
结合层级注意力的抽取式新闻文本自动摘要
2022-04-13 02:40:34王红斌金子铃毛存礼
计算机与生活 2022年4期
王红斌,金子铃,毛存礼+
1.昆明理工大学 信息工程与自动化学院,昆明650500
2.昆明理工大学 云南省人工智能重点实验室,昆明650500
随着信息社会进入大数据时代,传统媒体蓬勃发展的同时,自媒体也爆炸式增长。一方面越来越多的新闻通过微博、微信、知乎等各类信息平台涌入人们日常生活,导致人们被大量无用的信息所干扰,例如虚假浮夸、题文不符、繁杂冗余的新闻,言简意赅的新闻摘要可帮助人们提高信息获取效率;另一方面,智能手机、智能手表等小型设备的普及,面对微小屏幕及有限宽带,简短的新闻信息显然更受欢迎。因此,如何运用现有信息技术自动归纳出新闻文本所包含的主要内容具有重要的应用价值,文本自动摘要方法研究成为自然语言处理领域的重要研究子领域,同时也是目前的研究热点之一。
文本自动摘要是指在保证原文关键信息保留的情况下,通过计算机自动总结出简短流畅的新文本。文本摘要按技术主要分为两类,分别是抽取式(extractive)和生成式(abstractive)摘要。抽取式摘要是指从原文中抽取出较为重要的词语或句子组合成摘要,生成式摘要是指为了保证最终摘要的流畅性等,摘要中句子或词语可能不全都来自原文。
抽取式摘要有基于词频、主题识别、篇章关系、图模型等各类方法,这些模型主要依据一些人为设定的抽取因素进行重要程度排序,如选择每段落首句子、含主题句子等方法,虽然能归纳出原文本大意,但不能进行很好的文本向量表示且主观性太强,最关键的是也不能达到很好的摘要效果。近年来,基于端到端的神经网络模型在其他领域如语音识别、语言翻译、图像识别、语音问答都取得了很好的效果,基于神经网络的文本自动摘要技术也得到了广泛关注并取得了很好效果。例如:Nallapati等人提出了一个基于序列分类器的循环神经网络模型;Ren 等人提出结合注意力机制的基于神经网络的层次文档编码模型;Zhou 等人提出基于神经网络的句子抽取与打分相结合的动态抽取模型;Wang 等人提出基于神经网络的自监督学习模型;Liu提出使用BERT(bidirectional encoder representations from transformers)编码构建基于神经网络的二分类抽取模型;Wang 等人提出了基于异构图的抽取式神经网络摘要模型,它包含了除句子之外的不同粒度级别的语义节点。尽管目前基于神经网络的抽取式模型很受欢迎,但基于端到端的神经网络如循环神经网络(recurrent neural network,RNN)、门控循环单元(gate recurrent unit,GRU)、长短期记忆(long short-term memory,LSTM)对文本的记忆比较有限,对重点词语与句子无重点关注,从而影响模型最终摘要效果。注意力机制的提出对该问题的解决有很大的启发。本文提出了基于层级注意力的神经网络动态打分抽取模型,利用神经网络构建抽取模型解决了因人为设定抽取因素带来的主观性太强造成的摘要效果不佳问题,同时利用层级注意力机制解决了文本编码记忆有限及重点词语、句子关注欠佳问题,提高摘要质量。
该模型使用层级编码,第一层依次往双向GRU中输入每句话中的每个词,加以词级注意力,得到句子的向量表示;第二层依次往双向GRU 中输入文章的每句话,加以句子级注意力,得到文章的向量表示;采用双层MLP 作为打分函数,依次输入文本向量表示中的候选句子向量,并每次选出最高分对应句子作为摘要,依次循环选取得到最终摘要。本文不仅在多个公共数据集上与之前得分较好的模型做对比实验,而且将模型本身拆解做了对比实验,最终的层级注意力模型得分较baseline均有明显提高。
本文工作的创新点及贡献有如下几点:
(1)本文将词级注意力与句子级注意力相结合得到层级注意力,并融入到抽取式打分模型中,既考虑到句子中每个词重要程度各异造成句子对摘要影响程度不同,也考虑到文本中每个句子实际对摘要的影响程度。该方法使得该表征向量层次分明,更准确、明显地区分出重要程度较高的句子,也在一定程度上解决了神经网络记忆欠佳问题,并提高了文本向量表示的效果。从而加强了句子对摘要重要程度的准确性判断,提高了打分模型准确性并抽取出更好的摘要。
(2)本文使用公共数据集CNN/Daily Mail、New York Times、Multi-News。CNN/Daily Mail 数据集包含美国有线电视新闻网的新闻文本,该数据集包含匿名版本与非匿名版本,文中使用非匿名版共含英文新闻篇章312 085 篇。New York Times 数据集构建于LDC New York Times 语料库,文中整理出语料库2003—2007 年含有摘要的新闻文本共计149 834 篇。Multi-News 数据集来源于newser.com 网站的大规模多文档长句子摘要数据集,文中使用的是处理后的缩减版本,共含新闻篇章56 216 篇。在实验结果方面,本文与之前的多篇抽取式摘要得分进行比较,实验结果ROUGE 的3 个评测指标都有明显提高,证明了本文模型的有效性与优越性。
1 相关工作
近年来,抽取式摘要方法已被验证有很好的效果。基于统计的方法是文本摘要最早应用的技术,相对于其他方法,基于统计的方法建模容易且易于实现。文献[8]使用词频来衡量句子在一篇文本中的重要性,其思想是频繁出现的单词最能代表文章主题。TF-IDF 基本思想是单词的重要性与它在文本中出现的频率成正比,但与它在整个语料库中出现的频率成反比。通常来说,统计特征会与句子位置、句子长度、句子与文本题目的相似度等其他特征结合使用,以加强对文本单元权重衡量的精确性。
基于篇章关系的方法在文本摘要领域也有广泛应用。文献[12]结合了统计分析和语言学知识,实验表明这种组合方法优于使用单一类型的技术。文献[13]提出了从大规模的语料中提取与输入文档相近主题的文本组成背景语料,使用关键词扩展新闻文本自动摘要的方法。在文本摘要过程中,如果不能识别出文本中的全部实体,会导致指代有歧义的现象。文献[14-15]利用指代消解技术解决这个问题,即首先对文本进行预处理,然后利用指代消解系统将所有代词替换成相应的实体,最后进行摘要。
基于机器学习的方法在文本摘要领域也具有广泛应用,例如文献[16]使用了二分分类器,文献[17-18]使用隐马尔科夫模型进行文本摘要,文献[19]使用贝叶斯方法进行文本摘要。此外,其他机器学习方法在文本摘要领域的应用也很广泛,文献[20]提出了一种单文本摘要系统NetSum,该系统使用RankNet算法计算句子权重,除了利用关键词词频以及句子位置等统计特征外,该系统还融入了维基百科词条以及维基百科用户的搜索记录。文献[22]提出了一种基于查询的多文本摘要系统FastSum,该系统使用最小角回归选择关键特征,并使用支持向量回归技术对句子权重进行排序。文献[23]也使用了支持向量回归技术,并结合单词和短语词频、句子位置等统计特征以及基于语义和命名实体等其他特征共同训练分类器。
基于图模型的方法在文本摘要领域有广泛应用。文献[24]使用基于图模型的搜索方法进行摘要,文献[25]提出了一种基于亲和图解法的文本摘要方法,该方法通过考虑句子间的相似性,结合主题信息抽取出高信息性和高独特性的句子,经冗余削减后生成文本摘要。文献[26]利用N-Gram 图抽取文本中的重要成分。文献[27]使用WordNet 和is-a 关系识别文本中的概念来构建文本图,这种方法在新闻和生物信息领域应用广泛。文献[28-29]提出LexRank 算法使用句子作为图节点,根据句子间余弦相似度构建边,若两个句子无关,则两个句子所代表的节点间就没有连线。文献[30]提出TextRank 算法,该算法在LexRank 的基础上进行了改进,利用余弦相似度对边赋予权值,生成无向加权图并进行摘要。
近年来,基于深度神经网络的抽取式摘要正在兴起。2016 年Nallapati 等人提出了一个新的有监督的摘要模型SummaRuNNer,该模型通过双向GRU分别建立词语级别和句子级别的表示,对每一个句子表示有一个0,1 标签输出,指明句子是否为摘要。2017 年Ren 等人使用了层级注意力计算句子相似度,提出基于篇章关系的抽取式摘要模型。2017 年AAAI 2017 中Yu 等人在序列标注的基础上,使用Seq2Seq 学习一个句子压缩模型,使用该模型来衡量选择句子的好坏,并结合强化学习完成模型训练,提出了Latent 模型。2018 年Ai-Sabahi 等人采用层级自注意力机制,使用逻辑分类层生成每个句子的二值标签,来判断每个句子是否属于最终的摘要文本。2018 年,Zhou 等人提出了一种新的打分方式,使用句子受益作为打分方式,考虑到了句子之间的相互关系,基于已抽取的摘要逐步选择由打分函数打分最高的句子,解决了打分与句子选择割裂问题。2019 年Zhang 等人使用两个预训练Transformer,第一个用于表示句子的标记级别的标准BERT,第二个利用前者的表示来编码整个文件的句子。2019 年Wang 等人提出一种以自监督的方式训练抽取模型的方法,该模型能更快地训练并稍微提高效果。2019年Liu提出用BERT 生成句子向量表示,然后把向量用于二分类并判断去留,得到文本摘要。2020 年Wang 等人提出了一个基于异构图的抽取式摘要神经网络,它包含了不同粒度级别的语义节点,也是第一个将不同类型的节点引入到基于图的神经网络中并用于抽取文档摘要的模型。2020 年,Zhong 等人提出将摘要抽取任务视为文本语义匹配问题,将原文本与候选摘要文本在语义空间中进行匹配,选择匹配度最高的作为摘要,区别于之前大多数都是先独立抽取出部分句子再计算句子之间的相关度的摘要模型。
从上述相关工作可以看出,基于神经网络的抽取式摘要有很强的研究价值,但大部分文章均是先独立简单编码后运用二分类、相似度计算、打分后择优抽取句子等方式构建模型的。Zhou 等人的方法虽然使得句子打分与抽取可以同步动态进行,解决了句子打分与抽取被割裂的问题,但是编码部分处理得又比较简单,不能准确考虑到文章中实际每个句子以及句子中每个词对摘要影响程度及基于神经网络编码带来的记忆不佳问题,从而影响抽取质量。针对该问题,本文提出基于层级注意力的打分与抽取模型,不仅使文本向量表示中每个词、每个句子向量重要程度都有明显区别,提高了文本向量表示效果,而且进一步增强且提高了Zhou 等人提出的打分与抽取同时进行所带来的效果,有效解决了抽取式摘要中人为主观性判别抽取因素不准确带来的抽取效果欠佳问题与神经网络编码带来的记忆不佳问题。具体模型细节与算法见下章。
2 本文模型
本文针对传统抽取式摘要中因抽取因素判断具有较强的人为主观性,不能准确客观评测出文章中实际每个句子对摘要的重要程度,以及句子的每个词对句子的重要程度,从而影响摘要的抽取质量问题,提出了结合层级注意力的动态打分抽取式文本摘要模型。本文模型借鉴了Zhou 等人的打分抽取模型,在层级编码处加入了层级注意力得到最终模型。以下将先简略介绍baseline 模型NeuSum,其次详细介绍本文模型各部分结构。
2.1 NeuSum 模型介绍
本文的baseline 模型于2018 年Zhou 等人在ACL 提出,模型结构图如图1 所示,其含有一个层级双向GRU 编码部分,一个动态打分抽取网络部分。首先,该模型在层级双向GRU 编码部分先将文章中每句话的每个词向量x依次输入双向的GRU 中,并拼接GRU 输出的前向传播隐藏向量与后向传播隐藏向量得到句子向量表示~ ,如图1 左侧蓝色蓝框所示为词级编码部分。其次,将所得到的每个句子向量再次输入双向GRU 中并拼接前向与后向传播的隐藏向量得到文本向量表示s,如图1 左侧橙色橙框所示为句级编码部分。
最后,该模型在动态打分抽取部分使用了一个单向GRU 与双层MLP 网络,如图1 右侧所示。GRU部分主要记录已抽取的摘要,该部分将上一步已选择的摘要句子的向量表示s与GRU 上一步输出的隐藏向量h作为当前GRU 的输入并输出隐藏向量h。MLP 网络主要用来打分,输入为GRU 的当前输出隐向量h与文中剩余句子集合的每一句句子向量表示s,输出为得分最高的句子,即被选择的下一句摘要句子。因初始时,摘要集并无任何句子,所以用图1 右侧橙色橙框的0 向量表示已选择摘要句,结合自定义的初始化隐藏向量进行计算。最后运用MLP 打分后依次选择出每一步得分最高的句子,并将其作为当前已选择摘要句。如图1 右侧依次选出原文本的第5 句向量,第1 句向量,在下一步计算中,剩余文本中第几句得分最高则将该句子序号赋予为argmax 的值并选取该句子为此步计算所得到的摘要句,如图1 中右下部分公式描述所示。

图1 NeuSum 模型结构图Fig.1 NeuSum model structure diagram
2.2 本文模型介绍
本文模型主要分为三部分:第一部分是对新闻文本中每个句子的每个词进行词级编码,然后加以词级注意力,得到句子向量表示;第二部分是对文本中每个句子进行句子级编码,然后加以句子级注意力,得到文本向量表示;第三部分是构建动态打分函数,通过已选择摘要句子与文本剩余句子依次计算得分并选出分值最大的对应句子作为下一个摘要句子。本文模型结构图如图2 所示。

图2 基于层级注意力的抽取式模型Fig.2 Extraction model based on hierarchical attention
如图2 所示,左侧是结合层级注意力的层级双向GRU 编码部分,右侧是动态打分抽取网络部分。左侧蓝色蓝框代表文本句子的词级编码,其加以绿色的词级注意力分布后可得到绿框蓝底的句子级向量。橙色橙框代表句子级编码,其加以绿色的句子级注意力分布后可得到绿框橙底的文本向量表示。图2 右侧,该模型在动态打分抽取部分使用了一个单向GRU 与双层MLP 网络。GRU 部分主要记录已抽取的摘要部分,该部分将上一步已抽取的摘要句子的向量表示u与GRU 上一步输出的隐藏向量h作为GRU 的输入并输出隐藏向量h,因为初始时摘要为空,这里用图2 右侧第一个橙色橙框的0 向量作为初始已选择摘要句向量,结合自定义的初始化隐藏向量图2 右侧蓝色部分进行计算。MLP 网络主要用来打分,输入为GRU 的当前输出隐向量h与文本剩余句子集合的每一个句子向量s,输出为得分最高的句子,即被选择的下一句摘要句子。图2 依次选出了原文本第5 句向量,第1 句向量,在下一步计算中,剩余文本第几句得分最高则将该句子序号赋予为argmax 的值并选取该句子为此步计算所得到的摘要句,如图2 中右下部分公式描述。

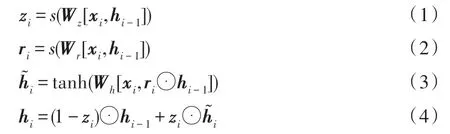
文中给定一篇包含个句子的文本,=(,,…,s),每个句子表示为s,其中每个句子又包含个单词,含有个单词的句子表示为S=(x,x,…,x),x表示为第句话中的第个词。





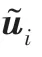

本模型的结合层级编码注意力的文本向量表示算法见算法1。
结合层级编码注意力的文本表示算法

2.3 打分函数


本模型的打分选择算法见算法2。
打分选择算法

2.4 目标函数
本文使用KL 散度作为目标函数并优化模型,对于同一随机变量的不同概率分布() 与() 。()表示样本的真实分布,()表示样本的预测分布,用KL 散度来衡量两个概率之间的差异,KL 散度越小表示()与()的分布越接近,可通过反复训练()使()接近()。这里KL 散度用表示如式(21)、式(22),最小化就能得到最好的效果。

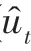

训练过程中本文使用ROUGE1 作为打分评估标准,所得分数这里用(·)表示,打分函数(u)的计算公式如式(24)所示,其中u表示已选择摘要集,{u}表示文本剩余句子集合。
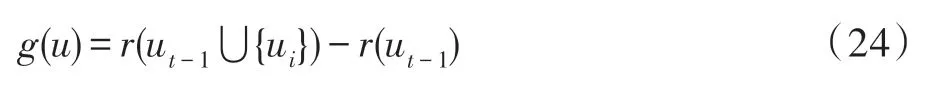
在训练过程中,打分模型所学习的分数标准为ROUGE1,考虑到ROUGE1 的分值可能为负数,这里引入归一化方法处理如式(25)所示使得分值分布在[0,1]之间。

对文中参考摘要所得到的真实分数进行softmax计算,如式(26)所示,即可得到真实样本分布。

3 实验结果与分析
3.1 数据集介绍
本文使用的CNN/Daily Mail、New York Times、Multi-News 均是人工标注的摘要,此类数据集在训练基于神经网络的摘要模型时具有较强的优势。使用Zhou 等人的预处理方法,将3 个数据集所含有的新闻文章与人工撰写参考摘要均作为输入,使用2-gram匹配的方法,从新闻文章中寻找出使得ROUGE-21得分最大的句子组合,并将其选择出的句子作为抽取式参考摘要。
(1)CNN/Daily Mail公用数据集由Hermann等人于2015 年在一文中发布。Hermann 从美国有线新闻网(CNN)和每日邮报网(Daily Mail)中收集了大约100 万条新闻数据作为机器阅读理解语料库,语料结构包括文章部分与标准摘要highlight 部分,其中highlight 部分为人工标注的用于生成式的摘要。该数据集也分为匿名版本与非匿名版本,匿名版本的数据集将实体用一些如entity4 等的标记替代。本文使用非匿名版作为数据集,文中CNN/Daily Mail 数据集共有312 085 篇新闻与对应参考摘要,其中训练集含有新闻287 227篇,测试集有新闻11 490 篇,验证集有新闻13 368篇。数据集统计如表1 所示。

表1 CNN/Daily Mail数据集Table 1 CNN/Daily Mail dataset
(2)New York Times 数据集构建于LDC New York Times语料库(https://catalog.ldc.upenn.edu/LDC2008T19),New York Times 语料库包含1987—2007 年多篇新闻文本。本文从2003—2007 年文本中除去摘要不完整及文章不完整的新闻篇章,整理出符合含有完整摘要与新闻的文本共计149 834 篇。文中New York Times数据集共有149 834 篇新闻与对应参考摘要,其中训练集含有新闻137 900 篇,测试集有新闻9 934 篇,验证集有新闻2 000 篇。数据集统计如表2 所示。
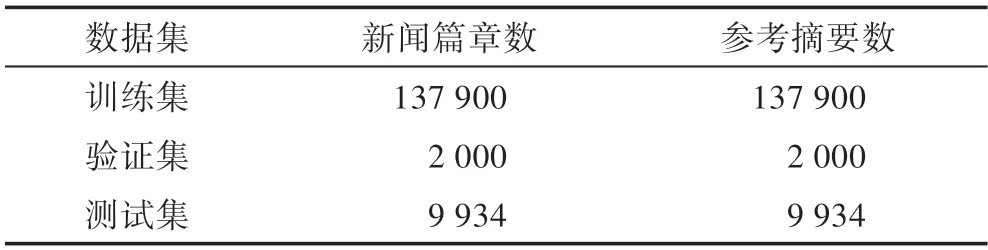
表2 New York Times数据集Table 2 New York Times dataset
(3)Multi-News 公共数据集由Fabbri等人于2019 年提出使用。Multi-News 数据集是来源于newser.com 网站的大规模多文档长句子摘要数据集,摘要为20 多名专业编辑撰写而成。本文中使用的是已将多篇原文本拼接为单文本的缩减版数据集,共含有56 216 篇新闻与对应参考摘要。其中训练集含有新闻44 972 篇,测试集有新闻5 622 篇,验证集有新闻5 622 篇。数据集统计如表3 所示。

表3 Multi-News数据集Table 3 Multi-News dataset
3.2 评价指标
本文使用2004 年由ISI 的Chin-Yew Lin 提出的一种自动摘要评价方法,是评估自动文摘以及机器翻译的一组指标。ROUGE 基于摘要中元词(gram)的共现信息来评价摘要,是一种面向元词召回率的评价方法,包括ROUGE-(是-gram 中,取值有1、2、3、4)、ROUGE-L、ROUGE-S、ROUGEW、ROUGE-SU 等。其基本思想为先构建标准摘要集,将系统生成的自动摘要与标准摘要相对比,通过统计二者之间重叠的基本单元(元语法、词序列和词对)的数目,来评价摘要的质量,本文使用的为ROUGE-1、ROUGE-2、ROUGE-L。ROUGE-计算公式如式(27)所示。
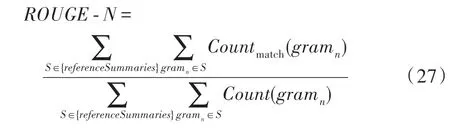
式中,表示-gram 的长度;(gram)表示同时出现在一篇候选摘要与参考摘要中的-gram 个数;(gram)表示参考摘要中-gram 个数。
3.3 预处理与实验环境
本文先用分词工具nltk 对CNN/Daily Mail、New York Times 与Multi-News 的训练集、测试集、验证集用自定义分隔符##SENT##进行分句,然后用2-gram匹配法选择出训练集中文章对应的最佳组合句子作为抽取式模型参考摘要。文中词汇表分别生成于CNN/Daily Mail、New York Times 与Multi-News 数据集,统计出所有词汇含特殊符号依次分别为728 412类、2 060 692 类、301 928 类,同时将每类词汇的词频从高到低排序选择出前100 000 类词汇作为词汇表,因为该词汇可以覆盖90%以上的训练词汇。词嵌入向量选择的是50 维的GloVe Vector,文中训练时设置文本句子长度最大为80。该模型实验环境为python3.6.5,pytorch 1.3.0,Windows10旗舰版,双2080Ti显卡。
3.4 实验结果对比与分析
本文模型使用ROUGE 作为评测指标衡量本文模型的输出摘要质量,在公共数据集CNN/Daily Mail的评测结果如表4 所示,表4 含有10 组文本摘要实验结果。在公共数据集New York Times 的评测结果如表5 所示,表5 含有8 组文本摘要实验结果。在公共数据集Multi-News 的评测结果如表6 所示,表6 含有5 组文本摘要实验结果。实验结果均为本文模型的最终ROUGE1 分值。

表4 CNN/Daily Mail ROUGE F1 分值Table 4 ROUGE F1 points on CNN/Daily Mail %

表5 New York Times ROUGE F1 分值Table 5 ROUGE F1 points on New York Times %

表6 Multi-News ROUGE F1 分值Table 6 ROUGE F1 points on Multi-News %
LEAD3 是非监督的抽取式模型,由于新闻文章普遍在开头就呈现重要信息,抽取文章的前3 个句子作为摘要通常被用作抽取式摘要中基础的对比实验。
TextRank 为2004 年由Mihalcea 和Tarau提出的非监督学习算法,将文章构建为图结构,节点为句子表示,边权重为句子间的关系。
NN-SE 为2016 年Cheng 和Lapata提出的基于句子抽取模型,主要对句子打分并基于神经网络预测标签,判断其是否属于摘要句并抽取。
CRSum 为2017 年Ren 等人提出的考虑句子上下文信息的抽取式摘要模型。
PGN 为2017 年See 等人提出的一种融合了指针生成网络与覆盖机制的生成式摘要模型,解决了大部分摘要重复与生成句子不连贯问题,取得了很好的效果。
NeuSum 为2018 年Zhou 等人提出的一种打分与抽取摘要句子相结合的摘要抽取模型。
HSG+Tri-Blocking 为2020 年Wang等人提出的基于异构图的抽取式摘要神经网络,它包含了不同粒度级别的语义节点,也是第一个将不同类型的节点引入到基于图的神经网络中并用于提取文档摘要的模型。
首先,本文将最终模型拆分为3 组对比实验与NeuSum(baseline)进行互相对比,分别是只添加句级注意力的模型、只添加词级注意力的模型、二者都添加的层级注意力动态打分抽取模型,统计出ROUGE1 分值如表4~表6 所示。
从表4可看出:(1)只加入句子级注意力时ROUGE-1 较baseline 提高了1.46 个百分点,ROUGE-2 提高了0.81个百分点,ROUGE-L下降了0.27个百分点。(2)只加入词级注意力时ROUGE-1 提高了1.47个百分点,ROUGE-2提高了0.86个百分点,ROUGE-L提高了0.66个百分点。(3)加入层级注意力机制即词级与句级注意力同时加时,ROUGE-1提高了1.78个百分点,ROUGE-2提高了1.12个百分点,ROUGE-L提高了0.91个百分点。从以上分值可知,无论是只加词级或是只加句级注意力机制都对该抽取式摘要模型效果有明显的提升作用,但只加入词级比只加入句级的效果好一些,该结果是词级别注意力粒度更细致导致的。当然,加入层级注意力之后效果是最好的,这也验证了词级与句级相结合后注意力分布更准确,更能反映出文章中句子重要性分布。
从表5 中可看出:(1)只加入句子级注意力时ROUGE-1 较baseline 下降了0.32 个百分点,ROUGE-2 下降了0.07 个百分点,ROUGE-L 下降了0.61 个百分点。(2)只加入词级注意力时ROUGE-1 提高了1.18个百分点,ROUGE-2 提高了0.23 个百分点,ROUGEL 提高了0.17 个百分点。(3)加入层级注意力机制即词级与句级注意力同时加时,ROUGE-1 提高了0.7 个百分点,ROUGE-2 提高了0.5 个百分点,ROUGE-L 下降了0.83 个百分点。从以上分值可知,加入句子级别注意力稍微削弱了抽取式摘要模型效果,加入词语级别注意力对抽取式摘要模型效果有明显提高,加入层次注意力对模型效果也有提高。
从表6 可看出:(1)只加入句子级注意力时ROUGE-1 较baseline 提高了1.07 个百分点,ROUGE-2 提高了0.57 个百分点,ROUGE-L 提高了0.28 个百分点。(2)只加入词级注意力时ROUGE-1 提高了1.35个百分点,ROUGE-2 提高了0.46 个百分点,ROUGEL 下降了2.24 个百分点。(3)加入层级注意力机制即词级与句级注意力同时加时,ROUGE-1 提高了1.44个百分点,ROUGE-2 提高了1.46 个百分点,ROUGEL 提高了0.26 个百分点。从以上分值可知,无论是只加词级或是只加句级注意力机制都对该抽取式摘要模型效果有明显的提升作用,只加入句子级注意力效果提升稍微弱一些,该结果是语料中句子长度较长的原因。加入层级注意力后效果最好,验证了词级与句级相结合后注意力分布更准确,更能反映出文章中句子重要性分布。
其次,本文模型与目前在相关领域中表现较好且使用较为广泛的模型进行对比实验,以证明本文中提出模型的有效性和优越性,从以上表4~表6 均可以看出本文模型与相关领域表现较好模型相比效果都有提升。对比baseline 模型NeuSum,在CNN/Daily Mail 数据集上ROUGE1 提高了1.78 个百分点,在New York Times 数据集上ROUGE1 提高了0.7 个百分点,在Multi-News 数据集上ROUGE1 提高了1.44 个百分点。
综上所述,本文首先设计了拆解模型的对比实验,其次将模型与该领域中得分较好的模型进行对比,证明了本文方法的有效性,同时使用多个数据集证明了本文方法的泛化性。并使用ROUGE-1、ROUGE-2、ROUGE-L 的1 值对模型进行评分,由于实验数据为公共数据集,保证了实验的合理性与有效性。最后得分ROUGE-1、ROUGE-2、ROUGE-3 的1 值都比现有模型有明显提高,由此可证明本文提出模型的有效性、优越性和较好的泛化性。
4 结束语
本文针对抽取式自动文本摘要存在的句子抽取判断因素有较强人为主观性,不能准确考虑到文章中实际每个句子以及句子中每个词对摘要影响程度从而影响抽取质量的问题,提出了一种结合层级注意力的动态打分抽取式方法。该方法通过添加层级注意力,使得文本向量表示结合了词级注意力与句子级注意力,从而更准确、明显地区分、判断出重要程度较高的句子,提高摘要质量。本文模型从整体上提高了抽取式文本摘要的抽取质量。最后通过在CNN/Daily Mail、New York Times 与Multi-News 数据集上对比实验的结果表明,本文方法与目前最佳效果相比,评测分值相近。为了更全面地评价本文方法效果,本文使用了3 个指标ROUGE-1、ROUGE-2、ROUGE-L,其1 分值都比baseline 有明显提升。由此证明了本文模型的有效性、优越性和泛化性。
由于自动文本摘要工作还在迅速发展阶段,各类研究方法与相关资源都还需要进一步完善并提高,在未来的研究路程中相信会探索出比较成熟的方法。抽取式自动摘要研究中也需要一些新的思维与角度来进一步提高摘要质量,由此也可以考虑预训练模型及混合式自动摘要的方法,通过将抽取式摘要与生成式摘要相结合,更好地提高摘要质量。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
