
双线性聚合残差注意力的细粒度图像分类模型
2022-04-13 02:40:56李宽宽刘立波
计算机与生活 2022年4期
李宽宽,刘立波
宁夏大学 信息工程学院,银川750021
细粒度图像分类已逐渐成为计算机视觉与图像处理领域中的热点研究方向之一,相对于传统的粗粒度图像分类而言,其主要研究内容是区分常见目标类别中的子类别问题(比如鸟的种类、飞机型号),但由于种类间的从属子类别十分相似,大多数类别只能通过局部区域中有差别的部件才能识别,这使得细粒度图像分类成为一个更具挑战性的研究任务。
针对以上细粒度图像分类的任务特性,早期一些学者提出了通过人工部件标注信息协助来强化模型定位的方法,以强监督的训练方式来提高分类精度。Zhang 等人通过使用区域选择性算法来产生区域,并利用边框与几何约束条件,完成对象与部件级别的目标位置检测与定位。Lin 等人通过网络模型局部部件定位、对齐与网络分类三个模块进行融合,通过部件定位模块递归完成对标注框的识别,然后使用对齐模块姿态、模板进行协调对准,最终由阀连接函数(valve linkage function,VLF)连接三个模块,优化分类精度。
虽然借助丰富的部件标注信息,辅以精准的检测定位技术,实现了更高的识别分类精度,但人工标注费用昂贵,且容易出现局部语义信息的错误注解,更加不符合现实研究与应用的实际需求,使得越来越多的算法不再依赖于这些强监督的人工标注信息,因此,仅依赖图像类别标签实现局部部件判别的弱监督方法也逐渐成为当下研究的新趋势。
相比于依赖人工部件标注的方法而言,基于弱监督的细粒度图像分类方法表现出更加优异的分类性能以及网络泛化能力,并且能够挖掘出人工标注缺失甚至错误的判别性区域。其中,一部分学者采用辅助子网络实现部件定位。Yang 等人提出了自监督导航网络(NTS-net),不需要使用人工部件标注,通过导航组件实现最大化的部件区域定位识别,然后通过反馈与审查两个组件进行局部区域的特征融合以及真实概率估计,并完成细粒度图像分类。
但随着网络复杂度的不断延伸,往往会出现特征信息冗余,最终导致网络的特征表达能力不足等现象,还有一些学者通过引入视觉注意力机制,突出关注具备目标识别度的区域,提取更多细微可区分的局部特征。Peng 等人利用目标-部件注意力组件选择性地关注可区分性区域,并借助空间约束消除冗余,增强部件判别力。Woo 等人提出了一种同时在通道域与空间域进行特征约束与互补的注意力模型,既关注了通道特征的依赖关系,也弥补了空间语义的重要特性,并且该模块更偏向于轻量化、通用性。Han 等人采用类别与属性协同互惠的注意力方法选择性去捕捉局部细节和有区分度的信息。但是这些方法对部件区域的关注更倾向于对象的几个关键部分(比如鸟的头部、腿部、翅膀、喙部),而忽略了制约分类性能的其他区域信息,比如颈背、喉咙等这些可快速判别该鸟种类的细微部分。Gao 等人通过SCI 与CCI 两个模块学习图像中不同通道间的判别特征以及通道关系,并促进每个通道信息互补,进而使得学习到的区域判别信息更加丰富,弥补了以上区域信息缺失的现象,但模块结构对基础网络依赖程度较高,且模型结构较为复杂。
鉴于以上分析,由于细粒度图像分类任务中类间信息表征易混淆特性,现有一些方法无法充分挖掘显著性及有判别力的部位信息,导致网络学习到的细节特征无法呈现出多样化与差异性,进而影响模型分类性能。为此,本文提出了一种双线性聚合残差注意力网络(bilinear aggregate residual attention network,BARAN),主要贡献如下:
(1)在仅需类别标签的前提下,BARAN 通过双线性聚合残差网络作为基础模型,来完成图像的深度特征提取。其中主要利用聚合残差网络中分组并行的拓扑结构特性,使其组间的不同子空间学习图像中的不同区域,捕获到更多的可区分特征,进而增强网络模型的表征能力。
(2)在聚合残差网络的每一个分组拓扑结构中嵌入分散注意力模块(split attention,SA),能够有效地避免特征通道之间信息离散的现象,提高特征通道之间的全局相互依赖性,以达到建模特征通道之间信息校准的目的,来保证特征的空间信息关联性。
(3)在双线性聚合残差网络的特征融合后引入互通道注意力模块(mutual-channel attention,MCA),该模块结合判别性子模块与区分性子模块这两部分,能够迫使所有特征通道进行类分组对齐操作,促使网络学习到多样化且具有差异性的局部信息来获得性能增益。并且在不会引入额外的网络参数前提下,使网络更易于训练。
1 相关工作
1.1 双线性卷积网络模型
Lin 等设计了一种双线性卷积网络模型(BCNN),通过两个子网络(特征提取函数)进行相互协调作用,分别完成了细粒度图像分类中的区域定位与特征提取,然后把两个不同的卷积子网络提取的特征利用外积相乘运算来得到双线性向量,最后通过分类器完成分类任务。该网络体系结构具有对局部特征进行交互建模提取的优势,且能够实现整个模型端到端的训练,使其更适用于细粒度中不同局部信息的提取。但是其特征提取子网络以相同卷积核尺度进行区域特征提取,导致每层卷积特征融合单一化,往往不利于细粒度图像分类任务中差异性局部信息的捕捉,进而影响网络的表征能力。此外,经外积运算后,双线性特征维度达到数十万甚至数百万,极大增加了后续特征信息的分析难度。
1.2 聚合残差网络
Xie 等人提出了一种聚合残差转换网络(aggregated residual transformations networks,ResneXt),ResneXt 在继承了Renset重复层策略(strategy of repeating layers)和跳跃连接(skip connection)这两大特性基础上,引入一种新颖的拓扑结构,即聚合残差转换模块(aggregated residual transformations,ART),该模块以分组的形式进行卷积化特征提取;ResneXt中每一小模块都是以组卷积的形式进行堆叠,聚合残差块中分组卷积通过多路并行的组卷积操作,能够监督网络学习更具区别的表征信息;并且也起到网络正则化效果,提取的卷积操作更加稀疏化,极大降低了每个子网络的复杂度,进而避免模型过拟合的风险。如图1 所示。
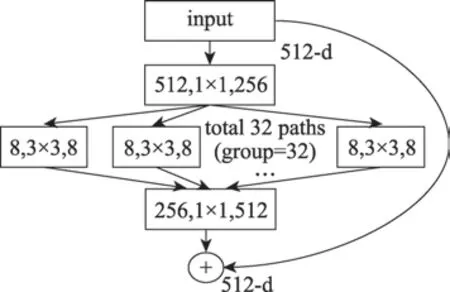
图1 聚合残差转换子模块Fig.1 Aggregated residual transformations block
ART 模块中引入一个超参数,基数(cardinality,C),代表组量,图中用group 表示;每一个聚合转换残差模块中特征聚合如式(1)所示:

其中,T()代表投影到低维空间进行转换的任意函数,类似于一个简单的神经元;代表组卷积数,是一个任意设定的值;() 代表个低维嵌入的T()进行求和输出。
2 双线性聚合残差注意力网络模型
2.1 BARAN 模型整体结构
为了弥补原B-CNN 模型存在特征提取能力不足,特征融合单一化以及维度过高等问题,本文方法以B-CNN 为基础网络原型,结合其端到端的训练方式以及两个子网络进行交互建模的特征提取这两大优点进行优化改进,提出了一种双线性聚合残差注意力网络模型(BARAN)。该网络模型主要由两部分组成:一是结合分散注意力的双线性聚合残差网络(bilinear aggregate residual network,BARN);二是互通道注意力模块(MCA)。如图2 所示。
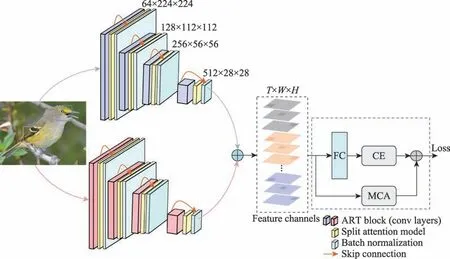
图2 双线性聚合残差注意力网络架构Fig.2 Bilinear aggregate residual attention network
具体而言,首先采用两个ResneXt29 网络分别替换原B-CNN 模型中的VGG16-D 与VGG16-M,作为图像的特征提取器,使其设计成一种新颖的双线性聚合残差网络(BARN),来完成卷积特征的深度提取;然后为双线性聚合残差网络(ResneXt29×2)中的每一个聚合转换残差子模块嵌入分散注意力模块(SA),整合跨维度的特征通道之间的权重信息,进一步强化整个网络的表征依赖性;最后对两个聚合残差网络分支提取的特征进行多维度的融合操作,得到加权融合后的特征通道图(feature channels map,FCM),使其更加完整性地传递给互通道注意力模块(MCA),来强制每一维度的特征通道按照类别进行划分,使得属于同一类别下的特征更具有判别力,并约束同一类别的特征在空间维度上更加互斥,即关注多样化且具有差异性的细节。通过以上双重注意力过滤捕获策略,能够促使模型学习到更加全面的图像表征知识。
2.2 嵌入分散注意力模块
为了强化特征通道之间的紧密依赖程度,本文方法在聚合残差模块的基础上,把分散注意力模块(SA)嵌入到聚合残差转换子模块(ART)与聚合运算之间。如图3 所示。
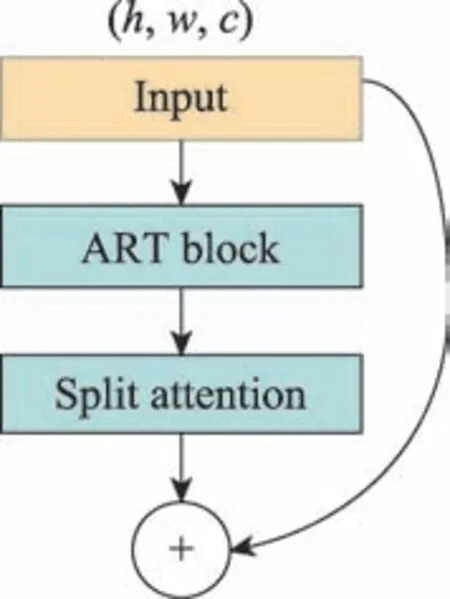
图3 分散注意力模块位置图Fig.3 Location figure of split attention model
本文提出的SA 模块是在SE-Net Block与ResNeSt Block的基础上设计的一种新结构,与ResNeSt Block 不同的是:本文提出的SA 模块的输入是ART Block 的组卷积输出,也就是图1 中1×1 组卷积拆分的特征分量;与SE-Net Block 的输入分量相似,极大降低了ResNeSt Block 因引入另一个超参数的模型参数量以及复杂度。
SA 模块在模型特征提取过程中,为更有效的特征分配权重值,摒弃无效或者效果甚微的特征权重值,减少冗余的特征信息,实现通道间的相关性建模,弥补特征通道之间相关依赖度不足的缺陷,并完成对分散特征进行紧密整合运算;并且通过跨通道之间的特征融合,不同尺度获得的特征进行融合,增强尺度特征的丰富性。并且能够有效防止模型过拟合。
SA 模块的实现原理如下,结合图4 所示。
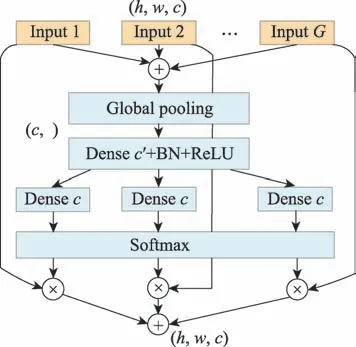
图4 分散注意力模块图Fig.4 Split attention model
(1)全局平均池化(global average pooling,GAP):其中,把聚合残差转换子模块(ART Block)中1×1 组卷积核每一分支的输出作为输入,首先把组卷积拆分的分支进行加权融合,如式(2)所示。

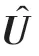
然后,通过GAP 把每一分支进行跨空间维度的融合运算,采用信道统计策略将每一维度特征图的全局上下文信息压缩成单通道描述信息,即使得通道空间维度中×变成1×1 的形式,如式(3)所示。

其中,表示通道空间特征图(×)中的每一个元素,通过进行缩量计算,∈R。
(2)密集连接层(dense connected layers,DCL):SA 模块中共包含两个微型的密集连接层。
首先,通过第一层DCL 以1/的减速比率进行降维操作,以获得更加紧凑的特征向量,紧接着对进行批量标准化(batch normalization,BN)与ReLU激活函数操作,如式(4)所示。

其中,∈R,=max(/,),代表维度的降速比率值,表示的最小值,本文实验中=4。表示ReLU 激活函数,B 表示BN。
随后,进行第二层DCL 运算来恢复维度,再通过Softmax 得到(),如式(5)所示。

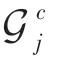
最后,把Softmax 得到的所有特征权重分支向量,与聚合残差子模块中1×1 组卷积核每一分支的输出()进行元素相乘,然后实现跨通道的软注意力的加权融合,得到,使得对应不同空间尺度的特征进行自适应选择,如式(6)所示。

相比单DCL,双DCL 具备更多的非线性运算操作,有利于拟合特征通道间相互依赖程度的复杂性,且极大简化模型的复杂度与参数运算量。
2.3 融合互通道注意力模块
为解决种类间因显著性区域差异较小而导致模型预测出类别信息易混淆等问题,本文在双线性聚合网络与类别预测的全连接层之间融合了互通道注意力模块(MCA)。使得MCA 模块融合到本文的聚合残差网络中使得图像识别度更优异。
MCA 模块通过捕捉多维通道中多样且细微化的特征,减少通道聚焦于无效或最具显著性的部分区域。进而提升模型判别力。具体而言,该模块不是直接从特征图上学习细粒度特征,它主要是从特征通道角度去施加制约条件,使得网络聚焦于通道之间特征与类别的映射关系,以捕获多样化且迥异的细节信息,进而学习粒度级别的特征,并且在没有引入额外的参数前提下,能够使得模型鲁棒性更强。
互通道注意力模块(MCA)包含两个不同的注意力子模块:判别性子模块()和区分性子模块()。由双线性聚合残差网络提取的特征图作为MCA 模块输入,分别输入到两个子模块中。在判别性子模块中,通过约束通道活性以及类别分组划分这两步操作,使得同一类别下的特征更具判别特性;在区分性子模块中,通过对所有信道进行相似度的匹配计算,使得同一类别下的信道关注点映射到不同的可区分部位,强化特征关注的多样性,进而减少冗余通道信息。如图5 所示。
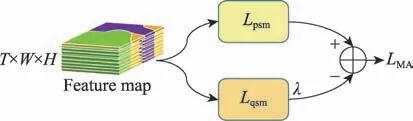
图5 互通道注意力模块分支图Fig.5 Branch of MCA model
图中,=×,代表总空间维度数,代表数据集中的类别,代表特征图的通道数,、分别代表每个特征图的宽度、高度。且在特征图中,不同的通道代表了同一类别中极具依赖性的关联信息,因而,每一类()都会由一定数量()的特征通道组表示。
通过判别性子模块与区分性模块各自分量进行加权求和,得到更有效的分类特征图;使得互通道注意力模块更加突出地捕获到同一类别下多样化的判别区域。原理由式(7)所示。
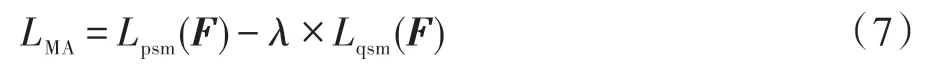
其中,为超参数。
MCA 模块中的判别性子模块与区分性子模块是互补的关系,并且区分性子模块不能脱离判别性子模块单独存在。
判别性子模块会迫使特征通道进行类对齐,并且每一个特征通道对于每一个类的特征应该具有足够的差异性,进而使得网络学习到的区域更具识别度。
判别性子模块由四部分构成,如图6 所示。
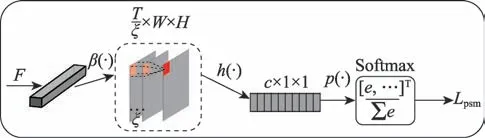
图6 判别性子模块Fig.6 Discrimination submodel
(1)通道注意力(channel-wise attention,CWA):其主要是为可区分性的特征通道优先分配软性注意力概率值。具体就是通过对每一类特定的(/2)特征图进行随机失活(即通道值归为0)掩膜操作,并与原特征图进行点乘运算;这一操作在每次迭代训练过程中会为每组特征图随机选择部分通道,分配权重值,能够迫使网络从每一个类别的所有特征通道()中捕捉到更具有判别力的区域信息。
(2)跨通道最大池化(cross-channel max pooling,CCMP):主要实现每组特征图的跨通道映射池化操作。相较于跨通道平均池化,它会对组特征图的权重进行平均化操作,进而会从很大程度抑制局部显著区域的识别,而CCMP 能够更有效地把组特征图()中所有通道的最大值投射到同一特征图上(/),来实现跨通道权重信息最大响应化运算,同时实现类别的通道降维。
(3)全局平均池化(GAP):主要实现对每个组特征图的平均池化响应操作。它能够约束每一类别的特征权重值映射到一个元素上,最终变成一个一维的向量(×1×1),进而完成通道维度的降维操作。
(4)Softmax:通过计算得到该类别的预测概率值,即全局平均池化得到的类别向量与所有类别的加权和进行比值运算;最后通过交叉熵损失评估与真实标签的匹配度,得到判别性子模块的输出分量。具体由式(8)计算得到。
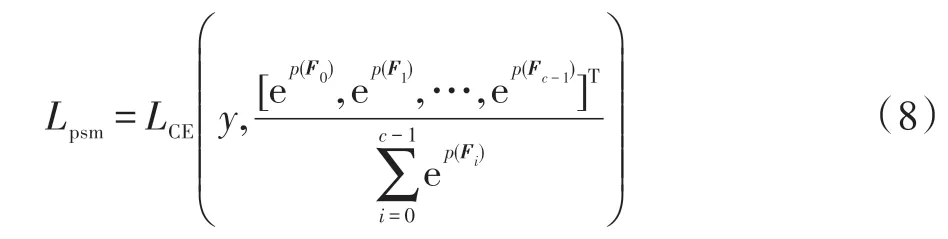
其中,代表分类的类别,(·,·)表示交叉熵损失,表示真实标签类别,Softmax 对输入的样本图像类别进行预测。计算出真实类别与GAP 输出之间的损失值。
式(8)中Softmax 中每一个类别的预测值由式(9)可得。

其中,(·)代表的就是全局平局池化每一类特征图的子分量值。

式中,(·)表示CCMP。式(11)中(·)表示CWA,其中M=diag(Mask),Mask代表一半组特征图(/2)进行随机的掩码操作,并对其取对角矩阵。
区分性子模块通过每类特征通道的特征相似度来约束通道特征,使其在空间维度上保持互斥性。具体而言,区分性子模块通过驱使模型的特征权重注意点,针对性地去捕获每一类别中显著且可区分的细节特征,使得特征图中有效的权重信息分布在不同的区域,进而学习到同一类别中更加多样化且具有可区分特性的类别信息,并从空间与通道两方面,对无关特征或者冗余信息区域进行丢弃操作。
区分性子模块由四部分构成,如图7 所示。
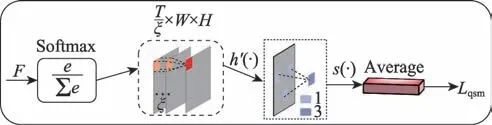
图7 区分性子模块Fig.7 Distinctive submodel
(1)Softmax:与判别性子模块有些不同,此处Softmax 主要是实现每类的特征通道归一化操作,即通过采用one-hot 编码策略把每一维度的特征通道实现标准化,其中one-hot 编码可以使得每一维度的离散特征之间的距离运算更加简便,有助于每类特征通道的相似度的计算。
(2)跨通道最大池化(CCMP),与判别性子模块的原理相同,都是通过对组特征进行元素的最大值映射,得到每一类的对应的特征图,同时实现降维的过程。
(3)Sum:通过前面跨通道最大池化,可以得到每一类别对应的一张特征图(×1×1);Sum 操作就是实现每一类别上的特征图进行求和运算,来测量每类特征通道的相交程度,从而实现特征的相似度测量。
(4)Average:对得到的所有的特征通道进行平均化操作,最终得到区别性分量,得到的区分性分量越大,说明每类所专注的多样化区域越分散。具体由式(12)计算得到。

其中,(·)代表对每组特征图的加权求和,求和值越大,说明特征之间的差异性越强。
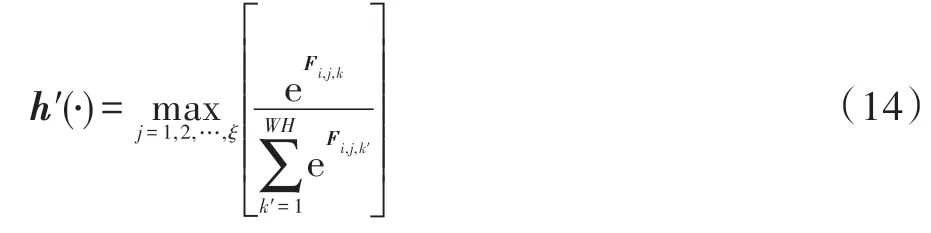
其中,′(·)代表CCMP;代表组特征图数量;′代表每一特征图的通道位置。
3 实验结果与分析
实验系统环境为Ubuntu 16.04,模型训练平台为基于开源深度学习框架PyTorch,硬件配置为NVIDIA Quadro P500 GPU,16 GB 显存,使用两个显卡并行训练,Intel Xeon E5-2620 CPU。并使用CUDA 9.0 与cuDNN 7 对模型进行加速。
3.1 数据集与预处理
为评估本文方法的分类性能,在Caltech-UCSDBirds(CUB-200-2011)、FGVC-Aircraft、Stanford Cars3个细粒度图像分类公共数据集上进行实验验证。其中CUB-200-2011是极具代表性的鸟类数据集,包含200 种鸟类,总共11 788 幅图像;FGVC-Aircraft包含100 种不同类别的飞机图像,共10 000 幅;Stanford Cars 包含196 种不同品牌的汽车图像,共计16 185 幅。这3 个数据集的训练集(Training)与测试集(Testing)的详细信息如表1 所示。

表1 数据集的训练集与测试集信息Table 1 Datasets information of training and testing
以上3 个数据集中每一类样本由60~100 张图像组成,尤其是CUB 的原始图片仅有60 张左右,为了避免模型因数据质量以及数据集丰富性导致过拟合或欠拟合问题,通过对图像进行随机水平翻转(图8b)、垂直翻转(图8c)、旋转(图8d)、平移(图8e)、缩放(图8f)以及引入高斯模糊(图8g)与噪声等方法进行数据扩充,其中水平以及垂直翻转以0.5 的概率进行扩充;每种数据集扩充后数据集将达到原数据集的6 倍左右。如图8 所示。

图8 3 个数据集中训练集的数据增强示例Fig.8 Data augmentation examples of training set in 3 datasets
通过对以上3 个数据集进行适度的数据增强,本文模型能够学习到更为多样化且丰富的样本细节,对模型表征能力的增益效果更好,从而强化模型的泛化能力以及鲁棒性。
3.2 实验评价指标及参数设置
实验评价指标:在细粒度图像分类任务中,为了验证提出BARAN 方法的分类性能,通常会选用准确率作为模型的评价指标,假设实验中各个数据集上的总类别数为,则模型的准确率计算如下:

其中,Acc代表每一类别的准确率;T表示类别分类正确的样本个数;I表示分为该类的样本总数。
模型预训练参数设置:实验过程中,利用随机梯度下降法(stochastic gradient descent,SGD)对模型进行优化以及批量标准化(BN)作为正则化。具体的模型预训练超参数设置:batchsize 设为32,动量(momentum)为0.9,学习率衰减因子gamma 为0.1,学习率衰减间隔(lr_step)为30,权重衰减率(weight_decay)为5E-4,total_epoch 为300,num_classes 根据数据集的类别数量进行动态调整。
MCA 模块中超参数设置:由于本文方法在双线性汇合后输出的是512 维,而输入到MCA 模块的空间维度是由=×决定,假如设定为3 作为每类特征图的基准数量,而根据数据集CUB-200-2011(200 类)、FGVC-Aircraft(100 类)、Stanford Cars(196类)应该分别分配600、300、588 特征通道数,而本文方法输出只有512 维度,因此采用动态的类别通道数分配方法,如表2 所示。

表2 本模型512 维的ξ 通道分配图Table 2 ξ value assignment using BARAN with 512 feature channels
表中,cnums 代表为每一类分配的特征通道数,cgroups 代表对应类别数,比如CUB-200-2011 为前88个类别每一类分配2 个特征通道,为后112 个类别每一类分配3 个特征通道。
3.3 消融实验
为验证本文方法的有效性,本文提出的BARAN方法采用重头训练与预训练卷积网络模型这两种训练方式,来验证本文方法中ResneXt29、SA、MCA 三个模块结构对网络学习能力的影响,并实现网络端到端的训练。
本小节的消融实验主要在CUB 数据集下,对嵌入分散注意力模块的双线性聚合残差网络进行不同基数()情况下的实验对比分析。
通过使用在ImageNet 上预训练的B-CNN 与ResneXt29 两个网络进行模型的迁移学习,改进优化为本文的双线性聚合残差模型,并对双线性聚合残差中所有层进行微调。此部分消融实验仅针对CUB数据集进行模型训练,来验证改进后的性能。数据集中的每一张图片采用中心裁剪的形式,将每张图片调整大小为448×448,初始学习率设为0.000 1,total_epoch 为80,weight_decay 为1E-5,其他参数与参数设置一致。
与原B-CNN 模型相比,虽然模型复杂度有所增加(表3 中Params代表每一分支参数量),但BARN 分类精度有显著性提高,其中BARN(2×64d)、BARN(4×64d)、BARN(8×64d)提高了0.007、0.011、0.014。而本文方法使用的ResneXt29(32×4d)提升了0.018。表3 为在CUB-200-2011 数据集上的实验结果。
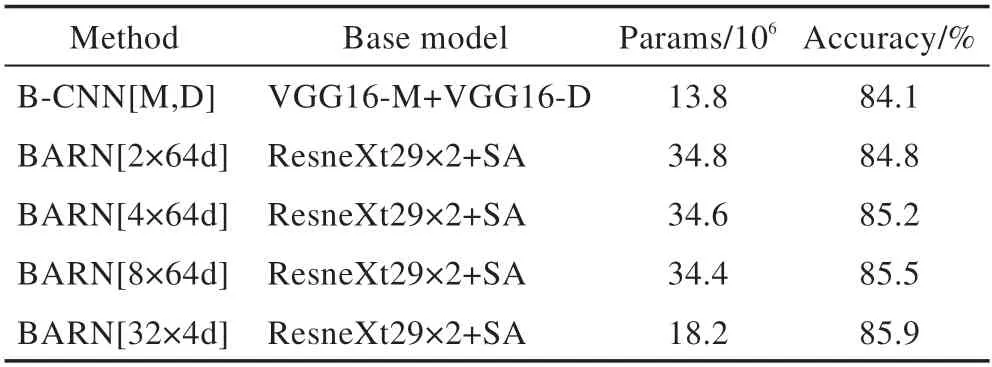
表3 嵌入SA模块的ResneXt在不同基数下的实验对比Table 3 Experimental comparison between SA module and ResneXt under different cardinality
由于聚合残差网络中引入一个新的超参数,并且在保持模型复杂性不变的情况下,随着基数从2增加到32,模型的训练误差在不断降低,相对于原BCNN,表征能力更优异,通过基数这一超参数的实验表明,多路拓扑并行的分组机制(multi-path topology parallel,MTP)进行细粒度图像分类的特征捕获效益更强,网络表征能力更好,且加入SA 之后特征通道之间紧密度更高,使得模型表示效果更优异。
为了验证互通道注意力模块中判别性子组件与区分性子组件对于整个网络的捕获特征能力的影响,本小节的消融实验对主干模型采用从头训练的模式,在双线性聚合网络的基础上,对每一个单独的组件进行实验训练。
输入的图像数据的大小采用中心裁剪的方式调整为224×224,整个网络架构的初始学习率设为0.1,并且在迭代轮数epoch 为150 到225 次的时候动态调整为0.01,其他的参数与预训练模式设置的一样;此外,为了使得互通道注意力模块的每一组件验证的合理性,超参数进行固定设置,其中=0.005,=10,根据表2 进行设置。
如表4所示,以嵌入SA模块的双线性聚合残差网络作为基准网络,MCA 模块中两个子模块进行并行训练,在CUB-200-2011、FGVC-Aircraft、Stanford Cars 3 个数据集上分别达到66.47%、89.90%、91.34%。经过分析,在仅使用CWA、判别性子模块的情况下,在3个数据集上性能相差不大;而在仅使用区分性子模块时,在3 个数据集上分别达到27.35%、79.88%、70.23%,相比仅使用CWA、判别性子模块分类性能相差十分明显。主要是由于区分性子模块实际上是在判别性子模块损失的基础上作为正则化器,隐式地去发现每一类图像中不同的可区分的区域,尤其是针对像CUB-200-2011 这样特征差异微小的数据集表现更具优势;因此单独使用区分性子模块会导致分类器判别能力较差。

表4 MCA 模块不同组件部分的消融实验对比Table 4 Ablation experiment of different components of MCA module
鉴于以上分析,互注意力模块中区分性子模块依赖于判别性子模块,在进行只有区分性模块训练时,训练结果偏差过大,尤其是在CUB-200-2011 数据集上尤为明显。通过不同子模块的训练结果显示,判别性与区分性子模块进行并行训练特征选择效果更好。
为了验证本文方法的优越性,在相同的实验条件下,与流行的PC、MaxEnt 等同样使用双线性网络方法进行分析对比,还与同样使用注意力机制的DFL-CNN、TASN 等方法进行性能比较,实验表明,本文方法优于大部分主流模型。
输入的图像大小以中心裁剪方式调整为448×448,且本文模型使用在ImageNet 上预训练好的ResneXt29(32×4d)网络,嵌入到B-CNN(baseline)进行改进训练。其中,预训练模型的学习率在卷积层(即特征提取层)定为0.000 1,全连接层设置为0.01,并且在迭代到150~225 次的时候,设置为0.000 01,避免模型过拟合以及梯度消失等现象,模型迭代300次,权重衰减率保持为5E-4,其中互通道注意力的超参数=0.005,=10。代表权重系数,是输入到全连接层之前的互通道注意力的制约系数。
对不同弱监督细粒度分类的流行方法进行实验分析:本文方法在Stanford Cars 数据集上达到精度最高,为94.7%,相对原模型提升了0.034;与性能最优的DCL模型相比,提高了0.006;其次是在FGVC-Aircraft数据集上准确率为92.9%,相较于DFL-CNN 方法,提升了0.012。而在CUB-200-2011 数据集上,虽然没有WPS-CPM 方法得到的准确率高,但是相对于其他方法略显优势。尤其是基于B-CNN 网络的成对混淆(PC)与MaxEnt 方法与本文方法类似,本文方法相比PC、MaxEnt 方法在3 个数据集上分类性能更优异,比MaxEnt(B-CNN)、PC(B-CNN)、PC(DenseNet161)分别高出0.026、0.023、0.01。如表5 所示。

表5 不同弱监督细粒度图像分类方法实验对比Table 5 Experimental comparison of different weakly supervised fine-grained image classification methods
鉴于以上分析,本文BARAN 方法在不需要引入额外参数的情况下,融合SA 模块以及MCA 模块之后,仅需要类别标签,就可以在这三种公共数据集上表现出良好的性能优势。
相比WPS-CPM 方法,在CUB-200-2011 数据集上没有表现出本文模型的竞争性,最主要的一个原因是每类的特征通道的缺乏,使得每个类别学习到混淆信息可能存在缺失。下面将从两个角度详细介绍性能差异的原因:
在不同数据集上对类别通道设置情况进行实验性能分析:在CUB-200-2011 数据集上,虽然相对大部分的先进方法都有很大的性能提升,但相比个别先进方法,或者其他数据集,并没有表现出更高的性能优势,其中一个重要原因是维度不足导致特征通道分配不均。由表2 可知,CUB-200-2011 中前88 个类别仅仅只占两个通道信息,而鸟具有多样化且丰富性的局部区域,因此,在特征通道数不足的情况下,无法获取更加鲁棒性的信息描述,会出现性能精度相比WPS-CPM 方法较差的结果,而且也不如本文方法在其他数据集上的性能表现。虽然Stanford Cars数据集中有76 个类别占有两个特征通道,但是车图像中含有较少的差别区域,因此,性能相比具有差异性区域较多的鸟类会更高,其中引入的互通道注意力模块,可以自适应地调节通道分配机制,避免无效特征通道占用现象,进而弥补在不同通道输出(本文输出通道512 维)情况下的识别精度不足问题。
从参数设置以及网络结构角度进行实验分析:从参数设置角度,本文选用的bachsize 为32 而不是64,每次迭代输入的图片批量大小会影响模型训练的学习能力,进而降低分类性能。从网络结构角度,若本文方法最后输出进行层数递增,输出维度也会增加,以上问题会根据输出维度不同,最终的识别能力也会有所增强,但由于卷积层数的堆叠递增,会出现模型梯度弥散以及实验环境GPU 算力受限等问题,因此本文最终选定ResneXt29 进行改进。
本小节通过类激活可视化(Grad-CAM)的方法对模型的识别分类性能进行验证,该方法作为模型判断图像类别的依据,能够更加清晰地说明类激活图与分类的映射关系。
为了验证本文模型的有效性以及拟合度,本小节测试的实验数据来自各个数据集的测试集中,以可视化热图形式标明嵌入不同模块后,模型预测出的判别性区域位置。如图9 所示,热图中高亮的区域(红色)代表与预测类别的相关区域,热图中制约预测类别的判别区域越多越准,模型对图像的识别准确率越高。
BARAN 模型融合各个模块的可视化对比分析:如图9 所示,第一列代表待识别的原图像,第二列为B-CNN 原模型生成的热图,第三列为ResneXt29×2+SA 生成的热图,第六列为ResneXt29×2+SA+MCA 生成的热图。双线性聚合残差网络模型较B-CNN 感受到更多的区域信息,使得模型置信度更高,有效弥补了原模型的表征能力以及特征融合单一化问题。融合MCA 模块后,整个网络关注的多样化信息更丰富、更精细,进而验证了MCA 模块更能识别出具有互斥的部件区域。

图9 各个模块在3 个数据集上生成的热图对比Fig.9 Comparison of heat maps generated by each module on 3 datasets
MCA 模块中判别力子模块与区分性子模块的可视化对比分析:为了验证区分性子模块依赖于判别性子模块,如图9 所示,第四列为ResneXt29×2+SA+,第五列为ResneXt29×2+SA+,由热力区域表明,判别性子模块提取的特征区域相比区分性子模块更多,而仅由区分性子模块进行分类,热图中显著性区域更加离散、微小。通过第四列、第五列、第六列热图区域分散程度对比,两个子模块进行辅助学习,模型表现得更精准。
4 结束语
针对细粒度图像分类任务中种类间差异性呈现出的微小区别,造成模型捕捉可判别性特征的能力不足,特征通道之间的相互依赖关系较差以及无法有效学习到显著且多样化的特征信息等问题,本文提出一种双线性聚合残差注意力网络模型。通过改进原双线性网络(B-CNN)中的特征提取函数,增强网络表征能力;然后在此基础上,引入两个注意力模块,其中,分散注意力专注于解决模型在提取过程中特征权重值分散问题,加强特征通道依赖程度,并实现多维特征融合;互通道注意力通过判别性与区分性子模块实现互补性提取可区分性与多样化的易混淆特征信息,避免无效特征影响分类性能;实验表明,本文提出模型相比其他方法更能有效地提取关键性且多样化的判别性信息。在未来工作中,将致力于联合图像空间语义信息弥补高阶特征的缺失问题以及使用合适的正则化方法减缓梯度弥散现象,进一步提高细粒度图像分类性能。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
数学物理学报(2021年3期)2021-07-19 06:02:32
高技术通讯(2021年1期)2021-03-29 02:29:24
电脑与电信(2018年11期)2018-02-16 05:41:32
小天使·五年级语数英综合(2017年3期)2017-04-25 13:15:13
读写算·小学低年级(2017年1期)2017-02-06 15:40:18
信息安全研究(2016年3期)2016-12-01 06:06:41
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
