
基于预训练语言模型的政策识别研究
2022-04-12 04:15朱娜娜张家乐孙英巍
中文信息学报 2022年2期
朱娜娜,王 航,张家乐,孙英巍
(1. 黑龙江大学 信息管理学院,黑龙江 哈尔滨 150080;2. 哈尔滨工业大学 计算学部,黑龙江 哈尔滨 150001;3. 哈尔滨学院 图书馆,黑龙江 哈尔滨 150086;4. 哈尔滨局集团公司党校,黑龙江 哈尔滨 150001)
0 引言
近年来,政策文本的定量研究逐渐成为政策研究的一个热点。相比定性研究,由于对于政策的定量研究以客观数据为依据,其研究结论在很大程度上可以克服以往对政策定性分析的主观性和随意性,而使其更具科学性,可信度更高。因此,基于政策文本的量化研究日渐成为政策科学领域的主流研究范式。政策文本是指因政策活动而产生的一切记录文献,既包括政府、国家或地区的各级权力或行政机关以文件形式颁布的法律、法规、部门规章等官方文献,也包括政策制定者或政治领导人在政策制定过程中形成的研究、咨询、听证或决议等公文档案,甚至包括政策活动过程中因辩论、演说、报道、评论等形成的政策舆情文本[1]。
一直以来,政策文本都是政策研究的重要工具和载体。为便于表述的一致性,本文将上述官方文献和公文档案等来源规范、文本由特定结构组成的政策文本统一定义为规范性政策文本;将政策解读、政策评论、政策分析等来源分散但结构不规范的政策文本定义为非规范性政策文本。非规范性政策文本虽然也具有一定的体例特征,如由标题和正文构成,但正文内容无明显结构特征。两类政策文本在政策研究中作用有所不同。规范性政策文本主要用于研究政策变迁、府际关系、政策关联、政策扩散、政策协同等;而非规范性政策文本主要用于政策情感分析、政策意见分析及政策行为预测等。随着政府信息公开趋势的日益增强,规范性政策文本越来越多,但同时,网络的普及、社交媒体的发展以及人民民主意识的日益提高,使得社交媒体上的政策评论等非规范性政策文本也日益增多。因此,在海量的政策文本数据中自动地快速识别和采集规范性政策文本,便成为大数据时代背景下政策量化研究的一个关键问题。
目前,国内外以规范性政策文本为基础进行的政策量化分析研究成果较多[2-4],但其数据采集基本依靠人工,耗时费力,且无法做到高效、一致。大数据技术的快速发展则为大规模、规范性和非规范性政策文本的自动识别、采集、数据预处理、量化分析等提供了可能性。鉴于此,本文通过深度学习方法,以我国数据政策文本为例,在政策文本数据中,对规范性政策文本进行识别,从而解决人工识别政策文本耗费时费力且数据规模有限的问题,便于后续相关政策文本自动化、实时收集和识别,为政策文本的量化研究提供多维视角,为下一步通过大数据分析,发现政策数据中隐含的规律,从语义层面进行政策量化的实证研究提供前期数据和资料准备。
1 相关工作
本文所研究的政策文本的自动识别主要涉及两个方面的工作: 一方面,在研究方向上,政策文本识别属于政策文本的量化分析研究;另一方面,在方法上,政策文本的识别属于文本分类的研究范畴。因此,本文的相关工作将从以上两个方面进行阐述。
1.1 政策文本量化研究
政策文本量化研究是将内容分析法、统计学、文献计量学等学科方法引入,围绕政策文本进行研究,对政策文本内容与外部结构要素进行量化分析,政策内容量化以政策文本语义内容为研究对象,政策文本计量以政策文本结构要素为分析对象,结合质性研究方法,揭示政策议题的历史变迁、政策工具的选择与组合、政策过程的主体合作网络等公共政策研究问题[5]。国内学者在政策文本量化方面开展了广泛研究,其中较为系统性的研究成果分别为: 一是清华大学公共管理学院黄萃等人基于政策工具视角进行特定领域政策文本量化分析的系列研究成果[6-7];二是南京大学商学院彭纪生等人基于中国创新政策进行量化政策演化分析的系列研究成果[8-10];三是兰州大学管理学院张国兴等人基于中国节能减排政策量化分析的系列研究成果[11-13]。
然而,已有政策文本量化分析研究都仅限于小数据样本上的分析研究,其收集政策文本的方法为人工采集,本文针对人工采集数据的规模有限和人力耗费问题,提出一种基于深度学习的方法,从而自动化、大规模地获取政策文本,并对规范性和非规范性政策文本进行识别。
1.2 文本分类技术
政策文本的识别属于文本分类范畴的问题。文本分类是对未知类别的文本进行自动处理,以判别其所属预定义类别集中的一个或多个类别。该技术可有效解决数字时代各种电子形式的文本文档数量的激增所带来的信息过载问题。因此,一直以来作为文本数据管理的一个重要方面,受到学术界的密切关注,并在信息过滤、网络检索、情感分析、情报处理和数字图书馆等领域有着广泛应用[14-15]。相比以往依靠专业人士进行人工分类的传统文本分类形式,文本分类显然更为省时省力。然而,文本分类的前提是将文本建模为在词属性方面具有频率的定量数据,而文本又是一种具有稀疏的、高维的、且大多数都是低频的属性的特殊类型数据。因此文本分类方法的设计对于文本自动分类至关重要。
国内外学者针对各种文本分类算法及其改进开展了广泛研究。传统的文本分类算法是基于统计的分类器,包括决策树分类器、基于规则的分类器、朴素贝叶斯分类器、线性分类器等类型。文献[16]提出了一种基于C4.5分类算法的决策树分类实现,文献[17]提出了一种基于贝叶斯方法的决策树算法,文献[18]使用一种自适应增强技术来提高分类的准确性。
随着文本数量的增长,传统的有监督的文本分类方法逐渐逊色。深度神经网络的发展为多样的NLP任务带来了灵感。近年来,深度神经网络[19]和表示学习[20]为解决数据离散问题提供了新的思路,提出了很多的用于学习词汇表示的神经网络模型[21-23]。神经网络重新表示一个单词称为词嵌入,是一个真正的赋值向量。词嵌入使得我们仅通过简单地使用两个词嵌入向量便可以衡量词的相关性。
基于提前训练的词嵌入,神经网络便可以用于很多NLP任务。文献[24]用循环神经网络提出了一种释义检测的方法。文献[25]使用半监督递归自编码器来预测句子的情感。文献[26]引入张量的递归神经网络来分析短语和句子的情感。 文献[27]提出了一种新颖的用于对话行为分类的循环网络。
文献[28]利用生成对抗网络检测欺骗性评论,文中首次提出了FakeGAN系统,该系统首次在文本分类任务中增加并采用生成对抗性网络(GANs)进行文本分类任务,特别是欺骗性评论的监测,实验验证了FakeGAN系统在检测欺骗性评论方面的有效性。文献[29]提出一个称为层次关注网络的模型来进行文本分类,在六个大规模的训练集上的实验结果验证了该结构明显优于以往研究成果。文献[30]提出了一种称为层次深度学习的模型来进行文本分类,该研究不同于传统分类模型,它不使用将问题看作多类别分类的方法,而是调用层次深度学习文本分类(HDLTex)方法来执行层次分类,该模型运用大量的深度学习结构在文档每个级别的层次结构中提供特定的理解。文献[31]首次运用深度学习中的卷积神经网络模型(CNN)解决极大规模多标签文本分类问题。
综上,我们可以看出,统计模型主要依赖专家经验及领域特征,而深度学习模型则可以自动地从数据中学习到文本分类所需的特征及其组合特征,因此深度学习模型更加灵活且表示能力更强,但由于政策文本本身具备一定的专业性和领域性,因此,本文试图将深度学习模型与传统的专家经验及领域特征相结合,充分发挥两者的优势,达到更好的政策文本识别效果。
2 本文方法
本文提出的模型是一种基于预训练语言模型的政策文本分类模型。模型整体结构如图1所示,使用由预训练语言模型参数初始化的多层Transformer编码器编码获取文本的特征表示,输入到分类器中得到最终的政策文本分类结果。
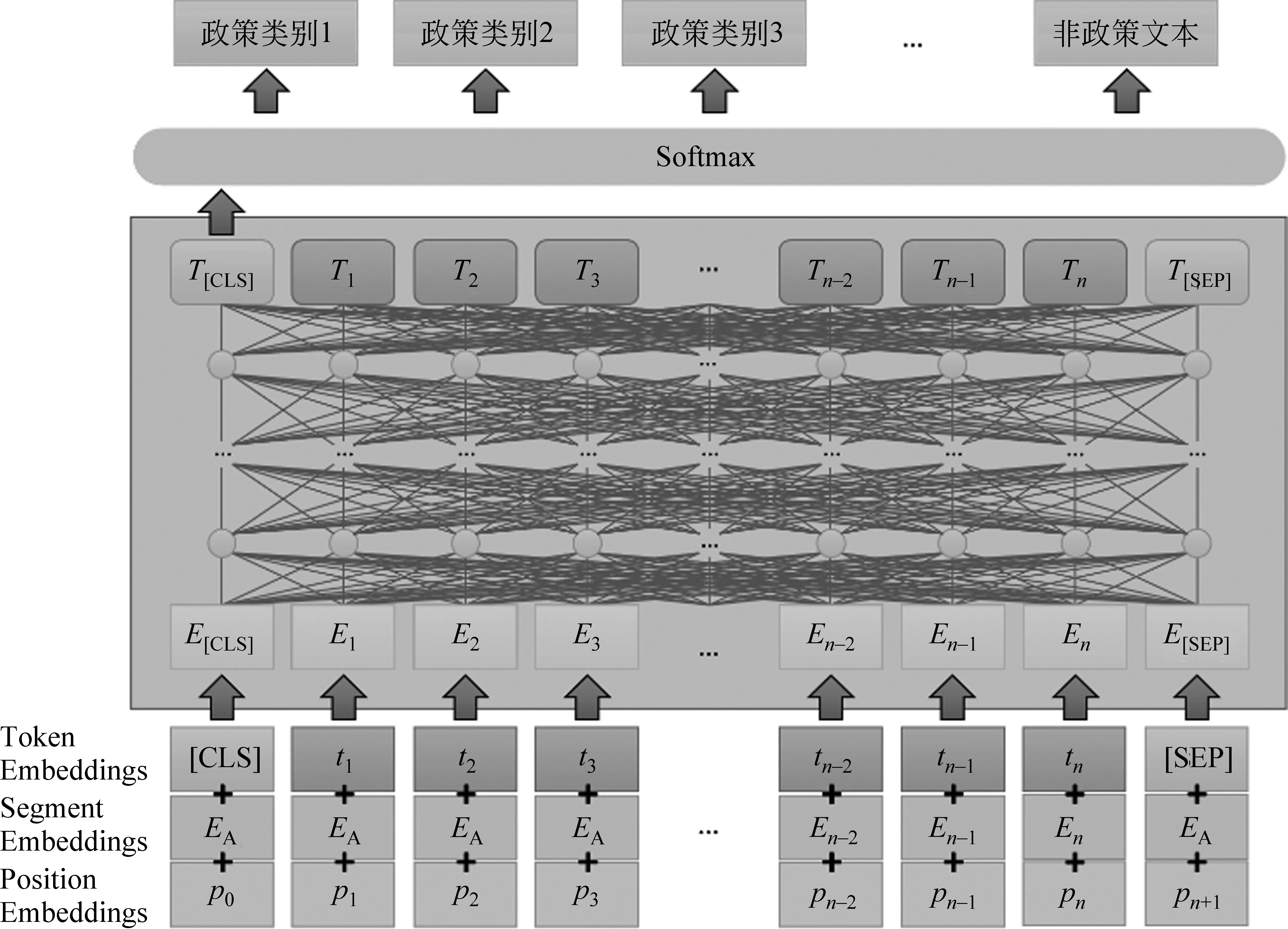
图1 政策文本分类模型的结构
2.1 使用预训练语言模型参数初始化
预训练语言模型在预训练阶段,通过在大规模的无标注数据上进行多个无监督子任务的多任务联合预训练,使模型具有更好的捕捉词法、句法、语义的能力。在预训练阶段,预训练模型能够学习到文本中的知识,因此,使用预训练语言模型进行模型的参数初始化,并添加额外的神经网络作为输出层来实现具体任务的功能,能很好地解决自然语言处理任务中训练数据稀少的问题,促进模型性能的提升。
本文的多层Transformer编码器使用预训练语言模型进行参数初始化来提高政策文本分类的性能,减少训练的时间,降低数据标注的成本。
2.2 多层Transformer文本编码器
Transformer模型由Vaswani等人[32]提出,在机器翻译、对话生成等自然语言处理领域广泛应用。Transformer包括编码器和解码器两个部分,我们仅使用Transformer进行文本特征提取,故只需要使用编码器即可。
Transformer编码器的结构如图2所示。每一层Transformer编码器由两个小的子层构成,包括多头注意力子层和前馈网络子层,在每一个子层后面还包括一个残差网络层。
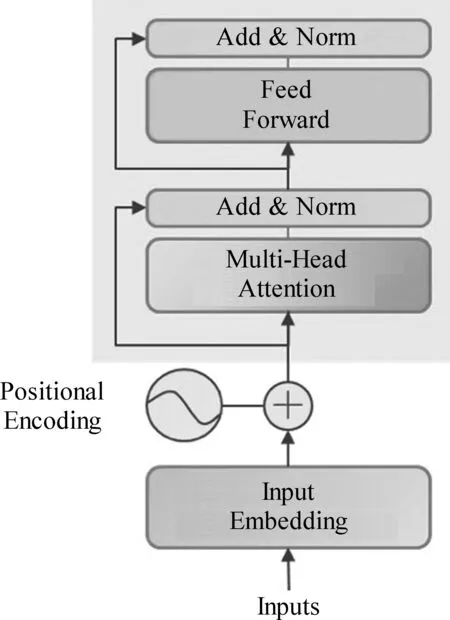
图2 Transformer模型编码器的结构
多头注意力层使用多个不同的线性变换,分别对传统注意力机制中的Q、K、V进行映射,最后将不同的多头注意力结果拼接起来。在计算注意力权重时,也使用了点积缩放机制,如式(1)~式(3)所示。
MultiHead(Q,K,V)=Concat(head1,…,headn)WO
(1)
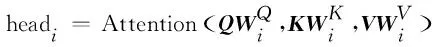
(2)

(3)
前馈网络子层为Transformer提供非线性变换,使用ReLU作为激活函数,如式(4)所示。
对于多头注意力子层和前馈网络子层,其输出都需要再额外经过一个残差层,如式(5)所示。
其中,SubLayer表示多头注意力子层和前馈网络子层,LayerNorm表示进行层归一化。
多层Transformer编码器的输入表示由三部分表示构成,包括词嵌入(word embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)。词嵌入是文本中的词对应的表示,段嵌入用于表示不同分段的信息,位置嵌入是由于Transformer不同于传统的循环神经网络(RNN),需要用位置嵌入来区分前后顺序。将三部分输入拼接后,输入到模型中。根据预训练的方式,需要在文本前后分别添加一个[CLS]和[SEP]字段。将构建好的表示输入到编码器中,经过多层的Transformer编码,使用文本开始位置的[CLS]字段在最后一层输出的表示作为文本的特征表示,实现编码器的特征抽取,如式(6)所示。
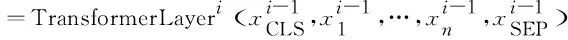
(6)
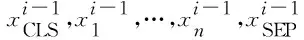
2.3 分类层
文本经过多层Transformer编码后,获得文本的特征表示。为了更加充分地利用预训练模型在预训练阶段学到的知识,我们对于预训练模型网络进行最小的改动,减少在训练阶段需要学习的参数。在获取文本特征表示之后,输入到一个前馈神经网络(FFNN)中,并通过softmax归一化获得该文本属于各个类别的概率。前馈神经网络的计算如式(7)所示。
其中,W和b是模型需要学习的参数。经过softmax,模型选择概率最大的类别作为分类结果。
3 实验及分析
3.1 实验数据集
目前没有公开的带有标签的政策数据集,因此我们构建了一个包含9个类别的政策文本数据集。数据集来源分为两部分,一部分是我们从网络上爬取到的政策数据,然后通过人工标注将政策文本分类。此外,我们对数据量较少的类别从特定领域的网站爬取了部分政策来进行补充,例如,我们从某些官网上爬取了一部分医疗政策作为医疗健康类的政策的补充。最后经过数据预处理去掉不符合条件的政策后,得到9类,共2 920条数据。我们统计了每类政策文档的句子级别的最大长度和平均长度,具体的统计信息见表1。
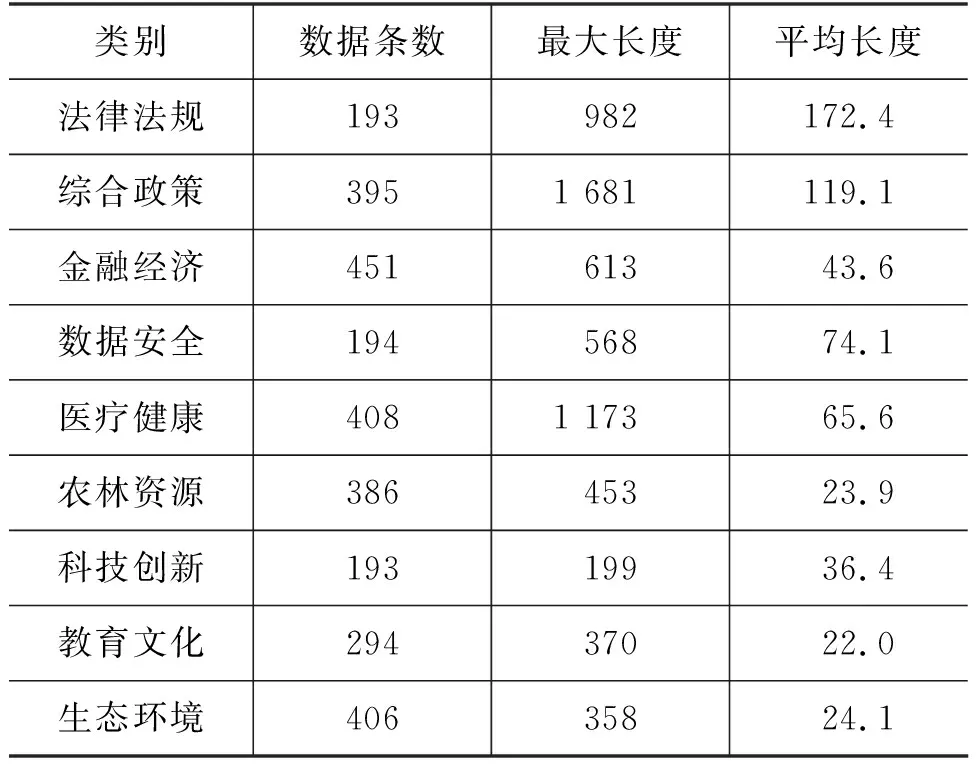
表1 实验数据统计信息
由于各类数据量不太均衡,因此我们划分训练集、验证集和测试集时按照每类政策文档占比来进行划分,即按照训练集:验证集:测试集=8:1:1的比例进行划分。
3.2 评价指标
在政策文本分类实验中,我们采用分类任务常用的分类指标: 精确率P、召回率R和F1值。准确率和召回率基于混淆矩阵计算,混淆矩阵有4个值: TP表示真实标签和预测标签都为true;FP表示真实标签为false,预测标签为true;TN表示真实标签为true,预测标签为false;FN表示真实标签和预测标签都为false。在多分类中,除了自身标签之外的其他标签都当作负样例(false)。
3.3 模型及参数设置
我们使用了BERT-base大小的预训练模型,采用12层Transformer模型,隐藏层向量维度为768,自注意力机制的头数为12,总参数量为1.1亿。我们分别使用谷歌发布的BERT-base-Chinese,讯飞发布BERT-wwm和BET-wwm-ext在本文构建的数据集上进行了微调来验证模型效果。其中warmup_steps设置为500,weight_decay设置为0.01,batchsize设置为8,分别训练15个epoch,保存在验证集上效果最好的模型。
3.4 实验结果及分析
实验结果如表2所示。
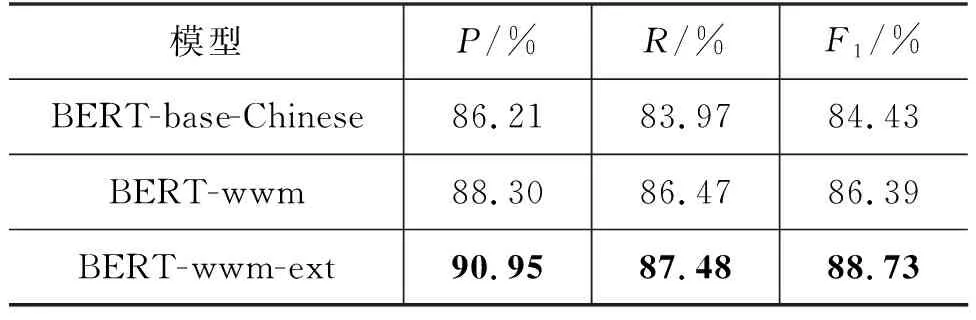
表2 实验结果
从表2可以看出,三个预训练模型上的F1结果都达到了84%以上,其中,BERT-wwm-ext效果最好,达到了88.73%,而BERT-wwm-ext的精确率甚至超过了90%,证明了我们提出的框架能够有效处理政策文本的多分类任务。BERT-base-Chinese模型的预训练样本生成使用了基于WordPiece的分词方式,这样会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被掩码,而中文与英文不同,中文有许多固定的词组,只掩码其中一部分,模型可能会通过相邻的字来预测,因而无法很好地学习到上下文信息。BERT-wwm采用了全词掩码的训练方式来生成训练样本,即如果一个完整的词的部分WordPiece子词被掩码,则同属该词的其他部分也会被掩码,这样能让模型更好地建模上下文。BERT-wwm-ext同样采用了全词掩码方式,与BERT-wwm的差别在于训练语料要更多。
我们的框架是一个分类通用的框架,利用预训练模型对文本进行编码,然后利用一个全连接层来获取不同文本的类别信息,从而得到文本的分类结果。在我们进行实验的模型上,均得到了较好的结果,随着预训练模型效果的提升,我们框架的分类能力也将得到提升。
4 结论
本文针对已有政策文本量化分析的不足,进行了自动化采集较大规模政策文本的探索,同时得益于预训练语言模型的强大语义建模能力,提出基于预训练语言模型的政策文本识别方法。在三种不同的预训练模型设置上,均取得了较好的实验效果。后续我们将针对政策内部要素进行深入分析,提出可解释性更强的方法。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
现代电力(2022年2期)2022-05-23
科学技术创新(2021年5期)2021-03-17
法律方法(2021年4期)2021-03-16
马克思主义哲学研究(2020年1期)2020-11-26
——编码器
演艺科技(2020年7期)2020-08-13
矿产勘查(2020年7期)2020-01-06
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
探测与控制学报(2015年4期)2015-12-15
