
基于Q学习与贝叶斯博弈的物联网安全
2022-04-21 08:00刘天莺朱建明王秀利
计算机工程与设计 2022年4期
李 洋,刘天莺,朱建明,王秀利
(中央财经大学 信息学院,北京 100081)
0 引 言
在物联网(internet of things,IoT)迅速得到发展和应用的同时,其安全问题也逐渐成为了关注重点。如果物联网应用收集的数据泄露,可能造成严重后果;同时,由于物联网网络中存在许多异构网互相融合,结构复杂,安全防护难以实施。在工业控制领域,震网病毒(Stuxnet)曾经在世界各国的大型设施系统中产生了巨大危害。为了提高物联网的安全性,过去的研究者提出了许多的安全方案,例如轻量级加密技术、云计算安全技术等。但是,这些技术都是基于某种具体的安全难题提出解决方案,没有考虑到物联网整体安全状况的感知与评估。物联网安全是一个整体,其分析也应该具备综合性,需要全面分析物联网络面临的威胁程度及安全态势。此外,在实施安全方案时,物联网也与传统网络有所不同。许多设备受资源所限,只有密码验证这类简单的措施,而无法配置大型安全分析系统,否则可能影响系统的正常运行。因此,物联网安全方案需要在能源消耗小的同时,帮助安全防御者在复杂动态环境中做出最优决策,评估整体安全态势。
1 研究现状
博弈论是研究对策的数学理论,在安全博弈中,攻击方和防守方相互对抗,策略与收益相互依存,能够同时考虑攻防双方行动对于安全的影响,而不是仅仅关注攻击或防守某一方的行为,符合全面性、整体性要求,适合应用于物联网安全研究。He等[1]使用SCPN计算攻击路径,构建动态博弈模型对物联网智能环境进行态势感知,并通过典型攻击场景对模型进行了验证。Kaur等[2]结合随机Petri网和博弈论构建随机博弈网模型,使博弈方法适用于复杂的IoT网络,管理员节点能够在动态、可扩展环境下探测和阻止攻击,做出合理的行动计划。上述文献将博弈理论应用于物联网以及网络安全的分析,能够综合考虑攻防双方行为对于安全状态的影响,但是缺乏对博弈过程的具体分析,无法使用博弈矩阵做出安全决策。
在应用博弈矩阵进行攻击路径预测和最优防御策略选取方面,Huang等[3]结合演化博弈论和Markov决策过程,在多状态情况下求解Markov演化博弈均衡,考虑到了决策者的非完全理性情况。Lei等[4]构建了移动目标防御的Markov博弈模型,综合量化防御收益和防御成本,提出最优策略选择算法。Wang等[5]动态分析网络攻防过程,通过贝叶斯博弈结果确定最优纯策略,相比混合策略可操作性更强。这些文献可以应用于非完全理性、安全状态存在转移等多种情况,但是主要从预测具体攻击和防御行为出发,没有对整体安全态势的分析。
网络安全态势感知(network security situation awareness,NSSA)是一个对整体网络安全状态进行感知的研究领域和研究方法,它通过将有关于网络安全的各种信息融合,对安全态势做出分析和判断,为网络管理者和参与者的决策提供帮助。Endsley提出态势感知的概念[6],许多学者在之后也从不同角度、不同方面分别阐述了NSSA的定义和内涵,但大多都涉及到“安全”、“整体”与“辅助决策”等认知。对物联网的安全态势进行感知、分析与评价,能够把握整体网络安全状态,预测未来发展趋势,做出最有利于安全防御的决策。针对物联网安全及安全态势感知,Rapuzzi等[7]从雾计算角度构建态势感知方案,将安全分析从垂直框架转换为适合分布式计算的水平结构,能够应用于复杂的安全环境。Park等[8]提出了一种IoT设备风险评估框架,从信息泄露角度度量威胁和风险,通过感知环境与风险,预测未来安全形势,做出合理决策。Chouhan等[9]介绍了IoT应用的安全评估方法,在本地设备、数据传输和数据存储等物联网安全领域分别给出了增强安全保障能力的建议。上述文献分析了网络中存在的风险和威胁,从整个物联网网络的角度感知安全态势,但是没有考虑到物联网中恶意攻击者和防御者之间的相互影响。
本文将Q-Learning算法与静态贝叶斯博弈相结合,分析物联网安全状况,在多状态、不完全信息条件下进行物联网安全态势感知。通过最优防御策略求解,以及对整体网络安全态势的量化分析,更好地帮助管理者做出防御行动,预测安全状态趋势,具有实际意义和应用价值。
2 Q-Learning算法
在物联网安全攻防博弈过程中,随着攻击者进行攻击,防御者采取措施防御,存在多个状态之间的转移和跳变,需要同时考虑到现在和未来的收益,才能做出更加符合长远利益的防御决策,因此,可以将多状态的随机博弈理念引入攻防过程中。传统的随机博弈大多使用基于模型的Markov决策过程来进行描述,但其中存在着状态转移概率难以确定的问题。使用免模型的Q-Learning算法,不需要预先获取状态转移概率,而是通过探索与环境交互,自主获取未知的环境信息,应用范围更加广泛。针对这些特点,本文构建了结合Q-Learning算法的安全态势感知模型,在环境未知的情况下通过探索更新状态与行为信息。作为一种免模型的强化学习算法,它基于马尔科夫决策过程,通过学习动作-值函数,可以在独立于未来策略的情况下估计出最佳的动作-值函数q*。其任务是在有限状态和有限动作集条件下进行每一步的选择,实现主体可控制的马尔科夫过程。
2.1 马尔科夫决策过程
在马尔科夫决策过程中,用于选取最优决策的Bellman方程的状态-值函数需要满足关系
(1)
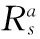
(2)
2.2 Q-Learning方法
在Q-Learning方法中,求解最优策略不需要了解和初始化状态转移概率。参与者与环境交互,在多个步骤的探索中不断更新Q值,最终达到选取最优策略的目的。一个步骤的Q-Learning可以定义为
Q(st,at)←Q(st,at)+

(3)
其中,Q(st,at)是当前的Q值,α表示对Q值计算差距的学习率,γ是一个衰减值,表示未来收益对现在影响的程度。在每一个步骤中,主体处于某个状态st,并可以根据st选择对应的at。每个状态-动作对(st,at)确定一个当前收益Rt+1,作为当前状态下做出某个选择的直接收益。同时,在整个状态空间中,当前状态到下一个状态的转移也由动作选择情况决定,不同的动作可能通往不同的下一步状态。
由于安全博弈是双方共同参与,在更新Q值的策略上,需要同时考虑到多个智能体的行为及其影响。针对攻击方采取行动at,防御方采取行动dt,一个步骤的更新可以定义为
Q(st,at,dt)←Q(st,at,dt)+

(4)
3 基于Q-Learning与贝叶斯博弈的物联网安全态势感知模型
3.1 物联网安全特点
物联网安全及其态势感知有许多与传统网络安全不同的特点。首先,物联网多采用无线网络的结构,没有中心节点来监测网络中传输的数据,因此需要分布式节点互相合作以保障安全,并且要考虑到众多节点中恶意节点存在的可能性;其次,由于物联网带宽有限,如果采取传统安全感知系统,其产生的大量信息流可能导致网络堵塞,影响网络系统的正常运行,为此应该尽可能减少安全感知所传输的数据流;同时,物联网设备的计算能力、存储资源都十分有限,安全感知和预测只能在资源受限的情况下进行,需要对传统安全模型进行优化。
传统的网络安全态势感知与风险评估对大量数据流进行分析,将之应用于物联网中,则会耗费过量电力能源与计算存储资源,难以长期进行态势监测,导致安全保障能力下降,缺乏对实时攻击的响应。此外,只从攻击方或防守方单方面出发,无法准确度量攻防双方互相影响的因素,也没有考虑到物联网中节点之间的相互联系。采用博弈论方法分析物联网安全,可以在一定程度上解决这些问题。
3.2 模型选取与定义
将博弈过程应用于网络安全分析可以采用静态博弈模型或动态博弈模型。在静态博弈中,博弈只有单一阶段,无法反映物联网安全中多状态之间的变化。在多个阶段的博弈中,也假设参与者的策略和收益固定,不会随着时间发生改变。这些模型无法适用于动态的物联网安全环境。在动态环境中,存在着多个状态,参与者在不同状态下采取不同策略,策略的影响也是长期的,因此运用Q-Lear-ning算法来度量存在状态转移的动态物联网环境下攻防参与者的收益。在Q-Learning中,随着一个步骤的Q值更新,主体需要完成以下任务:观察当前状态st,选择动作at,确定下一个状态st+1,得到当前收益Rt+1,并根据学习率α和衰减值γ重新计算Q,获得更新后的Q值。通过Q-Learning,环境中的主体不断进行探索和试错,获得策略当前和未来收益信息,考虑到多状态之间的转移和变化。
是否存在完全信息是构建博弈模型,获取最优策略所需的一个前提条件,许多安全博弈模型基于完全信息假设,即对于所有参与者,都假设其提前掌握了有关于博弈的全部信息,例如攻击方的攻击能力强弱、攻击成功率、攻击资源多少;防御方的防御能力、防御成功率、能够应用于防御的资源如节点的电量剩余等。但是,在物联网安全攻防过程中,攻防双方很难获取对方攻击和防御能力强弱的完整信息,只能有一个大概的判断,存在着信息不完全的情况。贝叶斯博弈描述了非完全信息条件下参与者之间的博弈过程,在静态贝叶斯博弈中,参与者同时行动,每个参与者可能有不同的类型,不同类型的参与者策略和收益也可以不同。与完全信息博弈相比,贝叶斯博弈将参与者从单一类型扩展到n个类型,更加符合现实中参与人能力不同的情况。
因此,定义物联网安全态势感知模型为一个九元组(N,Θ,P,M,S,U,W,π*,NS),其中:
(1)N=(NA,ND),是博弈参与者,NA为物联网中的攻击方(恶意节点),ND为物联网中的防御方(正常节点);

(3)P=(PA,PD),是攻击方和防御方在知道自己类型时对另一参与者类型的推断集合;
(4)M=(MA,MD)=(a1,…,am;d1,…,dn),是攻防双方的动作集合,参与者的类型不同,在该类型下的策略集合也可能不同,每个类型策略集合都是动作集合的一个子集;
(5)S=(s1,…,sk),是物联网安全状态空间,安全状态之间存在转移关系;
(6)U=(UA,UD),是参与人的收益空间,参与人得到的收益与状态、类型、采用策略和对方所选取的策略相关;
(7)W=(w,Aw,Dw),是不同节点的重要程度及其分布状况;

(9)NS=(NS1,…,NSk),是不同状态下安全态势值的集合。
为了简化模型,在博弈过程中,将物联网所有恶意节点共同视为一个攻击者,采取一系列的策略攻击网络;将物联网中所有正常节点共同视为一个防御者,采取一系列的防御策略维护网络安全。
3.3 最优防御策略选取
在不完全信息状态下,求解静态贝叶斯纳什均衡能够得到不同类型攻击者和防御者的最优策略。
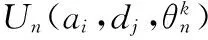
由于任意有限博弈都存在混合策略纳什均衡,模型中每个状态中攻击方和防御方都存在一个最佳混合策略,即混合策略贝叶斯纳什均衡[14]。
给定
((NA,ND),(ΘA,ΘD),(MA,MD),(PA,PD),(UA,UD))
(5)
攻防双方的混合策略为
(6)
其中,f表示策略选取的概率。
如果同时满足
(7)
和
(8)

3.4 物联网安全态势评估
物联网安全博弈是一个随着攻防双方行动和整体网络系统状态转移而不断变化的过程,其安全态势评估也需要考虑到恶意节点和正常节点分别采取的具体行动,以及网络当前和未来状态变化所产生的影响。贝叶斯均衡可以帮助攻击者和防御者预测对方的策略,但在自己决策时,一次只能选取一个具体行动。

(9)

(10)
在物联网网络中,恶意节点和正常节点的数量、节点重要程度等因素对整体网络安全态势有一定影响。设节点重要度由高到低为w={wH,wM,wL},3种类型节点在恶意节点中的分布情况是AW={AH,AM,AL},在正常节点中的分布情况是DW={DH,DM,DL},则物联网安全态势值为
(11)

3.5 模型算法
求解最优防御策略和网络安全态势的算法如下:
模型算法:
输入:状态集合S,动作集合M,类型空间Θ,先验推断P,收益空间U,节点状态W
输出:最优防御策略π*,网络安全态势NS
Begin
(1)Forso∈S

(5) Repeat
(6) Until
(7)Solve
(9)Calculate
(10) Output
该算法将Q-Learning与贝叶斯博弈相结合,适用于物联网安全多状态、防御者和攻击者拥有多个类型的情况,能够根据网络中正常节点和恶意节点的分布情况,确定最优防御决策,并评估安全态势值。与传统方法相比,该算法同时将攻防双方行动作为安全影响因素,安全态势评估更加准确。
4 实验仿真
4.1 实验设置
构建如图1所示的IoT网络,网络中分布了1100个物联网节点设备,设备通过路由器与网络连接。其中有100个恶意节点,1000个正常节点,正常节点中有一个管理员节点。

图1 模拟物联网网络
参考文献[2],攻防双方的策略见表1。

表1 攻防策略
简化的网络安全状态共有7个,分别是:s0={normal operation},s1={device Dos},s2={device attacked},s3={injects malicious data},s4={device direct to malicious portal},s5={device get malicious data},s6={network shutdown}。状态转移关系如图2所示。
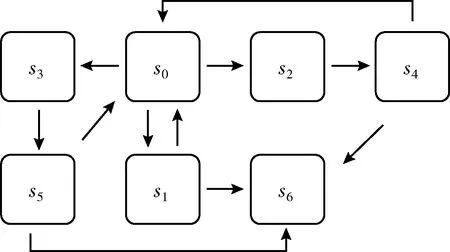
图2 状态转移关系
每个状态的动作见表2。
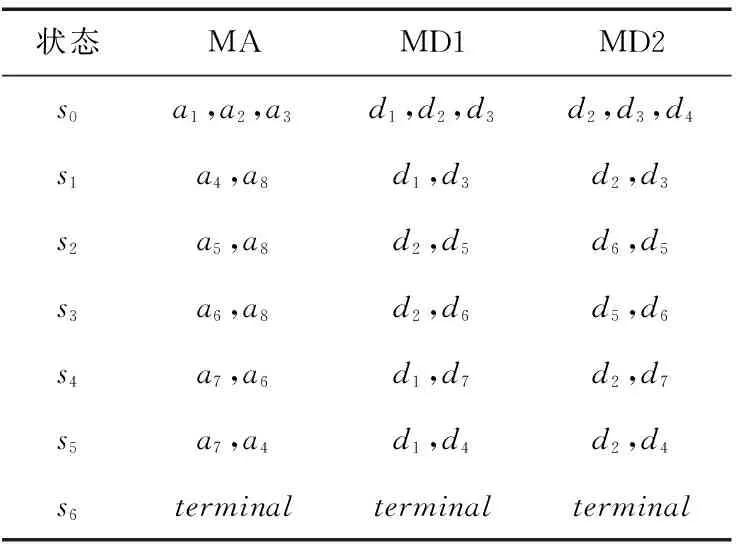
表2 状态动作
由于正常节点选择的防御措施会根据网络状况和自身情况确定,将正常节点的防御分为两种类型:高级防御和低级防御。假设恶意节点只有一种攻击类型:高级攻击,恶意节点对两种防御类型的先验信念为(0.7, 0.3)。以(高级攻击,高级防御)为例,其在状态s0的收益矩阵见表3。

表3 状态s0下(高级攻击,高级防御)收益矩阵
4.2 结果分析
由于算法采用Q-Learning进行状态-动作值的更新,计算策略选取收益不需要预先得到状态间转移概率,避免了可能产生的误差,并且其运行过程可以根据现实情况自主调整,当物联网安全状况发生变化时,也可以再次通过探索得到新的环境信息。同时,贝叶斯博弈的引入使得攻防参与者能够在信息不完全的情况下对另一参与者的行动做出合理推测,不需要掌握完全信息,提高了算法的实用价值。
在最优防御策略选取阶段,根据本文算法,可以得到最优防御策略为:πs0={(0,0.25,0.75),(0,1,0)},πs1={(0,1),(0.91,0.09)},πs2={(1,0),(1,0)},πs3={(1,0),(1,0)},πs4={(1,0),(1,0)},πs5={(1,0),(1,0)}。由结果可知,在状态初始,高级防御者和低级防御者都应该偏向于选择策略d3,随着网络攻击的继续进行,不同类型的防御者出现了不同的最优策略选择。
在网络安全态势评估阶段,基于攻防双方各自采取的行为,以及对另一方行为策略的预测,得到攻击者的安全威胁值以及防御者的安全收益值,综合评估网络安全态势。如果攻防双方在每个状态都选择一个最佳策略,物联网网络安全态势变化如图3所示。
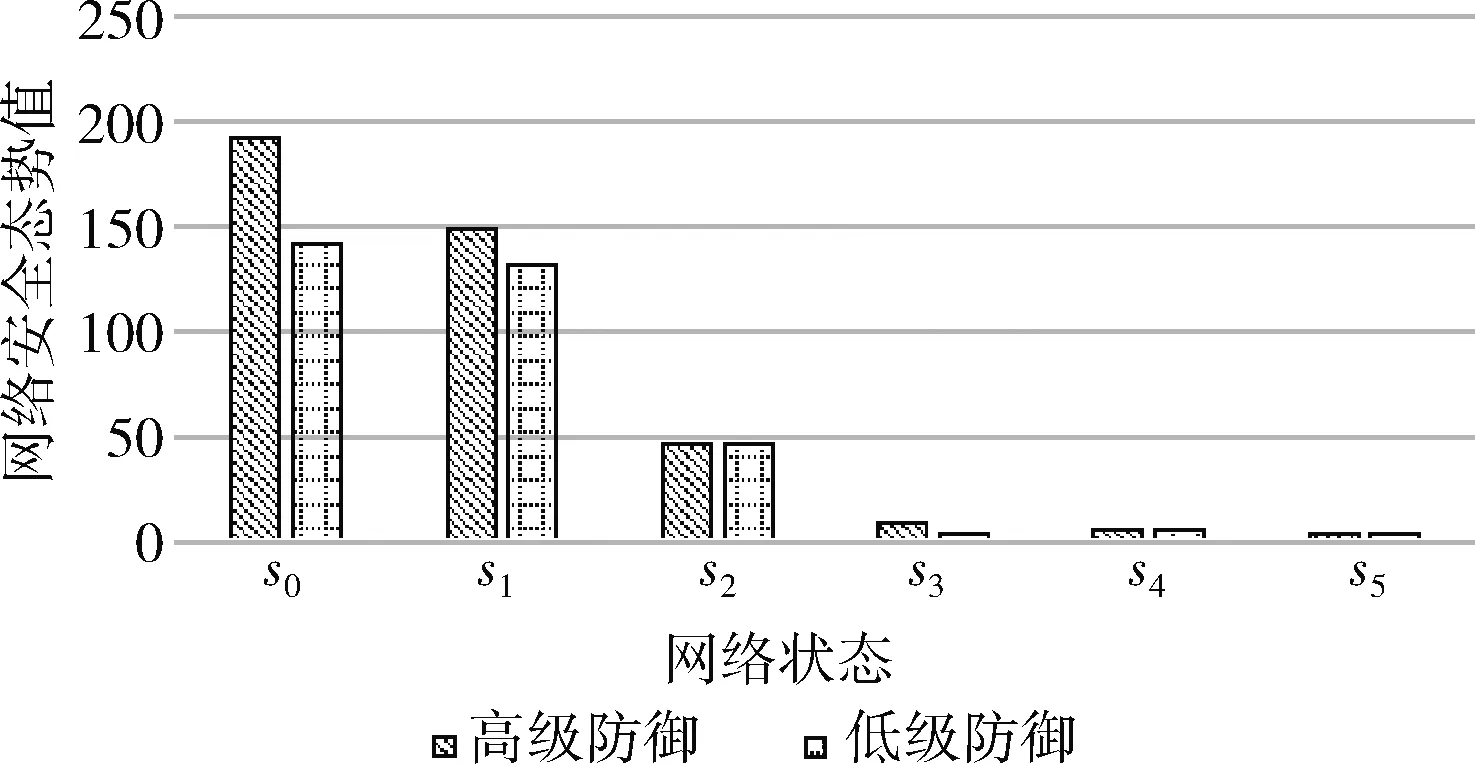
图3 网络安全态势变化
可以看出,随着状态改变,攻击程度加强,网络安全态势值变小。同时,在网络受到攻击的开始阶段,高级防御和低级防御类型之间的差距较大,而到了攻击后期,网络面临威胁十分严重,两种类型的防御者安全状况差距缩小,安全态势都处于较低的数值。这说明即使是防御能力强的防御方,也需要在攻击开始发生时就及时制止,防止网络面对更加严重的威胁。
5 结束语
物联网中存在着多个安全状态,攻击和防御节点也可能存在多种类型。针对物联网安全攻防双方相互影响、安全环境不断变化等问题,本文基于Q-Learning和贝叶斯博弈,提出了一种能够应用于不同安全状态相互转换,并且充分考虑到不同攻防类型和能力的物联网安全最优防御策略选取与态势感知方法。实验验证,本文提出的方法是有效的,能够合理且高效地实现最优防御决策,进行物联网安全态势感知。
猜你喜欢
社会科学战线(2022年4期)2022-06-15
党的生活(黑龙江)(2022年4期)2022-04-25
现代电子技术(2022年8期)2022-04-13
现代电子技术(2022年4期)2022-02-21
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
汽车与安全(2020年1期)2020-05-14
电子制作(2019年13期)2020-01-14
中国外汇(2019年19期)2019-11-26
中国外汇(2019年16期)2019-11-16
