层结构为256个3×3卷积核; 第C层卷积层结构为394个3×3卷积核; 第D层卷积层结构为512个3×3卷积核; 第E层卷积层结构为512个3×3卷积核; Softmax层为输出层,将分析进行输出。 (14) 图2 典型表情及其相关系数和表情分布 经分析可知,相关情绪标签分布的构建本质是一个映射关系运算(U,V)→D,即给定一个训练集 E=(X1,q1),(X2,q2),…,(Xn,qn) (15) 其中,Qi={q1,q2,…,qn} 是对Xi的真实值的单一标签。则真实值的情绪分布为 (16) 式中:y和qi表示相同的表情;yj和Ulj表示描述Xi的相同的特定情绪。以愤怒为例 (17) 相关情绪标签分布学习(correlation emotion label distribution learning,CELDL)模型本质为一个映射函数p(y|X):X→D,可测潜在相关面部表情的情绪分布[21]。本文假设p(y|X)是从S中学习的参数模型p(y|X;θ),其中θ是模型参数的向量。 (18) 在VGG-16网络中,可基于正则化避免过拟合,提高模型的泛化能力,如L2正则化。作为误差测量的L2损失公式如下 (19) 然后,最佳模型参数向量θ*由以下公式决定 (20) 式中:λ表示L2范数正则化系数。 此外,利用softmax函数计算样本的概率 (21) 式中:θ表示神经网络的参数;NN(X)是修改后VGG-16网络的最后一个全连接层的输出。 目标函数为 (22) 图3 CELDL模型框架 采用相关情绪标签分布结构有两个主要优点:首先,它缓解了不正确的真实值情感问题,只要真实值情感基本正确,即离真实情感不远,那么对真实情感的描述仍然足够高,足以传达积极的标签信息;其次,当学习特定表情的模型时,其它表情中的面部图像可能会有帮助,这意味着可以增强每个表情的训练样本,而无需实际扩展整个训练集。 采用小批量梯度下降法(mini-batch gradient descent, MBGD)有效地简化目标函数L(θ)。关于θj的更新规则表示如下 (23) 式中:α表示MBGD 中的学习率。 用链式法则从第1层到第L层的参数可以计算出CELDL相对于θ的偏导数,θ的递推偏导数方程为 (24) 其中 (25) 和 (26) 则得到δL(θ)/δ(θj)后,用式(23)更新θj。算法1为所提算法的学习过程。 算法1:近红外面部表情识别的CELDL模型 输入:训练集S={X,D} 集合:批量大小b,学习率为α (1)初始化θj (2)j←0 (3)重复 (4)通过式(24)计算δL(θj)/δθj (5)使用式(23)小批量更新θj (6)j←j+1 直至收敛 输出:网络层参数θ* 在本次实验中采用的是Windows 10的操作系统,CPU采用的型号是Intel i5-5400k 6.0 Hz,显卡采用的型号为Radeon Graphics 8核;软件支撑为Google旗下Tensorflow深度学习框架。对Oulu-CASIA近红外数据集、UCHThermalFace数据集及自采集数据集分别实现表情识别。 Oulu-CASIA 数据集包含3种不同亮度情况和两种成像系统的2880个图像数据集,且该数据集能对愤怒、厌恶、恐惧、快乐、悲伤以及惊讶等6种情感表情进行合理划分。本文实验验证选择可见光数据中480个图像表情进行所提识别方法可行性验证。 UCHThermalFace数据集则是在不同的水平角度和垂直角度采集的热成像人脸图像,其也包含室内室外两种情况。本文选择对俯仰角在[-15°,15°]、偏转角在[-30°,30°]的102个热红外图像进行识别实验验证,包含快乐、悲伤愤怒等表情。 为验证本文所提实验具有工程适用性,本文亦选择对实际采集图像进行识别分析。基于V4L2视频采集驱动实现测试图像采集,其大致流程如图4所示。采用内存映射方式,将设备采集的信息映射至应用程序的内存中,并基于mmap函数将数据缓冲区中的图片信息进行导出。本文为提高采集图像导出速率,在对采集数据进行处理时,同时调用两个ioctl命令,先将采集数据缓冲出队列,即VIDIOC_DQBUF,接着再将其入队VIDIOC_QBUF,可有效提升其处理速度。 图4 自采集数据集收集流程 4.2.1 Oulu-CASIA 数据集识别分析 为了评估所提出模型的学习能力,本文对所提的VGG-16 模型的准确率进行分析,如图5所示。为了验证学习能力优越性,在暗光照下对Oulu_CASIA 进行了实验。实验结果分析准确率如图5所示,VGG-16模型框架,随着训练次数的增加,准确率越来越高,在40次迭代后,所提方法的识别准确率趋于稳定。 图5 所提模型识别准确率 采用Grad-CAM来可视化重要区域,如图6所示,同一个人的不同表情不仅展示了大多数不同的类别判别区域,而且还显示了一小部分类别判别区域,图6(a)为愤怒,图6(b)为厌恶,图6(c)为恐惧,图6(g)为快乐,图6(h)为悲伤,图6(i)为惊讶,图6(d)~图6(f)和图6(j)~图6(l)表示来自训练网络的残差表情图像。结果表明,该模型可以在不同的表情中发现更多的有区别性的信息。 图6 同一人不同表情的类别区分区域比较 图7分别示出了愤怒、悲伤和惊讶的类别区分区域,图7(a)~图7(d)为愤怒,图7(e)~图7(h)为悲伤,图7(i)~图7(l)为惊讶。不同的人对同一表情的类别区分区域大部分在相同的区域被激活,验证本文方法的可行性。 图7 同一表情对不同人的类别区分区域的比较 进一步基于3种近红外光照条件下对所提出的模型进行了识别实验验证,平均识别准确率比较结果见表3。在黑暗条件下,本文所提方法较文献[13]、文献[14]、文献[15]、文献[16]和文献[17]的识别方法分别提高13.45%、9.34%、7.46%、6.89%和5.03%;在弱光照条件下,用文献[13]计算的平均识别准确率仅为76.83%,本文方法的平均识别准确率可达到91.54%;在强光照条件下,本文方法比文献[13]、文献[14]、文献[15]、文献[16]和文献[17]方法分别提高了8.35%、8.11%、4.89%、3.92%和2.67%。综上所述,证实所提方法在不同光照条件下的可行性于优越性,且在光照条件下的识别性能优于黑暗条件和弱光照下的识别性能。 表3 Oulu_SACIA的表情识别平均准确率 同时,表4为各方法对于Oulu_SACIA数据集处理时间对比。从图表中可明显看出,在处理时效性上,所提方法可有效实现对于表情的快速判别。 表4 各模型及方法识别时间 4.2.2 UCHThermalFace 数据集识别分析 本文选取UCHThermalFace数据集中6个数据子集进行表情识别实验,包含53个对象6个姿态图像,共计318个数据图像样本。分别3种近红外光照条件下基于UCHThermalFace数据集对所提出的模型进行了稳定性验证,平均识别准确率比较结果见表5。 如表5所示,所提方法对于UCHThermalFace数据集识别分析同样存在强光环境下识别结果要优于黑暗和弱光环境。在强光环境下,对于表情平均辨别准确率可达到93.51%,较文献[13]、文献[14]、文献[15]、文献[16]和文献[17]方法分别提升12.23%、10.31%、8.12%、2.28%和2.75%;而黑暗环境中,因存在光线不足的原因,其识别准确性较强光实验组有整体的下降,其准确率分别为71.23%、79.21%、85.12%、87.32%、88.96%和90.31%;而弱光场景下,所提模型准确率为92.34%,较文献[13]提升13.56%的准确性。 面向UCHThermalFace数据集各方法处理时间见表6,所提方法具有明显时效性。 表6 各模型及方法识别时间 4.2.3 自采集数据集识别分析 为了进一步验证所提方法的工程实用性,采用现场采集的方法对200人表情特征进行黑暗环境、弱光环境和强光环境下的图像采集与特征提取。如表7所示,所提方法因经过分布式学习和正则化学习的综合训练,对于黑暗环境、弱光环境和强光环境的识别准确率可以分别达到89.23%、90.23%和91.33%。而对比模型因训练网络结构简单以及缺乏综合训练学习,其判断效率和精度在各种场景下较所提方法存在一定差距。 表7 自采集图像数据集识别平均准确率 如前文所述,所提算法为简化计算步骤,提高计算效率采用MBGD方法实现算法网络模型的优化,从而提高识别效率。对于自采集人脸表情识别时间见表8,所提方法可在278.12 s对被测数据集完全实现识别,较文献[13]、文献[14]、文献[15]、文献[16]和文献[17]方法提高20.31 s、24.7 s、18.34 s、11.44 s和12.09 s。 表8 各模型及方法识别时间 为进一步验证所提方法的适用性,采用混淆矩阵对识别结果进行展示说明。如图8(f)所示,所提方法对于愤怒表情、厌恶表情、悲伤表情、开心表情、沮丧表情和惊讶表情的识别准确分别为82%、79%、83%、95%、82%和92%。同时因VGG-16网络训练结构的复杂性和两种学习规则的综合,可实现对于各种表情之间的明显区分。以开心表情为例,所提模型对其识别正确率可高至95%,对于厌恶和悲伤表情的识别区别错误率为4%和1%,并且对于其表情可实现完全区分;而对比模型并没有充分考虑各表情之间的关联关系,致使对于识别表情的区分性问题上存在缺陷,如文献[13]中厌恶表情和愤怒表情识别错误率为19%,已将厌恶表情误识别为愤怒。 图8 不同方法下混淆矩阵 本文所提的卷积网络模型输出目标主要包括两部分,即KL损失和L2损失。KL损失和L2损失参数对卷积网络模型的表情识别准确度十分重要,其中参数λ在这两个部分之间交换,参数σ控制相邻表情的关联度,均对识别精度有很大影响。如参数σ,若σ数值太小,单标签真实值与其它相邻表情之间的相关性变得很小,该方法类似于进行单标签分类任务;若σ太大,则其它相邻表情之间的相关性差别很小。 为了分析不同超参数λ和σ在CELDL 模型中的敏感度,以实现模型参数最优化,在VGG-16网络模型框架下对CELDL表情识别任务进行了实验验证。 在自采集数据集对模型参数优适值进行分析,如图9所示。在第一个实验(a)中,根据多次实验的设置,λ被固定为0.001,并在[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]中改变σ来学习不同的模型。可以观察到,CELDL模型的准确率一般都是先提高,在0.7时达到最大值,然后下降。结果表明,当σ设为0.7时,网络模型对参数选择没有影响,表情之间的相关性可以很好地表示出来。 图9 模型参数灵敏度分析 实验(b)将σ数值固定为0.7,在集合[0,0.0001,0.0005,0.001,0.005,0.01,0.05,0.1]中改变λ进行对比实验。结果表明,识别性能对参数λ的取值非常敏感,λ=0.001是依据KL损失和L2损失作为综合结果判定的情况,保障了深度学习特征的优秀识别性能。 面向多场景下多表情识别的准确性和快速性需求,本文提出一种基于高斯特征提取和VGG-16神经网络的红外人脸表情识别方法,其主要分为3部分:①基于极大似数据模型和高斯混合模型对采集图像进行处理,为后续深度神经网络学习训练提供良好的图像训练数据样本支撑;②采用相关情感标签分布学习和正则化学习对VGG-16神经网络进行改进,对各表情情绪针对分析,保障多环境场景下采集图像表情的精准识别;③基于MBGD方法有效简化网络模型的目标函数,提高识别方法的识别速度,具有工程应用实际意义。通过对3种数据集的实验仿真分析,可以得到所提方法较CNN模型、MTCNN模型和DBN模型具有人脸表情识别准确和快速的优势,其中对于自采集数据集的图像识别在黑暗、弱光和强光环境下识别正确率可达到90.31%、92.34%和91.51%,具有一定的工程适用性。 未来研究重点将探讨所提方法的平台化,努力实现所提方法的商用化。
3 学习与识别
3.1 VGG网络结构


3.2 高斯标签的分布构造

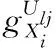


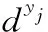
3.3 情绪标签的分布学习
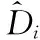
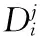
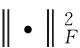
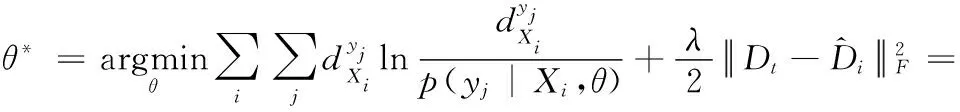
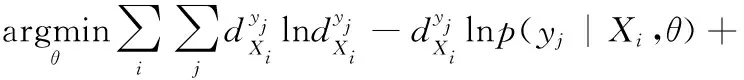


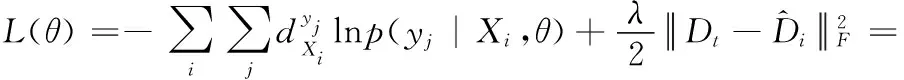
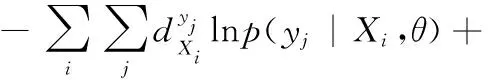


3.4 优 化
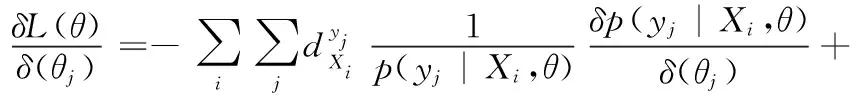

4 算例验证与结果讨论
4.1 实验数据集

4.2 人脸识别实验验证







4.3 模型参数敏感度分析

5 结束语
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
CHIP新电脑(2016年3期)2016-03-10
