
面向基因调控网络的弱关联调控优化方法*
2022-04-11 08:19王夙加刘云奇孙启轩高任飞王之琼
智库时代 2022年17期
王夙加刘云奇孙启轩高任飞王之琼
(1.东北大学医学与生物信息工程学院;2.东北大学理学院;3.东北大学软件学院)
基因本身蕴含着非常庞大且复杂的生物信息[1],通过建立基因调控网络可以直观地了解基因之间的相互作用机制,基因对组织细胞的调控机理等除此之外,我们通过对基因层面的研究,可以更加深入地了解疾病的发生与发展,从而可以针对疾病的诊断和治疗采取更为适当且有效的手段,达到治疗疾病、造福人类的目的[2]。特别是近几年的在癌症治疗上的应用,例如靶向药的研发与使用就达到很好的治疗效果。它可以针对癌细胞特异性的给药,相对于传统的化疗等癌症治疗手段来说可以极大地减轻患者治疗时的痛苦。这种靶向药物的研发很大程度上依赖于准确的基因调控网络的分析与研究,因此,基因调控网络优化的研究成为了重要的研究内容。近些年来,人们提出了许多基因调控网络结构优化的方法,Jamshid等人[3]基于卡尔曼滤波和线性回归方法改进了贝叶斯网络结构学习的搜索策略,并且利用条件互信息对构建好的网络进行了结构优化。Margolin等人[4]提出了基于信息论的ARACNE算法来构建基因调控网络,消除了大多数由共表达方法得出的间接交互,从而推断转录调控蛋白与靶点基因间的直接调控关系,Liu等人[5]提出了一种利用最小冗余网络(MRNET)算法减少冗余边的优化方法,通过减少基因的非调控和弱间接调控来减少基因间冗余关系进而获取优化网络。Xing等人[6]提出了洪水-修剪-爬坡算法(FPHC)作为一种基于贝叶斯网络的基因调控网络重建的新型混合方法。
以上这些优化方法虽然取得了一定的研究进展,但当前仍有待深入地研究与探索更为有效且精确性高的优化算法。想要达到高效准确地优化基因调控网络的目的,就必须要准确地寻找出基因间的冗余关系并删除它们。基于此,我们将弱间接调控关系的分析与判断作为寻找冗余边的重点并开展了相关研究。首先,利用互信息(MI)来计算任意两个基因间的相关性,通过这种方法可以对基因间的相关程度进行量化评估。接着使用洪水—剪枝算法,把目标基因进行数据处理等级划分(DPI),划分出的目标基因间的弱关联调控关系作为待删除的边。此外,引入了聚类算法的思想,首先采用重要程度评分(IDS)对基因间的相关联程度进行评估,然后结合使用k-means聚类算法,其中表现较差的类也归为待删除的边。最后,将两种方式同时寻找并确定为待删除的边进行删除。最终经过实验对此优化算法的准确性等进行进一步验证对比,发现此方法在敏感性、特异性、精确性、准确性等评估指标上均优于其他传统方法,可提高优化效率,具有很好的应用性。
一、基于信息论的基因调控网络弱关联调控优化
(一)总体框架
通过分析基因芯片探测基因表达数据,可以构建基因调控网络。关联网络与关联性背景相似性是基于信息论的基因调控网络构建常用方法。然而,使用这两种方法很容易引入由间接调控引起的假性阳边。
面向基因调控网络的弱关联调控优化方法主要可以分为以下三个步骤:计算基因间的相关性,分别采用洪水—剪枝算法和K-means算法计算弱关联调控边,根据两种算法综合判断弱关联调控关系并删除。步骤一,计算基因间相关性。根据输入的基因表达数据,计算基因间的互信息值。步骤二,计算弱关联调控边。通过基因之间的互信息值对基因调控边进行重要程度打分,然后利用K-means算法(类别设为4),选出重要程度打分较低的一类作为待删边集合A。使用洪水—剪枝算法对每个基因进行操作,找到每个基因相关的待删边集合B。步骤三,已经计算出洪水—剪枝算法和K-means算法分别计算出的待删边集合,查询其中共同判断为弱关联调控的边并删除,更新基因的调控网络。
查找目标基因相关基因集沿用了“关联背景相似性方法”的思想:若某些基因的互信息呈一定的概率分布,他们之间可能会存在联系,于是本算法首先对于每一个目标基因与其他基因的互信息进行升序排序,并且设置断点K,将集合分为两个部分。数据处理不等式存在一定的局限性,所以本算法可以设定数据处理级别,根据数据处理不等式对相关点集中的基因进行级别定义与阈值的设定,找出阈值以上的基因集合set 1。同一类事物往往具有相似的性质,所以本项目算法基于聚类技术选择弱调控基因,首先对基因的重要程度进行特定的打分,再利用K-means算法对打分结果进行聚类,与目标基因同一类的被选为弱调控基因,其中与set1集合的交集为与目标基因存在假阳边关系的基因集合set2。算法的总体框架如图1所示。
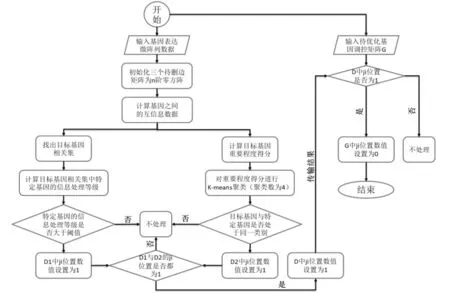
图1 面向基因调控网络的弱关联调控优化方法整体算法框图
(二)洪水—剪枝算法
已知目标节点X和所有其他节点的互信息向量M={T1,T2,......,Tm},m=n-1,并将所有互信息按升序排列。根据以上分析,零假设和备选假设如下:
零假设:没有断点存在
备选假设:一个重要的断点存在,即在向量M中存在一点将集合分为相关节点和其他节点两部分。在零假设下,若所有互信息均来自相同分布,则概率为。在备选假设下,在向量中存在目标节点X的一个断点,位于K∈[1,m]的位置,故两类节点来自两个不同的分布,可以定义如下式:
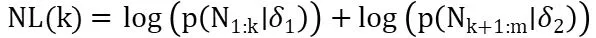
之后使用数据处理等级(DPI)对目标节点X的假阳性边进行修剪。节点Ti∈Rx的数据处理级别定义如下:
如果Ti是第一个节点,定义数据处理等级为1;如果不是,对于每个在Ti前的节点定义一个三元组,Ti的数据处理等级被定义为的最大数据处理等级,如满足数据处理等级不等式,则i+1。数据处理不等式如下:
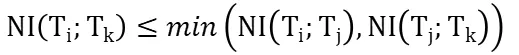
(三)K-means聚类算法
在计算了互信息(MI)和重要程度打分(IDS)后,得到每个基因与其他基因的相关性系数,通过此系数,删除那些相关性较差的基因关系[8]。我们使用K-means聚类算法,将每个基因与其它基因的相关系数进行聚类,经过百余次试验发现,将结果聚为4类,能得到最好的结果。删去4类中结果最差的一类,保留余下的3类,得到最后的网络结构。
流程如下所述:首先,读取通过IDS算法得到的IDS矩阵(随机设置4个聚类中心),分配数据点,并计算数据的平均误差,若最终仍有结果为空,则重新随机设置4个聚类中心,再进行计算,直到结果不为空;逐步更新聚类的中心,计算平均误差,比较前后两次的平均误差是否相同,直到两次的误差相同,得到最终的分类结果。我们选择最差的一类,作为最终的删边矩阵。
二、实验结果分析
(一)实验设置
实验所选用带金标准网络的大肠杆菌Dream4中的基因表达微阵列数据multifactorial数据,此数据共有五个网络,每个网络各有100个基因数据,我们选取了其中更具代表性的网络一进行分析。分别对本算法、ARANCNE算法和GRNInfer算法的性能进行评价,在对算法进行评价时,选用了敏感性、特异性、精确性、准确性、马修斯相关系数5个指标,各指标说明如表1所示。
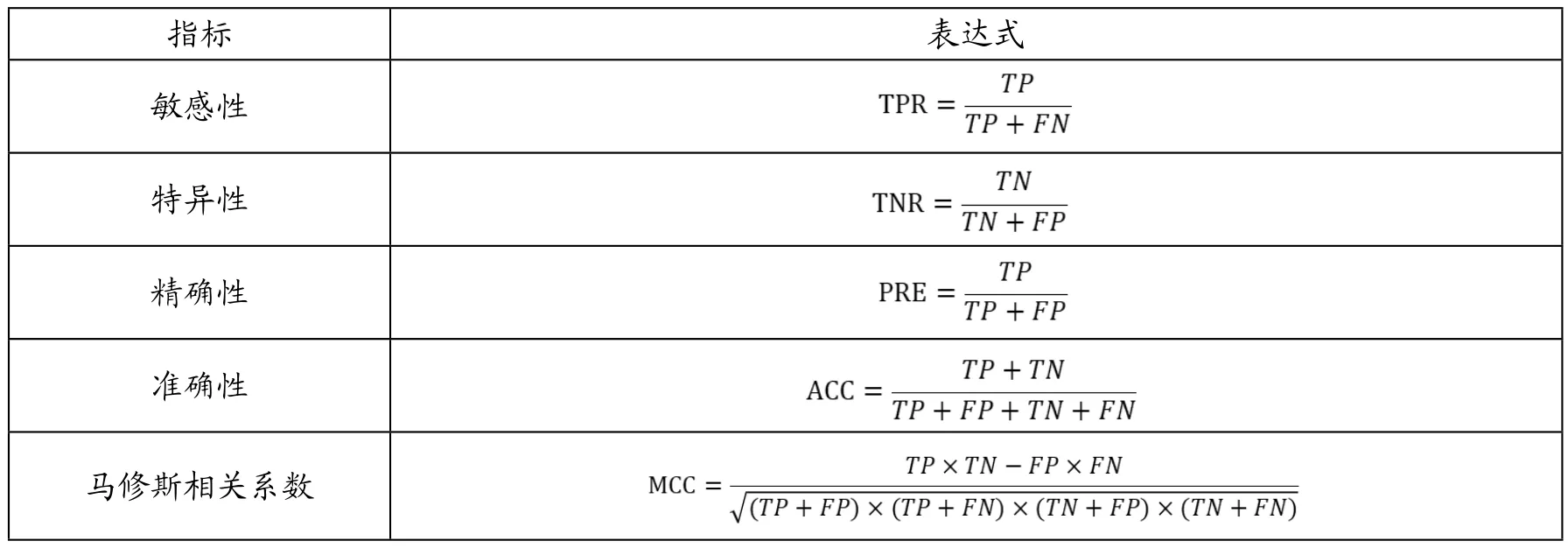
表1 各评估指标说明表
其中,TP表示真阳边,即边实际为阳性边且被判断为阳性的边;FP表示假阳边,即边实际为阴性边却被判断为阳性的边;TN表示真阴边,即边实际为阴性边且被判断为阴性的边;FN表示假阴边,即边实际为阳性边却被判断为阴性的边。
(二)实验结果
实验结果显示了三种算法的五个评估指标对比,如表2所示。

表2 各算法的五项评估指标对比
从表2中的信息我们可以得知,WRO算法五项评估指标优于ARANCNE和GRNInfer算法,在基因调控网络中的优化效果更加优良。在准确率的方面,WRO算法的准确率可以达到98%以上,比ARANCNE和GRNInfer算法的准确率提高2%-4%。特异性水平达到99%,为进一步研究基因调控网络的优化打下基础。在精确性、敏感性和MCC评估指标上,相较于ARANCNE和GRNInfer算法,WRO算法提升36%-45%,假阳边比例显著降低,筛选掉的假阳边数量和准确度较大幅度提升,从而使最终真阳边所占比例明显升高,实现了在正确删除假阳边的同时减少错误删除真阳边概率的目标。马修斯相关系数MCC的评估结果提升,也表示预测的结果与实际结果之间的误差减小,可以更加准确地预测优化结果。此外,WRO算法可操作性强,具有广阔的应用发展前景。
三、结语
为进一步提高基因调控网络的精确度,提升优化网络效率,本文提出了面向基因调控网络的弱关联调控优化方法,该方法将洪水—剪枝算法和K-means聚类算法合理有效的相互结合,准确地判断出基因调控网络中的弱关联调控关系。通过实验证明,该方法有效地提高了分析和判断弱间接调控关系的能力,减少了错误删除冗余边的概率,同时,对比其他先进方法,本方法在五项评估指标上均较优。
猜你喜欢
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
新世纪智能(数学备考)(2021年9期)2021-11-24
建材发展导向(2021年12期)2021-07-22
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
计算机应用(2016年10期)2017-05-12
电子制作(2017年20期)2017-04-26
读者(2017年5期)2017-02-15
电脑知识与技术(2016年1期)2016-03-22
