
基于模式识别算法的网页重复信息抽取仿真
2022-04-19 00:47李玉琦
计算机仿真 2022年3期
李玉琦,李 龙
(1. 北京邮电大学,北京 100876;2. 中国科学技术大学,安徽 合肥 230026)
1 引言
数据清洗是为了消除网页或数据集中存在的脏数据或错误数据,采用某种技术对其进行剔除或改正[1]。数据清洗通常包括重复数据归并处理、数据标准化处理、数据增强处理和数据解析等。在表达方式和数据格式方面对数据进行标准化处理是数据标准化处理的实质;拆分、合并处理数据是数据解析中的重要步骤;数据清洗处理的主要目的是为了提高数据的完整性,填补处理缺失的数据,消除文本中存在的相似数据。数据清洗技术被广泛地应用在各种工程数据和网络数据挖掘中[2]。网络中存在的重复数据会对数据的检索和判断产生影响,同时也会浪费存储空间,因此需要进一步深入研究网页重复信息抽取方法。
时珉等人[3]提出基于滑动标准差计算的网页重复信息抽取方法,该方法首先分析网页信息的来源和信息在网页中分布的特性,计算网页信息的滑动标准差,根据计算结果构建标准差曲线,通过曲线上翘特性判断网页中存在的重复信息,实现网页重复信息的抽取。但是,该方法没有对网页信息分类,导致方法的全面率较低。何俊等人[4]提出基于Petri网的网页重复信息抽取方法。该方法在Petri网的基础上建立RCCM模型,利用RCCM模型生成规则链,利用规则链对网络中存在的重复信息进行检测,实现网页重复信息的抽取,该方法无法区分网页信息的类别,导致方法存在重复信息比例高的问题。徐搏超[5]提出基于参数关联性的网页重复信息抽取方法。该方法利用关联规则对网页信息之间存在的关联性进行分析,获得关联性较强的网页信息,并通过空间数据聚类算法对网页信息进行初步检测,采用高斯核相关向量机对网页重复信息进行抽取。但是该方法没有对网页信息的类别进行划分,重复信息抽取结果受网页信息类别的影响较大,方法的整体性能较差。
为解决上述方法存在的问题,提出新的基于模式识别算法的网页重复信息抽取方法。
2 网页信息特征提取
若网页信息词频的贡献率较低,在实际情况中容易成为噪声特征[6]。基于模式识别算法的网页重复信息抽取方法通过特征词集中存在的因子ai描述不同类中特征词的集中程度,ai可通过下式计算得到
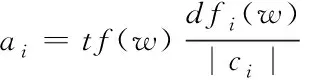
(1)
式中,在类别i中网页信息特征词w出现的次数为dfi(w),tf(w)为在类别i中网页信息特征词w对应的词频数;ci为属于类别i的文档数。
在互信息中引入词频信息MI(w,ci),其表达式如下
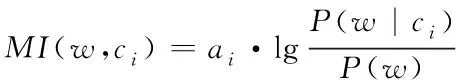
(2)
式中,P(w)为样本中存在特征词w的概率;P(w|ci)表示类别ci中存在特征词w的概率。
当网页中存在特征词时,用类间因子βi描述其集中程度,特征词的重要程度受类间均匀度的影响。
特征词w在类别ci网页中出现的数量为衡量类间均衡性的标准,基于模式识别算法的网页重复信息抽取方法通过差异因子βi描述网页中特征词的分布特征,通过下式计算因子βi
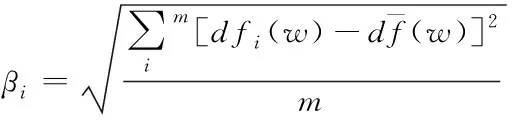
(3)

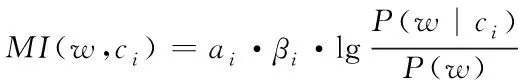
(4)
若网页中存在的信息对应的特征值较低,通常会被删掉[7]。但网页中通常存在大量的低信息量特征,仅仅加权处理累加分布和词频不能获得高精度的网页特征。
为解决上述问题,所提方法在关联规则的基础上获取网页中不同信息的利用率,计算过滤特征与上述提取特征之间存在的关联性。
设置特征词集Hw,网页信息特征均存在于该词集中,根据网页信息的特征值对网页信息进行过滤处理,并选取其中一部分信息构建特征词集Lw。
计算特征词集Hw与Lw对应的频繁2项集合,并对候选集C2过滤处理,消除频繁出现的前项,获得后项规则L2={(w11→w21,cv1),…(w1k→w2k,cvk)},其存在最大的特征值。
若特征词规则w1g满足w1g→w2g,则特征词w1g根据规则置信度cvg对应的概率转变为w2g。
根据特征集Hw向量化处理重新映射后获得的语料库,获得可入模数据txt={t1,t2,…,tn},其中ti即为网页信息特征。
3 网页重复信息抽取
3.1 网页信息分类
选择模式识别中的支持向量机根据提取的网页信息特征对网页信息进行分类。
基于模式识别算法的网页重复信息抽取方法为了建立软间隔分类器,在支持向量机中引入松弛因子。
通过下式描述线性分类器f(x)=w·x的目标函数,其表达式如下
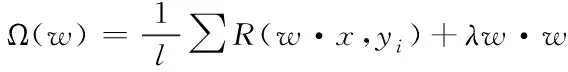
(5)
式中,l代表松弛因子;R(w·x,yi)代表损失函数,网页信息训练集产生的损失可以通过该函数进行描述;参数λ在上式中的主要目的是保证训练集中的网页信息可以实现正确的分类;w·w代表采用支持向量机对网页信息进行分类时对应的间隔。
网页之间存在的链接关系可以有助于网页信息的分类[8]。有向图的边通常情况下可以描述网页之间存在的链接,并通过边集合E存储网页中存在的所有链接结构。在此基础上可以将正则化因子γ引入目标函数中
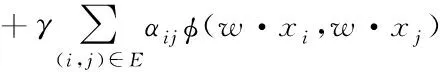
(6)
式中的第三项代表正则化因子;αij代表网页j与网页i之间存在的链接对应的权重;φ(w·xi,w·xj)代表惩罚函数。
分类器受特征空间丰富度的影响,两者之间呈线性关系[9],引入变量zi将其作为松弛因子提高分类器的灵活性,针对网页中存在的所有结点i,都构建对应的分类器,目标函数此时可以转变为下式
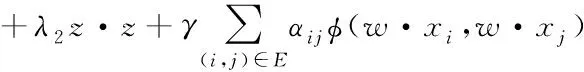
(7)
式中,参数w、z的值可以通过正则化因子λ1、λ2实现控制。
目标函数属于凸函数,需要对其进行优化,即在约束条件下最小化参数w、z[10],基于模式识别算法的网页重复信息抽取方法通过运行回归算法对参数w进行最小化处理。
所提方法对网页结点i和j分类之前,需要计算网页的置信度,根据计算结果获得正则化因子,设fi、fj分别代表网页i、j对应的可信度,基于模式识别算法的网页重复信息抽取方法根据可信度重新定义惩罚函数
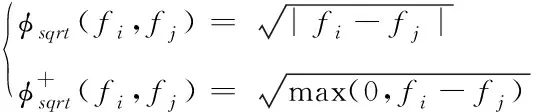
(8)
为提高惩罚函数的灵活性,在上式的基础上加入调整因子α

(9)
获得软间隔分类器
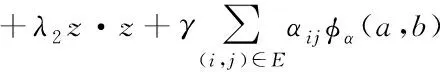
(10)
利用上式的软间隔分类器对网页信息完成分类处理。
3.2 重复信息抽取
基于模式识别算法的网页重复信息抽取方法在不同类别中对网络信息的语义相似度进行计算,根据计算结果实现网页重复信息的抽取。
1)语义相似度
设asim(A,B)代表网页信息A和网页信息B之间的语义相似度,其计算公式如下
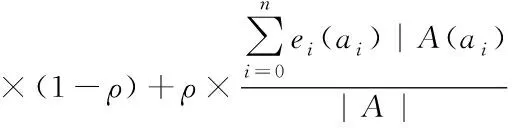
(11)
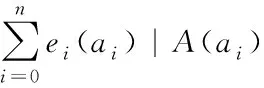
2)结构相似度
语义要素受网页结构要素的影响可以通过结构相似度进行衡量[11],因此计算结构相似度时需要引入权重要素,设csim(A,B)代表网页信息A和网页信息B之间存在的结构相似度,其计算公式如下
csim(A,B)=μδ×
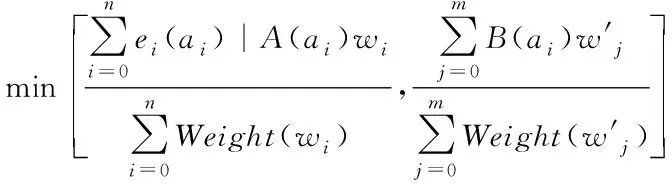
(12)
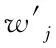
3)相似度
综合考虑语义相似度asim(A,B)和结构相似度csim(A,B),计算网页信息A与网页信息B之间存在的相似度sim(A,B)
sim(A,B)=αasim(A,B)+βcsim(A,B)
(13)
式中,α代表在网页中相同元素对应的语义影响因子;β代表在网页中相同元素对应的结构影响因子。语义影响因子α和结构影响因子β之间满足下式
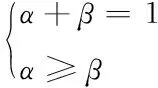
(14)
根据上式可知语义影响因子α通常情况下大于结构影响因子β,因此对网页信息相似度进行计算时,需重点考虑语义影响因子α[12]。
当相似度sim(A,B)大于等于阈值δ时,表明信息重复,完成网页重复信息的抽取。
4 实验与分析
为验证基于模式识别算法的网页重复信息抽取方法的整体有效性,需要对基于模式识别算法的网页重复信息抽取方法进行测试。分别采用基于模式识别算法的网页重复信息抽取方法(方法1)、基于滑动标准差计算的网页重复信息抽取方法(方法2)、基于Petri网的网页重复信息抽取方法(方法3)和基于参数关联性的网页重复信息抽取方法(方法4)进行对比测试。
设q代表全面率,代表网页重复信息Nt与网页信息N之间的比值,其计算公式如下
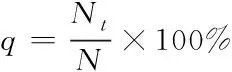
(15)
方法1、方法2、方法3和方法4的全面率测试结果如图1所示。
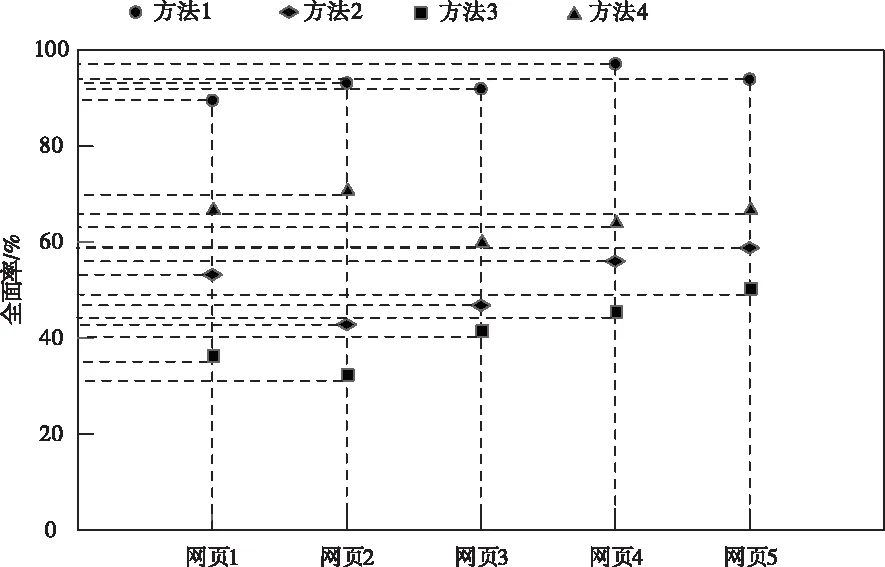
图1 不同方方法的全面率测试结果
分析图1中的数据可知,采用方法1对网页重复信息抽取时,获得的全面率均高于80%,采用方法2对网页重复信息抽取时,获得的全面率均在40%-60%内波动;采用方法3对网页重复信息抽取时,获得的全面率均在30%-50%内波动;采用方法4对网页重复信息抽取时,获得的全面率均在60%附近波动,通过上述分析可知,所提方法的全面率最高,表明方法1可有效地实现网页重复信息的抽取,这是因为该方法根据提取的网页信息特征对网页信息进行分类处理,对不同类别中存在的重复信息进行抽取,提高了方法1的全面率。
基于以上实验结果,下面将重复信息所占比例作为测试指标,对方法1、方法2、方法3和方法4进行测试,结果如表1所示。
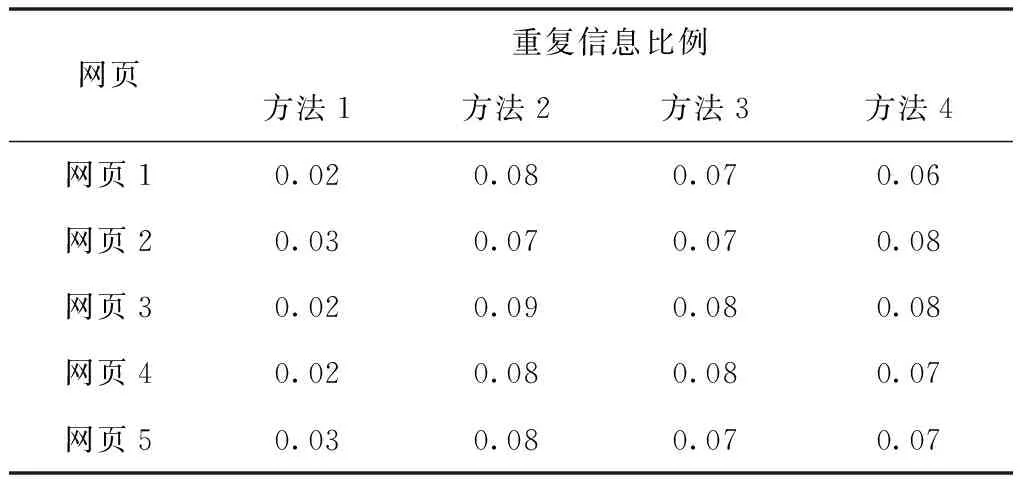
表1 不同方法的重复信息比例
根据表1数据可知,方法2、方法3和方法4的重复信息比例较高,表明采用上述方法对网页重复信息抽取后,网页中还存在大量的重复信息,表明方法的有效性较差。方法1在测试过程中获得的重复信息比例较低,表明采用方法1对网页重复信息进行抽取后,网页中的重复信息量明显下降,原因是方法1对网页信息进行分类处理时,引入了松弛因子,提高了分类器的灵活性,可有效的提取出网页中存在的重复信息,降低了重复信息比例。
采用综合指标F-Measure对方法1、方法2、方法3和方法4的整体有效性进行测试,F-Measure的计算公式如下
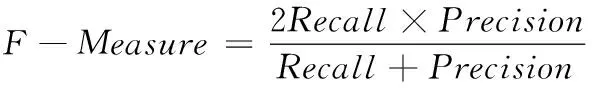
(16)
其中,Recall代表查全率;Precision代表查准率。
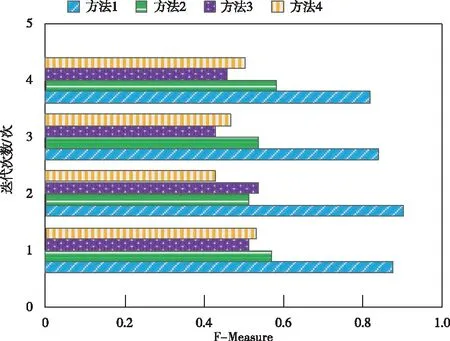
图2 整体性能测试结果
根据图2中的数据可知,方法1的综合指标值远远高于方法2、方法3和方法4的综合指标值,表明方法1进行网页重复信息抽取时的整体性能优于方法2、方法3和方法4的整体性能,原因为方法1对网页信息进行分类处理时,利用调节因子对惩罚函数进行调整,分类器分类性能得以提高,进而优化了方法1的整体性能。
5 结束语
目前网页重复信息抽取方法存在全面率低、重复信息比例高和整体性能差的问题,提出基于模式识别算法的网页重复信息抽取方法,根据网页信息的特征对网页信息进行分类,计算不同类别网页信息的相似度,以此完成网页重复信息的抽取,解决了目前方法中存在的问题,为网页信息资源的利用创造了条件。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
中国药房(2022年10期)2022-05-30
导弹与航天运载技术(2022年2期)2022-05-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
软件导刊(2017年4期)2017-06-20
科技视界(2016年26期)2016-12-17
科技视界(2016年12期)2016-05-25
