
基于改进YOLOv5s 的无人机图像实时目标检测
2022-04-15 09:17彭冬亮
光电工程 2022年3期
陈 旭,彭冬亮,谷 雨
杭州电子科技大学自动化学院,浙江 杭州 310018
1 引言
“无人机+行业应用”逐渐成为社会刚需,实现无人机图像的目标准确实时检测与跟踪是在安防巡警、农业防害、电力检修、物联网运输等领域广泛应用需要解决的核心问题之一。与通用目标检测不同,无人机视角图像小目标多且密集,不同类型目标间尺度差异大、背景复杂等特点[1]严重影响了目标检测的精度,而无人机图像的高分辨率特点对目标检测模型优化设计提出了挑战。
随着深度学习理论与技术的飞速发展,基于深度学习的通用目标检测性能取得了远超传统方法的性能[2-4],基于深度学习的通用目标检测算法可分为RCNN[2]系列双阶段算法和YOLO[3]、SSD[4]系列单阶段算法。单阶段检测器有着端到端的性能优势,但是在小目标定位识别上精度偏低。双阶段目标检测器以先定位后识别的方式,在精度方面优于单阶段,但实时性较差。
深度目标检测模型算法的训练需要大量的数据,目前主要的无人机图像目标检测数据集包括VisDrone[5]、UAVDT[6]等。VisDrone 无人机数据集由多架无人机倾斜俯视拍摄而成,涵盖了中国14 个城市景观,包含10000 张图像以及260 万标注信息,对于检测、跟踪任务而言仍然是一个难度较高的数据集。VisDrone 数据集中图片分辨率高达2000×1500,包含10 种目标类别,其中people 类和pedestrians 类极易混淆,图像的尺度、方向多样性、强度不均匀、退化严重等特点对算法设计提出了极大挑战。UAVDT无人机数据集是一个大规模的目标检测跟踪数据集,由100 个航拍视频、4 万张图片及其84.15 万标注信息组成,图片大小为1080×540,包含不同天气状况、飞行高度、摄像机视图和遮挡等14 种不同场景下的三类车辆图像,UAVDT 数据集中图像的背景复杂度高于VisDrone 数据集。
直接将通用目标检测算法应用于无人机图像目标检测时,由于无人机图像的上述特性,检测性能通常会有较大降低,因此研究学者进行了有针对性的改进,主要从优化双阶段检测网络、进行数据增强、优化无锚方法、优化轻量化网络等几个方面展开。
为充分利用双阶段网络在小目标检测上的优势,文献[7]针对提高IOU 训练阈值存在的问题,提出了一种级联指导IOU 重采样的网络结构Cascade RCNN,显著提升了小目标检测精度,但推理速度有所降低。基于无人机图像目标聚集的特点,文献[8]基于R-CNN 改进算法,提出了一种多阶段集群检测网络ClusDet。该网络使用区域聚类、切片检测、尺度适应的方法,提高了双阶段目标检测网络在高分辨率无人机图像上的运行速度与小目标检测率。Singh 等人[9]使用小目标缩放、均衡正负样本的训练策略,提高了双阶段R-CNN 的精度水平;文献[10]使用多方法联合增强的训练策略,解决了训练网络的过程中存在的尺度变化、目标稀疏、类别不均衡等问题,在不牺牲推理速度的情况下大幅提高精度。近年新兴的无锚网络十分适用于无人机图像小目标检测:Duan 等人提出的CenterNet[11]提出的视定位为检测中心点及其偏移的任务,使用预测焦点的方式进行回归,并从中心回归的偏移参数得到实际的位置信息,该方法有效增强了小目标的检出率,但高分辨率特征图也降低了算法实时性。从实时性角度出发,谷歌采用深度可分离卷积替换传统卷积,提出了MobileNet[12]骨干网络,大幅降低计算量,广泛应用在边缘设备上。随后也出现了大量轻量化网络:Pelee[13]、EfficientDet[14]、GhostNet[15]等。此外基于L1 正则化的模型剪枝、特征组之间的模型蒸馏加速方法也备受关注,提速效果明显,可兼容各种边缘设备,但是精度会出现较大损失。
结合无人机图像特点和单阶段YOLO 系列算法的实时性和准确性,本文充分利用YOLOv5s 的优势解决了其深度宽度不均衡、分类精度不足等问题,有效提高了无人机场景下小模型实时检测的精度,主要创新点包括以下几点:
1) 为解决无人机图像目标尺度差异大、小目标检测率低的问题,分析了深度模型中模型深度和宽度对于无人机图像检测的性能增益,提出了可显著提高感受野的混合残差空洞卷积模块,并结合无人机图像特点对YOLOv5s 模型进行改进,设计了YOLOv5sm模型;
2) 为进一步优化改进模型的实时性与识别率,设计了一种基于目标局部部件特征信息的注意力机制,提出了一种跨阶段注意力特征融合模块SCAM;
3) 考虑到目标检测任务中位置回归与分类任务之间的矛盾,通过对YOLO 检测头进行改进,单独对分类分支进行特征后处理,实现位置回归与分类任务的隔离解耦;
4) 最后采用VisDrone 和DIOR[16]数据集验证了提出算法的有效性与适用性。
2 基于YOLOv5s 改进算法
2.1 YOLOv5s 基准算法
基于全卷积的单阶段YOLO 目标检测算法,以其简洁、快速、易部署的优点,被广泛应用于工业领域的目标检测、跟踪、分割,其中YOLOv5s 十分适用于无人机场景实时目标检测。与其他检测算法相比,YOLOv5s 有着如下特点。
2.1.1 骨干网络
采用CSPDarkNet53 表征学习,在检测性能上优于ResNet 基准算法。其深度、宽度均衡化的特性兼容了不同设备、数据集。残差网络避免了深度网络学习中的梯度消失的问题,以及CSPNet[17](cross stage partial network)在不丢失模型精度的条件下,加速推理44%。在最后一个尺度的表征学习前添加SPP[18],极大提高感受野,提高大目标检出率和平移鲁棒性。
2.1.2 特征融合
沿用特征金字塔网络 (feature pyramid network,FPN)[19]辅以PANet[20]多尺度特征融合策略,如图2所示,在不同特征层输出检测结果,提高了各尺度目标的检出率与定位、识别精度。结合CSPNet 融合特征,优化特征融合速度。
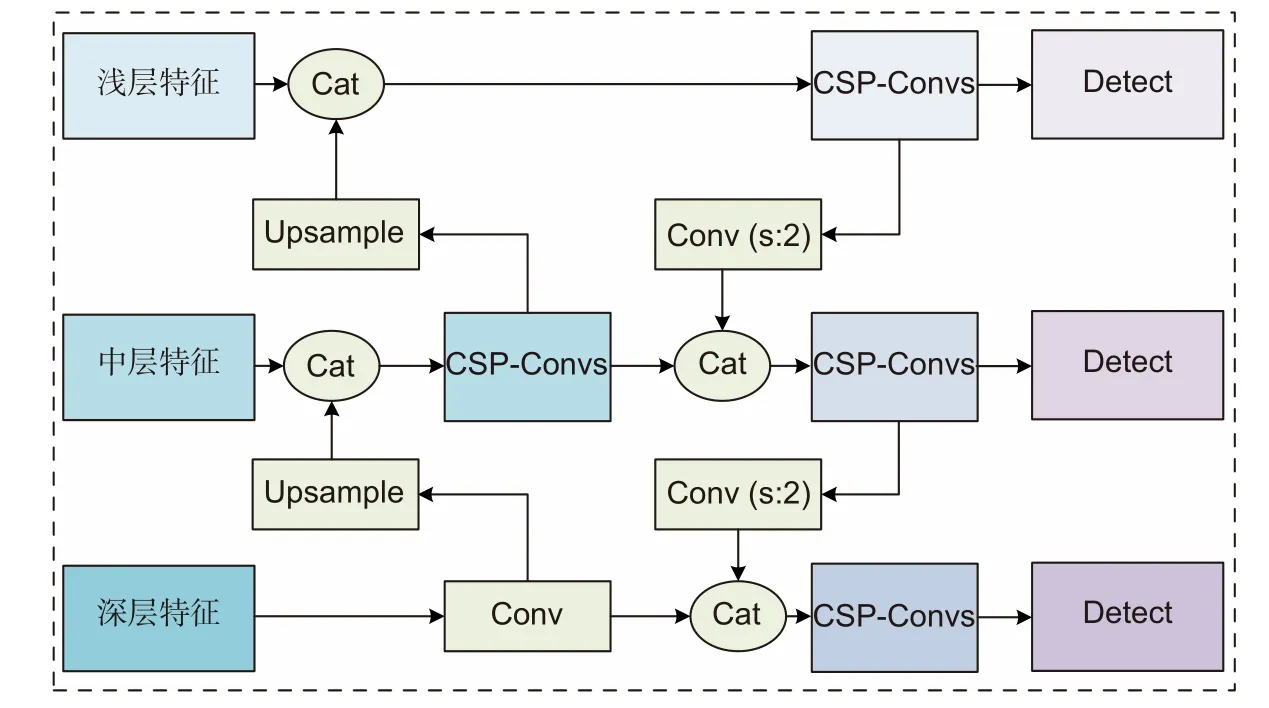
图2 特征融合模块结构图Fig.2 Structure diagram of feature fusion module
2.1.3 其他特性
采取一系列数据增强方法,并沿用目标检测算法中的先验框思想,在目标数据集上主动学习得到预设先验框,使得目标定位更加精确,训练更加快速稳定。
2.2 YOLOv5sm+算法
尽管YOLOv5s 性能优异,在无人机场景上有巨大优势,但是精度上相较YOLOv4[21]、EfficientDet 等一流模型差距较大,故本文从骨干网络、特征融合、检测头三个方面改进YOLOv5s,提出了一个均衡化的实时检测算法YOLOv5sm+,力图保持运行速度的同时提高检测精度。
2.2.1 YOLOv5sm 骨干网络
深度卷积通过不断叠加卷积模块来提高检测精度,但是无人机图像小目标众多,分辨率高,一味增加深度将严重降低算法实时性,给深度网络带来难以承受的推理、后处理计算成本,而且难以在硬件中实际部署。而YOLOv5s 模型低级特征映射少、感受野小,导致各大目标的召回率、精度偏低,故需针对无人机图像对网络进行调整。
深度网络可以映射更深层次的语义信息,这对分类有益,却不利于回归,回归框的优劣极大影响样本判定,即召回率,进而影响整体精度。宽度网络不但可以保存更多的历史信息,降低神经网络的灾难性遗忘,而且可以映射更细微的特征信息,即相似特征之间微弱的差异、偏移。这些对于无人机图像定位、识别来说尤为重要。
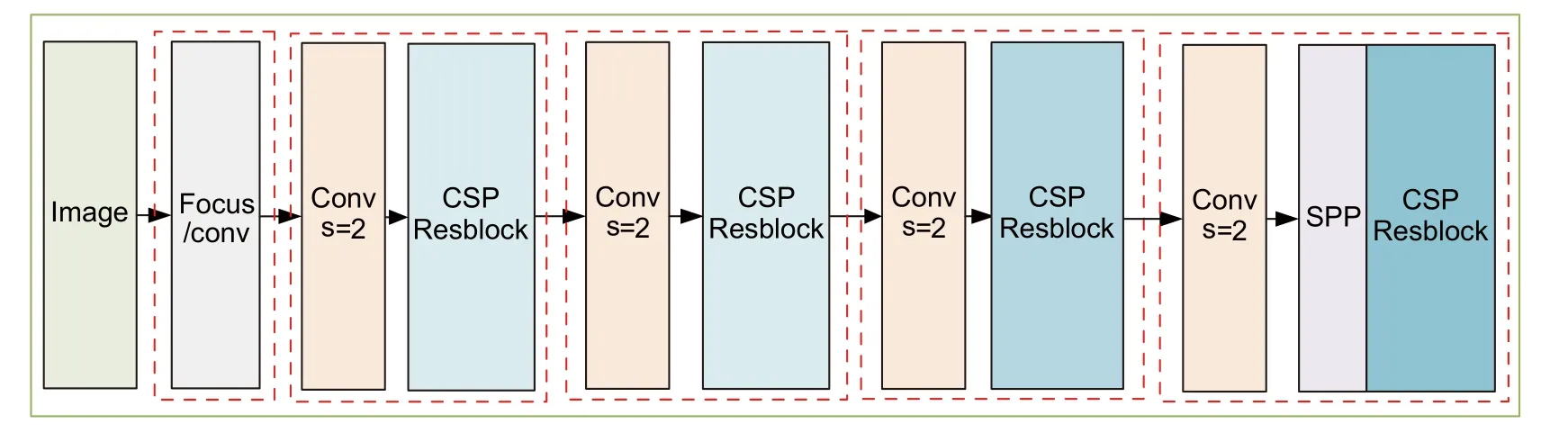
图1 YOLOv5 骨干网络架构图Fig.1 YOLOv5 backbone network architecture diagram
基于以上分析,本文对YOLOv5s 增宽50%以增加模型容量,去除Focus 模块降低对小目标定位的影响,由于低层特征提取模块内部仅有32 维特征,故替换为残差块以增加低层内部特征的容量、信息。为了解决低层特征感受野较小的问题,本文提出了混合残差空洞卷积模块(Res-DConv),如图3 (a),通过有效提高感受野来增强背景信息对回归、分类的指导,并避免降低局部细节信息损失,提高回归的精度。如图3 (b),该模块(空洞率为3)等价于四层普通卷积的感受野,即可以一半的计算量实现相同深度。最终提出YOLOv5sm 轻量化骨干网络,具体架构如表1 所示。

表1 感受野分析表Table 1 Receptive field analysis table
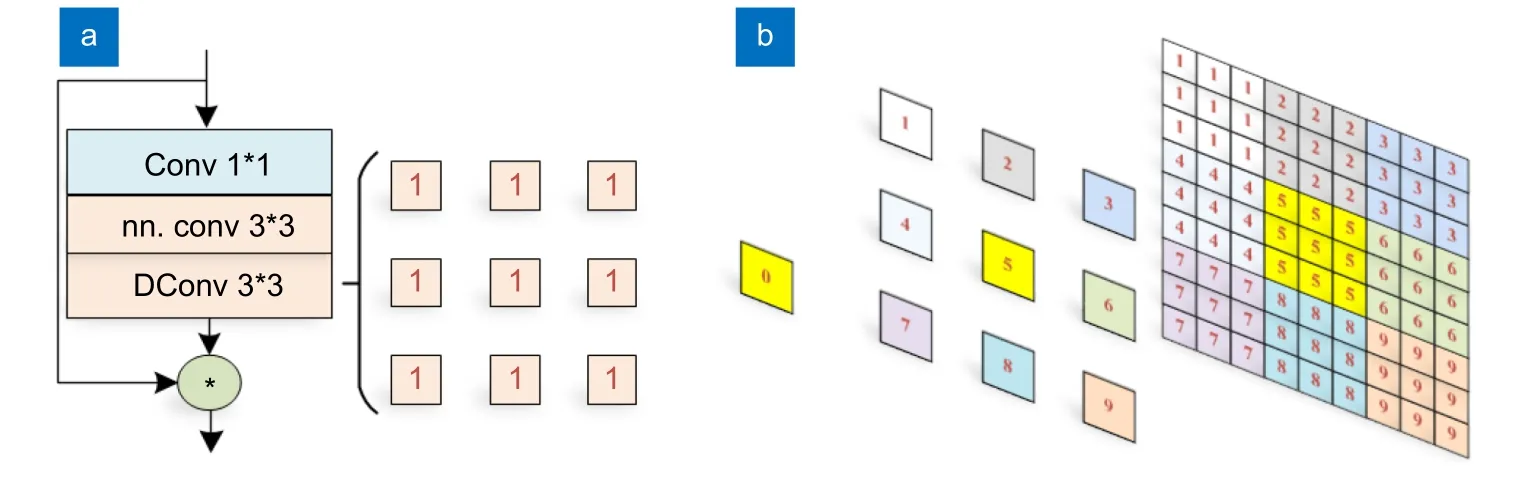
图3 (a) Res-DConv 模块;(b) 感受野映射Fig.3 (a) Res-DConv module;(b) Receptive field mapping
其次考虑到锚的尺寸需受到特征感受野、下采样次数的约束。首先根据实际数据集中目标的长宽分布,采用K-Means 聚类确定预设先验框的大致范围,再根据表2 中的框预设值范围对先验框进行归类。基于YOLO 系列模型,VisDrone 数据集的预设锚点要参考实际目标出现频次、长宽先验信息与模型预测输出的最值进行判断取舍。采用契合数据集的超参数设置方法,将三个预设框增加为四个,可增加硬件设备兼容性,提高训练速度,也可细分样本的尺度变化,增大锚与真实样本框的拟合度,提升训练样本召回率,利于检测框的回归,提升小目标的检测精度。

表2 呼应感受野、下采样的锚点预设置Table 2 Pre-setting anchors in response to the receptive field and down-sampling
2.2.2 SCAM 特征融合模块
为了保持小目标分类性能的同时平衡计算成本和物体尺度的方差、强化大目标的识别精度,受基于部件的细粒度目标分类[22]、注意力机制[23]启发,本文提出了SCAM 特征融合模块,其主要思想是基于低分辨率特征图的空间注意力对高分辨率特征图进行加权筛选,用以增强目标的部件特征,提高特征利用率,增强检测器的分类性能。本文称之为跨阶段注意力模块(stage crossed attention module,SCAM)。
本SCAM 模块可取代下采样模块:首先低分辨率特征经过最大池化和均值池化,连接后经过混合空洞卷积后得到注意力掩码图像Mask;然后对高分辨率特征按照尺度转通道进行处理(下转换)结合Mask掩码对高分辨率特征进行加权,后经过通道注意力[24]调整通道得到待融合特征;最后将高阶特征与处理后的低阶特征按维度级联融合得到融合特征。具体模块结构如图4 中SCAM 模块所示。

图4 改进模块结构Fig.4 Improved module structure
2.2.3 SDCM 检测头解耦模块
目标检测中分类和回归的矛盾本质上是卷积的平移、尺度的不变性和恒等性之间的矛盾。分类任务希望目标状态经平移、旋转、光照和尺度改变后,类别信息不变,即平移和尺度的不变性,而对于回归任务,需要目标的状态变化皆反映在特征上,进而回归出准确位置,即平移和尺度的恒等性。基于Retina-Net[24]、Double-Head R-CNN[25]等文献对检测头解耦的做法,本文提出SDCM(split de-couped module)模块,可分阶段地执行不同的任务,防止特征共用,第一阶段完成回归任务,第二阶段借助跨阶段卷积模块协助完成分类任务,从而缓解了这种互斥矛盾,提高了细类别的分类精度。
2.2.4 YOLOv5sm+模型架构
混合残差空洞卷积的高感受野和高维特征,降低了实际所需的卷积层数,使得低层特征具有较大感受野的同时包含较多的细节信息,辅以SCAM 特征融合模块和SDCM 检测头,用以提高检测速度与定位识别精度,改进模型并称之为YOLOv5sm+,和YOLOv5 相似,该模型有着四种不同的容量大小,以匹配不同设备、数据集。尤其在无人机场景中,性能优异的轻量化的模型结构十分重要。
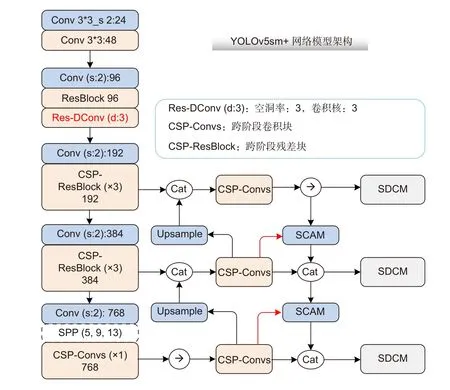
图5 YOLOv5sm+模型架构Fig.5 YOLOv5sm+model architecture
3 实验设计
3.1 实验准备
3.1.1 数据处理
本文选取VisDrone2019-DET 数据集进行实验,训练、验证数据集均以步长为600,切分为800×800的图像,其中训练数据集有样本25447 张图片及其标注,验证集样本1115 张图像及其标注信息,测试集为547 张验证集原图。
经过数值统计分析,由表3、图6 可知,VisDrone数据集类别分布不均衡、小目标众多、大目标稀少,部分类间方差较小,类别混淆严重,是一个极具挑战性的数据集。

图6 (a) VisDrone 数据集类别实例总计;(b) YOLOv5m 算法下的类混淆矩阵Fig.6 (a) Total number of category instances on the VisDrone dataset;(b) Classes confusion matrix of YOLOv5m algorithm

表3 不同类型目标数量统计Table 3 Statistics of different types of objects
3.1.2 实验设置
实验中采用的服务器配置如下:Intel(R) i7-6850K的CPU,64 G 内存,NVIDIA GeForce GTX 3090 图形处理器,Ubuntu 18.04 操作系统。
所有模型训练使用双卡分布式混合精度训练,并使用单卡单批次方式进行测试。实验代码基于ultralytics 的YOLOv5 工程第四个版本和yolov3-archive 工程融合改进,同时支持yaml 模型文件和cfg 模型文件,所有算法皆为官方模型在本工程的迁移实现。训练轮次(epoch)初始为200,批大小为16;采用SGD 梯度下降优化器,初始学习率0.01,动量为0.949,采用one-cycle 学习率衰减,其它为默认设置。
3.2 评价指标
为了准确评估深度模型在无人机空域图像上的检测性能,本文采用检测算法评估公认度最高的平均精度均值(mean average precision,mAP),即数据集中各类精度的平均值。每个类别根据准确率和召回率可绘制一条曲线,该曲线与坐标轴的面积则为AP 值。其中准确率(precision,P)、召回率(recall,R)定义如下。其中TP为真正例,FP为假正例,FN为假反例。
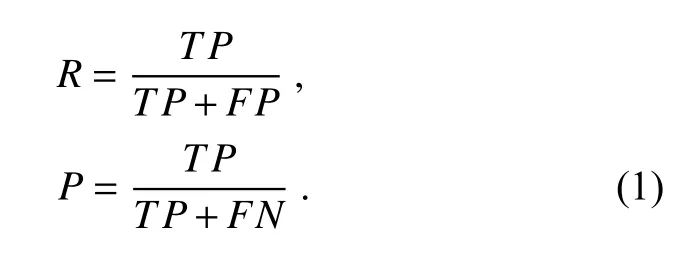
实验中采用COCO 评价标准[26],使用pycocotools工具对检测结果进行评估分析。当检测框与真值的交并比(intersection over union,IOU)大于0.5 认为该目标被准确预测,分别在IOU 取值为0.5、0.75、0.5:0.95条件下的计算总类别的平均精度(mAP50,mAP75,mAP),并且在IOU 为0.5 的条件下分别统计大、中、小三种尺度目标的平均精度(AP-large,AP-mid,APsmall)。模型实时性评估采用单张图片的平均推理时间。
4 数据分析
4.1 消融实验
4.1.1 目标检测模型中深度和宽度对检测精度影响实验分析
首先本文探索了深度和宽度对VisDrone 数据集算法精度的增幅,为了保证对比模型的计算量、参数量一致,模型设置如下:1) 深度为1.33、宽度为0.5的深度模型;2) 深度为0.33、宽度为0.75 的宽度模型;3) 深度为0.33,宽度为0.5 的基准模型YOLOv5s。实验使用处理后的训练集以及相同的默认参数进行训练,在800×800 的裁剪后的验证数据集上进行单尺度测试,评价模型的表征能力。由表4 实验结果可知:1) YOLOv5s 的模型容量不足以容纳VisDrone 数据集的知识总量;2) 在VisDrone 无人机数据集上,相比深度网络模型,宽度网络模型对精度提升增益更大。

表4 深度、宽度模型性能对比实验结果Table 4 Performance comparison experiment results of depth and width models
为了验证混合残差空洞卷积模块的有效性,设置实验如下,模型分别为YOLOv5s 和更改残差块为Res-Dconv 的YOLOv5s+Res-Dconv 模型,实验条件同上。由表5 实验结果可知,在VisDrone 数据集上,相较原始YOLOv5s 模型,改进模型平均精度提升1.4%,验证了本模块可增大感受野,缩减网络深度,进而提高性能。

表5 Res-Dconv 模块验证实验结果Table 5 Verification experiment results on Res-Dconv module
鉴于以上实验,本文提出了YOLOv5sm 骨干网络,并与官方s、m 模型进行对比实验,在1536×1536 的图片分辨率下测试各项指标,如表6 的1、2行所示,在s 模型基准下,改进骨干的mAP50 提高了4.1 个百分点,优于s 模型的0.548,验证了改进模型在无人机图像上具有可行性。
4.1.2 特征融合SCAM 模块对比实验
为验证SCAM 模块的有效性,本文以YOLOv5s为基准模型,并以SCAM 模块替换下采样特征融合模块进行对比实验,实验参数默认,使用单尺度训练,在1536×1536 分辨率下进行测试,由表6 第1、3 行可知,相较于YOLOv5s 基准模型,SCAM 模块提升mAP50 近0.7%,且目标越大,提升越明显,同时参数量和推理时间也低于基准模型。
4.1.3 SDCM 检测头解耦模块对比实验
为验证SDCM 模块的可行性,本文仍然以YOLOv5s 为基准模型,在此基础之上加入SDCM 模块进行对比实验。SDCM 模块可直接替换YOLOv5s的检测头结构,实验条件同上,通过比较表6 中的第1、4 行,得出SDCM 模块在轻量级s 模型基础上将性能指标mAP 提升1.4%,也验证了对于回归、分类解耦的可行性。
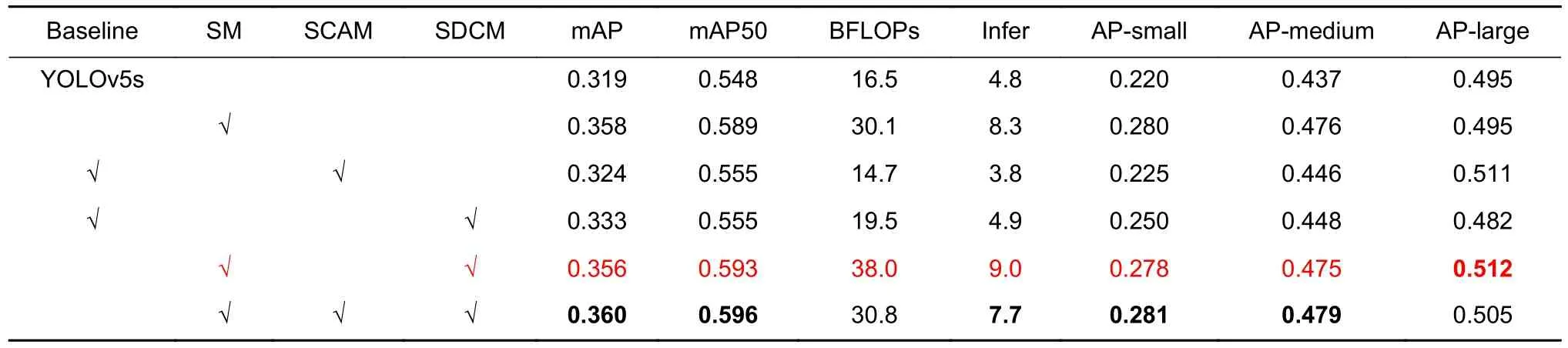
表6 本文算法模块在VisDrone 数据集上的消融实验结果Table 6 The ablation experiment results of our algorithm modules on the VisDrone dataset
4.2 VisDrone 数据集检测结果
为了验证本文方法的有效性,本文以YOLOv5s模型作为基准算法,然后以Scaled-YOLOv4[27]、YOLOv3[28]探索精度水平,MobileNetv3[29]探索速度基准,MobileViT[30]试验Transformer 算法的性能表现,YOLOX[31]试验无锚检测算法在VisDrone 数据集上的性能表现。实验结果如表7 所示。

表7 不同算法在VisDrone 数据集上的检测性能Table 7 Detection performance of different algorithms on VisDrone dataset
对比发现,在1536×1536 分辨率下,基准算法YOLOv5s 的mAP50 精度为54.8%,实时性最好;Scaled-YOLOv4 精度最高、YOLOv3 次之,同时模型复杂度最高,推理时间达不到无人机平台算法实时性的要求;对于轻量级网络MobileNetv3 来说,精度优于YOLOv5s 模型,但是速度上次于YOLOv5s;基于注意力的Transformer 轻量级网络性能上并不占优势;无锚检测器YOLOX 的精度最低,即在轻量骨干网络下,无锚检测器回归精度低,性能较差。
YOLOv5sm+模型较基准模型mAP50 高5.6%,优于m 模型且推理速度提升21.4%,也验证了改进算法在无人机数据集上的有效性。由图7 可知,本文YOLOv5sm+模型在远景小目标的检出率优于s 和m模型,由图8 可知,在重叠度高的目标集群中,本文算法可以更准确的检测出实际的目标,虚警低于对比模型。

图7 不同算法在VisDrone 无人机场景下的检测实例。(a) YOLOv5m 模型;(b) YOLOv5sm+模型;(c) YOLOv5s 模型Fig.7 The detection examples of different algorithms in the VisDrone UAV scene.(a) YOLOv5m model;(b) YOLOv5sm+model;(c) YOLOv5s model

图8 三种算法在密集车辆场景的检测结果对比图。(a) YOLOv5m;(b) YOLOv5s;(c) YOLOv5sm+Fig.8 Comparison of the detection effects of three algorithms in dense vehicle scenes.(a) YOLOv5m;(b) YOLOv5s;(c) YOLOv5sm+
4.3 DIOR 数据集迁移实验
为了充分验证本文方法有效性和鲁棒性,本文在DIOR 遥感数据集上进行了对比验证。该数据集是西北工业大学于2019 年发布了一个大规模的空域遥感数据集,数据集在不同成像条件、天气和季节下采集而成,覆盖20 个目标类别,类间相似、类内多样,尺度差异性大,背景复杂,适合迁移验证本文算法有效性。训练参数按照默认实施,使用多尺度训练模型200 个轮次。DIOR 数据集使用官方的数据划分,分为5876 张训练集,876 张验证集,14885 张测试集,采用默认超参数设置。
实验结果如表8 所示,在20 类的DIOR 遥感数据集上,相对于YOLOv5s 模型,改进模型检测精度提升近4.2%,达到了66.7%,优于Faster R-CNN 两阶段算法。由如图9 中的部分检测实例可知,本模型在虚警率、密集目标分辨率上表现优于YOLOv5s 模型。实验表明,本文算法对于小目标众多、尺度差异大、目标重叠度的数据集可以实现较好的鲁棒性。

图9 改进算法在DIOR 数据集的检测对比。(a) YOLOv5s;(b) YOLOv5sm+Fig.9 Detection comparison of improved algorithm in DIOR dataset.(a) YOLOv5s;(b) YOLOv5sm+

表8 不同算法在DIOR 数据集上的检测性能Table 8 Detection performance of different algorithms on DIOR dataset
5 结论
本文以无人机监视场景为背景,分析了VisDrone无人机视角数据集的目标分布规律。首先探索了在UAV 数据集上深度和宽度对YOLOv5 模型的精度增幅,实验结果表明,在无人机数据集上,虽然深度模型的深层语义提高了模型精度,但是由于内部特征匮乏,深度模型性能差于宽度模型,主要影响精度水平的是内部特征映射量。基于混合残差空洞卷积模块,提出了一种均衡化的实时目标检测模型YOLOv5sm,精度高于YOLOv5s 模型4.1 个百分点。SCAM 特征融合模块提高了特征空间利用率和特征融合速度,进一步提升了检测精度。在VisDrone 数据集上的结果表明,目标尺度越大,精度提升越明显。最后基于解耦的思想改进检测头结构,进一步提升了精度水平。通过与Scaled-YOLOv4、MobileNetv3 轻量化网络、MobileViT 注意力网络、YOLOX 无锚检测器对比可知,改进模型可显著提高模型精度,验证集mAP50高达60.6%,优于m 模型且速度提升21.4%,基本满足无人机边缘设备上的性能、精度要求。在DIOR 数据集上的迁移实验表明,改进模型相较于YOLOv5s基准模型,mAP50 提升4.2%,验证了算法的有效性和鲁棒性。虽然改进模型的精度、速度在VisDrone数据集上较为可观,但后期工作仍需关注召回对目标的精度影响以及在无人机并行设备上的实际测试部署工作。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
快乐学习报·教育周刊(2022年16期)2022-05-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
一重技术(2021年5期)2022-01-18
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
