
基于编解码器生成对抗网络的CT去噪
2022-04-21 07:23周广宇张鹏程刘生富桂志国
计算机工程与设计 2022年4期
周广宇,张鹏程,刘生富,刘 祎,桂志国
(中北大学 生物医学成像与影像大数据重点实验室,山西 太原 030051)
0 引 言
计算机断层扫描CT(computed tomography)是当今医学诊疗中最为重要的成像方式之一,在临床诊断中起到了极为重要的作用。然而CT扫描中使用的X射线辐射会对人体造成危害,为了减少这种危害,需要降低X射线的剂量,但通过降低X射线辐射剂量会导致图像信噪比下降,低剂量CT图像会出现严重的伪影与噪声,为了改善图像质量,低剂量CT图像去噪便成为医学成像领域内的重要研究方向。针对于低剂量的CT图像去噪主要有3个方向:投影域方法、图像域重建方法和后处理方法,本文针对后处理方法展开较为深入的研究。
随着深度学习的不断发展,已广泛运用到图像处理的领域中。使用卷积神经网络CNN(convolutional neural network)可以达到更好的处理效果以及更快的处理速度。Chen等[1]将CNN运用到CT图像去噪中,在此基础上,Chen等[2]使用含残差连接的编解码器神经网络(residual encoder decoder convolutional neural network)用于CT图像去噪,能够有效去除CT图像中的噪声伪影,但图像容易出现过度平滑的问题。生成对抗网络GAN(generative adversarial network)[3]提出后,Wolterink等[4]将GAN运用到CT图像去噪中,改善了CNN易使图像失真的缺点。但GAN也存在一些问题,例如在训练中损失函数难收敛、生成器与鉴别器的训练程度难以平衡、尺寸较小且结构混淆的噪声去除不到位等;Yang等[5]在GAN的基础上提出WGAN-VGG(generative adversarial network with Wasserstein distance and perceptual loss),该网络引入了Wasserstein距离[6]来平衡生成器与鉴别器的训练程度,并且使用VGG19模型[7]作为感知损失,对生成器网络参数有一定的优化功能,所得图像的质量明显优于GAN的结果,但是在训练中损失函数收敛较慢,且在有限的训练次数下无法获得质量好的去噪结果。同年,You等[8]采用多尺度损失函数提出SMGAN(structurally-sensitive multi-scale generative adversarial network),去噪结果可以在保留关键特征的同时有效去除噪声,更适用于临床诊断。Chi等[9]提出了基于U-Net的生成器及多级鉴别器的生成对抗网络用于CT去噪,能够更加有效去除噪声与伪影,但该网络结构复杂,训练耗费时间长,不易得出最好的训练结果。
本文提出的网络模型是基于文献[5]的改进,针对损失函数收敛慢的问题做出了改进,同时进一步提高了去噪的效果,对于CT图像中的微小组织有着更好的恢复效果。
1 方法介绍
1.1 去噪模型结构

x=ψ(y)+ζ
(1)
去噪的过程是已知x,通过去噪模型去预测一个接近于y的结果,即式(2),当得到的结果越接近y,那么去噪效果就越好
y=ψ-1(x)
(2)
由于LDCT的噪声具有复杂性,通过传统的去噪算法很难得到与NDCT非常相近的图像,而深度学习可以通过分层的多层框架从像素级数据中更高效学习图像特征,从而达到更好的去噪效果。
1.2 生成对抗网络与模型的改进
生成对抗网络(GAN)中包含两个网络,分别为生成器网络G(generator network)与鉴别器网络D(discriminator network),其原理是生成器与鉴别器不断博弈,进而使生成器学习到真实数据的分布。生成器G是一个生成式的网络,在网络输入端输入一个随机的噪声z,将噪声z输入到生成器中生成图片,生成的图片表示为G(z)。D是判别网络,可以判别输入图片是真实的还是由生成器生成的,当G(z)被输入到鉴别器中,鉴别器将会输出D[G(z)],它表示图片为真实的概率,当经过反复的训练,鉴别器D难以区分生成图像与真实图像时,则验证生成器G的能力达到最优。生成对抗网络在近年来被众多学者用于低剂量的CT图像去噪,其优势在于鉴别器可以对生成图像进行鉴别,从而能够进行反复的学习,不断调整网络参数,最终使去噪结果更加锐利与清晰,改善了CNN在去噪中易使图像过度平滑的问题。但生成对抗网络中损失函数收敛慢,超参数难调整的问题依然存在。
为了克服上述问题,本文提出了基于编解码器与多尺度损失函数的生成对抗网络,网络模型如图1所示。在生成器网络部分摒弃了WGAN-VGG中的单一卷积神经网络,采用了含残差连接的编解码器结构,这一结构有利于缓解梯度消失与梯度爆炸,避免网络退化等问题,能够有效增强生成器G的去噪能力,加快生成对抗网络的损失函数收敛。此外,为了使从输入端到输出端去除的噪声与真实的噪声尽可能相似,本文引入了噪声损失函数,将这两部分噪声的均方误差作为噪声损失函数,通过反向传播来优化生成器网络中的参数,对图像细节的保留起到了一定作用,使去噪后的结果更加接近NDCT。通过这两部分的改进,有效改善了生成对抗网络损失函数收敛速度慢的问题,对图像细节部分的恢复也更加清晰。
1.3 生成器网络(generator network)
在WGAN-VGG网络中[5],生成器网络含有8层卷积层,每层的卷积核均为32个,网络比较简单且所含参数较少,容易导致提取特征不充分,生成器输出图像质量差的问题。本文使用的生成器网络借鉴[10]的编解码器结构,以卷积层与反卷积层构成的编解码器组成,且使用了残差连接[11],将卷积层与反卷积层相连,能够使生成器网络更加有效且快速的提取特征,加快生成器损失函数的收敛。
第一,革兰阴性菌或厌氧菌所致的盆腔炎,选用喹诺酮类广谱抗生素,联合抗厌氧菌制剂,其中喹诺酮类是治疗妇科炎症的常用药。
在训练过程中,当网络更加深入时容易出现梯度消失或梯度爆炸的问题,网络性能将会减弱,变得难以训练。针对上述问题,生成器网络中引入了残差连接,如图2所示,在我们的网络中并不是直接学习从输入x到输出y的映射,而是拟合残差,利用F(x)=y-x表示输出与输入的残差,那么可以用R(x)=y=F(x)+x表示输出,即可将直接映射转化为残差映射。残差映射的优点首先在于优化残差映射比直接映射更加容易,可以有效避免在训练中当网络加深时导致的梯度消失;其次,由于卷积层与反卷积层仅处理残差,所以在反卷积层的输出可以保留更多的结构与对比度细节,可以显著提高图像的视觉效果。
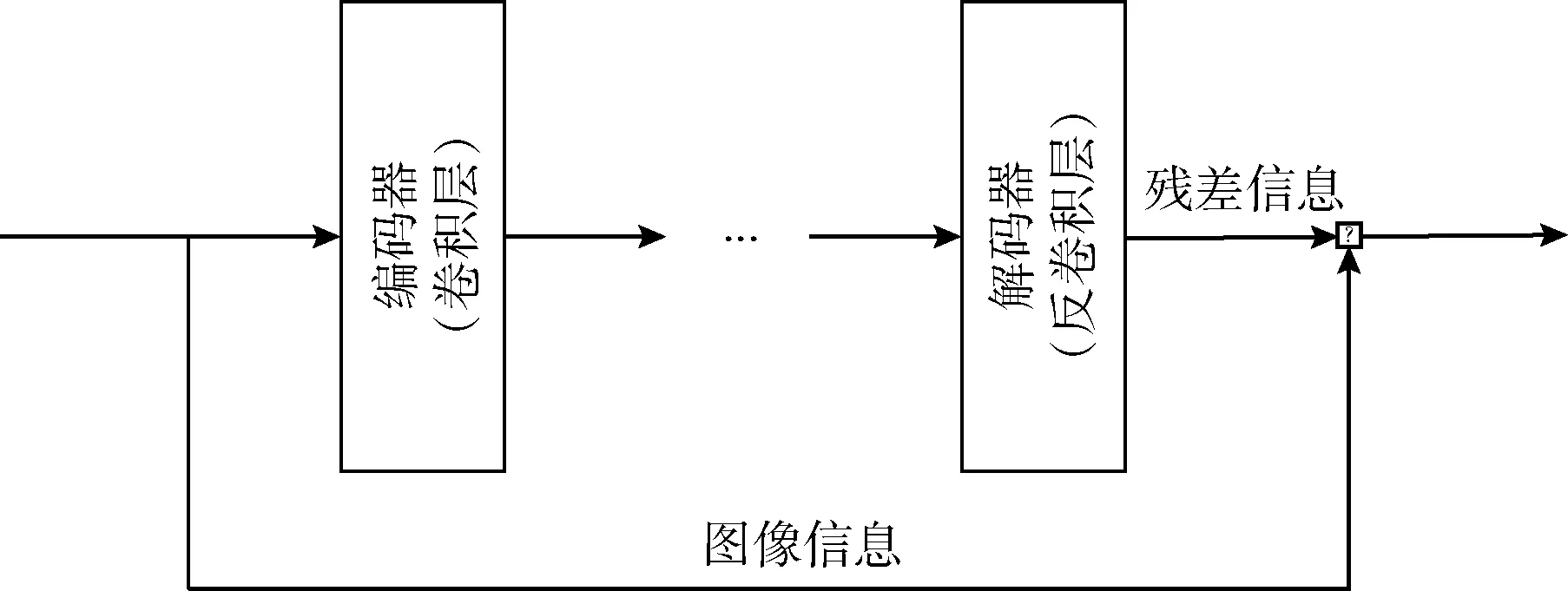
图2 残差连接的工作方式
本文的生成器网络中共有5层卷积层与5层反卷积层,分别一一对称,前5层构成了网络的编码器部分,后5层构成了网络的解码器部分。卷积层充当特征提取器,在保留图像中的主要成分同时消除噪声,反卷积层用于恢复图像细节,避免图像失真。在RED-CNN网络中[2],每个卷积层与反卷积层的卷积核个数均相同,可能出现特征提取不足的问题,在本文中对此做出了改进,生成器网络如图3所示,每一层卷积层的卷积核个数分别为96、96、192、192、384,每一层反卷积层的卷积核个数与卷积层对应,分别为384、192、192、96、96,图3中“n96 s1”的n为该层卷积核个数,s为卷积的步长,所以“n96 s1”即代表该卷积层含有96个步长为1的卷积核,同样,“n192 s1”与“n384 s1”代表该卷积层含有192个与384个步长为1的卷积核。使用En(ei)表示编码器,使用De(di)表示解码器。则可以表示为式(3)、式(4)

图3 生成器网络
En(ei)=ReLU(Wi*ei+bi)i=1,2,…,k
(3)
De(di)=ReLU(W′i⊗di+b′i)i=1,2,…,k
(4)
在式(3)中,i代表卷积层数,Wi与bi分别代表权重与偏置项,*代表卷积算子,ei代表从前一层卷积层提取的特征。在式(4)中,⊗代表反卷积算子,di代表从前一层反卷积层得到的特征向量。由于池化层可能会使图像丢失重要的细节,且该网络层数较少,复杂度不高,所以在该网络中舍弃了上采样与下采样的操作,仅在每层卷积层与反卷积层后采用ReLU线性校正单元进行校正。
1.4 鉴别器网络(discriminator network)
鉴别器网络结构如图4所示,包含6层卷积层以及2层全连接层。其中的6层卷积层分别含有64、64、128、128、256、256个卷积核,卷积核的大小均为3*3,在卷积层后有两层全连接层用于对之前的卷积层的特征做加权和,其中第一个全连接层有1024个输出,第二个全连接层只有一个输出。在鉴别器网络中,每层卷积层后都添加了LeakyReLU校正函数,LeakyReLU函数是广泛使用的ReLU激活函数的变体,该函数在负区域有着很小的正斜率,对于负的输入值也能够进行基于梯度的学习以及反向传播,解决了ReLU函数进入负区间后,导致神经元参数不更新,无法学习的问题。

图4 鉴别器网络
1.5 用于降噪的损失函数(loss functions for denoising)
生成对抗网络中有两个主要的损失函数,分别为生成器损失函数(generator loss)与鉴别器损失函数(discriminator loss),通过Wasserstein距离来衡量两个损失函数的距离,使两个损失函数接近全局最优点,将得到对抗损失函数,公式如下
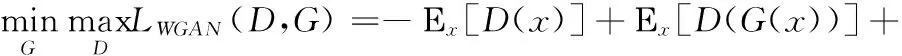
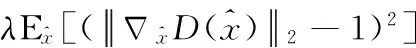
(5)

(1)感知损失函数
该部分由预先训练好的VGG19模型构成,将从生成器生成的图像G(x)与NDCT图像一同输入到VGG19网络中进行特征提取,根据式(6)来计算感知损失,随后根据损失函数的值反向传播来更新网络的权重
(6)
式中:w、h、d分别代表特征空间的宽度、高度以及深度,由于VGG19网络的输入为彩色图像,而我们输入的CT图像是灰度图像,所以将图像输入VGG19网络之前,将单通道复制3次成为三通道图像,即可完成输入。
(2)噪声损失函数
在噪声损失函数中,我们将计算两部分的差,分别为NDCT与LDCT的差以及通过生成器生成的图像G(x)与LDCT之间的差,随后对两部分的差求均方误差,使用LN表示噪声损失函数,如式(7)所示
(7)
式中:N为每张图像中的像素总数,xn为第n张LDCT,yn为第n张NDCT。NDCT与LDCT的差为真实的噪声,G(x)与LDCT的差为对LDCT进行一次去噪后去除的噪声,计算这两部分噪声的均方误差,再反向传播回生成器网络G中,使生成器过滤的噪声与真实的噪声更加接近,更好优化生成器的去噪能力。
综上所述,可以得到整体的多尺度损失函数,如式(8)所示,其中λ1与λ2表示不同损失的权重,以便于平衡训练,加快损失函数的收敛
(8)
2 实 验
2.1 实验数据
本实验使用开源的真实临床数据库,由Mayo Clinic授权的“the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge”公开数据集。数据集均为3 ms的全剂量CT图像与1/4剂量CT图像,高剂量CT图像与低剂量CT图像分别一一对应,图像大小均为512*512。本实验从中随机选取LDCT与NDCT相对应的图像1364组作为训练集,35组为测试集。
2.2 实验环境
本实验使用开源框架PyTorch,所使用的计算机中央处理器(CPU)型号为Intel®CoreTMi9-10900K,内存大小为64 GB,显卡型号为NVIDIA GeForce®RTX3090,显存为24 GB。
2.3 网络的训练
在本实验中,我们将每张训练图像随机裁成了10块64*64大小的贴片,随机裁剪将会数据库得到扩充,不仅可以提高模型的精度,也可以增强模型的稳定性,同时减少了参数数量,加快了训练的速度。经过多次超参数调整与训练,最后确定的参数见表1,经过16个小时的训练,得到了最终的模型。

表1 网络中各项参数的值
本实验使用峰值信噪比PSNR(power signal-to-noise ratio)和结构相似性指数度量SSIM(structural similarity index measure)这两个指标来定量评估图像质量。PSNR代表经过处理后的CT图像质量,单位为dB,它的值越大代表处理后的图像质量越高。SSIM是在[0,1]区间的数,本实验中去噪结果的SSIM值越高,则与NDCT越接近,去噪效果越好。
3 结果分析
本文同时复现了较为知名的去噪网络模型RED-CNN、WGAN-VGG以及经典去噪算法BM3D的改进型算法[12],通过对比实验来验证本文去噪的效果。以下列出了两组对比结果,均为测试集中的图像。
图5(a)为LDCT图像,图5(b)为NDCT图像,图5(c)为经典算法BM3D的去噪结果,图5(d)为RED-CNN去噪结果,图5(e)为WGAN-VGG去噪结果,图5(f)为本文实验的去噪结果。图6为图5(a)方框中感兴趣区域部分的放大图。从视觉效果看,图6(d)RED-CNN网络对噪声的抑制效果很强,但会造成过度平滑的效果,框选区域内的细小组织相较于本文的结果较模糊;图6(c)BM3D算法对噪声有一定抑制效果,但在处理较为复杂的低剂量CT图像上存在一定的劣势,例如框选区域内的微小细节就无法恢复出其原有的形状;图6(e)WGAN-VGG网络在处理微小细节上好于前两种算法,但通过框选区域的对比,本文网络对微小细节的处理显然好于WGAN-VGG网络。
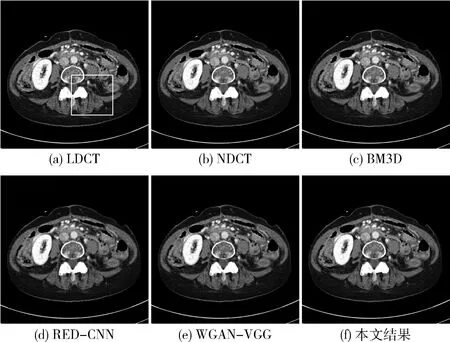
图5 第一组测试图的各算法对比
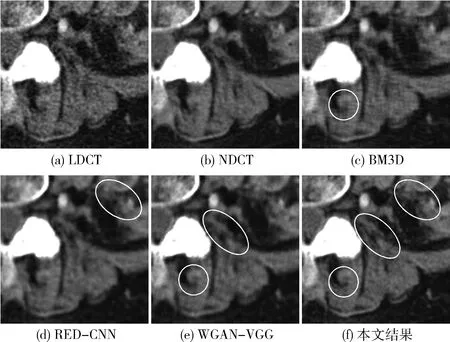
图6 图5(a)方框中感兴趣区域的局部放大
图7为第二组对比结果,图7(a)为LDCT图像,图7(b)为NDCT图像,图7(c)为经典算法BM3D的去噪结果,图7(d)为RED-CNN去噪结果,图7(e)为WGAN-VGG去噪结果,图7(f)为本文实验的去噪结果。图8为图7(a)方框中感兴趣区域部分的放大图。通过观察可得,在处理较亮且组织较多的低剂量CT图像时,图8(c)BM3D算法会产生块状伪影,且难以将复杂的组织恢复,在框选区域可以明显看出与NDCT的差别;图8(d)RED-CNN网络的问题依然是过度平滑,易将细微的组织当做噪声处理,在框选区域的处理有明显的误差;图8(e)WGAN-VGG网络在圆形框选区域恢复形状与NDCT不符,且在椭圆框选区域非常模糊,存在着平行伪影。由此可看出本文网络模型的去噪结果在整体图像质量与细节的恢复上有着明显的优势。

图7 第二组测试图的各算法对比
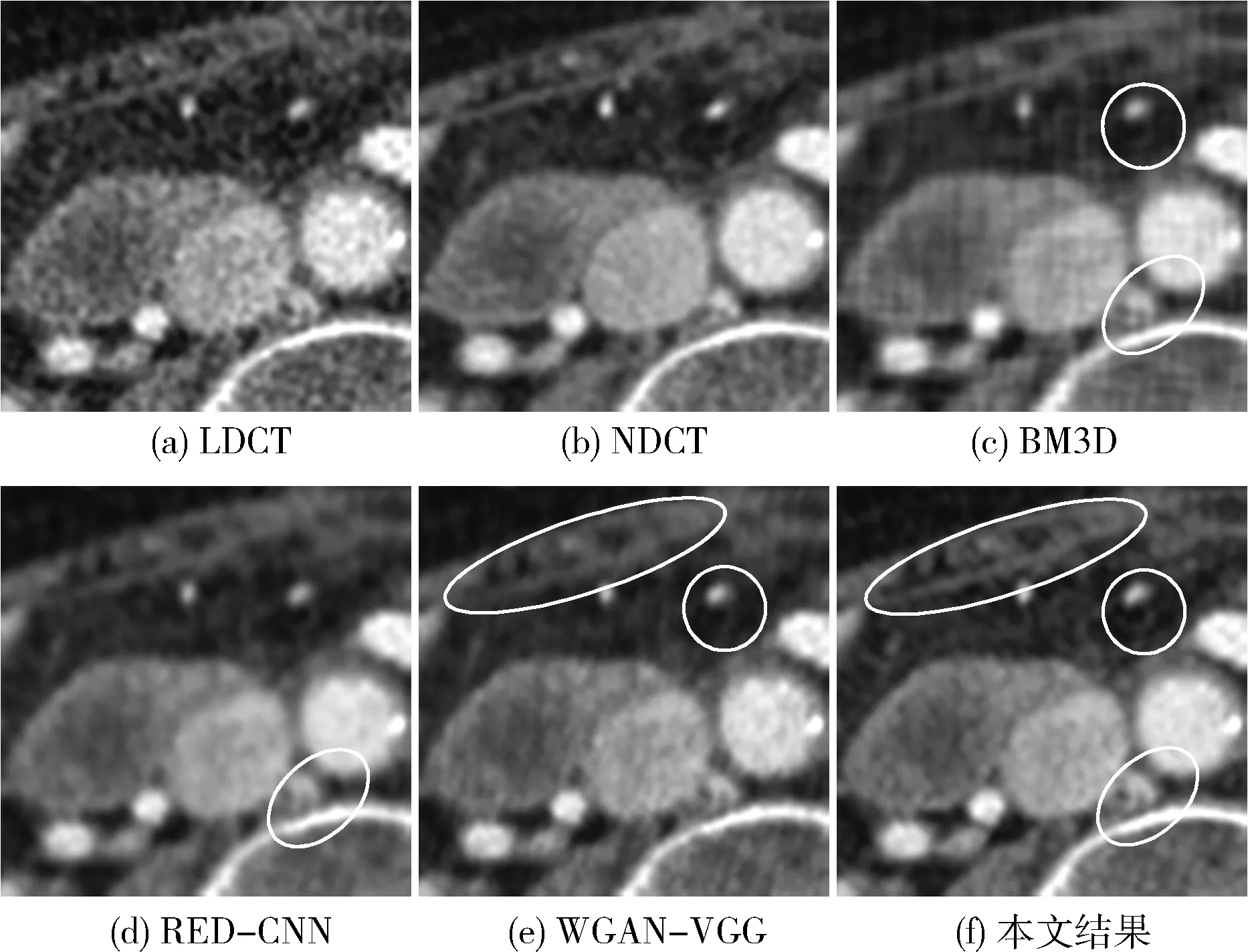
图8 图7(a)方框中感兴趣区域的局部放大
表2与表3分别为图5与图7的各项图像评估指标,通过对比可以发现,本文去噪网络结果的PSNR值均高于另外3种算法的结果,SSIM值也仅次于RED-CNN去噪网络,其原因是RED-CNN去噪网络的效果对于噪声的抑制有着非常明显的效果,可以从图中看出RED-CNN对于条形伪影的去除效果较明显,所以其SSIM值更高。然而根据图5及图7的对比,可以很明显看到RED-CNN去噪网络会使图像过度平滑,无法清晰的展现出与NDCT一样清晰的纹理,而本文的去噪网络不仅可以达到较好的去噪效果,且能较为清晰的复原出NDCT的一些细节,在视觉上的去噪效果明显好于其它几种方法,这对于实际中病理分析是更有意义的。
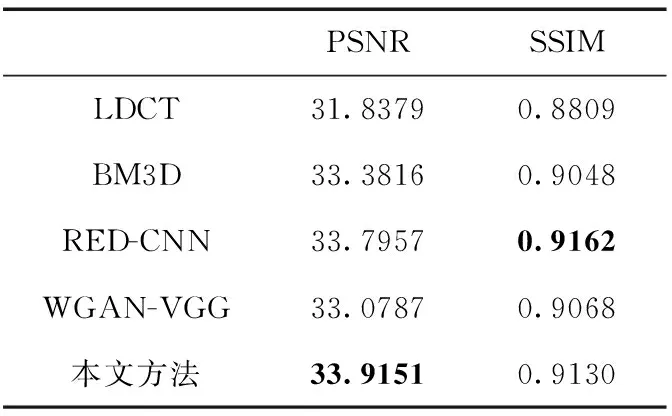
表2 图5各算法PSNR与SSIM值对比

表3 图7各算法PSNR与SSIM值对比
与WGAN-VGG网络模型相比,本文的去噪模型所得结果在PSNR与SSIM两项指标上均有着明显的提升。通过图像细节的对比,本文方法明显改善了对图像细节的恢复,在细小的部分更加锐利,更加接近NDCT图像,有效提高了网络模型的去噪性能。
BM3D为传统去噪算法中去噪能力最优秀的算法之一,其去噪结果的各项指标也很优秀,然而其去噪结果对于图像细节的处理较差,存在的块状伪影会影响图像的视觉效果,整体图像质量比深度学习的算法要略差一些,这也能够体现深度学习算法的优势。
图9为WGAN-VGG与本文网络训练结果随着Epoch增加PSNR的对比折线图。从图9中可以看出,WGAN-VGG网络去噪结果的PSNR值并没有随着训练的深入而趋于稳定,而本文网络随着训练次数增加,所得结果PSNR值也在稳步增加,并且在训练后期逐渐稳定。可以说明本文网络在训练中很稳定,并没有出现训练崩溃的问题,并且有效提高了去噪结果的图像质量。
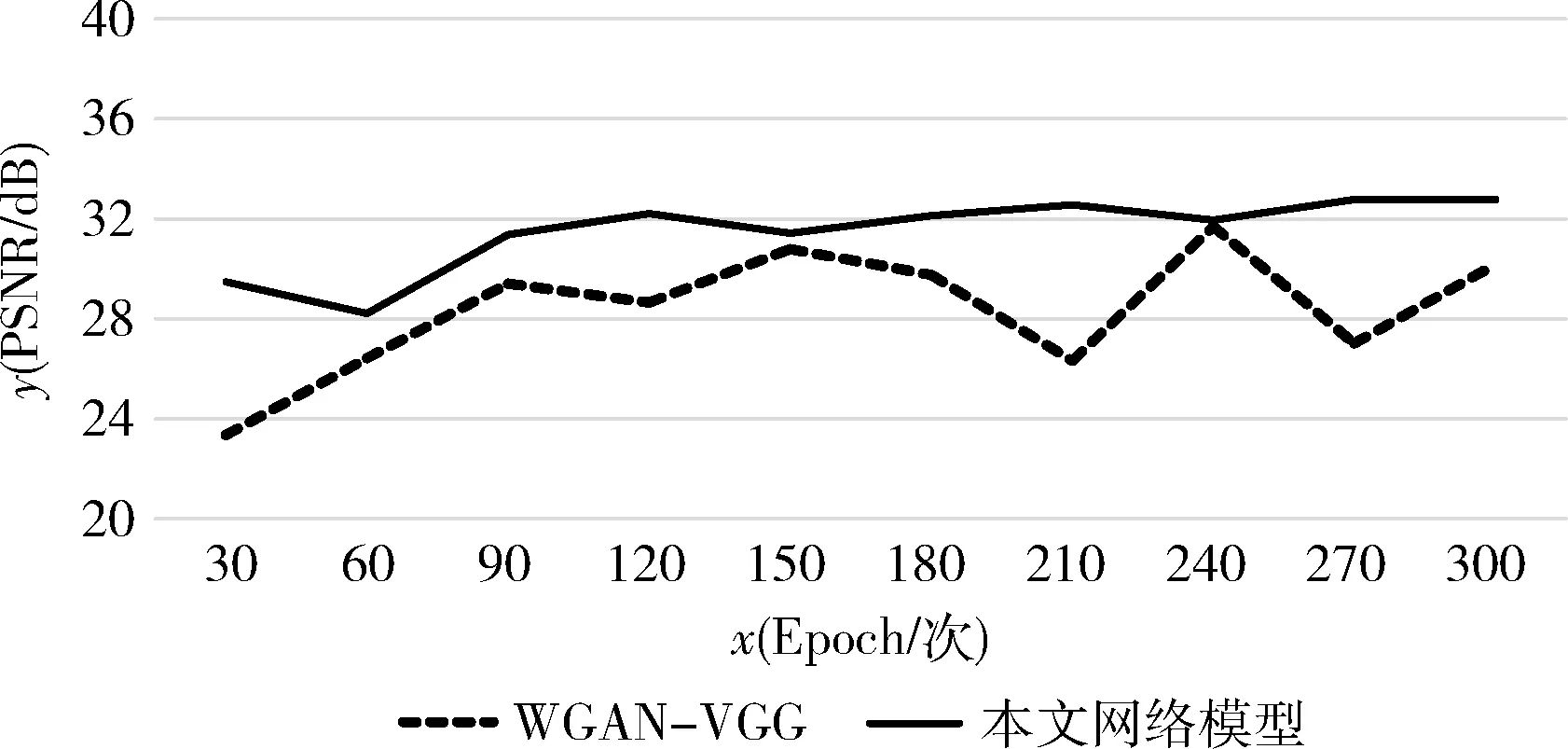
图9 WGAN-VGG与本文网络的PSNR值变化曲线
图10与图11分别为WGAN-VGG网络与本文网络的生成器损失函数(generator loss)与鉴别器损失函数(discriminator loss)随着训练次数增加的变化趋势。从图10可看出,在训练初始阶段,本文网络的生成器损失函数值就已经很小,且随着训练深入,其值迅速收敛,趋近于0。而WGAN-VGG网络的生成器损失函数值在结束300次Epoch之后仍未收敛。这是由于本文去噪网络的生成器采用了编解码器的构造且使用了残差连接,增加了生成器网络的复杂性,可以有效提高生成器输出的图像质量,从而降低生成器损失函数的值,使其迅速收敛。从图11可看出两个网络的鉴别器损失函数值都在下降,但本文网络收敛较快且损失函数值略低于WGAN-VGG。这也是得益于本文网络生成器输出的图像质量高的缘故。

图10 WGAN-VGG与本文网络生成器损失函数值变化曲线

图11 WGAN-VGG与本文网络鉴别器损失函数值变化曲线
由此可得,本文对WGAN-VGG的改进能够有效降低损失函数值并使损失函数值迅速收敛,改善了其训练困难的问题。
4 结束语
本文主要针对生成对抗网络训练困难、损失函数收敛慢、去噪结果细节恢复较差的问题提出了改进型生成对抗网络,使用了含残差连接的编解码器网络作为生成器网络,可以在提高生成图像质量的同时降低生成对抗网络训练的难度,有利于损失函数的收敛。此外,引入了噪声损失,与感知损失函数共同构成多尺度损失函数,通过反向传播来优化生成器网络中的参数,使去噪结果更加接近NDCT图像,以达到更好的去噪效果。从图像对比中可得,与输入的低剂量CT图像相比,去噪后图像的PSNR值提升了8.1%,SSIM值提升了4.8%;与WGAN-VGG网络模型的去噪结果相比,本文网络模型去噪结果的PSNR值提升了3.4%,SSIM值提升了1.0%;从PSNR随训练深入的变化趋势与损失函数随训练深入的收敛情况对比可得,本文网络模型损失函数的收敛速度更快,在有限次的训练中,所得去噪结果趋于稳定。综上所述,本文的算法是可行有效的。
与此同时,本文算法也存在着一些不足之处,由于网络结构复杂、参数较多,在GPU上运行时对显存要求较高,在配置较低的计算机上难以实现该算法,且由于该算法复杂度高,在训练中所耗费的时间较长。在未来的工作中,将针对网络复杂度高、训练时间长等问题做出改进,可通过添加已训练好的模型来加快网络训练速度,同时,也将继续针对图像质量进行改善。
猜你喜欢
北京工业大学学报(2022年9期)2022-09-15
激光与红外(2022年4期)2022-06-09
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
