
基于多通道BERT的跨语言属性级情感分类方法
2022-04-12 04:15王晶晶李寿山韦思义张啸宇
中文信息学报 2022年2期
陈 潇,王晶晶,李寿山,韦思义,张啸宇,陈 强
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
随着电子科技的发展和电商平台的进一步扩大,电子贸易日益频繁,购买过商品的用户经常会反馈一些商品评价,这些评价对于无法直接接触真实商品的新用户具有很高的参考价值,同时可以帮助商家了解客户需求,及时调整企业决策。因此,挖掘这些商品评价中包含的情感倾向具有广泛的实际应用价值。
一般的情感分类任务是判断一句话或一段篇幅较长的文本的整体情感倾向,但实际中这种粗粒度的情感分类应用价值并不高。本文致力于研究一个更细粒度的情感分类任务——属性级情感分类,即判断一句话中描述的针对具体属性的情感极性,例如,“电脑挺便宜的,但是电池不太耐用,容易发烫”,句中关于属性“价格”是正面情感,而关于属性“电池”则是负面情感。因此,在设计模型进行情感分类时,本文面临的第一个挑战就是要将属性和描述语对齐,以便判断对应于每个属性的情感极性。
除此之外,本文面临的另一个挑战是跨语言处理。训练一个高性能的属性级情感分类模型,通常需要充分的标注语料,但由于人工标注会耗费大量的时间和精力,现有的情感分析标注文本资源有限且在各种语言之间分布不平衡,例如,英文是自然语言处理领域最常用的语言,所以英文的标注语料是相对最多的,而其他语言(如中文、韩文等)的标注语料并不充分。在缺少情感标注语料的语言(目标语言)环境下进行属性级情感分类任务具有很高的挑战性,而跨语言处理就是要充分利用其他资源丰富的语言(源语言)的情感标注语料中的语义和情感信息来弥补目标语言语料的不足,以期提高情感分类的准确性。但是跨语言处理需要解决一个问题,那就是源语言和目标语言的语法是完全不同的,两者之间的语义和情感无法直接互通,而模型需要适应两种语言的特点才能高效地将源语言文本中的信息应用到目标语言文本的分类任务中。
因此,我们设计了一个基于多通道BERT的跨语言属性级情感分类方法,首先进行翻译操作,使每条语句都有中、英文两种表达形式的文本;然后分别将中文文本、英文文本和拼接后的多语言文本输入中文BERT、英文BERT和多语言BERT模型中进行编码,使用构造辅助疑问句的方式将属性信息融入语句表达中;接着使用注意力机制为三个语言通道分配权重,获取语句的加权表示;最后交互融合三种语言特征,得到语句的最终表示并将其送入分类器进行情感分类。实验结果表明,本文提出的多通道方法可有效提高跨语言属性级情感分类的性能。
1 相关工作
本节首先回顾单语言属性级情感分类任务,然后介绍跨语言情感分类的一系列相关工作。
1.1 单语言属性级情感分类
属性级情感分类任务旨在预测一句话中每个属性的情感极性。现有的研究主要专注于使用各种方法(如注意力机制、记忆网络等)学习属性相关的句子表示。Wang等[1]提出了基于注意力机制的长短时记忆网络来探索属性和情感极性之间的潜在关联;Wang等[2]提出了一个层次注意力网络,结合了词和短语信息来处理属性级情感分类任务;He等[3]提出了一个基于注意力的方法,在属性级情感分类任务中融入了属性相关的句法信息;Lin等[4]提出了一个语义和上下文感知的存储网络,用于集成属性相关的语义解析信息。近年来,一些研究人员意识到了属性级情感分类任务中数据稀疏的问题,并尝试通过引入外部信息来缓解这一问题。例如,He等[5]和Chen等[6]引入了额外的篇章级情感分类中的信息;Ma等[7]提出了一个扩展的长短时记忆网络,将常识信息集成到递归编码器中,以此来提高属性级情感分类的性能。
1.2 跨语言情感分类
对于一些资源不足的语言,通常缺乏大规模的标注语料来为其构建情感分类模型,而跨语言处理理念提出了使用其他语言的丰富资源帮助进行情感分类的方法,有效缓解了单语言资源不足的问题。Lambert[8]将约束性统计机器翻译运用到跨语言属性级情感分类中,提出了一种保留观点词单元边界的翻译方法,以避免转换后需要进行源语言和目标语言之间的词对齐;Barnes等[9]探索了分布式语义表示和机器翻译对跨语言情感分类的影响;Chen等[10]和Keung等[11]采用对抗学习的方法,在模型中添加了一个判断编码特征来自源语言还是目标语言的判别网络,减少不同语言之间的分布差异,从而生成具有语言不变性的特征表示;Zhou等[12]在双向LSTM的基础上提出了一种基于注意力机制的双语表示学习模型,同时学习源语言和目标语言的文本特征;Wan[13]提出了一种半监督的协同训练方法,在训练集中加入了部分未标注的目标语言文本,使模型同时适应源语言和目标语言的特征分布。
不同于以上工作,本文使用多通道的方式训练跨语言模型,使之同时学习不同语言的特征分布,取得了较为满意的实验结果。
2 语料收集与分析
本文使用了中文和英文两个语料集,中文语料是来自苏宁易购电商平台(1)https://www.suning.com/的公开语料中有关电子产品(如手机、笔记本等)的用户评价文本;英文语料是评测任务SemEval-2016的任务5[14]中Laptop领域的文本。在设计跨语言属性级情感分类模型时,我们使用英文语料集作为源语言文本(训练集),中文语料集作为目标语言文本(测试集)。为了统一中文文本和英文文本中的属性类别,我们归纳了七个属性,分别是质量、性能、硬件、价格、电池、设计和总体,即每条中文文本或英文文本描述的是这七个属性中的一个或多个属性。我们主要将文本分为正面、负面和中性三个情感类别,其中,中性指不包含明显的情感倾向。英文语料情感类别分布情况为: 正面情感样本1 530条,负面情感样本1 027条,中性情感样本188条;中文语料情感类别分布情况为: 正面情感样本737条,负面情感样本1 205条,中性情感样本81条。
3 基于BERT的跨语言属性级情感分类方法
作为一个预训练的文本编码机制,BERT经过微调后可用于构建高性能的模型,适用于一系列的自然语言处理任务,如文本分类、阅读理解等。本文使用了三个不同的BERT模型对文本进行编码,分别是BERT-base (uncased)、BERT-base (Chinese)和BERT-base (multilingual cased)(2)https://github.com/google-research/bert,对应三个不同语言的BERT通道。
3.1 基于单通道BERT的跨语言属性级情感分类方法
基于单通道BERT的跨语言属性级情感分类的框架如图1所示,该模型只有一个英文BERT层。我们首先将作为测试集的目标语言文本翻译为源语言(即训练集使用原始的英文文本,测试集使用中文文本翻译过后的相应的英文译文文本),然后通过BERT-base (uncased)模型对训练集和测试集文本共同编码。Sun等[15]提出了构造辅助句的方法,这个方法在属性级情感分类任务中取得了优异的性能,我们将其用于生成属性相关的句子表示。具体来说,给定句子s和其对应的属性ak,BERT-base (uncased)模型的输入格式定义如式(1)所示。
[CLS]question(ak)[SEP]s[SEP]
(1)
其中,question(·)表示为属性ak构造的辅助疑问句,例如属性“price(价格)”的辅助句为“What do you think of price ?”。将上述语句对输入BERT-base (uncased)后,得到句子s的与属性ak相关的向量表示v。
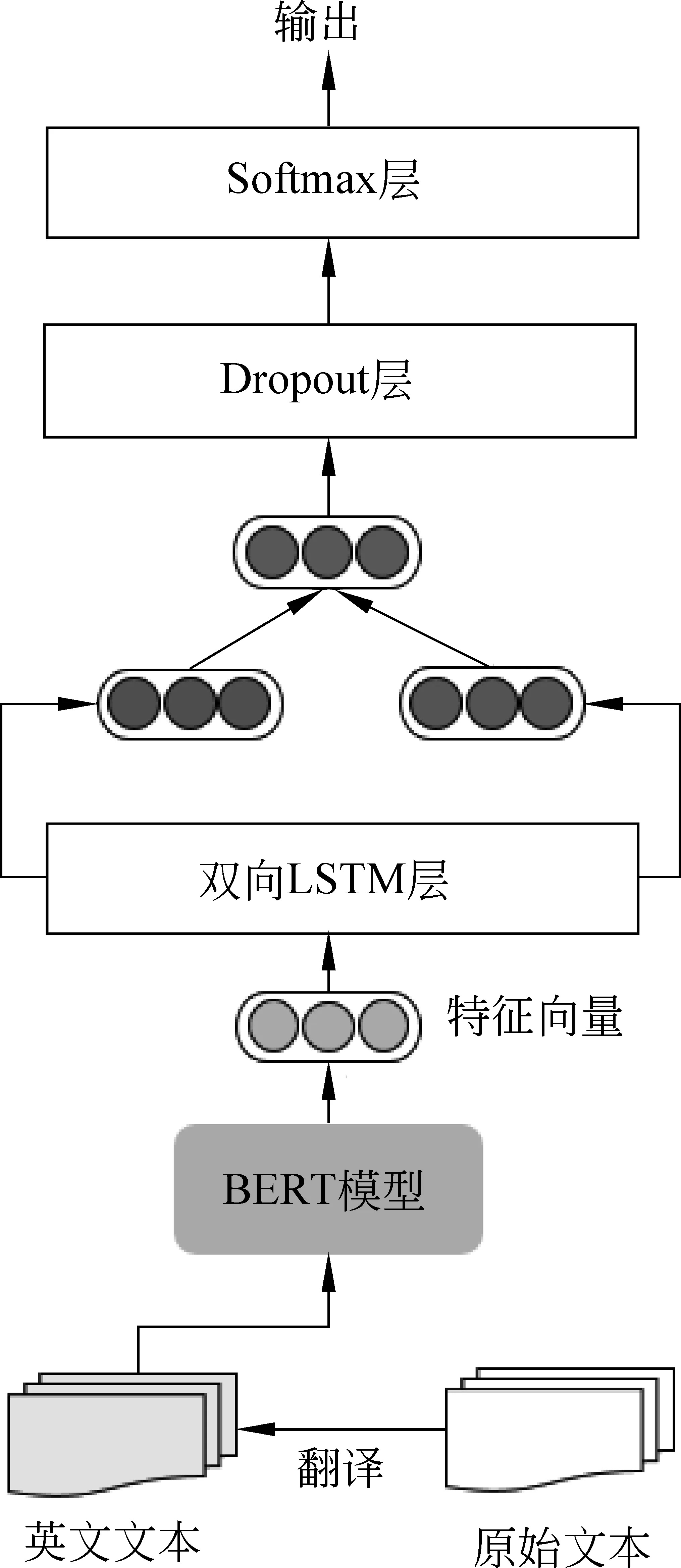
图1 基于单通道BERT的跨语言属性级情感分类模型
得到句子向量v后,我们将其输入双向LSTM层,双向LSTM[16]包括前向LSTM和反向LSTM,在每个时间步中可以同时利用过去的特征(通过前向传播)和未来的特征(通过反向传播),将双向的信息进行整合后提取出深层次的特征,得到更高维的句子向量,如式(2)~式(4)所示。
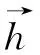
Dropout层的作用是随机让网络中部分隐含节点不工作,减少特征的数量,可以有效防止神经网络过拟合。最后Softmax层接收来自Dropout层的输出并进行属性级情感分类,得到输出结果。
以上介绍的是基于单通道BERT的跨语言属性级情感分类的一种情况,即将作为测试集的目标语言文本翻译为源语言,然后将所有文本输入BERT-base (uncased)模型进行编码。除此之外还有两种情况: ①将作为训练集的源语言文本翻译为目标语言(即训练集使用英文文本翻译过后的相应的中文译文文本,测试集使用原始的中文文本),通过BERT-base (Chinese)模型编码。②训练集和测试集都同时使用源语言和目标语言(即训练集使用原始英文和对应中文译文的拼接文本,测试集使用原始中文和对应英文译文的拼接文本),通过BERT-base (multilingual cased)模型编码。
3.2 基于多通道BERT的跨语言属性级情感分类方法
上一节简单介绍了三种基于单通道BERT的跨语言属性级情感分类方法,本节将详细描述基于多通道BERT的跨语言属性级情感分类方法。多通道BERT模型将三个单通道BERT神经网络合理高效地结合在一起,在跨语言属性级情感分类任务中取得了显著的成果。
多通道BERT模型主要包括三个模块,分别是多通道BERT编码模块、多粒度交互模块和解码模块,具体模型结构如图2所示。
3.2.1 多通道BERT编码模块
对于一条原始语句s,经过翻译处理后都会有一条中文文本sch和一条英文文本sen,将sch和sen拼接后得到多语言文本smul(即多语言文本将一条语句表述两遍,第一遍为中文,第二遍为英文)。将sch、sen和smul分别输入中文BERT(BERT-base(Chinese))模型、英文BERT(BERT-base(uncased))模型和多语言BERT(BERT-base(multilingual cased))模型进行编码,输入格式如式(1)所示。在构造辅助句时,针对语句s相应的属性ak,英文辅助句句式为“What do you think ofak?”,中文辅助句句式为“你觉得ak怎么样?”,多语言辅助句为中、英文辅助句的拼接,即“你觉得ak怎么样? What do you think ofak?”。经过BERT模型编码后,得到语句s的三个向量表示vch,ven,vmul。
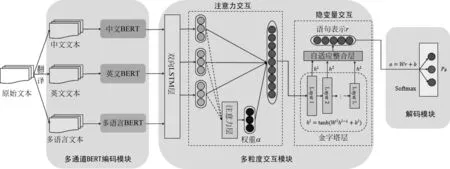
图2 基于多通道BERT的跨语言属性级情感分类方法
多粒度交互模块主要包括两部分: 注意力交互和隐变量交互,分别从粗、细两个粒度融合及提取语句特征。
3.2.2 注意力交互
双向LSTM层分别接收vch、ven和vmul作为输入,根据式(2)~式(4)获取更深层次的特征向量hch,hen,hmul∈Rd。此外,我们设计了一个注意力层,用于衡量不同语言通道提取出的语句特征对于属性级情感分类的重要程度。具体过程主要是根据特征向量hch、hen和hmul计算出一个权重向量α=(αch,αen,αmul),如式(5)、式(6)所示。
其中,x∈(ch,en,mul),Wx是一个中间矩阵,bx是偏置向量。
得到各语言通道的权重向量(αch,αen,αmul)后,我们就可以获取语句s的结合多种语言特征的向量表示,⊕表示向量拼接,如式(7)所示。
h=αch·hch⊕αen·hen⊕αmul·hmul
(7)
3.2.3 隐变量交互
经过简单的加权拼接操作得到的向量h虽然整合了中文BERT通道、英文BERT通道和多语言BERT通道提取的语句特征,但是并没有关注到三种特征之间的细粒度交互,而这种交互的过程会有助于提取潜在的特征,挖掘不同语言在描述情感时的潜在关联。
He等[17]提出一个理论,即在较高的层中使用少量隐藏单元的模型可以学习到更抽象的特征。受此启发,我们设计了一个金字塔层结构和一个自适应融合层,用于特征之间的交互,以期获取更具代表性的向量表示。
金字塔层结构包含了若干个隐层,最底端的层拥有的隐藏单元数量最多,依次向上,上一层的隐藏单元数是下一层的一半。具体来说,语句s的第l层向量表示定义如式(8)所示。
hl=tanh(Wlhl-1+bl)
(8)
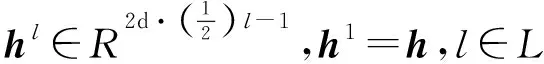
为了充分融合不同抽象程度的语句表示,我们使用自适应融合层来融合金字塔结构中所有层的表示,得到语句s的最终表示r∈Rd,如式(9)所示。
(9)
其中,∏表示多个向量的拼接操作,Wr和br是可训练参数,B=[β1,…,βL]是一组随机初始化的权重向量,表示每一层的权重,在整体模型训练的过程中不断更新。
3.2.4 解码模块
得到语句s的最终表示r后,我们将其输入Softmax分类器,如式(10)所示。
o=W·r+b
(10)
其中,o∈RC是输出向量,C表示情感极性的个数,W是权重矩阵,b是偏置。语句s分类为情感极性c∈[1,C]的概率如式(11)所示。

(11)
其中,θ代表所有参数。最终,概率值最高的情感极性代表语句s关于属性ak的情感倾向。
3.2.5 模型训练
我们在语料集T上使用交叉熵损失来训练整个模型,即训练的目标为最小化以下损失函数,如式(12)所示。
(12)
其中,E表示期望最大化,“~”表示随机抽样操作,si是第i个待预测的语句,ak是si对应的属性,yi是语句si关于属性ak的真实情感极性,θ代表整个模型中所有的可训练参数,δ是L2正则化。
4 实验结果与分析
4.1 实验设置
本文使用了英文和中文两个语料集,分别作为源语言和目标语言,语料具体来源和情感分布情况如第2节所示;在实验过程中,我们使用腾讯翻译(3)https://fanyi.qq.com/进行中英文之间的转换。由于两个语料集中情感分布都极不平衡,中性情感的文本数量明显小于正面情感和负面情感的文本,因此我们设计了两组实验: 剔除中性情感文本的正、负情感二分类实验和包括中性情感文本的正、负和中性情感三分类实验,以此检验我们提出的多通道方法在提高跨语言属性级情感分类性能上的稳定性。
在具体实验过程中,各项参数设置如下: 多个BERT编码器生成的表示向量的维度均为768;注意力交互模块的双向LSTM层生成128维的表示向量,Dropout参数设置为0.4;隐变量交互模块包含3个神经元数量依次减少的隐层;整个模型使用SGD优化器,学习率设为0.01;在训练过程中,batch_size为16,epochs设置为10。
本文采用标准正确率(accuracy,Acc)和综合评价指标macro-F1值(F1)作为衡量分类性能的标准。
4.2 实验结果与分析
为了全面地分析本文提出的Multi-BERT方法的性能,我们选取了其他几种高效的属性级情感分类方法进行比较。
TC-LSTM[18]: 此方法是一种扩展的LSTM模型,该模型使用了两个LSTM,分别从两个方向来捕获目标词的上下文信息,以生成用于情感预测的目标相关表示。(TC-LSTM_en表示训练集使用原始英文语料,测试集使用中文语料的英文译文;TC-LSTM_ch表示训练集使用英文语料的中文译文,测试集使用原始中文语料。)
ATAE-LSTM[1]: 这个方法是一种基于注意力机制的LSTM模型,将属性的表示添加到句子的表示中,加强属性和上下文之间的相互依赖。(ATAE-LSTM_en表示训练集使用原始英文语料,测试集使用中文语料的英文译文;ATAE-LSTM_ch表示训练集使用英文语料的中文译文,测试集使用原始中文语料。)
ASCNN: 这个方法将卷积神经网络(CNN)用于属性级情感分类任务中,CNN可以有效地将属性词和上下文进行语义上的对齐。(此方法训练集使用原始英文语料,测试集使用中文语料的英文译文。)
ASGCN[19]: 这个方法在句子的依存关系树上建立了一个图卷积网络(GCN),充分利用句法信息和词之间的依存关系进行属性级情感分类。(此方法训练集使用原始英文语料,测试集使用中文语料的英文译文。)
Bi-LSTM: 这个方法借助了Zhou等[12]的思想,设计了一个双语LSTM模型,采用注意力机制分别从源语言文本和目标语言文本中提取有助于情感分类的关键信息。(此方法同时使用原始英文语料和原始中文语料。)
BERT: 这个方法采用了谷歌公布的原始BERT模型(4)https://github.com/google-research/bert,相较于BERT-QA方法减少了构造辅助疑问句的步骤。(BERT_en表示训练集使用原始英文语料,测试集使用中文语料的英文译文;BERT _ch表示训练集使用英文语料的中文译文,测试集使用原始中文语料;BERT _multi表示训练集使用原始英文文本和对应中文译文的拼接文本,测试集使用原始中文文本和对应英文译文的拼接文本。)
BERT-QA: 这个方法是本文3.1节介绍的基于单通道BERT的跨语言属性级情感分类方法,通过构造辅助疑问句将属性信息融入到语句表示中。(BERT-QA_en表示训练集使用原始英文语料,测试集使用中文语料的英文译文;BERT-QA_ch表示训练集使用英文语料的中文译文,测试集使用原始中文语料;BERT-QA_multi表示训练集使用原始英文文本和对应中文译文的拼接文本,测试集使用原始中文文本和对应英文译文的拼接文本。)
XLM-based: 这个方法采用了Lample等[20]的思想,在BERT模型的基础上进行了改进,使之适应跨语言任务,取得了较好的实验性能。(此方法同时使用原始英文语料和原始中文语料。)
Multi-BERT: 这个方法是本文3.2节重点提出的基于多通道BERT的跨语言属性级情感分类方法。(Multi-BERT_2表示仅有中文BERT和英文BERT双通道的情况。)
不同方法在两组跨语言属性级情感分类实验上的性能如表1所示。
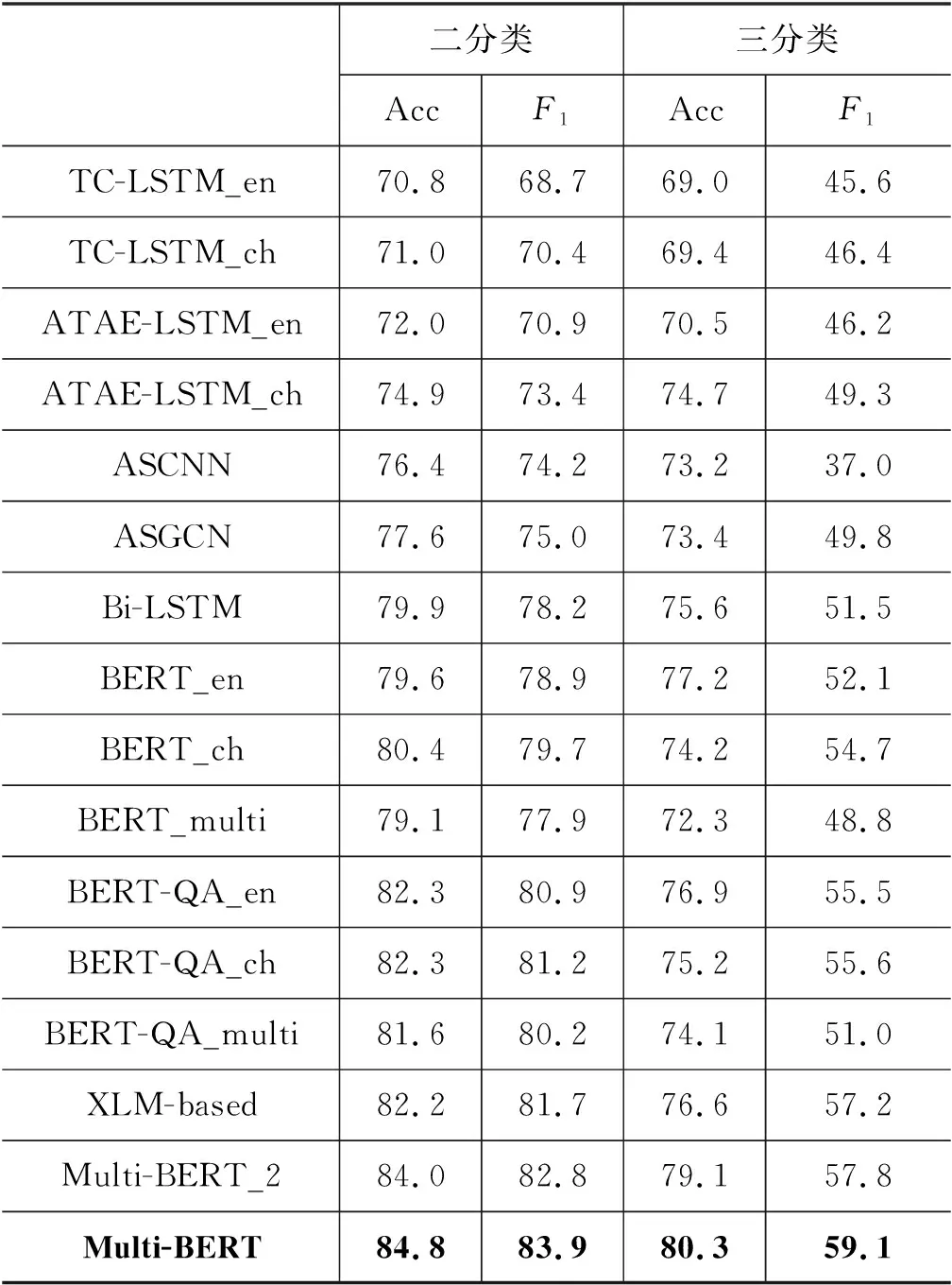
表1 各种方法在跨语言属性级情感分类任务中的性能
通过比较实验结果,我们可以发现: ①一些比较先进的方法,如ATAE-LSTM、ASGCN和Bi-LSTM,实验数据都高于TC-LSTM,这些结果说明在模型中使用合理的注意力机制对提高属性级情感分类任务的性能是有效的。②基于BERT的方法,如BERT和BERT-QA,实验性能总体高于上述几个方法,这个对比结果表明在属性级情感分类任务中,预训练的BERT模型作为编码器可以高效地获取属性相关的语句表示,有助于提高模型性能。此外,BERT-QA的实验结果总体优于BERT,说明构造辅助句的方法可以进一步提高模型性能。③本文提出的多通道方法Multi-BERT在情感分布相对平衡的二分类实验和情感分布不平衡的三分类实验中,性能均明显高于其他所有方法。尤其是相比于最基础的TC-LSTM,Multi-BERT二分类的准确率比TC-LSTM提高了13.9%,F1值提高了14.4%;三分类的准确率提高了11.1%,F1值提高了13.1%。TC-LSTM性能取TC-LSTM_en和TC-LSTM_ch的平均值。这些数据表明,本文方法可以同时学习到源语言和目标语言的特征,能够顺利地将源语言中的信息应用于目标语言的分类任务中,对于处理跨语言属性级情感分类是有效的。
4.3 性能分析
为了进一步分析各种方法在实际领域的应用前景,我们统计了几个复杂度较高的模型的训练和推理时间,T/(s/epoch)表示一轮训练所需时间,Inference T/s表示模型在所有验证集数据上的推理时间),结果如表2所示。从统计数据来看,基于BERT的模型需要的训练和推理时间更长,并且随着模型的复杂化,时间也逐渐增加。
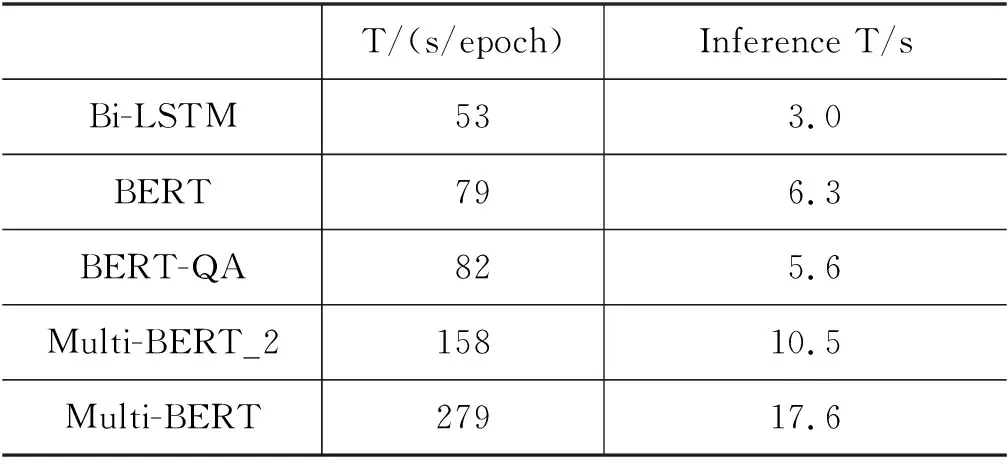
表2 模型训练及推理时间
但是,尽管复杂的模型消耗更多的时间,却仍在可承受范围之内,并且模型在细粒度情感分类任务上的性能得到了显著的提高(表1),具备一定的现实应用前景。
4.4 错误分析
为了在接下来的工作中进一步提高跨语言属性级情感分类的性能,我们对预测错误的样本进行了分析,归纳总结了以下几种错误类型:
(1) 语句中存在否定词的情况,例如,“不怎么好(not so good)”,模型错误地将此类样本预测为正面情感,因此需要进一步优化模型,使之能够更好地捕捉到否定词。
(2) 翻译的时候存在错误。由于真实语言复杂多样,机器翻译无法完全正确且贴合实际语境,例如,“手机会有一小点卡(The mobile phone will have a little bit of card.)”。
(3) 语句中的情感倾向描述得比较轻微且相对模糊,例如,“勉勉强强吧”,模型在判断这类文本时有一些困难。
(4) 语句中存在两者进行比较的情况,会出现属性和情感对应错误,例如,“小米29一个的耳机都比这个好”,模型捕捉到“好”就倾向于将针对“小米29一个的耳机”和针对“这个(耳机)”的情感倾向都判断为正面。但实际上“好”并不是对“这个(耳机)”的描述,针对“这个(耳机)”的情感判断出现了对应错误,应该判断为负面情感。
(5) 三分类的实验中,中性情感很难识别,主要是由于用于模型训练的中性样本太少,模型学习中性情感的特征比较困难,可以考虑采取数据增强的方法扩大中性情感的文本数量或者引入额外的常识信息。
5 总结
本文提出了一个基于多通道BERT的跨语言属性级情感分类方法,用以训练一个能够同时学习源语言文本和目标语言文本的语义特征、适应源语言和目标语言语法特点的分类器。具体而言,首先通过翻译,使每条语句都有中、英文两种表达形式的文本;然后分别将中文文本、英文文本和多语言文本输入不同的BERT模型中编码;接着通过注意力机制获取语句的加权表示;最后通过隐变量交互,进一步融合三种语言特征,得到语句的最终表示并将其送入分类器进行情感分类。
未来工作中,我们将尝试使用半监督的对抗学习方法,在模型训练的过程中加入未标注的目标语言文本,缓解真实语言与译文之间存在分布差异的问题。
猜你喜欢
通信技术(2021年12期)2022-01-25
新世纪智能(语文备考)(2020年4期)2020-07-25
计算机应用与软件(2018年9期)2018-09-26
鄱阳湖学刊(2016年6期)2017-01-16
中国远程教育(2016年6期)2016-12-07
财经(2016年19期)2016-08-11
中国远程教育(2016年5期)2016-06-29
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年2期)2014-06-21
小雪花·初中高分作文(2009年8期)2009-11-16
