
面向多模态情感分析的双模态交互注意力
2022-04-13 02:40:40包广斌李港乐王国雄
计算机与生活 2022年4期
包广斌,李港乐,王国雄
兰州理工大学 计算机与通信学院,兰州730050
随着移动互联网和和社交媒体的蓬勃发展,越来越多的用户通过YouTube、微博、抖音等社交媒体讨论时事、表达观点、分享日常等,从而产生了海量的具有情感取向的多模态数据。在社交媒体平台上,用户上传的视频是多模态数据的重要来源之一。视频数据通常包含三种模态:描述用户观点的文本、表达用户面部表情的图像以及记录用户语音语调的音频。针对这些多模态数据进行情感分析将有利于了解人们对某些事件或商品的观点和态度,在舆情分析、心理健康、政治选举等方面都有着巨大的应用价值。
与传统的单模态情感研究相比,多模态情感分析的目标是通过融合多个模态的数据来推断目标序列的情感状态。如图1 显示了文本、面部表情和语音语调对于情感分类的作用。其中,视频中说话人关于某部电影发表评论“The only actor who can really sell their lines is Erin.”这条评论是一个陈述句,而且没有明显体现情感取向的词语,因此仅仅依据这句话所传达的信息很难判断出说话人的情感状态,但如果为这句评论加入说话人的面部表情(facial expressions)和语音语调(voice intonation),则可以反映出说话人目前的情感状态是消极的。因此,对于多模态情感分析任务,文本、语音和视频模态之间的语义和情感关联能够为情感分类带来重要的补充信息。

图1 文本、面部表情和语音语调对于情感分类的作用Fig.1 Effect of text,facial expressions and voice intonation on sentiment classification
由于文本、语音和视频特征在时间、语义维度上存在较大差异,目前大多数多模态情感分析方法是将所有可用的模态特征直接映射到一个共享空间中,学习不同模态之间复杂的交互作用。但是,大多数情况下,并不是融合的模态信息越丰富,情感分类的准确率就越高,这主要是因为不同模态的信息对于情感分类的贡献是不相等的。
为了解决上述问题,本文提出了一种融合上下文和双模态交互注意力的多模态情感分析方法,该方法首先采用BiGRU(bidirectional gated recurrent unit)分别捕获文本、语音和视频序列的上下文特征。然后利用不同模态之间存在的语义和情感关联,设计了一种双模态交互注意力,并结合自注意力和全连接层构造了一个层次化的多模态特征融合模块,旨在通过注意力机制更多地关注目标序列及其上下文信息与各模态之间的相关性,从而帮助模型区分哪些模态信息对于判别目标序列的情感分类更加重要,实现跨模态交互信息的有效融合。最后,在CMU-MOSI(CMU multimodal opinion-level sentiment intensity)数据集上进行实验,实验结果表明,相比现有的多模态情感分类模型,该模型在准确率和1分数上均有所提升。
1 相关工作
多模态情感分析主要致力于联合文本、图像、语音与视频模态的情感信息来进行情感的识别与分类,是自然语言处理、计算机视觉和语音识别相交叉的一个新兴领域。与单一模态的情感分析相比,多模态情感分析不仅要学习单模态的独立特征,还要融合多种模态的数据。多模态融合主要是通过建立能够分析和处理不同模态数据的模型来为情感分类提供更多的有效信息。Zadeh 等人利用模态之间的联系建立了一种张量融合网络模型,采用三倍笛卡尔积以端到端的方式学习模态之间的动力学。Zadeh等人提出了一种可解释的动态融合图(dynamic fusion graph,DFG)模型,用于研究跨模态动力学的本质,并根据每个模态的重要性动态改变其结构,从而选择更加合理的融合图网络。Chen 等人提出利用时间注意力的门控多模态嵌入式模型来实现多模态输入时单词级别的特征融合,该方法有效地缓解了噪声对特征融合的影响。上述方法在进行特征提取时都将每个话语看作独立的个体,忽略了与上下文之间的依赖关系。
多模态情感分析的研究数据通常来自社交网站上用户上传的视频,这些视频数据被人为地划分成视频片段序列,而片段序列之间往往存在着一定的语义和情感联系。因此,当模型对目标序列进行情感分类时,不同片段序列之间的上下文可以提供重要的提示信息。Poria 等人建立了一种基于LSTM(long short-term memory)的层次模型来捕捉视频片段间的上下文信息。Majumder 等人通过保持两个独立的门控循环单元来跟踪视频中对话者的状态,有效地利用了说话者之间的区别和对话中的上下文信息。Shenoy 等人提出的基于上下文感知的RNN(recurrent neural network)模型能够有效地利用和捕获所有模态对话的上下文用于多模态情绪识别和情感分析。Kim 等人建立了一种基于多头注意力的循环神经网络模型,该模型采用BiGRU 和注意力机制来捕获会话的上下文信息的关键部分。但是,现在人们表达情感的方式已不再局限于单一的文字,往往通过文本、图像、视频等多种模态相结合的方式共同传递信息,那么如何有效利用多模态信息进行情感分析仍是一项艰巨的任务。
近年来,注意力机制已被广泛应用于NLP(natural language processing)领域。研究表明,注意力机制能够聚焦于输入序列的关键信息,并忽略其中不相关的信息,从而提高模型的整体性能。因此,越来越多的研究人员尝试将注意力机制应用于探索模态内部和不同模态之间的交互作用。Zadeh 等人提出了一种多注意力循环神经网络(multi-attention recurrent network,MARN),利用多注意力模块(multi-attention block,MAB)发现模态之间的相互作用,并将其存储在长短时混合记忆(long-short term hybrid memory,LSTHM)的循环网络中。Xi 等人提出利用多头交互注意力来学习文本、语音和视频模态之间的相关性。Verma 等人提出了一种高阶通用网络模型来封装模态之间的时间粒度,从而在异步序列中提取信息,并利用LSTM 和基于张量的卷积神经网络来发现模态内部和模态之间的动力学。
综上所述,随着深度学习研究的不断深入,多模态情感分析实现了跨越式的进步和发展,但如何有效地利用单模态独立特征和多模态交互特征进行建模依旧是多模态情感分析所面临的主要问题。为此,本文在现有多模态情感分析方法的基础上,提出了一种融合上下文和双模态交互注意力的多模态情感分析模型,旨在利用BiGRU 和注意力机制更多地关注相邻话语之间的依赖关系以及文本、语音和视频模态之间的交互信息并为其分配合理的权重,实现多模态特征的有效融合,从而提高多模态情感分类的准确率。
2 融合上下文和双模态交互注意力的模型
本文针对现有多模态情感分析方法中存在情感分类准确率不高,难以有效融合多模态特征等问题,提出了一种融合上下文和双模态交互注意力的多模态情感分析模型(multimodal sentiment analysis model based on context and bimodal interactive attention,Con-BIAM),如图2 所示。具体来说,Con-BIAM 模型分为以下四部分:
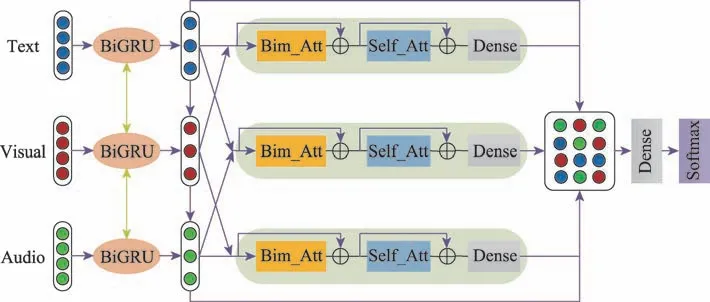
图2 融合上下文和双模态交互注意力的模型结构Fig.2 Model structure combining context and bimodal interactive attention
(1)针对文本、语音和视频模态数据的不同特点,构建不同的神经网络提取单模态特征。
(2)利用BiGRU 分别编码文本、语音和视频序列,然后将其映射到共享的语义空间中,在每个模态的不同时间步长上捕获视频目标序列的上下文信息。
(3)利用不同模态之间的交互作用,设计了一种新颖的双模态交互注意力机制融合不同模态的信息;然后通过双模态交互注意力、自注意力和全连接层构造多模态特征融合模块,得到跨模态联合特征。
(4)将得到的上下文特征和跨模态联合特征连接起来,经过一层全连接层后馈送至Softmax 进行最终的情感分类。
2.1 特征提取
为了获取视频中的文本、语音和视觉特征,采用卡内基梅隆大学提供的多模态数据分析工具CMUMultimodal Data SDK进行提取。对于文本数据,首先将视频中的每个话语进行转录,然后将其表示为Glove 词向量,输入至卷积神经网络中提取文本特征。为了有效地利用视频中的动态信息,使用3DCNN(3D convolutional neural networks)从视频中提取视觉特征。在实验过程中,32 个特征图(f)和5×5×5(f×f×f)的过滤器取得了最优的结果。对于音频模态数据,利用openSMILE工具包以30 Hz的帧速率和100 ms的滑动窗口提取音频特征。

2.2 上下文特征表示
本文将预处理后的文本()、语音()和视频()特征分别输入至BiGRU 中提取序列的上下文信息。考虑到不同模态数据的异构性,利用Dense层在时间维度上提取目标序列与上下文特征之间的长跨度信息,获得相同数据维度的上下文特征表示。
假设数据集包含个视频片段,每个视频片段对应一个固定情感强度的观点。视频中包含的一系列片段序列可表示为:

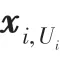
此外,为了更加准确地对视频片段X进行情感分类,将X定义为X的上下文:

其中,表示视频中其他片段序列的长度。
BiGRU 由两个方向相反的GRU(gated recurrent unit)构成,能够有效地捕获序列中上下文的长依赖关系,解决RNN 训练过程中出现的梯度消失和梯度爆炸问题。在BiGRU 中,正向和反向输入的特征向量会得到对应时刻的隐藏层表示,之后通过拼接操作得到具有上下文信息的文本、视觉和语音特征。双向门控循环单元的结构如图3 所示。

图3 BiGRU 结构模型图Fig.3 BiGRU structure model diagram
每个GRU 单元的工作原理如下:

其中,X是当前节点的输入序列,h是上一个GRU 单元传输下来的状态,r是GRU 的重置门,z是GRU 的更新门,W,W,U,U∈R是训练过程中要学习的参数,是Sigmoid 函数,⊙表示对应元素相乘。
为了深度挖掘单模态特征的内部相关性,将得到的具有上下文信息的单模态特征分别映射到各自的语义空间中。计算过程如下:

其中,W、、、分别是激活函数tanh 的参数,、、是经过BiGRU 得到的文本、语音和视觉特征。∈R,∈R,∈R分别表示最终输出的具有上下文信息的文本、语音和视觉特征向量,表示Dense层中神经元的数量。
2.3 特征融合模块
对于多模态情感分析任务,不同模态的数据包含了各自的情感信息,它们彼此不同却又相辅相成。因此,在基于模态内部关系建模的同时关注另一种模态信息的补充作用,能够有效地提升模型的分类性能。此外,在进行多模态信息融合时,不同模态的信息对情感分类结果的重要性也是不同的。因此,对多模态信息进行建模时,需要有选择性地区分各模态信息对目标序列的情感预测的重要程度,增强重要信息所占的权重,从而输出更有效的跨模态联合特征表示。
由此,本文提出了一种多模态特征融合模块(multimodal feature fusion module,MFM)。该模块采用层次化的融合策略融合所有的模态特征,主要由两层注意力机制和一个全连接层串联构成。首先第一层是双模态交互注意力(bimodal interactive attention,Bim_Att)层,Bim_Att 能够将两种模态的融合特征作为条件向量,强化与模态间重要交互特征的关联,弱化与次要交互特征的关联,深度探索不同模态之间的交互性;第二层是自注意力层(self attention,Self_Att),用于捕获目标序列及其上下文信息与模态自身的相关性,从而减少对外部信息的依赖;最后一层是全连接层,用于提取双模态交互融合信息和单模态内部信息,输出跨模态联合特征。
为了进一步增强模态之间的交互性,本文提出了一种双模态交互注意力机制,整体结构如图4 所示。双模态交互注意力机制类似于一种门控机制,能够将文本、语音和视觉特征进行两两融合,即文本+视频、文本+语音和语音+视频,并有条件地计算不同模态之间的交互向量。以文本()和语音()为例,首先将两种模态的信息进行拼接,并经过一层全连接层捕获模态之间的交互信息,得到双模态联合特征;接着在激活函数Sigmoid 的作用下生成条件向量,用于约束每个模态内部的相似程度,增加强关联特征所持的比重。计算过程如式(10)、式(11)所示。

图4 双模态交互注意力(Bim_Att)结构图Fig.4 Structure diagram of bimodal interactive attention(Bim_Att)

其中,⊕表示向量的拼接操作;表示随机初始化的权重矩阵;表示偏置项。

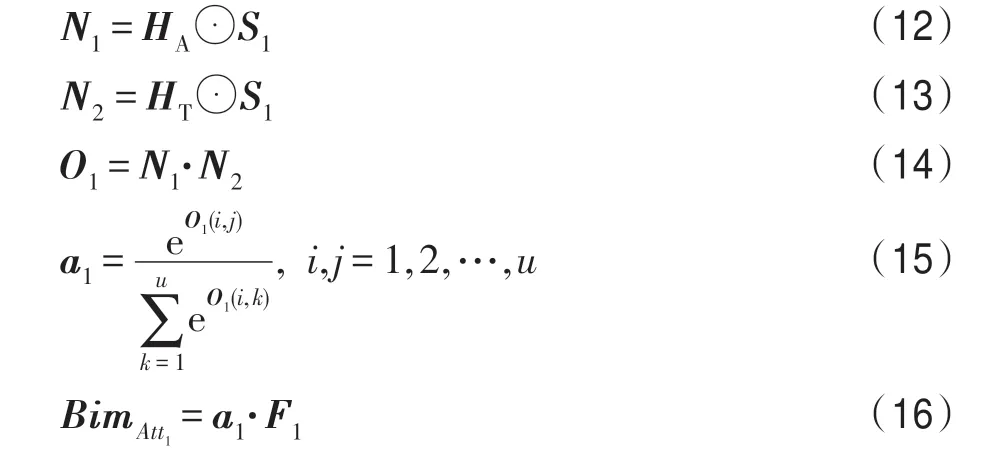
其中,⊙表示对应元素相乘,·表示矩阵乘法。



最后,将得到的注意力特征向量与上下文特征向量进行拼接,并使用全连接层整合得到的模态间交互特征和模态内部特征,输入至Softmax 进行情感分类,其计算过程如下:

其中,∈R,′表示全连接层输出的特征维度,W和b是激活函数ReLU 的权重和偏置。
3 实验与结果分析
3.1 数据集
本文使用多模态情感分析数据集CMU-MOSI 进行实验,简称MOSI。该数据集由89 位不同英语演讲者对来自YouTube网站中的主题进行评论,共有93个视频。数据集中共包含3 702个观点片段,共计26 295个单词。每个视频片段的情感强度在∈[-3.0,3.0]的线性范围内,其中大于或等于0 的情感值表示正面情绪,小于0 的情感值表示负面情绪。本实验将数据集划分为训练集、验证集和测试集,分别设置为52、10、31。每个集合分别包含1 151、296和752个视频片段。
3.2 实验设置
本实验所有代码都是在Pycharm 代码编辑器上采用Tensorflow 和Keras 深度学习框架编写,利用显存为32 GB 的GPU(NVIDIA Tesla V100)进行模型的训练。实验参数设置如表1 所示。
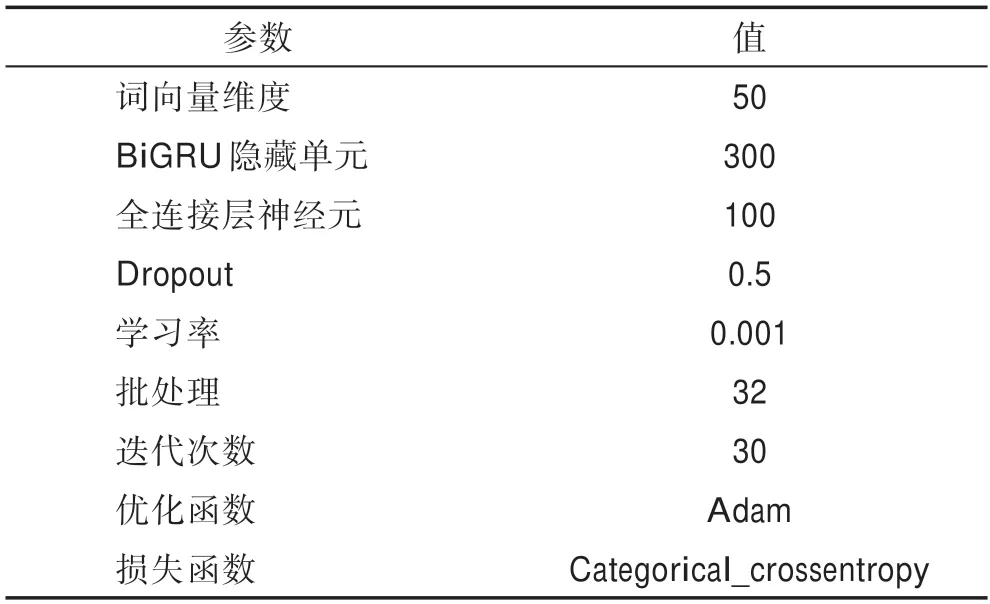
表1 实验参数设置Table 1 Experimental parameter setting
本文选取1 分数和准确率(Accuracy)作为分类性能的评价指标。1 分数和Accuracy 的值越大,说明模型的整体性能越好。为了进一步验证模型的有效性,将本文提出的Con-BIAM 模型与现有的一些多模态情感分析模型进行对比,实验结果如表2 所示。
3.3 实验结果分析
表2 列出了不同模型在MOSI 数据集上的实验结果。图5 是Con-BIAM 模型在MOSI 数据集上得到的混淆矩阵。
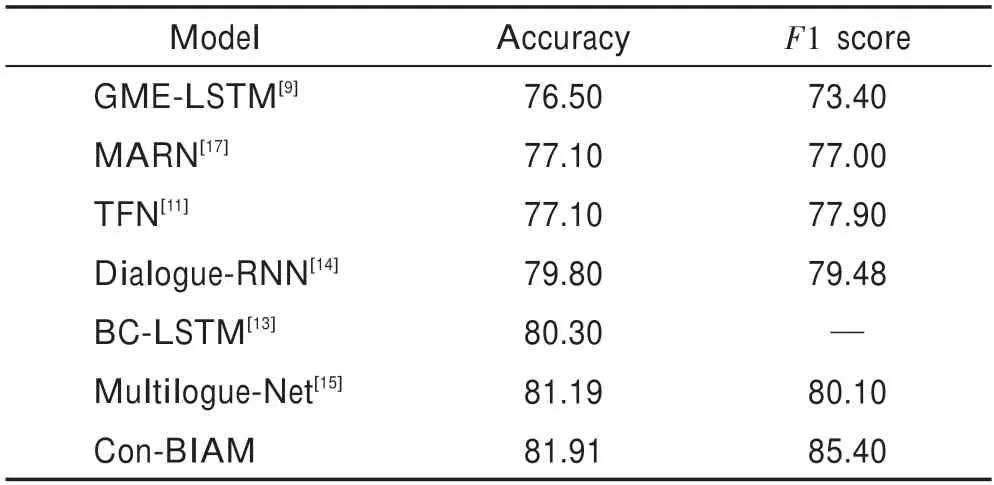
表2 在MOSI数据集上的实验结果Table 2 Experimental results on MOSI dataset %

图5 Con-BIAM 模型在MOSI数据集上的混淆矩阵Fig.5 Con-BIAM model confusion matrix on MOSI dataset
实验结果表明,本文提出的Con-BIAM 模型在准确率和1 分数这两个评价指标上的表现都要优于其他对比模型,准确率和1分数分别提升了5.41个百分点和12个百分点,尤其是对比现有先进的Multilogue-Net模型,准确率提升了0.72 个百分点,1 提升了5.3个百分点。这充分地说明了融合上下文和双模态交互注意力的多模态情感分析(Con-BIAM)在多模态情感分类任务上的有效性和先进性。此外,根据上述实验结果可以看出,Con-BIAM 模型的1 值与其他模型相比具有较大提升,这可能是因为不同层次不同组合的模态融合方法关注到了模态的内部信息和更高层次的模态交互信息,使得模型的精确率和召回率分别达到了85.22%和85.59%,进而增大了模型的1 值,提高了模型的分类性能。
4 对比实验
为了进一步分析模态之间的联合特征对模型最终分类效果的贡献程度,在MOSI 数据集上分别针对双模态和三模态联合特征,选择以下几种多模态情感分析方法进行对比,实验结果如表3 和表4 所示。

表3 不同模型在双模态、三模态特征融合的准确率Table 3 Accuracy of different models in bimodal and trimodal feature fusion %

表4 不同模型在双模态、三模态特征融合的F1 分数Table 4 F1 scores of different models in bimodal and trimodal feature fusion %
实验结果表明,与其他模型相比,除了语音和视频模态的融合之外,Con-BIAM 模型的其他模态融合方式都达到了最好的结果。其中,三种模态(文本、语音和视觉)融合的分类效果最佳,证明了多模态信息的必要性。在双模态融合的实验中,文本+图像和文本+语音融合分类准确率高于语音+视频的融合。这一方面说明了文本模态的情感特性更为显著,另一方面也反映了语音和视频模态的情感特性较弱,可能存在噪声的干扰。
为了进一步分析视频片段的上下文信息、自注意力和双模态交互注意力对模型性能的贡献,本文设计了三组对比实验,比较不同模块对于模型整体性能的影响。在MOSI 数据集上对比实验的结果如图6 所示。
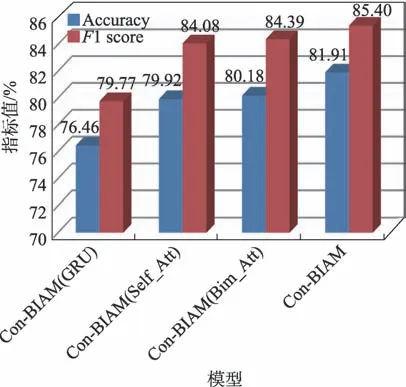
图6 在MOSI数据集上的对比实验Fig.6 Comparative experiment on MOSI dataset
(1)Con-BIAM(GRU):使用GRU代替模型中BiGRU,比较上下文信息对模型性能的影响。
(2)Con-BIAM(Self_Att):舍弃双模态交互注意力机制,保留自注意力机制,探究两种模态之间的交互信息对分类效果的影响。
(3)Con-BIAM(Bim_Att):舍弃自注意力机制,保留双模态交互注意力,探究单模态情感信息对分类效果的影响。
(4)Con-BIAM:本文所提出模型。
实验结果表明,对于MOSI 数据集,舍弃Con-BIAM 模型中的任一重要模块,都会使得模型的分类性能下降。首先,相比于GRU 模型,基于BiGRU 的模型准确率提升了2.52 个百分点,说明了对于视频中某一片段序列,序列前面和后面的视频片段都会对它产生一定的影响,而BiGRU 能够同时捕捉到视频片段序列前向和反向的信息。其次,多模态特征融合模块中的双模态交互注意力和自注意力对情感分类的准确率分别贡献了1.20 个百分点和0.94 个百分点,1 值也分别提升了2.67 个百分点和2.36 个百分点。这主要是因为文本、语音和视频模态内部与模态之间存在着大量的情感信息,而本文所设计的多模态特征融合模块能够同时提取单模态信息和双模态融合信息,并通过注意力机制有选择地关注有利于情感分类的模态信息,从而提高了模型分类性能。
5 结束语
本文建立了一种融合上下文和双模态交互注意力的多模态情感分析模型,利用视频片段的上下文信息和不同模态之间的交互信息来预测情感分类。该模型首先采用BiGRU 捕获文本、语音和视频序列之间的上下文信息。然后,通过双模态交互注意力、自注意力和全连接层构成的多模态特征融合模块,关注目标序列及其上下文信息与模态内部和模态之间的关联性,实现了多模态信息的有效融合。最后,将得到的上下文特征和跨模态联合特征输入至分类器进行情感分类。在MOSI 数据集上的实验结果证明了所提出的模型在多模态情感分类任务上的有效性和优异性。在未来的工作中,将针对多模态融合过程中所出现的语义冲突和噪声问题展开进一步研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
