
基于特征迁移的永磁同步电机性能预测
2022-04-13 05:13:46金亮杨柳王艳阳
电机与控制学报 2022年3期
金亮, 杨柳, 王艳阳
(1.河北工业大学 省部共建电工装备可靠性与智能化国家重点实验室,天津 300130; 2.天津工业大学 天津市电工电能新技术重点实验室,天津 300387)
0 引 言
永磁同步电机具有体积小、结构简单、高效节能、功率密度高等优点,广泛应用于航空航天、轨道交通、电动汽车等领域[1-2],因此电机性能分析与优化一直是国内外研究的热点。随着应用环境日趋严苛和极限性能的提升,应综合考虑设计目标性能、材料、能源、造价、工艺和应用环境等多方面的要求,电机性能分析与优化逐步演变为一个数据量大、特征维数高、映射关系复杂的问题。
电机设计参数与性能数据的映射关系,是性能分析与优化的基础和重点。由于电机结构复杂、材料多样、工况复杂,多采用数值模拟方法实现对电机性能的精确计算[3-4]。如,通过数值模拟方法和优化算法优化电机的电枢槽口宽度[5]、转子斜极[6]、分数槽绕组[7]和定子开槽[8]等结构。考虑到数值模拟计算耗时长、所需计算资源多,一般先通过数值模拟方法得到电机设计参数与性能数据的样本数据,并用样本数据训练机器学习算法建立设计参数与性能数据的映射(也称作代理模型),完成电机性能分析或优化[9]。可以通过Kriging模型[10]、径向基函数[11]、支持向量回归[12]模型等方式建立代理模型。代理模型代替数值模型参与优化,可以在很大程度上减少仿真次数、节约时间和计算成本[13-14]。随着机器学习的发展,研究者们将BP神经网络[15]、决策树[16](decision tree,DT)、径向基函数神经网络[17-18](radial basis function,RBF)和支持向量机(support vector machine,SVM)等浅层机器学习方法应用到电机优化设计中。
浅层机器学习方法受限于信息处理能力,在有限样本情况下对复杂函数的表达能力有限[19],往往导致算法性能提升困难、鲁棒性差、泛化能力弱等严重问题,在高维数据中此问题更加凸显[20-22]。深度学习可自动学习数据的深层和抽象特征,并在输出层实现预测或回归[23-24]。近年来,研究者们将深度学习应用到复杂电机的性能分析与优化中[26-29],有效提高了对高维数据的拟合和泛化能力[30]。
传统机器学习和深度学习方法都需要大量带标注结果的样本,而且测试集或验证集的数据必须和训练集有着相同的分布[31]。但实际情况是,较易获得的数据是历史积累的不同电机的标签数据(通过数值模拟或实验得到的性能数据)以及目标电机的设计参数。仅使用历史电机数据,由于目标电机与历史电机数据分布的差异,导致用于性能预测的机器学习模型精确度差、鲁棒性差;对目标电机数据集进行标注,存在计算耗时长和所需计算资源多的问题[32]。
因此,提出一种智能自学习新方法,尝试从历史电机数据中学习知识和特征,并迁移应用到目标电机性能预测中,使用极少量甚至不使用新电机样本数据,实现目标电机设计参数与性能数据的映射。主要思路为提出一种基于特征迁移[33-34]的智能自学习电机性能预测方法,使得数据特征空间分布不同的电机数据也可以使用相同模型进行预测。自学习方法主要思想为:
1)将源域和目标域数据进行特征转换,提取特征到同一公共空间。回归器对提取的特征进行预测,可以解决目标域与源域数据特征不一致时无法使用同一模型进行训练的问题。
2)通过加入对抗训练的方式获得特征对齐。通过min-max的方式,最小化标签分类器的损失的同时最大化域分类器的损失,使得源域数据和目标域数据具有相同或非常相似的空间分布。
1 性能预测自学习方法
机器学习对数据有独立同分布的假设要求,也就是训练集与测试集必须具有相同的分布特性。当数据集的特征分布差异较大时,常规基于训练集与测试集的训练和测试方法通常找不到数据集之间的关联,导致机器学习算法在不同数据集上的迁移应用困难。因此尝试基于对抗训练构建一个不同数据之间共性特征的提取方法,提取数据集之间的共性特征,实现特征对齐,建立性能预测自学习方法,并通过改进的长短期记忆网络(long short-term memory,LSTM)实现。
1.1 自学习方法的基本原理
考虑到目标电机性能参数取值容易获得,本文采用通过将源域和目标域投影到公共特征空间的方法实现特征对齐,进而构建探索不同域或不同任务间特征相关性的自学习方法。有标签的源域指已有设计参数及其对应的性能数据的数据集,可以是已有电机的实验或者数值模拟数据。无标签的目标域指目标电机的设计参数集。有标签的源域和无标签的目标域共享相同的特征和类别,但是它们空间分布不同,自学习方法与传统算法的比较,如图1所示。图中,每种形状的标签数据代表一个领域的数据,传统的机器学习针对不同领域的数据集要并训练不同的模型,模型之间不通用;自学习方法把两个分布不同的数据集分别作为源域和目标域,将源域和目标域映射到公共空间,通过特征提取,将学到的知识迁移到目标域的训练中,自学习方法解决了传统机器学习算法在目标域数据没有标签时不能很好的训练模型的问题。

图1 自学习方法与传统方法的比较
电机数据在自学习方法中的定义如下:电机样本数据中任选两个数据集分别作为源域设计参数样本集Xs、目标域样本集Xt和源域性能数据样本集Ys,探寻不同电机数据的相互迁移性。模型输入数据Xs∈Xs(Xs={Xs1,Xs2,…,Xsn}),Xt∈Xt(Xt={Xt1,Xt2,…,Xtn}),Ys是一个有限集(Ys={1,2,…,L})。
在Xs、Xt上存在源域特征分布S(X,y)和目标域特征分布T(X,y),两种分布都是复杂且未知的,相关但又不同。在训练时,通过对抗学习将S(X)和T(X)映射到公共空间,实现特征对齐。在训练时已知源域的标签yi∈Ys。对于来自目标域的数据,在训练时无标签,但是通过自学习方法在测试时可以预测这些标签。
1.2 自学习方法的实现
自学习方法在减少不同数据分布差异上面有着良好的表现。其模型主要由生成器、回归器和域分类器组成。
自学习方法的步骤,如图2所示。
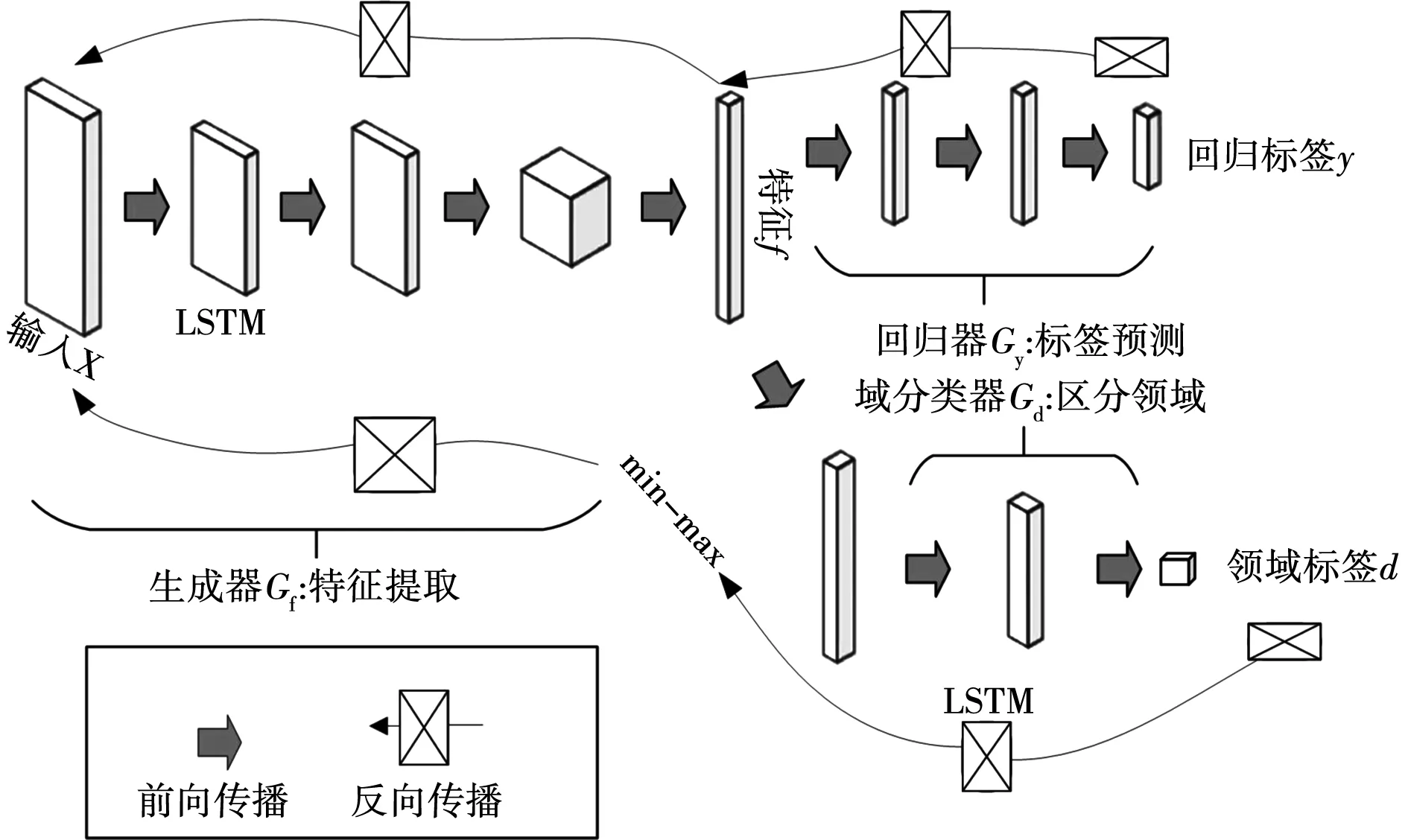
图2 自学习方法模型
1)使用源域有标注的数据对生成器Gf和回归器Gy进行有监督训练。域分类器Gd将源域数据Xs和目标域数据Xt提取共性特征到公共空间,回归器Gy对生成器Gf提取的共性特征进行预测,并基于源域性能数据样本集Ys实现回归器Gy的参数优化。训练的目标是使生成器Gf产生的共性特征可以保留源域数据的关键信息,且回归器Gy可以对生成器Gf产生的共性特征进行准确预测。
2)通过加入对抗训练的方式实现特征对齐。在优化回归器Gy的参数以最小化训练集(Xs、Ys)上误差的同时,通过min-max方法,优化生成器Gf的参数以最小化回归器Gy损失的同时并最大化域分类器Gd的损失。
通过引入对抗学习将源域特征和目标域特征进行空间转化,并约束两者分布尽可能接近,在很大程度上能够提高不同数据集之间预测的准确率。
2 自学习建模与调优
2.1 自学习建模
自学习建模具体步骤如下,通过特征提取,特征对齐的方式最终实现不同的电机的预测。
1)特征提取。
定义一种深度前馈架构,将不同领域的数据特征提取到公共空间。
此映射中将所有层的参数向量表示为θf,即f=Gf(x;θf),然后,特征向量f通过标签预测Gy映射到回归标签,将相同的特征向量f通过映射到领域标签d,Gd参数记为θd。
输入向量x=xs+xt经过隐藏层被映射成D维的特征图,过程可表示为
Gf(x;W,b)=sigm(Wx+b)。
(1)
式中:sigm为激活函数sigmoid,W和b为当前层的权重和偏置。为了确保了特征向量f的可辨别性以及特征提取器和标签预测在源域上的组合的总体良好预测性能。因此在源域的带标签的部分上最小化回归器损失,从而按顺序优化生成器和回归器的参数以最小化源域样本的经验损失。
2)特征对齐。
对提取的特征实现特征对齐,域之间的转换是不变的,即分布S(f)={Gf(x;θf|x~Sx|}和T(f)={Gf(x;θf)|x~Tx|}相似,这将使目标域上的标签预测准确性与源域上的相同。考虑到f是高维的,并且随着学习的进行,分布本身不断变化,因此测量分布S(f)和T(f)的不相似性并非易事,可以通过查看Gd的损失,前提是已经训练了Gd的参数θd以最佳方式在两个特征分布之间进行区分。
Gy对特征空间的源域数据进行预测,尽可能分出正确的标签数据,Gy的输出为
Gy(Gf(x),V,c)=softmax(VGf(x)+c)。
(2)
式中:softmax为输出层Gy激活函数,V和c为当前层的权重和偏置。
Gd的定义为
Gd(Gf(x),U,z)=sigm(UTGf(x)+z)。
(3)
式中:U和z为当前层的权重和偏置矩阵。

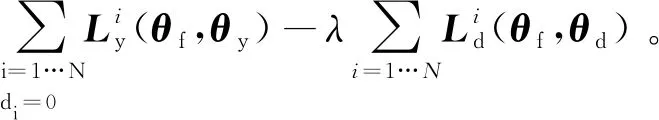
(4)
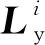
(5)
在不断地对抗过程中,特征映射参数θf最小化标签预测损失(即,特征是可区分的),域分类器的参数θf使域预测损失最大化(即,特征是域不变的)。该参数控制在学习过程中塑造特征的两个目标之间的权衡。
2.2 评价指标
选取评价指标为平均绝对百分误差(mean absolute percentage error,MAPE),选取确定系数(R squared,R2)、均方误差(mean squared error,MSE)、评价网络结构如下:
(6)
(7)
(8)
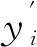
MSE取值范围是[0,+∞],数值越小,说明预测值与真实值越接近。R2取值范围是[0,1],R2如果结果是0,说明模型拟合效果很差,如果R2结果越接近1,拟合效果越好,但是随着数据量的增加,R2的值也会趋近于1,因此R2≈1并不能说明模型效果很好。MAPE取值范围是[0,+∞],当MAPE大于100%时,表示模型是劣质模型,MAPE值越小,则说明预测模型拥有更好的精确度。
2.3 自学习网络结构优化
本次实验的GPU平台为GTX1660Ti-6G。
采用不同深度的LSTM以及其他不同的超参数,包括学习率、dropout进行训练,表1“LSTM_数字”表示神经元参数的个数,每个单元的输出为一组超参数,建立自学习模型实验矩阵,如表1所示。对不同的网络结构依次进行编号。使用的源域数据和目标域数据,在节3中有详细介绍。在本文中,整个网络采用RELU为激活函数,50个Epoch训练完毕后的均方误差作为验证指标。实验结果及超参数,如表1所示。

表1 网络结构及实验结果
采用不同深度、不同的网络参数进行比较发现,采用3层(编号5)和4层(编号9)结构的网络效果比较好。与2层的网络相比,误差明显改善,而5层的网络(编号11、12)和4层(编号9)相比,结果相差不大,说明网络出现了饱和。
自学习模型调优后,选择结果如下:
生成器:生成器的架构是由4层LSTM组成,参数量分别是32,64,128,16,对于LSTM的每一层的输出,使用了注意力机制[35](Attention)。Attention机制通过对模型输入变量进行计算,赋予输入变量不同的权重,可以排除周围的干扰信息,加入Attention机制可以提高输出质量,获得更准确的精确度。最后对于最后一层的一个LSTM,我们最后使用了一个全连接的形式,全连接层的参数量分别是512、120、1。
域分类器:域分类器的架构是由3层LSTM组成,参数量分别是16,32,64,对于最后一层同样使用了一个全连接的形式,全连接的参数量分别是512、100、1。
回归器:为了使模型做出更精确的预测,回归器使用LightGBM[36],在训练过程中不断添加新的决策树,新添加的决策树更加关注预测错误的样本并具有使模型预测结果向误差梯度下降方向前进的能力。内部采用了基于直方图的决策树算法以及使用带深度限制的叶节点生长策略,具有较高的训练效率并且支持并行化学习。
3 实验及结果分析
3.1 数据集的建立
仿真是验证产品早期设计唯一可行的方法,利用仿真,可以替代绝大部分实验,节约成本和减少研发周期。因此,训练的数据集借助于有限元分析软件,建立永磁同步电机模型,在不同参数下采集数据,得到数据样本集。
研究对象为3个不同的永磁同步电机,并且选取相同的结构参数,对3个电机依次编号。
电机1选取日本Toyota混合动力轿车中的Prius 2010电机[37],Prius 2010电机的二维模型,如图3所示,结构为48槽8极数,内置V型永磁体,单层绕组。
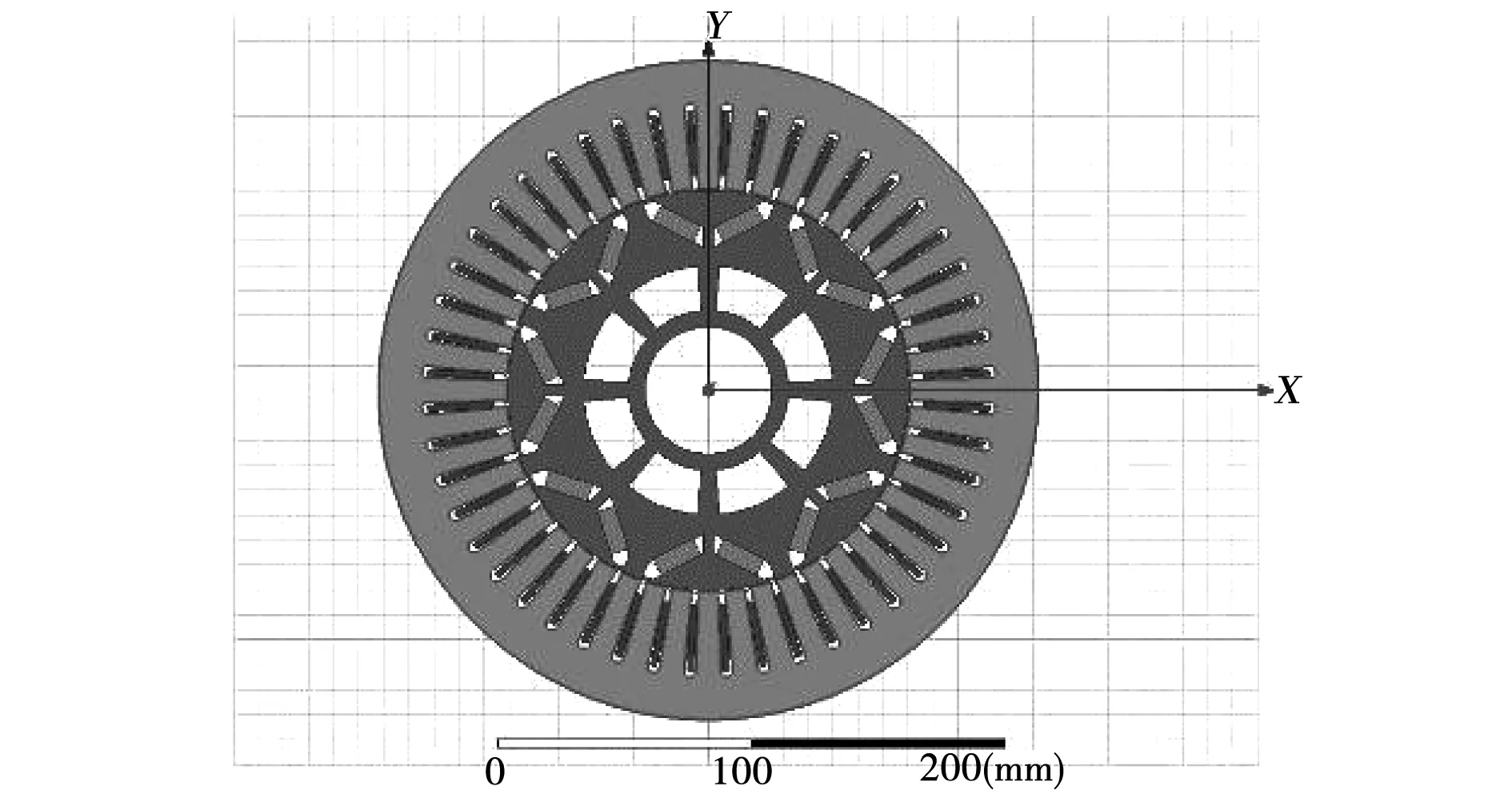
图3 Prius 2010电机的二维模型
电机2选取的日本Toyota混合动力轿车中的Prius 2004电机[38],Prius 2004电机的二维模型,如图4所示,电机1是在电机2的基础上优化的,最主要区别是电机1的转子中一部分是空心的,因此与电机1结构差异不大,结构为48槽8极数,内置V型永磁体,单层绕组。
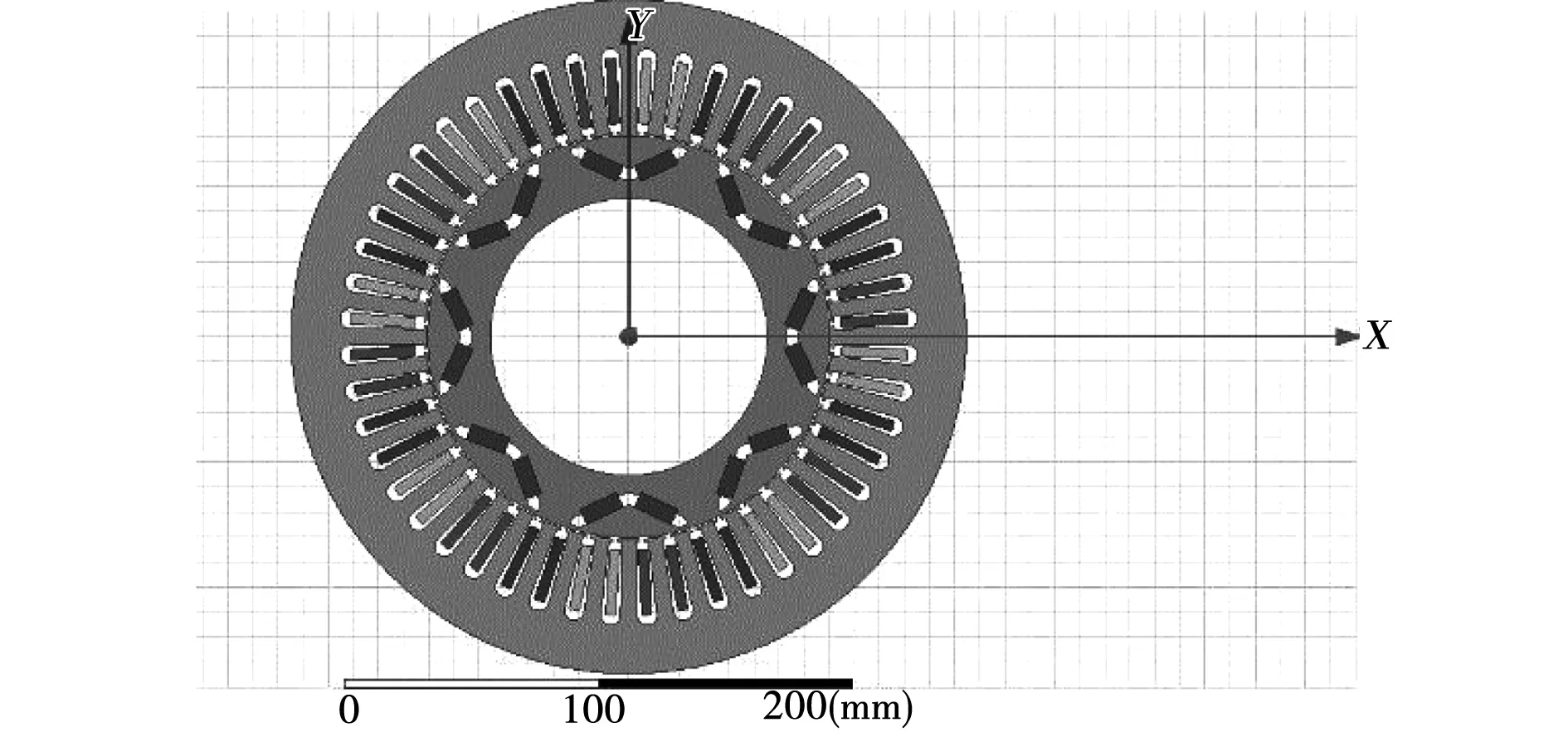
图4 Prius 2004电机的二维模型
电机3选取实验室中实际电机,如图5所示,结构为36槽6极,内置一字型永磁体,双层绕组,电机3结构在极对数、槽数、绕组等方面与前两电机差距较大。
图5 实验室中实际电机模型
在永磁同步电机有限元模型中选取6个输入变量,分别为定子槽口宽度、永磁铁宽度、永磁铁厚度、槽高、气隙长度、极弧系数。选取的变量均是影响电机性能相对重要的参数,也是优化的重点,各电机结构取值,如表2所示。选取电机效率和齿槽转矩两个性能参数作为预测性能参数。
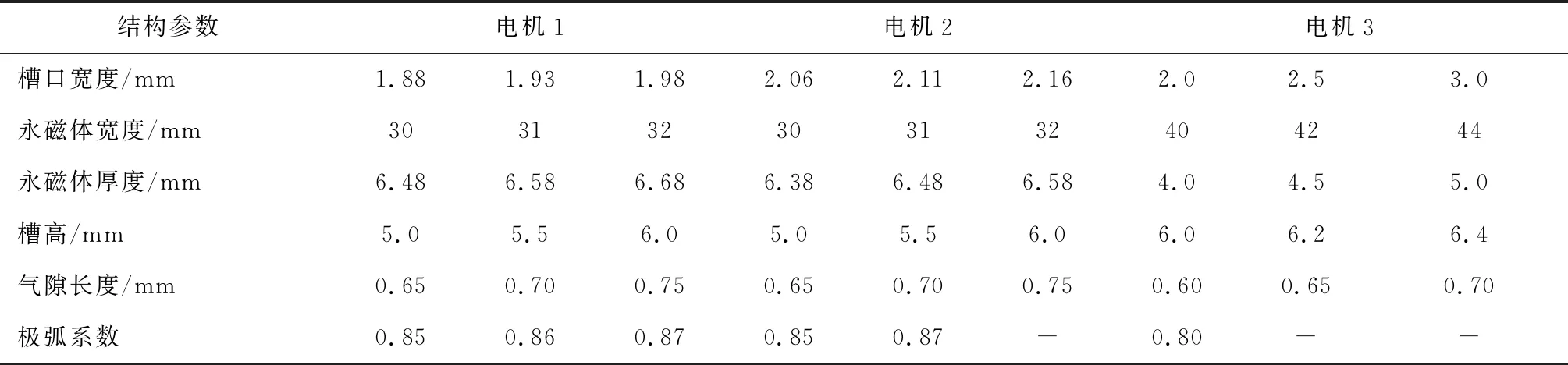
表2 电机变量取值
3.2 案例验证
案例验证一:相似电机实验结果与分析
为了验证自学习方法在不同的数据集上的预测效果,电机1和电机2的结构较为相似。分别使用四种算法建立电机性能预测模型:LSTM、LSTM+PCA、LSTM+Attention、自学习算法。训练集为电机1的设计参数和性能数据,测试集为电机2的设计参数和性能数据。对于特征迁移的自学习算法,电机1数据和电机2数分别作为源域数据和目标域数据。
对比实验结果,如表3所示。加入PCA在降维过程中失去了部分高级特征,因此预测精确度略差,使用LSTM+Attention在测试集中效果是最好的,相对于测试集中最优的效果,使用自学习方法时,相似电机的齿槽转矩MAPE值从8.68降低到3.07,即预测精确度提高了64%,效率MAPE值从4.93降低到1.51,即预测精确度提高了69%。自学习在不同数据集中的表现出良好的预测效果。
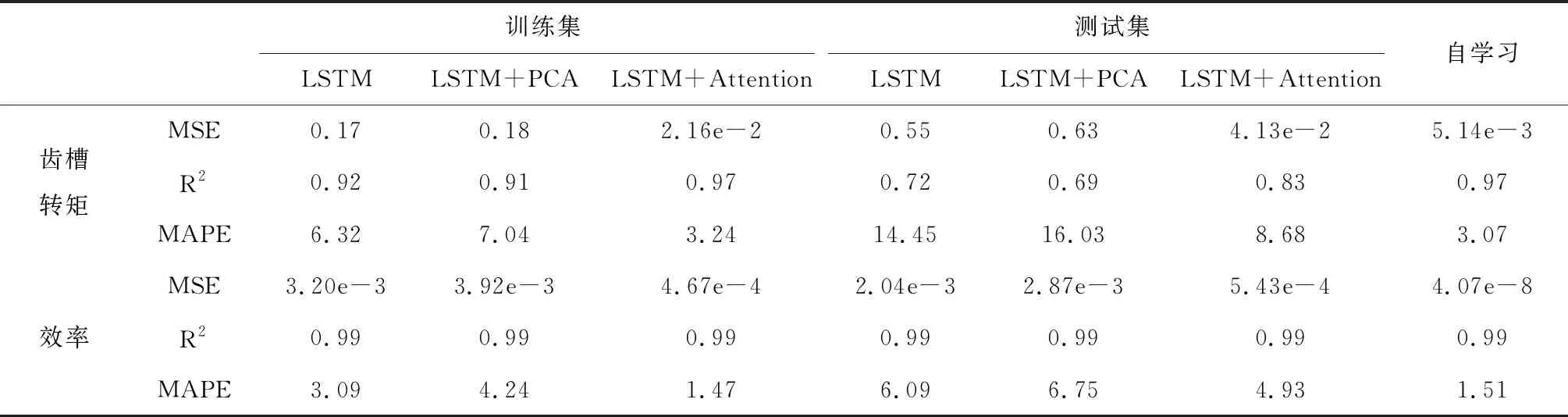
表3 相似电机预测实验
相似的两个电机齿槽转矩、效率在不同模型下的真实值与预测值的对比,如图6和图7所示。训练集效果最好,测试集效果虽然最差,但是预测趋势与真实值接近。训练集、自学习的预测趋势与真实值一致,并且预测值逐渐逼近真实值,有较高的预测精确度。

图6 齿槽转矩的真实值与预测值
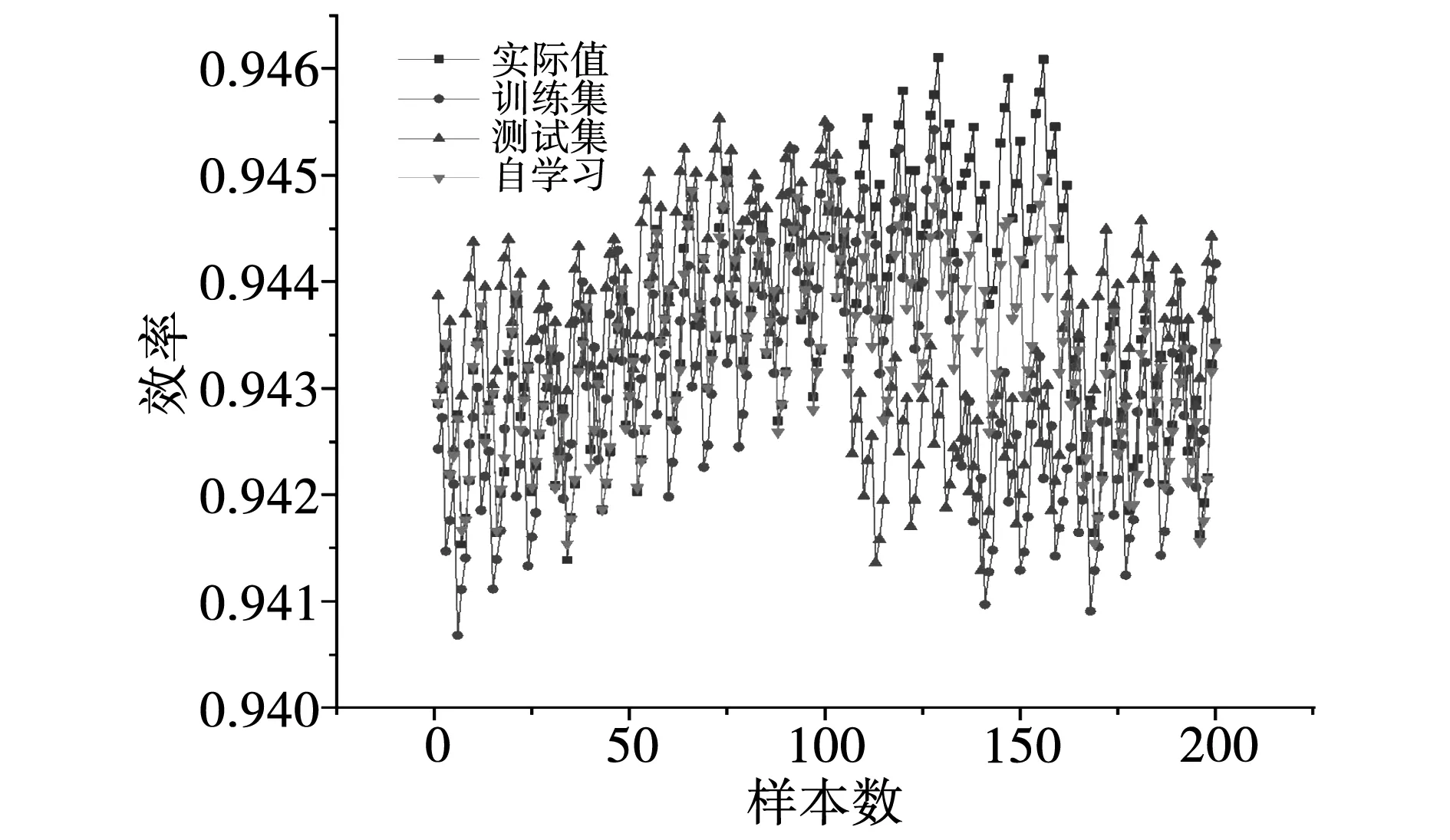
图7 效率的真实值与预测值
案例验证二:差异电机实验结果与分析
电机1和电机3的结构差异较大。分别使用4种算法建立电机性能预测模型:LSTM、LSTM+PCA、LSTM+Attention、自学习算法。训练集为电机1的设计参数和性能数据,测试集电机3的设计参数和性能数据。对于特征迁移的自学习算法,电机1和电机3分别作为源域和目标域。对比实验结果,如表4所示。

表4 差异电机预测实验
将LSTM模型用到测试集中,发现预测质量会有一个明显的下降,并且验证集齿槽转矩部分的MAPE值大于100%,证明此模型已无法使用。数据差异越大,模型通用性越差,即数据差异越大,预测效果越差。
对于测试集LSTM+Attention模型,使用自学习方法时,相似电机的齿槽转矩MAPE值从134.83下降到23.72,即预测精确度提高了80%,效率MAPE值从29.42下降到5.70,即预测精确度提高了82%。当使用特征迁移的自学习算法时,可以明显的看出,即使应用在分布不同的数据集上,自学习方法也能得到一个很好的预测值,解决了在差异电机设计过程中数据特征迁移难的问题。
电机1和电机3差异较大,其电机齿槽转矩、效率在不同模型下的真实值与预测值的对比图,如图8和图9所示。
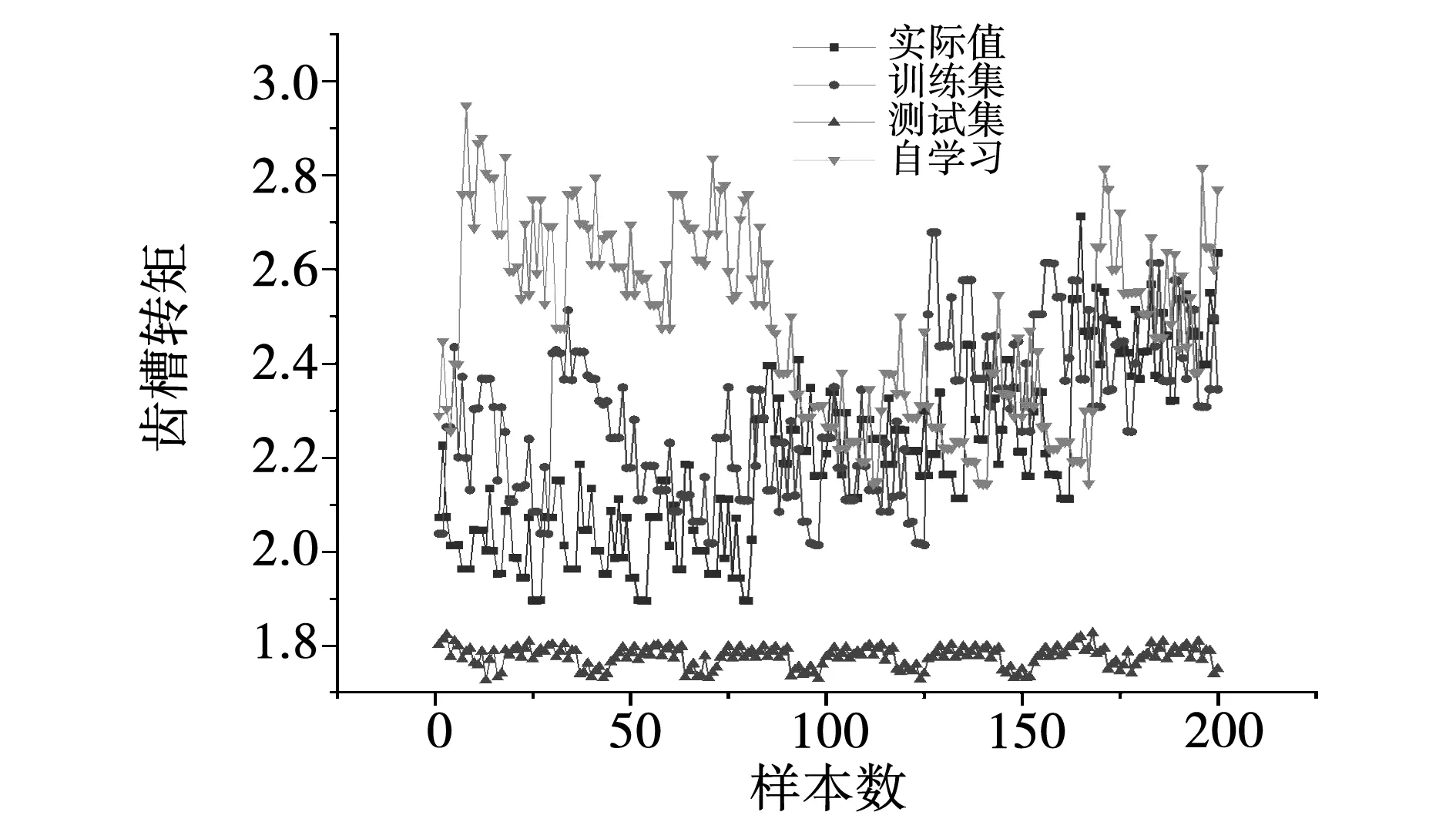
图8 齿槽转矩的真实值与预测值
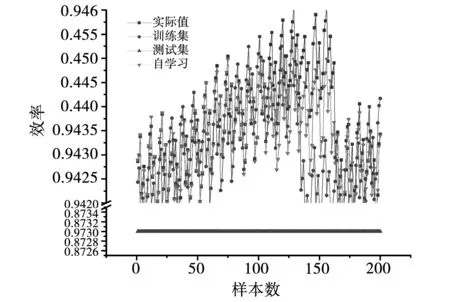
图9 效率的真实值与预测值
训练集效果最好,测试集效果最差,LSTM模型已无法得出预测趋势和预测值。自学习的预测趋势和预测值逐渐逼近真实值,自学习在处理差异较大的数据时表现出良好的预测性能。
在电机设计初期,仅能得到很少的样本数据,因此探索标签数据量对预测结果十分必要。选取不同的目标域标签数据占比,其实验结果,如表5所示。

表5 样本标签数量对结果的影响
根据表5的实验结果,目标域的标签数据越多,特征提取时拟合程度更高,预测效果更准。当标签数据在40%时,在齿槽转矩和效率上的预测精确度已经达到了误差要求。数据的累积对模型的预测精确度有很大的提升,因此在长期的使用过程中,通过数据的不断积累可提升模型的预测精确度或者对于新的电机问题的适应能力。
使用有限元软件计算和使用自学习方法预测1000个数据时的所用时间对比,实验结果,如表6所示。用有限元建立电机模型仿真花费了大量的时间和精力,使用领域自适应模型可以大大降低计算工作量,节省了时间成本。如果有限元模拟仿真采用三维模型,和自学习算法相比,计算耗时将进一步拉开差距。
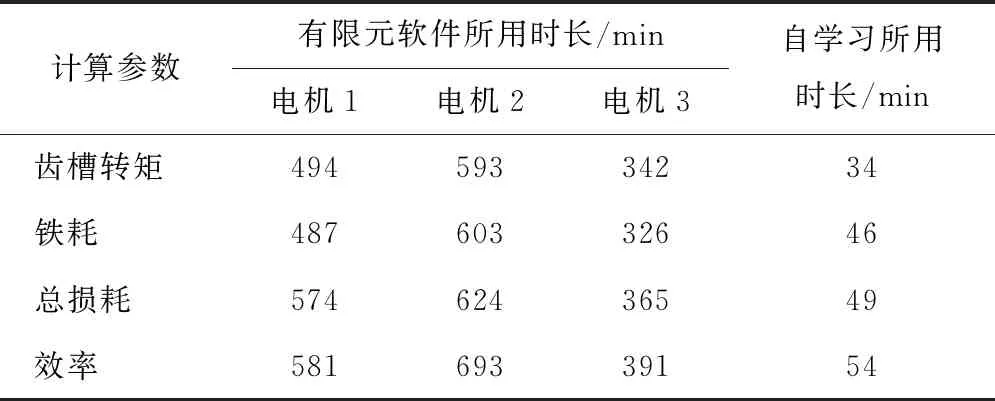
表6 预测所用时间对比
4 结 论
本文提出了基于特征迁移的自学习方法,用于不同的电机设计研究,经案例验证得到如下结论:
1)自学习方法可以实现跨领域的学习,将不同分布的源域和目标域数据映射到公共空间提取特征,解决了不同类型电机设计过程中数据特征迁移难的问题。
2)在计算初期,使用自学习方法对电机性能快速验证,得到初步的性能值再进行分析,可以大幅度降低有限元的样本计算量和时间成本。
3)通过历史数据的不断累积,可以增加样本标签数量,从而可以得到更精确的预测值,实现最佳的自学习效果,将在电机的智能设计中发挥重要的作用。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
防爆电机(2021年3期)2021-07-21 08:13:00
防爆电机(2021年1期)2021-03-29 03:02:52
电机与控制应用(2021年12期)2021-02-28 07:55:22
计算机技术与发展(2020年11期)2020-12-04 07:50:46
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
能源(2016年2期)2016-12-01 05:10:31
公民与法治(2016年10期)2016-05-17 04:12:58
电子与信息学报(2015年12期)2015-08-17 11:14:42
