
交通道路行驶车辆车标识别算法
2022-04-12 09:24徐光柱雷帮军马国亮石勇涛
计算机应用 2022年3期
李 讷,徐光柱,2*,雷帮军,2,马国亮,石勇涛,2
(1.三峡大学计算机与信息学院,湖北宜昌 443002;2.水电工程智能视觉监测湖北省重点实验室(三峡大学),湖北宜昌 443002;3.宜昌市公安交通警察支队,湖北宜昌 443002)
0 引言
基于视频的车辆信息的检测和识别是智能交通系统的一个重要分支,而车标作为车辆的一个重要信息,具有显著和不易更换的特点,因此其检测和识别具有重要意义[1]。实际生活中单靠车牌的识别不能完全准确确认车辆身份,正确识别车标有助于车辆身份的确认,因此对于车标的准确快速识别在套牌车识别、车辆布控查询、车辆违章逃逸等方面有广泛的应用。
目前对车标识别技术的研究一般分为定位和识别两部分。
对于车标定位算法,其中较为普遍的定位算法是两步定位法,即车标的粗定位和精定位。李哲等[2]利用车牌与车标相对位置关系对车标进行粗定位,再利用投影方法进行车标精定位;杨正云等[3]利用Sobel算子和Shen算子对车牌进行定位,然后利用车牌与车标的相对位置确定车标大概位置,再利用纹理特征对车标精定位;李熙莹等[4]根据散热器栅格背景的纹理信息对车标进行精确定位;张闯等[5]在HSV(Hue,Saturation,Value)下使用滤镜定位车牌位置来粗定位车标,然后运用垂直投影法分割并分离出车标图像。这些方法定位过程繁琐,受车型、环境影响较大,定位速度慢且精度低。
对于车标识别的算法主要有模板匹配算法、传统的机器学习方法和基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习方法。李哲等[6]采用改进的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征和局部二值化特征作为联合特征,训练反向传播(Back Propagation,BP)神经网络分类器来识别车标;耿庆田等[7]利用尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算子对图像的视角、平移、放射、亮度、旋转等不变特性进行提取,并采用BP 神经网络算法自主选取车标图像特征进行分类、匹配和识别;张硕[8]利用Adaboost 算法训练出各种车标分类器,并将各种车标分类器组合在一起,实现车标的识别。上述方法使用HOG、SIFT 等机器学习提取图像特征,使用支持向量机(Support Vector Machine,SVM)、BP 神经网络等分类器进行识别,该类方法可识别较多类车标,但是对误识别的车标无法判断,且识别率与训练样本数量、种类密切相关。Huang 等[9]采用基于卷积神经网络模型的方法对车标进行分类,利用主成分分析提高了车标的识别精度和速度,但是出现了前期训练时间过长且对于未知品牌的车标不可识别的问题,而且受车标种类密度影响较大;叶玉双等[10]使用基于OpenCV 模板匹配和边缘检测技术来解决识别的任务,该方法有较高的识别精度,但需要车标较为清晰,不适用于交通道路中的车标识别。
针对上述车标定位效率低且精度低的问题,本文采用基于卷积神经网络的方法进行车标一步定位,速度快且精度高;针对上述车标识别中存在的受车标种类密度影响、不可识别未知类型车标及车标需高清晰等问题,本文采用基于形态学模板匹配算法进行识别,对二值化图像进行匹配,识别精度高。具体来说,本文的主要贡献包括4 个方面:
1)提出了一种改进的YOLOv4 车标检测算法,该算法可对车标一步定位,提高了检测速度;且通过K-Means++重新聚类初始锚框值,并加入ResNet 残差网络提高了小目标复用率,提高了检测精度。
2)采用形态学模板匹配算法对检测到的车标进行识别,该算法对车标二值化处理后与模板库中的模板进行匹配,有效减少了色差、光照、噪声等环境影响,提高了识别精度。
3)采用DenseNet201 卷积神经网络对车标进行分类训练,该训练模型可识别130 种车标。
4)本文提供了包含130 种车标的车标模板库和60 000张包含130 种车标的车标数据集。
1 相关技术
1.1 YOLOv4算法原理
基于深度学习的目标检测算法分为两大类:一类是两阶段检测算法(R-CNN(Region-CNN)[11]、Fast-R-CNN(Fast-Region-CNN)[12]、Faster-R-CNN(Faster-Region-CNN)[13]);另一类是一阶段检测算法(YOLO[14-17]系列)。前者是基于候选区域检测算法,在检测精度上占优势;后者是基于回归检测算法,则在检测速度上占优势。YOLOv4 目标检测算法[17]以CSPDarknet53 作为骨干网络,相比Darknet53 加入了CSPNet结构[18],增强了CNN 学习能力,减少了计算量,在不降低速度的同时提高了检测精度;并在CSPDarknet 上添加了SPP 模块[19],相比传统最大池化方式,其可以分离出最重要的上下文特征;颈部采用路径聚合网络(Path Aggregation Network,PAN)[20]与特征金字塔(Feature Pyramid Network,FPN)[21]相融合的结构,针对不同层级的检测器,挑选PAN 对不同骨干层进行参数聚合,改善了FPN 由浅层特征向深层传递导致的浅层特征丢失的问题;检测头部延续了YOLOv3 中的YOLOhead,最终形成了“CSPDarknet+FPN+PAN+YOLOv3-head”的模型结构,如图1所示。
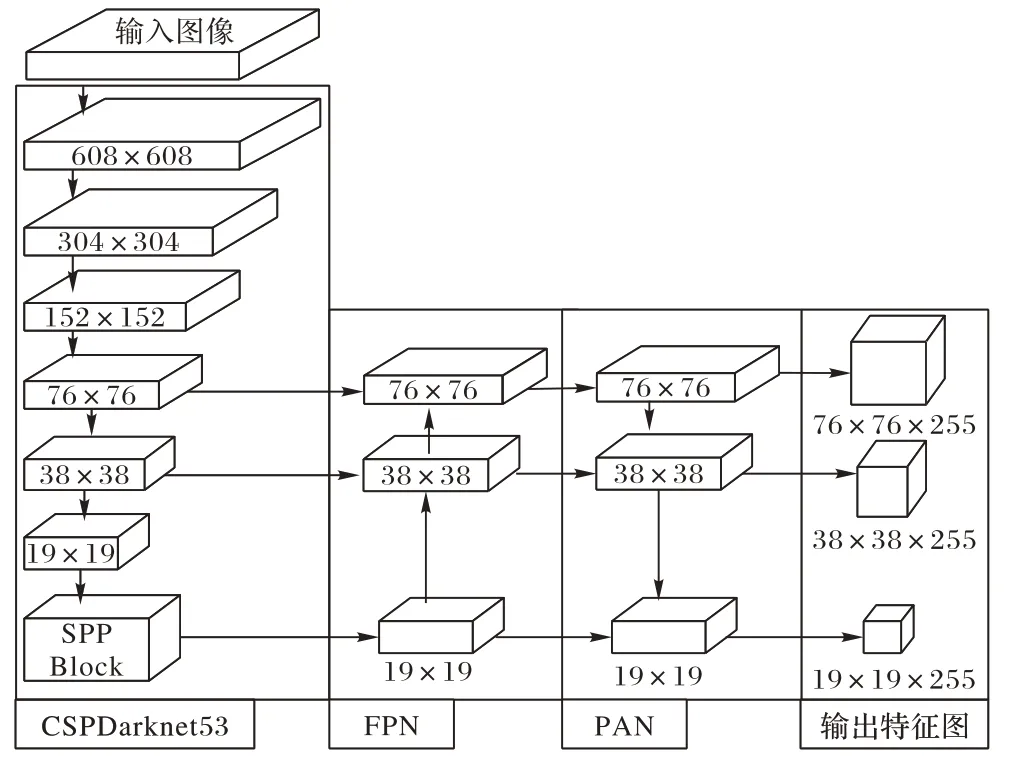
图1 YOLOv4网络结构Fig.1 Network structure of YOLOv4
YOLOv4 优化方法还包括Mosaic 数据增强,丰富了数据多样性;采用Mish 激活函数[22],其上无边界性(即正值可以达到任何高度)避免了由于封顶而导致的饱和;采用DropBlock[17]特征增强缓解过拟合等。YOLOv4 是一种结合了大量前人研究技术,加以组合并进行适当创新的目标检测算法,该算法实现了速度和精度的完美平衡。相对于YOLOv3 在准确率上提升了近10 个百分点,然而速度几乎没有下降,其检测性能表现十分优异。
1.2 残差网络
卷积神经网络在训练时随着网络结构的加深,会出现梯度消失,训练退化的问题,这使得模型很难继续训练。He等[23]提出的ResNet 残差网络是在VGG19 网络基础上进行修改,通过采用短路连接机制加入残差单元,该方法有效改善了随着网络层次加深带来的梯度消失问题。在网络结构中,数据进入每层个卷积层都会输出新的特征图,实现输入和输出数据的映射,ResNet 中的映射称为恒等映射(identity mapping),其残差单元通过identity mapping 的引入在输入和输出之间建立了一条直接的关联通道,从而使得强大的有参层集中学习输入和输出之间的残差。ResNet 相比普通网络每两层间增加了短路机制,这就形成了残差学习,增强了网络的表达能力。残差学习单元如图2 所示。

图2 残差学习单元Fig.2 Residual learning unit
1.3 密集连接网络
密集连接网络(DenseNet)[24]是继残差网络(ResNet)后的一个分类网络,其在ResNet 基础上同时增加了特征复用的通道,使得在各大数据集上的分类效果都优于ResNet。密集连接网络的基本组成单元是密集连接块,如图3 所示。主要特点是将每层的输出都接入该层之后的所有层的输入,此连接方式使每个层能接受前面所有层的特征映射,使得网络更紧凑、特征和梯度传递更加有效、网络更加容易训练。
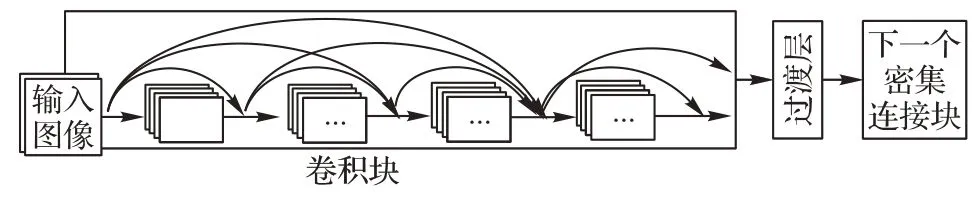
图3 密集连接块Fig.3 DenseNet block
一个密集块的输出是该密集块内所有的特征图的拼接,一个密集连接网络包含多个密集块,密集块之间通过过渡层进行相连。过渡层由BN(Batch Normalization)层、1×1 卷积层和一个2×2 平均池化层组成,主要作用是对前一个密集块进行输出和融合。
2 改进的YOLOv4车标检测算法
YOLOv4 是YOLO 系列算法中较为强大的一个版本,与YOLOv3 相比,其平均精度(Average Precision,AP)和每秒传输帧数(Frames Per Second,FPS)分别提高了10%和12%,可见YOLOv4 有较高的目标检测和识别精度。本文采用YOLOv4 进行目标检测,但由于车标尺寸小,属于小目标检测,原始YOLOv4 锚框值不能适应车标尺寸,对目标物体不能有好的匹配度,本文采用K-Means++进行锚框值重新聚类。由于车标目标较小,为充分利用其特征,在YOLOv4 输出层中加入残差网络ResNet。
2.1 K-Means++聚类锚框值
YOLOv4 为了得到较好的训练效果采用K-Means 算法重新聚类锚框,但由于该算法本身的局限性,聚类结果会受初始值选取的影响,为了更加有效地匹配目标物体,在选取K时,可以一个一个选取,不要一次性选取K个,因此本文采用K-Means++算法[25]对初始锚框值重新聚类。其步骤如下:
1)输入数据集中随机选择一点作为第一个初始中心点;
2)计算每一个点到选取的中心点的距离;
3)按轮盘法选择一个新的点作为一个新的中心点,选取原则:距离越大选取概率越大;
4)重复2)、3)直到K个中心点被选出;
5)利用这K个中心点作为初始点执行K-Means 算法。
2.2 加入残差网络ResNet
YOLOv4 有3 个输出层,每个YOLO 层在输出目标类别和位置之前会采用1×1 和3×3 的卷积结构用于转换特征维度。由于车标尺寸较小且形状多样性,传统YOLOv4 在输出层直接进行卷积操作并输出,没能充分利用小目标特征,为了适应小目标的检测,提取更细致的纹理等特征,就需要充分利用其特征。因此为了缓解网络层次越深,梯度消失越明显所导致的小目标特征消失,特征利用不充分,导致检测效果退化的问题,在每个YOLO 输出层之前的1×1 和3×3 的卷积间引入ResNet 残差网络结构,该结构使用短路连接机制,可以提高特征的复用率。加入残差网络的输出网络结构使网络中数据信息正向传递更加多元,传递能力更强,提高了小目标特征的复用率,有助于提高网络学习的能力,提高了车标检测精度。修改后的网络结构如图4 所示。

图4 改进后的YOLOv4输出层Fig.4 Output layer of improved YOLOv4
3 基于模板匹配的车标识别
3.1 车标模板库的建立
对于模板匹配方法,车标模板库的标准与完善是最重要的,本文在每个车标品牌官网上采集官方原始标准车标Logo图像来制作车标模板库;同时为了减少噪声、光照等环境影响所带来的色差以及车标更新换代导致的颜色差异,将模板库中的模板进行二值化处理,并统一大小为300×300 像素;由于车辆颜色深浅不一,导致车标二值化时会出现颜色反相的车标,如图5(a)所示,所以每种车标采用颜色相反的两种车标模板;而有些车标由于车辆设计的不同会导致其二值图像出现差异,所以有些车的二值化模板库会有多个模板,如图5(b)所示。最终制作了130 种车标模板,包含286 张,如图6 所示。
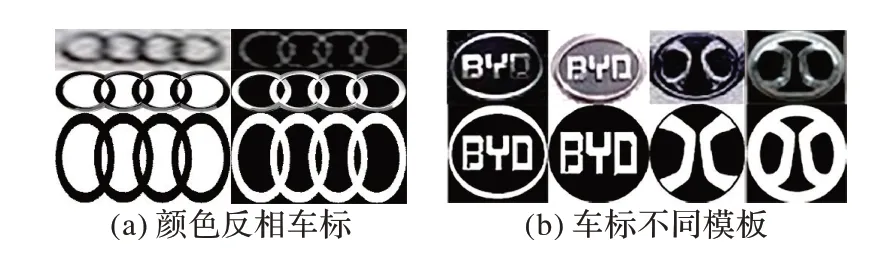
图5 车标二值化Fig.5 Vehicle logo binarization

图6 车标模板库Fig.6 Vehicle logo template library
3.2 车标模板匹配
模板匹配就是在模板库中搜索和待查找图像相匹配的模板。本文使用车标定位中得到的车标作为待查找图像,然后在模板库中逐个匹配模板图像,操作流程如图7 所示。
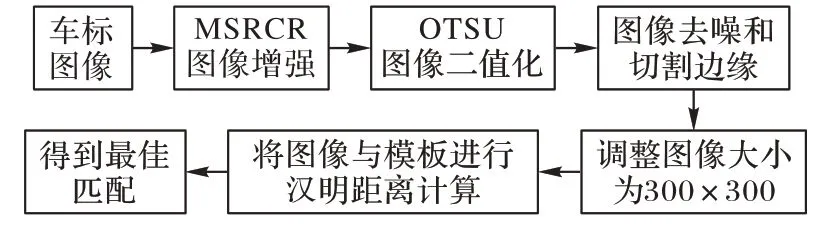
图7 模板匹配流程Fig.7 Flowchart of template matching
其中步骤2 中进行MSRCR(Multi-Scale Retinex with Color Restoration)[26]图像增强,由于部分车标图像受环境光的影响,使车标纹理不明显,在OTSU[27]二值化图像时,会丢失车标部分位置,所以采用MSRCR进行图像增强。该算法可对每个通道的分量比值进行调整从而降低色彩失真的影响,并且该算法对清晰图像增强后,对二值化不会产生影响。如图8为原始图像和MSRCR 增强图像后的OTSU 二值化图像。

图8 原始图像和MSRCR增强图像后的OTSU二值化图像Fig.8 OTSU binarized images of original image and MSRCR enhanced image
步骤3 中,前期分别进行OTSU、Kittler 最小分类错误(Kittler Minimum error thresholding,KittlerMet)[28]、niblack[29]和交叉皮层模型(Intersecting Cortical Model,ICM)[30]二值化图像处理(如图9),多幅图像对比可得,KittlerMet、niblack 二值化后噪点居多,ICM 二值化图像不稳定,时好时坏,而OTSU二值化后图像相对清晰、噪点少且稳定,所以选择OTSU作为二值图像处理的方法。

图9 不同二值化算法处理后的效果对比Fig.9 Processing effect comparison of different binarization algorithms
步骤6 中汉明距离计算,由于待匹配图像与模板库中图像都为二值图像(像素值为0 或1)且尺寸都为300×300,所以两幅图像可看成0-1 矩阵,然后直接比较两个矩阵中对应位置的值,统计不相同值的个数,不相同值的个数越少,汉明距离越小,匹配度越高。如图10 所示,矩阵A和矩阵B中,元素不相同的位置为2、6、7、11、13、14 共有6 个,所以汉明距离为6。

图10 汉明距离计算原理Fig.10 Calculation principle of Hamming distance
4 实验与分析
4.1 实验环境
本文所提出的车标检测和车标识别方法是基于OpenCV和Darknet 框架实现,在Ubuntu18.04 系统下采用Intel i7-9700 2.9 GHz 处理器、32 GB 内存、Nvidia Geforce GTX1080ti 8 GB 显卡进行实验。
4.2 实验所用数据集
本实验数据采集于不同路段,不同时间段湖北宜昌、浙江义乌和浙江宁波三地。对采集的视频数据进行车辆检测,提取出车辆,得到一个车标检测数据集,如图11;然后通过增强图像对比度、饱和度、调整亮度、添加噪点、图像模糊等方式进行图像扩增,符合环境多样性,如图12;接着再对图11所示的车标检测数据集进行车标检测得到车标识别数据集。

图11 车标检测数据集Fig.11 Vehicle logo detection dataset

图12 数据扩增效果Fig.12 Data augmentation effect
目前公开车标数据集有XMU(XiaMen University vehicle logo dataset)[31]和HFUT-VL(Vehicle Logo dataset from HeFei University of Technology)[32]。XMU 数据集包含10 个制造商的11 500 幅图像的车辆徽标数据集,所有分割的图像均被归一化像素为70×70,该数据集经过各种变形处理以模拟各种恶劣的户外情况,增强鲁棒性,但是车标大部分为粗略定位的车标图像,且车标种类和数量较少。HFUT-VL 数据集分为HFUT-VL1 和HFUT-VL2 数据集,前者通过自动裁剪工具获得,包括80种车标图像,每个类别有200张图像,标准化像素为64×64;后者通过粗定位获得,包括80种车标图像,每个类别有200张图像,标准化像素为64×96。该数据集种类较多,但全部来自室外环境,且无经过变形处理,数据集多样性不强。
本文采用自制车标数据集(https://github.com/Line-code/CTGU-VLD),该数据集一部分来自交通摄像头捕获的室外车辆正面、背面、侧面区域图像,一部分来自网上车辆截取车标图像。本数据集包含130 种车标,每种车标有300~600 张不等,一共有60 000 张,每种车标都进行了数据增广(调光、变色、加噪点、旋转等),达到符合环境多样性,同时标准化像素为80×80。本文数据集有如下的优点:1)数据集包含130种车标、60 000 张车标图像,超过目前所有公开车标数据集的数量。2)数据集通过车标检测网络精确定位获得。3)数据集公开。4)数据集一部分采集自不同区域、不同室外环境(白天、傍晚、雨天等)、不同角度(正面、背面、侧面)的交通视频图像;一部分采集自网上室内、室外(停车场、二手车等)近距离单个车辆的车标图像;符合环境多样性并通过图像变形来扩增图像,提高鲁棒性。
4.3 实验流程
实验首先使用YOLOv4 网络对视频中车辆进行检测和提取;然后将提取的车辆输入改进的YOLOv4 网络进行车标定位和提取;最后将车标进行形态学模板匹配和输入分类网络。采用形态学模板匹配时,将定位到的车标首先进行MSRCR 图像增强,然后进行OTSU 二值化处理,接着将二值化的图像进行去噪和切除边缘,其次再将车标调整为300×300 大小,最后与模板库的车标模板进行汉明距离匹配,输出匹配度最高的模板。采用分类网络识别时,将车标直接输入分类网络中,即可输出识别结果。实验流程如图13。

图13 实验流程Fig.13 Experimental flowchart
4.4 车标检测实验结果和分析
针对基于监控视频的车标检测,本文采用改进的YOLOv4 网络结构,在实验初期采用K-Means++算法对锚点值进行重新聚类,K-Means++算法优化了初始聚类中心的选择方法,能够获得更好的聚类效果,获得的锚点值更加贴合车标检测的场景。原始的YOLOv4 锚点值为(12,16),(19,36),(40,28),(36,75),(76,55),(72,146),(142,110),(192,243),(459,401),K-Means++得到的新的锚点值为(20,26),(25,36),(29,23),(34,50),(35,31),(38,20),(47,42),(63,26),(172,62),更贴合车标尺寸。
实验设置输入图片大小尺寸为448×448,初始学习率为0.001,每50 次迭代后将学习率衰减为原来的0.1 倍,动量为0.9,衰减系数为0.000 5,batch 设置为64,subdivisions 设置为16;对30 000 张图片进行训练,训练完成后对10 000 张图片进行测试,训练和测试数据集分布如表1 所示。
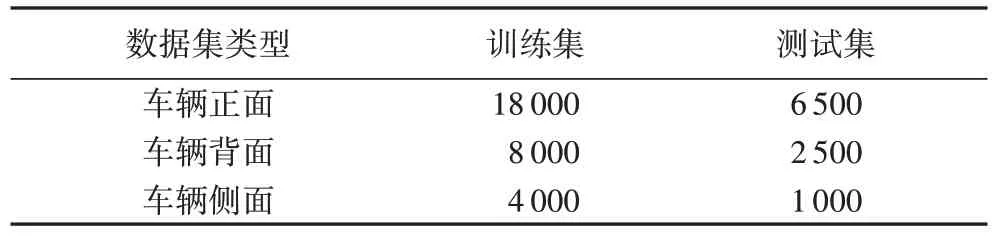
表1 实验数据集类型分布Tab.1 Distribution of experimental dataset types
本实验采用准确率P、召回率R和检测速度FPS三项性能指标评定网络性能,分别表示为:
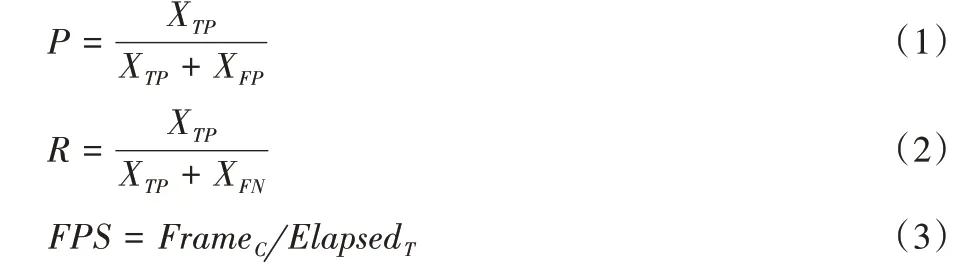
式中:XTP表示被正确检测出来的目标数,XFP表示被错误检出的目标数,XFN表示没有被检测出来的目标数,FrameC表示处理图像的数量,ElapsedT表示处理图像所用时间,FPS 单位为fps(秒/帧)。
实验结果如表2 所示,本文改进的YOLOv4 准确率和召回率分别为99.04%、98.27%,比原始YOLOv4 准确率高1.66个百分点,召回率高0.84 个百分点;但是由于加入残差网络,算法复杂度略有提高,使得速度比YOLOv4 略慢一点,但相差很小。同时本文还与文献[2]和文献[4]中两步车标定位法进行对比,实验表明车标两步定位法只适应车辆正前方和正后方,对于侧面车辆并不能准确定位出车标,因此准确率较低;且两步定位法过程繁琐、速度较慢。实验对比结果如表3 所示。

表2 原始YOLOv4和改进的YOLOv4车标检测结果Tab.2 Vehicle logo detection results of original YOLOv4 and improved YOLOv4
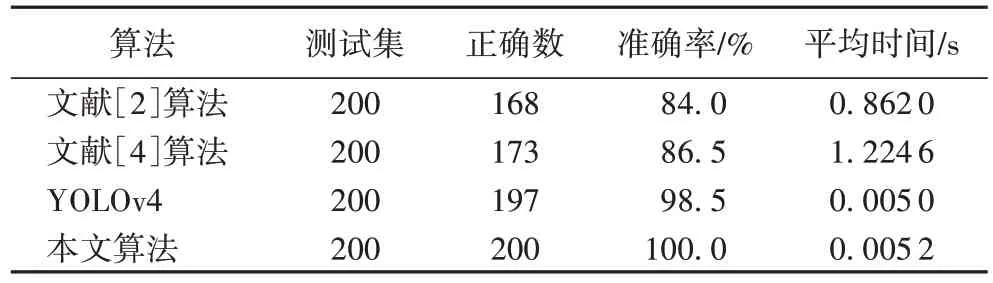
表3 不同车标定位算法的准确率和时间结果Tab.3 Accuracy and time results of different vehicle logo positioning algorithms
如图14、15 为本文算法的车标检测效果示例,部分由于车标较小,原始YOLOv4 检测不出图15 中的车标,而改进的YOLOv4 可检测出,这说明改进的YOLOv4 对微小车标检测效果更好。

图14 本文算法车标检测效果Fig.14 Vehicle logo detection effect of proposed algorithm

图15 本文算法对微小车标检测效果Fig.15 Small vehicle logo detection effect of proposed algorithm
实验结果表明,本文算法也可以检测出未知车标的车标,本文网上搜集了一些不常见车标及训练集中不包含的车标的车辆图像,该算法可检测出这些图像的车标,检测效果如图16 所示。图16 第五张图片上的车灯部分也检测成了车标,可知该模型存在不足之处,其将一些细小且有一定规则并位于车头部分的图案识别为车标。

图16 未知车标检测效果Fig.16 Effect of unknown vehicle logo detection
4.5 车标识别实验与结果分析
本实验通过计算两个车标汉明距离来得出两幅图像的匹配程度。由于模板匹配适合车辆正面和背面车标的识别,所以在车标识别阶段,采用车辆正面和背面车标数据集。将待匹配图像与模板库中所有图像依次进行汉明距离计算,最后输出汉明距离最小的模板。匹配结果如图17 所示。

图17 模板匹配结果Fig.17 Result of template matching
本文还对基于卷积神经网络的车标识别方法进行了实验分析。选取DenseNet201 分类网络进行分类训练,其中车标类别数为130 类,通过数据扩增来平衡数据集,每类数据集200~300 张不等。训练时batch 设置为64,subdivisions 设置为16,测试时batch 设置为1,subdivisions 设置为1,学习率learning_rate 设置为0.1,训练次数max_batches 设为800 000,filter 设为124,代表训练类别数,训练时的损失函数曲线变化如图18 所示,分类网络的损失函数表示为:
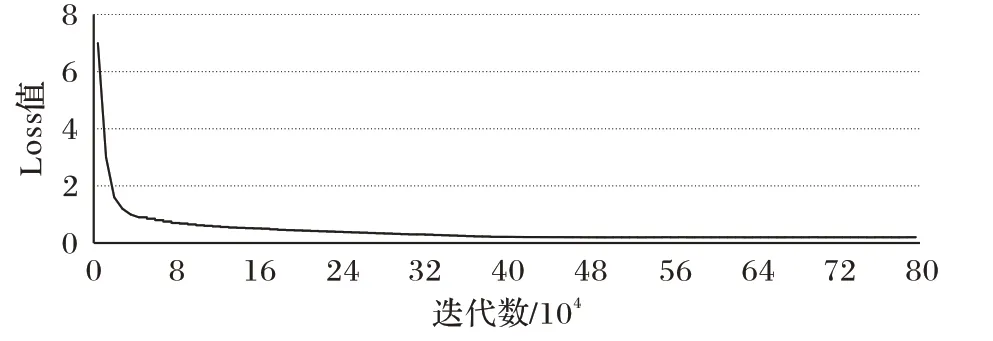
图18 分类网络损失函数变化曲线Fig.18 Loss function change curve of classification network

其中:K表示种类数;y表示标签,如果类别是i,则yi=1,否则yi=0;P表示神经网络的输出,pi表示类别i的概率。
实验用两种方法分别对30 种车标进行测试,在测试过程中发现神经网络对车标的识别容易受环境的影响,尤其是光照和色差,例如长城车标由于光照和色差,会导致颜色偏黄色,这种情况下的长城车标就容易被识别成黄色的雪佛兰,如图19 所示;五菱宏光和三菱车标由于颜色都为红色且形状有相似度,所以这两种车标容易识别错误。而且随着车标种类的增多,基于卷积神经网络的车标识别精度逐渐降低。而在模板匹配中,由于是二值化图像,匹配的主要是车标的形状,所以不会受到颜色、光照等带来的影响,且每种车标形状各不相同,即使车标种类增多也不会受其他车标的影响。

图19 不同方法对同一车标的识别过程Fig.19 Recognition process of the same vehicle logo by different methods
两种方法部分测试结果如表4 所示,模板匹配平均准确率91.93%,DenseNet201 平均准确率为88.99%。由表4 可知模板匹配总体准确度高于DenseNet201 分类网络,个别车标识别准确度低于分类网络。测试时,由于模板匹配需对车标进行预处理,过程比分类网络繁琐,速度相对较慢,但是分类网络需提前训练,且对未知车标不可识别,每出现一种新车标都需重新训练模型,而模板匹配只需将新的车标模板加入模板库,方便快速。综合考虑,模板匹配效果更佳。

表4 模板匹配与深度学习方法车标识别结果比对Tab.4 Comparison of vehicle logo recognition results between template matching and deep learning methods
为了更好验证模板匹配优越性,本文与传统的车标识别方法HOG和LBP进行实验对比,实验结果如表5所示,模板匹配对每种车标的识别率都较高,而车标颜色对卷积神经网络影响较大,噪声污染和车标形状相似性对HOG 和LBP 影响较大,可以看出在同等条件下本文的模板匹配方法在光照变化、噪声污染下都保持着较高的车标识别率,有一定鲁棒性。
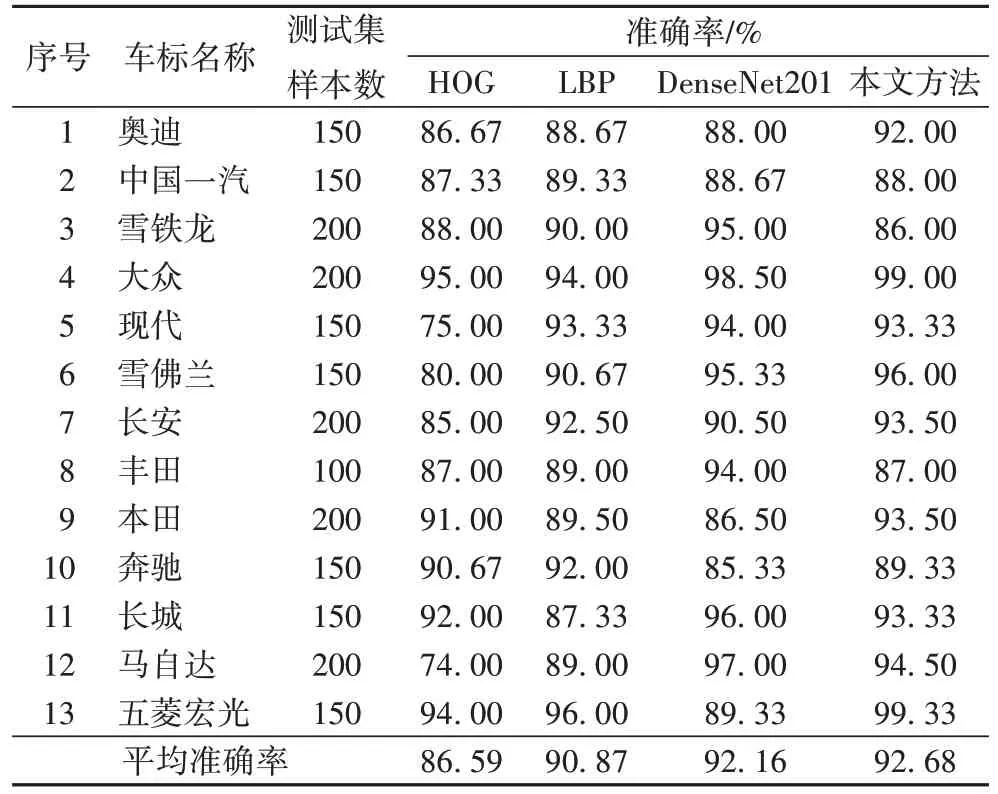
表5 不同方法车标识别准确率结果对比Tab.5 Comparison of vehicle logo recognition results by different methods
5 结语
针对目前车标定位过程繁琐,车标目标小、种类多导致识别率低的问题,本文提出一种基于深度学习与模板匹配技术相结合的方法。对大众、奥迪、丰田等常见的30 种车标进行了实验测试,实验结果表明该方法在不同环境下对车标的检测速度较快,精度高达99%,且在不同光照、对比度、强度、噪声等不利因素下仍能取得较高的识别率,其中车标模板库的全面使得该系统可应对新型车标的识别。实验表明本文对车标的检测和识别方法仍然存在改进之处:
1)模板匹配对图片预处理使得识别速度减慢,后期应考虑如何提高模板匹配速率;
2)本文的基于深度学习的车标检测和模板匹配方法只关注一张图像上只有一辆车的车标检测和识别,在以后的扩展中,可能会用到视频中,对视频中每一帧进行处理,在同一帧中同时识别出多辆车的多个车标;
3)该方法只关注白天或光线不太暗时车标的识别,以后可能会考虑夜间灯光下车标的检测和识别。
猜你喜欢
建材发展导向(2022年20期)2022-11-03
心理学报(2022年9期)2022-09-06
建材发展导向(2022年12期)2022-08-19
成都信息工程大学学报(2022年2期)2022-06-14
世界汽车(2022年3期)2022-05-23
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
建材发展导向(2021年20期)2021-11-20
考试与评价·高二版(2020年2期)2020-09-10
动漫界·幼教365(中班)(2019年3期)2019-06-11
