
基于概率统计的多维关联数据动态挖掘仿真
2022-04-19 00:47关丽红
计算机仿真 2022年3期
张 平,关丽红
(长春大学理学院,吉林 长春 130022)
1 引言
数据处理技术[1]迅猛发展,待处理数据规模日益庞大,在初始数据内挖掘出所需信息的有效手段逐渐增多,已成为数据处理技术的一个主要研究方向[2]。数据挖掘技术与统计分析息息相关,只有经过数据分析,才能发现数据之间隐藏的关系与模式。该项技术作为应用策略之一,其数据间具有一种独有的关联规则,此类数据统称为关联数据[3,4]。为拓宽关联数据挖掘技术的应用领域,相关研究领域的众多专家与学者对其展开了深入探索。
例如,部分学者通过建立强关联规则,经选择、交叉、变异等操作,结合信息增益建立决策树挖掘模型,运用该模型实现关联数据挖掘;部分学者通过数据处理层、挖掘层、储存层以及查询层构建硬件部分,结合数据量化、子集抽取以及模糊聚类等软件程序,建立漏洞信息数据挖掘系统。除上述方法外,文献[5]在关联规则中添加改进遗传算法,基于此,通过引入亲密度来构建一种数据挖掘方法。但是,以往的数据挖掘方法通常是静态挖掘已有的历史数据,无法满足实时获取的应用需求,因此,本文以挖掘领域中最基础、最关键的统计策略为基础,架构出基于概率统计的多维关联数据动态挖掘方法。构建的非参数概率统计模型基础是核密度估计,有助于互补参数化与非参数化优劣势,提升少样本数据的概率密度预估准确度;根据参数设置原则,合理设置模型参数,使概率统计模型性能得到最大化发挥;提取多维关联数据之间的关联规则,增加多维关联数据动态挖掘的有效性。
2 概率统计模型
假定任意采集到的独立样本集合为{X1,X2,…,Xn},样本数量是n,且服从某未知概率密度f(x)分布,则引入核密度估计[6]的非参数概率密度预估界定表达式如下所示
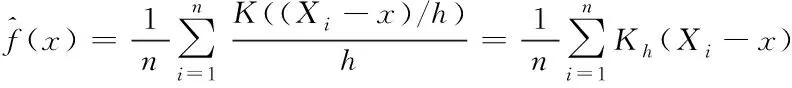
(1)
由上式推导出

(2)
其中,核函数与窗宽分别是K(z)、h,且h>0,对概率密度预估平滑度起着决定性作用。
根据核密度估计理念下的非参数概率密度预估方法,结合实际的数据分布先验知识,建立一种以提升少样本数据的概率密度预估准确度为目标,互补参数化与非参数化优劣势的半参数化概率密度预估模型。
(x)=r(x)*f(x,)
(3)
依据式(3)所示的理想修正因子形式,通过核密度估计的概率密度预估方法,完成非参数化修正因子r(x)预估的界定,表达式如下所示
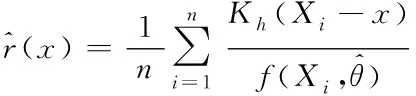
(4)

(5)
基于式(4)的界定公式,构建出下列基于核密度估计的半参数化概率密度预估模型
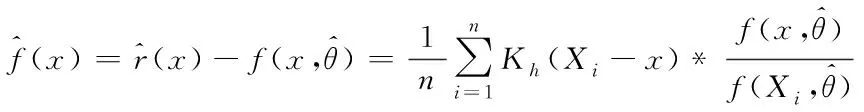
(6)
为使概率统计模型性能最大化,依据设计的半参数化概率密度预估模型,结合以下参数设置原则,合理设置模型参数:
1)利用积分均方误差算法[7],最小化窗宽h的最佳值,计算公式如下所示
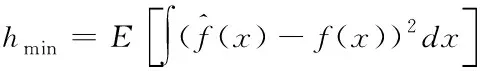
(7)
2)若式(6)中的f(Xi,)≈0或与f(x,)的差值较大,则分式的值对概率密度预估结果有直接影响,因此,利用下列截断表达式,令分式值局限在0.1到10以内:
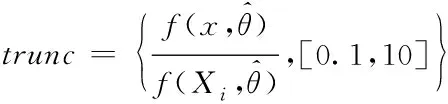
(8)
3 基于概率统计的多维关联数据动态挖掘
3.1 多维关联数据挖掘规则
为有效实现多维关联数据的动态挖掘,需先挖掘出多维关联数据之间的关联规则,规则提取通过改进的遗传优化算法[8]完成,具体流程描述如下:
1)令初始种群随机产生,得到种群P={A1,A2,…,Am};
2)基于种群P={A1,A2,…,Am},获取使用者预设的支持度与置信度极小值,分别为smin、cmin;
3)利用下列计算公式求解种群P={A1,A2,…,Am}所含个体的适应度值:
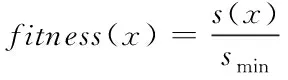
(9)
4)根据解得的个体浓度dj与选择概率
5)完成当前种群内所有个体至交配池的复制;
6)在交配池里任意选取到个体A′、A″,采用下式任意动态选择到的交叉概率,完成交叉操作

(10)
7)利用任意动态选择到的变异概率,完成变异操作

(11)
8)当符合遗传优化算法停止迭代的条件时,运算停止;反之,则返回第3)步,开始新一周期的循环计算;
9)根据解得的置信度,提取出多维关联数据之间的关联规则。
3.2 多维关联数据动态采集
将滑动窗口设定成动态采集窗口,以平滑地动态采集多维关联数据。滑动窗口的两个相关界定条件描述如下:
1)对于多维关联的动态数据源,已知标识号是i∈Z+的数据di,根据数据形成时长,划分为τ规格窗口的数据段Dk,其中,k∈N,τ表示时段,同时也指代数据的门限值[9],因此,各数据段均是一个数据窗口;
2)ω是一个给定正数,满足ω=τn,当ω规格的窗口在T时间时,出现数据段集合D={D1,D2,…,Dn},且每间隔τ时段,窗口就会向前运动,步长是s个数据窗口,则该窗口就是滑动窗口。
图1展示的是多维关联数据的滑动窗口动态采集过程,将两个数据窗口作为滑动窗口规格,移动步长设定成每次一个窗口。

图1 滑动窗口动态采集过程示意图
3.3 多维关联数据动态处理
为避免忽略边界数据,利用叠加窗口方法设计一种动态窗口,完成数据的实时动态处理。给定有限数据集Z={Z1,Z2,…,Zn},Z⊂RC,将其分类成数量为(2k-1)的数据窗口,令窗口i与i+1局部叠加,反复求解重合区域的边界数据,逐个窗口完成处理直至结束。该方法使密度点的选择贡献值全部相同,并有助于减小k值对密度点的影响。
将动态窗口规格界定为sτ,按照表1所示的窗口分类条件,划分多维关联的动态数据源,以处理所有数据di。

表1 动态数据源窗口分类条件
在数据窗口不断向前运动的过程中,基于数据流特征,采用设计的动态窗口,按照以下流程完成数据的实时动态处理:
1)针对滑动窗口采集到的m维流式数据序列{x1,x2,…,xi,…}与数据处理窗口时间序列{t1,t2,…,ti,…},根据滑动窗口的两个相关界定条件,推动出下列表达式

(12)
2)令数据集满足下列等式
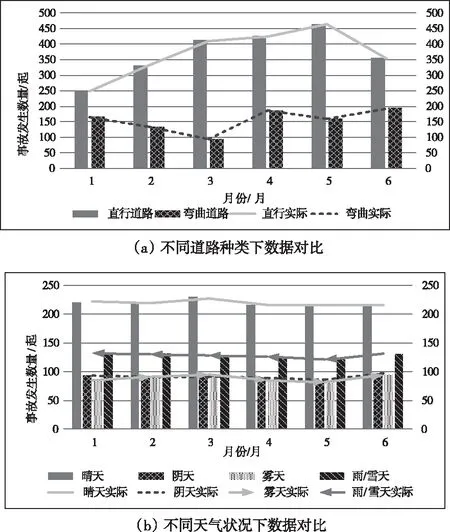
xi={D(i-1)*s+k|0 (13) 3)设定2τs为动态窗口规格,v=τs; 4)先后在流式数据集xi、xi∩xi+1以及xi+1内,分别提取出特征项; 5)逐个窗口进行处理,去除重复特征项,发送处理结果至目标数据集。 假设θτ(θ∈R+)表示时间门限值,每当到达该时间门限值时,动态挖掘便运行一次,且需要于下个运行周期开始前结束挖掘。 在动态挖掘目标数据集的过程中,利用K标号方法标识使用的数据,实现动态控制目标数据,解决处理后、未处理以及目标数据间的平滑问题。 针对已知目标数据集TDS={TD1,TD2,…,TDj},其中,j∈N,0是其初始标识号码,在每次实施动态挖掘后,都要在目标数据TDi的标号数值上做加一处理,待标号增加至K(K∈N)后,处理操作停止。动态挖掘的每次运行均采用比K小的标号数值数据。 选取某市区五个交警大队半年内的道路交通事故数据作为挖掘目标,利用本文构建的动态挖掘模型分析事故属性数据,提取出潜在关联规则,获取实验结论。 表2所示为多维关联数据动态挖掘方法的开发环境与运行环境软硬件相关参数。 表2 挖掘方法仿真环境参数配置 根据事故成因,将道路交通事故进行分类,利用由美国flexsim公司开发的FlexSim仿真软件[10],绘制出图2所示的道路交通事故类别及其对应数量。 图2 道路交通事故类别及其对应发生数量 以违章变更车道为例,在设定支持度阈值与置信度阈值的极小值后,挖掘与该事故成因类别存在关联的多维数据相关规则。部分关联规则描述如下,其中,括号中数据分别表示各关联规则的支持度与置信度,用于反映该条关联规则的必要性与可用性: 1)道路因素+时间因素:混合式横断面与主干路(5.48%,42.65%);四岔口路段(6.23%,38.11%);沥青路面、混合式横断面、日间时段、无信号灯(10.31%,40.38%); 2)道路因素+天气因素+时间因素:晴天、平原地形、混合式横断面、日间时段、直行线路、无信号灯(8.76%,41.98%);阴天;沥青路面、混合式横断面、日间时段(9.37%,35.61%);雾天、平坦路面、混合式横断面、夜间时段、直行线路、无信号灯(7.56%,39.74%);雨天、平原地形、混合式横断面、日间时段、弯曲线路、无信号灯(10.31%,42.18%); 3)道路因素+时间因素+驾驶员因素:主干路、混合式横断面、日间时段、无信号灯、无证驾驶(12.16%,44.65%);平坦路面、混合式横断面、夜间时段、疲劳驾驶(12.75%,43.49%);沥青路面、混合式横断面、日间时段、弯曲线路、无信号灯、醉酒驾驶(11.68%,43.57%)。 基于得到的多维数据关联规则,从直行与弯曲道路类型、不同天气状况的月统计周期数据以及不同时段的事故数量中,动态挖掘多维关联数据,并将其与实际事故发生数据作对比,如图3所示。 根据图3中动态挖掘到的事故数据可以看出:在直行、晴天等视野更好的行车环境中,驾驶员更容易麻痹大意,导致直行与晴天条件下的道路交通事故发生频率高于其它情况,从事故发生时段来讲,午后发生频率更高,尤其是疲惫感剧增的傍晚时段,肇事死亡率较大;通过对比事故的实际发生次数,显而易见,本文方法能够有效挖掘出所需的多维关联数据,且具有较为理想的精准度,究其原因是半参数化概率密度预估模型的构建目标是提升少样本数据的概率密度预估准度,利用遗传优化算法,提取到了多维关联数据之间的关联规则,通过滑动窗口动态采集、叠加窗口动态处理,结合时间门限值与K标号方法,实现动态控制、挖掘目标数据。 在大数据中发现可用信息的处理过程就是数据挖掘,该项技术已随着网络技术的发展演变成了学术界的主要课题,并在保险、医疗、电信、金融等现代社会的诸多重要领域中,起着决策与管理的指导作用。不断更新的数据信息对以往的挖掘技术提出了前所未有的巨大挑战,使其无法及时给予有效信息,故利用概率统计方法,动态挖掘多维关联数据,实现本文的研究目的。概率统计作为数据挖掘的关键环节,需做深入的理论知识研究,使概率统计方法与数据动态挖掘技术更有效地结合;需尝试利用开环分类学习系统,通过逆向反馈流程,检验、明确反馈效果,实现适应性调整,提升模型学习效率;由于提取到的关联规则以支持度与置信度为基础,存在使用者不感兴趣的规则,为解决该问题,应将兴趣度添加作为下一阶段的研究侧重点,令得到的关联规则更具实用性。3.4 多维关联数据动态挖掘
4 多维关联数据动态挖掘仿真
4.1 仿真环境配置
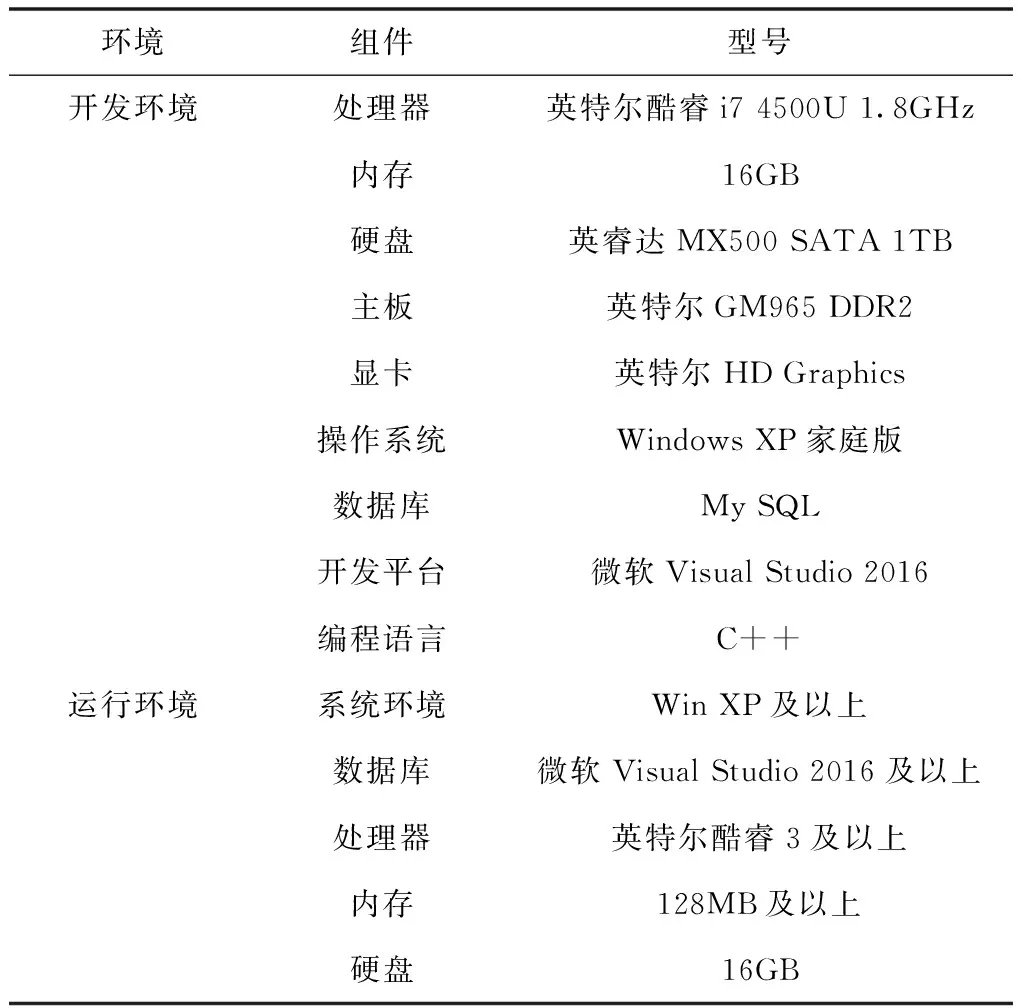
4.2 多维关联数据动态挖掘

5 结论
猜你喜欢
当代陕西(2019年15期)2019-09-02
综艺报(2018年17期)2018-09-14
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
棋艺(2014年7期)2014-09-09
中国文化遗产(2009年6期)2009-01-11
