
注意力机制与复合卷积在手写识别中的应用
2022-04-13 02:40:36卓天天桑庆兵
计算机与生活 2022年4期
卓天天,桑庆兵
江南大学 人工智能与计算机学院,江苏 无锡214122
脱机手写识别处理的手写文字来自扫描仪或相机等设备采集到的数字图像,与联机手写不同,不包含在线书写获取到的书写轨迹等其他信息。1990 年起,对于脱机英文手写字符识别的研究取得了一定的进展,商业上也出现了一些可用的系统用于识别邮件地址或银行支票数字。基于图像矩特征、基于图像结构特征、基于主成分分析特征(principal component analysis,PCA)等多种方式可提取出孤立字符图像的特征,再将其送入分类器识别。后Liu 等人对于近邻、贝叶斯分类、神经网络和支持向量机谁是最好的分类器进行了比较,结果也是取决于具体的特征分布。不过经过了长时间的发展,如今的单字符识别已经达到了非常高的准确率。
脱机英文手写单词的识别难度要高于孤立字符识别。词识别的一种方法是先将单词图像切分成多个字符图像,之后对每个单“字”识别后将其连接。这种方式依赖于字符的切分效果,然而在实际情况中由于手写体的书写随意、风格无规律,很难找到完美的切分方法。后来研究者们提出了其他方法,如先在小词表上对单个单词建立分类器,将识别的对象改为整个单词而非单个字符,或将切割的单元改为更小的称为“字素(类似语音识别中的音素)”的单元而不是单个字符,并在此基础上进行识别。此外还有基于隐马尔可夫模型的方法(hidden Markov model,HMM),这种方法也是对整个单词建模,但不同于第一种方法对特征的提取,HMM 使用一个滑动窗口对每一帧数据提取特征,而且对图像的长度也没有要求。
在分类任务中,鉴别模型的效果要优于HMM 这种生成模型。人工神经网络作为一种受生物学启发的鉴别模型近年取得了飞速发展。循环神经网络(recurrent neural network,RNN)是传统神经网络的变形,可用于提取图片的序列特征。Shi 等人将卷积神经网络(convolutional neural network,CNN)与RNN结合为卷积循环神经网络(convolutional recurrent neural network,CRNN),它直接在粗粒度的单词标签上运行,在训练阶段不需要详细标注每一个单独的字符。基于CRNN 的脱机英文手写单词识别能够获取不同尺寸的输入图像,并产生不同长度的预测。
CRNN 虽解决了文本标签不易对齐问题,但在处理脱机手写文本上,由于书写者的书写风格迥异,原网络提取出的特征表示力不够,泛化性弱。为解决上述问题,本文在CRNN 基础上引入了加强型卷积块注意力模块和复合卷积,构建了一种新的特征提取网络。
1 基于加强型卷积块注意力模块与复合卷积的手写文本识别网络
当前处理脱机手写文本识别的主流框架有两种,CRNN+CTC 框架与CNN+Seq2Seq+Attention 框架。第二种Seq2Seq 属于encoder-decoder 结构的一种,其利用一个RNN 做编码,压缩序列到指定长度的状态向量;另一个RNN 做解码,再根据输入的状态向量生成指定的序列。比起需要两个RNN 分别做编码和解码,CRNN 中只需要一个RNN,一定程度上减轻了模型的参数压力。而且Seq2Seq 为解决不定长序列的对齐问题引入的Attention 机制限制较大,因此CRNN 的使用更为广泛。本文采用的网络结构是基于注意力机制的CRNN+CTC 框架,具体的结构为CNN(其中嵌入注意力机制)+BLSTM+CTC,如图1所示。
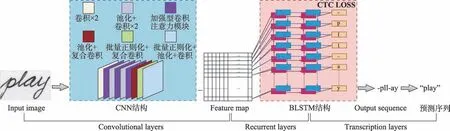
图1 基于注意力机制和复合卷积的CRNN+CTC 框架Fig.1 CRNN+CTC framework based on attention mechanism and composite convolution
本文的贡献主要是对CNN 结构部分的改进。首先将输入图片大小规范为32××,等比例缩放不会破坏文本细节,经加入注意力模块的复合卷积神经网络后得到高级语义特征图∈R,然后将特征图转置为′∈R并将′的列向量依次输入到双向长短期记忆神经网络(bidirectional long short term memory network,BLSTM)中继续提取文字序列特征,其中BLSTM 选择stack 形深层双向架构,支持不定长输入。最后使用优化算法优化CTC损失。若使用Softmax cross-entropy loss,则每一列输出都需要对应一个字符元素,然而在实际情况中很难做字符对齐,因此CTC 提出了一种对不需要对齐的LOSS 的计算方法。CTC 引入了“blank”输出标签并将其添加到BLSTM 的输出层,很好地减轻了网络预测不确定、未完全对齐的字符标签的压力,一定程度上解决了两个相邻单元的混淆性。
将训练样本视为给定输入特征和目标字符串,CTC 的目标函数定义如下:

其中,表示整个训练集,(|)表示在给定输入特征下BLSTM 预测出目标字符串的概率,其定义如下:

其中,表示将输出路径即带“blank”标签的路径转换为目标字符串的运算符,(|)为给定输入特征,输出路径为的条件概率,其定义如下:
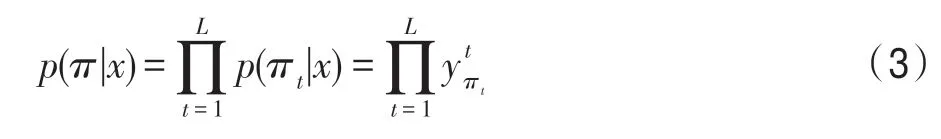
其中,表示输出路径的长度;π表示在时刻输出的路径;y表示在时刻的BLSTM 输出。
1.1 加强型卷积块注意力模块
注意力机制模拟了人眼的视觉感知从而更加关注有用信息,部分人群在书写时存在拖拽问题,如图2 所示。图2(a)中的字母“u”由于书写拖拽可能被网络识别成“w”,而图2(b)中字母“o”可能被网络识别成“a”。
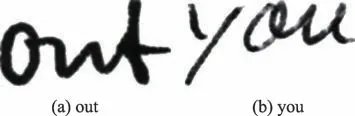
图2 存在书写拖拽的脱机手写单词图片Fig.2 Offline handwritten word pictures with writing drag and drop
不规范的书写会严重影响网络的判别力,在卷积神经网络中添加注意力模块可以有效提升模型对关键特征的提取能力,减小拖拽笔迹信息的权重输入。Woo等人在2018年提出的CBAM(convolutional block attention module)通过通道、空间注意力模块的串联模式实现了跨通道和空间信息提取到有用特征。
CBAM 结构如图3 所示,输入特征图依次通过通道、空间注意力模块获取到细化特征图(refined feature),此细化特征图可看成在通道、空间两个维度上提取出的重要特征。但在此策略中,空间注意力模块的输入特征是通道注意力模块的输出特征,因此空间维度上的特征有效性间接依赖于通道注意力模块的权重最优解。此外,原始输入特征图语义信息亦丰富,对原始特征的利用程度也将影响到注意力模块的性能,而CBAM 仅在通道注意力模块中使用原始输入特征。综上考虑,本文提出了加强型卷积块注意力模块(下文简称CBAM)。CBAM结构如图4 所示,其取缔了CBAM 中先将输入特征图送入通道注意力模块,再将输出结果送入空间注意力模块的串联方式,而是需要输入的特征图同时经过通道注意力和空间注意力模块,并联地获取到各自的注意力映射()和(),之后分别与输入特征图做点乘得到通道注意力特征图和空间注意力特征图。获取()和()的细节如下:

图3 CBAM 结构Fig.3 Structure of CBAM
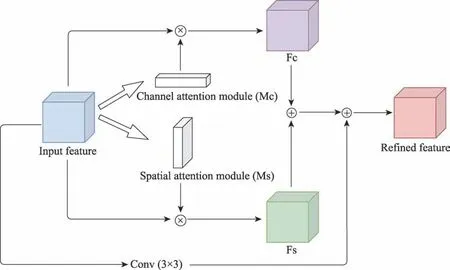
图4 CBAM+结构Fig.4 Structure of CBAM+
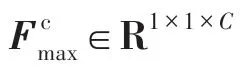
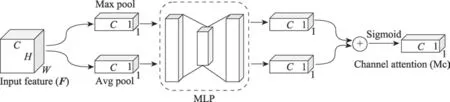
图5 通道注意力模块结构Fig.5 Structure of channel attention module
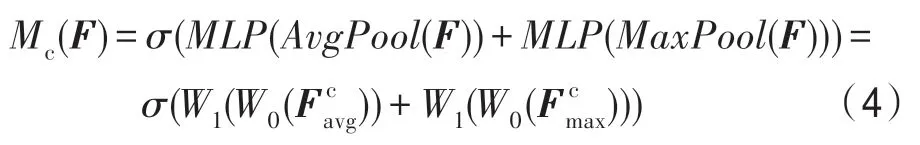
其中,后使用了ReLU 作为激励函数,表示Sigmoid 激活函数。
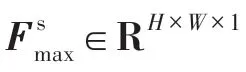
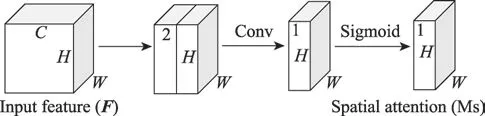
图6 空间注意力模块结构Fig.6 Structure of spatial attention module
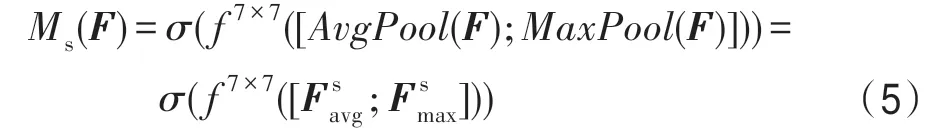
其中,表示7×7 的卷积层。
最终的细化特征图在、()、()的基础上进行计算可得,过程如下:
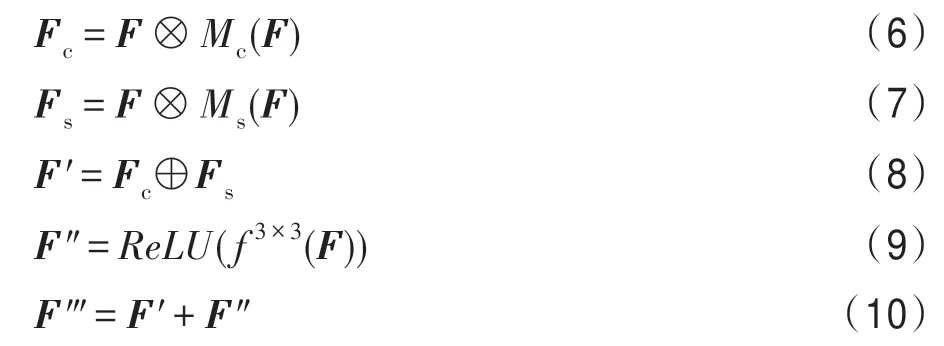
其中,表示通道注意力特征图;表示空间注意力特征图;‴表示细化特征图。
注意力映射()和()在经过sigmoid 函数后将特征值限制到0~1 范围,与输入特征图点乘可以在增强有用的特征表示的同时抑制无用特征的干扰。和相加后生成了3D 的注意力特征图。比起传统的CBAM,避免了先经过通道注意力模块再经过空间注意力模块后()对()可能存在的部分权重系数干扰。对输入特征图的卷积一方面让模型自行选择对输入特征图的响应权重,另一方面除了空间注意力模块中的7×7 卷积核,额外的3×3卷积核使得CBAM融入多感受野,信息更加丰富。3D 注意力特征图与输入特征图的卷积结果相加得到最终的细化特征图。
BAM(bottleneck attention module)指出将注意力模块置于每个池化层之前可以在每个stage 之间消除类似背景语义特征的低层次特征,聚焦高级的语义,因此将CBAM同样置于池化层之前。
1.2 复合卷积
可通过其自主学习的能力提取出图片的有用特征是卷积神经网络的主要特点和优势,在CRNN 中32××大小的图片经卷积神经网络下采样后得到1×(/4)×512 大小的特征图,但这种网络结构采用的是顺次连接的方式,并不能很好地提取出图像的细微特征。对于脱机英文手写单词图片的识别来说,网络提取细微特征的能力对最后的识别精度有着非常重要的影响。
卷积神经网络的深层特征语义信息丰富,如何利用深层特征决定着网络表达能力的强弱。复合卷积指在深层卷积层中以双通道卷积提取特征结构替换原本的单通道卷积结构,之后以相加方式处理双特征图。复合卷积可对深层特征进行重利用,进一步提升网络对语义信息的判别能力,同时不同尺寸的卷积核提取多尺度特征,对于书写风格因人而异的脱机手写单词来说,复合卷积结构能学习到不同人的书写细节,一定程度上提升模型的泛化性。图7为将原CRNN 中部分深层卷积层替换为复合卷积层的新CRNN 结构。
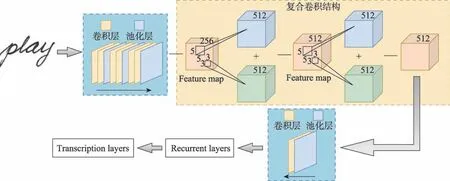
图7 复合卷积CRNN 结构图Fig.7 Schematic diagram of CRNN with composite convolution
2 实验结果及分析
2.1 数据集
为充分验证算法的有效性,本文在两个不同的数据集上进行实验。其中,IAM 脱机英文手写数据集由657 个不同作者手写的1 539 个扫描文本页面组成,对应于从LOB 语料库中提取的英语文本。每张文本页又按文本行和单词切分。RIMES 数据集包括12 723 个手写页面,对应于2~3 页的5 605 封邮件。该数据集已在ICDAR 和ICFHR 的众多比赛中使用。它包括51 739 个要训练的单词,7 464 个要验证的单词和7 776 个要测试的单词。由于数据集中部分单词标签有误,为避免模型的不收敛,各从中筛选出标签无误的单词图片23 914 张,其中22 010 张作为训练集,1 904 张作为验证集。表1 是部分数据及标签示例。

表1 数据集示例Table 1 Examples of dataset
2.2 评估方法
本文采用的是端到端的识别,输入脱机英文手写单词图片,直接输出图片的识别结果。
字符错误率(character error rate,CER)是手写体文本采用的标准性能指标。CER 计算Levenshtein 距离,它是将一个字符串转换为另一个字符串所需的字符替换,插入和删除之和再除以真实标签中的字符总数字。本文采用批量验证,因此将批量图片的CER 均值作为性能评价标准,计算公式如下:
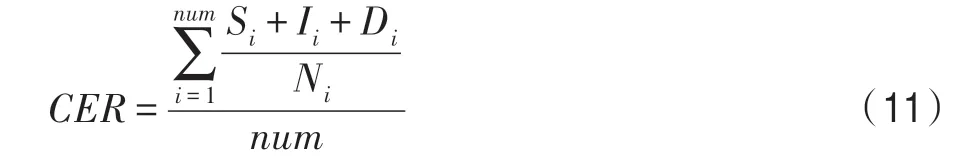
其中,S表示第张图片识别结果的字符替换个数;I表示第张图片识别结果的字符插入个数;D表示第张图片识别结果的字符删除个数;N表示第张图片标签字符串的字符个数;表示验证集中的脱机英文手写单词图片总数,本文中取1 904。
除CER 外,本文还引入识别准确率,计算方法如下:

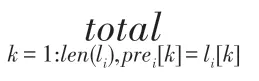
2.3 实验过程与结果分析
实验运行环境:CPU IntelCorei7-8750H@2.2 Hz;GPU NVIDIA GeForce RTX2060;内存16 GB;程序代码在Windows 系统Tensorflow1.13 框架下编写运行。
实验过程采用先训练后验证的方式,每次迭代后输出CTC 损失值。训练完成后将验证集中所有图片按批次全部送入模型识别,最终输出准确率。由于验证集中的图片不参与训练,极大地提高了实验结果的可信度。
为了进一步增强实验结果的可靠性,将训练参数做统一规范:优化方式使用学习率指数衰减的Adadelta,初始学习率设为0.1,每2 000次迭代进行一个0.8 的学习率衰减。batch_size 设为16,共进行30 000次迭代。
基于CBAM和复合卷积,搭建了如表2 所示的CRNN+CTC 脱机文本识别框架,其中在一些卷积层后添加批标准化(batch normalization,BN),通过规范数据分布来避免梯度消失带来的训练困难,BLSTM中隐藏层单元为256。
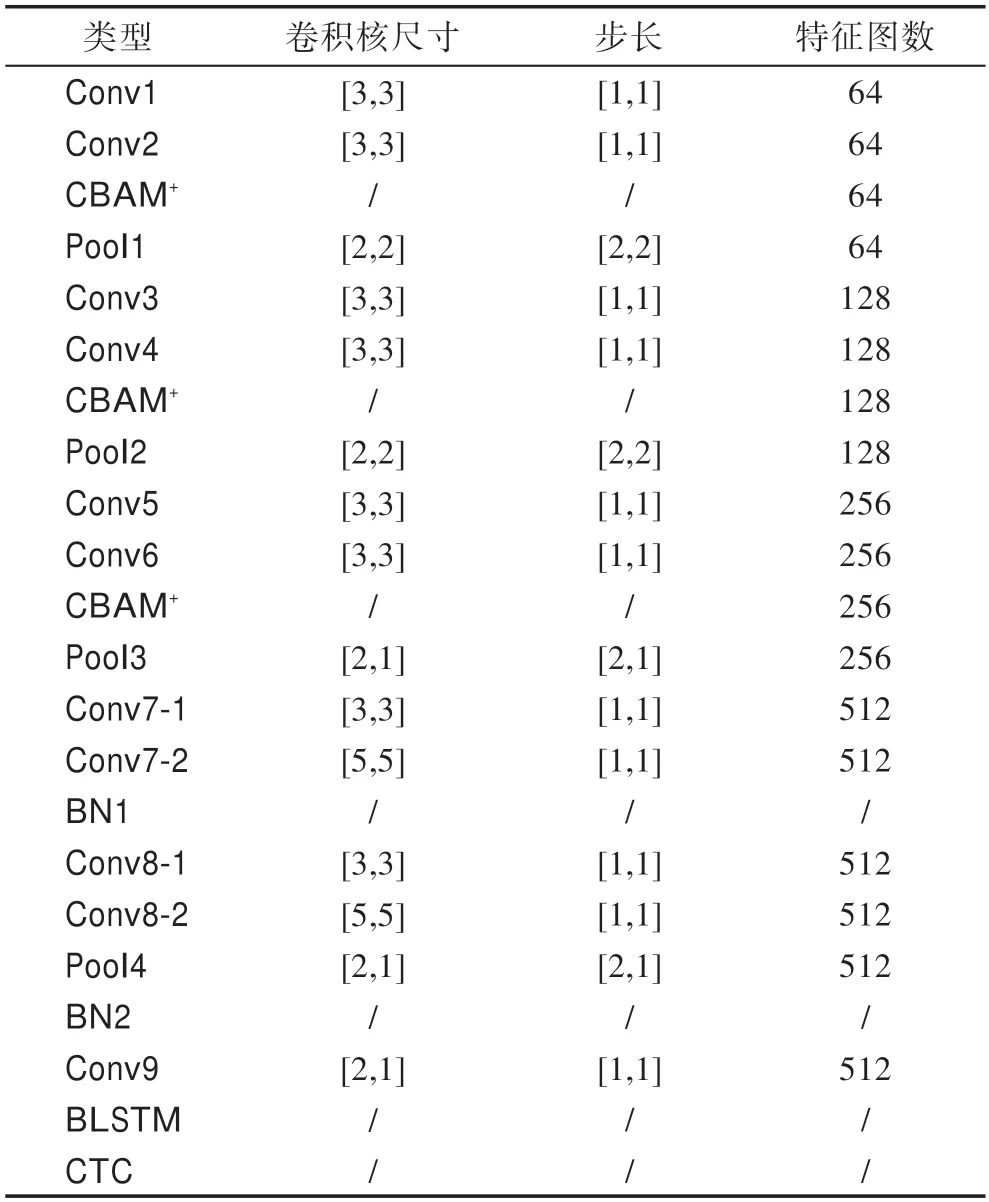
表2 本文提出的基于CBAM+和复合卷积的CRNN+CTC 框架Table 2 CRNN+CTC framework based on CBAM+and composite convolution proposed in this paper
2.3.1 CBAM消融实验
为验证CBAM对模型的性能提升,本小节设计了CBAM消融实验。在最终模型的基础上删除CBAM,删除组件前后的两模型的性能对比如表3 所示,其中拥有CBAM的最终模型在识别准确率和字符错误率上的表现都优于无CBAM的模型,由此验证了CBAM的有效性。
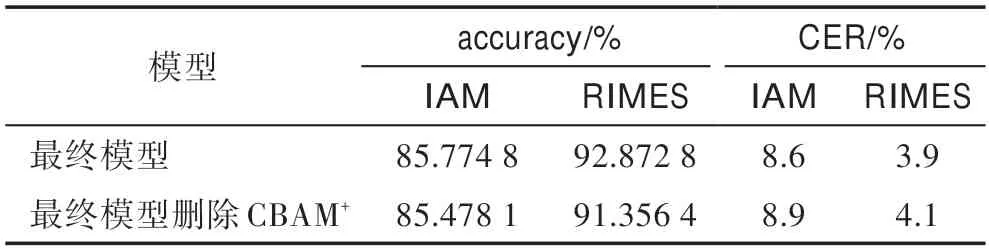
表3 删除CBAM+前后的模型性能对比Table 3 Performance comparison of models before and after deleting CBAM+
CBAM中涉及两类卷积核尺寸问题:空间注意力模块中×尺寸的卷积核以及对输入特征图卷积的×尺寸的卷积核。本小节对于、的最优选择进行了实验,实验中还对比了传统CBAM 对模型的性能影响,如表4 所示。

表4 不同注意力机制、参数对模型的性能影响Table 4 Impact of different attention mechanisms and parameters on model performance
从表4 中可以看出,传统CBAM 中先使用通道注意力再使用空间注意力的方式确实对模型性能有一定的提升,但本文提出的CBAM既使用了双注意力模块,在对输入特征图的处理上又融入了多感受野,不同尺度的特征融合进一步提高了网络模型的表达能力。当=7,=3 时,CBAM对网络性能的提升最大。
2.3.3 CBAM的效果可视化
为更加直观地看出CBAM对有用特征的提取能力,本小节实验比较有无CBAM的模型经同一卷积层后的输出特征图区别。如图8 所示,从上到下依次是原图、输出特征图在通道维度上取平均的特征图以及为更直观地看出特征提取效果,增强对比度后的特征图。

图8 有无CBAM+的模型经同一卷积层后输出特征图对比Fig.8 Comparison of feature maps with or without CBAM+after same convolution layer
因为实验将CBAM添加在卷积层的较浅层,所以语义信息还未变得抽象。从增强对比度后的特征图比较可以看出,未使用CBAM的网络未能处理好单词的轮廓信息,字母“W”和“T”未与背景做明显区分。而且字母“E”和“N”之间出现了粘连,这对于网络判别力无疑是一项干扰。而添加了CBAM的网络特征图轮廓鲜明,提取有用特征的能力得到了提升。
为验证复合卷积对模型的性能提升,本小节设计了复合卷积消融实验。在最终模型的基础上删除复合卷积部分,删除组件前后的两模型的性能对比如表5 所示。其中拥有复合卷积的最终模型在识别准确率和字符错误率上的表现都优于无复合卷积的模型,由此验证了复合卷积的有效性。
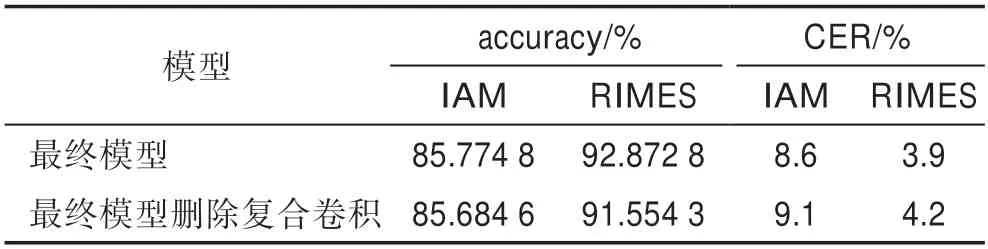
表5 删除复合卷积前后的模型性能对比Table 5 Performance comparison of models before and after deleting composite convolution
本小节首先对复合卷积中双卷积核尺寸的选择进行实验:对3、5 的卷积核尺寸进行两两组合,不同尺寸的组合对模型的性能影响如表6 所示。
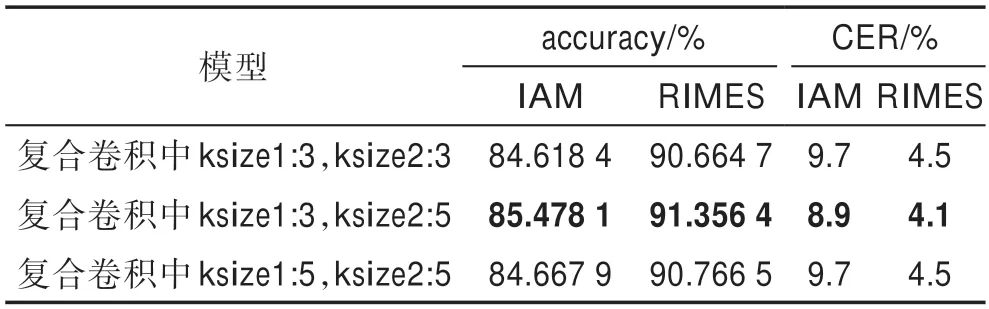
表6 复合卷积中卷积核尺寸对模型的性能影响Table 6 Impact of convolution kernel size on model performance in composite convolution
从表6 中可以看出,复合卷积中如果双卷积核尺寸相同,对模型性能提升不大,3 和5 的卷积核尺寸搭配可以显著提升模型性能。由于不同人的单词手写习惯不同,连笔方式、字体大小也不尽相同,多尺度的卷积核一定程度上使得模型的泛化性更强。
复合卷积中卷积核个数同样对模型的性能存在影响,考虑到参数代价带来的训练困难,只将双卷积核和三卷积核的复合卷积进行性能对比。实验结果如表7 所示。

表7 复合卷积中卷积核个数对模型的性能影响Table 7 Impact of the number of convolution kernels on model performance in composite convolution
从表7 中可以看出,三卷积核的复合卷积效果不及双卷积核,可能存在过拟合现象。双卷积核的复合卷积不仅花费更小的参数代价,而且其模型更加健壮。
消融实验验证了CBAM和复合卷积对网络性能的有效提升。增加网络深度也被认为是提升网络性能的手段,原CRNN 网络中共有9 层卷积层,为了验证CRNN 卷积层数对网络的性能影响进行了以下实验,如表8 所示。
从表8 中可以看出,卷积层层数为9 网络性能表现最好,8 层的卷积层可能存在欠拟合问题,而10 层的网络可能由于深度过深出现了梯度消失引起的训练困难或网络退化问题。
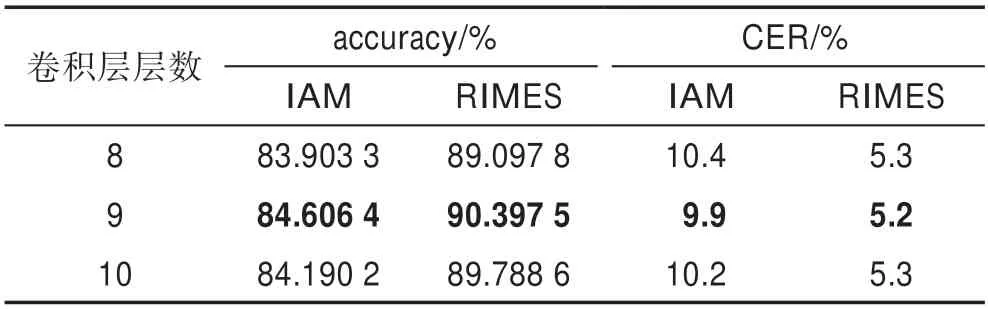
表8 卷积层层数对模型的性能影响Table 8 Impact of the number of convolution layers on model performance
图9 为在训练中改进前后的模型的测试准确率随迭代次数的变化曲线。其中每轮的测试准确率为该批次中从测试集随机抽取的16 张图片的平均识别准确率。从图中可以看出,在10 000 轮之前,改进后的模型的识别准确率提升效果明显,反映出加入了CBAM和复合卷积的模型收敛性更好。此外,模型收敛后的识别准确率较改进前也有所提升。
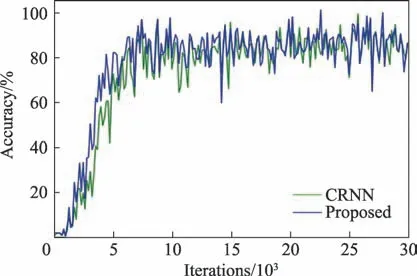
图9 模型改进前后的准确率随迭代次数变化曲线Fig.9 Accuracy of model before and after improvement varies with the number of iterations
表9 为当前几种流行方法在IAM 与RIMES 数据集上的识别表现对比,它们大多对原始数据进行了预处理。Krishnan 等使用了语言模型,在训练模型前先在自己合成的数据上进行预训练。Stuner 等同样使用了语言模型,并在训练过程使用240 万的单词词典(lexicon)。Luo 等提出了新的文本图像增强方法并联合AFDM 智能增强模块一起加入识别网络。Xu 等对原始数据进行预处理(pre-processing),清理了标点符号和大写字母,使用了轮廓规范化并应用了测试扩充。Bluche 等额外使用CTC 损失进行了预训练,获得了更有意义的特征表示。Sueiras 等校正了图像中的线条偏斜和倾斜,根据基线和语料库线条对字符的高度进行了归一化处理。本文的模型与Shi 等、Carbonell 等一样未使用任何预处理、预训练和额外训练数据补充的操作,但是在IAM 数据集上,85.774 8%的识别准确率和8.6%字符错误率识别结果还是比较令人满意的,进一步说明加入了CBAM和复合卷积的新框架更能聚焦有用特征,多尺度卷积在风格各异的脱机英文手写单词识别上表现良好。
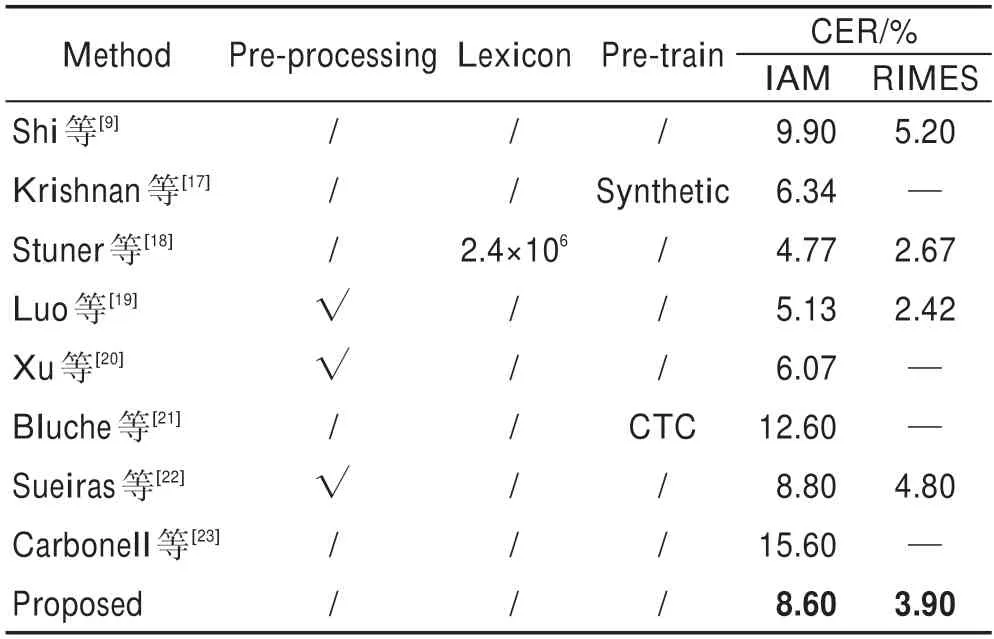
表9 当前流行方法在IAM、RIMES 数据集上的精度对比Table 9 Accuracy comparison of current popular methods on IAM and RIMES datasets
3 结束语
本文将加强型卷积块注意力模块(CBAM)和复合卷积应用到处理文本识别的主流框架CRNN+CTC的卷积层中,特征提取网络采用七层单通道卷积、三层CBAM和两层复合卷积,经这种结构提取出的高层特征表示力强,为接下来提取文字序列特征免除了部分无用信息的干扰,因此针对具有语义信息的脱机英文手写单词数据取得了较好的实验结果。为了进一步提升框架在脱机英文手写单词识别上的表现,接下来的研究工作会优化文字序列有效特征的提取方法,修改成合适的网络结构后重新进行训练。
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
电脑爱好者(2022年15期)2022-05-30 01:29:23
故事作文·低年级(2021年12期)2021-12-21 23:04:39
实用临床医药杂志(2021年7期)2021-05-18 06:40:32
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
中国现代医药杂志(2019年6期)2019-07-31 13:06:56
中国民间疗法(2019年24期)2019-02-12 09:33:22
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
