
选择性传输与铰链对抗的多图像域人脸属性迁移
2022-04-18 10:56陈壮源李玉强
计算机工程 2022年4期
林 泓,陈壮源,任 硕,李 琳,李玉强
(武汉理工大学计算机科学与技术,武汉 430063)
0 概述
人脸属性迁移可以看成是一类图像域到图像域的任务[1],其主要应用于数据预处理、辅助人脸识别、娱乐社交等领域。生成对抗网络[2]作为当前人脸属性迁移的主流架构,结合零和博弈的思想,在判别器和生成器协同对抗训练中不断提高生成图像的真实性和质量。相比使用配对图像训练数据集的有监督图像迁移方法[3],无监督图像迁移方法可以通过非配对图像数据集完成图像域迁移,具有更广泛的应用场景[4]。
根据训练过程中建立的源图像域和目标图像域的映射关系,无监督图像迁移分为单图像域迁移和多图像域迁移[5]。针对单图像域之间的映射关系,文献[6]提出DFI 方法,根据线性特征空间假设直接从源图像域特征空间学习目标图像的属性特征,以实现单图像域人脸属性的迁移。文献[7]提出cycleGAN 方法,引入循环重构一致性约束,采用两个生成器和判别器在另外一个生成器中对生成的迁移图像进行重构,从而更好地建立图像域之间的映射关系。文献[8]在cycleGAN 的基础上,通过引入自注意力机制建立像素间远近距离的依赖性,以更好地还原图像的细节信息,并通过谱规范化提升模型的稳定性,从而提高迁移图像的真实性。但是无监督的单图像域人脸属性迁移只能在单个人脸属性图像域之间进行,如果进行多个图像域迁移,需分别对每个图像域进行单独训练,增大了训练的难度。
多图像域人脸属性迁移是单图像域迁移的拓展,其目标是在一次训练过程中完成多个图像域之间的迁移。文献[9]提出IcGAN 方法,使用标签完成人脸图像重构以及多图像域迁移,采用两个编码器分别提取图像中的内容信息和属性标签信息,再通过CGAN[10]生成指定的迁移图像。文献[11]在UNIT[12]基础上提出MUNIT 方法,基于图像可以分解成固定的内容编码和样式编码的假设,利用自适应实例归一化融合两个编码器,并分别提取内容编码和样式编码,从而完成多图像域的迁移任务。文献[1]提出的ELEGANT 方法,通过提取图像中各个属性的内容信息来建立每个属性和隐层编码特征向量的位置关系,以指导多图像域人脸属性迁移。同样,文献[13]提出的StarGAN 方法,在生成器网络中引入目标图像域标签信息,通过循环重构一致性约束保证迁移图像域前后的一致性,并结合分类损失函数指导建立源图像域和目标标签的映射关系,从而完成多图像域人脸属性迁移。文献[14]在StarGAN 基础上提出StarGAN v2,利用映射网络生成样式编码信息,生成器将源域输入图像和生成的样式编码信息迁移成目标域图像,以增加迁移图像域的多样性。文献[15]基于Attgan[16]提出STGAN方法,利用选择性传输单元(Selective Transfer Units,STU)将编码器提取的图像内容特征根据差分属性标签选择性传输到解码器,以降低跳跃连接对图像分辨率的影响,从而减少无关图像域的变化,且提升多图像域人脸属性迁移的质量。
当前多图像域人脸属性迁移方法能够较好地建立目标标签与迁移图像域之间的对应关系,但仍存在图像域表达形式多样性差、无关迁移图像域变化较大和判别器准确度低的问题,通过类别标签指导的多图像域人脸属性迁移直接输入离散形式的目标标签,一方面无法明确迁移目标图像域和源图像域之间的差异,另一方面造成图像域表达方式多样性的损失。下采样的卷积操作导致图像分辨率降低和图像迁移细节失真。单个判别器的鉴别能力无法准确定位迁移的图像域,导致判定准确度低,从而降低生成图像的协调性与真实性。在寻找纳什均衡解的过程中,判别器未能很好地使用输入数据(一半是真一半是假)的先验知识,导致目标图像域定位不够准确,且指定图像域的迁移效果欠佳。
为改进多图像域人脸属性迁移的视觉效果,本文提出一种多图像域人脸属性迁移方法。在生成器网络设计中,通过引入相对属性标签[18]和选择性传输单元,迁移目标图像域。利用图像域控制器和自适应实例归一化[19]融合内容特征和样式特征。在判别器网络设计中,采用双尺度判别提高人脸属性迁移的图像质量。在损失函数设计中,设计融合相对鉴别[20]与铰链损失的铰链对抗损失函数,从而提升指定图像域的整体迁移效果。
1 融合选择性传输和铰链对抗的迁移模型
1.1 整体模型
人脸属性迁移任务的本质是在保证其他区域像素不变的情况下,通过修改特定部分的像素获取迁移目标图像。基于此,本文设计的多图像域人脸属性迁移整体结构由一个生成器G和两个判别器D组成,如图1 所示。生成器网络由基本网络和图像域控制器组成,其中基本网络由编码器、解码器构成,图像域控制器由多层感知机(Multilayer Perceptron,MLP)构成,主要生成目标图像的样式信息。判别器整体结构由鉴别网络和分类网络2 个部分组成,真假信息由鉴别网络输出,迁移图像域类别信息由分类网络获取,如图1 所示。
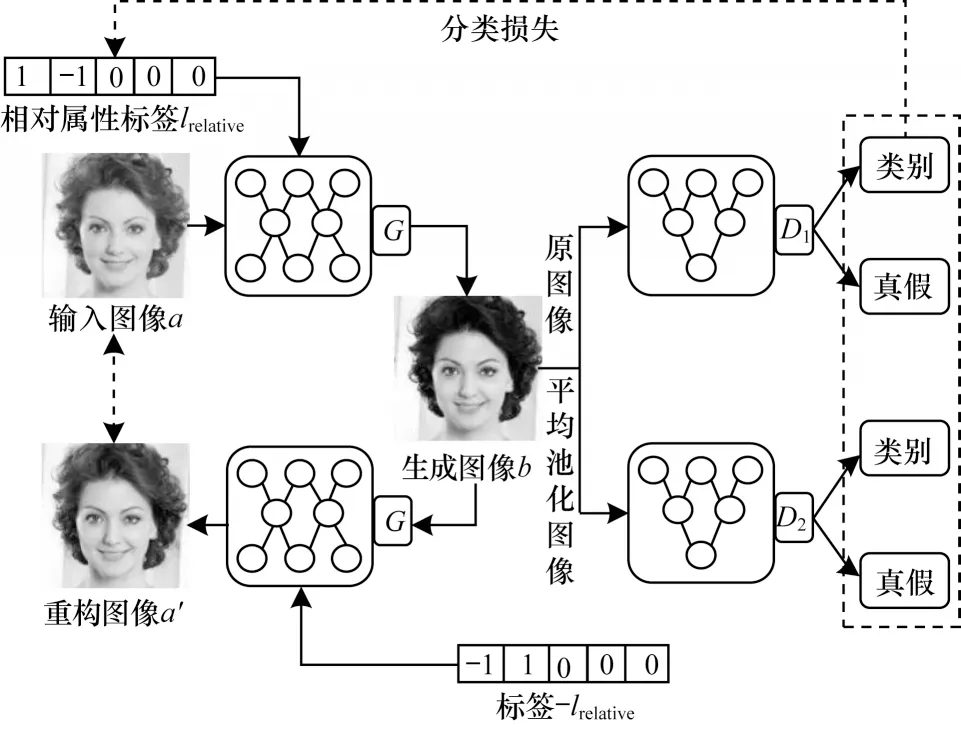
图1 本文模型整体结构Fig.1 Overall structure of the proposed model
从图1 可以看出,属性标签中每个位置的具体值分别表示其中的一种人脸属性图像域,为减少目标图像域和生成图像域之间的差异性,本文模型采用相对属性标签作为输入,模型的整体流程主要是将真实图像a和相对属性标签lrelative输入到生成器G,生成器根据相对属性标签lrelative将真实图像a迁移为图像b,为保证迁移图像和原始图像的一致性,将生成的图像b根据属性标签-lrelative再次经过生成器G重新生成循环重构的图像a′。在判别器中利用卷积神经网络获得生成器所生成图像各个域特征信息的分类损失,以建立生成图像与相对属性标签的映射关系,同时对生成图像进行真假鉴定,从而获取生成图像与原始图像的对抗损失,更好地引导图像域的迁移。
本文模型设计了相对属性标签,通过单个生成器和双尺度判别器相互对抗,使其专注于生成目标图像域,利用对抗损失和分类损失指导生成器建立相对属性标签和生成图像域的映射,从而完成多图像域迁移任务。
1.2 生成器模型
本文生成器的整体结构由图像域控制器、上采样、中间区域、下采样和选择性传输单元5 个部分组成。由MLP 构成的图像域控制器将目标图像的相对属性标签和高斯分布的噪声数据迁移为图像域样式信息;由卷积神经网络组成的下采样区域提取图像的内容特征信息;由自适应实例归一化(AdaIN)残差网络块结构组成的下采样区域,融合提取的内容信息和图像域控制器生成的样式信息;STU 将在下采样区域中的图像内容特征信息传输到上采样区域中;反卷积神经网络组成的上采样区域将融合的特征迁移成图像。具体结构如图2所示。
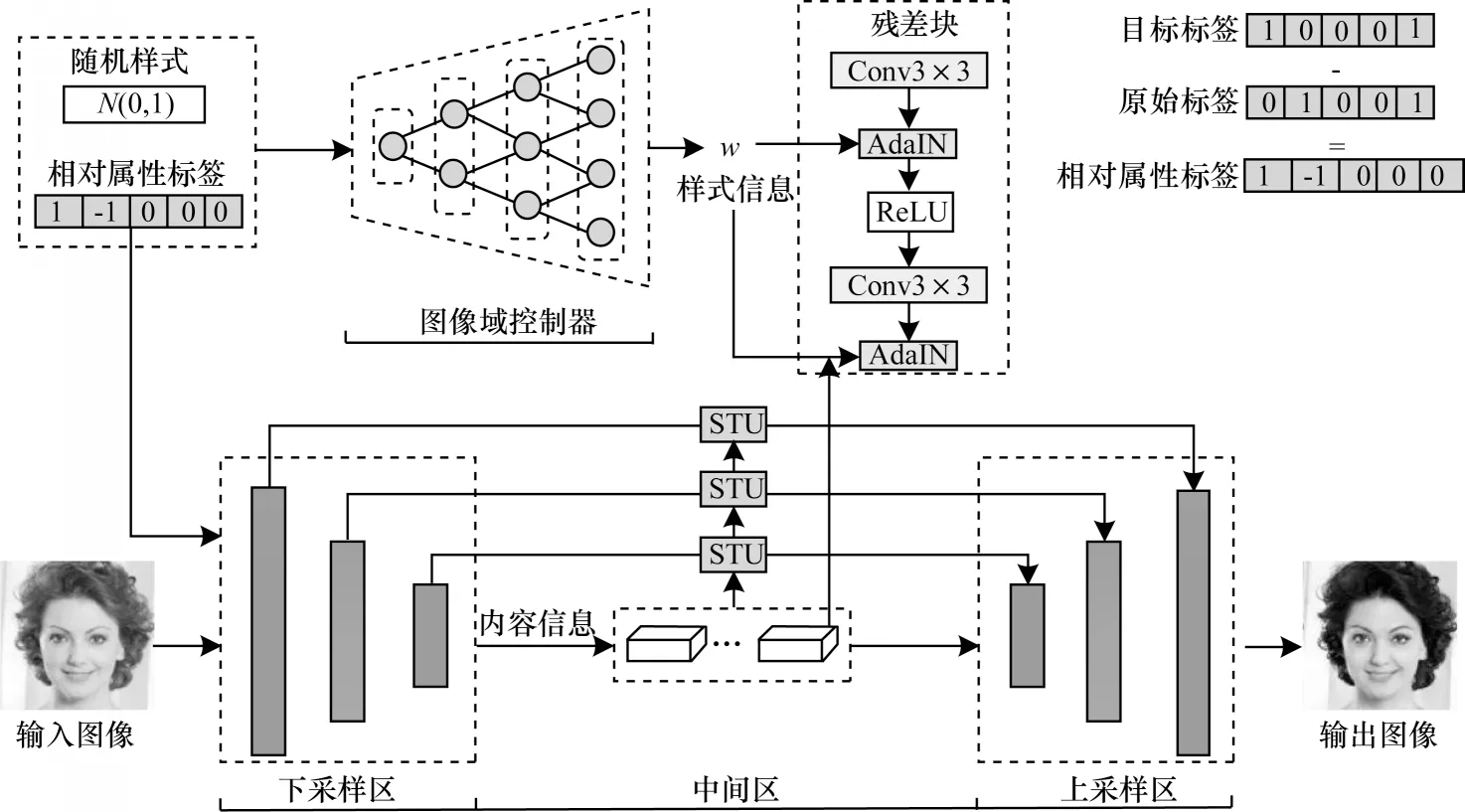
图2 融合域控制器和选择性传输单元的生成器结构Fig.2 Structure of generator with domain controller and selective transfer units
在生成器的参数设置上,除上采样输出层使用Tanh 作为非线性激活函数以外,其他区域的卷积神经网络均选择ReLU 作为激活函数。图像归一化处理时在下采样区域卷积层采用IN,在中间区域的残差网络块采用AdaIN,其他参数设置如表1 所示。
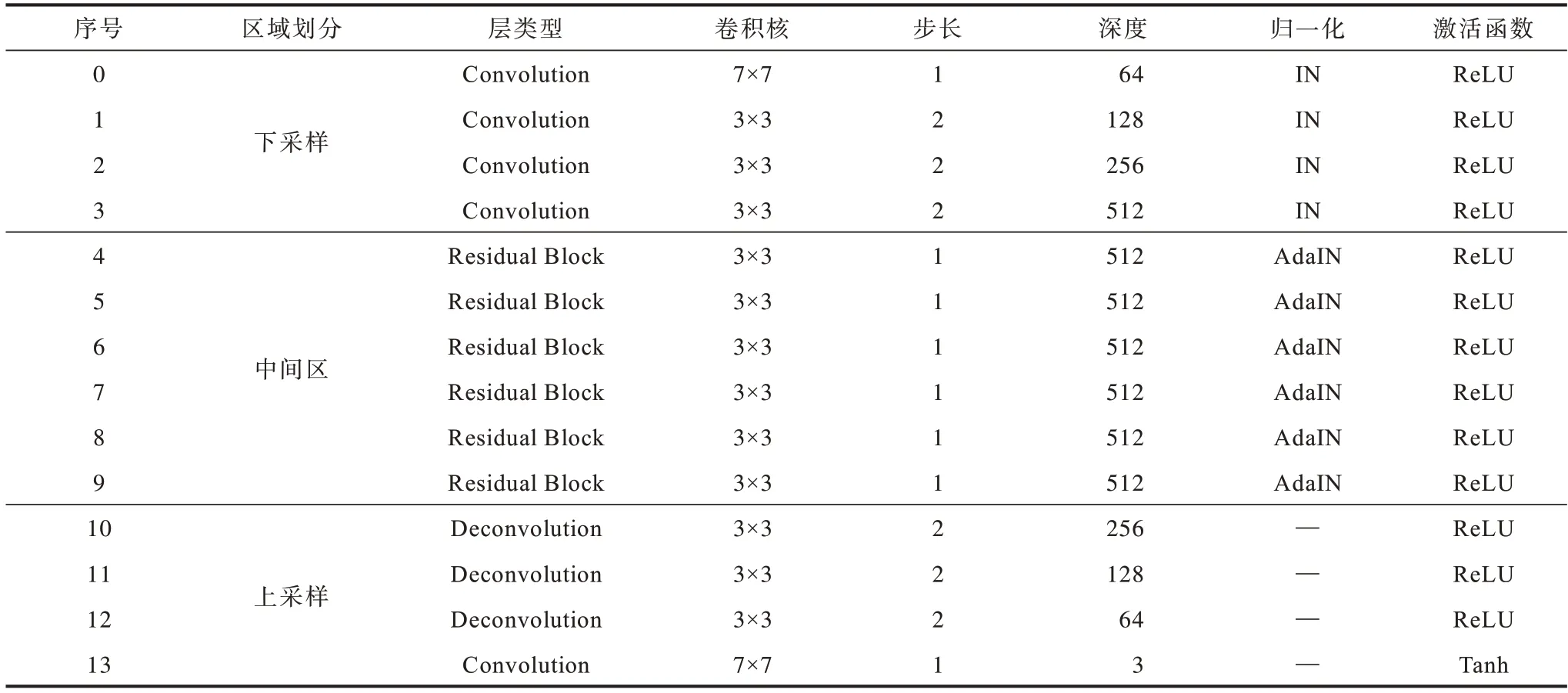
表1 生成器的参数设置Table 1 Parameter settings of generator
1.2.1 图像域控制器
采用离散形式的目标标签作为输入,一方面导致无法建立明确的迁移图像域和源图像域映射关系,另一方面造成生成图像的图像域表达形式单一。本文利用相对属性标签代替目标标签,将相对属性标签与随机的噪声数据拼接作为图像域控制器的输入。图像域控制器根据不同的随机噪声生成图2 中的目标图像域样式信息w,并利用中间区残差网络块中的自适应实例归一化,将图像域控制器生成的样式信息和下采样提取的内容特征信息进行融合,以增加图像域表达方式的多样性。
图像域控制器结构由4层感知机网络组成,将c维随机高斯噪声数据和n维相对属性标签数据拼接后作为输入,n代表训练的属性个数,输出维度设定为残差网络深度的2 倍,m代表AdaIN 层数,整体结构参数设置如表2 所示。
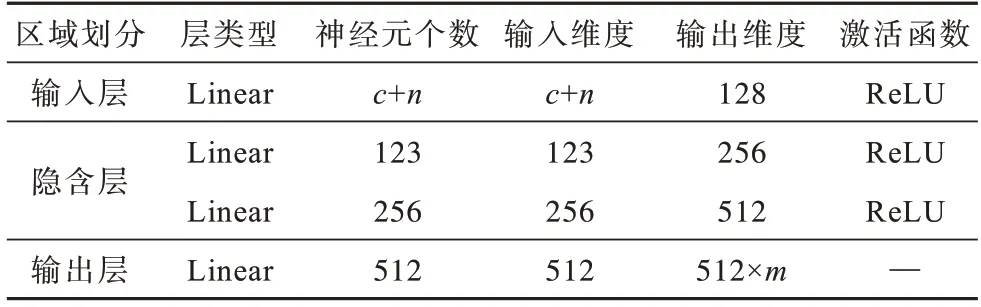
表2 图像域控制器的参数设置Table 2 Parameter settings of image domain controller
1.2.2 自适应实例归一化残差网络
为更好地融合图像域控制器生成的样式信息和迁移图像的内容信息,本文在生成器中采用多个自适应实例归一化(AdaIN)残差网络块组成中间区,将图像域控制器的输出作为残差网络块的输入样式信息,并利用AdaIN 融合图像内容特征信息和样式特征信息,以保留原图像内容信息的同时增加样式的多样性。
AdaIN[19]是基于IN 的改进,将图像内容信息与样式信息的均值和标准差对齐,从而更好地融合不同的图像域信息。x表示图像内容信息,y表示样式信息,AdaIN 的计算如式(1)~式(3)所示:
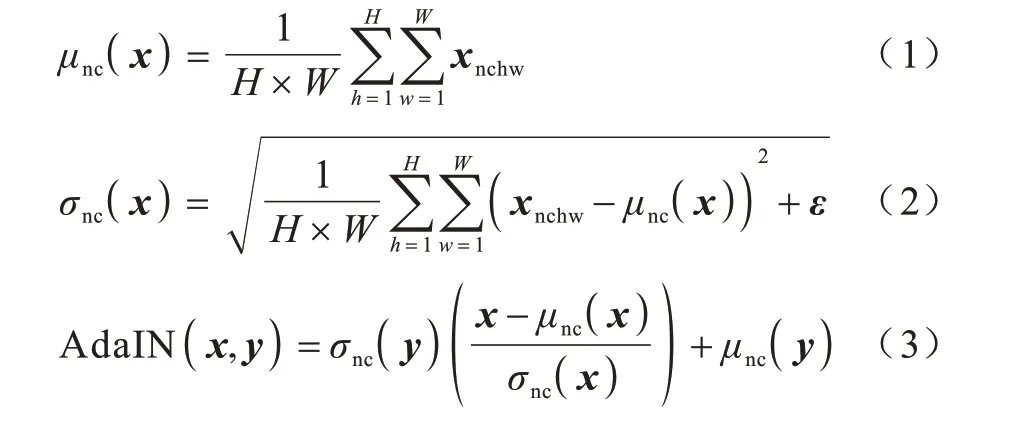
1.2.3 选择性传输单元
下采样的卷积操作仅通过跳跃连接将下采样提取的特征传输到上采样,难以有效地增加迁移图像域的细节特征信息。针对此问题,本文引入STU[15]将下采样提取的特征根据输入的相对属性标签选择性地传输到上采样,以形成融合特征,从而增加迁移图像域的细节信息,减少无关图像域的变化。STU是在GRU[17]基础上进行改进,结构如图3 所示。
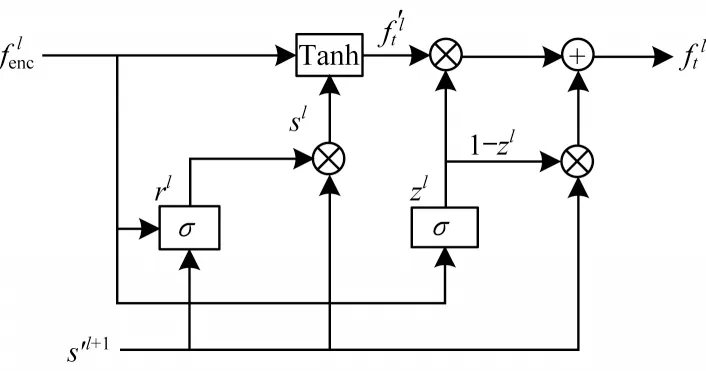
图3 选择性传输单元结构Fig.3 Structure of selective transfer units
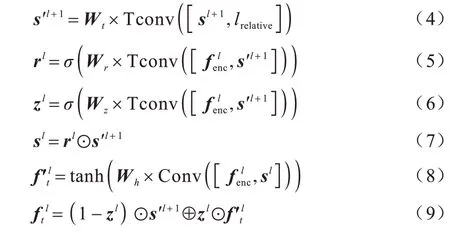
1.3 判别器模型
为建立明确的相对属性标签和迁移图像域之间的映射关系,本文在对输入图像真伪鉴别的基础上增加类别的判定,通过类别的分类损失引导生成器明确标签中每个位置上的数值信息与迁移目标图像域的对应关系,从而根据相对属性标签生成迁移的目标图像域。
在判别器结构设计中,判别器D1对尺寸为H×W的输入图像进行判别,判别器D2对平均池化后尺寸为H/2×W/2 的图像进行判别。双尺度判别的对抗损失和分类损失的计算如式(10)所示:

式(10)是通过协同鉴定图像真伪和类别,解决单一判别器判定准确度低的问题,双尺度判别器结构如图4 所示。判别器网络由真伪鉴定结构和图像域分类结构组成,共享0~2 层网络,在真假鉴别区采用PatchGAN[3]输出真伪信息,分类区输出分类信息,具体参数设置如表3 所示。

图4 双尺度判别器结构Fig.4 Structure of dual-scale discriminator
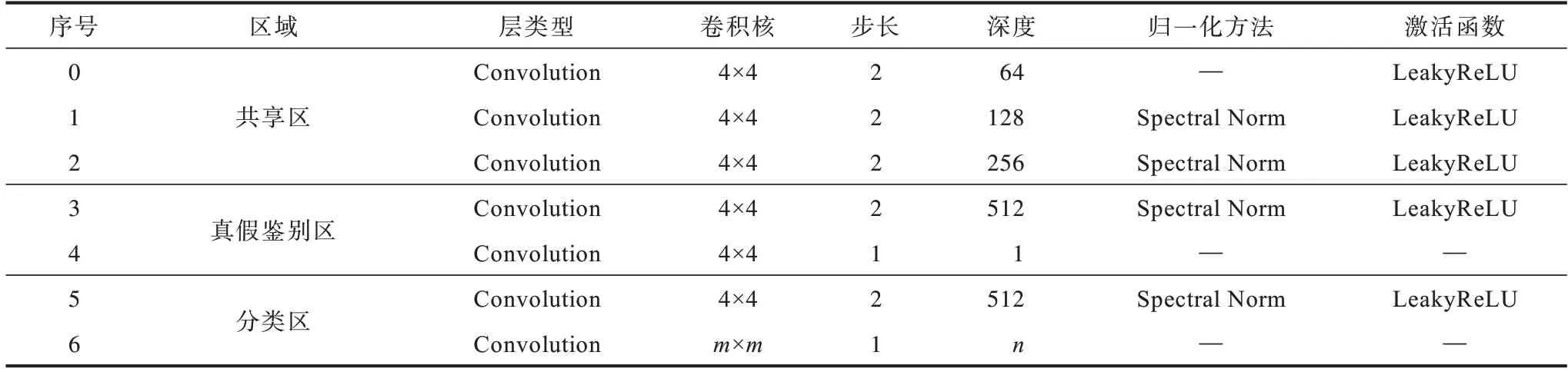
表3 具有多分类结构的判别器参数设置Table 3 Parameter settings of discriminator with multi-classification structure
从表3可以看出,除输入层和输出层以外,判别器模型均采用谱归一化(Spectral Normalization,SN)提高模型整体训练的稳定性。m为当前特征通道尺寸,如本文的输入图像尺寸为128,共享区网络有3 层,则m设置为8,n为输入图像的类别标签长度,如本文训练5 种属性,则n设置为5。
本文选择在不同权重比例超参数λ1=0.3λ2=0.7、λ1=0.4λ2=0.6 和λ1=0.5λ2=0.5 的双尺度判别器上进行实验,验证了λ1和λ2选择0.5 效果最优。
2 损失函数
本文所提的人脸属性迁移模型是基于STU 和铰链对抗损失,通过循环一致性约束确保输入图像和迁移图像内容特征的一致性,利用分类损失指导生成器建立属性标签与生成图像的关联;同时,将相对对抗损失与铰链损失相结合以关注整体样本间的差异,从而指导人脸属性的迁移,整体损失如式(11)所示:
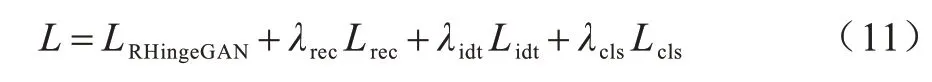
其中:LRHingeGAN为铰链对抗损失;重构损失由循环重构损失Lrec和自我重构损失Lidt两个部分组成;Lcls为属性标签分类损失;λrec、λidt和λcls分别为循环重构、自我重构和分类损失的权重比例超参数。
2.1 铰链对抗损失
GAN 的对抗损失是为了寻找在零和博弈状态下的纳什均衡解,在图像迁移任务中,即生成与原始真实图像分布相同的图像。文献[2]提出的原始GAN 中损失函数如式(12)所示:

其中:Pdata(x)为图像域X的样本分布;Pdata(z)为图像域Z的样本分布。当判别器D测量JS 散度的最小值时,由于其不具有输入数据一半是真一半是假的先验知识,会出现对所有的输入x均为D(x) ≈1 的情况,从而造成判别器难以同时依赖真实数据和生成数据,最终真实数据与生成数据的概率难以达到理想状态下的0.5,即难以找到真实的纳什均衡解。
针对原始生成对抗损失未能充分利用输入数据一半是真一半是假的先验知识,本文引入相对鉴别[20]的思想,采用相对真假代替绝对真假,增大生成数据为真的概率的同时减小真实数据为真的概率。在人脸属性迁移任务中,本文通过训练真伪图像之间的间隔边界以提高生成图像的真实性。因此,本文在真假二分类过程中利用铰链损失寻找不同分布间的最大间隔,以严格决策真伪图像间的最大间隔边界[21],进而关注所有样本间的差异性,从而提升判别器真伪鉴别的能力与生成图像的真实性和质量。最终,本文将相对鉴别与铰链损失相结合,得到判别器和生成器的对抗损失如式(13)所示:
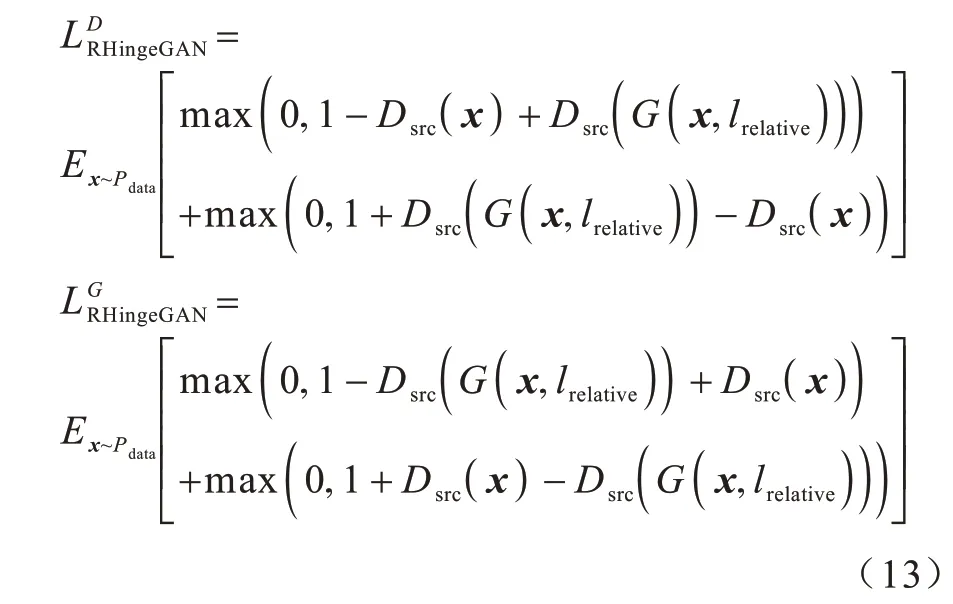
其中:x为 输入图 像;Pdata为真实 数据分 布;Dsrc为判别器D中的真伪鉴别结构;lrelative为相对属性标签;max()为取两者间最大值函数。
2.2 重构损失
本文的重构损失由循环重构和自我重构组成,通过增加自我重构以保证人脸属性迁移图像内容的一致性。
2.2.1 循环重构
在人脸属性迁移任务中,循环重构不仅保留原始图像的结构和内容等信息,同时还迁移指定的图像域,仅利用对抗损失无法保证生成图像与原图像结构和内容信息的一致性。为更好地建立相对属性标签和迁移图像间的映射关系,本文引入循环一致性条件约束,通过相对属性标签引导人脸属性迁移。首先原始图像a在相对属性标签lrelative的引导下,生成器G将原始图像迁移成目标图像b=G(a,lrelative);然后生成图像b在标签-lrelative的引导下,再次经过生成器G还原得到a的循环重构图像a'=G(b,-lrelative)。循环重构损失如式(14)所示:
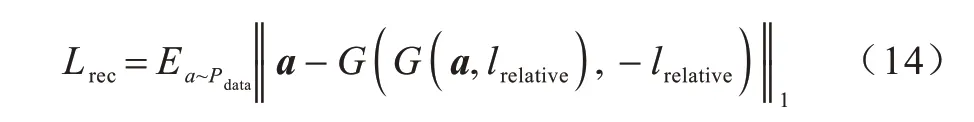
2.2.2 自我重构
为避免无关图像域在迁移过程中发生改变,本文引入自我重构一致性约束以降低无关图像域的变化。在自我重构过程中,对于任意的真实图像a,在无差异属性标签的引导下,a经过生成器重构成原图像a',减少无关图像域的变化。自我重构损失的计算如式(15)所示:
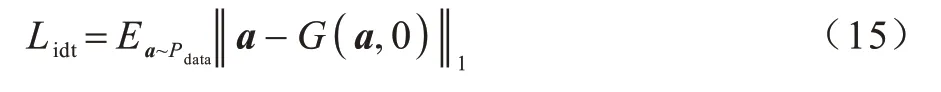
其中:0 为无差异属性标签。
2.3 分类损失
为保持原图像域和迁移图像域的一致性,本文设计分类损失以平衡输入标签与判别器输出类别之间的差异。本文通过相对属性标签指导图像迁移,以判定生成图像中每个迁移图像域特征的类别,从而加强相对属性标签和生成图像之间的联系,并完成目标图像域的迁移。为区分不同的目标图像域,本文采用多分类任务的交叉熵作为分类损失函数。判别器和生成器的分类损失如式(16)所示:
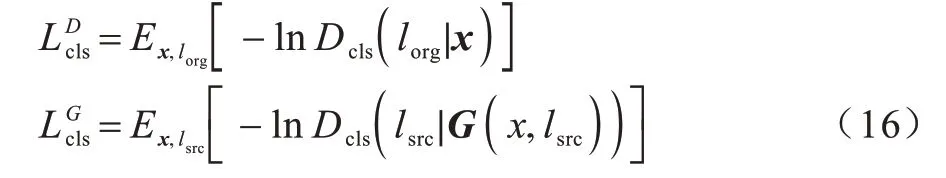
其中:x为输入图像;lorg为原始标签;lsrc为目标标签;Dcls为判别器D中的分类结构。
3 实验结果及分析
本文采用的数据集CelebA[22]由202 599 张人脸图片组成,总共10 177 个名人,每张图片有40 个二分属性标签。本文将数据集中原始大小为178×218 的图像裁剪成178×178,并重新调整大小为128×128,随机选择其中1 999 张作为测试数据集,其余200 600 张作为训练数据集。
在数据集上,本文通过选取发色(黑发、金发、棕发)、性别和年龄这5 种属性进行人脸属性迁移实验,并分别与采用标签训练的IcGAN、StarGAN 和STGAN 进行对比。本文选取发色(黑发、金发、棕发)、刘海和眼镜这5 种属性完成多样性效果实验。
3.1 实验环境与训练参数设置
本文实验CPU为40 Intel®Xeon®Silver 4210 CPU@2.20 GHz,31 GB;GPU 为NVIDIA GeForce RTX 2080 Ti,11 GB;操作系统为Ubuntu 18.04 LTS;开发环境为PyTorch 1.7.0,python 3.6.12,CUDA 10.0.130
在模型参数设置上,训练集的迭代批次batch_size设置为16,生成器中间区域残差块个数设置为6;采用TTUR[23]策略提高判别器的收敛速度,生成器和判别器的学习率分别设置为0.000 1和0.000 2;在权重选择上,循环重构超参数λrec和自我重构超参数λidt都设置为10,分类损失超参数λcls设置为1;在模型优化训练上,选取Adam 作为梯度下降算法,算法的一阶矩估计和二阶矩估计的指数衰减率参数分别设置为0.5 和0.999;选取70×70 的尺寸作为PatchGAN 判别区域的patch_size。具体实验训练参数设计如表4 所示。
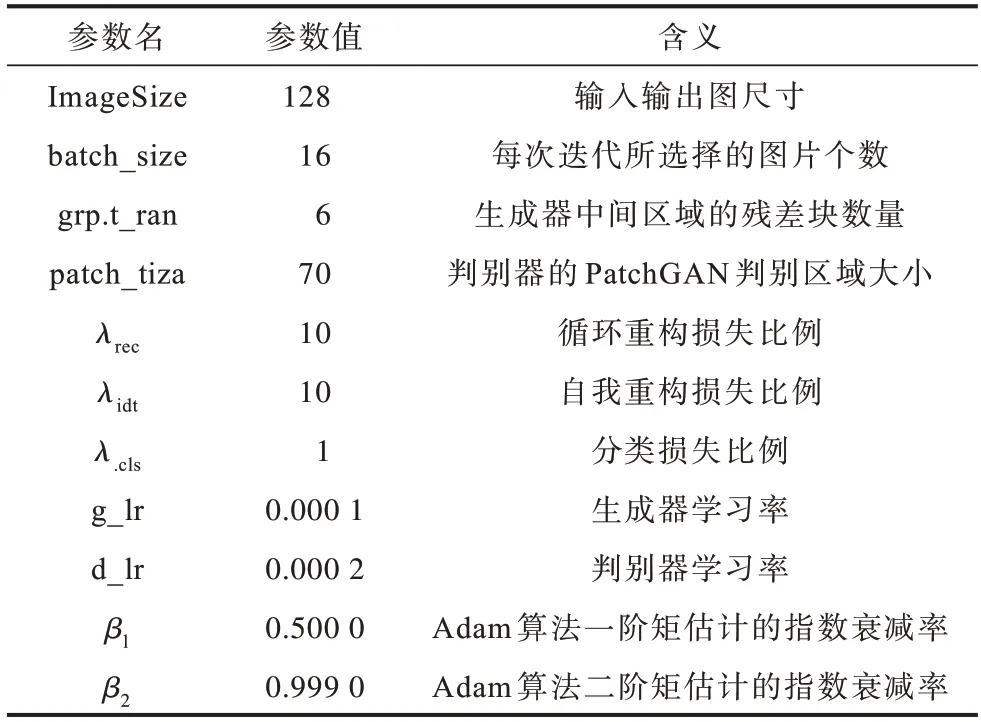
表4 训练参数设置Table 4 Training parameter settings
3.2 评价指标
本文采用分类准确率(CCA)、FID(Frechet Inception Distance)和用户调研评价(UUS)作为人脸属性迁移效果的评价指标。
1)分类准确率CCA能有效反映迁移图像域的准确性。本文利用图像分类模型对真实图像进行训练,将其得到的分类准确率作为基准值,然后根据训练好的模型对生成图像进行分类,将得到的分类准确率与基准值进行对比。准确率越高,越容易区分迁移图像的图像域,生成图像的效果越好。本文的分类模型选择Xception[24]网络,分类准确率如式(17)所示:

2)FID 能有效评估GAN 生成图像质量的指标,用于度量2 个图像数据集之间的相似性。本文通过将原始图像数据集和GAN 生成的图像数据集拟合到Inception[25]网络,由网络对所得到的两个高斯分布之间的弗雷谢距离进行计算。FID 数值越低,代表生成图像的真实性越高,迁移图像的效果越好。定义X1~N(μ1,σ1)为真实数据集X1的高斯分布,X2~(μ2,σ2)为生成数据集的高斯分布,FID 如式(18)所示:
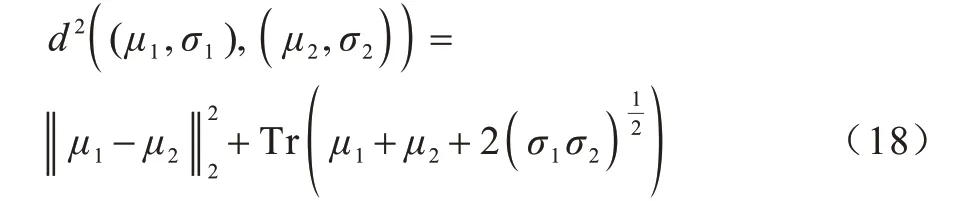
3)用户调研评价UUS能有效反映人眼对迁移图像质量的评估,是属性迁移常用的主观评价方法。从测试集随机选择M张图像输入到不同的模型,根据相同输入图像的输出图像分成M组。被评选为最佳效果图的次数越多,代表该模型的视觉效果越好,图像迁移质量越高。UUS如式(19)所示:

其中:n为被评为最佳效果图的次数
3.3 自适应实例归一化和选择性传输效果评估
为验证自适应实例归一化和选择性传输单元对迁移效果的影响,本文在CelebA 数据集上进行图像迁移实验。
3.3.1 铰链对抗损失和选择性传输单元效果评估
本文实验进行了160 000~200 000 次迭代,当迭代次数达到200 000 次时,模型处于完全收敛状态,故选择200 000 次作为模型最终的迭代训练次数。
为达到最优的迁移效果,本文选择双尺度判别并选取原始图像H×W和平均池化后的图像H/2×W/2作为判别器的输入。单尺度判别因缺少细节特征的判定,导致整体迁移图像略显失真。然而多尺度判别过于强调背景的细节特征,导致整体迁移图像的背景等无关图像域变化较为明显,双尺度判别能协同鉴定输入图像的真伪及类别,以提升图像细节特征的判定准确度,提高迁移图像的质量。
为验证铰链对抗损失和选择性传输单元融合的有效性,在相同实验环境下,不同条件的实验对比结果如图5 所示。

图5 不同条件下的实验结果对比Fig.5 Comparison of experimental results with different conditions
从图5 可以看出,第1 行采用铰链对抗损失和基本图像生成结构的迁移效果,第2 行采用原始对抗损失和选择性传输单元的迁移效果,第3 行融合铰链对抗损失和选择性传输单元的迁移效果。从第1行和第3行可以看出,通过增加选择性传输单元后,在图像域特征细节上的迁移效果更加明显,如第3 列转换金发属性时,融合铰链对抗损失和选择性传输单元的图像迁移效果中金发部分失真明显减少。当第5 列转变为女性时,融合铰链对抗损失和选择性传输单元的背景颜色更接近输入图像;第6 列在年龄增大后面部轮廓特征更加明显。从第2 行和第3 行可以看出,增加铰链对抗后的图像迁移效果能够有效减少无关图像域的转变,如在第2 列迁移黑发属性图像域中,人物的肤色更接近输入图像的肤色;第5 列转变为女性时,嘴唇的口红颜色更鲜艳以及面部轮廓也更加明显。第1 行和第3行的图像迁移结果表明选择性传输单元能改进图像的细节特征;第2 行和第3 行的图像表明铰链对抗损失减少了无关图像域的迁移。
本文在不同条件下计算生成图像FID的数值,如表5所示,加粗表示最优数据。从表5可以看出,与铰链对抗损失相比,采用铰链对抗损失+选择性传输单元得到迁移图像域的FID平均降低了0.652,即迁移的图像域更接近真实图像;与选择性传输单元相比,采用铰链对抗损失+选择性传输单元得到迁移图像域的FID平均降低了5.228。
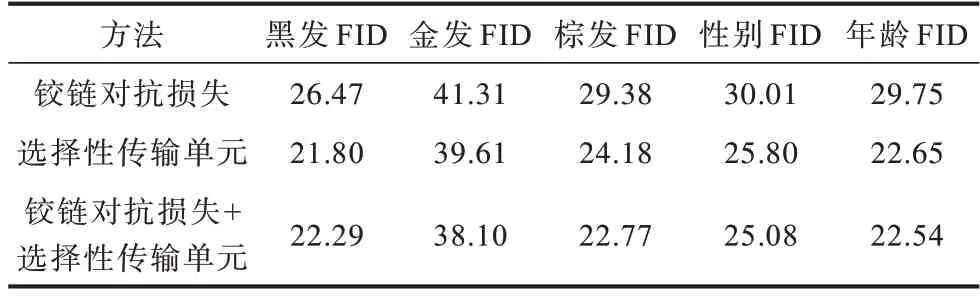
表5 在不同条件下FID 对比Table 5 FID comparison under different conditions
实验结果表明,铰链对抗损失可以充分利用输入数据一半是真一半是假的先验知识,从而提高迁移图像的真实性;选择性传输单元可以解决下采样的卷积操作存在图像细节信息缺失的问题。融合铰链对抗损失和选择性传输单元可以有效提高本文整体模型迁移图像的质量。
3.3.2 自适应实例归一化效果评估
为评估融合域控制器和AdaIN 残差网络增加迁移图像域表达方式的多样性效果,本文选取发色(黑发、金发、棕发)、眼镜和刘海属性作为训练的属性标签进行实验。在输入图像和相对属性标签不变的条件下,根据不同的随机噪声数据,输出迁移图像,从多组图像中选取具有代表性的输出图像。未采用AdaIN 和采用AdaIN 的实验结果对比如图6 所示。

图6 本文方法未采用AdaIN 和采用AdaIN 的实验结果对比Fig.6 Experimental results comparison of the proposed method with AdaIN and without AdaIN
从图6(a)可以看出,未采用AdaIN的图像迁移效果除发色变化之外,刘海比较稠密且向左下斜,镜片是颜色略深的方形,样式单一。从图6(b)可以看出,采用融合域控制器与AdaIN后,刘海弯曲形状的斜右下样式、略微稀疏的左下斜样式,镜片轮廓上有方形的和椭圆形的,且颜色上是黑色的、白色的,均呈现多种不同的样式。
为进一步验证刘海和眼镜迁移图像多样性的质量,本文计算相对应的FID 数值,如表6 所示。采用AdaIN 能有效提升眼镜和刘海多种表达方式的真实性。实验结果验证融合域控制器与AdaIN 的有效性,将不同的随机噪声输入到图像域控制器,能有效增加图像域样式的多样性。
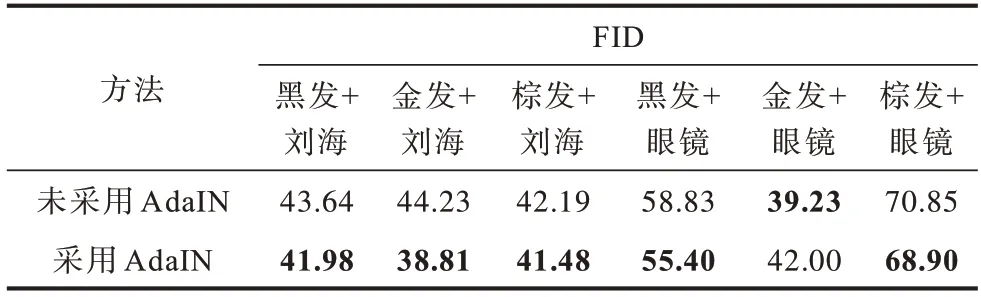
表6 本文方法未采用AdaIN 和采用AdaIN 的FID 对比Table 6 FID comparison of the proposed method with AdaIN and without AdaIN
综合以上的对比实验可以得出:铰链对抗损失通过训练真伪图像的间隔边界,可以更好地提高生成图像的真实性;选择性传输单元能有效降低下采样的卷积操作对图像分辨率的影响,提高图像迁移的细节信息;融合图像域控制器与AdaIN 可以实现图像域多样性的表达。
3.4 人脸属性迁移效果评估
本文的图像域属性迁移模型经一次训练后,既可以完成单个属性的图像域迁移,也可以同时完成多个属性的图像域迁移。为验证本文方法在单个属性迁移和多个属性同时迁移的有效性,在相同的实验环境下,本文选取发色(黑发、金发、棕发)、性别和年龄这5 种属性进行训练,与同样完成人脸属性迁移工作的IcGAN[9]、StarGAN[13]和STGAN[15]进行对比实验。
本文均复现原作者源代码进行对比:1)IcGAN,在CGAN 基础上融合Z 和Y 编码器完成多图像域迁移工作,引入标签完成多图像域迁移任务;2)StarGAN,经过一次训练即可完成多图像域迁移任务,通过循环一致性约束和分类损失完成多图像域迁移任务;3)STGAN,经过一次训练即可完成多图像域迁移任务,在生成器的输入中加入差分属性和选择性传输单元完成图像迁移任务。
3.4.1 单属性迁移
在经过一次训练完成的多图像域迁移模型中,本文分别改变输入图像单个目标图像域属性标签,以生成人脸属性迁移图像。本文选取具有代表性的生成图像进行单个属性迁移效果对比,如图7 所示。
从图7(a)可以看出,采用IcGAN 方法将发色迁移成黑发时,出现了明显的胡子,发型也发生了转变,整体图像失真严重;从图7(b)可以看出,采用StarGAN 方法将发色迁移成金发时,斜向左的刘海发丝略微失真且不自然,迁移成男性时,唇部颜色略显苍白,面部肤色也略显暗淡。从图7(c)和图7(d)可以看出,采用STGAN 和本文方法将发色迁移成黑发时,发色自然且发丝更加逼真;当增加图像中人物年龄时,迁移图像显示仅改变了脸上的皱纹。因此,IcGAN 迁移效果中整体图像细节模糊且背景变化大,StarGAN 迁移效果中部分细节不够真实,STGAN 和本文方法都较好地完成了属性的迁移,整体图像显得自然、真实,无关图像域变化小。

图7 不同方法的单个属性迁移效果对比Fig.7 Single attribute migration effects comparison among different methods
为体现实验的公正性,本文选择10 名研究生分别对5 种属性的迁移效果图进行评选,迁移效果图由30 组评价样本组成,每组评价样本由4 张相同的测试输入图像及4 种方法的迁移效果图构成,以得到10×30=300 组迁移效果对比主观评价结果。用户评选最佳图像标准如下:
1)图像质量,轮廓边缘、头发和五官等细节清晰,整体真实的迁移图像质量最佳。
2)无关图像域变化,其他无关图像域变化少,且符合目标图像域特征的迁移图像质量最佳。
用户调研数据从300 组用户问卷评估数据统计得到,每种方法在该对应属性迁移上所占的百分比如表7 所示,加粗表示最优数据。IcGAN 整体迁移图像效果较差。在金发、棕发和性别迁移图像评选中,STGAN 的迁移效果优于本文方法。在黑发和年龄迁移图像评选中,本文方法优于STGAN。因此,本文方法在迁移效果与生成图像质量方面相较于IcGAN 和StarGAN 均有提升,与STGAN 效果相当。

表7 单属性迁移的用户调研评价对比Table 7 Comparison of user survey evaluation of single attribute migration
为有效地评估本文方法,本文对这4 种方法输出图像的分类准确率进行对比,如表8 所示,加粗表示最优数据。本文方法比IcGAN、StarGAN 的分类准确率平均提高16.3 和2 个百分点,与STGAN 效果相当,均接近真实图像的分类准确率。
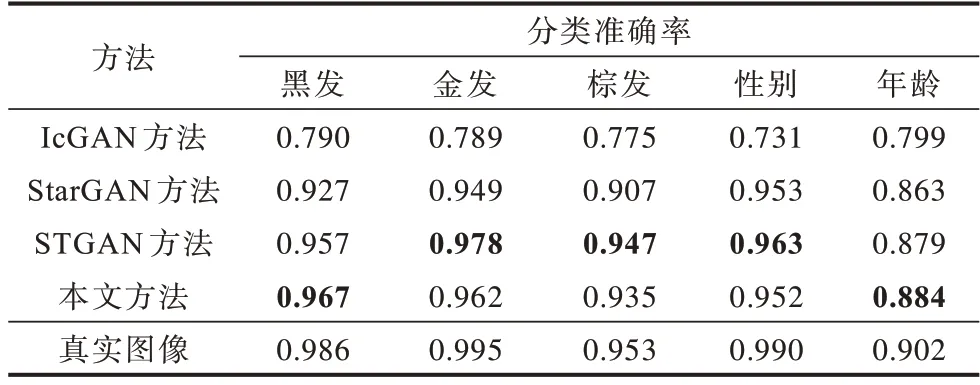
表8 不同方法单属性迁移的分类准确率对比Table 8 Classification accuracy comparison among different methods with single attribute migration
为评估这4 种方法输出图像的真实性,本文计算不同方法输出图像FID 的数值,对比结果如表9 所示。从表9 中可知,IcGAN 迁移图像的真实性较低,本文方法的迁移效果要优于StarGAN 和IcGAN,与STGAN 效果相当。
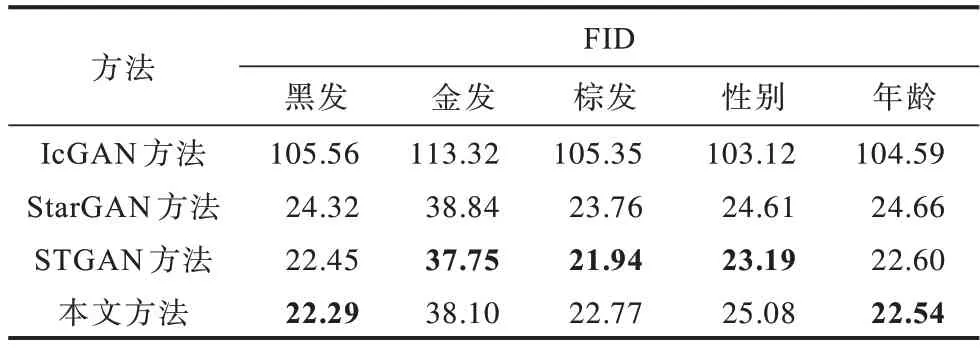
表9 不同方法单属性迁移的FID 对比Table 9 FID comparison among different methods with single attribute migration
3.4.2 多属性迁移
在经过一次训练完成的多图像域迁移模型中,本文分别改变输入图像2 个或者3 个目标图像域属性标签,以生成人脸属性迁移图像,选取具有代表性的输出图像进行对比,如图8 所示。
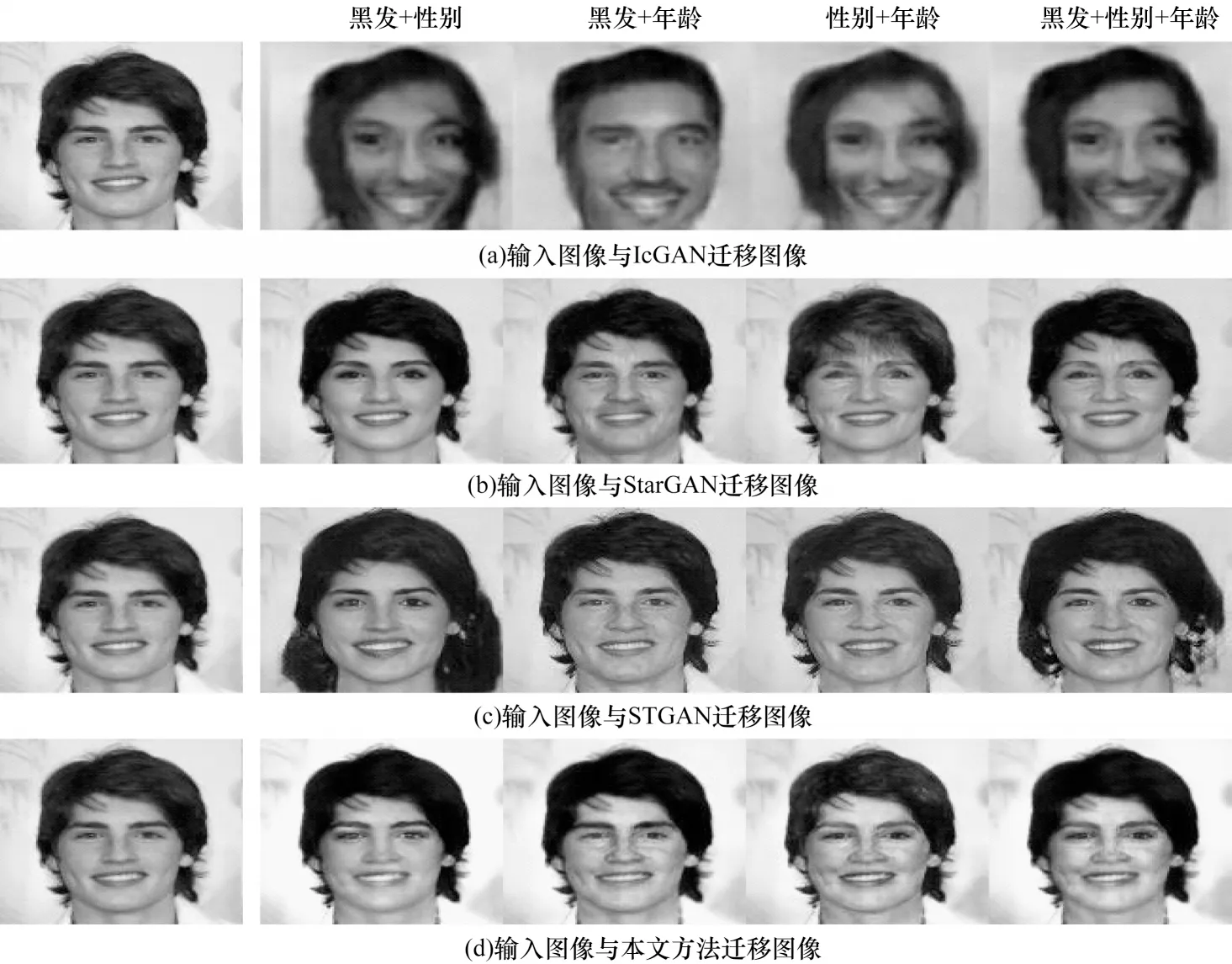
图8 不同方法的多属性迁移效果对比Fig.8 Muti-attribute migration effects comparison among different methods
从图8 可以看出:IcGAN 迁移的图像真实性低,无关图像域改变大;StarGAN、STGAN 和本文方法都较好地完成多个属性同时迁移的任务,但StarGAN 和STGAN 仍然有一些无关图像域发生了改变,当性别和年龄同时转变时,StarGAN 出现了较为明显的刘海;当黑发和性别同时转变时,STGAN迁移的发型显得不自然;本文方法整体迁移图像真实性更高,人脸肤色随着不同属性的迁移均发生相应的转变,随着年龄增大,目标图像域的特征更为明显;当性别和年龄同时迁移时,本文方法迁移图像中面部特征的细节清晰、自然,更接近真实图像。
为进一步验证本文方法多属性迁移的有效性,本文计算多个属性同时迁移FID 的数值,如表10 所示,加粗表示最优数据。从表中数据得知,在多个属性同时迁移的任务中,IcGAN 生成的迁移图像真实性较差,STGAN 生成的迁移图像要优于IcGAN 和StarGAN,本文方法生成的迁移图像质量最优。
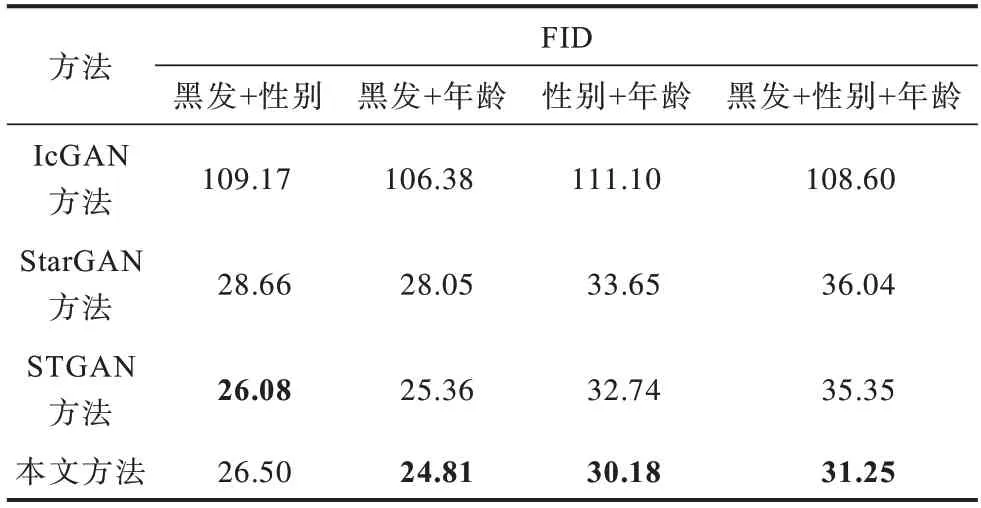
表10 不同方法多属性迁移的FID 对比Table 10 FID comparison among different methods with multi-attributes migration
在人脸属性迁移任务中单属性迁移与多属性迁移的主客观实验结果表明:相较于IcGAN、StarGAN,本文方法的单属性迁移图像效果能较好地保留人脸面部的细节特征信息,无关图像域改变较少,且迁移图像的真实性和质量与STGAN 效果相当;相较于IcGAN、StarGAN 和STGAN,本文方法的多属性迁移效果更优,能建立更加明确的多图像域映射关系。
4 结束语
本文提出一种选择性传输和铰链对抗的多图像域人脸属性迁移方法。通过引入域控制器和自适应实例归一化,增加生成的人脸属性样式多样性,同时利用选择性传输单元提高迁移图像的细节和质量,设计并融合相对鉴别与铰链损失的铰链对抗损失,以减少无关图像域的迁移。实验结果表明,与StarGAN、STGAN、IcGAN 方法相比,该方法迁移图像的质量更优,同时能有效增加迁移图像表达的多样性。下一步将对属性标签进行优化,以减少样式信息对属性标签的依赖,使本文模型适用于实际的应用场景。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
第一财经(2019年8期)2019-08-26
民用飞机设计与研究(2019年2期)2019-08-05
中南民族大学学报(自然科学版)(2019年1期)2019-04-04
北京汽车(2019年6期)2019-02-12
汽车电器(2018年10期)2018-11-01
动漫星空(2018年9期)2018-10-26
安徽医科大学学报(2015年9期)2015-12-16
CHIP新电脑(2014年5期)2014-05-14
