
基于改进Faster RCNN的小尺度铁路侵限算法
2022-04-21 07:23余志强
计算机工程与设计 2022年4期
余志强,张 明
(石家庄铁道大学 电气与电子工程学院,河北 石家庄 050000)
0 引 言
由行人、动物、车辆等异物侵入铁道沿线极大的威胁了列车的安全运行,因此为避免异物侵限所造成的安全隐患,利用机器视觉[1]的异物检测方法有着安装维护便捷等优点,但是往往受外界的干扰较大,导致检测结果出现偏差。
目前在异物目标检测方面的研究大多是采用特征提取结合机器学习的方法。覃剑等[2]采用在线高斯模型对目标候选框快速生成。陈丽枫等[3]采用HOG特征和机器学习对行人进行检测。
上述研究都是基于人工手动提取特征来实现对目标的检测,而且特征的适应性较差,在调节过程的时候费时费力、泛化性较差。
近年来,随着深度学习的快速发展,以及其自动提取特征来进行训练学习,其高度的智能化成为目标检测最优的选择。邹逸群等[4]提出一种基于anchor-free损失函数的行人检测算法,解决行人平移问题和缓解行人尺度变化问题。李佐龙等[5]提出利用多尺度特征融合来提高对行人检测的精确度。付云霞[6]提出基于YOLO算法的行人检测。徐喆等[7]提出基于候选区域和并行卷积神经网络的行人检测。邵丽萍等[8]提出利用Faster RCNN对行人及车辆进行检测。
然而,对于传统的Faster RCNN网络模型存在对于小物体目标漏检等问题,因此本文提出了一种改进的Faster RCNN铁路异物检测方法来提高小尺度识别的精确度。由于传统算法设置的锚点框尺寸以及数量比例较少,不能很好覆盖图像的缺陷信息。因此本文通过调整锚点框数量来提高对于小尺度目标检测的精确度,同时根据FPN[9]的思想,使主干提取网络的深浅层特征相融合;并对NMS算法进行改进,提出一种基于衰减得分的NMS算法,在训练中使用在线难例挖掘方案对模型进行训练;引入迁移学习[10]的思想,降低了在训练网络时所需的大量数据信息的需求。
1 Faster RCNN算法
1.1 Faster RCNN原理
原始图像首先经过Reshape得到主干特征提取网络所需要的输入尺寸,然后进入主干特征提取网络(Backbone)进行特征提取,本文选取的Backbone为VGG16模型。结构如图1所示。

图1 VGG16结构
随后由主干网络提取的特征图作为共享特征图分别送到RPN层和RoI Pooling层[11],其中一部分共享特征图经过RPN层得到多个建议框,之后将建议框映射到另一部分的特征图上共同输入RoI Pooling层进行Max Pooling操作,由于输出为全连接层,因此经过Max Pooling的输出为固定大小的尺寸。最后进行分类、回归,然后根据非极大值抑制(NMS)算法筛选Bounding box,找到最优的目标位置以及对应的分类概率。Faster RCNN原理流程如图2所示。
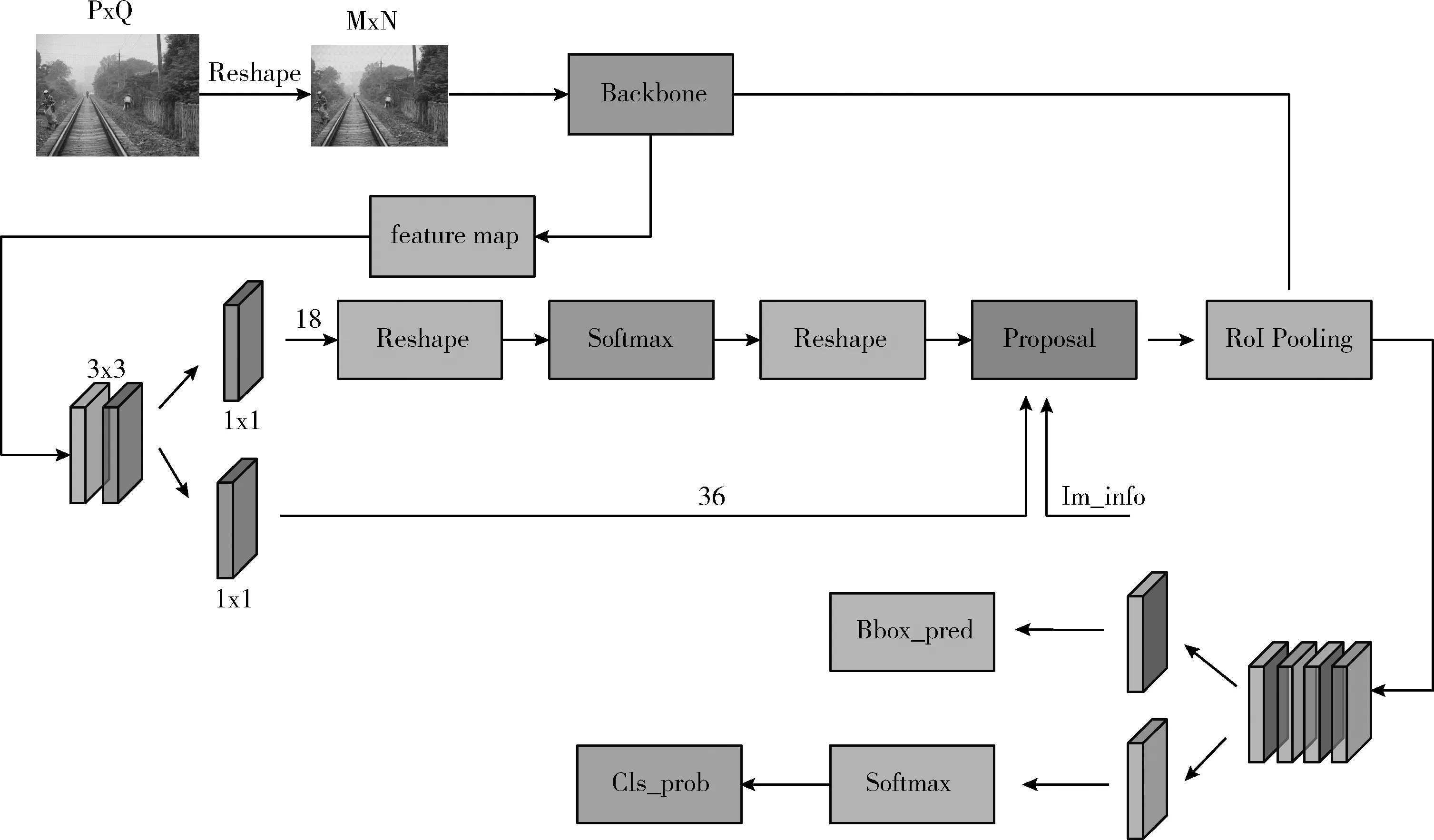
图2 Faster RCNN流程
1.2 RPN网络结构
RPN是一个基于全卷积的网络,可以通过卷积操作同时预测输入特征图的每个位置目标候选区域框的坐标信息以及目标得分。RPN的结构如图3所示。

图3 区域建议网络RPN结构
首先在主干网络提取的特征图上的每一个锚点(anchor point),生成具有不同尺度和宽高比的k个锚点框。然后采用滑动窗口机制,对每个位置的锚点都产生一个对应短的向量来输入到全连接层中进行位置和种类的判断。其中一个网络rpn_bbox_pred用来输出4个位置坐标,为(x,y,w,h), 其中(x,y)为建议框中心位置坐标,w,h分别为建议框的宽和高。
另一个网络rpn_cls_score用来做分类,判断该锚点框中的特征图是属于前景(foreground)还是背景(background)。对于每个锚点处有产生k个锚点框,因此,rpn_bbox_pred层产生4k个参数用来编码k个框的4个坐标。rpn_cls_score则产生2k个参数,用来预测每个特征区域所对应的目标是前景的概率还是所属背景的概率。
1.3 NMS算法
基于RPN网络得出每个默认框的得分(score),RPN网络会将所有得分超过阈值的锚点框全部保留,因此对于一个目标物体可能存在多个选择框,若要去掉多余的选择框则需要采用非极大值抑制算法(non-maximum suppression,NMS)。
对于检测出某一个物体的所有锚点框(bounding box)记为列表B,对应的置信度记为Si。首先选择检测框M的重叠区域面积比例(IOU)大于阈值Nt的检测框,将其从列表B中移除并加入到最终的检测结果D中。重复该过程,直到B为空集为止。其中阈值Nt一般选取0.3~0.5。具体如式(1)所示
(1)
2 基于改进的Faster RCNN铁路异物侵限算法
2.1 轨道区域划定算法
由于在拍摄时,图像所呈现的距离很远,范围很广。因此对于一些并不会对列车产生威胁的物体也被检测进取,会使得网络存在误检的情况,而且还会浪费检测时间,影响运算速率。
因此本文考虑在图像输入神经网络时先对待测图像进行预处理,根据轨道区域进行区域分割。这样就达到了只对潜在危险区域进行检测,间接的提高了整体网络的运算速度。
对于危险区域的划分本文根据铁轨的位置作为参考物,向左右延伸作为确定入侵的检测区域。轨道区域划分算法流程如图4所示。
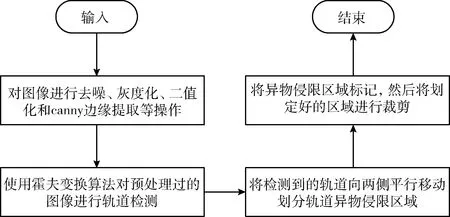
图4 轨道区域划分算法流程
在划定侵限区域最关键的就是找到铁轨沿线。因为铁轨检测的实质其实就是直线检测。因此本文采用霍夫变换算法(hough transform)来对轨道进行检测。
霍夫直线检测算法具有空间变换对偶性,因此每一个点都可以对应某一条直线。相当于在霍夫直线变换时,原像素空间设为x、y坐标系。因此对于任意像素(x0,y0)都可以用表达式y=kx+b来表示。那么对应的参数空间k、b坐标系中用一条对应直线来代表原像素空间中的直线,即:b=-kx0+y0。空间变换如图5所示。
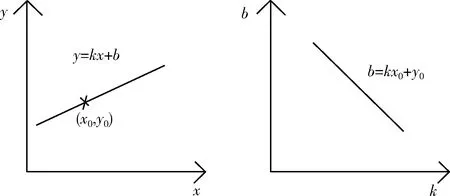
图5 从(x,y)空间转换为(k,b)空间
霍夫直线检测的检测过程如图5所示,对每个像素点均求过该点的N条直线的坐标参数(r,theta),采用投票的方式选出拥有最多相同的(r,theta)坐标。当坐标数量超过某一阈值时则确定出一条对应的直线。
若使用霍夫检测算法进行直线检测,则参数空间不能选择直角坐标系,因为在使用直角坐标系的时候,无法表达对于斜率为无穷大时的直线,即垂直直线。在这种情况时直角坐标系对于直线的表达就受到了限制。因此采用极坐标系。
本文使用OpenCV测试仿真如图6所示。

图6 轨道侵限区域划分
由仿真图可知,若要得到轨道侵限区域首先需要到铁轨的位置信息如图6所示中实线部分,通常将检测出的轨道位置向左右延伸一定距离得到易侵限区域。如图6中虚线线段表示区域所示,最后将该区域的图像进行裁剪,作为最终输入神经网络的输入图像。
2.2 深浅层特征融合算法
对于深层的特征图,往往会有更小的像素值,表达着更强的语义,若想与浅层的特征值相融合则需要将低层特征和高层特征通过横向连接和top-down网络进行融合,这样操作充分利用了卷积层计算出来的特征信息。横向连接就是利用1x1的卷积核进行卷积操作,该操作只会改变特征图的维度不会改变特征图像的尺寸大小。
自顶向下网络(top-down)就是一个上采样的过程,采用双线性插值算法来对其像素进行扩充。
将上采样的结果与尺寸相匹配的深层特征相融合,融合之后采用尺寸为3x3的卷积核对融合后的feature map进行卷积计算,该操作可以消除上采样造成的混叠效应(aliasing effect)。结构如图7所示。

图7 特征融合结构
2.3 调整锚点数量
在区域建议网络RPN中有两个层,一个是坐标回归层(rpn_bbox_pred)用于对边框进行回归;另一个是目标判断层(rpn_cls_score)用来对目标物体和背景进行分类判别。

2.4 采用迁移学习训练网络
针对铁路异物侵限数据集搜集困难,资料匮乏的问题,如果在训练过程中直接随机化初始权重,同时使用收集到的数据进行训练会导致权重更替缓慢,不利于网络模型的收敛。因此采用迁移学习的思想对网络模型进行预训练。
在预训练时使用Pascal VOC 2007数据集、INRIA Person Dataset数据集和KITTI数据集中的相似数据整合为训练集,对网络模型进行预训练,得到预权重。通过这种方式就有效的防止了数据量过少造成的过拟合的问题,同时加快了网络模型的收敛速度。
2.5 在线难例挖掘(OHEM)
首先通过主干神经网络提取出feature map,将feature map和所有RoI输入到RoI网络中进行前向传播,根据损失函数计算出损失值,并将其进行排序,取损失值(loss)最大的B/N(实际中一般N取2,B取128)个样本进行反向传播,因此在反向传播是只选择loss值较大的RoI用于更新模型,所以使得参数量大幅度减少,运算速度增加。在一张图像中,若每个RoI之间的交叠区域越大,那么两者的loss值也就越相似,由于在经过多层卷积之后得到的feature map,其分辨率不高,交叠区域较大的RoI投射到feature map上可能为同一个区域,会导致loss重复计算。为防止该问题的产生,本文采用非极大值抑制(NMS)对RoI进行去重复,过滤掉交叠区域较大的RoI。最后再令筛选之后的RoI进行反向传播。经实验验证,非极大值抑制的阈值选取0.7为最佳。
如图8所示,在Faster RCNN的RoI Pooling层之后设计两个具有同样架构的RoI网络,不同的是将其区分为只读层和可读-写层。对于只读层,只对所有RoI做前向运算,而可读-写层既要对可读层筛选出的难例RoI做前向运算也要进行反向传播。这一个整体作为一次迭代。
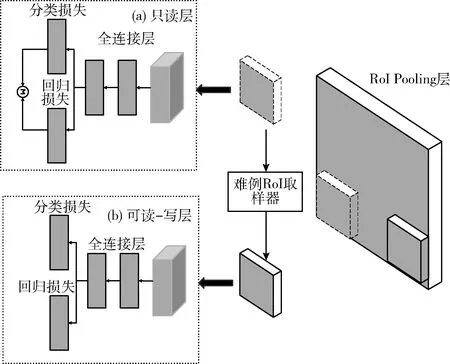
图8 在线难例挖掘原理
2.6 基于衰减得分的NMS算法
由于NMS的计算方法是当IOU大于阈值时直接把其置信度设置为0。如果将两个相近的预测框之间进行非极大值抑制时就会出现高得分的预测框直接将较低得分的预测框抑制的问题,这样就删除了原本正确分类的预测框。因此本文采用基于衰减得分的非极大值抑制算法,即在NMS的基础上用一个与IOU值成反比的函数来衰减得分,具体如式(2)所示
(2)
这样就避免了传统算法直接置为0,这样以来即便两个检测框的IOU值较大,得分也不会直接置为0,避免了漏检的现象。
2.7 基于改进的Faster RCNN铁路异物侵限算法框架
将原始图经过主干特征提取网络(Backbone)输出共享特征图。本文的主干提取网络采用的改进的VGG16网络模型。主要改进措施是将卷积层的高低特征层进行融合,用第二层卷积之后的特征图Conv2_1,其输出维度为512x38x38。第7层卷积后的Conv7_2将其经过双线性插值上采样得到特征维度为512x38x38的特征图,使两者相拼接得到Conv_merge,融合后的特征层(Conv_merge)作为输入区域建议网络(RPN)和感兴趣区域池化的输入图像,最后经过分类、回归输出检测的目标图像。异物侵限算法的模型整体结构如图9所示。
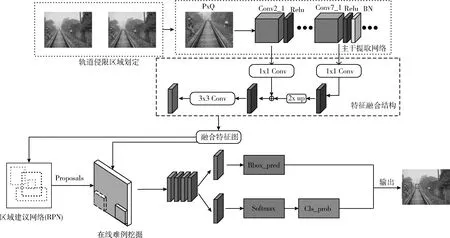
图9 基于改进Faster RCNN铁路异物侵限算法框架
3 实验设计及结果分析
3.1 实验平台环境
基于Faster RCNN铁路异物侵限算法的训练测试硬件环境见表1。
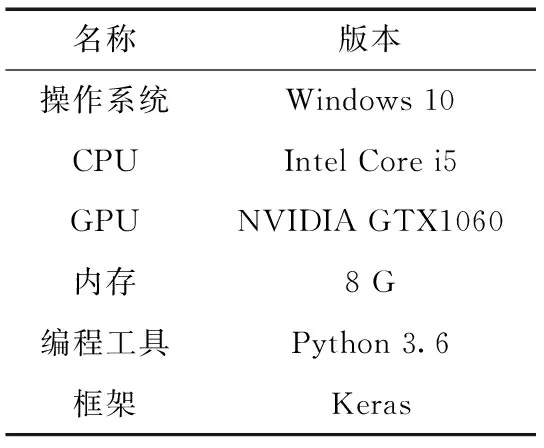
表1 网络模型训练及测试环境
3.2 网络训练
3.2.1 数据集制作
在进行网络模型训练时需要大量的数据集,然而针对铁路异物侵限的相关数据数量较少,因此若使用的数据量较少就有可能存在在训练网络有着较好的训练效果但是在测试集上泛化性较差的问题。
因此为了避免过拟合现象,文本使用迁移学习的方式对网络模型进行训练,即使用一些公开的数据集中与异物侵限内容相近的数据进行预训练,然后再使本文的数据集参与到训练之中。
本文使用的公开数据集主要包括VOC 2007数据集中的人像、车辆、动物的内容数据、INRIA Person Dataset数据集、KITTI数据集,以及使用labellmg工具安装VOC2007格式人工标注的铁路异物侵限数据集。
3.2.2 损失函数
Faster RCNN的损失函数主要是由RPN网络的损失函数和Fast RCNN的损失函数组成,并且两部分都包含分类损失(cls_loss)和回归损失(bbox regression loss),形式皆如式(3)所示
LFrcnn=LRPN({pi},{ti})+LFcnn({pi},{ti})
(3)
由RPN结构可知,RPN层分为两个网络,一个是判断RPN网格产生的候选框里面的目标是前景还是背景;另一部分则是对该候选框进行回归的回归任务。因此对应RPN网络的总体损失函数如式(4)所示
(4)
其中,Lcls为分类的损失函数,Ncls为mini-batch大小,Lreg为回归的损失函数,λ为回归损失函数的权重。

(5)
分类的loss函数使用的是交叉熵,如式(6)所示
(6)
对于Fast RCNN的分类损失因为所检测的目标大于2,故使用的是多分类交叉熵损失函数。而对于RPN只需分类出背景与前景因此使用的是二分类交叉熵损失函数。

(7)
其中,R为smoothL1函数
(8)
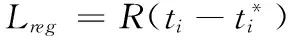
3.2.3 训练步骤
本文由于数据集匮乏的限制,因此采用了迁移学习的思想,首先基于参数迁移的思想,在GitHub上下载已经训练好的Faster RCNN模型。然后使用预训练之后的权重对RPN网络进行初始化,并使用均值为0,方差为0.01的高斯分布对新增的网络层进行随机初始化,最终完成RPN网络的初始化设置,同理根据参数迁移将Fast RCNN进行初始化。最后基于实例迁移的思想使用异物侵限数据集对RPN网络和Faster RCNN网络进行参数权重的细微调整,最后完成对于整个网络模型的训练。
在RPN网络和Fast RCNN网络训练时采用随机梯度下降(stochastic gradient descent,SGD),对网络进行50次迭代训练,计算公式如式(9)所示
(9)
其中,α为模型所设置的学习率,m为整体数据样本总量,hθ(x)为参数的函数,x(j)为第j组的x,y(j)为第j组的y。
其中每一批训练的数据包含60张训练样本,初始化学习率设置为0.01,在此之外还采取图像旋转,高度、宽度自由裁剪、增加对比度等数据增强的方式来对原始的数据集进行扩增,防止过拟合并且加快模型的收敛速度。具体操作见表2。

表2 数据集扩展方式
对于网络模型的评价指标,利用AP(average precision)对检测网络中的各类目标进行评价。其计算公式
(10)
其中,Ji为在所有类别中第i类物体的AP值,M为所有数据样本中正样本(positive)的数量,P为在不同正样本数量下对不同的召回率(recall)中最大精确率(precision)。
对于精确率以及召回率的公式如式(11)、式(12)所示
(11)
(12)
mAP则是对每一个类别都计算出AP,然后再计算AP平均值。
3.2.4 基于改进Faster RCNN检测效果
本文所提出的铁路异物侵限算法是基于Faster RCNN网络模型,对其主干特征提取网络选用VGG16,并对其进行深浅层特征融合,增加了对细小物体特征的学习能力。在RPN网络中改变了默认的锚点框尺寸,使之更好适应小物体目标的检测。
为验证本文模型的效果,从VOCdevkit数据集中选取包括行人、动物、车辆3种类别的数据总共2000张,铁路异物侵限数据集中数据1000张。总共3000张图像作为训练集对模型进行训练。此外总计1000张异物侵限图像作为测试集用来对模型的性能进行检测。如图10(a)、图10(b)所示,为50次迭代后模型的准确率和损失率。图10(c)为5种不同检测对象各自的准确率。验证了本文算法有着较高的准确率。
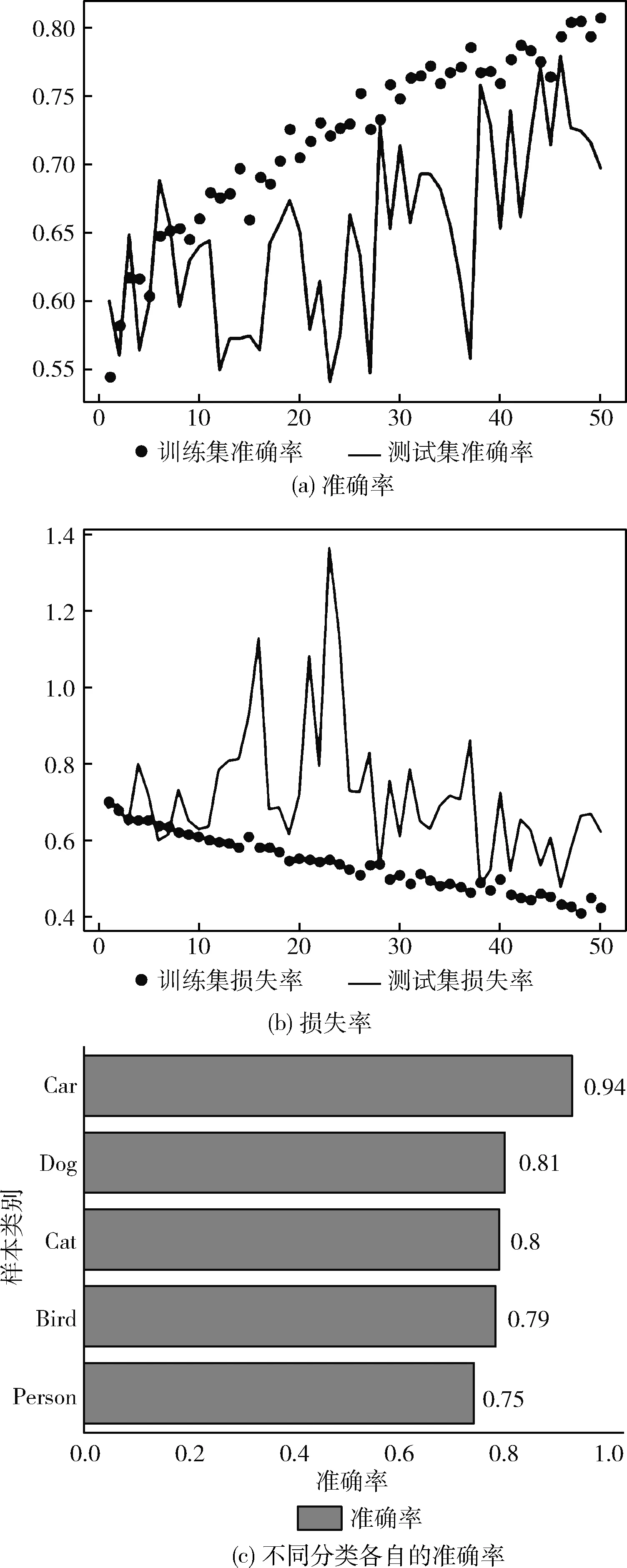
图10 实验数据分析结果
3.2.5 不同锚点框尺寸的检测效果比较
根据上述对于设置默认锚点框尺寸的分析可知不同尺寸的锚点框对于检测不同大小物体的精确度有所影响。考虑到文献[12]对于原始的Faster RCNN中使用的是人工预设定的锚点框尺寸(anchor scales)大小为 {128×128,256×256,512×512}, 但是该尺寸对于本文研究内容来说并不能很好覆盖数据集中较小尺度的目标物体。因此本文在原有改进的基础上进一步研究对比了不同尺寸的锚点框在铁路异物侵限数据集上的检测效果。文本一共选取3组不同尺寸的锚点框在同样的主干网络—VGG16下测试对于车辆、动物、行人的准确率以及整体网络的mAP值。其中,锚点框的尺寸分别为Anchor Scales A{128×128,256×256,512×512},Anchor Scales B{64×64,128×128,256×256},Anchor Scales C{32×32,64×64,128×128}。实验结果见表3。
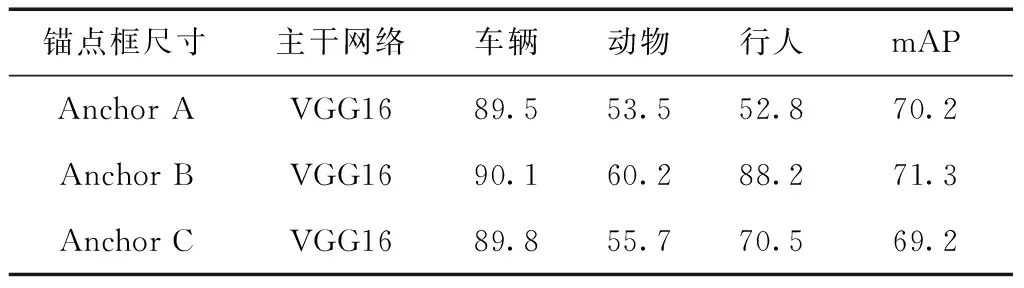
表3 不同尺寸锚点框的检测结果比较
表3可知,Anchor B的综合比分更高,因此通过将锚点框尺寸调整为 {64×64,128×128,256×256} 时,其尺寸分布更适应于特征图感受野同时能够更好地覆盖数据集中的大部分目标区域,包括小目标区域。如果继续将锚点框的尺寸缩小到Anchor C规格,虽然与原尺寸Anchor A相比提高了准确度,但是提高幅度并不大,因此对于本文的研究来说锚点框规格选取Anchor B最为适合。
同时通过Anchor A、Anchor B、Anchor C这3组不同规格的锚点框的对比也验证本文所提到的较小的预定义锚点框能有效提升小目标的检测结果。
3.2.6 本文算法性能改进对比
根据表4可知在4种改进方法中增加特征融合和改进锚点框的尺寸可以使整体网络的性能大幅增加。在保证都加入锚点框时,增加特征融合层,使mAP增加5.1%,验证特征融合能够有效地提取小目标特征,对于本文的检测有极大的提升。在对锚点框的尺寸进行调整之后mAP提升了5.6%,而在训练中利用在线难例挖掘进行训练以及基于衰减得分的NMS对mAP也有较大的提升。最后,将4种有效提升小目标检测效果的方法结合起来,mAP达到77.3,验证了本文算法的有效性。

表4 本文算法性能改进对比
3.2.7 本文算法与当前主流目标检测算法对比
将本文算法与当前主流目标检测算法进行对比,比较结果见表5。
由表5可知通过本文的改进,使Faster RCNN的mAP相比传统的Faster RCNN提高了2.1%,同时与目前主流的目标检测算法相比都有着较高的准确率,该结果验证了本文算法的可靠性。

表5 主流目标检测算法对比
最后,图11展示了本文算法对铁路异物侵限的预测效果图。

图11 预测效果
4 结束语
本文针对铁路异物侵限的小目标物体检测困难问题,提出了一种改进的Faster RCNN算法。
(1)本文采用深层特征与浅层特征相融合的方法,这样既可以保留高层特征的高语义的特点又能保证低层特征高分辨率的位置细节信息。经实验验证,该融合方法能够有效弥补小目标识别问题,从而提升对于小尺度物体的检测效果。
(2)通过分析铁路异物侵限数据集,将原预定的锚点框尺寸进一步精细化,缩小其尺寸,并设计3组不同的锚点框尺寸进行了对比实验,选取了最适合本文的Anchor Scales。
(3)基于衰减得分的NMS算法经实验验证相比NMS算法对mAP有着较好的表现。
(4)由于网络训练所需的训练数据较少,因此本文采用了基于参数和基于实例的迁移学习方式。实现了对本文模型的训练,实验结果也有着较高的准确度,具有现实应用的价值。
(5)训练采用在线难例挖掘的方案,加快网络的收敛速度,增加了网络模型对小物体检测的鲁棒性。
猜你喜欢
China’s foreign Trade(2021年6期)2021-12-26
中老年保健(2021年9期)2021-08-24
小雪花·成长指南(2021年6期)2021-08-18
通信电源技术(2021年2期)2021-05-21
电子技术与软件工程(2020年22期)2021-01-30
昆明医科大学学报(2020年12期)2021-01-26
数字技术与应用(2020年12期)2021-01-22
移动通信(2020年5期)2020-06-08
汽车与新动力(2017年3期)2017-06-29
中华奇石(2015年7期)2015-07-09
